前言
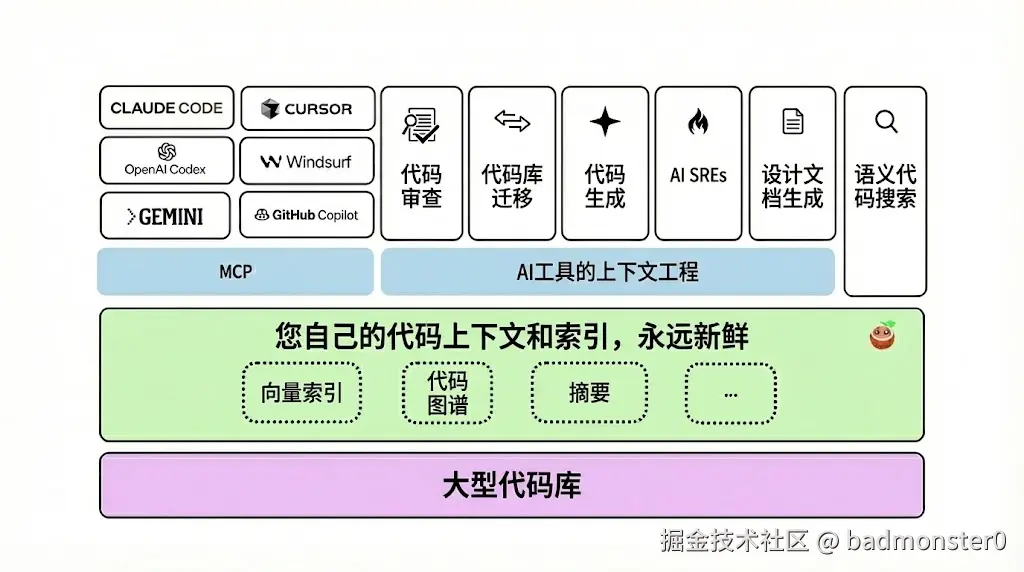
在现代软件开发中,代码库的规模越来越大。如何快速定位相关代码、理解代码上下文,成为了开发者面临的重大挑战。传统的文本搜索已经无法满足需求,我们需要更智能的解决方案。
今天,我想向大家介绍一个开源工具 ------ CocoIndex,它通过实时代码库索引和语义搜索,彻底改变了我们与代码交互的方式。
为什么需要代码库索引?
传统代码搜索的痛点
- 关键词匹配不精确:grep、ripgrep 等工具只能进行字面匹配
- 缺乏语义理解:无法理解代码的实际含义和上下文
- 扩展性差:大型代码库搜索速度慢
- AI 集成困难:为 AI 编码助手提供上下文非常复杂
CocoIndex 的解决方案
CocoIndex 利用 Tree-sitter 进行代码解析,结合向量数据库实现语义搜索,能够:
✅ 理解代码的语义和结构
✅ 支持近实时增量更新
✅ 原生支持所有主流编程语言
✅ 轻松与 AI 工具集成(Cursor、Claude、Windsurf)
技术架构深度解析
核心工作流
CocoIndex 的索引流程包含以下关键步骤:
python
# 1. 从本地文件系统读取代码文件
# 2. 提取文件扩展名,确定编程语言
# 3. 使用 Tree-sitter 将代码切分为语义块
# 4. 为每个代码块生成向量嵌入
# 5. 存储到向量数据库(Postgres + pgvector)Tree-sitter:代码感知的分块策略
与传统的按行或按字符数分块不同,CocoIndex 使用 Tree-sitter 进行语义分块:
- 保持函数、类的完整性
- 理解代码的语法结构
- 支持 Python、Rust、TypeScript、Go 等数十种语言
这意味着搜索结果总是返回完整的、有意义的代码片段,而不是被截断的碎片。
实战:构建自己的代码索引
安装配置
bash
# 安装 PostgreSQL(推荐使用 Docker)
docker run -d \
--name cocoindex-postgres \
-e POSTGRES_PASSWORD=postgres \
-p 5432:5432 \
pgvector/pgvector:pg16
# 安装 CocoIndex
pip install -U cocoindex定义索引流
以下代码展示如何索引一个 Python/Rust 混合代码库:
python
import os
import cocoindex
@cocoindex.flow_def(name="CodeEmbedding")
def code_embedding_flow(flow_builder: cocoindex.FlowBuilder,
data_scope: cocoindex.DataScope):
# 添加本地文件源
data_scope["files"] = flow_builder.add_source(
cocoindex.sources.LocalFile(
path=os.path.join('..', '..'),
included_patterns=["*.py", "*.rs", "*.toml", "*.md"],
excluded_patterns=[".*", "target", "**/node_modules"]
)
)
code_embeddings = data_scope.add_collector()
# 提取文件扩展名
@cocoindex.op.function()
def extract_extension(filename: str) -> str:
return os.path.splitext(filename)[1]
with data_scope["files"].row() as file:
file["extension"] = file["filename"].transform(extract_extension)
# Tree-sitter 语义分块
file["chunks"] = file["content"].transform(
cocoindex.functions.SplitRecursively(),
language=file["extension"],
chunk_size=1000,
chunk_overlap=300
)生成向量嵌入
python
@cocoindex.transform_flow()
def code_to_embedding(text: cocoindex.DataSlice[str]) \
-> cocoindex.DataSlice[list[float]]:
return text.transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"
)
)
with data_scope["files"].row() as file:
with file["chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].call(code_to_embedding)
code_embeddings.collect(
filename=file["filename"],
location=chunk["location"],
code=chunk["text"],
embedding=chunk["embedding"]
)
# 导出到 Postgres + pgvector
code_embeddings.export(
"code_embeddings",
cocoindex.storages.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[
cocoindex.VectorIndex(
"embedding",
cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY
)
]
)运行索引
bash
# 创建并更新索引
cocoindex update main
# 启动 CocoInsight 可视化界面
cocoindex server -ci main语义搜索:超越关键词
构建完索引后,我们可以进行强大的语义搜索:
python
def search(pool: ConnectionPool, query: str, top_k: int = 5):
table_name = cocoindex.utils.get_target_storage_default_name(
code_embedding_flow, "code_embeddings"
)
# 将查询转换为向量
query_vector = code_to_embedding.eval(query)
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute(f"""
SELECT filename, code, embedding <=> %s::vector AS distance
FROM {table_name}
ORDER BY distance LIMIT %s
""", (query_vector, top_k))
return [{
"filename": row[0],
"code": row[1],
"score": 1.0 - row[2]
} for row in cur.fetchall()]
# 示例查询
results = search(pool, "如何处理配置文件")
for result in results:
print(f"[{result['score']:.3f}] {result['filename']}")
print(result['code'])注意:即使你的查询是中文,它也能找到相关的英文代码!这就是向量语义搜索的威力。
实际应用场景
1. AI 编码助手的上下文引擎
为 Cursor、Claude、Windsurf 提供精准的代码上下文:
python
# 在 AI 提示前注入相关代码
context = search(pool, "用户认证逻辑", top_k=3)
prompt = f"""相关代码:\n{context}\n\n请帮我优化用户认证流程"""2. 代码审查自动化
python
# 查找所有与安全相关的代码
security_code = search(pool, "password hashing authentication")
# 自动检查是否使用了不安全的实践3. 大规模代码迁移
python
# 找到所有使用旧 API 的代码
old_api_usage = search(pool, "deprecated legacy API calls")
# 自动生成迁移计划4. SRE 和故障排查
python
# 快速定位与某个服务相关的配置文件
configs = search(pool, "database connection pool settings")性能优化技巧
增量更新
CocoIndex 支持增量处理,只重新索引变更的文件:
bash
# 监听文件变化,自动更新索引
cocoindex update main --watch选择合适的嵌入模型
- 快速原型 :
all-MiniLM-L6-v2(轻量级) - 高精度 :
text-embedding-3-large(OpenAI) - 代码专用 :
microsoft/codebert-base
调整分块参数
python
file["chunks"] = file["content"].transform(
cocoindex.functions.SplitRecursively(),
chunk_size=1500, # 增大块大小以保留更多上下文
chunk_overlap=400 # 增大重叠以避免边界问题
)与现有工具的对比
| 特性 | grep/ripgrep | GitHub Code Search | CocoIndex |
|---|---|---|---|
| 语义理解 | ❌ | 部分支持 | ✅ |
| 本地部署 | ✅ | ❌ | ✅ |
| 实时更新 | ✅ | ❌ | ✅ |
| AI 集成 | ❌ | ❌ | ✅ |
| Tree-sitter | ❌ | ✅ | ✅ |
| 开源 | ✅ | ❌ | ✅ |
社区和生态
CocoIndex 是一个快速发展的开源项目:
- GitHub : cocoindex-io/cocoindex
- Star 数: 3,500+(持续增长中)
- Discord 社区: 活跃的开发者讨论
- 文档 : cocoindex.io/docs
总结
CocoIndex 不仅仅是一个代码搜索工具,它是一个完整的代码理解平台。通过 Tree-sitter 的语法感知和向量数据库的语义搜索,它为现代开发工作流提供了强大的基础设施。
核心优势
- 开源且可定制 - 完全掌控你的代码索引
- 生产级性能 - 支持大型代码库的实时索引
- AI 原生 - 专为 AI 编码时代设计
- 语言无关 - 支持所有主流编程语言
如果你正在构建 AI 编码工具、代码搜索引擎,或者只是想更好地理解你的代码库,CocoIndex 绝对值得一试。
给项目点个 Star 吧! ⭐
参考资源
- 官方文档:cocoindex.io/docs/exampl...
- GitHub 仓库:github.com/cocoindex-i...
- YouTube 教程:查看官方频道的实战演示
- Discord 社区:加入讨论,获取技术支持
如果这篇文章对你有帮助,欢迎点赞、收藏、分享!有任何问题也欢迎在评论区讨论。