🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 ↓↓文末获取源码联系↓↓🍅
基于大数据的全国健康老龄化数据分析系统-功能介绍
本系统【python大数据毕设实战】全国健康老龄化数据分析系统,是一个旨在应对人口老龄化挑战、利用现代大数据技术深度挖掘老年健康数据价值的综合性分析平台。系统核心构建于Hadoop分布式存储框架与Spark高性能计算引擎之上,采用Python语言进行数据处理与算法实现,并结合Django框架提供后端服务支持。它聚焦于老年人群体,围绕基本健康状况、医疗服务利用、睡眠健康及生活质量、健康风险评估四大维度展开深度分析。具体功能上,系统能够对比不同年龄段、性别、就业状态下的健康差异,探究心理健康与身体健康的内在关联,评估口腔健康对整体健康的影响;同时,它还深入分析影响老年人就医频率的关键因素,揭示不同群体间的医疗资源获取差异,并综合评估睡眠问题与健康的复杂关系。最终,系统通过K-means聚类等机器学习算法,对老年人进行健康风险分层,构建多维健康评分体系,旨在为公共卫生政策制定、医疗资源优化配置及社区健康服务提供精准、量化、数据驱动的决策支持。
基于大数据的全国健康老龄化数据分析系统-选题背景意义
选题背景 随着社会经济发展和医疗水平进步,人口老龄化已成为全球许多国家共同面临的重大社会现象,我国也正步入深度老龄化社会。这一趋势不仅改变了人口结构,更对现有的社会保障体系、公共卫生服务和健康管理模式提出了前所未有的挑战。老年人的健康问题呈现出多维度、复杂性的特点,涵盖生理、心理、社会适应等多个层面,传统的基于小样本调查和经验判断的管理方式,已难以全面、精准地把握老年群体的整体健康状况和真实需求。因此,如何有效利用日益增多的健康相关数据,从中提炼出有价值的洞见,以支持科学决策和精准干预,成为了一个亟待解决的课题。在此背景下,运用大数据技术对全国范围内的健康老龄化数据进行系统性分析,具有重要的现实紧迫性。 选题意义 这个毕业设计项目,它的意义在于尝试将前沿的大数据分析技术应用于具体的社会健康问题中,做一次小小的探索。从实际应用角度看,通过系统性地分析老年健康数据,可以帮助我们更清晰地了解不同老年人群体的健康特征差异,比如哪些健康问题最普遍、哪些因素导致他们频繁就医。这些分析结果,或许能为社区或医疗机构在规划健康服务、分配医疗资源时提供一些数据上的参考,让资源能更精准地用在刀刃上。从技术实践角度看,本项目完整地走过了从数据采集、清洗、存储到利用Spark进行大规模计算分析和可视化的全过程,对于计算机专业的学生来说,这是一个锻炼解决复杂问题能力的绝佳机会。它不仅仅是一个理论课题,更是一次将技术与实际社会需求相结合的实践,希望能为健康老龄化这个宏大议题,贡献一点来自技术领域的微薄力量。
基于大数据的全国健康老龄化数据分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的全国健康老龄化数据分析系统-视频展示
基于大数据的全国健康老龄化数据分析系统-图片展示

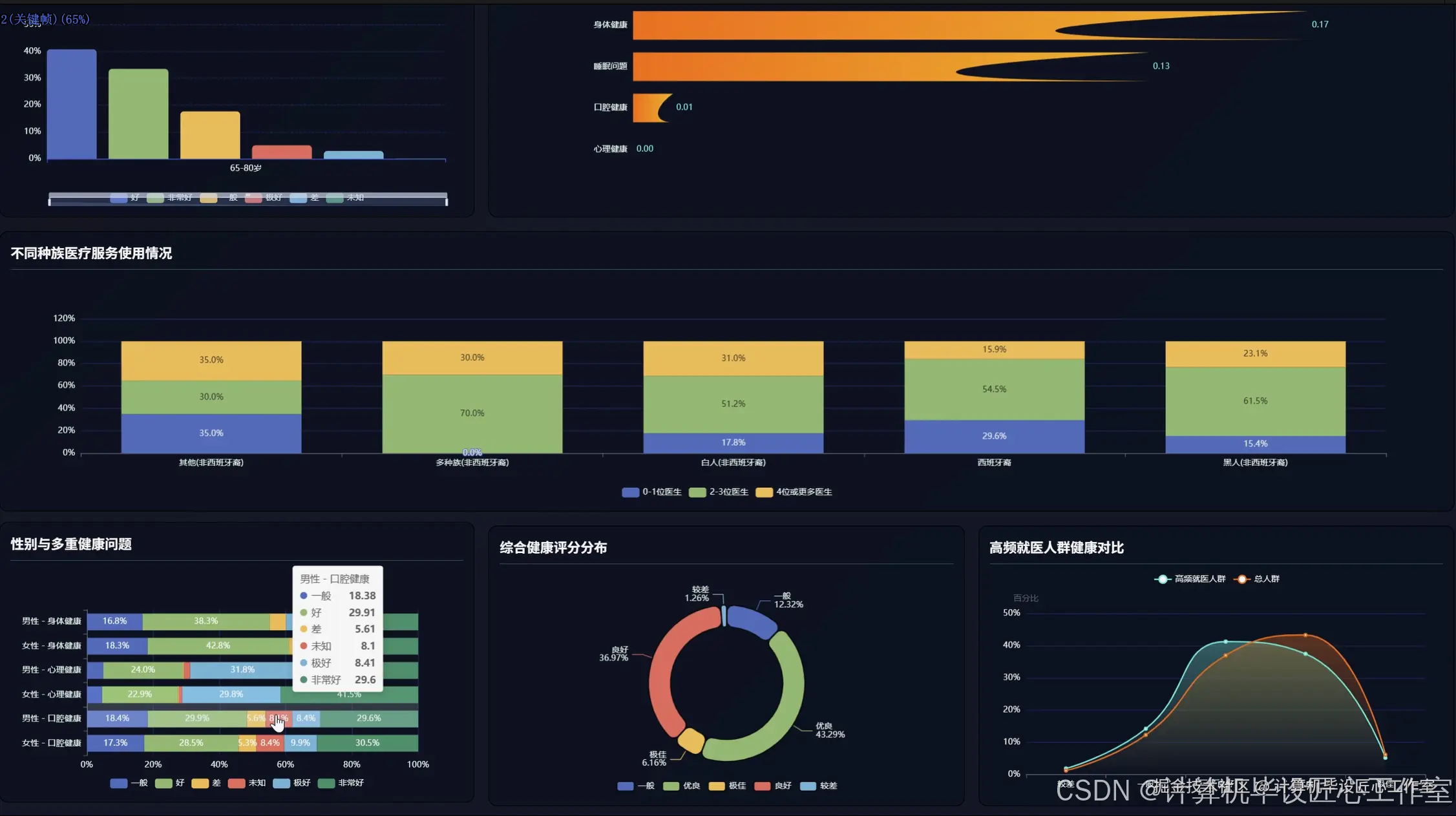
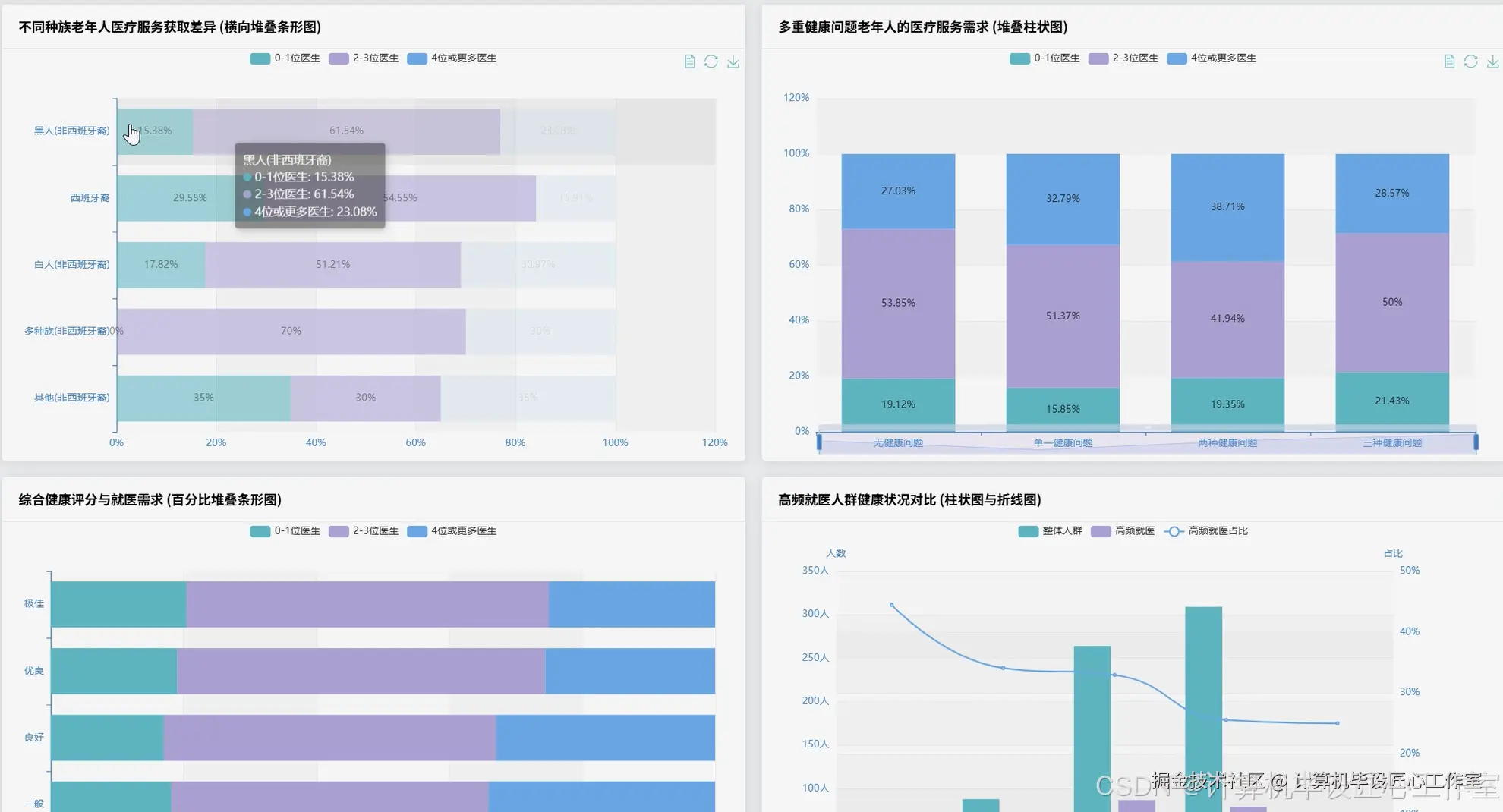
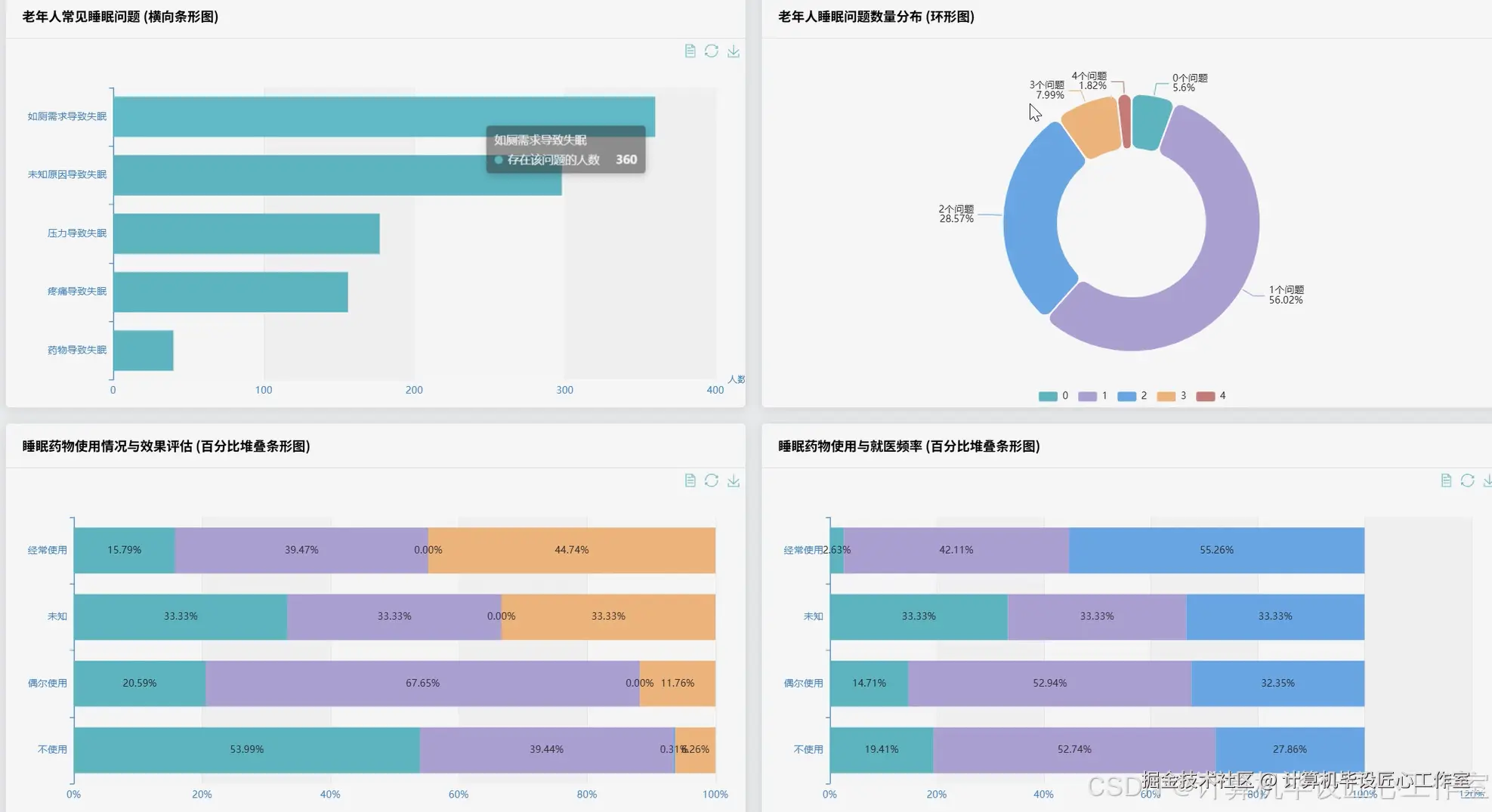
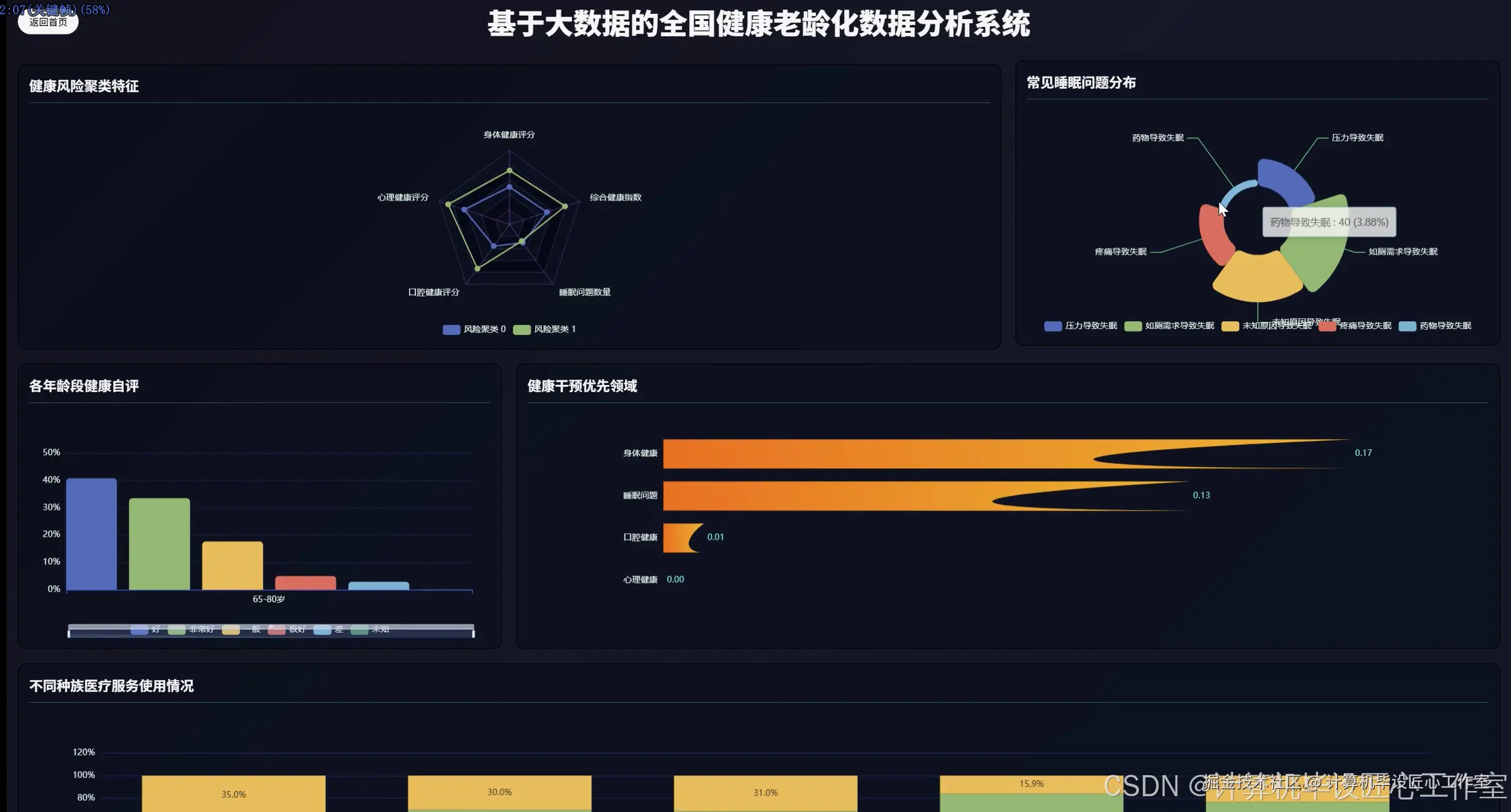
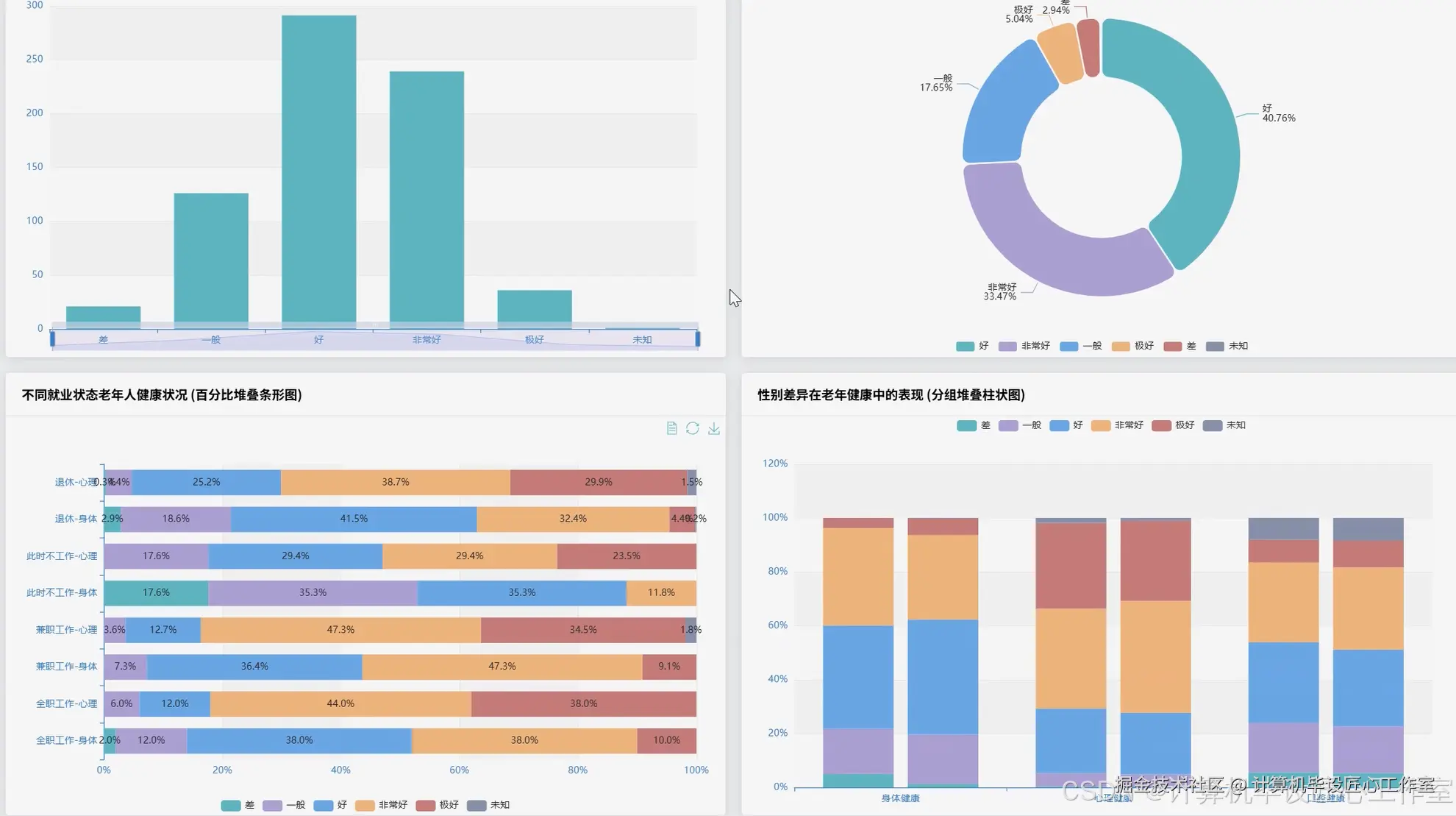
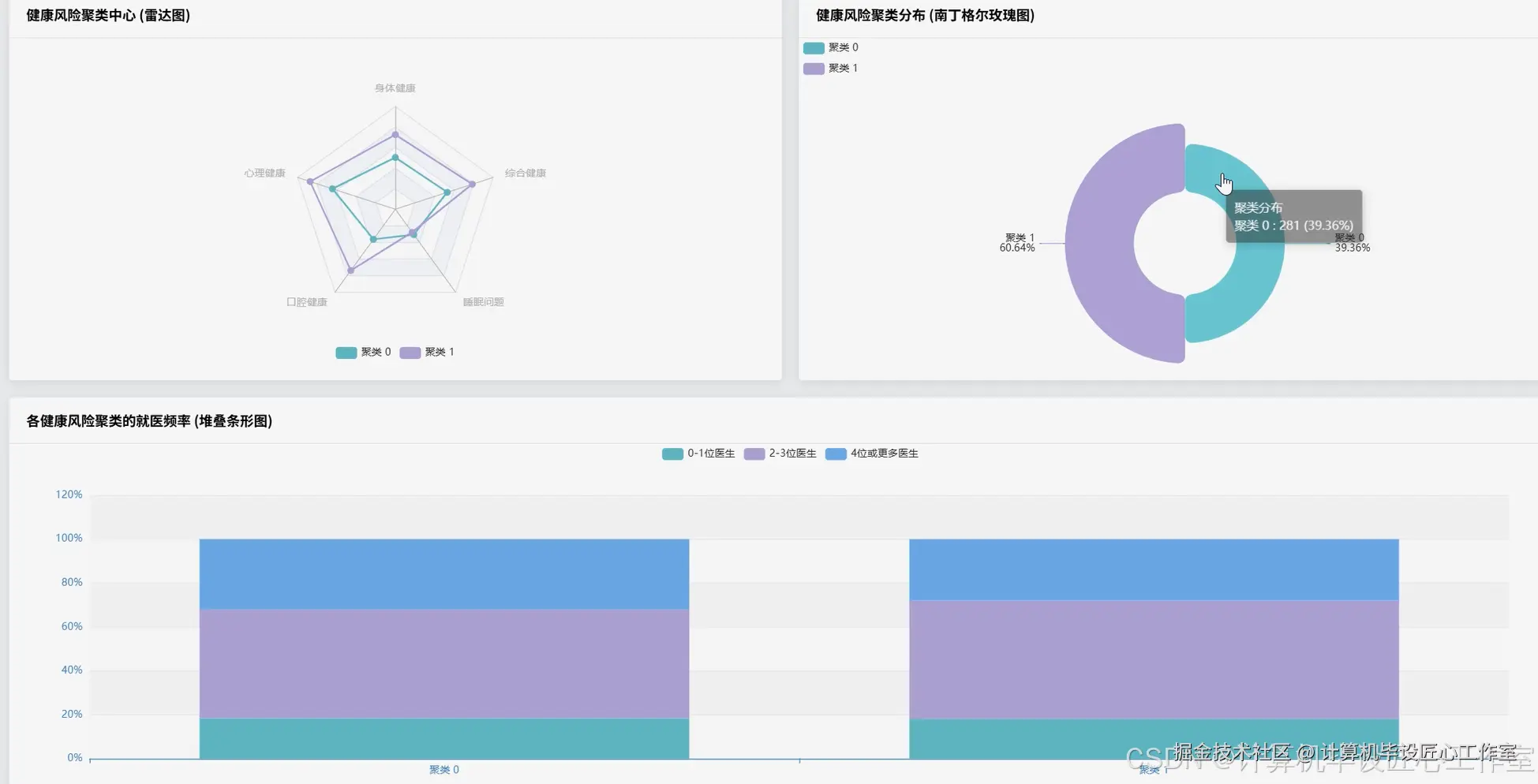
基于大数据的全国健康老龄化数据分析系统-代码展示
python
# 核心功能1:心理健康与身体健康关联分析
spark = SparkSession.builder.appName("HealthAgingAnalysis").getOrCreate()
df = spark.read.csv("hdfs://path/to/npha_data.csv", header=True, inferSchema=True)
df.createOrReplaceTempView("health_data")
correlation_result = spark.sql("SELECT Physical_Health, Mental_Health, COUNT(*) as count FROM health_data GROUP BY Physical_Health, Mental_Health ORDER BY Physical_Health, Mental_Health")
correlation_result.show()
# 核心功能2:影响老年人就医频率的关键健康因素
from pyspark.sql.functions import avg, col, round
# 将就医次数转换为数值类型,假设'4 or more doctors'记为4
df_doctors = df.withColumn("Doctors_Visited_Num", when(col("Number of Doctors Visited") == "4 or more doctors", 4).otherwise(col("Number of Doctors Visited").cast("int")))
# 按身体健康状况分组,计算平均就医次数
physical_impact = df_doctors.groupBy("Physical_Health").agg(round(avg("Doctors_Visited_Num"), 2).alias("Avg_Doctor_Visits_by_Physical")).orderBy("Physical_Health")
# 按心理健康状况分组,计算平均就医次数
mental_impact = df_doctors.groupBy("Mental_Health").agg(round(avg("Doctors_Visited_Num"), 2).alias("Avg_Doctor_Visits_by_Mental")).orderBy("Mental_Health")
print("关键健康因素对就医频率的影响分析:")
physical_impact.show()
mental_impact.show()
# 核心功能3:老年人健康风险聚类分析
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
# 筛选出用于聚类的关键健康指标,并处理缺失值
cluster_df = df.select("Physical_Health", "Mental_Health", "Dental Health", "Trouble Sleeping").na.drop()
# 将健康评分转换为数值,假设评分是1-5分,分数越高健康状况越差
assembler = VectorAssembler(inputCols=["Physical_Health", "Mental_Health", "Dental Health", "Trouble Sleeping"], outputCol="features")
cluster_data = assembler.transform(cluster_df)
# 训练K-Means模型,设定聚类数量为3(低风险、中风险、高风险)
kmeans = KMeans(featuresCol="features", predictionCol="cluster", k=3, seed=1)
model = kmeans.fit(cluster_data)
# 将聚类结果附加到原始数据
clustered_results = model.transform(cluster_data)
# 显示每个聚类的中心点,代表该类别的平均健康风险状况
centers = model.clusterCenters()
print("健康风险聚类中心点(物理、心理、口腔、睡眠):")
for center in centers:
print(center)
# 展示部分聚类结果
clustered_results.select("Physical_Health", "Mental_Health", "Dental Health", "Trouble Sleeping", "cluster").show(20)基于大数据的全国健康老龄化数据分析系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 主页获取源码联系🍅