Spark计算流程是怎样的?
RDD
Resilient Distributed Dataset(弹性分布式数据集)
RDD指的是一个抽象的概念,用户操作 RDD通过操作RDD来不需要关心底层细节。
4大属性:
- partitions:数据分片,RDD的数据被切分为数据分片,散落在集群的不同节点上
- partitioner(分区器):分片切割规则,Partitioner 决定数据去哪个 分区号 (Partition ID) (逻辑层)(拥有 Partitioner 的通常是Shuffle 类转换算子)
- dependencies:RDD依赖,指的是上一个RDD(从哪个父RDD而来)
- compute:转换函数(父RDD到现在RDD的转换函数)
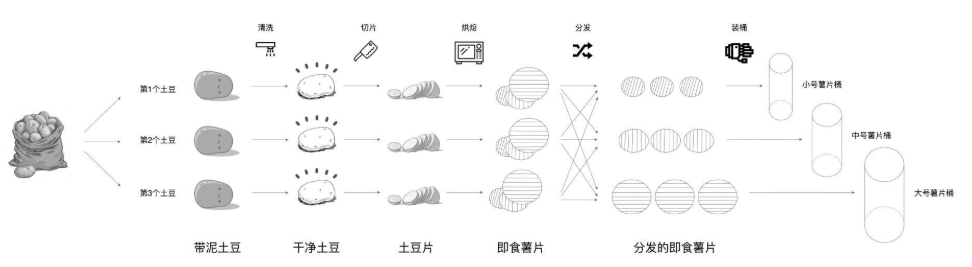
带泥土豆这总体就是RDD,每一个就是数据分片,带泥土豆是干净土豆的dependencies,清洗是干净土豆的compute。
这里一开始那一筐土豆被分为数据分片,这里面有partitioner起作用,包括后面分类也有partitoner起作用
分布式计算过程
Spark 采用**懒执行(Lazy Evaluation)**机制。在 Driver 执行代码中的 Transformation 算子(如 map, filter)时,并不会立即计算,而是隐式构建DAG。
当触发action算子时,DAGShceduler会以宽依赖将DAG划分为stage,然后以从后向前,递归的形式执行所有stage。
一旦确定stage可以运行了,就会将stage转化为TaskSet(stage里由多少个partition就有多少个Task,打包为一个taskSet)。到此DAGScheduler的工作结束了,接下来将TaskSet扔给TaskScheduler。
TaskScheduler以任务的本地倾向性将任务分配到数据所在的节点(例如TaskA要处理的数据在Node5上,那么就会优先将TaskA分配给Node5上的Executor)。
DagScheduler和TaskScheduelr都是在Driver中的

什么是 Shuffle?
Shuffle指的是集群范围内跨节点、跨进程的数据分发。
之前学的几个算子比如map,filter,mapPartition,flatmap都是用于RDD内部的数据转换,不会引入Shuffle计算
而groupByKey,sortByKey,reduceByKey,aggregateByKey都会引入Shuffle计算,并且这些算子只可以作用在paired(KV)RDD上。
磁盘 I/O (Disk I/O): 这是最核心的瓶颈。Map 端必须将中间结果写入磁盘 以保证容错,而 Reduce 端又必须从磁盘读取这些文件。大量的小文件读写会严重拖慢速度。
网络 I/O (Network I/O): 这是数据流动的瓶颈。下游 Reduce 任务需要跨节点去上游拉取属于自己的数据。如果数据量大或发生数据倾斜,会导致集群带宽被打满,引发网络拥堵。
CPU 开销 (CPU Overhead): 这是计算资源的瓶颈。
- 首先是序列化与反序列化,CPU 必须将对象在内存和字节流之间转换。
- 其次是排序与压缩,Shuffle 过程通常涉及 Key 的排序和数据的压缩解压,这都是 CPU 密集型操作。"
为什么 Spark SQL 比原生的 RDD 快?
DataFrame = RDD + Schema + 优化器
DataFrame会多走一层DataFrame API
DataFrame API里有两个优化器,分别是Catalyst优化器和Tungsten。
Catalyst优化器主要是逻辑优化和物理优化。逻辑优化和MySQL很像,索引下推,条件下推等
Tungsten优化有点难理解
DataFrame创建
从Driver创建DataFrame
从driver的数据转化为RDD,再调用createDataFrame方法将RDD转化为DataFrame
toDF的隐适转化,
从文件系统创建DataFrame
scala
import org.apache.spark.sql.types._
// 1. 定义 Schema (虽然文档未展示StructType细节,但在实际开发中必须定义)
val schema = new StructType()
.add("name", StringType, nullable = true)
.add("age", IntegerType, nullable = true)
val csvFilePath = "hdfs://path/to/user.csv"
// 2. 读取时显式应用 Schema
// "val df: DataFrame = spark.read.format("csv").schema(schema).option("header", true).load(csvFilePath)"
val df: DataFrame = spark.read
.format("csv")
.schema(schema) // 关键点:手动注入 Schema
.option("header", true)
.load(csvFilePath)从Parquet/ORC创建DataFrame
scala
val parquetFilePath: String = "hdfs://path/to/user.parquet"
// "val df: DataFrame = spark.read.format("parquet").load(parquetFilePath)"
val df: DataFrame = spark.read
.format("parquet")
.load(parquetFilePath) // 关键点:Spark 自动读取文件头部的 Schema访问数据库来创建DataFrame
scala
val sqlQuery: String = "select * from users where gender = 'female'"
// "spark.read.format("jdbc") .option("driver", "com.mysql.jdbc.Driver") ... .load()"
val df: DataFrame = spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", "jdbc:mysql://hostname:port/mysql")
.option("user", "用户名")
.option("password","密码")
.option("numPartitions", 20) // 性能优化:设置读取并发度
.option("dbtable", sqlQuery) // 关键点:指定表名或查询语句,Spark由此获取Schema
.load()其他
不同表关联形式
内关联,左关联,右关联,外关联
左半关联,右半关联
6种join策略
2种分法模式:shuffle join和broadcast join模式
3个join机制:Hash join,Sort Merge Join,Nested Loop Join
Spark内存管理
Excutor的内存:
- Reserverd Mwmory:固定为300MB,用来存储Spark内部对象的内存区域
- User Memory:用于存储开发这自定义的数据结构,例如数组,列表,映射
- Execution Memory:用来执行分布式任务的计算,主要就是RDD算子嘛
- Storage Memory:缓存分布式数据集,比如RDD Cache,广播变量等。(RDD Cache指的是在一个较长的DAG中,如果频繁使用到某个RDD,那么就会把这个RDD缓存到内存中,从而提升性能)广播变量之后再讲
- Execution Memory和Storage Memory可以相互转化
- 如果对方的内存空间有空闲,双方可以互相抢占;
- 对于Storage Memory抢占的Execution Memory部分,当分布式任务有计算需要时,Storage Memory必须立即归还抢占的内存,涉及的缓存数据要么落盘、要么清除;
- 对于Execution Memory抢占的Storage Memory部分,即便Storage Memory有收回内存的需要,也必须要等到分布式任务执行完毕才能释放