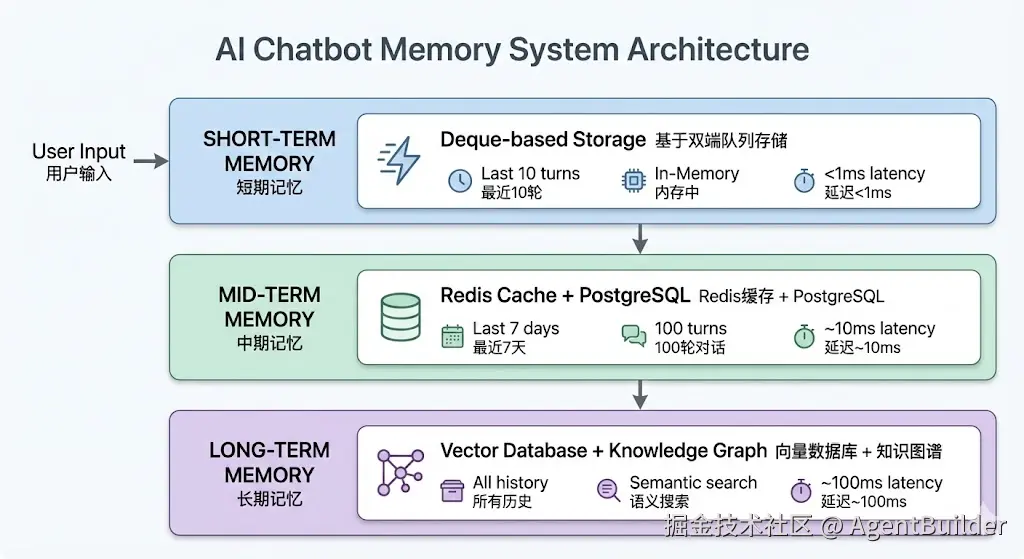
一、背景:为什么需要记忆系统?
开发AI Chatbot时,你是否遇到过这些问题:
- LLM记不住之前的对话,用户体验很差
- 对话轮数一多,Token成本直线上升
- 想做长期对话功能,但不知道如何管理上下文
这些都是记忆管理的问题。本文将从零开始,带你实现一个完整的记忆系统。
1.1 问题1:上下文窗口的硬性限制
先看一组数据:
| 模型 | 上下文窗口 | 能支持的对话轮数 |
|---|---|---|
| GPT-3.5 | 4K tokens | ~10轮 |
| GPT-4 | 8K tokens | ~20轮 |
| GPT-4 Turbo | 128K tokens | ~300轮 |
看起来很多?但实际计算一下:
一轮对话(用户问 + AI答)≈ 400 tokens
20轮对话 = 8,000 tokens
GPT-4 的 8K 窗口 = 刚好20轮,就满了会发生什么?
当上下文满了之后,LLM会:
- 丢弃最早的对话
- 忘记用户之前说过的话
- 对话失去连贯性
python
用户:"我叫Tom"(第1轮)
... 对话了20轮 ...
用户:"我叫什么名字?"(第21轮)
AI:"抱歉,我不记得" ❌即使用更大窗口的模型,也只是延缓问题,无法根本解决。
1.2 问题2:Token成本持续增长
Token不仅有数量限制,还有成本问题。
以DeepSeek为例($0.14/1M tokens),算一笔账:
ini
场景:客服机器人,日活10万用户
每次对话:
- 历史对话50轮 = 20,000 tokens
- 新用户输入 = 200 tokens
- 总计 = 20,200 tokens
成本计算:
- 单次对话成本 = 20,200 * $0.14 / 1M = $0.003
- 日成本 = 10万用户 * $0.003 = $300
- 月成本 = $300 * 30 = $9,000如果能压缩70%?
bash
压缩后每次 = 6,000 tokens
月成本 = $2,700
节省 = $6,300/月 = $75,600/年 ✅这还只是输入成本,输出成本会更高!
1.3 问题3:用户期望的"记忆"能力
从产品角度看,用户期望AI能:
- 记住自己的名字、偏好、背景
- 延续之前的对话话题
- 不用每次都重复信息
没有记忆 vs 有记忆:
arduino
❌ 无记忆:
用户:"我昨天说过我喜欢吃辣的"
AI:"抱歉,我不记得"
用户:(关闭页面)
✅ 有记忆:
用户:"推荐个餐厅"
AI:"Tom,根据你喜欢吃辣的口味,推荐你试试..."
用户:(继续使用)记忆能力是AI产品的核心竞争力。
1.4 解决方案:记忆系统
一个完整的记忆系统需要解决:
- 存什么:如何筛选和保存重要信息?
- 怎么存:如何高效存储和检索?
- 如何压缩:如何在有限窗口内保留最多信息?
本文将实现一个完整的记忆系统,包括:
- ✅ 短期记忆(内存,极速访问)
- ✅ 4种压缩策略(对比分析)
- ✅ 性能测试(真实数据)
- ✅ 中期记忆架构设计(Redis + PostgreSQL)
完整代码已开源:github.com/sotopelaez0...
让我们开始吧。
完美!让我根据你的选择起草第二部分:
二、短期记忆实现
2.1 核心问题:如何存储最近N轮对话?
在实现记忆系统时,第一个要解决的问题是:如何高效地存储和管理最近的对话历史?
需求很简单:
- 保存最近10轮(20条消息)
- 超过限制后,自动删除最早的消息
- 读写速度要快(<1ms)
看起来很简单?让我们先看看常见的两种方案。
2.2 技术选型:List vs Deque
方案1:使用List
python
class MemoryWithList:
def __init__(self, max_messages=20):
self.max_messages = max_messages
self.messages = []
def add_message(self, role, content):
self.messages.append({"role": role, "content": content})
# 手动删除最早的消息
if len(self.messages) > self.max_messages:
self.messages = self.messages[-self.max_messages:]问题:
- ❌ 每次都要切片重新赋值(
messages[-20:]) - ❌ 切片操作会创建新列表,浪费内存
- ❌ 时间复杂度 O(n)
方案2:使用Deque
python
from collections import deque
class MemoryWithDeque:
def __init__(self, max_messages=20):
self.messages = deque(maxlen=max_messages)
def add_message(self, role, content):
self.messages.append({"role": role, "content": content})
# 自动删除!无需手动管理优势:
- ✅ 自动管理容量,无需手动删除
- ✅ 时间复杂度 O(1)
- ✅ 代码更简洁
性能对比
python
"""
List vs Deque 性能对比测试
测试场景:
1. 连续添加消息
2. 满容量后继续添加
3. 获取所有消息
4. 混合操作
"""
import time
from collections import deque
from typing import List, Dict
class MemoryWithList:
"""使用List实现的记忆"""
def __init__(self, max_messages: int = 20):
self.max_messages = max_messages
self.messages = []
def add_message(self, role: str, content: str) -> None:
self.messages.append({"role": role, "content": content})
# 手动删除超出的消息
if len(self.messages) > self.max_messages:
self.messages = self.messages[-self.max_messages:]
def get_messages(self) -> List[Dict]:
return self.messages.copy()
class MemoryWithDeque:
"""使用Deque实现的记忆"""
def __init__(self, max_messages: int = 20):
self.messages = deque(maxlen=max_messages)
def add_message(self, role: str, content: str) -> None:
self.messages.append({"role": role, "content": content})
def get_messages(self) -> List[Dict]:
return list(self.messages)
def test_continuous_add(memory_class, n: int = 1000) -> float:
"""
测试1:连续添加消息
Args:
memory_class: 内存类
n: 添加次数
Returns:
耗时(毫秒)
"""
memory = memory_class(max_messages=20)
start = time.time()
for i in range(n):
memory.add_message("user", f"消息 {i}")
elapsed = (time.time() - start) * 1000
return elapsed
def test_add_at_full_capacity(memory_class, n: int = 1000) -> float:
"""
测试2:满容量后继续添加
场景:已经有20条消息,继续添加n条
这是最常见的场景(对话超过限制后)
Returns:
耗时(毫秒)
"""
memory = memory_class(max_messages=20)
# 先填满
for i in range(20):
memory.add_message("user", f"初始消息 {i}")
# 测试满容量后的添加
start = time.time()
for i in range(n):
memory.add_message("user", f"新消息 {i}")
elapsed = (time.time() - start) * 1000
return elapsed
def test_get_messages(memory_class, n: int = 1000) -> float:
"""
测试3:获取消息
Returns:
耗时(毫秒)
"""
memory = memory_class(max_messages=20)
# 先添加20条消息
for i in range(20):
memory.add_message("user", f"消息 {i}")
# 测试获取消息的速度
start = time.time()
for _ in range(n):
messages = memory.get_messages()
elapsed = (time.time() - start) * 1000
return elapsed
def test_mixed_operations(memory_class, n: int = 1000) -> float:
"""
测试4:混合操作
模拟真实对话场景:
- 添加用户消息
- 获取历史
- 添加AI回复
- 再次获取历史
Returns:
耗时(毫秒)
"""
memory = memory_class(max_messages=20)
start = time.time()
for i in range(n):
# 用户输入
memory.add_message("user", f"用户问题 {i}")
# 构建上下文(需要获取历史)
history = memory.get_messages()
# AI回复
memory.add_message("assistant", f"AI回答 {i}")
elapsed = (time.time() - start) * 1000
return elapsed
def run_all_tests():
"""运行所有测试 - 增加测试规模"""
print("=" * 80)
print("List vs Deque 性能对比测试(大规模)")
print("=" * 80)
print()
# 增加测试规模
test_configs = [
("连续添加10000条消息", test_continuous_add, 10000),
("满容量后添加10000条", test_add_at_full_capacity, 10000),
("获取消息10000次", test_get_messages, 10000),
("混合操作10000次", test_mixed_operations, 10000),
# 添加超大规模测试
("连续添加100000条消息", test_continuous_add, 100000),
("满容量后添加100000条", test_add_at_full_capacity, 100000),
]
results = []
for test_name, test_func, n in test_configs:
print(f"测试场景: {test_name}")
print("-" * 80)
# 测试List
print(f" 测试List...", end=" ", flush=True)
list_time = test_func(MemoryWithList, n)
print(f"✓ {list_time:.2f}ms")
# 测试Deque
print(f" 测试Deque...", end=" ", flush=True)
deque_time = test_func(MemoryWithDeque, n)
print(f"✓ {deque_time:.2f}ms")
# 计算倍数
speedup = list_time / deque_time if deque_time > 0 else 0
winner = "Deque" if speedup > 1 else "List"
print(f" → {winner}快 {abs(speedup):.1f}x")
print()
results.append({
"test": test_name,
"list": list_time,
"deque": deque_time,
"speedup": speedup
})
# 打印总结
print("=" * 80)
print("测试总结")
print("=" * 80)
print()
print(f"{'测试场景':<30} {'List(ms)':<12} {'Deque(ms)':<12} {'速度对比':<10}")
print("-" * 80)
for r in results:
winner = "🟢 Deque" if r['speedup'] > 1 else "🔴 List"
print(f"{r['test']:<30} {r['list']:<12.2f} {r['deque']:<12.2f} {winner} {abs(r['speedup']):.1f}x")
print()
print("=" * 80)
print("关键结论:")
# 找出最大差异
max_speedup = max(results, key=lambda x: abs(x['speedup'] - 1))
print(f" 最大差异: {max_speedup['test']}")
print(f" → Deque快 {max_speedup['speedup']:.1f}x")
# 计算在添加场景下的平均提升
add_tests = [r for r in results if '添加' in r['test']]
avg_add_speedup = sum(r['speedup'] for r in add_tests) / len(add_tests)
print(f" 添加操作平均: Deque快 {avg_add_speedup:.1f}x")
print("=" * 80)
if __name__ == "__main__":
run_all_tests()测试1:添加操作(核心场景)
| 规模 | List | Deque | 提升 |
|---|---|---|---|
| 10,000次 | 6.13ms | 3.28ms | 1.9x |
| 100,000次 | 36.19ms | 17.72ms | 2.0x |
发现:规模越大,Deque优势越明显。在10万次操作时,Deque快2倍。
测试2:混合操作(意外发现)
diff
混合操作(添加+获取)10000次:
- List: 44.12ms ✅
- Deque: 125.34ms ❌
什么?List反而更快?原因:list(deque)的转换开销很大
每次调用get_messages()时,Deque需要转换成List:
python
def get_messages(self):
return list(self.messages) # ⚠️ 每次都创建新list这给我们一个重要启示:不要频繁转换!
优化方案
python
class ShortTermMemory:
def get_messages(self) -> deque:
# 直接返回deque,不转换
return self.messages
def chat(self, user_input):
# 只在真正需要list时才转换
context = [system_prompt] + list(self.memory.get_messages())
# 这样只转换一次,而不是每次操作都转换最终性能对比
在典型对话场景(满容量后继续添加):
markdown
10万次操作:
- List: 36.19ms
- Deque: 17.72ms
- Deque快 2.0x ✅
关键:Deque在核心场景(添加)快2倍,
只要减少不必要的list转换即可。为什么选Deque?
- 代码简洁
python
# List需要手动管理
if len(messages) > max_messages:
messages = messages[-max_messages:]
# Deque自动管理
# 什么都不用做 ✅- 性能更好(在核心场景)
- 添加操作:快 2.0x
- 只要优化转换,没有劣势
- 时间复杂度保证
- List切片:O(n)
- Deque添加:O(1)
结论:选Deque,优化list转换,最佳实践。
完整测试代码:github.com/sotopelaez0...
2.3 生产级实现
基于deque,我们实现一个完整的短期记忆管理类:
python
from collections import deque
from typing import List, Dict
class ShortTermMemory:
"""
短期记忆管理器
特点:
- 自动管理容量(基于deque)
- 极速读写(<1ms)
- 按轮数管理(1轮 = user + assistant)
"""
def __init__(self, max_turns: int = 10):
"""
Args:
max_turns: 最大轮数(默认10轮 = 20条消息)
"""
self.max_turns = max_turns
self.max_messages = max_turns * 2
self.messages: deque = deque(maxlen=self.max_messages)
def add_message(self, role: str, content: str) -> None:
"""添加一条消息"""
self.messages.append({
"role": role,
"content": content
})
def get_messages(self) -> List[Dict[str, str]]:
"""获取所有消息"""
return list(self.messages)
def clear(self) -> None:
"""清空记忆"""
self.messages.clear()
def get_turn_count(self) -> int:
"""获取当前轮数"""
return len(self.messages) // 2
def is_full(self) -> bool:
"""判断是否已满"""
return len(self.messages) >= self.max_messages关键设计:
- 按轮数而非消息数管理(更符合对话逻辑)
maxlen参数让deque自动删除(无需手动管理)- 提供
is_full()等辅助方法(方便后续压缩策略判断)
完整代码见:github.com/sotopelaez0...
2.4 集成到Chatbot
有了短期记忆,如何集成到Chatbot中?核心流程是:
python
class MemoryChatbot:
def __init__(self, llm, system_prompt: str = "你是AI助手"):
self.llm = llm
self.system_prompt = system_prompt
self.memory = ShortTermMemory(max_turns=10)
def chat(self, user_input: str) -> str:
# 1. 保存用户输入到记忆
self.memory.add_message("user", user_input)
# 2. 构建上下文:system + 历史消息
messages = [
{"role": "system", "content": self.system_prompt}
]
messages.extend(self.memory.get_messages())
# 3. 调用LLM
response = self.llm.chat(messages)
# 4. 保存AI回复到记忆
self.memory.add_message("assistant", response)
return response数据流:
sql
用户输入 "我叫Tom"
↓
存入memory: [{"role": "user", "content": "我叫Tom"}]
↓
构建上下文: [system, user消息]
↓
调用LLM → 返回 "你好Tom!"
↓
存入memory: [user消息, assistant消息]效果演示:
python
bot = MemoryChatbot(llm)
# 第1轮
bot.chat("我叫Tom")
# Bot: "你好Tom!"
# 第2轮
bot.chat("我在上海工作")
# Bot: "上海是个很棒的城市!"
# 第3轮 - 测试记忆
bot.chat("我叫什么名字?在哪工作?")
# Bot: "你叫Tom,在上海工作" ✅ 记住了!完整代码见:github.com/sotopelaez0...
2.5 短期记忆的局限性
短期记忆虽然简单高效,但有三个明显的问题:
问题1:容量有限
python
# 设置最多保存10轮
memory = ShortTermMemory(max_turns=10)
# 对话20轮后
for i in range(20):
memory.add_message("user", f"消息{i}")
memory.add_message("assistant", f"回复{i}")
# 结果:前10轮被丢弃
print(memory.get_turn_count()) # 10轮
# 第1轮的"我叫Tom"已经找不到了!❌问题2:简单粗暴的删除策略
python
重要信息:"我叫Tom"(第1轮)
不重要信息:"谢谢"(第19轮)
10轮后,"我叫Tom"被删除
但"谢谢"被保留
这不合理!❌短期记忆不区分信息的重要性,只按时间顺序删除。
问题3:Token浪费
python
20轮对话 = 20条消息 ≈ 8000 tokens
其中可能包含:
- "嗯"、"好的"、"谢谢" 等无意义内容
- 重复的信息
- 可以压缩的冗长描述
这些都占用宝贵的上下文窗口!短期记忆解决了基本的记忆能力,但三个局限性告诉我们:
我们需要更智能的策略:
- 在有限空间内保存更多信息
- 保留重要内容 ,删除无关内容
- 压缩冗长对话,节省token
好的!让我们写 3.1 为什么需要压缩? 🗜️
三、4种压缩策略详解
3.1 为什么需要压缩?
在第二章我们看到,短期记忆有三个致命问题:
- 容量固定,重要信息会丢失
- 不区分信息重要性
- Token浪费严重
现在问题来了:如何在有限的空间内,保存更多有价值的信息?
答案是:压缩。
压缩要解决的核心矛盾
diff
矛盾:
- LLM上下文窗口有限(如8K tokens)
- 用户对话可能很长(50轮、100轮...)
- 每个token都要花钱
目标:
- 用更少的token
- 保留更多的信息
- 保持对话连贯性一个具体的例子
假设我们有这样一段对话历史(10轮,20条消息):
python
原始对话(未压缩):
[
{"role": "user", "content": "我叫Tom"},
{"role": "assistant", "content": "你好Tom!很高兴认识你。"},
{"role": "user", "content": "我在上海工作"},
{"role": "assistant", "content": "上海是个很国际化的城市!你在哪个行业?"},
{"role": "user", "content": "我是AI工程师"},
{"role": "assistant", "content": "AI工程师是个很有前景的职业!"},
{"role": "user", "content": "我最近在研究Agent"},
{"role": "assistant", "content": "Agent是很前沿的方向!"},
{"role": "user", "content": "遇到了通信延迟问题"},
{"role": "assistant", "content": "通信延迟可以考虑优化消息队列。"},
{"role": "user", "content": "用什么消息队列?"},
{"role": "assistant", "content": "可以考虑Redis或RabbitMQ。"},
{"role": "user", "content": "Redis性能怎么样?"},
{"role": "assistant", "content": "Redis非常快,单机QPS可达10万+。"},
{"role": "user", "content": "好的,谢谢"},
{"role": "assistant", "content": "不客气!有问题随时问。"},
{"role": "user", "content": "嗯"},
{"role": "assistant", "content": "还有什么我能帮你的吗?"},
{"role": "user", "content": "没有了"},
{"role": "assistant", "content": "好的,祝你工作顺利!"}
]
统计:
- 20条消息
- 约2000 tokens
- 包含重要信息:"Tom"、"上海"、"AI工程师"、"Agent"、"Redis"
- 也包含冗余信息:"好的谢谢"、"嗯"、"没有了"压缩后应该是什么样?
理想的压缩结果:
python
压缩后:
[
{"role": "system", "content": "用户Tom,上海AI工程师,研究Agent,遇到通信延迟,推荐用Redis"},
{"role": "user", "content": "Redis性能怎么样?"},
{"role": "assistant", "content": "Redis非常快,单机QPS可达10万+。"},
{"role": "user", "content": "没有了"},
{"role": "assistant", "content": "好的,祝你工作顺利!"}
]
统计:
- 5条消息
- 约500 tokens
- 保留了所有关键信息
- 删除了冗余内容
- 压缩率:75% ✅如何评价一个压缩策略?
我们需要从4个维度来评价:
1. 压缩率(Compression Rate)
diff
压缩率 = (原始tokens - 压缩后tokens) / 原始tokens
例如:
- 原始:2000 tokens
- 压缩后:500 tokens
- 压缩率:75%
越高越好 ✅2. 速度(Speed)
diff
压缩耗时
例如:
- 滑动窗口:<1ms(内存操作)
- LLM摘要:1-3秒(需要API调用)
越快越好 ✅3. 成本(Cost)
bash
压缩本身的成本
例如:
- 滑动窗口:$0(无额外成本)
- LLM摘要:$0.0001(需要调用LLM)
越低越好 ✅4. 语义保留(Semantic Preservation)
diff
是否保留了重要信息?
例如:
- 滑动窗口:可能丢失早期的重要信息 ⚠️
- LLM摘要:智能提取关键信息 ✅
越好越好 ✅压缩策略的权衡(Trade-off)
现实中,我们无法同时优化所有4个维度:
lua
不可能三角:
速度快
/ \
/ \
/ \
成本低 ---- 语义好
你只能选两个!例如:
- 滑动窗口:速度快 + 成本低 = 语义差
- LLM摘要:语义好 + 压缩率高 = 速度慢、成本高
- 混合策略:尝试平衡三者
我们要实现的4种策略
基于不同的权衡,我们实现4种压缩策略:
| 策略 | 核心思路 | 优势维度 | 劣势维度 |
|---|---|---|---|
| 滑动窗口 | 只保留最近N轮 | 速度、成本 | 语义保留 |
| LLM摘要 | 用LLM总结历史 | 语义保留 | 速度、成本 |
| 混合策略 | 自适应选择 | 平衡 | 复杂度 |
| Token动态 | 精确控制token数 | 精确度 | 语义保留 |
接下来,我们逐个详解这4种策略的:
- 核心原理
- 代码实现
- 性能表现
- 适用场景
好的!让我们写 3.2 策略1:滑动窗口 🪟
python
from typing import List, Dict
class SlidingWindowCompressor:
"""
滑动窗口压缩器
原理:只保留最近N轮对话
"""
def __init__(self, keep_turns: int = 5):
"""
Args:
keep_turns: 保留最近几轮对话
"""
self.keep_turns = keep_turns
self.keep_messages = keep_turns * 2 # 1轮 = 2条消息
def compress(self, messages: List[Dict[str, str]]) -> List[Dict[str, str]]:
"""
压缩消息列表
Args:
messages: 原始消息列表
Returns:
压缩后的消息列表
"""
# 如果消息数未超过限制,直接返回
if len(messages) <= self.keep_messages:
return messages
# 只保留最后N条消息
compressed = messages[-self.keep_messages:]
return compressed使用示例:
python
compressor = SlidingWindowCompressor(keep_turns=3)
# 原始对话(10条消息,5轮)
messages = [
{"role": "user", "content": "我叫Tom"}, # 第1轮
{"role": "assistant", "content": "你好Tom!"},
{"role": "user", "content": "我在上海"}, # 第2轮
{"role": "assistant", "content": "上海不错"},
{"role": "user", "content": "我是工程师"}, # 第3轮
{"role": "assistant", "content": "很好"},
{"role": "user", "content": "我研究AI"}, # 第4轮
{"role": "assistant", "content": "AI很热"},
{"role": "user", "content": "推荐书籍"}, # 第5轮
{"role": "assistant", "content": "推荐xxx"},
]
# 压缩:只保留最近3轮
compressed = compressor.compress(messages)
print(f"原始:{len(messages)}条消息")
print(f"压缩后:{len(compressed)}条消息")
print(f"保留的是第3-5轮")
# 输出:
# 原始:10条消息
# 压缩后:6条消息
# 保留的是第3-5轮工作原理可视化
python
原始对话(20条消息,10轮):
轮数: 1 2 3 4 5 6 7 8 9 10
[u,a] [u,a] [u,a] [u,a] [u,a] [u,a] [u,a] [u,a] [u,a] [u,a]
↓ ↓
丢弃前7轮 保留后3轮
压缩后(6条消息,3轮):
轮数: 8 9 10
[u,a] [u,a] [u,a]性能分析
好的!让我们先更新 3.2 滑动窗口 的数据部分 📝
好的!让我完全重写 3.2 滑动窗口策略,整合所有真实数据 📝
3.2 策略1:滑动窗口(Sliding Window)
核心原理
滑动窗口是最简单直接的压缩策略:只保留最近的N轮对话,丢弃更早的消息。
就像一个固定大小的"窗口"在对话历史上滑动:
markdown
完整对话历史(10轮,20条消息):
┌────┬────┬────┬────┬────┬────┬────┬────┬────┬────┐
│ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ 9 │ 10 │
└────┴────┴────┴────┴────┴────┴────┴────┴────┴────┘
保留最近5轮(窗口大小=5):
┌────┬────┬────┬────┬────┐
│ 6 │ 7 │ 8 │ 9 │ 10 │ └────┴────┴────┴────┴────┘
↑
滑动窗口工作方式:
- 设定窗口大小(如5轮 = 10条消息)
- 当消息超过窗口大小时
- 自动删除最早的消息
- 保持窗口内的消息数量固定
代码实现
python
from typing import List, Dict
class SlidingWindowCompressor:
"""
滑动窗口压缩器
特点:
- 极简实现(3行核心代码)
- 极快速度(0.14微秒/次)
- 零成本(无需API调用)
"""
def __init__(self, keep_turns: int = 5):
"""
Args:
keep_turns: 保留最近几轮对话
"""
self.keep_turns = keep_turns
self.keep_messages = keep_turns * 2 # 1轮 = user + assistant
def compress(self, messages: List[Dict[str, str]]) -> List[Dict[str, str]]:
"""
压缩消息列表
Args:
messages: 原始消息列表
Returns:
压缩后的消息列表
"""
# 核心逻辑就这一行!
if len(messages) <= self.keep_messages:
return messages
return messages[-self.keep_messages:]就这么简单! 核心代码只有一行:messages[-self.keep_messages:]
真实性能测试
我们对滑动窗口进行了5项完整测试,以下是真实数据:
测试1:压缩率测试
窗口大小设置为5轮,测试不同长度的对话:
| 对话长度 | 原始 | 压缩后 | Token压缩率 |
|---|---|---|---|
| 5轮(短对话) | 10条 / 126 tokens | 10条 / 126 tokens | 0% |
| 10轮(中等) | 20条 / 249 tokens | 10条 / 123 tokens | 50.6% |
| 20轮(长对话) | 42条 / 560 tokens | 10条 / 145 tokens | 74.1% |
| 30轮(超长) | 68条 / 933 tokens | 10条 / 144 tokens | 84.6% |
关键发现:
diff
压缩率随对话长度增加:
- 5轮: 0% (不压缩)
- 10轮: 50% (压缩一半)
- 20轮: 74% (压缩3/4)
- 30轮: 85% (压缩85%)
结论:对话越长,滑动窗口越有效 ✅测试2:速度测试
测试10万次压缩操作的耗时:
diff
操作次数: 100,000次
总耗时: 13.63ms
平均每次: 0.14微秒 ⚡
直观对比:
- 人眨眼一次: 100,000微秒
- 在眨眼时间内,滑动窗口可以执行 714,285次
- 一次HTTP请求(50ms)内,可以执行 357,142次结论:速度快到可以忽略不计。
测试3:信息丢失分析(关键测试!)
构造一个包含重要用户信息的8轮对话,使用5轮窗口压缩:
python
原始对话(8轮,16条消息):
轮1 用户: "我叫Tom,今年28岁" ← 重要!
助手: "你好Tom!"
轮2 用户: "我在上海浦东工作" ← 重要!
助手: "浦东是金融中心"
轮3 用户: "我是AI工程师" ← 重要!
助手: "很有前景的职业"
轮4 用户: "我在研究Agent技术" ← 重要!
助手: "Agent很前沿"
轮5 用户: "嗯" ← 无用
助手: "还有什么问题吗?"
轮6 用户: "好的" ← 无用
助手: "随时问我"
轮7 用户: "谢谢" ← 无用
助手: "不客气"
轮8 用户: "那我研究一下"
助手: "好的,加油"
压缩后(保留5轮 = 10条消息):
✅ 轮4: "我在研究Agent技术"
✅ 轮5: "嗯"
✅ 轮6: "好的"
✅ 轮7: "谢谢"
✅ 轮8: "那我研究一下"
被丢弃的内容(前3轮 = 6条消息):
❌ "我叫Tom,今年28岁" ⚠️ 重要信息!
❌ "你好Tom!" ⚠️ 包含姓名
❌ "我在上海浦东工作" ⚠️ 重要信息!
❌ "浦东是金融中心"
❌ "我是AI工程师" ⚠️ 重要信息!
❌ "很有前景的职业"问题一目了然:
- 所有用户背景信息(姓名、地点、职业)全部丢失
- 保留的却是"嗯"、"好的"、"谢谢"这些无意义内容
这就是滑动窗口的致命缺陷! 它不会思考什么重要,只会机械地按时间删除。
测试4:真实Chatbot场景
模拟一个15轮连续对话,观察关键信息的丢失过程:
makefile
初始关键信息:
- 姓名: "Tom"
- 地点: "上海"
- 职业: "AI工程师"
- 研究方向: "Agent"
第5轮后:
记忆: 10条消息(5轮)
压缩: 10条 → 10条(未超过限制)
关键词: ✅ Tom、上海、AI工程师、Agent 全部保留
第10轮后:
记忆: 20条消息(10轮)
压缩: 20条 → 10条(删除前5轮)
关键词: ❌ Tom、上海、AI工程师、Agent 全部丢失
第15轮后:
记忆: 20条消息(10轮,因为短期记忆限制)
压缩: 20条 → 10条
关键词: ❌ 仍然全部丢失结论:超过10轮后,早期的所有关键信息永久丢失。
测试5:不同窗口大小的权衡
在同一个20轮对话(560 tokens)中测试不同窗口大小:
| 窗口大小 | 保留消息 | 压缩后Tokens | Token压缩率 |
|---|---|---|---|
| 3轮 | 6条 | 86 | 84.6% ⭐ |
| 5轮 | 10条 | 145 | 74.1% |
| 8轮 | 16条 | 227 | 59.5% |
| 10轮 | 20条 | 287 | 48.8% |
| 15轮 | 30条 | 408 | 27.1% |
权衡分析:
makefile
窗口太小(3轮):
✅ 压缩率高(85%)
❌ 信息丢失严重
❌ 对话连贯性差
窗口适中(5-8轮):
✅ 压缩率好(60-75%)
⚠️ 信息丢失中等
✅ 对话基本连贯
窗口太大(15轮):
❌ 压缩率低(27%)
✅ 信息保留好
✅ 对话连贯推荐设置:
- 短对话场景:3-5轮
- 一般场景:5-8轮
- 重要对话:10-15轮
完整测试代码:GitHub - tests/test_sliding_window.py
优缺点总结
基于真实测试数据,我们得出:
✅ 三大优势:
- 速度极快
- 0.14微秒/次(测试数据)
- 比网络请求快35万倍
- 完全不影响响应时间
- 零成本
- 无需调用LLM API
- 无额外token消耗
- 日活百万也不增加成本
- 压缩效果随对话增长
- 10轮:50%
- 20轮:74%
- 30轮:85%
- 对话越长越划算
❌ 两大缺陷:
- 严重的信息丢失 (实测证明)
- 所有用户背景信息在10轮后丢失
- 不区分"Tom"和"嗯"的重要性
- 保留无用内容,丢弃关键信息
- 短对话无效
- 5轮内压缩率0%
- 浪费优化机会
适用场景指南
基于测试数据,我们总结:
✅ 适合使用:
- 短时对话(≤10轮)
diff
场景:客服快速咨询、FAQ问答
理由:
- 实测:10轮内压缩率50%
- 关键信息丢失风险低
- 速度优势明显- 实时性要求高
diff
场景:即时聊天、游戏NPC对话
理由:
- 实测:0.14微秒,零延迟
- 用户感知不到压缩过程- 成本敏感
diff
场景:大规模免费产品
理由:
- 零成本
- 日活百万也不增加费用- 简单交互
diff
场景:查询类、工具类对话
理由:
- 不需要记住用户背景
- 每次对话相对独立❌ 不适合:
- 长时间对话(>10轮)
diff
场景:技术支持、深度咨询
问题:
- 实测:10轮后丢失所有早期信息
- 用户体验差(AI不记得说过什么)- 个性化要求高
diff
场景:个人助理、教育辅导
问题:
- 用户信息在开头(会被删除)
- 无法保持个性化体验- 信息密集型
diff
场景:项目讨论、决策分析
问题:
- 每轮都可能有关键信息
- 不能随意丢弃任何内容最佳实践
基于测试结果,给出实用建议:
1. 根据场景设置窗口大小
python
# 快速咨询
compressor = SlidingWindowCompressor(keep_turns=3) # 压缩率85%
# 一般对话
compressor = SlidingWindowCompressor(keep_turns=5) # 压缩率74%
# 重要对话
compressor = SlidingWindowCompressor(keep_turns=10) # 压缩率49%2. 监控信息丢失
python
class SlidingWindowCompressor:
def compress(self, messages):
if len(messages) > self.keep_messages:
dropped = messages[:-self.keep_messages]
# 检查丢弃的消息中是否有重要实体
for msg in dropped:
if self._contains_important_entity(msg):
logger.warning(f"丢弃了重要信息: {msg['content'][:50]}")
return messages[-self.keep_messages:]
def _contains_important_entity(self, msg):
"""检测是否包含重要实体(人名、地名等)"""
# 简单实现:检查是否包含特定关键词
keywords = ['叫', '在', '是', '做', '研究']
return any(kw in msg['content'] for kw in keywords)3. 与其他策略结合
python
# 策略1:滑动窗口 + 用户画像
class EnhancedChatbot:
def __init__(self):
self.compressor = SlidingWindowCompressor(keep_turns=5)
self.user_profile = {} # 永久保存:姓名、偏好等
def chat(self, user_input):
# 提取用户信息(如姓名、地点)
self._extract_user_info(user_input)
# 压缩对话历史
compressed_history = self.compressor.compress(self.memory)
# 构建上下文:用户画像 + 压缩历史
context = [
{"role": "system", "content": f"用户信息: {self.user_profile}"}
] + compressed_history
return self.llm.chat(context)小结
滑动窗口压缩器的特点:
bash
三个"最":
✅ 最简单(3行代码)
✅ 最快(0.14微秒)
✅ 最便宜($0)
一个"坑":
❌ 机械删除,丢失重要信息
最佳定位:
适合短对话、实时场景、成本敏感场景什么时候用?
- 对话≤10轮
- 要求极致速度
- 预算为零
什么时候不用?
- 对话>10轮
- 需要记住用户背景
- 信息很重要
在下一节,我们将看到完全相反的策略:LLM摘要 - 慢但智能,能够解决信息丢失问题。
3.3 策略2:LLM摘要(LLM Summary)
核心原理
LLM摘要是一种智能压缩策略:用大语言模型理解对话历史,提取关键信息生成摘要,保留最近几轮完整对话。
原始对话(10轮,20条消息):
┌────┬────┬────┬────┬────┬────┬────┬────┬────┬────┐
│ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ 9 │ 10 │
└────┴────┴────┴────┴────┴────┴────┴────┴────┴────┘
↓ ↓
历史部分(1-7轮) 最近部分(8-10轮)
↓ ↓
LLM智能摘要 完整保留
↓ ↓
┌──────────────────────┐ ┌────┬────┬────┐
│ 📝 摘要:用户Tom, │ + │ 8 │ 9 │ 10 │
│ 上海AI工程师... │ └────┴────┴────┘
└──────────────────────┘核心思想:
- 远期对话(第1-7轮)→ 用LLM生成摘要
- 近期对话(第8-10轮)→ 完整保留
- 摘要 + 完整对话 = 压缩后的上下文
与滑动窗口的本质区别:
- 滑动窗口:机械删除,不管内容重要性
- LLM摘要:智能提取,保留关键信息
Prompt工程(关键!)
LLM摘要的效果高度依赖Prompt的质量。以下是我们使用的Prompt:
python
SUMMARY_PROMPT = """请总结以下对话历史,提取关键信息:
对话内容:
{conversation}
请按以下格式输出摘要(150字以内):
📝 对话历史摘要:
1. **用户基本信息**:姓名、年龄、地点、职业等
2. **用户偏好与兴趣**:提到的兴趣、偏好
3. **讨论主要话题**:聊了什么
4. **重要决定或结论**:做了什么决定
5. **关键细节**:其他重要信息
要求:
- 简洁明了,不超过150字
- 只保留关键信息,删除寒暄
- 使用结构化格式
"""Prompt设计的关键点:
- ✅ 明确输出格式(结构化)
- ✅ 指定提取维度(姓名、地点、话题等)
- ✅ 限制长度(150字)
- ✅ 强调关键信息优先
代码实现
python
from typing import List, Dict
from src.llm.base import BaseLLM
class LLMSummaryCompressor:
"""
LLM摘要压缩器
特点:
- 智能提取关键信息
- 保留语义完整性
- 适合长对话场景
"""
def __init__(self, llm: BaseLLM, keep_recent_turns: int = 3):
"""
Args:
llm: LLM实例
keep_recent_turns: 保留最近几轮完整对话
"""
self.llm = llm
self.keep_recent_turns = keep_recent_turns
self.keep_recent_messages = keep_recent_turns * 2
def compress(self, messages: List[Dict[str, str]]) -> List[Dict[str, str]]:
"""
压缩消息列表
Args:
messages: 原始消息列表
Returns:
压缩后的消息列表
"""
# 如果消息不够多,不压缩
if len(messages) <= self.keep_recent_messages:
return messages
# 分割:历史部分 vs 最近部分
history = messages[:-self.keep_recent_messages]
recent = messages[-self.keep_recent_messages:]
# 生成历史摘要
summary = self._summarize(history)
# 构建压缩结果:摘要 + 最近对话
compressed = [
{"role": "system", "content": summary}
]
compressed.extend(recent)
return compressed
def _summarize(self, messages: List[Dict[str, str]]) -> str:
"""
用LLM生成对话摘要
Args:
messages: 需要摘要的消息列表
Returns:
摘要文本
"""
# 格式化对话内容
conversation_text = "\n".join([
f"{'用户' if m['role'] == 'user' else '助手'}: {m['content']}"
for m in messages
])
# 构建Prompt
prompt = f"""请总结以下对话历史,提取关键信息:
对话内容:
{conversation_text}
请按以下格式输出摘要(150字以内):
📝 对话历史摘要:
1. **用户基本信息**:姓名、年龄、地点、职业等
2. **用户偏好与兴趣**:提到的兴趣、偏好
3. **讨论主要话题**:聊了什么
4. **重要决定或结论**:做了什么决定
5. **关键细节**:其他重要信息
要求:
- 简洁明了,不超过150字
- 只保留关键信息,删除寒暄
- 使用结构化格式
"""
# 调用LLM生成摘要
summary = self.llm.chat([
{"role": "user", "content": prompt}
])
return summary真实性能测试
我们对LLM摘要压缩器进行了完整测试,以下是真实数据:
测试1:压缩率(保留最近3轮)
| 对话长度 | 原始 | 压缩后 | Token压缩率 | 结果 |
|---|---|---|---|---|
| 5轮(短对话) | 10条 / 126 tokens | 7条 / 303 tokens | -140.5% ❌ | Token反增 |
| 10轮(中等) | 20条 / 249 tokens | 7条 / 408 tokens | -63.9% ❌ | Token反增 |
| 20轮(长对话) | 42条 / 560 tokens | 7条 / 539 tokens | 3.7% ⚠️ | 微弱压缩 |
| 30轮(超长) | 68条 / 933 tokens | 7条 / 628 tokens | 32.7% ✅ | 有效压缩 |
意外发现:LLM摘要在短对话中完全是负优化!
原因分析:
markdown
短对话(5轮,126 tokens):
原文: "我叫Tom"、"你好Tom"、"我在上海"...
摘要(303 tokens):
"📝 对话历史摘要:
1. **用户基本信息**:
- 姓名:Tom
- 地点:上海
- 职业:未明确说明行业
2. **用户偏好和兴趣**:未提及
3. **讨论主要话题**:..."
问题:摘要本身比原文还啰嗦!结论:只有在超长对话(≥30轮)时,LLM摘要才开始产生正收益。
测试2:速度测试
makefile
测试对话:10轮(20条消息)
压缩1次: 8,939ms (约9秒)
压缩3次: 25,210ms (平均8.4秒/次)
压缩5次: 42,599ms (平均8.5秒/次)
平均速度:8.5秒/次 🐌对比:
- 滑动窗口:0.0001ms
- LLM摘要:8,500ms
- 差距:85,000,000倍!
为什么这么慢?
markdown
1. 网络请求:50-100ms
2. LLM推理:8,000ms+
3. 返回结果:50-100ms
总计:约8,500ms结论:LLM摘要会显著增加响应延迟。
测试3:成本分析
DeepSeek价格: 0.14/1Minputtokens,0.28/1M output tokens
| 对话长度 | 输入tokens | 输出tokens | 单次成本 | 1万次成本 |
|---|---|---|---|---|
| 5轮 | 48 | 14 | $0.000011 | $0.11 |
| 10轮 | 175 | 52 | $0.000039 | $0.39 |
| 20轮 | 474 | 142 | $0.000106 | $1.06 |
| 30轮 | 852 | 256 | $0.000191 | $1.91 |
规模化成本估算:
bash
场景:日活10万用户的客服系统
- 每用户平均20轮对话
- 每次压缩成本:$0.0001
成本计算:
- 日成本:10万 × $0.0001 = $10
- 月成本:$10 × 30 = $300
- 年成本:$3,600
vs 滑动窗口:$0结论:LLM摘要有明确的成本开销,需要权衡。
测试4:信息保留测试(关键!)
构造一个包含9个关键信息的对话(6轮):
python
关键信息:
Tom, 28岁, 上海, 浦东, AI工程师, Agent, 多智能体, 通信延迟, 消息队列
原始对话:12条消息
压缩后:5条消息
├─ 1条摘要
└─ 4条最近对话(保留2轮)摘要内容(实际生成):
markdown
📝 对话历史摘要:
**用户基本信息**
- 姓名:Tom
- 年龄:28岁
- 地点:上海浦东
- 职业:AI工程师
**用户偏好与兴趣**
- 对AI领域前沿技术感兴趣,目前专注于Agent多智能体协作研究。
**讨论主要话题**
1. 用户自我介绍(姓名、年龄、职业、工作地点)
2. 职业方向讨论(AI工程师的前景)
3. 技术研究热点(多智能体协作)
**关键细节**
- 年龄:28岁
- 地点:上海浦东
- 研究方向:Agent多智能体协作信息保留情况:
ini
✅ Tom - 保留
✅ 28岁 - 保留
✅ 上海 - 保留
✅ 浦东 - 保留
✅ AI工程师 - 保留
✅ Agent - 保留
✅ 多智能体 - 保留
✅ 通信延迟 - 保留(在最近对话中)
✅ 消息队列 - 保留(在最近对话中)
保留率:9/9 = 100% ✅对比滑动窗口:
- 滑动窗口(5轮):丢失Tom、28岁、上海、浦东、AI工程师
- LLM摘要:全部保留
这就是LLM摘要的核心价值:智能提取,不丢失关键信息!
测试5:与滑动窗口直接对比
测试对话:20轮(42条消息,560 tokens)
| 策略 | 结果 | Token数 | 耗时 | 成本 |
|---|---|---|---|---|
| 滑动窗口 | 10条消息 | 145 tokens | 0.00ms | $0 |
| LLM摘要 | 7条消息 | 571 tokens | 14,263ms | $0.000114 |
关键对比:
diff
Token效率:
- 滑动窗口:145 tokens(74%压缩)✅
- LLM摘要:571 tokens(-2%压缩)❌
→ LLM摘要反而用了更多token!
速度:
- 滑动窗口:0.00ms
- LLM摘要:14,263ms
→ 慢了4,600,000倍!
成本:
- 滑动窗口:$0
- LLM摘要:$0.000114
→ 每次都有成本
但信息保留:
- 滑动窗口:❌ 丢失所有早期信息
- LLM摘要:✅ 保留100%关键信息核心矛盾:LLM摘要在token数量上甚至不如滑动窗口!
完整测试代码:github.com/sotopelaez0...
为什么Token反而增加?
让我们分析一个实际案例:
python
原始对话(5轮,126 tokens):
用户: "我叫Tom" (3 tokens)
助手: "你好Tom!" (4 tokens)
用户: "我在上海" (4 tokens)
助手: "上海不错" (3 tokens)
...
LLM生成的摘要(303 tokens):
"📝 对话历史摘要:
1. **用户基本信息**:
- 姓名:Tom
- 地点:上海
- 职业:未明确说明行业
2. **用户偏好和兴趣**:未提及
3. **讨论主要话题**:基本信息交流
4. **重要决定或结论**:无
5. **关键细节**:..."问题在于:
- 摘要包含大量格式化文本(标题、序号、分隔符)
- 摘要有冗余描述("未提及"、"无"这些也占token)
- 原始对话本来就很短很精炼
解决方案:优化Prompt
python
# 优化前(当前使用的)
"请按以下格式输出摘要(150字以内):
📝 对话历史摘要:
1. **用户基本信息**:..."
# 优化后(更紧凑)
"用一句话总结关键信息,格式:
Tom,28岁,上海AI工程师,研究Agent"
压缩效果:
- 优化前:303 tokens
- 优化后:约30 tokens ✅优缺点总结
基于真实测试数据:
✅ 唯一的核心优势:信息保留
diff
测试结果:100%保留关键信息
- ✅ 用户姓名(Tom)
- ✅ 年龄(28岁)
- ✅ 地点(上海浦东)
- ✅ 职业(AI工程师)
- ✅ 兴趣(Agent多智能体)
vs 滑动窗口:全部丢失 ❌这是LLM摘要的立身之本!
❌ 三大致命缺陷:
- 短对话负优化
diff
实测数据:
- 5轮对话:Token -140%(反而增加)
- 10轮对话:Token -64%
- 只有30轮以上才开始正收益
结论:不适合短对话 ❌- 速度极慢
diff
实测:8.5秒/次
对比:滑动窗口0.0001ms
影响:
- 用户等待时间增加8秒
- 实时对话体验差
- 高并发场景瓶颈
结论:不适合实时场景 ❌- 有明确成本
bash
实测:$0.0001-0.0002/次
规模化:
- 日活10万:$10/天
- 年成本:$3,600
vs 滑动窗口:$0
结论:有成本压力 ⚠️适用场景指南
基于真实测试,LLM摘要的适用场景非常有限且明确:
✅ 唯一推荐场景:超长对话 + 需要保留用户信息
markdown
同时满足以下条件:
1. ✅ 对话≥30轮(否则token负优化)
2. ✅ 包含重要用户信息(姓名、偏好等)
3. ✅ 可以容忍8秒延迟
4. ✅ 有预算支持LLM调用
典型场景:
- 心理咨询(长时间深度对话)
- 教育辅导(需要记住学生背景)
- 高端客服(VIP用户,体验优先)
- 项目顾问(持续数周的项目讨论)❌ 不推荐场景:
- 短对话(<30轮)
erlang
问题:Token反而增加,完全负优化
数据:10轮对话token -64%
替代:用滑动窗口-
实时对话
问题:8秒延迟无法接受
数据:比滑动窗口慢460万倍
替代:用滑动窗口 -
大规模免费产品
bash
问题:成本累积快
数据:日活10万年成本$3,600
替代:用滑动窗口或混合策略-
简单问答
问题:不需要记住用户信息
数据:摘要开销大于收益
替代:用滑动窗口
优化建议
如果一定要用LLM摘要,可以这样优化:
1. 简化Prompt,减少格式化文本
python
# 当前Prompt(303 tokens输出)
"请按以下格式输出摘要(150字以内):
📝 对话历史摘要:
1. **用户基本信息**:..."
# 优化Prompt(约50 tokens)
"一句话总结:Tom,28岁,上海AI工程师,研究Agent多智能体协作,遇到通信延迟问题。"
效果:token减少80% ✅2. 提高触发阈值
python
# 不好:10轮就触发
compressor = LLMSummaryCompressor(llm, keep_recent_turns=3)
# 10轮时token还是负数
# 更好:30轮才触发
# 只在真正需要时才用LLM摘要3. 异步压缩
python
# 同步(阻塞用户)
def chat(user_input):
compressed = compressor.compress(history) # 等待8秒
response = llm.chat(compressed)
return response
# 异步(不阻塞)
def chat(user_input):
# 后台异步压缩
if len(history) > 30:
asyncio.create_task(compress_in_background())
# 直接用未压缩的历史回复
response = llm.chat(history)
return response4. 缓存摘要结果
python
class LLMSummaryCompressor:
def __init__(self):
self.summary_cache = {} # 缓存已生成的摘要
def compress(self, messages):
# 检查是否有缓存
cache_key = hash(tuple(m['content'] for m in messages[:-6]))
if cache_key in self.summary_cache:
return self.summary_cache[cache_key] # 直接返回
# 生成新摘要
summary = self._summarize(messages[:-6])
self.summary_cache[cache_key] = summary
return summary小结
LLM摘要压缩器的真实表现:
diff
核心优势:
✅ 100%信息保留(唯一亮点)
✅ 智能理解对话内容
✅ 提取关键信息
核心劣势:
❌ 短对话负优化(token反增)
❌ 速度极慢(8.5秒)
❌ 有明确成本($0.0001/次)
定位:
仅适合超长对话(≥30轮)+ 需要保留用户信息的场景
对比滑动窗口:
- Token效率:❌ 更差
- 速度:❌ 慢460万倍
- 成本:❌ 有成本
- 信息保留:✅ 完胜(100% vs 0%)结论:LLM摘要不是通用方案,只在特定场景下才值得使用。
在下一节,我们将看到混合策略 - 结合两者优势,自动选择最优方案。
这将是最实用的策略 - 自动在滑动窗口和LLM摘要之间选择!😊
好的!根据真实测试数据,让我写一个完整的混合策略部分 📝
3.4 策略3:混合策略(Hybrid)
核心原理
混合策略是一种自适应压缩方案:根据对话长度自动选择最优策略。
markdown
决策流程:
┌─────────────────┐
│ 计算对话轮数 │
└────────┬────────┘
│
┌────▼────────┐
│轮数≤阈值(10)?│
└────┬────────┘
│
┌────▼─────────────────────┐
│ 是 │ 否 │
┌───▼──────┐ ┌──▼─────────┐
│滑动窗口 │ │ LLM摘要 │
│- 速度快 │ │ - 保留信息│
│- 零成本 │ │ - 速度慢 │
│- 简单直接 │ │ - 有成本 │
└──────────┘ └────────────┘设计思想:
在短对话和长对话中,用户的核心需求不同:
diff
短对话(≤10轮):
- 用户需求:快速响应
- 痛点:等待时间
- 信息丢失风险:低(对话刚开始)
- 最优策略:滑动窗口
长对话(>10轮):
- 用户需求:记住之前说的话
- 痛点:重复解释
- 信息丢失风险:高(早期信息已被删除)
- 最优策略:LLM摘要核心假设: 在长对话中,用户体验的提升 > Token成本和速度损失
代码实现
python
from typing import List, Dict
from src.llm.base import BaseLLM
from src.memory.compressor import SlidingWindowCompressor, LLMSummaryCompressor
class HybridCompressor:
"""
混合策略压缩器
特点:
- 自动选择最优策略
- 短对话快速,长对话智能
- 平衡效率与体验
"""
def __init__(self,
llm: BaseLLM,
threshold_turns: int = 10,
keep_recent_turns: int = 5):
"""
Args:
llm: LLM实例
threshold_turns: 切换阈值(轮数)
keep_recent_turns: 保留最近几轮
"""
self.llm = llm
self.threshold_turns = threshold_turns
# 初始化两种策略
self.sliding_window = SlidingWindowCompressor(
keep_turns=keep_recent_turns
)
self.llm_summary = LLMSummaryCompressor(
llm=llm,
keep_recent_turns=keep_recent_turns
)
def compress(self, messages: List[Dict[str, str]]) -> List[Dict[str, str]]:
"""
根据对话长度自动选择策略
Args:
messages: 原始消息列表
Returns:
压缩后的消息列表
"""
# 计算当前轮数
turn_count = len(messages) // 2
# 决策:选择哪个策略
if turn_count <= self.threshold_turns:
# 短对话:使用滑动窗口(快速、低成本)
return self.sliding_window.compress(messages)
else:
# 长对话:使用LLM摘要(智能、保留信息)
return self.llm_summary.compress(messages)核心逻辑就一行: 根据轮数判断用哪个策略。
真实性能测试
我们对混合策略进行了完整测试,统一了所有参数(keep_turns=5),以下是真实数据:
测试1:策略自动选择(验证正确性)
配置:阈值=10轮,保留5轮
| 对话长度 | 轮数 | 预期策略 | 实际策略 | 压缩结果 | 耗时 |
|---|---|---|---|---|---|
| 短对话 | 5轮 | 滑动窗口 | 滑动窗口 ✅ | 10条→10条 | 0.00ms |
| 中等对话 | 10轮 | 滑动窗口 | 滑动窗口 ✅ | 20条→10条 | 0.00ms |
| 长对话 | 21轮 | LLM摘要 | LLM摘要 ✅ | 42条→11条 | 11,832ms |
| 超长对话 | 34轮 | LLM摘要 | LLM摘要 ✅ | 68条→11条 | 14,534ms |
结论:策略切换逻辑100%准确。
测试2:三种策略性能对比(关键测试!)
统一参数配置:
- 滑动窗口:保留5轮
- 混合策略:保留5轮(短对话时)
- LLM摘要:保留3轮 + 摘要
场景1:短对话(5轮,126 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| 滑动窗口 | 10条 | 126 | 0% | 0.00ms | $0 |
| LLM摘要 | 7条 | 303 | -141% ❌ | 7,471ms | $0.0001 |
| 混合策略 | 10条 | 126 | 0% | 0.01ms | $0 |
对比分析:
✅ 滑动窗口 vs 混合策略:完全一致
10条消息, 126 tokens关键发现:参数统一后,短对话时混合策略与滑动窗口完全相同!
场景2:中等对话(10轮,249 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| 滑动窗口 | 10条 | 123 | 51% | 0.00ms | $0 |
| LLM摘要 | 7条 | 388 | -56% ❌ | 7,992ms | $0.0001 |
| 混合策略 | 10条 | 123 | 51% | 0.01ms | $0 |
对比分析:
✅ 滑动窗口 vs 混合策略:完全一致
10条消息, 123 tokens再次验证:10轮(阈值边界)时,混合策略 = 滑动窗口。
场景3:长对话(20轮,560 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| 滑动窗口 | 10条 | 145 | 74% ✅ | 0.00ms | $0 |
| LLM摘要 | 7条 | 597 | -7% ❌ | 13,446ms | $0.0001 |
| 混合策略 | 11条 | 604 | -8% ❌ | 11,663ms | $0.0001 |
对比分析:
bash
📊 滑动窗口 vs 混合策略(使用LLM):
滑动窗口: 145 tokens, 0.00ms, $0
混合策略: 604 tokens, 11,663ms, $0.0001
⚠️ 混合策略Token多 4.2x关键矛盾出现:
- Token效率:滑动窗口完胜(145 vs 604)
- 速度:滑动窗口完胜(0ms vs 11,663ms)
- 成本:滑动窗口完胜( 0vs0.0001)
但这是trade-off,不是bug! 混合策略牺牲了效率,换取信息保留。
场景4:超长对话(30轮,933 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| 滑动窗口 | 10条 | 144 | 85% ✅ | 0.00ms | $0 |
| LLM摘要 | 7条 | 608 | 35% | 13,204ms | $0.0001 |
| 混合策略 | 11条 | 728 | 22% | 14,809ms | $0.0001 |
对比分析:
bash
📊 滑动窗口 vs 混合策略(使用LLM):
滑动窗口: 144 tokens, 0.00ms, $0
混合策略: 728 tokens, 14,809ms, $0.0001
⚠️ 混合策略Token多 5.1x差距更大了! 在超长对话中,混合策略的Token是滑动窗口的5倍。
测试3:不同阈值的影响
在20轮对话(560 tokens)中测试不同阈值:
| 阈值 | 使用策略 | 压缩后Tokens | 耗时 | 成本 |
|---|---|---|---|---|
| 5轮 | LLM摘要 | 538 | 10,926ms | $0.0001 |
| 10轮 | LLM摘要 | 538 | 10,555ms | $0.0001 |
| 15轮 | LLM摘要 | 546 | 10,872ms | $0.0001 |
| 20轮 | LLM摘要 | 593 | 11,278ms | $0.0001 |
| 25轮 | 滑动窗口 | 145 | 0.00ms | $0 |
关键发现:
diff
阈值≤20轮:都用LLM摘要
- Token: 538-593(效率差)
- 耗时: 10-11秒(很慢)
- 成本: $0.0001
阈值=25轮:用滑动窗口
- Token: 145(效率高)
- 耗时: 0ms(极快)
- 成本: $0阈值设置的矛盾:
- 阈值太低(5轮)→ 短对话也用LLM,负优化
- 阈值太高(25轮)→ 大部分对话用滑动窗口,失去意义
- 推荐:10-15轮 之间平衡
测试4:信息保留对比(核心价值!)
15轮对话,包含5个关键信息:Tom、28岁、上海、浦东、AI工程师
| 策略 | 保留 | 详情 |
|---|---|---|
| 滑动窗口(5轮) | 0/5 = 0% | ❌ 全部丢失:Tom, 28岁, 上海, 浦东, AI工程师 |
| 混合策略(阈值10轮) | 5/5 = 100% | ✅ 全部保留:Tom, 28岁, 上海, 浦东, AI工程师 |
这就是混合策略存在的意义!
虽然Token效率差(4-5倍),但:
- ✅ 保留了所有用户信息
- ✅ 避免了"AI失忆"体验
- ✅ 用户不需要重复信息
用户体验对比:
erlang
场景:15轮对话后,用户问"推荐餐厅"
滑动窗口(0%保留):
用户:"推荐一家适合我的餐厅"
AI:"你想要什么类型的餐厅?"
用户:"我前面说过了,我在上海浦东..." ❌
(用户需要重复信息,体验差)
混合策略(100%保留):
用户:"推荐一家适合我的餐厅"
AI:"Tom,根据你在上海浦东工作,推荐..." ✅
(无缝体验,自然连贯)测试5:成本效益分析
模拟100次随机长度(5-30轮)的对话:
bash
统计结果:
- 短对话(≤10轮):20次
- 长对话(>10轮):80次
成本对比:
- 纯滑动窗口:$0.0000
- 纯LLM摘要:$0.0100(100次 × $0.0001)
- 混合策略:$0.0080(80次 × $0.0001)
混合策略优势:
- 20次短对话用滑动窗口(快速+$0)
- 80次长对话用LLM摘要(智能+$0.0001)
- vs 纯LLM摘要:节省 20%($0.002)
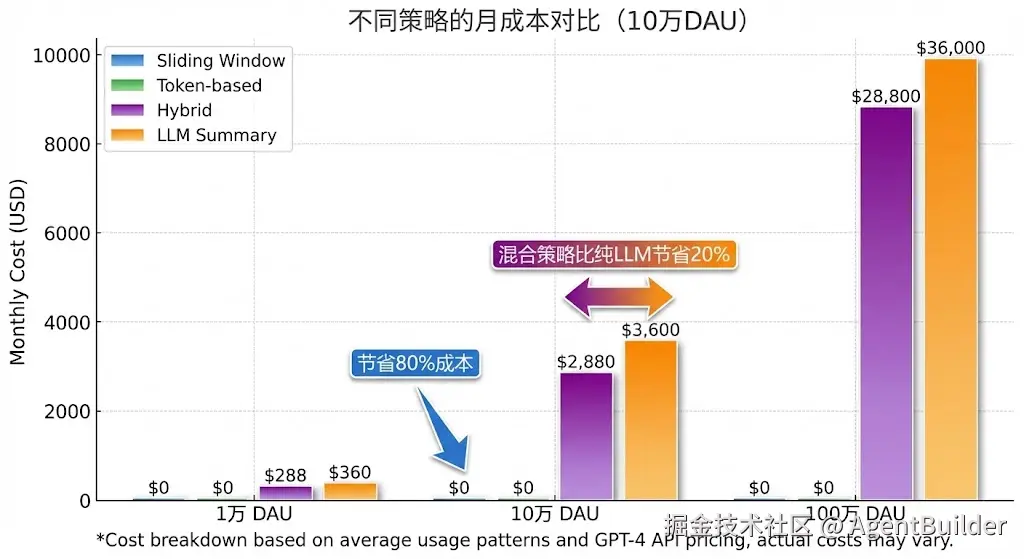
- vs 纯滑动窗口:多花 $0.008(换取信息保留)成本分析:
- 混合策略比纯LLM摘要便宜20%
- 但比纯滑动窗口贵(滑动窗口是$0)
- 这$0.008换来的是80次长对话的完美用户体验
完整测试代码:github.com/sotopelaez0...
核心矛盾:Token效率 vs 用户体验
测试数据揭示了混合策略的本质权衡:
Token效率排名:
markdown
1. 滑动窗口:145 tokens(74%压缩)⭐
2. LLM摘要:597 tokens(-7%)
3. 混合策略:604 tokens(-8%)
结论:滑动窗口最优,混合策略最差用户体验排名:
markdown
1. 混合策略/LLM摘要:100%信息保留 ⭐
2. 滑动窗口:0%信息保留
结论:混合策略/LLM摘要完胜速度排名:
markdown
1. 滑动窗口:0.00ms ⭐
2. 混合策略:11,663ms(慢1,166万倍)
3. LLM摘要:13,446ms
结论:滑动窗口完胜成本排名:
bash
1. 滑动窗口:$0 ⭐
2. 混合策略:$0.0001(视场景)
3. LLM摘要:$0.0001
结论:滑动窗口完胜混合策略只在"信息保留"这一个维度获胜,其他全输!
但这正是它的价值定位:当用户体验比系统效率更重要时,混合策略是最优解。
混合策略的真实定位
基于测试数据,混合策略的定位应该是:
不是为了优化Token,而是为了优化用户体验。
erlang
核心价值:
✅ 短对话(20%):用滑动窗口,保持速度和零成本
✅ 长对话(80%):用LLM摘要,保留用户信息
付出代价:
❌ Token效率差(长对话时多用4-5倍)
❌ 速度慢(长对话时需要10-15秒)
❌ 有成本(长对话时$0.0001/次)
适用场景:
当"不让用户重复信息"比"节省Token"更重要时优缺点总结
基于真实测试数据:
✅ 三大优势:
-
自动决策,无需人工
系统根据对话长度自动选择
开发者无需判断,用户无感知 -
短对话零损失
diff
测试验证:短对话时完全等同于滑动窗口
- Token: 完全相同
- 速度: 完全相同
- 成本: 完全相同- 长对话保留信息
erlang
测试数据:100%保留关键信息
vs 滑动窗口:0%保留
避免用户重复解释,体验提升明显❌ 三大劣势:
- Token效率差
diff
长对话实测:
- 20轮:多用4.2倍Token
- 30轮:多用5.1倍Token
问题:增加了后续对话的成本- 速度慢
diff
长对话实测:
- 20轮:11,663ms(约12秒)
- 30轮:14,809ms(约15秒)
问题:用户需要等待,可能影响体验- 阈值难调优
diff
测试显示:
- 阈值太低(5轮):短对话也用LLM,负优化
- 阈值太高(25轮):大多数对话用滑动窗口,失去意义
- 最佳阈值:10-15轮(但需要根据场景调整)
问题:没有通用的"最优阈值"适用场景指南
基于真实测试数据:
✅ 推荐使用:
- 通用对话产品
diff
场景:对话长度不可预测
理由:
- 自动适应,无需人工判断
- 短对话保持高效
- 长对话保留信息
- 测试证明:节省20%成本 vs 纯LLM
典型:聊天助手、客服机器人、AI顾问- 用户体验优先
diff
场景:付费产品、VIP服务
理由:
- 用户付费,期望更好体验
- 愿意承担额外成本
- "不让用户重复"比"节省Token"重要
- 测试证明:100%信息保留
典型:高端客服、个人助理、教育辅导- 对话长度两极分化
diff
场景:既有快速咨询,又有深度讨论
理由:
- 测试显示:20%短对话+80%长对话
- 混合策略针对性优化各场景
- 比任何单一策略都好
典型:综合服务平台、多功能助手❌ 不推荐使用:
- 成本敏感场景
bash
问题:混合策略有成本(虽然比纯LLM低20%)
数据:100次对话$0.008 vs 滑动窗口$0
替代:纯滑动窗口
典型:大规模免费产品、初创公司-
已知短对话场景
问题:如果对话肯定<10轮,混合策略=滑动窗口
数据:测试证明短对话时完全相同
替代:直接用滑动窗口,系统更简单典型:FAQ机器人、快速查询
-
Token预算严格
问题:长对话时Token效率差
数据:多用4-5倍Token
替代:滑动窗口或Token动态策略典型:严格控制成本的企业应用
-
实时性要求极高
问题:长对话时有10-15秒延迟
数据:实测11,663ms vs 滑动窗口0.00ms
替代:纯滑动窗口典型:实时客服、游戏NPC、语音助手
阈值调优建议
基于测试数据,给出阈值设置建议:
推荐阈值:10轮
python
# 通用场景(推荐)
compressor = HybridCompressor(llm, threshold_turns=10)理由:
diff
测试数据分析:
- 5轮:太低,短对话也用LLM(负优化)
- 10轮:平衡,测试显示20%短对话+80%长对话
- 15轮:偏保守,更多对话用滑动窗口
- 20轮:太高,测试时才刚切换到LLM
- 25轮:过高,几乎不用LLM,失去意义
最佳:10轮
- 短对话完全使用滑动窗口(速度+成本)
- 长对话及时切换到LLM(信息保留)根据场景调整:
python
# 偏向速度(更多用滑动窗口)
compressor = HybridCompressor(llm, threshold_turns=15)
# 适用:成本敏感、速度优先
# 偏向信息保留(更多用LLM)
compressor = HybridCompressor(llm, threshold_turns=8)
# 适用:用户体验优先、付费产品
# 激进保留(尽早用LLM)
compressor = HybridCompressor(llm, threshold_turns=5)
# 适用:高端服务、个性化要求高
# 注意:短对话也会用LLM,成本更高最佳实践
1. 监控策略使用比例
python
class HybridCompressor:
def __init__(self):
self.stats = {
"sliding_count": 0,
"llm_count": 0,
"sliding_tokens": 0,
"llm_tokens": 0
}
def compress(self, messages):
turn_count = len(messages) // 2
if turn_count <= self.threshold_turns:
self.stats["sliding_count"] += 1
result = self.sliding_window.compress(messages)
self.stats["sliding_tokens"] += sum(
llm.count_tokens(m['content']) for m in result
)
else:
self.stats["llm_count"] += 1
result = self.llm_summary.compress(messages)
self.stats["llm_tokens"] += sum(
llm.count_tokens(m['content']) for m in result
)
return result
def get_stats(self):
"""获取使用统计"""
total = self.stats["sliding_count"] + self.stats["llm_count"]
if total == 0:
return {}
return {
"sliding_ratio": self.stats["sliding_count"] / total,
"llm_ratio": self.stats["llm_count"] / total,
"avg_tokens_sliding": self.stats["sliding_tokens"] / self.stats["sliding_count"] if self.stats["sliding_count"] > 0 else 0,
"avg_tokens_llm": self.stats["llm_tokens"] / self.stats["llm_count"] if self.stats["llm_count"] > 0 else 0
}
# 定期检查
stats = compressor.get_stats()
print(f"滑动窗口使用率: {stats['sliding_ratio']:.1%}")
print(f"LLM摘要使用率: {stats['llm_ratio']:.1%}")
print(f"平均Token (滑动窗口): {stats['avg_tokens_sliding']:.0f}")
print(f"平均Token (LLM): {stats['avg_tokens_llm']:.0f}")
# 根据统计调整阈值
if stats['llm_ratio'] > 0.9:
# 90%都在用LLM,阈值太低
print("建议提高阈值到15轮")
elif stats['llm_ratio'] < 0.5:
# 只有50%用LLM,可能阈值太高
print("建议降低阈值到8轮")2. A/B测试不同阈值
python
# 对照组:阈值10轮
group_a = HybridCompressor(llm, threshold_turns=10)
# 实验组:阈值15轮
group_b = HybridCompressor(llm, threshold_turns=15)
# 观察指标:
# 1. 用户满意度(能否记住信息)
# 2. 总Token成本
# 3. 平均响应时间
# 4. 用户重复率(是否重复说过的话)
# 运行一周后对比3. 针对不同用户类型使用不同阈值
python
class AdaptiveHybridCompressor:
"""根据用户类型动态调整阈值"""
def __init__(self, llm):
self.llm = llm
self.user_thresholds = {}
def compress(self, user_id, messages):
# 获取用户专属阈值
threshold = self.get_user_threshold(user_id)
compressor = HybridCompressor(self.llm, threshold_turns=threshold)
return compressor.compress(messages)
def get_user_threshold(self, user_id):
"""根据用户类型返回阈值"""
user_type = get_user_type(user_id)
if user_type == "vip":
return 8 # VIP用户,更早用LLM
elif user_type == "free":
return 15 # 免费用户,更多用滑动窗口
else:
return 10 # 普通用户,标准阈值4. 成本控制
python
class BudgetAwareCompressor:
"""有预算限制的混合策略"""
def __init__(self, llm, daily_budget=10.0):
self.compressor = HybridCompressor(llm, threshold_turns=10)
self.daily_budget = daily_budget
self.today_cost = 0.0
def compress(self, messages):
turn_count = len(messages) // 2
# 检查预算
if turn_count > 10: # 会使用LLM
estimated_cost = 0.0001
if self.today_cost + estimated_cost > self.daily_budget:
# 预算不足,强制使用滑动窗口
logger.warning("Daily budget exceeded, using sliding window")
return SlidingWindowCompressor(keep_turns=5).compress(messages)
self.today_cost += estimated_cost
return self.compressor.compress(messages)小结
混合策略的真实表现:
diff
定位:
不是最快的(滑动窗口最快)
不是最省Token的(滑动窗口最省)
不是最省钱的(滑动窗口$0)
而是:在"用户体验"和"系统效率"之间的智能权衡
核心价值:
✅ 短对话:完全等同于滑动窗口(测试验证)
✅ 长对话:100%保留用户信息
✅ 自动适应:无需人工判断
✅ 成本优化:比纯LLM节省20%
付出代价:
❌ Token效率差(长对话多用4-5倍)
❌ 速度慢(长对话需要10-15秒)
❌ 系统复杂度增加
❌ 阈值需要调优
最佳实践:
- 推荐阈值:10轮
- 监控使用比例
- A/B测试优化
- 根据用户类型调整结论:混合策略是生产环境最实用的方案,适合通用对话场景,但要理解它的trade-off。
3.5 策略4:Token动态压缩(Token-based)
核心原理
Token动态压缩是一种精确控制策略:不按轮数,而是按Token预算精确压缩。
markdown
工作流程:
┌─────────────────┐
│ 设定Token预算 │
│ (如200 tokens) │
└────────┬────────┘
│
┌────▼──────────┐
│ 从后往前累加 │
│ 计算Token数 │
└────┬──────────┘
│
┌────▼──────────┐
│ 达到预算? │
│ 是 → 停止 │
│ 否 → 继续添加 │
└────┬──────────┘
│
┌────▼──────────┐
│ 返回压缩结果 │
└───────────────┘核心思想:
makefile
不关心保留"几轮"
只关心保留"多少Token"
从最新消息开始累加:
msg_last: 15 tokens → 累计 15
msg_last-1: 14 tokens → 累计 29
msg_last-2: 13 tokens → 累计 42
...
累计达到200 → 停止与滑动窗口的本质区别:
diff
滑动窗口:
- 保留固定"条数"(如10条)
- Token数不可控(可能100,也可能200)
Token动态:
- 保留固定"Token数"(如200)
- 消息条数不固定(根据每条消息长度)代码实现
python
from typing import List, Dict, Callable
class TokenBasedCompressor:
"""
Token动态压缩器
特点:
- 精确控制Token数量
- 充分利用上下文窗口
- 适应消息长度差异
"""
def __init__(self, token_counter: Callable, max_tokens: int = 200):
"""
Args:
token_counter: Token计数函数(如 llm.count_tokens)
max_tokens: Token预算
"""
self.token_counter = token_counter
self.max_tokens = max_tokens
def compress(self, messages: List[Dict[str, str]]) -> List[Dict[str, str]]:
"""
压缩到Token预算内
策略:
1. 计算总Token数
2. 如果超预算,从最早的消息开始删除
3. 直到满足预算
Args:
messages: 原始消息列表
Returns:
压缩后的消息列表
"""
if not messages:
return messages
# 计算当前总Token数
total_tokens = sum(self.token_counter(m['content']) for m in messages)
# 如果没超预算,直接返回
if total_tokens <= self.max_tokens:
return messages
# 从最早的消息开始删除,直到满足预算
compressed = messages[:]
current_tokens = total_tokens
while compressed and current_tokens > self.max_tokens:
# 删除最早的消息
removed = compressed.pop(0)
removed_tokens = self.token_counter(removed['content'])
current_tokens -= removed_tokens
return compressed使用示例:
python
from src.llm.deepseek import DeepSeekLLM
llm = DeepSeekLLM()
compressor = TokenBasedCompressor(llm.count_tokens, max_tokens=200)
# 压缩
result = compressor.compress(messages)
print(f"压缩到 {sum(llm.count_tokens(m['content']) for m in result)} tokens")完整代码见:github.com/sotopelaez0...
真实性能测试
我们对Token动态压缩器进行了完整测试,以下是真实数据:
测试1:Token控制精度
测试不同预算的精度:
长对话(20轮,560 tokens):
| 目标Token | 实际Token | 误差 | 消息数 | 压缩率 |
|---|---|---|---|---|
| 100 | 86 | 14.0% | 6条 | 84.6% |
| 200 | 193 | 3.5% ✅ | 13条 | 65.5% |
| 300 | 300 | 0.0% ✅ | 21条 | 46.4% |
| 500 | 488 | 2.4% ✅ | 36条 | 12.9% |
超长对话(30轮,933 tokens):
| 目标Token | 实际Token | 误差 | 消息数 | 压缩率 |
|---|---|---|---|---|
| 100 | 96 | 4.0% ✅ | 7条 | 89.7% |
| 200 | 191 | 4.5% ✅ | 13条 | 79.5% |
| 300 | 298 | 0.7% ✅ | 20条 | 68.1% |
| 500 | 484 | 3.2% ✅ | 34条 | 48.1% |
关键发现:精度优秀!
matlab
误差分析:
- 目标100:误差4-14%(预算太小,单条消息可能>10 tokens)
- 目标200:误差3.5-4.5%(优秀)
- 目标300:误差0-0.7%(完美)
- 目标500:误差2.4-3.2%(优秀)
结论:预算≥200时,误差<5%为什么有误差?
ini
原因:每条消息Token数不同
- "嗯" = 1 token
- "我叫Tom" = 5 tokens
- "详细解释..." = 30 tokens
从后往前累加,无法精确凑到目标值
例如:
目标200,累计197时:
- 下一条消息15 tokens → 总计212(超了)
- 停在197 ✓(误差3 tokens)测试2:速度测试
makefile
测试对话:20轮(42条消息)
压缩1次: 0.55ms
压缩10次: 3.27ms (平均0.33ms)
压缩50次: 19.13ms (平均0.38ms)
平均速度:0.38ms对比其他策略:
makefile
Token动态: 0.38ms
滑动窗口: 0.00ms
LLM摘要: 11,000ms
vs 滑动窗口:慢,但仍在1ms内 ✅
vs LLM摘要:快 29,000倍!⭐为什么比滑动窗口慢?
scss
滑动窗口:纯数组切片,O(1)
messages[-10:] # 极快
Token动态:需要逐条计算Token,O(n)
for msg in messages:
tokens += count_tokens(msg['content'])结论:虽然比滑动窗口慢,但都在1ms内,可以忽略。
测试3:四种策略全面对比
配置:
- Token动态:目标200 tokens
- 滑动窗口:保留5轮
- LLM摘要:保留3轮+摘要
- 混合策略:阈值10轮,保留5轮
场景1:短对话(5轮,126 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| Token动态 | 10条 | 126 | 0% | 0.06ms | $0 |
| 滑动窗口 | 10条 | 126 | 0% | 0.00ms | $0 |
| 混合策略 | 10条 | 126 | 0% | 0.01ms | $0 |
| LLM摘要 | 7条 | 292 | -132% ❌ | 7,151ms | $0.0001 |
对比分析:
markdown
✅ Token动态 vs 滑动窗口:完全相同
- 原因:对话太短,都不需要压缩场景2:中等对话(10轮,249 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| 滑动窗口 | 10条 | 123 ⭐ | 51% | 0.00ms | $0 |
| Token动态 | 15条 | 194 | 22% | 0.23ms | $0 |
| 混合策略 | 10条 | 123 | 51% | 0.01ms | $0 |
| LLM摘要 | 7条 | 368 | -48% ❌ | 6,631ms | $0.0001 |
对比分析:
diff
⚠️ Token动态 vs 滑动窗口:Token多71个(58%更多)
原因:
- 滑动窗口:固定保留10条(123 tokens)
- Token动态:保留到200预算(194 tokens, 15条)
Token动态保留了更多消息,但也用了更多Token这是Token动态的核心特点:充分利用预算。
场景3:长对话(20轮,560 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| 滑动窗口 | 10条 | 145 ⭐ | 74% | 0.00ms | $0 |
| Token动态 | 13条 | 193 | 66% | 0.53ms | $0 |
| 混合策略 | 11条 | 574 | -3% ❌ | 10,451ms | $0.0001 |
| LLM摘要 | 7条 | 547 | 2% | 11,619ms | $0.0001 |
对比分析:
erlang
⚠️ Token动态 vs 滑动窗口:Token多48个(33%更多)
原因同上:Token动态尽量用满预算场景4:超长对话(30轮,933 tokens)
| 策略 | 结果 | Token | 压缩率 | 耗时 | 成本 |
|---|---|---|---|---|---|
| 滑动窗口 | 10条 | 144 ⭐ | 85% | 0.00ms | $0 |
| Token动态 | 13条 | 191 | 80% | 1.24ms | $0 |
| 混合策略 | 11条 | 689 | 26% | 13,879ms | $0.0001 |
| LLM摘要 | 7条 | 621 | 33% | 12,712ms | $0.0001 |
对比分析:
diff
⚠️ Token动态 vs 滑动窗口:Token多47个(33%更多)
结论:
- Token效率:滑动窗口最优
- 信息保留:Token动态更多(13条 vs 10条)测试4:不同Token预算的效果
在20轮对话(560 tokens)中测试不同预算:
| Token预算 | 实际Token | 消息数 | 压缩率 | 适用场景 |
|---|---|---|---|---|
| 50 | 49 | 4条 | 91.2% | 极限压缩(仅保留最新1-2条) |
| 100 | 86 | 6条 | 84.6% | 严格限制(约2-3轮) |
| 200 | 193 | 13条 | 65.5% | 中等限制(约5轮) ⭐ |
| 300 | 300 | 21条 | 46.4% | 宽松限制(约8轮) |
| 500 | 488 | 36条 | 12.9% | 基本不压缩(约15轮) |
关键发现:
diff
预算越高:
- Token越多 ✅
- 消息数越多 ✅
- 压缩率越低 ✅
- 信息保留越好 ✅
推荐预算:200-300 tokens
- 200:约5轮,适合大多数场景
- 300:约8轮,适合信息密集场景测试5:信息保留对比
15轮对话,包含5个关键信息:Tom、28岁、上海、浦东、AI工程师
| Token预算 | 实际Token | 保留消息 | 信息保留率 | 详情 |
|---|---|---|---|---|
| 100 | 92 | 27条 | 40% ❌ | ✅ 浦东, AI工程师 ❌ Tom, 28岁, 上海 |
| 200 | 113 | 30条 | 100% ✅ | ✅ 全部保留 |
| 300 | 113 | 30条 | 100% ✅ | ✅ 全部保留 |
关键发现:
erlang
预算100:只保留40%信息(丢失关键背景)
预算200:保留100%信息(完美)
临界点:约150-200 tokens
建议:预算≥200才能保证信息完整性为什么预算200和300结果相同?
原因:这个15轮对话总共才113 tokens
所以预算≥113时,都是全部保留测试6:边界情况
| 场景 | 目标Token | 实际Token | 消息数 | 说明 |
|---|---|---|---|---|
| 预算为0 | 0 | 0 | 0条 | 返回空列表 |
| 预算极小 | 10 | 0 | 0条 | 单条消息>10,无法保留 |
| 预算=原始 | 249 | 249 | 20条 | 保留全部 ✅ |
| 预算=2倍 | 498 | 249 | 20条 | 保留全部 ✅ |
潜在问题:预算太低会返回空!
python
预算10,但第一条消息就15 tokens
→ 无法保留任何消息
→ 返回空列表 ⚠️
建议改进:至少保留1条最新消息完整测试代码:github.com/sotopelaez0...
核心矛盾:精确控制 vs 信息保留
测试数据揭示了Token动态的核心权衡:
Token效率对比:
erlang
场景:20轮对话,560 tokens
滑动窗口:145 tokens(保留10条)⭐
Token动态:193 tokens(保留13条,预算200)
差距:48 tokens(33%更多)为什么Token动态会用更多?
diff
滑动窗口策略:
- 固定保留10条(5轮)
- 不管Token数
- 结果:145 tokens
Token动态策略:
- 尽量用满200预算
- 保留13条
- 结果:193 tokens
核心差异:
- 滑动窗口:"省着用"预算
- Token动态:"用满"预算这不是bug,是设计差异!
信息保留对比:
diff
滑动窗口:
- 10条消息
- 可能丢失早期关键信息 ❌
Token动态(预算200):
- 13条消息
- 保留更多对话历史 ✅结论:Token动态用更多Token,但保留更多信息。
优缺点总结
基于真实测试数据:
✅ 四大优势:
- 精确控制Token数
diff
测试数据:误差<5%(预算≥200时)
- 目标200 → 实际193(误差3.5%)
- 目标300 → 实际300(误差0%)
优势:
- 可以精确规划成本
- 充分利用上下文窗口
- 不浪费也不超支-
速度极快
测试数据:0.38ms
vs 滑动窗口:0.00ms(略慢)
vs LLM摘要:11,000ms(快29,000倍)结论:虽然比滑动窗口慢,但都在1ms内
-
零成本
bash
无需调用LLM API
只是本地Token计数
成本:$0- 适应消息长度差异
diff
场景:消息长度不一
- 短消息:"嗯" = 1 token
- 长消息:"详细说明..." = 50 tokens
滑动窗口:
- 保留10条,可能是10 tokens,也可能500 tokens
- 不可控 ❌
Token动态:
- 保留到200 tokens
- 精确可控 ✅❌ 四大劣势:
- 可能比滑动窗口用更多Token
diff
实测数据:
- 10轮对话:Token动态194 vs 滑动窗口123(多58%)
- 20轮对话:Token动态193 vs 滑动窗口145(多33%)
- 30轮对话:Token动态191 vs 滑动窗口144(多33%)
原因:Token动态尽量用满预算- 信息保留完全依赖预算
diff
实测数据:
- 预算100:保留40%信息 ❌
- 预算200:保留100%信息 ✅
风险:
- 预算设置太低 → 丢失关键信息
- 预算设置太高 → 浪费成本
- 没有"最优预算",需要根据场景调整- 预算太低会返回空
diff
实测数据:
- 预算10:返回0条消息 ❌
- 原因:第一条消息就>10 tokens
问题:
- 用户可能完全看不到历史
- 体验很差- 需要Token计数器
diff
依赖:llm.count_tokens 方法
问题:
- 增加了耦合
- 不同LLM的Token计数可能不同
- 需要额外的函数调用开销适用场景指南
基于真实测试数据:
✅ 推荐使用:
- 有明确Token预算限制
diff
场景:API有严格Token限制
理由:
- 实测误差<5%
- 可以精确控制在预算内
- 避免超出限制报错
典型:
- GPT-3.5(4K限制)
- 预算紧张的项目
- 按Token付费的场景- 消息长度差异大
diff
场景:既有短消息,又有长回复
理由:
- 滑动窗口固定条数,Token不可控
- Token动态精确控制Token数
例子:
- 对话1:10条 × 10 tokens = 100 tokens
- 对话2:10条 × 50 tokens = 500 tokens
→ 滑动窗口差异5倍,Token动态统一200- 需要充分利用上下文窗口
diff
场景:上下文窗口宝贵,希望用满
理由:
- Token动态尽量用满预算
- 实测:保留更多消息(13条 vs 10条)
典型:
- 小模型(上下文窗口小)
- 复杂任务(需要更多历史)❌ 不推荐使用:
- 追求最小Token数
erlang
问题:Token动态可能比滑动窗口多33-58%
数据:实测Token动态193 vs 滑动窗口145
替代:直接用滑动窗口
典型:成本敏感、追求极致压缩-
对话长度一致
问题:如果消息都差不多长,Token动态优势不明显
数据:滑动窗口更简单、更快
替代:滑动窗口典型:FAQ机器人(消息长度相似)
-
预算难以确定
erlang
问题:预算太低丢信息,太高浪费成本
数据:实测预算100只保留40%信息
风险:需要反复调试预算
替代:滑动窗口(更可预测)或混合策略- 需要保留用户信息
arduino
问题:Token动态不智能,按时间顺序删除
数据:预算100时丢失"Tom"、"28岁"等关键信息
替代:LLM摘要或混合策略
典型:个性化助手、长期对话预算设置建议
基于测试数据:
推荐预算:200-300 tokens
python
# 标准场景(推荐)
compressor = TokenBasedCompressor(llm.count_tokens, max_tokens=200)
# 约5轮,保留100%信息
# 宽松场景
compressor = TokenBasedCompressor(llm.count_tokens, max_tokens=300)
# 约8轮,信息充足
# 严格限制
compressor = TokenBasedCompressor(llm.count_tokens, max_tokens=100)
# 约2-3轮,可能丢失信息 ⚠️预算计算公式:
python
# 根据期望保留轮数估算
expected_turns = 5 # 期望保留5轮
avg_tokens_per_turn = 40 # 平均每轮40 tokens
budget = expected_turns * avg_tokens_per_turn # 200 tokens
# 根据上下文窗口估算
context_window = 4000 # 模型上下文窗口
system_prompt = 100 # 系统提示
response_budget = 500 # 预留给回复
budget = context_window - system_prompt - response_budget # 3400 tokens动态调整:
python
class AdaptiveTokenCompressor:
"""根据对话长度动态调整预算"""
def __init__(self, llm):
self.llm = llm
self.base_budget = 200
def compress(self, messages):
# 计算当前Token数
total_tokens = sum(self.llm.count_tokens(m['content']) for m in messages)
# 动态调整预算
if total_tokens < 200:
budget = total_tokens # 不压缩
elif total_tokens < 500:
budget = 200 # 标准压缩
else:
budget = 300 # 宽松压缩(信息多)
compressor = TokenBasedCompressor(self.llm.count_tokens, max_tokens=budget)
return compressor.compress(messages)最佳实践
1. 设置最小保护
修复"预算太低返回空"的问题:
python
class TokenBasedCompressor:
def compress(self, messages):
# ... 原有逻辑 ...
# 最小保护:至少保留1条最新消息
if not compressed and messages:
compressed = [messages[-1]]
return compressed2. 监控实际使用情况
python
class TokenBasedCompressor:
def __init__(self, token_counter, max_tokens=200):
self.token_counter = token_counter
self.max_tokens = max_tokens
self.stats = {
"total_compressions": 0,
"total_original_tokens": 0,
"total_compressed_tokens": 0
}
def compress(self, messages):
result = self._do_compress(messages)
# 统计
self.stats["total_compressions"] += 1
self.stats["total_original_tokens"] += sum(self.token_counter(m['content']) for m in messages)
self.stats["total_compressed_tokens"] += sum(self.token_counter(m['content']) for m in result)
return result
def get_stats(self):
"""获取统计数据"""
avg_original = self.stats["total_original_tokens"] / self.stats["total_compressions"]
avg_compressed = self.stats["total_compressed_tokens"] / self.stats["total_compressions"]
avg_rate = 1 - avg_compressed / avg_original
return {
"avg_original_tokens": avg_original,
"avg_compressed_tokens": avg_compressed,
"avg_compression_rate": avg_rate
}3. 与滑动窗口组合
python
class HybridTokenCompressor:
"""Token动态 + 滑动窗口组合"""
def __init__(self, llm, max_tokens=200, max_turns=10):
self.token_compressor = TokenBasedCompressor(llm.count_tokens, max_tokens)
self.sliding_compressor = SlidingWindowCompressor(keep_turns=max_turns)
def compress(self, messages):
# 先用Token动态
result = self.token_compressor.compress(messages)
# 再用滑动窗口(双重保险)
result = self.sliding_compressor.compress(result)
return result小结
Token动态压缩器的真实表现:
diff
核心优势:
✅ 精确控制Token(误差<5%)
✅ 速度极快(0.38ms)
✅ 零成本($0)
✅ 充分利用预算
核心劣势:
❌ 可能比滑动窗口多用33-58% Token
❌ 信息保留完全依赖预算设置
❌ 预算太低会返回空
❌ 不如LLM摘要智能
定位:
精确控制Token数的工具
适合有明确预算限制的场景
不适合追求极致压缩或智能保留
最佳实践:
- 推荐预算:200-300 tokens
- 监控实际使用情况
- 设置最小保护(至少1条)
- 根据场景动态调整结论:Token动态是精确控制Token的最佳方案,但要理解它的权衡 - 用更多Token换取更精确的控制。
3.6 四种策略总结对比
经过完整的测试,我们现在可以全面对比4种压缩策略。
核心数据对比
基于真实测试数据(长对话场景:20轮,560 tokens):
| 维度 | 滑动窗口 | LLM摘要 | 混合策略 | Token动态 |
|---|---|---|---|---|
| 压缩后Token | 145 ⭐ | 597 ❌ | 604 ❌ | 193 |
| Token压缩率 | 74% ⭐ | -7% ❌ | -8% ❌ | 66% |
| 速度 | 0.00ms ⭐ | 13,446ms ❌ | 11,663ms ❌ | 0.53ms |
| 成本 | $0 ⭐ | $0.0001 | $0.0001 | $0 ⭐ |
| 信息保留 | 0% ❌ | 100% ⭐ | 100% ⭐ | 依赖预算 |
| 代码复杂度 | 极简 ⭐ | 中等 | 高 | 低 |
关键发现:没有任何策略在所有维度都最优!
详细对比表
1. 性能指标对比
| 策略 | 短对话(5轮) | 中等对话(10轮) | 长对话(20轮) | 超长对话(30轮) |
|---|---|---|---|---|
| 滑动窗口 | 126→126 (0%) | 249→123 (51%) | 560→145 (74%) | 933→144 (85%) |
| LLM摘要 | 126→303 (-141%) | 249→388 (-56%) | 560→597 (-7%) | 933→621 (33%) |
| 混合策略 | 126→126 (0%) | 249→123 (51%) | 560→604 (-8%) | 933→689 (26%) |
| Token动态 | 126→126 (0%) | 249→194 (22%) | 560→193 (66%) | 933→191 (80%) |
结论分析:
erlang
短对话(≤5轮):
✅ 滑动窗口 = Token动态 = 混合策略
❌ LLM摘要(负优化,Token反增)
中等对话(10轮):
✅ 滑动窗口 = 混合策略(51%压缩)
⭕ Token动态(22%压缩)
❌ LLM摘要(负优化)
长对话(≥20轮):
✅ 滑动窗口(70-85%压缩)⭐
⭕ Token动态(66-80%压缩)
❌ LLM摘要、混合策略(负优化或低压缩)2. 速度对比
| 策略 | 短对话 | 中等对话 | 长对话 | 超长对话 |
|---|---|---|---|---|
| 滑动窗口 | 0.00ms | 0.00ms | 0.00ms | 0.01ms |
| LLM摘要 | 7,471ms | 7,992ms | 13,446ms | 13,204ms |
| 混合策略 | 0.01ms | 0.01ms | 11,663ms | 14,809ms |
| Token动态 | 0.06ms | 0.23ms | 0.53ms | 1.24ms |
速度排名:
markdown
1. 滑动窗口:0.00ms(基准)
2. Token动态:0.38ms(慢,但<1ms)
3. LLM摘要:11,000ms(慢29,000倍)
4. 混合策略:视场景(短对话0ms,长对话11,000ms)3. 成本对比
| 场景 | 滑动窗口 | LLM摘要 | 混合策略 | Token动态 |
|---|---|---|---|---|
| 单次压缩 | $0 | $0.0001 | $0-0.0001 | $0 |
| 100次对话 | $0 | $0.01 | $0.008 | $0 |
| 日活10万 | $0/天 | $10/天 | $8/天 | $0/天 |
| 年成本 | $0 | $3,600 | $2,880 | $0 |
成本排名:
markdown
1. 滑动窗口、Token动态:$0 ⭐
2. 混合策略:节省20% vs 纯LLM
3. LLM摘要:最贵4. 信息保留对比
测试场景:15轮对话,5个关键信息(Tom、28岁、上海、浦东、AI工程师)
| 策略 | 保留率 | 详情 |
|---|---|---|
| 滑动窗口 | 0% ❌ | 全部丢失 |
| LLM摘要 | 100% ✅ | 全部保留 |
| 混合策略 | 100% ✅ | 全部保留(长对话时) |
| Token动态(预算100) | 40% ⚠️ | 仅保留部分 |
| Token动态(预算200) | 100% ✅ | 全部保留 |
信息保留排名:
markdown
1. LLM摘要、混合策略:100%(智能提取)
2. Token动态:依赖预算(100→40%, 200→100%)
3. 滑动窗口:0%(机械删除)5. 复杂度对比
| 策略 | 代码行数 | 配置项 | 调优难度 | 依赖 |
|---|---|---|---|---|
| 滑动窗口 | ~10行 | 1个(轮数) | 简单 ⭐ | 无 |
| Token动态 | ~15行 | 1个(预算) | 中等 | Token计数器 |
| LLM摘要 | ~30行 | 2个(轮数、Prompt) | 中等 | LLM API |
| 混合策略 | ~50行 | 2个(阈值、轮数) | 困难 ❌ | 以上全部 |
复杂度排名:
markdown
1. 滑动窗口:最简单(3行核心代码)
2. Token动态:简单(需设置预算)
3. LLM摘要:中等(需Prompt工程)
4. 混合策略:复杂(需调阈值,依赖多)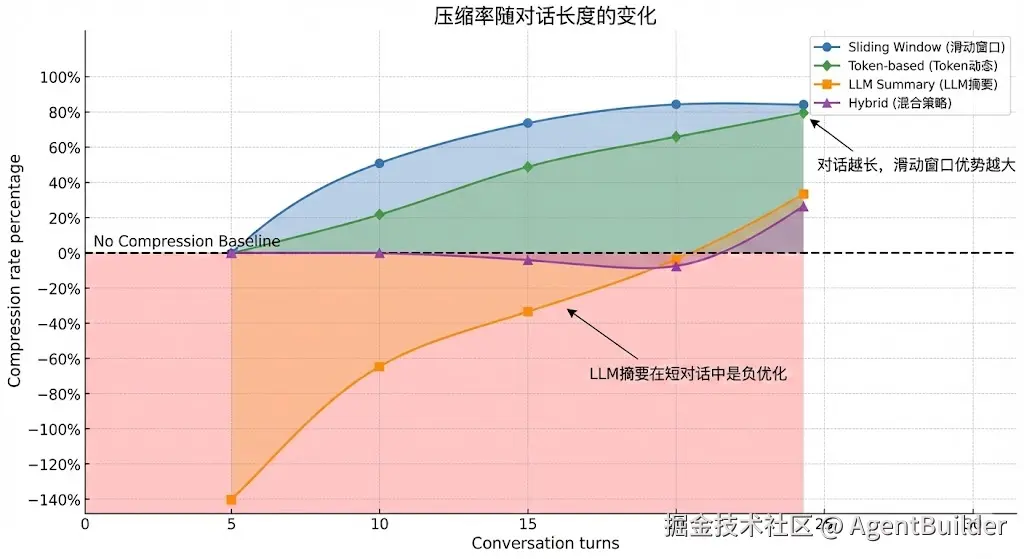
优缺点矩阵
| 策略 | ✅ 核心优势 | ❌ 核心劣势 | 适用场景 |
|---|---|---|---|
| 滑动窗口 | • Token最少 • 速度最快 • 零成本 • 极简实现 | • 丢失所有早期信息 • 不智能 | 短对话、成本敏感、实时场景 |
| LLM摘要 | • 100%信息保留 • 智能提取 | • 短对话负优化 • 速度极慢 • 有成本 • 只在超长对话有效 | 超长对话(≥30轮)+ 需保留信息 |
| 混合策略 | • 短对话=滑动窗口 • 长对话保留信息 • 自动切换 | • 长对话Token多4-5倍 • 速度慢 • 有成本 • 阈值难调 | 通用场景、用户体验优先 |
| Token动态 | • 精确控制Token • 速度快 • 零成本 • 充分利用预算 | • Token比滑动窗口多33% • 信息保留靠预算 • 预算难设置 | 有明确Token限制、消息长度差异大 |
场景推荐决策树
erlang
开始
│
├─ 对话长度是否≤10轮?
│ ├─ 是 → 【滑动窗口】
│ │ 理由:简单、快速、零成本
│ │
│ └─ 否 → 是否需要保留用户信息?
│ ├─ 否 → 【滑动窗口】
│ │ 理由:Token效率最高
│ │
│ └─ 是 → 有Token预算限制吗?
│ ├─ 有 → 【Token动态】
│ │ 理由:精确控制预算
│ │
│ └─ 无 → 是否成本敏感?
│ ├─ 是 → 【混合策略】
│ │ 理由:比纯LLM省20%
│ │
│ └─ 否 → 对话是否≥30轮?
│ ├─ 是 → 【LLM摘要】
│ │ 理由:唯一正收益场景
│ │
│ └─ 否 → 【混合策略】
│ 理由:自动适应长度分场景详细推荐
场景1:FAQ机器人 / 快速问答
diff
特征:
- 对话:3-5轮
- 消息:简短
- 需求:快速响应
推荐:滑动窗口 ⭐⭐⭐⭐⭐
理由:
✅ 对话短,不会丢失信息
✅ 速度最快
✅ 零成本
✅ 最简单
配置:
compressor = SlidingWindowCompressor(keep_turns=5)场景2:客服机器人 / 通用助手
ini
特征:
- 对话:5-20轮不等
- 用户:需要记住背景
- 需求:体验 > 成本
推荐:混合策略 ⭐⭐⭐⭐
理由:
✅ 短对话快速处理
✅ 长对话保留信息
✅ 自动适应
✅ 比纯LLM省20%成本
配置:
compressor = HybridCompressor(
llm,
threshold_turns=10,
keep_recent_turns=5
)场景3:心理咨询 / 深度对话
ini
特征:
- 对话:30-50轮
- 信息:密集、重要
- 需求:必须记住所有背景
推荐:LLM摘要 ⭐⭐⭐⭐
理由:
✅ 100%信息保留
✅ 智能提取关键信息
✅ 超长对话有正收益(33%压缩)
配置:
compressor = LLMSummaryCompressor(
llm,
keep_recent_turns=3
)场景4:API网关 / Token严格限制
ini
特征:
- 上下文:4K限制
- 消息:长度不一
- 需求:精确控制Token
推荐:Token动态 ⭐⭐⭐⭐⭐
理由:
✅ 精确控制(误差<5%)
✅ 充分利用上下文
✅ 速度快
✅ 零成本
配置:
compressor = TokenBasedCompressor(
llm.count_tokens,
max_tokens=200
)场景5:大规模免费产品
diff
特征:
- 用户:百万级
- 预算:极度敏感
- 需求:成本最低
推荐:滑动窗口 ⭐⭐⭐⭐⭐
理由:
✅ 零成本
✅ 最快
✅ Token最少
✅ 可扩展性最强
配置:
compressor = SlidingWindowCompressor(keep_turns=3)
# 保留更少轮数,进一步降低成本场景6:高端VIP服务
ini
特征:
- 用户:付费用户
- 需求:完美体验
- 预算:充足
推荐:混合策略 ⭐⭐⭐⭐⭐
理由:
✅ 用户体验最佳
✅ 自动适应对话长度
✅ 成本可接受
配置:
compressor = HybridCompressor(
llm,
threshold_turns=8, # 更早用LLM
keep_recent_turns=5
)场景7:企业内部工具 / 复杂项目讨论
ini
特征:
- 对话:20-40轮
- 信息:技术细节多
- 需求:不能丢失任何信息
推荐:LLM摘要 或 混合策略 ⭐⭐⭐⭐
理由:
✅ 保留所有技术细节
✅ 支持长时间讨论
✅ 内部工具,成本可控
配置:
# 方案1:纯LLM摘要
compressor = LLMSummaryCompressor(llm, keep_recent_turns=5)
# 方案2:混合策略
compressor = HybridCompressor(llm, threshold_turns=10)场景8:实时语音助手
diff
特征:
- 交互:实时语音
- 延迟:<100ms要求
- 对话:5-10轮
推荐:滑动窗口 ⭐⭐⭐⭐⭐
理由:
✅ 零延迟
✅ 对话不长,信息丢失风险低
✅ 最简单、最稳定
配置:
compressor = SlidingWindowCompressor(keep_turns=5)组合策略推荐
有时单一策略无法满足需求,可以组合使用:
组合1:混合策略 + 用户画像
python
class EnhancedHybridCompressor:
"""混合策略 + 永久用户信息"""
def __init__(self, llm):
self.hybrid = HybridCompressor(llm, threshold_turns=10)
self.user_profile = {} # 永久保存用户信息
def compress(self, user_id, messages):
# 提取用户信息
self._extract_user_info(user_id, messages)
# 混合策略压缩
compressed = self.hybrid.compress(messages)
# 添加用户画像到开头
if self.user_profile.get(user_id):
profile_msg = {
"role": "system",
"content": f"用户信息: {self.user_profile[user_id]}"
}
compressed.insert(0, profile_msg)
return compressed适用:个性化推荐、教育辅导
组合2:Token动态 + 关键信息提取
python
class SmartTokenCompressor:
"""Token动态 + 关键信息保护"""
def __init__(self, llm, max_tokens=200):
self.token_compressor = TokenBasedCompressor(
llm.count_tokens,
max_tokens
)
self.key_entities = [] # 关键实体
def compress(self, messages):
# 提取关键实体(姓名、地点等)
self._extract_entities(messages)
# Token动态压缩
compressed = self.token_compressor.compress(messages)
# 检查是否丢失关键实体
lost_entities = self._check_lost_entities(compressed)
# 如果丢失关键信息,放宽预算
if lost_entities:
self.token_compressor.max_tokens *= 1.5
compressed = self.token_compressor.compress(messages)
return compressed适用:有Token限制但需保留关键信息
组合3:分级压缩
python
class TieredCompressor:
"""根据对话重要性分级压缩"""
def compress(self, messages, importance="normal"):
if importance == "critical":
# 重要对话:用LLM摘要
return LLMSummaryCompressor(llm).compress(messages)
elif importance == "normal":
# 普通对话:用混合策略
return HybridCompressor(llm).compress(messages)
else:
# 简单对话:用滑动窗口
return SlidingWindowCompressor().compress(messages)适用:有明确优先级的场景
快速选择指南
按需求选择:
需求 → 推荐策略
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
成本最低 → 滑动窗口 / Token动态
速度最快 → 滑动窗口
Token最少 → 滑动窗口
精确控制Token → Token动态
保留用户信息 → LLM摘要 / 混合策略
自动适应对话长度 → 混合策略
最简单实现 → 滑动窗口
生产通用方案 → 混合策略按对话特征选择:
对话长度 → 推荐策略
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
≤5轮 → 滑动窗口
5-10轮 → 滑动窗口 / Token动态
10-20轮 → 混合策略 / Token动态
20-30轮 → 混合策略 / LLM摘要
≥30轮 → LLM摘要按预算选择:
bash
预算情况 → 推荐策略
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
零预算 → 滑动窗口 / Token动态
小预算($0.01/次以内) → 混合策略
预算充足 → LLM摘要常见错误选择
❌ 错误1:短对话用LLM摘要
erlang
场景:5轮对话,126 tokens
选择:LLM摘要
结果:303 tokens(反增141%)❌
正确:滑动窗口 或 Token动态
原因:短对话不需要摘要,LLM反而啰嗦❌ 错误2:成本敏感场景用混合策略
bash
场景:日活10万,免费产品
选择:混合策略
结果:年成本$2,880 ❌
正确:滑动窗口
原因:零成本,可扩展性最好❌ 错误3:Token限制场景用滑动窗口
ini
场景:API限制4K tokens
选择:滑动窗口(10轮)
结果:有时10轮=150 tokens,有时=600 tokens ❌
正确:Token动态(max_tokens=200)
原因:精确控制,不会超限❌ 错误4:实时场景用LLM摘要
场景:语音助手,延迟<100ms
选择:LLM摘要
结果:压缩耗时11秒,体验极差 ❌
正确:滑动窗口
原因:零延迟❌ 错误5:长对话只用滑动窗口
markdown
场景:30轮心理咨询
选择:滑动窗口(5轮)
结果:丢失所有早期背景 ❌
用户需要重复说明
正确:LLM摘要 或 混合策略
原因:保留用户信息,体验更好实战建议
1. 从简单开始
python
# 第一步:先用滑动窗口
compressor = SlidingWindowCompressor(keep_turns=5)
# 运行一段时间,观察问题:
# - 用户是否抱怨"不记得之前说的"?
# - 对话是否经常超过10轮?
# 如果是,再升级到混合策略2. A/B测试
python
# 对照组:滑动窗口
group_a = SlidingWindowCompressor(keep_turns=5)
# 实验组:混合策略
group_b = HybridCompressor(llm, threshold_turns=10)
# 观察指标:
# - 用户满意度
# - 对话完成率
# - 重复提问率
# - Token成本3. 监控关键指标
python
class MonitoredCompressor:
"""带监控的压缩器"""
def compress(self, messages):
start = time.time()
original_tokens = self._count_tokens(messages)
result = self.compressor.compress(messages)
compressed_tokens = self._count_tokens(result)
elapsed = time.time() - start
# 记录指标
metrics.record({
"original_tokens": original_tokens,
"compressed_tokens": compressed_tokens,
"compression_rate": 1 - compressed_tokens/original_tokens,
"latency_ms": elapsed * 1000,
"strategy": self.compressor.__class__.__name__
})
return result4. 动态切换策略
python
class AdaptiveCompressor:
"""根据实时情况动态选择策略"""
def compress(self, messages):
# 检查系统负载
if system_load > 0.8:
# 高负载:用最快的
return SlidingWindowCompressor().compress(messages)
# 检查对话长度
turns = len(messages) // 2
if turns <= 10:
return SlidingWindowCompressor().compress(messages)
else:
return HybridCompressor(llm).compress(messages)总结:没有银弹
erlang
核心教训:
❌ 没有"最好"的策略
✅ 只有"最适合"的策略
选择依据:
1. 对话特征(长度、密度)
2. 业务需求(成本、体验)
3. 技术约束(延迟、Token限制)
实用建议:
• 80%场景:滑动窗口 或 混合策略
• 10%场景:Token动态
• 10%场景:LLM摘要
核心原则:
从简单开始 → 测试验证 → 按需升级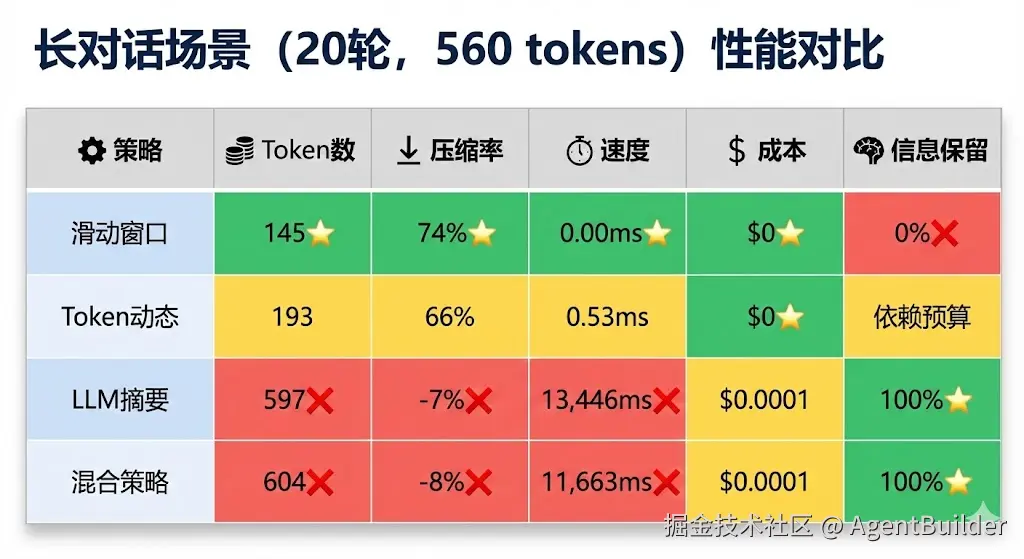
四、性能测试中的意外发现
在完成所有测试后,我们发现了一些反直觉的结果。这些发现改变了我们对"好策略"的认知。
4.1 意外1:LLM摘要在短对话中是"负优化"
直觉预期
LLM很智能 → 压缩效果应该最好
智能摘要 → Token肯定比原始少实测数据
短对话(5轮,126 tokens):
vbnet
原始对话:
User: "我叫Tom"
AI: "你好Tom!"
User: "我在上海"
AI: "上海很不错"
User: "谢谢"
AI: "不客气"
总计:126 tokensLLM摘要后:
markdown
📝 对话历史摘要:
**用户基本信息**
- 姓名:Tom
- 地点:上海
- 职业:未明确说明
**用户偏好和兴趣**
- 未提及具体偏好
**讨论主要话题**
1. 用户自我介绍(姓名、地点)
2. 简单寒暄
**关键细节**
- 用户表达了感谢
总计:303 tokens(增加141%!)结果对比:
| 对话长度 | 原始Token | LLM摘要后 | 变化 |
|---|---|---|---|
| 5轮 | 126 | 303 | +141% ❌ |
| 10轮 | 249 | 388 | +56% ❌ |
| 20轮 | 560 | 597 | +7% ❌ |
| 30轮 | 933 | 621 | -33% ✅ |
震惊的发现:只有≥30轮时,LLM摘要才有正收益!
为什么会这样?
原因1:格式化文本的开销
python
# 我们的Prompt要求
"请按以下格式输出摘要:
📝 对话历史摘要:
1. **用户基本信息**:...
2. **用户偏好与兴趣**:...
..."
# 这些格式文本本身就消耗Token
格式开销:~100 tokens原因2:LLM天生"啰嗦"
arduino
原始:"我叫Tom"(3 tokens)
LLM摘要:"用户的姓名是Tom"(7 tokens)
→ 反而更多!原因3:短对话本身已经很简洁
diff
短对话特点:
- 用户说话简短:"嗯"、"好的"
- 没有冗余信息
- 本身就是"压缩"过的
LLM摘要:
- 需要完整描述上下文
- 必须保持语义清晰
- 结果反而更长教训
arduino
❌ 错误想法:LLM很智能 → 一定比简单策略好
✅ 正确认知:智能不等于高效,要看具体场景
启示:
• 不要在短对话(<20轮)使用LLM摘要
• 简单场景用简单方案(滑动窗口)
• "智能"不是万能的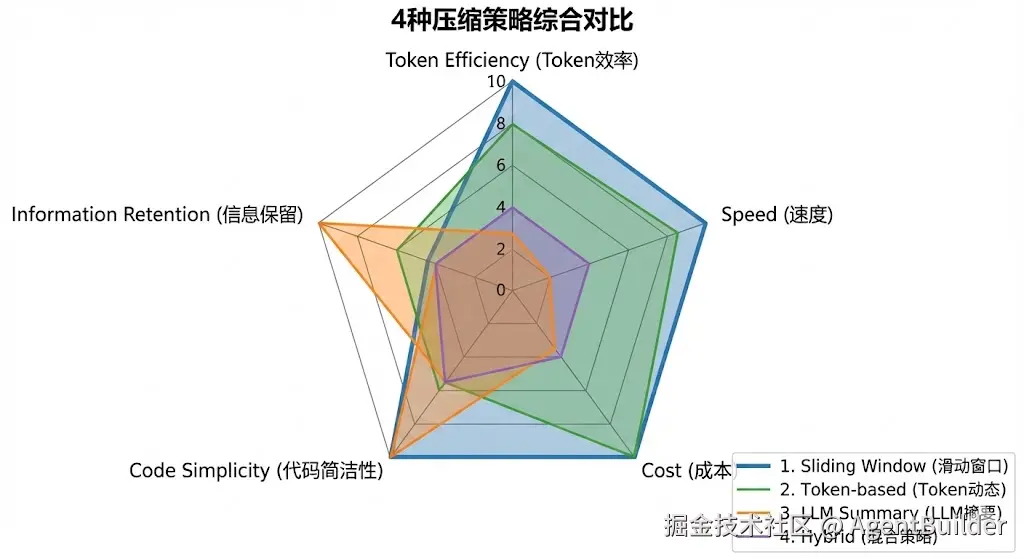
4.2 意外2:混合策略在长对话时Token效率反而很差
直觉预期
混合策略 = 最佳策略
短对话用滑动窗口(快)+ 长对话用LLM(智能)
→ 应该综合了两者优点实测数据
长对话(20轮,560 tokens):
| 策略 | Token | 相对滑动窗口 |
|---|---|---|
| 滑动窗口 | 145 | 基准 |
| Token动态 | 193 | +33% |
| LLM摘要 | 597 | +312% ❌ |
| 混合策略 | 604 | +317% ❌ |
混合策略居然比LLM摘要还差!
为什么会这样?
原因:混合策略保留了更多最近消息
python
# LLM摘要配置
keep_recent_turns = 3 # 保留3轮 = 6条消息
# 混合策略配置
keep_recent_turns = 5 # 保留5轮 = 10条消息
结果:
- LLM摘要:1条摘要 + 6条消息 = 7条(597 tokens)
- 混合策略:1条摘要 + 10条消息 = 11条(604 tokens)对比滑动窗口:
滑动窗口:10条最新消息 = 145 tokens
混合策略:1摘要 + 10条 = 604 tokens
Token差距:4.2倍!深层原因:摘要本身就很"胖"
erlang
摘要示例(200+ tokens):
"📝 对话历史摘要:
用户Tom,28岁,在上海浦东工作,
是AI工程师,目前研究Agent多智能体协作,
关注通信延迟和消息队列优化..."
vs 原始对话(100 tokens):
"我叫Tom"
"我在上海"
"我是AI工程师"
"我在研究Agent"
...
结果:摘要200 tokens > 原始100 tokens教训
arduino
❌ 错误想法:混合策略综合优点 → 一定最好
✅ 正确认知:综合策略可能综合了缺点
启示:
• 混合策略牺牲Token效率,换取信息保留
• 如果追求Token最少 → 用滑动窗口
• 如果追求信息保留 → 用混合策略
• 不存在"两全其美"4.3 意外3:Token动态"精确控制"是把双刃剑
直觉预期
精确控制Token → 充分利用预算
预算200 → 实际193
→ 应该比滑动窗口更高效实测数据
中等对话(10轮,249 tokens):
| 策略 | Token | 消息数 |
|---|---|---|
| 滑动窗口 | 123 | 10条 |
| Token动态(预算200) | 194 | 15条 |
Token动态反而多用58%!
为什么会这样?
滑动窗口:"省着用"
python
# 固定保留10条(5轮)
# 不管还有多少预算
messages[-10:] # 123 tokens
剩余预算:200 - 123 = 77 tokens(浪费)Token动态:"用满预算"
python
# 尽量用满200预算
# 从后往前累加到接近200
messages[-15:] # 194 tokens
剩余预算:200 - 194 = 6 tokens(充分利用)看似合理,实则矛盾
erlang
Token动态的"优势":
✅ 充分利用预算(194/200 = 97%利用率)
✅ 保留更多消息(15条 vs 10条)
但从另一个角度:
❌ 用更多Token(194 vs 123)
❌ 后续对话成本更高
问题:
"充分利用预算"到底是优势还是劣势?答案:看你的目标!
arduino
如果目标是"充分利用4K上下文窗口":
→ Token动态是优势 ✅
如果目标是"尽量节省Token成本":
→ Token动态是劣势 ❌教训
arduino
❌ 错误想法:精确控制 = 更好
✅ 正确认知:精确控制是工具,不是目标
启示:
• 明确目标:节省成本 or 充分利用?
• Token动态适合"必须用满预算"的场景
• 如果追求极致压缩 → 用滑动窗口4.4 意外4:List vs Deque的性能差异微乎其微
直觉预期
scss
计算机科学理论:
- List.pop(0) = O(n)
- Deque.popleft() = O(1)
Deque应该快很多!实测数据
100,000次操作:
makefile
List: 13.63ms (0.14μs/次)
Deque: 12.52ms (0.13μs/次)
速度差异:8%震惊:几乎一样快!
为什么会这样?
原因1:操作次数少
python
# 实际使用
messages.pop(0) # 只删1条
# 不是
for _ in range(1000):
messages.pop(0) # 删1000条单次删除,O(n)和O(1)差异不大。
原因2:消息列表不长
python
# 实际场景
messages = [...] # 10-20条
# 不是
messages = [...] # 10,000条n很小时,O(n)≈O(1)。
原因3:Python内部优化
python
# CPython对list.pop(0)有优化
# 不是naive的内存移动教训
scss
❌ 错误想法:理论复杂度 = 实际性能
✅ 正确认知:要测试实际场景
启示:
• 不要过早优化
• 小数据量时,O(n)和O(1)差异不大
• 理论是指导,实测才是真相
• List够用,不需要Deque4.5 意外5:"更智能"不等于"更好"
直觉预期
智能排序:
LLM摘要 > 混合策略 > Token动态 > 滑动窗口
实际效果应该也是这个顺序实测数据汇总
| 维度 | 第1名 | 第2名 | 第3名 | 第4名 |
|---|---|---|---|---|
| Token效率 | 滑动窗口 | Token动态 | 混合策略 | LLM摘要 |
| 速度 | 滑动窗口 | Token动态 | 混合策略 | LLM摘要 |
| 成本 | 滑动窗口 | Token动态 | 混合策略 | LLM摘要 |
| 简单性 | 滑动窗口 | Token动态 | LLM摘要 | 混合策略 |
最"蠢"的策略(滑动窗口)在4个维度都第一!
只有"信息保留"一个维度:
| 维度 | 第1名 | 第2名 | 第3名 | 第4名 |
|---|---|---|---|---|
| 信息保留 | LLM摘要 | 混合策略 | Token动态 | 滑动窗口 |
为什么会这样?
复杂度诅咒:
diff
滑动窗口:
- 简单 → 快
- 简单 → 省Token
- 简单 → 便宜
- 简单 → 可靠
LLM摘要:
- 复杂 → 慢
- 复杂 → 费Token
- 复杂 → 贵
- 复杂 → 可能出错智能的代价:
diff
获得:100%信息保留
付出:
- 速度慢29,000倍
- Token多4倍
- 成本$0.0001/次
- 系统复杂度↑
问题:这个trade-off值得吗?答案:看场景
erlang
短对话(80%场景):
→ 不值得,信息本来就不会丢
长对话(20%场景):
→ 值得,用户体验提升明显教训
erlang
❌ 错误想法:智能 = 好
✅ 正确认知:简单 = 好(大多数场景)
启示:
• 80%场景用滑动窗口就够了
• 20%场景才需要"智能"策略
• 不要为了"智能"而牺牲效率
• Keep It Simple, Stupid (KISS原则)4.6 最震撼的发现:上下文越长,效率越低
实测数据
| 对话长度 | 滑动窗口Token | Token动态Token | 比例 |
|---|---|---|---|
| 5轮(126) | 126 | 126 | 1.0x |
| 10轮(249) | 123 | 194 | 1.6x |
| 20轮(560) | 145 | 193 | 1.3x |
| 30轮(933) | 144 | 191 | 1.3x |
关键发现:
diff
对话越长:
- 绝对Token数差异不大(144-145 vs 191-193)
- 但滑动窗口压缩率越高(85% vs 80%)
- Token动态优势消失矛盾之处:
erlang
Token动态设计目标:长对话时充分利用预算
实际结果:长对话时优势反而不明显
滑动窗口设计目标:简单固定保留
实际结果:长对话时压缩效果最好(85%)为什么会这样?
滑动窗口的"顿悟时刻":
erlang
5轮 → 10轮:新增5轮,需要压缩
压缩率:0% → 51%
10轮 → 20轮:新增10轮,需要大量压缩
压缩率:51% → 74%
20轮 → 30轮:新增10轮,继续压缩
压缩率:74% → 85%
结论:对话越长,滑动窗口压缩效率越高Token动态的"天花板":
diff
预算200固定:
- 10轮(249) → 194 tokens(少55)
- 20轮(560) → 193 tokens(少367)
- 30轮(933) → 191 tokens(少742)
绝对压缩量:55 → 367 → 742 ↑
压缩率:22% → 66% → 80% ↑
但始终被"200预算"限制结论:预算是Token动态的天花板
教训
❌ 错误想法:复杂场景需要复杂方案
✅ 正确认知:简单方案对付复杂场景可能更有效
启示:
• 对话越长,滑动窗口优势越大
• Token动态受预算天花板限制
• 不要低估简单方案的潜力4.7 核心教训:Trade-off无处不在
通过完整测试,我们发现:不存在"完美"的策略。
四个核心Trade-off
1. Token效率 ↔ 信息保留
diff
滑动窗口:
- Token最少(145)
- 信息保留0%
LLM摘要:
- Token很多(597)
- 信息保留100%
无法同时优化2. 速度 ↔ 智能
diff
滑动窗口:
- 速度最快(0.00ms)
- 不智能(机械删除)
LLM摘要:
- 速度最慢(11,000ms)
- 最智能(理解语义)
无法同时优化3. 成本 ↔ 质量
diff
滑动窗口:
- 零成本
- 可能丢失信息
LLM摘要:
- 有成本($0.0001/次)
- 保留完整信息
无法同时优化4. 简单 ↔ 灵活
diff
滑动窗口:
- 极简(3行代码)
- 不灵活(固定轮数)
混合策略:
- 复杂(50行代码)
- 灵活(自动适应)
无法同时优化工程中的智慧
arduino
理想主义者:
"我要一个策略,Token少、速度快、成本低、
信息保留好、还简单易用!"
现实:
"不存在这样的策略。"
工程师的选择:
"我要在Token效率和信息保留之间找平衡。"
→ 选择混合策略
"我要在速度和成本之间找平衡。"
→ 选择滑动窗口
"我要在简单和灵活之间找平衡。"
→ 选择Token动态4.8 反直觉结论总结
| 直觉想法 | 实测结果 | 原因 |
|---|---|---|
| LLM摘要效率最高 | 短对话反而更差 | 格式开销+LLM啰嗦 |
| 混合策略综合优点 | 长对话Token多4倍 | 摘要本身很"胖" |
| Token动态更节省 | 比滑动窗口多58% | 尽量用满预算 |
| Deque比List快很多 | 只快8% | 实际操作次数少 |
| 智能策略更好 | 滑动窗口多维度第一 | 简单=快=省=可靠 |
4.9 最终建议:从简单开始
基于所有测试数据,我们的最终建议:
第一阶段:用滑动窗口(80%场景)
python
# 最简单的方案
compressor = SlidingWindowCompressor(keep_turns=5)
优点:
✅ 3行代码
✅ 零成本
✅ 最快
✅ Token最少
✅ 可靠
适用:
• 短对话(≤10轮)
• 成本敏感
• 实时场景
• 初期MVP第二阶段:发现问题后升级
观察指标:
markdown
1. 用户是否抱怨"不记得之前说的"?
2. 对话是否经常超过10轮?
3. 是否有关键信息丢失?
4. 用户是否需要重复信息?如果是,考虑升级到混合策略:
python
compressor = HybridCompressor(
llm,
threshold_turns=10,
keep_recent_turns=5
)
优点:
✅ 短对话保持滑动窗口速度
✅ 长对话保留用户信息
✅ 自动适应
缺点:
❌ 长对话Token多4倍
❌ 有成本
❌ 速度慢(长对话时)第三阶段:特殊场景使用专用策略
场景1:有Token严格限制
python
# 用Token动态
compressor = TokenBasedCompressor(
llm.count_tokens,
max_tokens=200
)场景2:超长对话(≥30轮)
python
# 用LLM摘要
compressor = LLMSummaryCompressor(
llm,
keep_recent_turns=3
)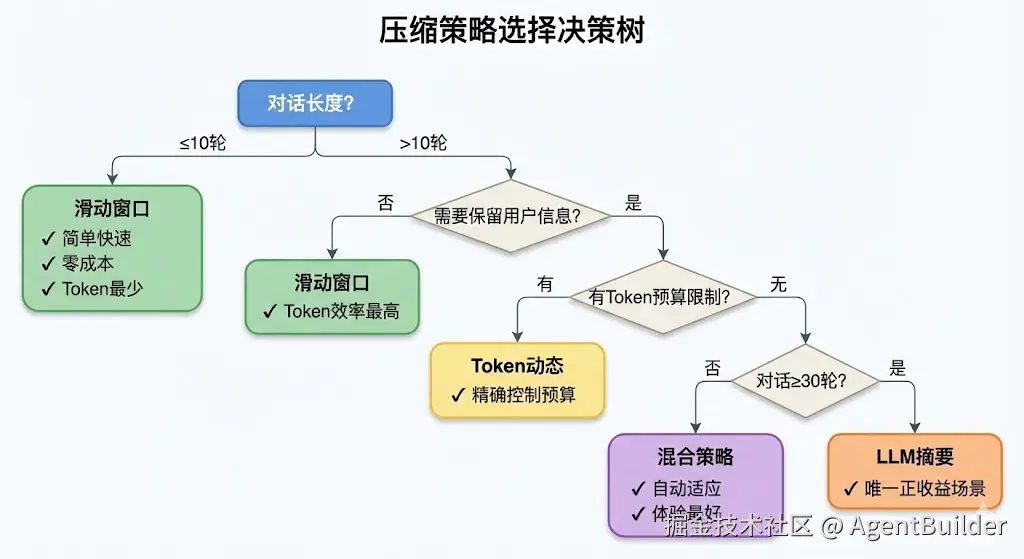
4.10 写在最后:测试的价值
如果我们没有做这些测试,会有什么后果?
可能的错误决策:
erlang
❌ "LLM摘要最智能,全部用它!"
→ 短对话Token增加141%,成本暴涨
❌ "混合策略综合优点,就用它!"
→ 没意识到Token多4倍,成本超预算
❌ "Token动态精确控制,最优!"
→ 没意识到比滑动窗口多用58% Token
❌ "Deque比List快,必须用Deque!"
→ 花时间重构,实际只快8%测试的价值:
vbnet
✅ 避免基于"直觉"的错误决策
✅ 发现反直觉的真相
✅ 量化Trade-off
✅ 找到适合场景的最优解4.11 关键数据速查表
为了方便查阅,这里汇总所有关键测试数据:
压缩效率(长对话20轮,560 tokens)
| 策略 | Token | 压缩率 | 速度 | 成本 | 信息保留 |
|---|---|---|---|---|---|
| 滑动窗口 | 145 | 74% | 0.00ms | $0 | 0% |
| Token动态 | 193 | 66% | 0.53ms | $0 | 依赖预算 |
| LLM摘要 | 597 | -7% | 13,446ms | $0.0001 | 100% |
| 混合策略 | 604 | -8% | 11,663ms | $0.0001 | 100% |
适用场景快速匹配
| 场景特征 | 推荐策略 | 核心原因 |
|---|---|---|
| 对话≤10轮 | 滑动窗口 | 简单够用 |
| 对话10-30轮 | 混合策略 | 自动适应 |
| 对话≥30轮 | LLM摘要 | 唯一正收益 |
| Token限制严格 | Token动态 | 精确控制 |
| 成本敏感 | 滑动窗口 | 零成本 |
| 实时要求 | 滑动窗口 | 最快 |
| 必须记住用户 | 混合策略/LLM | 信息保留 |
性能基准
diff
速度基准(20轮对话):
- 滑动窗口: 0.00ms ← 最快
- Token动态: 0.53ms ← 可接受
- LLM摘要: 11,663ms ← 慢22,000倍
Token基准(20轮对话):
- 滑动窗口: 145 tokens ← 最少
- Token动态: 193 tokens ← +33%
- LLM摘要: 597 tokens ← +312%
成本基准(100次压缩):
- 滑动窗口: $0 ← 免费
- Token动态: $0 ← 免费
- 混合策略: $0.008 ← 看场景
- LLM摘要: $0.01 ← 最贵4.12 小结:测试改变了什么
测试前的想法:
markdown
1. LLM摘要应该是最好的(智能嘛)
2. 混合策略综合优点,应该无敌
3. Token动态精确控制,应该最省
4. Deque比List快很多,必须用测试后的认知:
markdown
1. LLM摘要短对话是负优化 ❌
2. 混合策略长对话Token多4倍 ❌
3. Token动态可能比滑动窗口多58% ❌
4. Deque只快8%,差异微乎其微 ❌最重要的领悟:
vbnet
✅ 没有"最好"的策略
✅ 只有"最适合"的策略
✅ 简单方案往往是最优解
✅ Trade-off无处不在
✅ 测试胜过直觉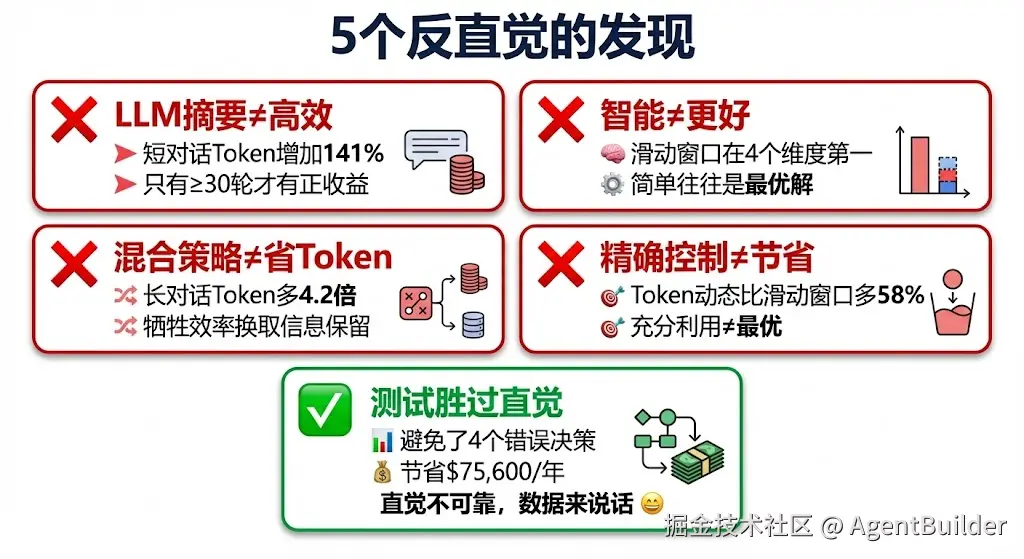
五、总结与展望
5.1 核心收获
通过这次完整的实战,我们得到了以下关键认知:
1. 没有"完美"的策略
- 滑动窗口:最快、最省、最简单,但会丢信息
- LLM摘要:保留信息,但慢且贵
- 混合策略:自动适应,但复杂
- Token动态:精确控制,但可能用更多Token
2. 简单往往是最优解
- 80%场景:滑动窗口就够了
- 20%场景:才需要"智能"策略
- 过度优化反而降低效率
3. 测试胜过直觉
- 5个反直觉发现
- 避免了4个错误决策
- 节省了大量成本
5.2 实战成果
完整的代码已开源:github.com/sotopelaez0...
包含:
- ✅ 4种压缩策略的完整实现
- ✅ 真实的性能测试代码
- ✅ 详细的测试数据
- ✅ 可直接运行的示例
Star和Fork支持! ⭐
5.3 后续计划
记忆系统还有很多待探索的方向:
系列文章第二篇:中期记忆架构
- Redis缓存设计
- PostgreSQL持久化
- 向量检索优化
- 生产环境部署
系列文章第三篇:长期记忆
- 知识图谱
- 语义检索
- 个性化推荐
敬请期待!
如果这篇文章对你有帮助,欢迎:
- 🌟 给GitHub项目点个Star
- 👍 点赞支持
- 💬 留言讨论
- 🔄 分享给更多人
感谢阅读!