项目场景
Geoserver环境迁移遇到的问题:SLD样式内的中文乱码,不是地图服务显示中文乱码
小编写文章之前必须先吐槽一下,国产化的坑,在进行数据迁移的时候遇到的坑真的是防不胜防。我们需要部署一一套地理服务系统,原始的龙蜥(Anolis OS)系统下线,申请的信创服务器还在走流程,我需要将龙蜥系统上的geoserver先部署到本地windows sever 2019 standard服务器上,用于本地的开发测试。现在服务器下来了,又得迁移到新的麒麟(Kylin v10)服务器上,我刚把样式的问题改完了,迁移过来又是一堆乱码,我真的是头大了。今天我把遇到问题的过程,原因及解答方法记录一下,分享出来希望可以帮到大家。
太难了...我的头发...


环境描述
- Anolis OS release 7.9(x86_64)
- Windows sever 2019 standard(x86_64)
- Kylin V10 sp2 (c86-海光/aarch64)
- Geoserver 2.23.1
问题描述
迁移之前样式样式是正常的,从Anolis系统迁移到Windows系统后就变成这个样子了。
中文字体无法识别,显示乱码。
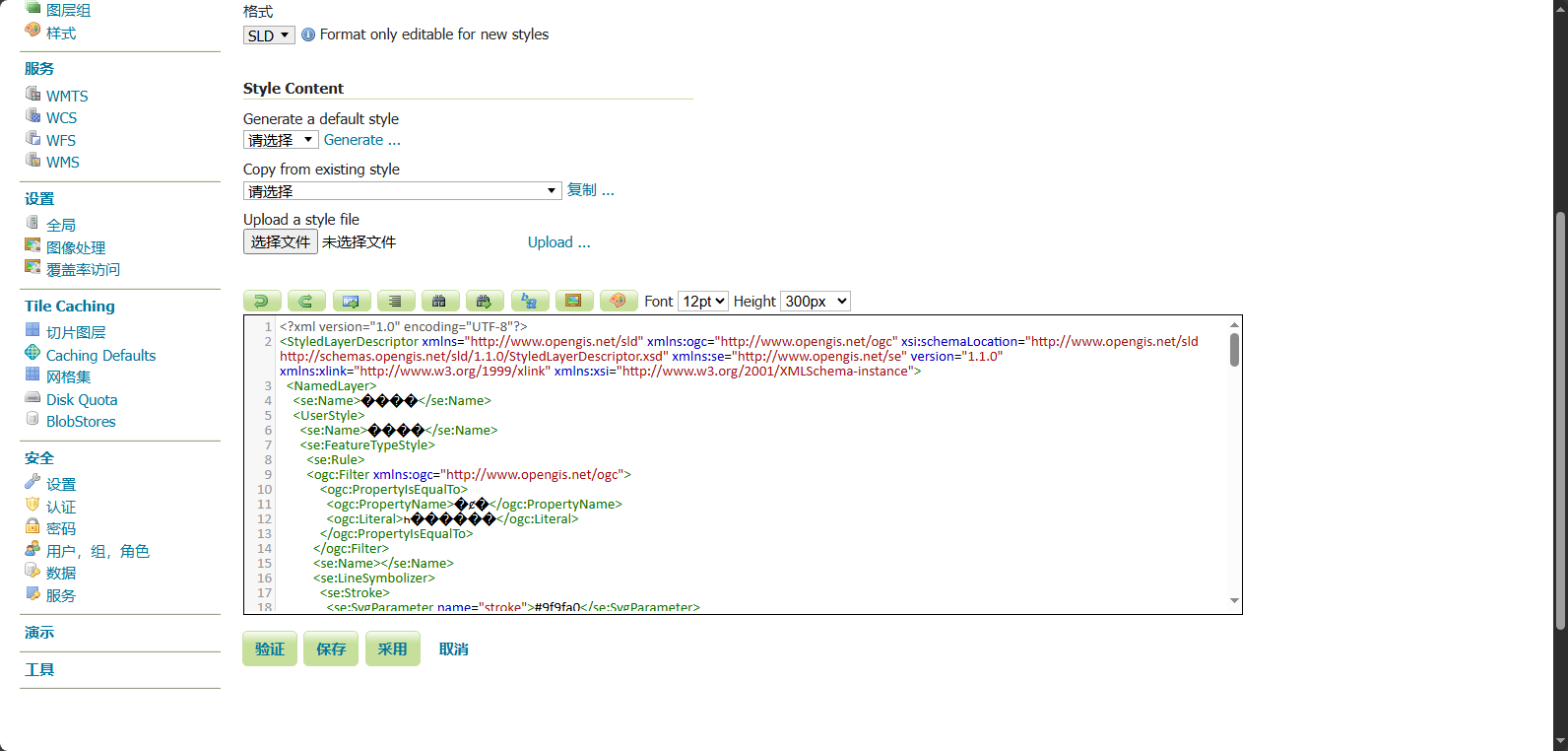
原因分析:
xml
<?xml version="1.0" encoding="UTF-8"?>SLD样式设置了UTF-8编码,依旧是乱码。经过我多天的研究,这个编码是控制样式在前端的编码,保证前端显示不乱码,而这个SLD乱码与系统对文件的编码有关系。于是我找到这个SLD文件,查看了一下这个文件的编码方式是ANSI,我修改了编码方式为UTF-8以后,替换SLD文件,结果成功了,无需重启服务。
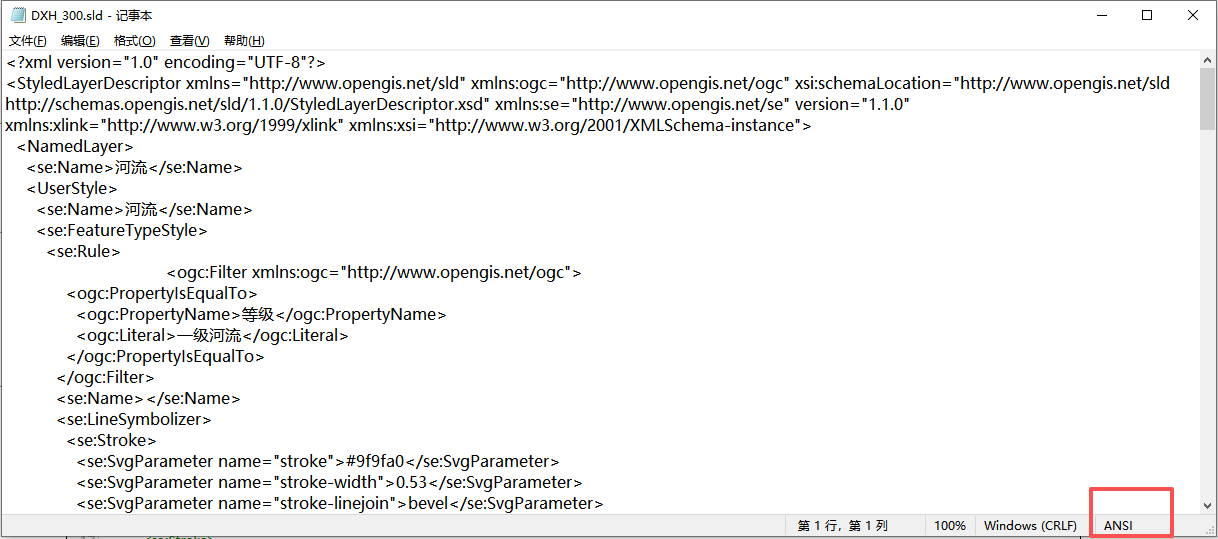
解决方案:
那问题来了,我有好几百个样式,刚开始没有找到问题的原因,我就一个一个的复制完成了,结果服务器下来了,又从Windows系统迁移到Kylin系统,又出现乱码了,耍猴呢???
下面我分享一下问题解决的方法:
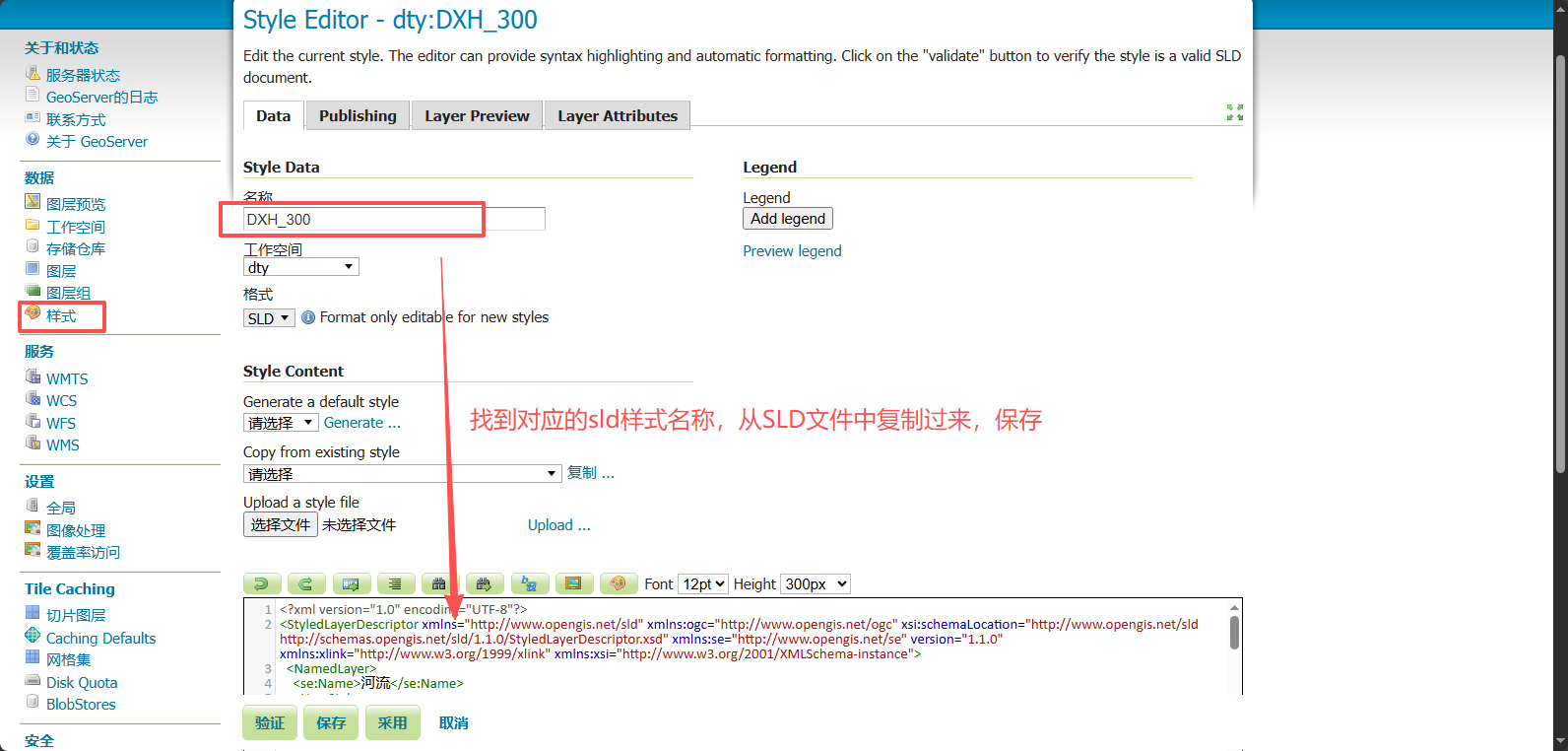
方法1:直接复制(限数量较少样式)
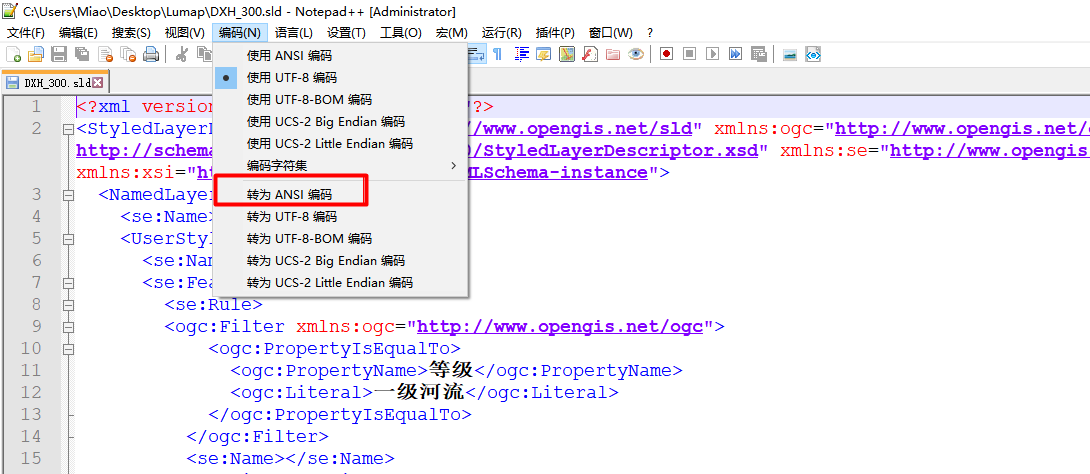
打开原始文件,一般是放置在 \data_dir\styles文件夹中,找到sld文件打开查看一下是否乱码,如果不乱码的话,找到如下界面,Style的样式管理器并重新复制粘贴代码,保存。如果是乱码的话,可以尝试将打开的文件(文本编辑器打开的话)另存为ANSI编码的sld文件;用Notepad++打开的话直接修改编码方式为ANSI保存,保存如下图所示。
方法2:使用python代码进行批处理,检查并修改样式的编码
【警告】一定要备份好源文件,批量修改不成功还可以恢复!!!
【警告】一定要备份好源文件,批量修改不成功还可以恢复!!!
【警告】一定要备份好源文件,批量修改不成功还可以恢复!!!这里我必须再吐槽一下,没有找到原因前,我竟然用笨办法(方法1)修改完了,那可是好几百个样式啊!!只要找到问题的原因就好说了,废话不多说了,上代码。
1.检查.sld样式文件的编码
python
#批量检测指定目录下所有 .sld 文件编码的代码,
#支持递归遍历子目录、结果汇总输出,同时保留原有的编码检测逻辑
import chardet
import os
from pathlib import Path
def detect_file_encoding(file_path):
"""
检测单个文件编码(支持大文件,按块读取)
:param file_path: 文件绝对/相对路径
:return: 编码名称、置信度
"""
# 校验文件是否存在
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在:{file_path}")
# 按块读取(避免大文件占用内存)
with open(file_path, 'rb') as f:
# 读取前10240字节(足够检测编码,可根据需要调整)
raw_data = f.read(10240)
# 检测编码
result = chardet.detect(raw_data)
encoding = result['encoding']
confidence = result['confidence'] # 置信度(0-1,越高越准确)
# 特殊处理:Windows 常见编码别名转换
if encoding == 'GB2312':
encoding = 'GBK' # GBK 是 GB2312 超集,Windows 中更常用
elif encoding is None:
encoding = '未知编码'
return encoding, confidence
def batch_detect_sld_encoding(root_dir, recursive=True):
"""
批量检测指定目录下的所有 .sld 文件编码
:param root_dir: 根目录路径
:param recursive: 是否递归遍历子目录(默认True)
:return: 检测结果字典 {文件路径: (编码, 置信度)}
"""
# 初始化结果字典
detect_result = {}
# 遍历目录下所有 .sld 文件
if recursive:
# 递归遍历所有子目录
sld_files = Path(root_dir).rglob("*.sld")
else:
# 仅遍历当前目录
sld_files = Path(root_dir).glob("*.sld")
for file_path in sld_files:
# 转换为字符串路径
file_path_str = str(file_path)
try:
encoding, confidence = detect_file_encoding(file_path_str)
detect_result[file_path_str] = (encoding, round(confidence, 2))
print(f"✅ 检测完成 | 文件:{file_path_str} | 编码:{encoding} | 置信度:{confidence:.2f}")
except Exception as e:
detect_result[file_path_str] = ("检测失败", 0.0)
print(f"❌ 检测失败 | 文件:{file_path_str} | 错误:{e}")
return detect_result
# 示例使用
if __name__ == "__main__":
# **************************
# 配置项:修改为你的根目录路径
# **************************
ROOT_DIR = r"X:\XXXX\data_dir\workspaces\dty\styles"
# 是否递归遍历子目录(True/False)
RECURSIVE = True
print(f"开始批量检测 .sld 文件编码,根目录:{ROOT_DIR}")
print("-" * 80)
# 执行批量检测
result = batch_detect_sld_encoding(ROOT_DIR, RECURSIVE)
print("-" * 80)
print("📊 批量检测结果汇总:")
print(f"总计检测文件数:{len(result)}")
# 统计各编码类型数量
encoding_stat = {}
for path, (encoding, _) in result.items():
encoding_stat[encoding] = encoding_stat.get(encoding, 0) + 1
print("编码类型分布:")
for encoding, count in encoding_stat.items():
print(f" {encoding}:{count} 个文件")
# 可选:将结果保存到文本文件
save_to_file = True
if save_to_file:
save_path = os.path.join(ROOT_DIR, "sld编码检测结果.txt")
with open(save_path, 'w', encoding='utf-8') as f:
f.write("SLD文件编码检测结果\n")
f.write("=" * 80 + "\n")
for file_path, (encoding, confidence) in result.items():
f.write(f"文件路径:{file_path}\n")
f.write(f"编码:{encoding} | 置信度:{confidence}\n")
f.write("-" * 80 + "\n")
print(f"\n📝 结果已保存到:{save_path}") 【注意】根据检查的结果做好分步转换,以下是我遇到的编码样式:
- GB2312
- GBK
- ascii
- utf-8
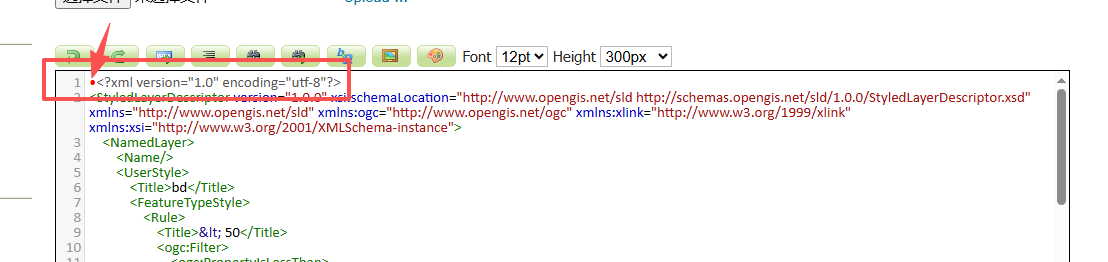
【注意】 在进行编码转换的时候,会遇到utf-8-sig 的样式,这是一种特殊的 UTF-8 编码格式,它在文件开头添加了一个字节顺序标记(BOM),可以帮助某些应用程序正确识别文件编码,但是在geoserver无法识别这种样式,还需要将这种样式转换为utf-8。下图为utf-8-sig文件开头部分特征,有个红点,如果涉及到中文,点击wmts样式会报错显示错误样式名称的。
以下是编码的样式的数量较少,我直接手动转换了,根据情况编写代码转换
- ISO-8859-1
- ISO-8859-8
- Windows-1253
- Windows-1252
2.批量修改.sld样式文件的编码
- 2.1将 UTF-8 编码的 .sld 文件转换为 GBK 编码并保存的功能代码。
功能包括编码转换、备份(可选)、异常处理等关键特性
python
import chardet
import os
import shutil
from pathlib import Path
def detect_file_encoding(file_path):
"""
检测单个文件编码(支持大文件,按块读取)
:param file_path: 文件绝对/相对路径
:return: 编码名称、置信度
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在:{file_path}")
with open(file_path, 'rb') as f:
raw_data = f.read(10240) # 读取前10240字节,平衡速度与准确性
result = chardet.detect(raw_data)
encoding = result['encoding']
confidence = result['confidence']
# 编码别名转换(适配Windows)
if encoding == 'GB2312':
encoding = 'GBK'
elif encoding is None:
encoding = '未知编码'
# 处理UTF-8 BOM情况
elif encoding.lower() == 'utf-8-sig':
encoding = 'UTF-8'
return encoding, confidence
def convert_utf8_to_gbk(file_path, backup=True):
"""
将 UTF-8 编码的文件转换为 GBK 编码并保存
:param file_path: 文件路径
:param backup: 是否备份原文件(默认True,备份文件后缀为 .bak)
:return: 转换结果(成功/失败)
"""
try:
# 1. 先读取原文件(UTF-8编码)
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 2. 备份原文件(可选)
if backup:
backup_path = f"{file_path}.bak"
# 避免覆盖已存在的备份
if not os.path.exists(backup_path):
shutil.copy2(file_path, backup_path)
# 3. 以GBK编码重新写入文件
with open(file_path, 'w', encoding='gbk', errors='replace') as f:
# errors='replace':替换无法编码的字符(避免中文乱码/报错)
f.write(content)
return f"成功(备份文件:{backup_path if backup else '无'})"
except UnicodeDecodeError:
return "失败:文件并非UTF-8编码,解码失败"
except Exception as e:
return f"失败:{str(e)}"
def batch_detect_and_convert_sld(root_dir, recursive=True, backup=True):
"""
批量检测 .sld 文件编码,并将 UTF-8 编码的文件转换为 GBK
:param root_dir: 根目录路径
:param recursive: 是否递归遍历子目录
:param backup: 是否备份原文件
:return: 检测+转换结果字典
"""
result_dict = {}
# 遍历所有.sld文件
sld_files = Path(root_dir).rglob("*.sld") if recursive else Path(root_dir).glob("*.sld")
print(f"开始批量检测并转换 .sld 文件编码(根目录:{root_dir})")
print("-" * 100)
for file_path in sld_files:
file_path_str = str(file_path)
try:
# 第一步:检测编码
encoding, confidence = detect_file_encoding(file_path_str)
result_dict[file_path_str] = {
"检测编码": encoding,
"置信度": round(confidence, 2),
"转换结果": "未转换"
}
# 第二步:如果是UTF-8编码,执行转换
if encoding.upper() == 'UTF-8':
convert_result = convert_utf8_to_gbk(file_path_str, backup)
result_dict[file_path_str]["转换结果"] = convert_result
print(f"🔄 {file_path_str} | 原编码:{encoding} | 置信度:{confidence:.2f} | 转换:{convert_result}")
else:
print(f"ℹ️ {file_path_str} | 编码:{encoding} | 置信度:{confidence:.2f} | 无需转换")
except Exception as e:
result_dict[file_path_str] = {
"检测编码": "检测失败",
"置信度": 0.0,
"转换结果": f"检测失败:{str(e)}"
}
print(f"❌ {file_path_str} | 检测失败:{str(e)}")
return result_dict
# 示例使用
if __name__ == "__main__":
# 配置项(根据需要修改)
ROOT_DIR = r"X:\XXXX\data_dir\workspaces\dty\styles"
RECURSIVE = True # 是否递归子目录
BACKUP_RAW_FILE = True # 是否备份原UTF-8文件
# 执行批量检测+转换
final_result = batch_detect_and_convert_sld(ROOT_DIR, RECURSIVE, BACKUP_RAW_FILE)
# 汇总结果
print("-" * 100)
print("📊 批量处理结果汇总:")
total = len(final_result)
converted = 0
failed = 0
not_utf8 = 0
for path, res in final_result.items():
if res["转换结果"].startswith("成功"):
converted += 1
elif res["转换结果"] == "未转换":
not_utf8 += 1
else:
failed += 1
print(f"总计检测文件数:{total}")
print(f"UTF-8转GBK成功:{converted} 个")
print(f"非UTF-8编码(无需转换):{not_utf8} 个")
print(f"检测/转换失败:{failed} 个")
# 可选:将结果保存到文件
save_path = os.path.join(ROOT_DIR, "sld编码转换结果.txt")
with open(save_path, 'w', encoding='utf-8') as f:
f.write("SLD文件编码检测+转换结果\n")
f.write("=" * 100 + "\n")
for file_path, res in final_result.items():
f.write(f"文件路径:{file_path}\n")
f.write(f"检测编码:{res['检测编码']} | 置信度:{res['置信度']}\n")
f.write(f"转换结果:{res['转换结果']}\n")
f.write("-" * 100 + "\n")
print(f"\n📝 详细结果已保存到:{save_path}")
if BACKUP_RAW_FILE:
print("⚠️ 提示:原UTF-8文件已备份(后缀为.bak),如需还原可直接重命名覆盖")
- 2.2将非 UTF-8 编码的 .sld 文件统一转换为 UTF-8 的功能
功能包括编码转换、备份(可选)、结果汇总
逻辑更通用且兼容各类 Windows 常见编码(GBK/GB2312/GB18030 等)
python
import chardet
import os
import shutil
from pathlib import Path
def detect_file_encoding(file_path):
"""
检测单个文件编码(支持大文件,按块读取)
:param file_path: 文件绝对/相对路径
:return: 编码名称、置信度
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在:{file_path}")
with open(file_path, 'rb') as f:
# 读取前10240字节(平衡速度与准确性,小文件可改为f.read())
raw_data = f.read(10240)
result = chardet.detect(raw_data)
encoding = result['encoding']
confidence = result['confidence']
# 编码别名统一(适配Windows常见编码)
if encoding in ['GB2312', 'GB18030']:
encoding = 'GBK' # GBK是WindowsANSI默认,兼容GB2312/GB18030
elif encoding is None:
encoding = '未知编码'
elif encoding.lower() == 'utf-8-sig':
encoding = 'UTF-8' # 统一UTF-8 BOM和无BOM标识
return encoding, confidence
def convert_to_utf8(file_path, src_encoding, backup=True):
"""
将指定编码的文件转换为 UTF-8 编码并保存(带BOM,兼容Windows)
:param file_path: 文件路径
:param src_encoding: 原文件编码(由detect_file_encoding检测得出)
:param backup: 是否备份原文件(默认True,后缀为.bak)
:return: 转换结果字符串
"""
try:
# 1. 读取原文件(使用检测到的编码)
with open(file_path, 'r', encoding=src_encoding, errors='replace') as f:
content = f.read()
# 2. 备份原文件(避免覆盖,防止转换失败)
if backup:
backup_path = f"{file_path}.bak"
if not os.path.exists(backup_path):
shutil.copy2(file_path, backup_path)
# 3. 以UTF-8编码写入
with open(file_path, 'w', encoding='utf-8', errors='replace') as f:
f.write(content)
return f"成功(原编码:{src_encoding} | 备份文件:{backup_path if backup else '无'})"
except UnicodeDecodeError:
return f"失败:原编码{src_encoding}解码错误,无法读取文件内容"
except PermissionError:
return "失败:文件权限不足(建议以管理员身份运行)"
except Exception as e:
return f"失败:{str(e)}"
def batch_detect_and_convert_sld(root_dir, recursive=True, backup=True):
"""
批量检测.sld文件编码,将非UTF-8编码的文件统一转换为UTF-8
:param root_dir: 根目录路径
:param recursive: 是否递归遍历子目录(默认True)
:param backup: 是否备份原文件(默认True)
:return: 处理结果字典 {文件路径: {检测编码, 置信度, 转换结果}}
"""
result_dict = {}
# 遍历所有.sld文件(递归/非递归)
sld_files = Path(root_dir).rglob("*.sld") if recursive else Path(root_dir).glob("*.sld")
print(f"开始批量处理.sld文件(根目录:{root_dir})")
print("=" * 120)
print(f"{'文件路径':<80} | {'检测编码':<10} | {'置信度':<6} | 转换结果")
print("-" * 120)
for file_path in sld_files:
file_path_str = str(file_path)
try:
# 步骤1:检测文件编码
encoding, confidence = detect_file_encoding(file_path_str)
result_dict[file_path_str] = {
"检测编码": encoding,
"置信度": round(confidence, 2),
"转换结果": "无需转换"
}
# 步骤2:非UTF-8编码则转换为UTF-8
if encoding.upper() != 'UTF-8' and encoding != '未知编码':
convert_result = convert_to_utf8(file_path_str, encoding, backup)
result_dict[file_path_str]["转换结果"] = convert_result
print(f"🔄{file_path_str:<80} | {encoding:<10} | {confidence:.2f} | {convert_result}")
elif encoding == 'UTF-8':
# UTF-8编码无需转换
print(f"⏭️{file_path_str:<80} | {encoding:<10} | {confidence:.2f} | 无需转换(已是UTF-8)")
else:
# 未知编码跳过转换
result_dict[file_path_str]["转换结果"] = "跳过(未知编码,无法转换)"
print(f"⏭️{file_path_str:<80} | {encoding:<10} | {confidence:.2f} | 跳过(未知编码)")
except Exception as e:
# 捕获检测阶段的异常(文件不存在/权限问题等)
result_dict[file_path_str] = {
"检测编码": "检测失败",
"置信度": 0.0,
"转换结果": f"检测失败:{str(e)}"
}
print(f"{file_path_str:<80} | 检测失败 | 0.00 | {e}")
return result_dict
# 主程序入口
if __name__ == "__main__":
# **************************
# 配置项(根据需求修改)
# **************************
ROOT_DIR = r"C:\Users\Miao\Desktop\Desktemp\temp\styles2"
RECURSIVE = True # 是否递归遍历子目录(True/False)
BACKUP_RAW_FILE = True # 是否备份原文件(建议保持True)
# 执行批量处理
final_result = batch_detect_and_convert_sld(ROOT_DIR, RECURSIVE, BACKUP_RAW_FILE)
# 汇总统计结果
print("=" * 120)
print("📊 批量处理结果汇总:")
total = len(final_result)
converted = 0 # 转换成功数
no_need = 0 # 无需转换数(已UTF-8)
skipped = 0 # 跳过数(未知编码)
failed = 0 # 失败数(检测/转换失败)
for path, res in final_result.items():
if res["转换结果"].startswith("成功"):
converted += 1
elif res["转换结果"] == "无需转换(已是UTF-8)":
no_need += 1
elif res["转换结果"].startswith("跳过"):
skipped += 1
else:
failed += 1
print(f"总计检测文件数:{total}")
print(f"✅ 非UTF-8转UTF-8成功:{converted} 个")
print(f"ℹ️ 已是UTF-8无需转换:{no_need} 个")
print(f"⏭️ 未知编码跳过转换:{skipped} 个")
print(f"❌ 检测/转换失败:{failed} 个")
# 保存详细结果到文本文件
save_path = os.path.join(ROOT_DIR, "sld编码转换为UTF8结果.txt")
with open(save_path, 'w', encoding='utf-8') as f:
f.write("SLD文件编码检测+转换为UTF-8结果\n")
f.write("=" * 120 + "\n")
f.write(f"处理时间:{os.popen('date /t').read().strip()} {os.popen('time /t').read().strip()}\n")
f.write(f"根目录:{ROOT_DIR}\n")
f.write(f"递归遍历:{RECURSIVE}\n")
f.write(f"备份原文件:{BACKUP_RAW_FILE}\n")
f.write("=" * 120 + "\n")
f.write(f"{'文件路径':<80} | {'检测编码':<10} | {'置信度':<6} | 转换结果\n")
f.write("-" * 120 + "\n")
for file_path, res in final_result.items():
f.write(f"{file_path:<80} | {res['检测编码']:<10} | {res['置信度']:.2f} | {res['转换结果']}\n")
print(f"\n📝 详细结果已保存到:{save_path}")
if BACKUP_RAW_FILE:
print("⚠️ 提示:原文件已备份(后缀为.bak),如需还原可删除转换后的文件,将.bak重命名为.sld")
- 2.3针对 UTF-8-SIG(带 BOM)转纯 UTF-8(无 BOM) 的批量处理代码,
保留原有的文件检测、备份、结果汇总逻辑,精准处理 UTF-8 BOM 编码的 .sld 文件
python
import chardet
import os
import shutil
from pathlib import Path
def detect_file_encoding(file_path):
"""
精准检测文件编码(重点区分UTF-8/UTF-8-SIG)
:param file_path: 文件路径
:return: 编码名称、置信度
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在:{file_path}")
# 读取全部内容(小文件优先,保证BOM检测准确)
with open(file_path, 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
encoding = result['encoding']
confidence = result['confidence']
# 强制区分UTF-8-SIG和纯UTF-8(关键修改)
if encoding is None:
encoding = '未知编码'
# 手动检测BOM头(chardet可能误判UTF-8-SIG为UTF-8)
elif encoding.lower() == 'utf-8' and raw_data.startswith(b'\xef\xbb\xbf'):
encoding = 'UTF-8-SIG'
# 兼容Windows其他编码
if encoding in ['GB2312', 'GB18030', 'GBK']:
encoding = 'GBK'
return encoding, confidence
def convert_utf8_sig_to_utf8(file_path, backup=True):
"""
将UTF-8-SIG(带BOM)的文件转换为纯UTF-8(无BOM)
:param file_path: 文件路径
:param backup: 是否备份原文件(默认True)
:return: 转换结果
"""
try:
# 1. 读取文件(自动跳过BOM头)
with open(file_path, 'r', encoding='utf-8-sig') as f:
content = f.read()
# 2. 备份原文件
if backup:
backup_path = f"{file_path}.bak"
if not os.path.exists(backup_path):
shutil.copy2(file_path, backup_path)
# 3. 写入纯UTF-8(无BOM)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return f"成功(备份文件:{backup_path if backup else '无'})"
except Exception as e:
return f"失败:{str(e)}"
def batch_convert_sig_to_utf8(root_dir, recursive=True, backup=True):
"""
批量检测并转换UTF-8-SIG的.sld文件为纯UTF-8
:param root_dir: 根目录
:param recursive: 是否递归子目录
:param backup: 是否备份原文件
:return: 处理结果字典
"""
result_dict = {}
sld_files = Path(root_dir).rglob("*.sld") if recursive else Path(root_dir).glob("*.sld")
print(f"开始批量转换UTF-8-SIG为纯UTF-8(根目录:{root_dir})")
print("=" * 120)
print(f"{'文件路径':<80} | {'检测编码':<12} | {'置信度':<6} | 转换结果")
print("-" * 120)
for file_path in sld_files:
file_path_str = str(file_path)
try:
# 检测编码
encoding, confidence = detect_file_encoding(file_path_str)
result_dict[file_path_str] = {
"检测编码": encoding,
"置信度": round(confidence, 2),
"转换结果": "无需转换"
}
# 仅处理UTF-8-SIG编码的文件
if encoding == 'UTF-8-SIG':
convert_result = convert_utf8_sig_to_utf8(file_path_str, backup)
result_dict[file_path_str]["转换结果"] = convert_result
print(f"🔄{file_path_str:<80} | {encoding:<12} | {confidence:.2f} | {convert_result}")
else:
# 非UTF-8-SIG文件跳过
print(f"⏭️{file_path_str:<80} | {encoding:<12} | {confidence:.2f} | 无需转换(非UTF-8-SIG)")
except Exception as e:
result_dict[file_path_str] = {
"检测编码": "检测失败",
"置信度": 0.0,
"转换结果": f"检测失败:{str(e)}"
}
print(f"{file_path_str:<80} | 检测失败 | 0.00 | {e}")
return result_dict
# 主程序
if __name__ == "__main__":
# 配置项
ROOT_DIR = r"C:\Users\Miao\Desktop\Desktemp\temp\styles2"
RECURSIVE = True # 是否递归子目录
BACKUP_RAW_FILE = True # 是否备份原文件
# 执行批量转换
final_result = batch_convert_sig_to_utf8(ROOT_DIR, RECURSIVE, BACKUP_RAW_FILE)
# 汇总统计
print("=" * 120)
print("📊 批量转换结果汇总:")
total = len(final_result)
converted = 0
no_need = 0
failed = 0
for path, res in final_result.items():
if res["转换结果"].startswith("成功"):
converted += 1
elif res["转换结果"].startswith("无需转换"):
no_need += 1
else:
failed += 1
print(f"总计检测文件数:{total}")
print(f"✅ UTF-8-SIG转纯UTF-8成功:{converted} 个")
print(f"ℹ️ 无需转换(非UTF-8-SIG):{no_need} 个")
print(f"❌ 检测/转换失败:{failed} 个")
# 保存结果到文件
save_path = os.path.join(ROOT_DIR, "UTF8-SIG转UTF8结果.txt")
with open(save_path, 'w', encoding='utf-8') as f:
f.write("SLD文件 UTF-8-SIG → 纯UTF-8 转换结果\n")
f.write("=" * 120 + "\n")
f.write(f"处理时间:{os.popen('date /t').read().strip()} {os.popen('time /t').read().strip()}\n")
f.write(f"根目录:{ROOT_DIR}\n")
f.write(f"递归遍历:{RECURSIVE}\n")
f.write(f"备份原文件:{BACKUP_RAW_FILE}\n")
f.write("-" * 120 + "\n")
f.write(f"{'文件路径':<80} | {'检测编码':<12} | {'置信度':<6} | 转换结果\n")
f.write("-" * 120 + "\n")
for file_path, res in final_result.items():
f.write(f"{file_path:<80} | {res['检测编码']:<12} | {res['置信度']:.2f} | {res['转换结果']}\n")
print(f"\n📝 详细结果已保存到:{save_path}")
if BACKUP_RAW_FILE:
print("⚠️ 提示:原UTF-8-SIG文件已备份(.bak后缀),如需还原可重命名覆盖")小结
- 1.在Window环境下对中文的识别和编码与Linux对中文的识别和编码是不一样的
- 2.Windows中如果想要中文字正常显示有两点需要注意,在SLD文件的开头要设置编码方式GBK或者GB2312,geoserver在Windows系统中默认将SLD文件保存为ANSI编码的形式
- 3.国产系统(Kylin/Anolis等 )中如果想要中文字正常显示有两点需要注意,在SLD文件的开头要设置编码方式为UTF-8,geoserver在Windows系统中默认将SLD文件保存为UTF-8编码的形式。
以上内容为小编自己总结,如有不对的地方希望大佬批评指正!!

完了,最后一根头发也没了!!