老师给了我几个论题让我选择,我选择了基于因果学习的临床疗效预测。
https://mp.weixin.qq.com/s/NbOFeGgkngdRpYAMFOR1UQ
github
搜索:Causal machine learning AND treatment
首先就是查找根据通过关键字"Causal machine learning AND treatment"去github查找前人的数据与代码,进行学习与创新。
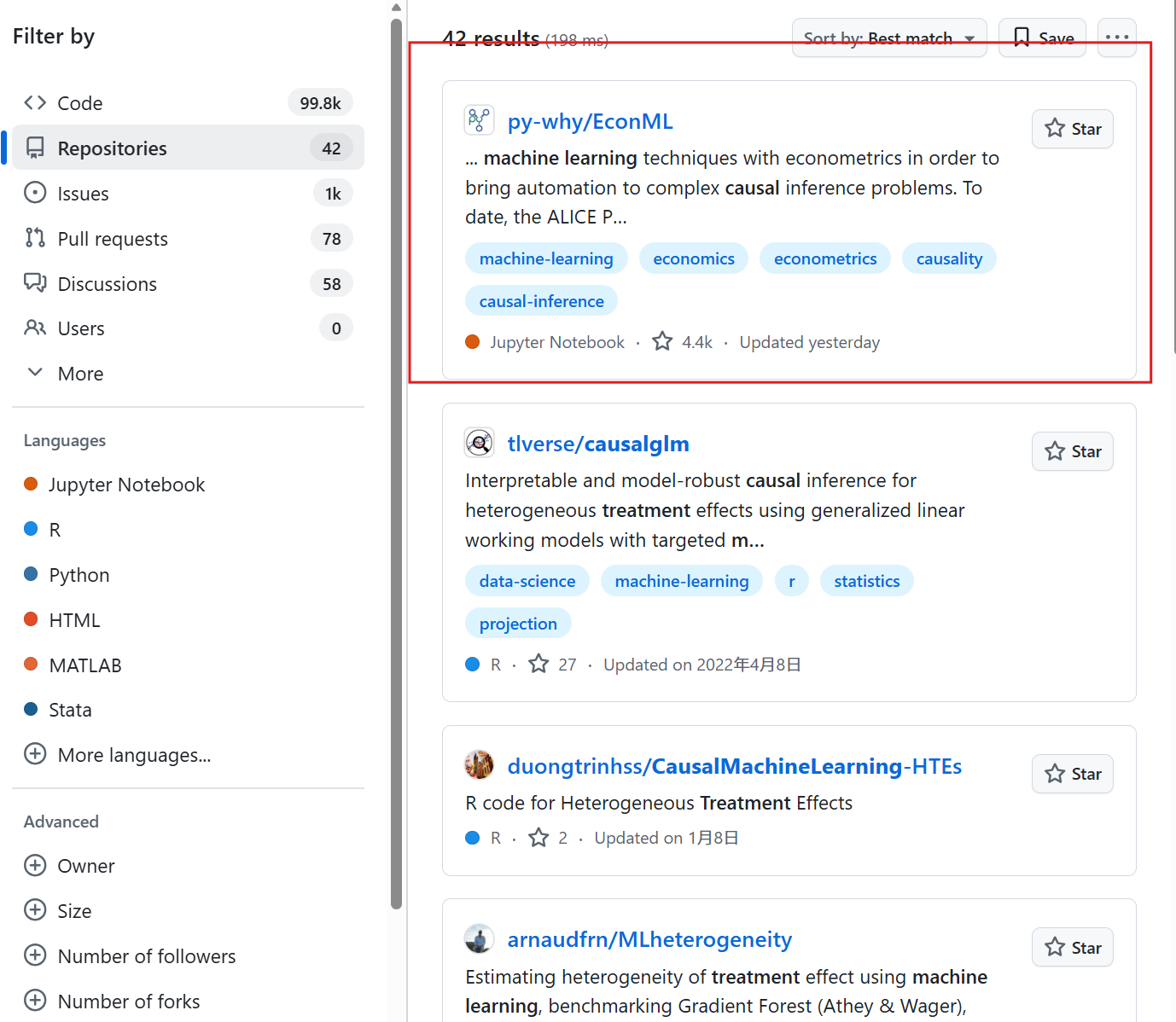
我选择第一个(py-why/EconML)是因为它由微软研究院开发,功能全面、文档完善、示例丰富,支持主流因果机器学习算法(如DML、Causal Forest等),且持续维护更新,是学术界和工业界广泛认可的权威工具,最适合从入门到进阶系统学习。
python
# 导入所需的标准库和第三方库
import os # 用于操作系统相关的功能,如路径处理
import requests # 用于发送 HTTP 请求(访问 GitHub API 和下载文件)
from pathlib import Path # 提供面向对象的文件路径操作方式
from tqdm import tqdm # 用于显示进度条,提升用户体验
# ==================== 配置参数 ====================
# 指定要下载的 GitHub 仓库地址
repo_url = "https://github.com/py-why/EconML"
# 指定本地保存下载文件的目录(可按需修改)
download_dir = "D:/Python/Jupyter_Notebooks/因果分析/EconML"
# ==================== 创建本地目录 ====================
# 使用 pathlib.Path 确保目标目录存在;若不存在则自动创建(包括父目录)
Path(download_dir).mkdir(parents=True, exist_ok=True)
# ==================== 获取仓库根目录下的文件列表 ====================
# 将 GitHub 页面 URL 转换为对应的 GitHub API 地址
# 例如:https://github.com/user/repo → https://api.github.com/repos/user/repo/contents
api_url = f"{repo_url.replace('https://github.com', 'https://api.github.com/repos')}/contents"
# 向 GitHub API 发送 GET 请求,获取仓库根目录的内容信息
response = requests.get(api_url)
# 检查请求是否成功(HTTP 状态码 200 表示成功)
if response.status_code != 200:
print("❌ 获取项目失败,请检查网络或 URL")
exit() # 如果失败,终止程序
# 解析返回的 JSON 数据,得到一个包含文件和文件夹信息的列表
files = response.json()
# ==================== 遍历并下载每个文件 ====================
# 使用 tqdm 显示下载进度条
for item in tqdm(files, desc="正在下载文件"):
file_path = item['path'] # 文件在仓库中的相对路径(如 "README.md" 或 "src/utils.py")
url = item['download_url'] # GitHub 提供的直接下载链接(仅文件有,文件夹为 None)
# 如果 download_url 为空,说明这是一个目录(文件夹),跳过不处理
if not url:
continue
# 提取文件所在子目录(如果有的话)
folder = os.path.dirname(file_path)
if folder: # 如果文件在子目录中
# 在本地创建对应的子目录结构
Path(os.path.join(download_dir, folder)).mkdir(parents=True, exist_ok=True)
# 构造本地完整的文件保存路径
filepath = os.path.join(download_dir, file_path)
# 尝试下载并保存文件
try:
# 发起流式请求(避免一次性加载大文件到内存)
r = requests.get(url, stream=True)
r.raise_for_status() # 如果响应状态码不是 2xx,抛出异常
# 以二进制写入模式打开本地文件
with open(filepath, 'wb') as f:
# 分块读取响应内容(每块 8192 字节),并写入文件
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
# 下载成功提示
print(f"✅ 已下载: {file_path}")
except Exception as e:
# 捕获任何异常(如网络错误、权限问题等),并打印错误信息
print(f"❌ 下载失败: {file_path} - {e}")懒得一个一个的下载了,我选择用python进行克隆到我电脑上。