思维导图
本文的思维导图如下:
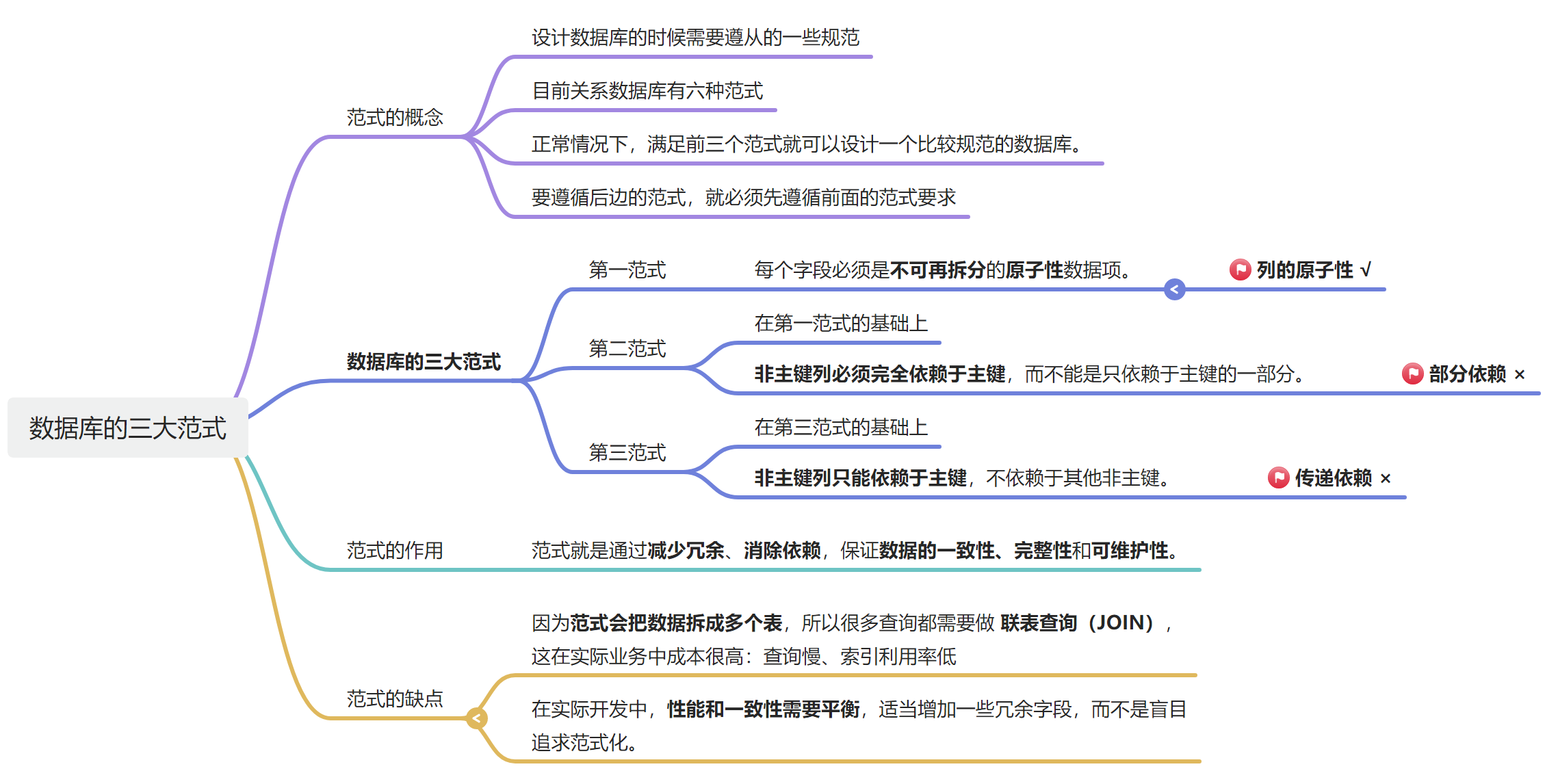
一、范式的概念
设计数据库的时候需要遵从的一些规范 ,目前关系数据库有六种范式:
第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
当然正常情况下,我们满足前三个范式就可以设计一个比较规范的数据库。
注意:要遵循后边的范式,就必须先遵循前面的范式要求,比如第二范式就必须先遵循第一范式的,第三范式必须先遵循第二范式,以此类推。
二、数据库的三大范式
数据库的三大范式是数据库设计中常见的++规范化原则++ ,主要用于++减少冗余、避免异常更新、提升数据一致性++。
注意:三大范式是"关系模型"理论提出的设计准则,它适用于所有关系型数据库(MySQL、Oracle、PostgreSQL...)
第一范式(1NF)
第一范式,就是要求字段必须不可再分原子性。
核心要求:
- 每个字段必须是不可再拆分的原子性数据项。
- 即字段值不能再继续拆成多个部分。
示例:
| 学号 | 姓名 | 性别 | 出生年月日 |
|---|
"出生年月日"如果还能拆成++出生年++ 、++出生月++ 、++出生日++ → 违反 1NF。
如何满足 1NF? 拆成:出生年、出生月、出生日。
第二范式(2NF)
第二范式,就是在第一范式的基础上,要求非主键字段必须"完全依赖"主键,而不是"部分依赖。
简单来说,就是:
非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第二范式主要就是为了解决"联合主键导致的部分依赖问题"的。
示例:
| 学号 | 课程号 | 姓名 | 学分 |
|---|
这张表的使用的是联合主键,主键 =(学号,课程号)
为什么要设置联合主键?
因为:
- 一个学生可以选多门课
- 一门课也可以被很多学生选
因此要唯一标识一条"学生选课关系",必须用:
同一个"学号 + 课程号"组合,才能唯一标识一条记录。
上面的这个表不符合 2NF,因为:
- "姓名"只依赖"学号",不依赖"课程号",即不依赖整个主键。
- "学分"只依赖"课程号",不依赖"学名",即不依赖整个主键。
正确做法------拆表,将上述表拆成三张表:
表1:学生表(Student)
| 学号 | 姓名 |
|---|
表2:课程表(Course)
| 课程号 | 学分 |
|---|
表3:选课关系表(StudentCourse)
| 学号 | 课程号 |
|---|
第三范式(3NF)
第三范式,就是在第二范式的基础上,非主键字段之间不能存在传递依赖;
也就是说,非主键列只依赖于主键,不依赖于其他非主键。
- √ 正确的依赖关系:直接依赖 ,就是++非主键只依赖主键++;
- × 错误的依赖关系:传递依赖,非主键不是直接依赖主键,而是依赖另一个非主键,"绕了一圈"最后依赖关系才传递到主键。
示例:
| 学号(A) | 姓名 | 年龄 | 所在学院(B) | 学院电话© |
|---|
传递关系是:学号A → 所在学院B → 学院电话C
C 不是直接依赖 A,是通过 B 间接依赖 A → 这就是传递依赖 → 违反第三范式
如何改?
拆成两张表:
1)学生:学号、姓名、年龄、所在学院
2)学院:学院名、学院电话
✔ 三范式总结表
| 范式 | 存在问题 | 解决问题 |
|---|---|---|
| 1NF | 字段可再拆 | 字段要原子化 |
| 2NF | 部分依赖 | 非主键字段必须完全依赖主键 |
| 3NF | 传递依赖 | 非主键字段不能依赖其他非主键字段 |
💡注意:范式判断是 ++设计层面的逻辑++ ,数据库不能自动推断是否违反了三大范式。
因为数据库无法知道:
- 哪个字段是"业务上"的主键
- 哪些字段"业务上"应该依赖谁
- 哪些字段"业务上"有计算关系
三、相关面试题
1. 数据库的三大范式是什么?
第一范式: 要求所有字段都是++不可再分的原子数据项++,强调的是列的原子性,
第二范式: 要求++非主键字段必须"++ ++完全依赖++ ++"主键++ ,++而不是"++ ++部分依赖++ ++"++
第二范式主要就是为了解决"联合主键导致的部分依赖问题"。
第三范式: ++非主键字段之间不能++ ++传递依赖++ ++,也就是说非主键字段不能相互依赖++ ,++非主键字段只能++ ++直接依赖++ ++于主键字段++。
在实际开发中没必要严格遵循三大范式,而是在++性能和一致性之间++找到平衡。
2. 范式设计是为了解决什么问题?
数据库范式的目的,是为了解决几类典型的数据问题:
- 数据冗余------避免同一份数据被重复存多次,浪费空间,也容易产生不一致。
- 数据不一致(更新异常)------当同一份信息存多处、更新时只改了一部分,就会出现数据不一致的问题;范式化通过拆分表来保证更新一致性。
- 插入异常------某些字段因为结构不合理导致必须填冗余字段,否则插不进去;范式避免这种情况。
- 删除异常------删除一条记录时可能误删其他重要信息;范式通过拆分相关数据避免级联丢失。
简单说,范式就是通过减少冗余、消除依赖,保证数据的一致性、完整性和可维护性。
3. 范式设计有什么缺点?
范式化的确能减少冗余、保持数据一致性,但它也有明显的缺点。 因为范式会把数据拆成多个表,所以很多查询都需要做 联表查询(JOIN),
这在实际业务中成本很高:查询慢、索引利用率低,而且联表查询很不适合做 分库分表,会让架构复杂度增加。
所以在真实项目里,很多时候我们会做
反范式设计。也就是说,适当冗余一些字段,让查询直接在单表内完成,避免大量的联表查询,提高性能和可扩展性。所以,在实际开发中,++性能和一致性需要平衡,而不是盲目追求范式化++。