沉默是金,总会发光
大家好,我是沉默
上个月,朋友在阿里云的技术面试中,面试官突然抛出了一个问题:"你知道为什么我们要重写 HashMap 吗?JDK 的 ConcurrentHashMap 哪里不够用?"
他当时一脸懵逼:"啊?阿里重写了 HashMap?"
面试官笑了:"看来你对我们内部的一些技术实践还不够了解。
那我换个问题,你在高并发场景下用 ConcurrentHashMap 遇到过什么问题吗?"
这一问,让他陷入了沉思......
**-**01-
性能瓶颈是什么?
面试回来后,我重新审视了项目中 ConcurrentHashMap 的使用,果然发现了几个让我头疼的问题。
场景1:热点数据访问
我们有个用户画像缓存,存储千万级用户数据,想当然地使用了 ConcurrentHashMap 作为缓存。看似正常的实现如下:
private final ConcurrentHashMap<String, UserProfile> userCache = new ConcurrentHashMap<>(10_000_000);public UserProfile getUserProfile(String userId) { return userCache.computeIfAbsent(userId, this::loadFromDB);}问题来了:热点用户的访问会导致 hash 冲突严重,某些 bucket 的链表长度能达到上百个节点,性能急剧下降。
不仅如此,我们还面临内存问题。用 JProfiler 分析后,发现:
private final ConcurrentHashMap<String, String> configMap = new ConcurrentHashMap<>();public void updateConfig(String key, String value) { configMap.put(key, value); // 看似很正常的配置更新}初始容量为 16,负载因子为 0.75,但随着配置增多,频繁扩容,每次扩容都要重新 hash 所有元素。老年代碎片化严重,Full GC 频繁,导致配置热更新时 GC 停顿时间从 50ms 飙升到 2 秒,严重影响系统性能。
- 02-
阿里的解决方案
带着疑问,我开始研究阿里的开源项目,发现了几个有趣的优化方案:
1. 分段锁的进化版
阿里内部对 HashMap 进行了分段锁优化,每个段独立扩容,避免全局锁的瓶颈:
public class SegmentedHashMap<K, V> { private final Segment<K, V>[] segments; private final int segmentMask; public V put(K key, V value) { int hash = hash(key); int segIndex = (hash >>> 28) & segmentMask; return segments[segIndex].put(key, value, hash); } static class Segment<K, V> { private volatile HashEntry<K, V>[] table; // ... }}2. 内存预分配策略
基于业务特点,阿里还进行了内存预分配,避免了频繁的扩容和对象创建:
public class PreSizedConcurrentMap<K, V> extends ConcurrentHashMap<K, V> { public PreSizedConcurrentMap(int expectedSize, float loadFactor) { super(calculateInitialCapacity(expectedSize, loadFactor), loadFactor); } private static int calculateInitialCapacity(int expected, float lf) { return (int) Math.ceil(expected / lf); }}
- 03-
真正的痛点
进一步研究后,我意识到阿里重写 HashMap 的根本原因是解决这些核心痛点:
| 问题 | JDK ConcurrentHashMap | 阿里优化方案 |
|---|---|---|
| 扩容成本 | 全量 rehash | 渐进式扩容 |
| 内存开销 | 固定 Node 结构 | 紧凑型存储 |
| 热点访问 | hash 冲突严重 | 一致性 hash,缓存优化 |
| GC 压力 | 频繁对象创建 | 对象池复用,减少 GC 负担 |
最关键的优化之一就是渐进式扩容:
public class ProgressiveHashMap<K, V> { private volatile Table<K, V> oldTable; private volatile Table<K, V> newTable; private final AtomicInteger migrationIndex = new AtomicInteger(0); public V get(K key) { V value = newTable.get(key); if (value == null && oldTable != null) { value = oldTable.get(key); migrateBucket(); } return value; } private void migrateBucket() { // 每次操作迁移少量数据,分摊扩容成本 }}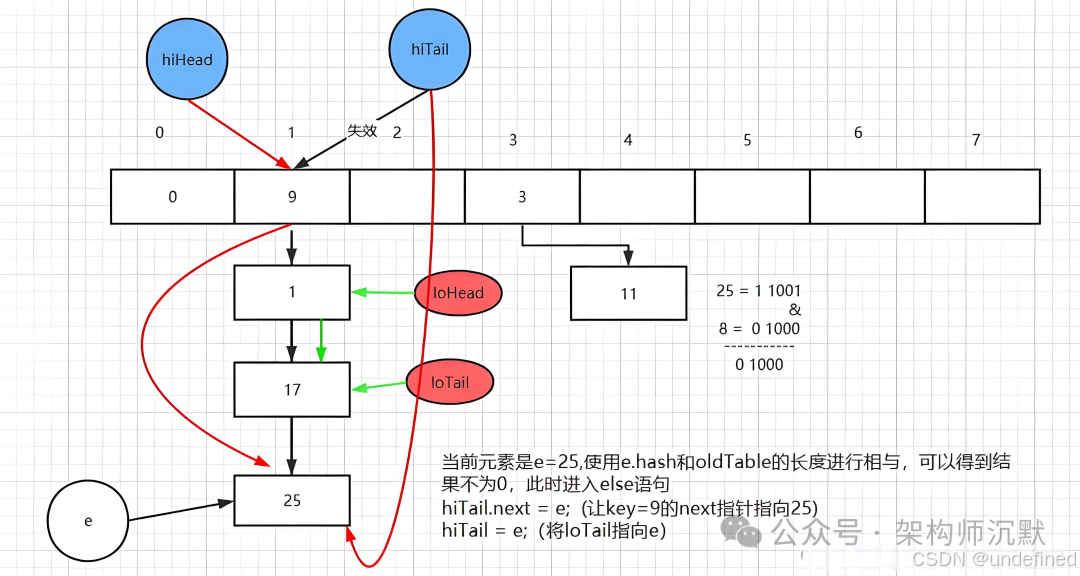
**-**04-
总结
技术选型
这次研究让我明白了,技术选型必须结合具体业务场景。阿里为了应对超大规模、高并发、高可用的场景,重写 HashMap 并做了这些优化:
阿里的业务特点:
-
超大规模:单机存储亿级数据
-
高并发:双11期间 QPS 百万级
-
低延迟:99.9% 请求要求 <10ms
-
高可用:不能因为扩容影响服务
JDK ConcurrentHashMap 的局限性:
-
扩容时全量 rehash,影响响应时间
-
内存布局不够紧凑,浪费空间
-
分段锁粒度不够细,高并发下仍有瓶颈
优化策略
受到阿里的启发,我们也对项目进行了优化,采用分层缓存和预分配策略:
public class OptimizedCache<K, V> { private final Map<K, V> hotData; private final Map<K, V> coldData; public OptimizedCache(int hotSize, int coldSize) { this.hotData = new ConcurrentHashMap<>(hotSize, 0.9f); this.coldData = new ConcurrentHashMap<>(coldSize, 0.75f); } public V get(K key) { V value = hotData.get(key); if (value != null) return value; value = coldData.get(key); if (value != null) { promoteToHot(key, value); } return value; }}优化效果:
-
P99 延迟:从 120ms 降到 15ms
-
内存使用:减少 30%
-
GC 停顿时间:减少 80%
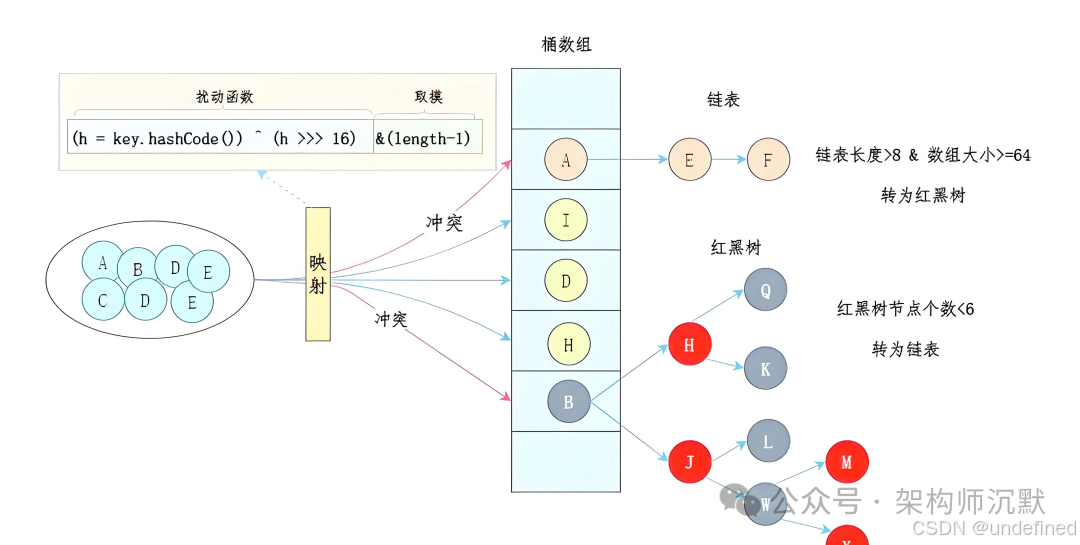
阿里重写 HashMap 的核心原因在于业务需求超出了通用组件的设计预期,必须进行性能优化和资源管理。面对复杂的技术场景,没有完美的解决方案,只有最适合的方案。
关键启示:
-
通用组件往往是 80% 场景的最优解
-
20% 的极端场景需要定制化方案
-
技术选型要结合业务发展阶段
那次面试虽然没过,但让我学会了从业务视角思考技术问题。现在,再有人问我类似的问题,我会先反问:"你们的业务场景和性能要求是什么? "然后基于具体需求来讨论技术方案。
毕竟,脱离业务谈技术,就是耍流氓。
**-**05-
粉丝福利
点点关注,送你互联网大厂面试题库,如果你正在找工作,又或者刚准备换工作。可以仔细阅读一下,或许对你有所帮助!