Z-Image 是由阿里巴巴通义实验室推出的一款高效图像生成基础模型,参数量"仅"60亿(6B),却能在图像质量、文本渲染、文化理解等多个维度媲美甚至超越许多参数规模大一个数量级的国际主流模型。

1.Z-Image 的版本
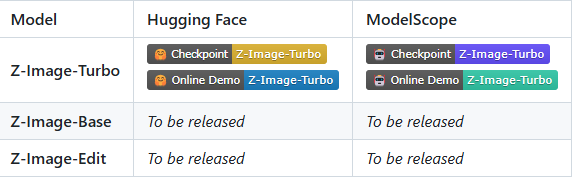
目前,Z-Image 已开源两个专用版本:
- Z-Image-Turbo:主打超快、高质的图像生成,仅需8步推理即可输出照片级真实感图像;
- Z-Image-Base:基础版本
- Z-Image-Edit:专注于图像编辑,能精准执行复杂指令(如改表情、换风格、加文字等),保持画面逻辑连贯。
Z-Image 能在16GB显存的消费级显卡上流畅运行,真正让高性能AI图像生成"飞入寻常百姓家"。
官方已开放:
- GitHub 代码仓库:https://github.com/Tongyi-MAI/Z-Image
- ModelScope 模型页面:https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo
- Hugging Face 模型库:https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
- 官方技术博客:https://tongyi-mai.github.io/Z-Image-blog/
2.特点
Z-Image 的能力远不止"画得像",而是理解深、执行准、表达美:
- 照片级真实感图像生成
无论是人像、风景还是产品图,Z-Image-Turbo 都能生成细节丰富、光影自然、构图优美的图像,接近专业摄影水准。
- 中英双语文本精准渲染
它能准确地在图像中嵌入中文或英文文字------比如海报、广告牌、书封等场景,即使字体小、角度斜、背景复杂,也能清晰可读,且不破坏整体美感。这在当前多数开源模型中极为罕见。
- 深厚的文化与世界知识
Z-Image 能正确生成西湖断桥、故宫角楼、李白杜甫等具有文化标识性的内容,甚至能为古诗《登科后》配图,或还原"苏轼夜游承天寺"的历史场景,展现出对中华文化的深度理解。
- 强大的逻辑推理与指令遵循
借助内置的"提示词增强器"(Prompt Enhancer),它能处理带逻辑的问题,比如"鸡兔同笼"数学题的可视化,或根据模糊指令推断用户真实意图,实现智能编辑。
- 创意图像编辑
Z-Image-Edit 可同时修改人物表情、服装、背景、文字等多个元素,并保持高度一致性。例如:"把男生外套换成蓝色羽绒服,头发染成粉色,对话框写'是Z-Image,我们有救了'"------一句话,全搞定。
3.应用场景
Z-Image 的应用场景非常广泛,既适合个人创作者,也适用于企业级产品:
- 设计师/自媒体人:快速生成海报、封面、插画、广告素材;
- 教育工作者:为古诗、历史事件、科学概念配图,提升教学趣味性;
- 电商/营销团队:批量生成商品展示图、促销 banner,降低拍摄成本;
- 开发者/研究者:基于开源模型进行二次开发,构建定制化AIGC工具;
- 普通用户:通过在线 Demo(如 ModelScope 或 Hugging Face)零门槛体验AI绘画。
体验地址: https://www.modelscope.cn/aigc/imageGeneration
4.本地部署
4.1 环境
| 环境 | 版本 |
|---|---|
| ubuntu-24.04.3 Server | release 10.0 |
| Cuda | 12.8 |
| 显卡 RTX 2080 Ti 22G | 驱动 NVIDIA-Linux-x86_64-580.105.08 |
| conda | 25.9.1 |
| 内存 | 32G |
shell
conda create -n zimage python=3.10
conda activate zimage
# 接下来会使用pip安装依赖,所以添加国内加速
(zimage) pip config set global.index-url https://mirrors.huaweicloud.com/repository/pypi/simple/
# 设置全局代理
git config --global http.proxy http://192.168.6.120:7897
git config --global https.proxy http://192.168.6.120:7897
# 克隆源码
git clone https://github.com/huggingface/diffusers.git zimage
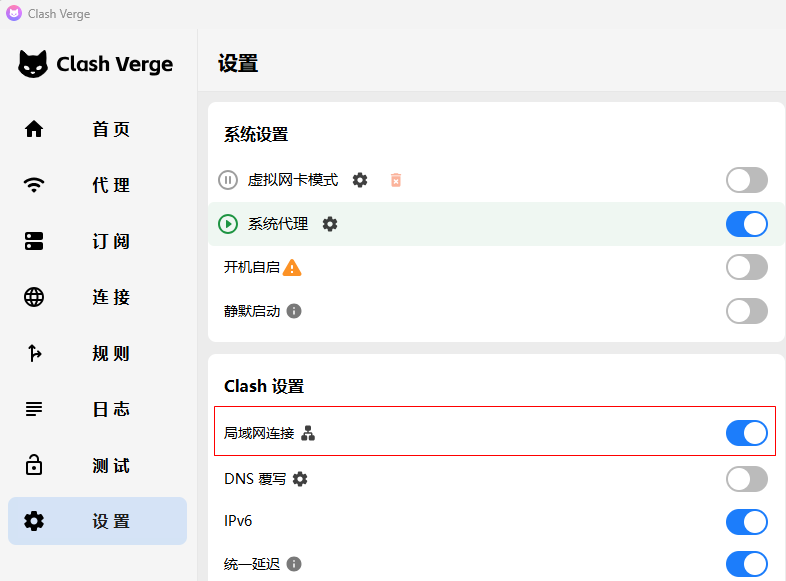
cd zimage192.168.6.120 是一台windows机器,安装了 Class Verge ,通过它加速访问github。
git 代理指向了这个机器,要通过192.168.6.120 代理到github, Class Verge 必须要允许局域网连接(默认是关闭的)
4.2 安装依赖
shell
cd ~/zimage
pip install -e .
# 查看 cuda版本, 可以看到,本地机器上安装的 cuda 版本是 12.8 版本
nvcc --version
Build cuda_12.8.r12.8/compiler.35583870_0
# 安装对应cuda版本的 pyTorch
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128
#安装transformers
pip install transformers4.3 下载模型
shell
cd ~/zimage
# 从 modelscope下载
pip install modelscope
mkidr -p models使用python代码下载:
python
#模型下载,模型文件保存到 当前目录的 models文件夹中
from modelscope import snapshot_download
model_dir = snapshot_download('Tongyi-MAI/Z-Image-Turbo',local_dir='models')4.4 官方脚本测试
python
import torch
from modelscope import ZImagePipeline
# 1. Load the pipeline
# Use bfloat16 for optimal performance on supported GPUs
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True, # 启用低 CPU 内存模式
)
pipe.to("cuda")
# [Optional] Attention Backend
# Diffusers uses SDPA by default. Switch to Flash Attention for better efficiency if supported:
# pipe.transformer.set_attention_backend("flash") # Enable Flash-Attention-2
# pipe.transformer.set_attention_backend("_flash_3") # Enable Flash-Attention-3
# [Optional] Model Compilation
# Compiling the DiT model accelerates inference, but the first run will take longer to compile.
# pipe.transformer.compile()
# [Optional] CPU Offloading
# Enable CPU offloading for memory-constrained devices.
# pipe.enable_model_cpu_offload()
prompt = "Young Chinese woman in red Hanfu, intricate embroidery. Impeccable makeup, red floral forehead pattern. Elaborate high bun, golden phoenix headdress, red flowers, beads. Holds round folding fan with lady, trees, bird. Neon lightning-bolt lamp (⚡️), bright yellow glow, above extended left palm. Soft-lit outdoor night background, silhouetted tiered pagoda (西安大雁塔), blurred colorful distant lights."
# 2. Generate Image
image = pipe(
prompt=prompt,
height=512,
width=512,
num_inference_steps=9, # This actually results in 8 DiT forwards
guidance_scale=0.0, # Guidance should be 0 for the Turbo models
generator=torch.Generator("cuda").manual_seed(42),
).images[0]
image.save("example.png")将
low_cpu_mem_usage=False修改成了low_cpu_mem_usage=False,height=1024, with=1024修改为了height=512,width=512,不然会因为显存不够导致程序崩溃。
生成效果:
