最近后台有小伙伴提了一些实际工作中使用Spark遇到的问题,笔者挑选了几个相对常见的问题,分别从场景模拟/问题现象、问题分析、解决方案三个层面,来深入分析这些问题,并且提供一个解决类似问题的思路。
>> 问题1
使用SparkSQL(2.4版本)往存储格式为parquet的Hive分区表中存储NullType类型的数据时报错:
kotlin
org.apache.spark.sql.AnalysisException: Parquet data source does not support null data type.虽然在Stack OverFlow上找到了类似的问题,但没有具体阐明到底是什么原因导致了这种问题以及如何解决?
1. 场景模拟
1)创建temp view:test_view
python
sparkSession.sql( """ |select 1 as id, null as name """.stripMargin ).createOrReplaceTempView("test_view")2)打印test_view的schema信息
bash
-- id为integer类型,name对应到Spark SQL内部字段数据类型即位NullTyperoot |-- id: integer (nullable = false) |-- name: null (nullable = true)3)将test_tab中数据存入Hive分区表test_partition_tab的分区partitionCol=20201009中
lua
df.write.mode(SaveMode.Overwrite).format("parquet").save("/bigdatalearnshare/test_partition_tab/partitionCol=20201009")4)报错信息
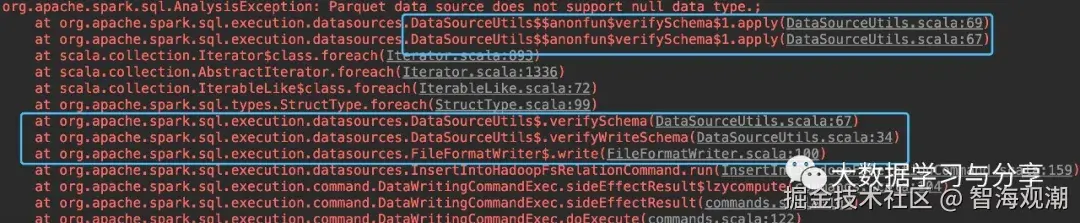 2. 问题分析
2. 问题分析
根据报错信息,提示Parquet数据源不支持null type类型的数据。既然是保存数据,我们很容易联想到FileFormatWriter,再结合错误信息:
less
org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:100对应的源码为:
scss
DataSourceUtils.verifyWriteSchema(fileFormat, dataSchema)debug进去,看看这个方法究竟干了什么?
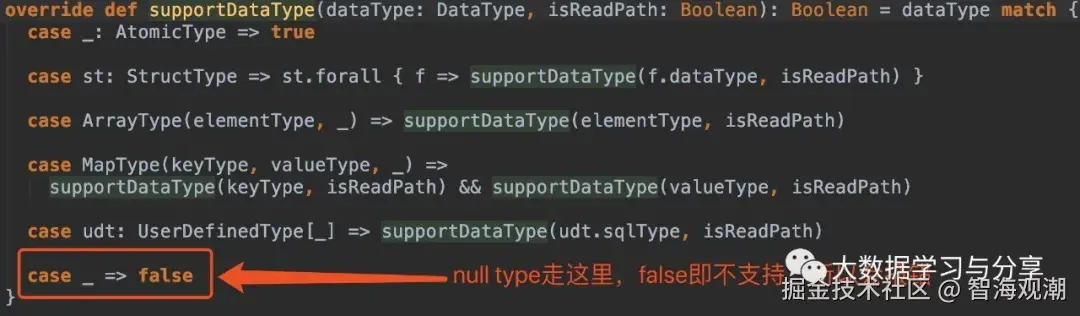
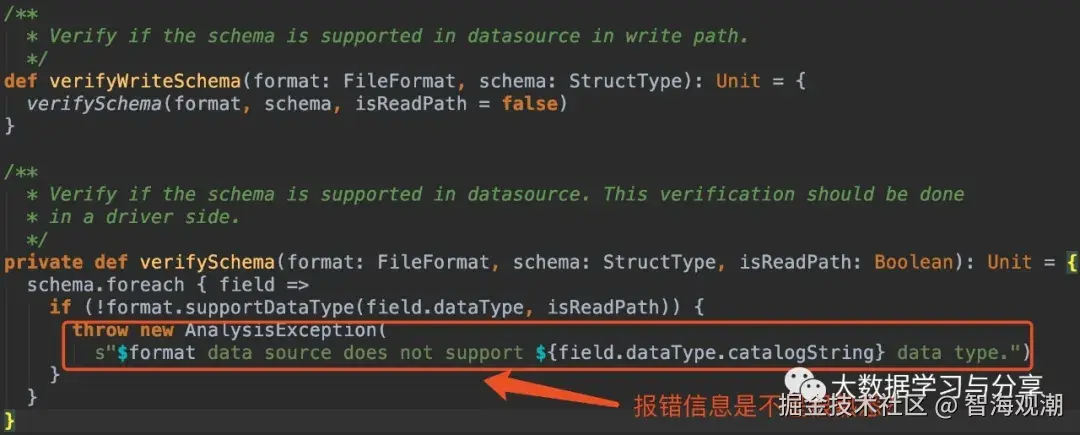 根据源码分析可知,上述程序中SparkSQL在保存数据时会对数据的schema进行校验,并且不同的存储格式(parquet、csv、json等)支持的数据类型会有所不同,以parquet为例,查看源码:
根据源码分析可知,上述程序中SparkSQL在保存数据时会对数据的schema进行校验,并且不同的存储格式(parquet、csv、json等)支持的数据类型会有所不同,以parquet为例,查看源码:
 3. 解决方案
3. 解决方案
csharp
-- 使用insert sql进行数据的保存insert overwrite table test_partition_tab partition(partitionCol=20201009) select * from test_view;>> 问题2
1. 问题现象
在利用Spark和Kafka处理数据时,同时在maven pom中引入Spark和Kafka的相关依赖。但是当利用SparkSQL处理数据生成的DataSet/DataFrame进行collect或者show等操作时,抛出以下异常信息:
php
in stage 3.0 (TID 403, localhost, executor driver): java.lang.NoSuchMethodError: net.jpountz.lz4.LZ4BlockInputStream.<init>(Ljava/io/InputStream;Z)V at org.apache.spark.io.LZ4CompressionCodec.compressedInputStream(CompressionCodec.scala:122) at org.apache.spark.serializer.SerializerManager.wrapForCompression(SerializerManager.scala:163) at org.apache.spark.serializer.SerializerManager.wrapStream(SerializerManager.scala:124) at org.apache.spark.shuffle.BlockStoreShuffleReader$$anonfun$3.apply(BlockStoreShuffleReader.scala:50) at org.apache.spark.shuffle.BlockStoreShuffleReader$$anonfun$3.apply(BlockStoreShuffleReader.scala:50) at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:453) at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:64) at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:434) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.agg_doAggregateWithKeys_0$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:255)2. 问题分析
错误信息提示找不到方法:
bash
net.jpountz.lz4.LZ4BlockInputStream.<init>(Ljava/io/InputStream;Z)V根据经验,找不到某个方法,一般主要有两个原因造成:
- 没有相应的jar包依赖
- jar包依赖冲突
经过排查发现导致本问题发生的原因是:Spark内部使用的包net.jpountz.lz4和Kafka中包产生冲突
3. 解决方案
排除Kafka中net.jpountz.lz4的依赖包:
xml
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.0.0</version> <exclusions> <exclusion> <groupId>net.jpountz.lz4</groupId> <artifactId>lz4</artifactId> </exclusion> </exclusions> </dependency>>> 问题3
通过SparkSQL,对两个存在map类型字段的Hive表进行union操作,报如下错误:
python
org.apache.spark.sql.AnalysisException: Cannot have map type columns in DataFrame which calls set operations(intersect, except, etc.), but the type of column map is map<string,string>;1. 场景模拟
1)通过函数str_to_map/map生成map类型的字段,然后进行union操作
go
select 1 id, str_to_map("k1:v1,k2:v2") map
union
select 2 id, map("k1","v1","k2","v2") map2)报错信息
css
org.apache.spark.sql.AnalysisException: Cannot have map type columns in DataFrame which calls set operations(intersect, except, etc.), but the type of column map is map<string,string>;;Distinct+- Union :- Project [1 AS id#116, str_to_map(k1:v1,k2:v2, ,, :) AS map#117] : +- OneRowRelation +- Project [2 AS id#118, map(k1, v1, k2, v2) AS map#119] +- OneRowRelation
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$class.failAnalysis(CheckAnalysis.scala:42) at org.apache.spark.sql.catalyst.analysis.Analyzer.failAnalysis(Analyzer.scala:95) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:364) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:85) at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:127) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$class.checkAnalysis(CheckAnalysis.scala:85)2. 问题分析
根据报错信息,我们查看org.apache.spark.sql.catalyst.analysis.CheckAnalysis的checkAnalysis方法,第362行源码处理逻辑(错误信息是不是很熟悉呢?):

关键看mapColumnInSetOperation中对逻辑计划的匹配:

针对逻辑计划中有Intersect、Except、Distinct的output"返回"的属性(Attribute)有map类型,或者Deduplicate的keys(也是Attribute)包含map字段类型,都会导致上述问题。
而union导致上述报错,是因为union会对结果去重,即distinct
3. 解决方案
询问后台小伙伴儿,目前的业务场景是考验不需要去重处理的。
那么我们都知道,union和union all的主要区别就是,前者会对结果去重,后者则不会。那么将union改为union all就好了。