🚀 从零到一:一款全能Markdown转PDF脚本的深度解析
注:脚本链接在尾部
在日常工作和学习中,我们经常需要将Markdown文档转换为PDF格式以便分享和存档。但市面上的转换工具要么功能单一,要么格式错乱,尤其是代码高亮和图片处理常常不尽人意。今天我要向大家介绍一款功能完备的Markdown转PDF脚本,它能完美解决这些痛点,让你的文档转换体验焕然一新。
脚本核心功能概览
这款名为md2pdf.py的脚本是一个一站式Markdown转PDF解决方案,主要特点包括:
- 全自动依赖管理,无需手动安装所需模块
- 完美支持代码块高亮显示,支持多种编程语言
- 智能处理图片,包括SVG格式转PNG功能
- 生成美观的PDF排版,支持目录、表格和复杂格式
- 自定义CSS样式,确保PDF输出效果一致且专业
核心技术解析
1. 智能依赖管理
脚本最贴心的功能之一是自动检测并安装所需依赖,无需用户手动处理繁琐的环境配置:
python
模块名 = 'weasyprint'
try:
from weasyprint import HTML, CSS
except ImportError as impErr:
print(f"尝试导入 {模块名} 依赖时检测到异常:{impErr}")
print(f"尝试安装 {模块名} 模块:")
try:
os.system(f"pip install {模块名}")
except OSError as osErr:
print(f"尝试安装模块 {模块名} 时检测到异常:{osErr}")
exit(0)
else:
try:
from weasyprint import HTML, CSS
except ImportError as impErr:
print(f"再次尝试导入 {模块名} 依赖时检测到异常:{impErr}")
exit(0)这种设计极大降低了使用门槛,即便是Python新手也能轻松上手。
2. 代码高亮实现
脚本通过自定义Markdown扩展实现了代码块的高亮显示,支持自动识别编程语言:
python
class CodeHighlightPostprocessor(Postprocessor):
def run(self, html):
"""后处理HTML,替换<pre><code>为高亮代码"""
# 匹配<pre><code class="language-xxx">格式的代码块
pattern = re.compile(
r'<pre><code(?: class="language-([a-zA-Z0-9_-]+)")?>(.*?)</code></pre>',
re.DOTALL # 匹配多行
)
def replace_code(match):
lang = match.group(1) or ""
code = match.group(2)
# 还原HTML转义字符
code = code.replace('&', '&').replace('<', '<').replace('>', '>')
try:
# 识别编程语言
if lang:
lexer = get_lexer_by_name(lang)
else:
lexer = guess_lexer(code)
except:
lexer = get_lexer_by_name('text') # 兜底为纯文本
# 生成高亮HTML
formatter = HtmlFormatter(
style='colorful',
noclasses=False,
linenos=False
)
return highlight(code, lexer, formatter)
# 替换所有代码块
html = pattern.sub(replace_code, html)
return html这段代码通过正则匹配找到所有代码块,使用Pygments库进行语法高亮处理,然后替换原始HTML内容,实现了优雅的代码展示效果。
3. 图片处理机制
脚本特别处理了SVG格式图片,将其转换为PDF更兼容的PNG格式:
python
def svg_to_png(svg_path):
try:
img = Image.open(svg_path)
img_byte_arr = io.BytesIO()
img.save(img_byte_arr, format='PNG')
img_byte_arr = img_byte_arr.getvalue()
return f"data:image/png;base64,{base64.b64encode(img_byte_arr).decode()}"
except:
return svg_path # 转换失败则保留原路径同时,在CSS中对图片显示做了专门优化,确保图片在PDF中完美展示:
css
/* 图片适配A4页面(核心修复显示不全) */
img {
max-width: 100%; /* 强制图片宽度不超过容器(A4内容区) */
height: auto; /* 保持宽高比,避免拉伸变形 */
object-fit: contain; /* 关键:完整显示图片,不裁剪 */
display: block; /* 消除图片默认行内间隙 */
margin: 1em auto; /* 图片居中显示,上下留间距 */
page-break-inside: avoid; /* 避免图片跨页断裂 */
}4. PDF排版优化
脚本使用WeasyPrint库将HTML转换为PDF,并通过精心设计的CSS样式确保输出质量:
python
# 生成PDF
try:
HTML(string=full_html).write_pdf(
pdf_path,
stylesheets=[css_style],
presentational_hints=True,
optimize_images=True
)
画板.消息(绿字(f"PDF生成成功!路径:{pdf_path}"))
return True
except Exception as e:
画板.提示错误(f"PDF转换失败:{str(e)}")
return FalseCSS中对页面布局、标题样式、表格样式等都做了细致的定义,确保最终PDF的专业外观。
效果演示
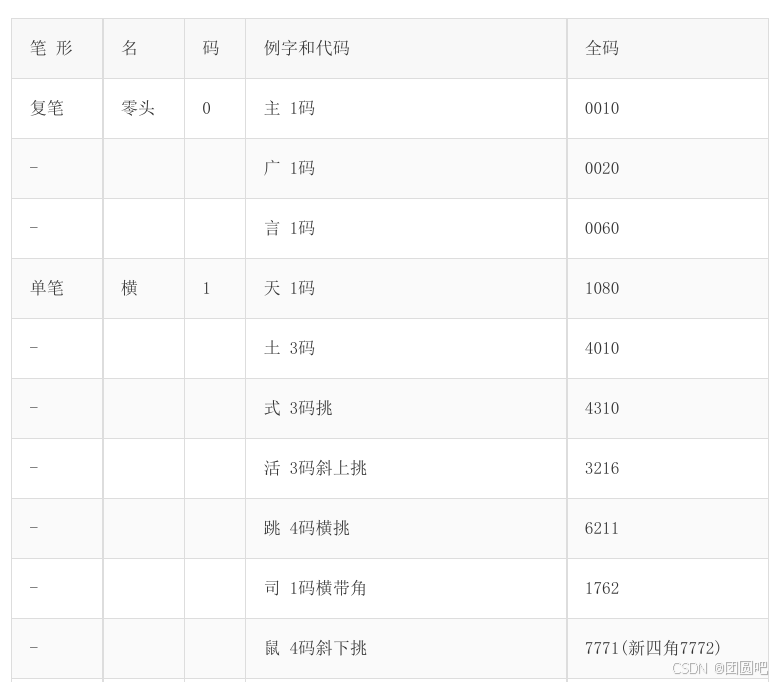
表格效果
原始md内容:
md
笔 形| 名 |码 | 例字和代码|全码
:-|:-|:-|:-|:-
复笔 |零头|0|**主** 1码 | 0010
-|||**广** 1码 | 0020
-|||**言** 1码| 0060
单笔 |横 |1 |**天** 1码 |1080
-|||**土** 3码 |4010
-|||**式** 3码挑 |4310
-|||**活** 3码斜上挑|3216
-|||**跳** 4码横挑|6211
-|||**司** 1码横带角| 1762
-|||**鼠** 4码斜下挑|7771(新四角7772)转换为pdf的效果:
文本着色效果
原始md内容:
md
## 【 第一节】 笔形的位置和代码
【笔形的位置】方块汉字的<font color=green>左上</font>,<font color=green>右上</font>,<font color=green>左下</font>,<font color=green>右下</font>四区为【1234区】。在这些区取<font color=green>左上</font>,<font color=green>右上</font>,<font color=green>左下</font>,<font color=green>右下</font>四个角码即1234码(图sjft9j0,sjft09j1)、【哪个角的码在哪个区里取,哪个区的笔作哪个角的码】是四角号码【取码最高原则】。字的12区合并为【上边】,13区是【左边】,24区是【右边】,34区是【下边】。字的5码即附码在4码笔形上面(或附近)的笔形中取(5码细节规定见后),字的6码即又附码在5码笔形上面(或附近)的笔形中取(6码细节规定见后)转换为pdf的效果:

图片效果
原始md文档:
md
### 附图列表
- 附图sjft09j0 👇
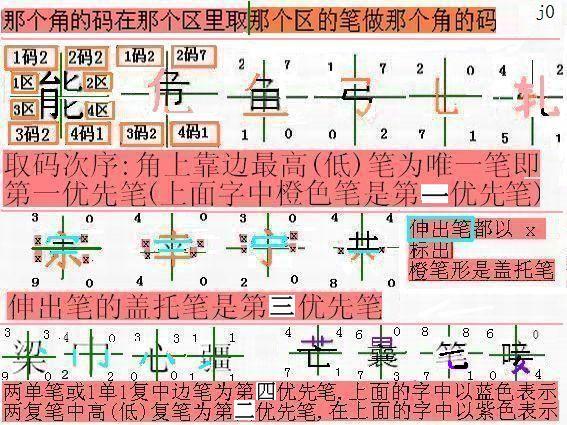
👆面是原图,👇下面是重建图
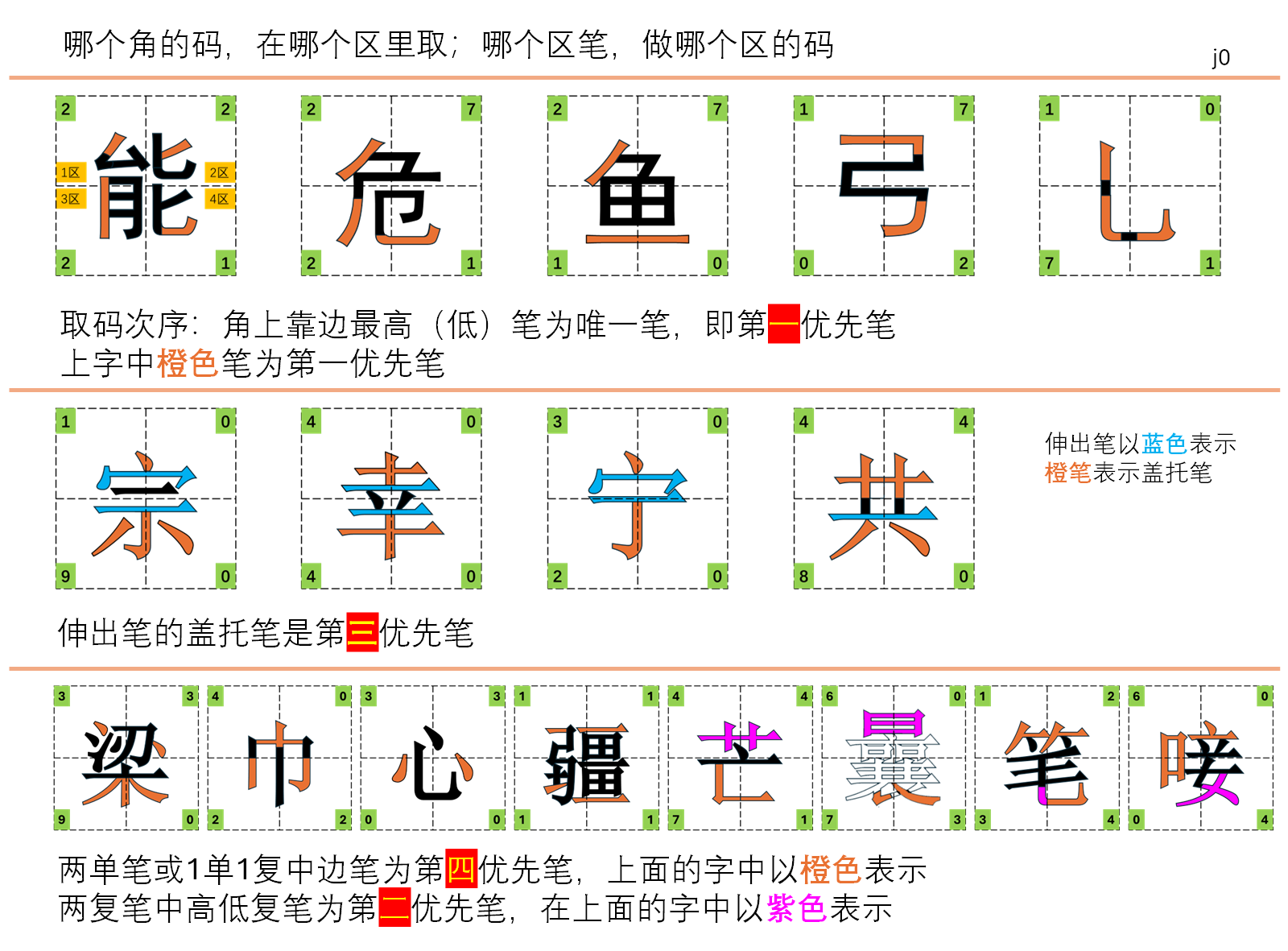转为pdf的效果:
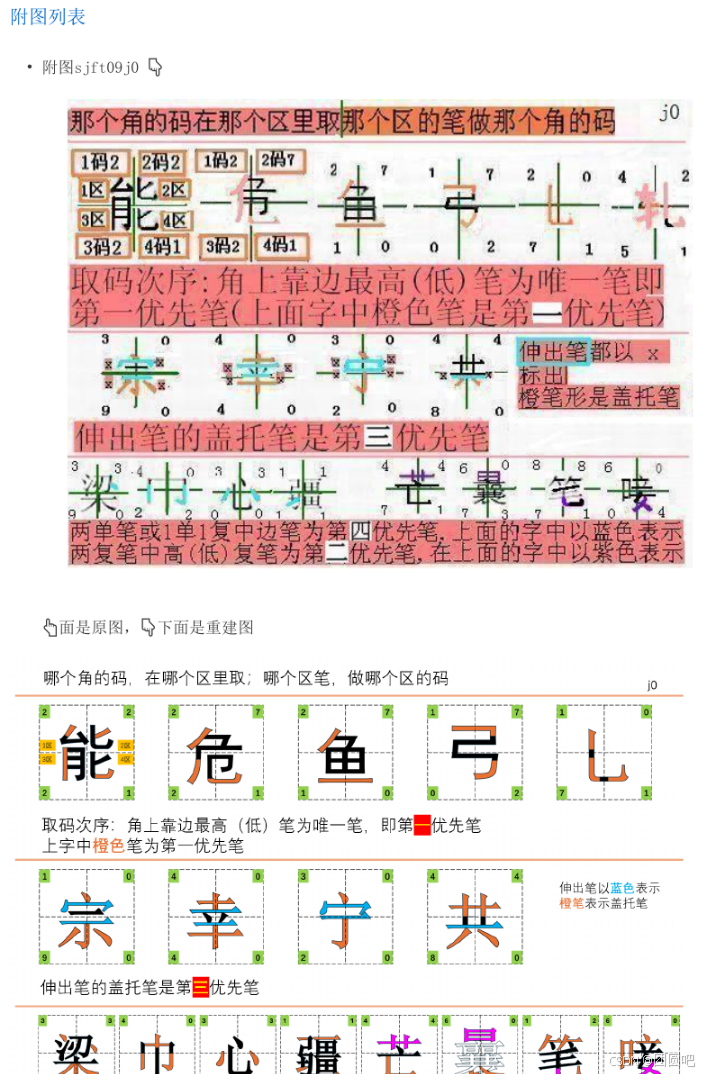
使用方法
使用这款脚本非常简单,只需以下几个步骤:
- 将脚本保存为 md2pdf.py
- 在命令行中运行:
python md2pdf.py --md 你的文档.md - 脚本会自动处理并在同一目录生成同名PDF文件
对于开发者,还可以通过修改CSS部分自定义PDF的样式,满足个性化需求。
总结
这款md2pdf.py脚本通过巧妙的技术组合,解决了Markdown转PDF过程中的诸多痛点。它不仅提供了开箱即用的便捷体验,还通过模块化设计保证了良好的可扩展性。无论是程序员分享代码文档,还是学生整理学习笔记,这款工具都能显著提升工作效率,让你的文档呈现更加专业美观。
如果你也经常需要处理Markdown到PDF的转换任务,不妨试试这款脚本,相信它会成为你日常工作中的得力助手。