在缓存架构设计中,除了缓存穿透,缓存击穿、缓存雪崩、热点数据一致性 是影响系统稳定性的核心痛点。本文将深入解析三种工业界常用的缓存优化方案 ------随机过期时间 、缓存预热 、热点数据永不过期 + 后台更新,从原理、实现、优缺点到适用场景,帮你精准解决缓存架构中的高频问题。
一、先明确:三个方案要解决的核心痛点
在讲解方案前,先理清背后要应对的问题:
- 缓存雪崩:大量缓存 Key 在同一时间过期,导致所有请求瞬间穿透到数据库,压垮数据库;
- 缓存击穿:某个热点 Key 过期瞬间,大量并发请求穿透到数据库,导致数据库短时间压力暴增;
- 热点数据一致性:高频访问的热点数据(如爆款商品、首页配置),既要保证缓存高性能,又要避免数据过期后出现的穿透 / 不一致问题。
下面三个方案分别针对这些痛点,从不同角度优化缓存稳定性。
二、随机过期时间:避免缓存雪崩的 "去中心化" 方案
核心原理
缓存雪崩的核心原因是 "大量缓存 Key 集中过期 "(比如同一时间批量写入的缓存,设置了相同的 TTL)。随机过期时间的思路是:在固定过期时间基础上,增加一个随机偏移量,让不同 Key 的过期时间分散开,避免集中失效。
本质是 "去中心化过期时间",将缓存失效的压力均匀分摊到不同时间点,避免数据库在某个瞬间面临洪峰请求。
实现逻辑
以 Cache Aside 策略为例,在设置缓存过期时间时,不使用固定值,而是通过 "基础 TTL + 随机值" 计算最终过期时间。
代码示例(Redis 实现)
java
String cacheKey = "product:1001"; // 热点商品Key
String productData = redis.get(cacheKey);
if (productData == null) {
// 缓存未命中,查询数据库
productData = db.query("SELECT * FROM products WHERE id=1001");
// 基础过期时间1小时(3600秒),随机偏移量0-600秒(10分钟)
int baseTtl = 3600;
int randomTtl = new Random().nextInt(600); // 0-599秒
int finalTtl = baseTtl + randomTtl;
// 设置随机过期时间的缓存
redis.setex(cacheKey, finalTtl, productData);
}
return productData;关键细节
- 随机偏移量选择 :偏移量过大可能导致缓存过期时间不可控,过小则无法有效分散过期时间。建议根据业务场景设置:
- 常规场景:偏移量为基础 TTL 的 10%-20%(如基础 1 小时,偏移 0-12 分钟);
- 高并发场景:偏移量可扩大到基础 TTL 的 30%-50%(如基础 2 小时,偏移 0-1 小时),进一步分散压力。
- 批量缓存写入场景:如果是批量初始化缓存(如凌晨同步商品数据),必须给每个 Key 设置随机过期时间,否则会导致所有 Key 在同一时间过期,引发雪崩。
- 与其他方案配合:随机过期时间是 "防御性方案",通常需要与缓存集群、数据库限流等方案配合,进一步提升稳定性。
优缺点分析
优点:
- 实现简单:仅需在设置 TTL 时增加随机逻辑,开发成本极低;
- 无额外开销:不增加缓存、数据库的资源占用,性能损耗可忽略;
- 效果直接:能从根本上避免缓存集中过期,防御缓存雪崩的效果显著;
- 兼容性强:适配所有缓存策略(Cache Aside、Read/Write Through 等)和缓存组件(Redis、Memcached)。
缺点:
- 无法解决缓存击穿:随机过期时间只能分散过期压力,无法应对单个热点 Key 过期后的并发穿透;
- 过期时间不可控:无法精准预测某个 Key 的过期时间,可能导致部分 Key 提前过期或过期延迟(但不影响业务,仅影响缓存命中率);
- 不适用于 "必须精准过期" 的场景:如限时活动商品(需在活动结束后立即过期),随机过期时间会导致过期时间偏差。
适用场景
- 批量缓存写入场景(如凌晨同步数据、批量初始化缓存);
- 缓存 Key 数量多、过期时间集中的场景;
- 对过期时间精度要求不高的业务(如商品详情、用户信息);
- 所有需要防御缓存雪崩的场景(几乎是缓存架构的 "标配" 方案)。
三、缓存预热:提升缓存命中率的 "前置加载" 方案
核心原理
缓存预热的思路是:在系统正式提供服务前(如上线前、流量低峰期),主动将热点数据加载到缓存中,避免用户请求时缓存未命中,导致大量穿透到数据库。
本质是 "提前填充缓存",让缓存在高流量到来前就处于 "饱和状态",最大化缓存命中率,减少数据库压力。
实现逻辑
缓存预热的核心是 "识别热点数据"+"批量加载到缓存",完整流程如下:
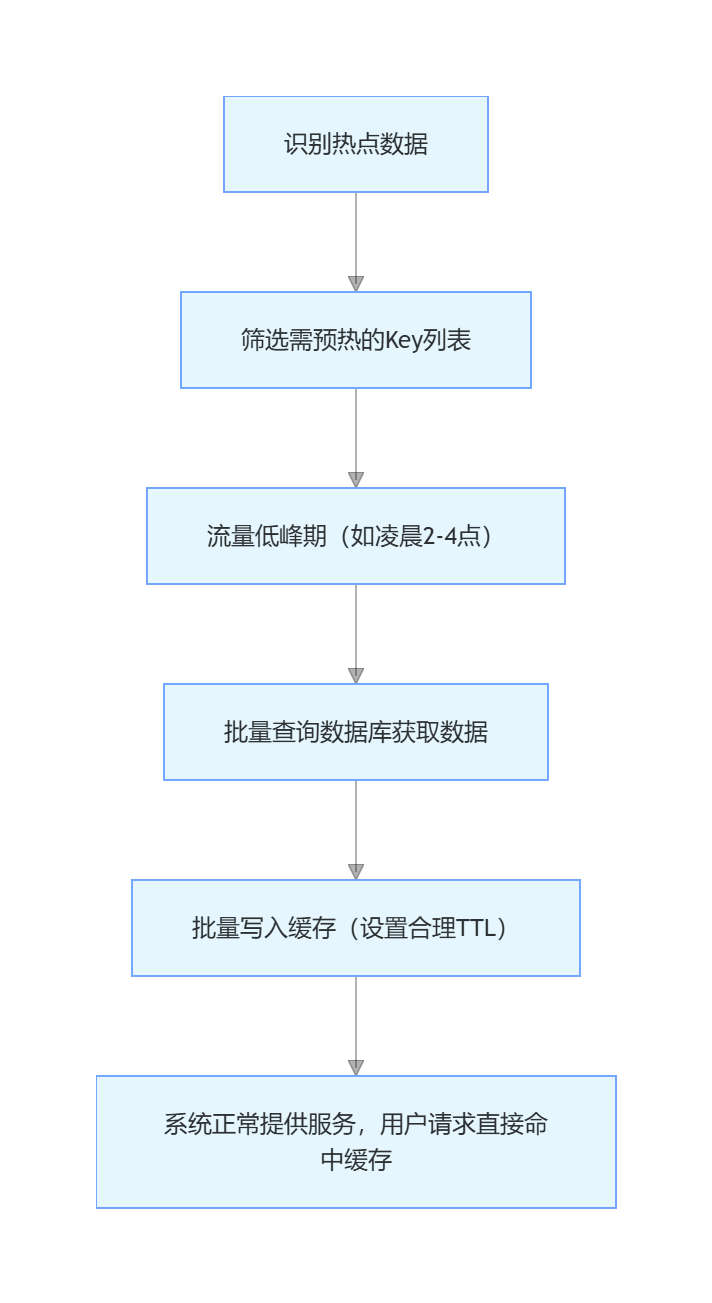
关键步骤拆解:
- 识别热点数据 :
- 历史日志分析:统计过去 1-7 天的高频查询 Key(如商品 ID、用户 ID);
- 业务预判:根据业务场景确定热点数据(如电商大促的爆款商品、首页推荐内容);
- 实时监控:通过缓存命中率、数据库查询频率,动态识别新增热点数据。
- 批量加载缓存 :
- 避免高并发加载:选择流量低峰期(如凌晨)执行预热脚本,避免预热过程中压垮数据库;
- 分批加载:如果热点数据量较大(如 100 万条),分批次(如每批 1 万条)加载,避免单次请求过多;
- 设置合理 TTL:预热时给缓存设置随机过期时间(配合上文方案),避免预热后的缓存集中过期。
代码示例(Java 预热脚本)
java
// 1. 识别热点商品ID(假设从历史日志中筛选出Top1000爆款商品)
List<Long> hotProductIds = getHotProductIds(); // 自定义方法:获取热点商品ID列表
// 2. 分批加载(每批100条)
int batchSize = 100;
for (int i = 0; i < hotProductIds.size(); i += batchSize) {
int end = Math.min(i + batchSize, hotProductIds.size());
List<Long> batchIds = hotProductIds.subList(i, end);
// 3. 批量查询数据库(避免循环单查,提升效率)
List<Product> products = db.batchQuery("SELECT * FROM products WHERE id IN (?)", batchIds);
// 4. 批量写入缓存(设置随机过期时间)
for (Product product : products) {
String cacheKey = "product:" + product.getId();
String productData = JSON.toJSONString(product);
int baseTtl = 3600 * 24; // 基础过期时间24小时
int randomTtl = new Random().nextInt(3600); // 随机偏移0-1小时
redis.setex(cacheKey, baseTtl + randomTtl, productData);
}
// 5. 休眠100ms,避免数据库压力过大
Thread.sleep(100);
}关键细节
- 避免预热期间影响线上服务 :
- 选择低峰期执行:如凌晨 2-4 点,此时用户请求少,数据库压力低;
- 控制预热速度:分批加载 + 休眠,避免单次批量查询导致数据库连接耗尽;
- 监控数据库状态:预热过程中实时监控数据库 CPU、IO、连接数,异常时暂停预热。
- 热点数据动态更新:缓存预热不是 "一劳永逸",需定期执行(如每天凌晨),或结合实时热点识别动态补充预热(如大促期间新增爆款商品)。
- 缓存预热失败处理:如果预热过程中数据库查询失败或缓存写入失败,需记录失败的 Key,后续重试,确保热点数据全部加载。
优缺点分析
优点:
- 大幅提升缓存命中率:预热后用户请求可直接命中缓存,减少数据库穿透;
- 平稳数据库压力:避免高流量到来时,大量请求同时穿透到数据库;
- 适配高并发场景:尤其适合电商大促、秒杀等流量突增的场景,提前做好缓存准备;
- 可结合业务预判:主动加载未来可能成为热点的数据(如即将上线的新品)。
缺点:
- 需额外开发维护:需要开发预热脚本、热点数据识别逻辑,增加维护成本;
- 占用缓存空间:预热会加载大量数据到缓存,需确保缓存容量充足(避免正常数据被淘汰);
- 热点数据识别难度:如果业务场景复杂,难以精准识别所有热点数据(可能遗漏部分热点,或加载非热点数据浪费资源);
- 不适用于动态热点场景:如果热点数据频繁变化(如实时热搜),预热效果有限,需配合动态缓存策略。
适用场景
- 流量集中的场景(如电商大促、秒杀、节假日峰值);
- 热点数据相对固定的场景(如爆款商品、首页配置、常用接口数据);
- 数据库性能较弱,无法承受大量穿透请求的场景;
- 对缓存命中率要求高(如要求 99% 以上)的业务。
四、热点数据永不过期 + 后台更新:解决缓存击穿的 "终极" 方案
核心原理
缓存击穿的核心是 "单个热点 Key 过期瞬间,大量并发请求穿透到数据库"。热点数据永不过期的思路是:
- 对热点数据设置 "逻辑永不过期"(不设置 TTL,或设置极长的 TTL,如 1 年),避免 Key 自动过期;
- 通过后台线程(定时任务)主动更新缓存数据,保证缓存中的数据与数据库一致。
本质是 "用后台定时更新替代自动过期",既避免了热点 Key 过期后的穿透,又保证了数据一致性。
实现逻辑
1. 缓存设置逻辑永不过期
- 方案一:不设置 TTL,Key 永久存在(需手动管理更新 / 删除);
- 方案二:设置极长 TTL(如 365 天),同时通过后台线程定期更新,避免 Key 过期。
2. 后台更新流程
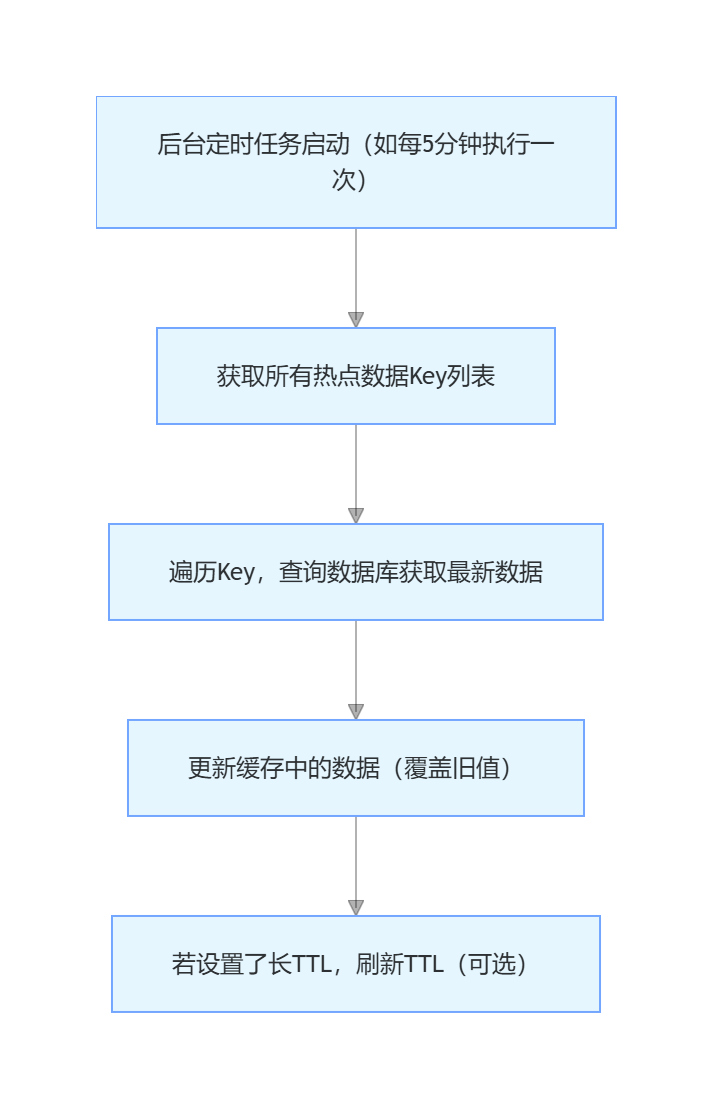
代码示例(Redis + 定时任务实现)
java
// 1. 热点数据缓存写入(逻辑永不过期)
String cacheKey = "hot:product:1001"; // 热点商品Key
String productData = db.query("SELECT * FROM products WHERE id=1001");
// 方案一:不设置TTL(永久存在)
redis.set(cacheKey, productData);
// 方案二:设置极长TTL(365天)
// redis.setex(cacheKey, 3600 * 24 * 365, productData);
// 2. 后台定时任务(Spring Schedule示例,每5分钟执行一次)
@Scheduled(cron = "0 0/5 * * * ?")
public void refreshHotDataCache() {
// 获取所有热点商品ID
List<Long> hotProductIds = getHotProductIds();
for (Long productId : hotProductIds) {
String cacheKey = "hot:product:" + productId;
// 查询数据库获取最新数据
String latestData = db.query("SELECT * FROM products WHERE id=?", productId);
// 更新缓存(覆盖旧值,保证一致性)
redis.set(cacheKey, latestData);
// 若设置了长TTL,刷新TTL(可选)
// redis.expire(cacheKey, 3600 * 24 * 365);
}
}关键细节
- 后台更新频率选择 :
- 数据变更频率高:更新频率可设短(如 1-5 分钟),保证数据一致性;
- 数据变更频率低:更新频率可设长(如 30 分钟 - 1 小时),减少数据库压力;
- 避免更新频率过高:过于频繁的后台更新会增加数据库压力,需平衡一致性和性能。
- 并发更新处理:如果后台线程是多线程执行,需避免同时更新同一个 Key(可能导致缓存写入冲突),可通过分布式锁或分段更新解决。
- 失效降级处理:如果后台线程更新失败(如数据库宕机),需记录失败的 Key,下次重试;同时前端可降级使用缓存中的旧数据(保证服务可用)。
- 热点数据范围控制:"永不过期" 的 Key 会一直占用缓存空间,需严格控制热点数据范围(如仅 Top100/Top1000 热点数据),避免缓存膨胀。
优缺点分析
优点:
- 彻底解决缓存击穿:热点 Key 永不过期,不会出现 "过期瞬间穿透" 的问题;
- 数据一致性可控:通过后台定时更新,可精准控制缓存数据的新鲜度;
- 缓存命中率 100%:热点数据始终存在于缓存中,用户请求无需等待数据库查询;
- 服务稳定性高:即使数据库短时间不可用,热点数据仍可从缓存中获取,提升服务可用性。
缺点:
- 缓存空间占用:热点数据永不过期,会持续占用缓存空间(需控制热点范围);
- 后台更新开销:定时任务会定期查询数据库,增加数据库的后台压力;
- 数据存在延迟:缓存数据的新鲜度取决于更新频率,存在 "缓存数据滞后于数据库" 的窗口(如 5 分钟内数据库数据变更,缓存未更新);
- 维护成本高:需要管理热点数据列表、定时任务、失败重试等逻辑,复杂度高于其他方案。
适用场景
- 核心热点数据(如爆款商品、首页 Banner、高频接口配置);
- 对缓存击穿敏感,无法承受热点 Key 过期后的穿透压力;
- 数据变更频率适中(可通过定时更新保证一致性);
- 对数据一致性要求不是 "实时",可接受短暂延迟(如 5 分钟内);
- 缓存空间充足,可容纳热点数据的场景。
五、三大方案核心对比与组合使用建议
核心对比表
| 对比维度 | 随机过期时间 | 缓存预热 | 热点数据永不过期 + 后台更新 |
|---|---|---|---|
| 核心解决问题 | 缓存雪崩(集中过期) | 缓存命中率低(冷启动 / 穿透) | 缓存击穿(热点 Key 过期穿透) |
| 实现复杂度 | 低(仅增加随机 TTL) | 中(热点识别 + 批量加载) | 高(定时任务 + 热点管理) |
| 缓存命中率 | 无直接提升(仅分散过期) | 大幅提升(提前填充) | 100%(热点数据始终存在) |
| 数据库压力 | 无额外压力 | 预热时增加低峰期压力 | 后台更新增加低峰期压力 |
| 数据一致性 | 依赖 TTL,无额外保障 | 依赖预热频率,存在延迟 | 依赖更新频率,存在延迟 |
| 缓存空间占用 | 无额外占用 | 增加(加载热点数据) | 增加(热点数据永不过期) |
| 适用数据类型 | 所有数据(批量过期场景) | 热点数据(相对固定) | 核心热点数据(少量、高频) |
组合使用建议(工业界最优实践)
三个方案并非互斥,而是互补的,组合使用可覆盖绝大多数缓存稳定性问题:
-
基础组合:随机过期时间 + 缓存预热
- 随机过期时间防御缓存雪崩;
- 缓存预热提升缓存命中率,减少穿透;
- 适用场景:大多数互联网业务(如电商商品、用户信息、接口数据)。
-
高并发核心场景组合:随机过期时间 + 缓存预热 + 热点数据永不过期
- 随机过期时间:分散普通数据的过期压力;
- 缓存预热:填充普通热点数据,提升整体命中率;
- 热点数据永不过期:保护核心热点数据(如爆款商品、秒杀商品),避免缓存击穿;
- 适用场景:电商大促、秒杀、节假日高流量场景。
-
组合流程示例(电商商品缓存):
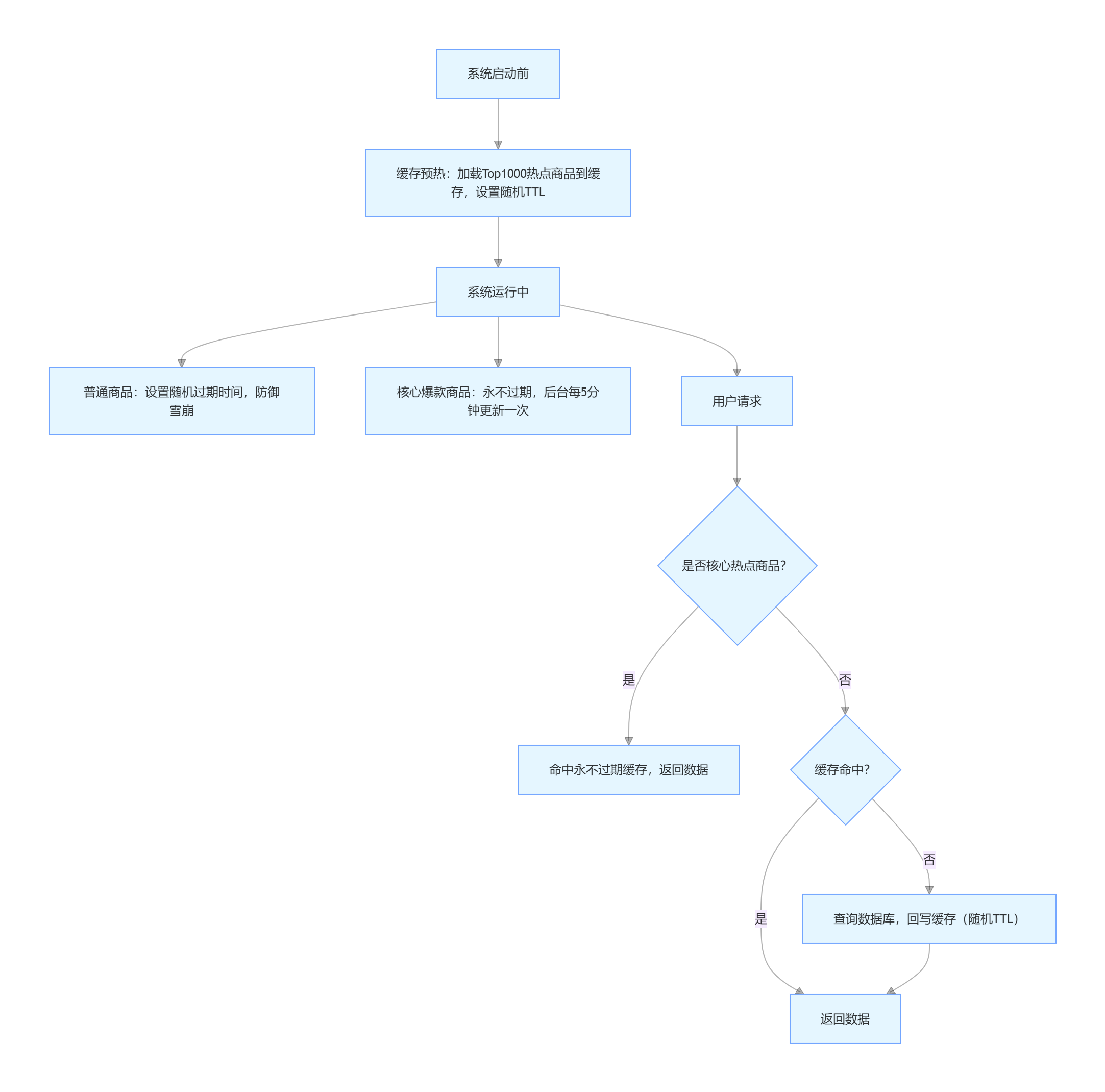
总结
缓存架构的稳定性设计,核心是 "提前防御" 和 "精准优化":
- 随机过期时间是 "基础防御",用最低成本避免缓存雪崩,是所有缓存架构的 "标配";
- 缓存预热是 "主动优化",通过前置加载提升命中率,适合流量集中的场景;
- 热点数据永不过期是 "核心保障",针对少量高频热点数据,彻底解决缓存击穿。
选型的核心原则是:根据数据的 "热度" 和 "变更频率" 分层优化------ 普通数据用随机过期时间,普通热点数据用缓存预热,核心热点数据用 "永不过期 + 后台更新"。
在实际开发中,无需过度设计,先落地 "随机过期时间" 这个最低成本的方案,再根据业务流量和数据库压力,逐步引入缓存预热和热点数据特殊处理,平衡开发成本和系统稳定性。