原文: https://mp.weixin.qq.com/s/dutPyteGCa9staazBion8A?scene=1&click_id=7
OpenAI拉响"红色警报",下周推新模型硬刚Gemini 3 pro
2025年12月2日,面对Google等竞争对手的压力,OpenAI拉响"红色警报",决定下周发布全新推理模型硬刚Gemini 3 pro。为此,OpenAI采取了一系列应对举措,包括暂停广告、AI Agent和Pulse项目,调配人力和算力资源修复和升级ChatGPT;将产品体验置于商业变现之上,推迟广告业务全面铺开,重点改善超8亿周活用户的核心体验与个性化服务,修补"模型行为";升级重点聚焦于更好的个性化、更快更可靠的响应速度、减少不必要的拒绝回答、改进模型行为,以让用户更倾向选择ChatGPT;还将图像生成列为重点项目,确保其在创意和商业用例中的竞争力。背后原因在于,尽管ChatGPT占据全球约70%的"助手活动"和约10%的搜索份额,但面临Google和Anthropic的围剿,需确立绝对优势实现营收快速增长(从100亿美元增至200亿,2027年达约350亿美元),以支撑约1000亿美元的融资需求。
Runway Gen-4.5发布:"视频生成AGI时刻"来袭!
2025年12月2日,Runway Gen - 4.5刷屏发布,被赞为"视频生成AGI时刻"。它在文本转视频基准测试中拿下SOTA,运镜、视角切换丝滑,复杂场景处理出色,细节丰富,两年迭代质感全面提升,难辨真实与AI生成内容。其功能强大,能执行复杂序列式指令,保留Gen - 4速度效率优势且画质突破,物理还原与视觉精准度高,适配多种控制模式。官方正逐步开放使用权限,未来几天所有用户可体验,"加量不加价"。不过,它在因果推理与物体恒存性方面存在不足,团队正在优化。
快手可灵AI「O1模型」实测:多模态视频与图片生成亮点多
在ChatGPT发布三周年且OpenAI无新内容发布之际,各大AI玩家纷纷行动,快手可灵宣布"一周连续上新",首日推出号称"全球首个统一多模态视频模型"的可灵AI视频「O1模型」,具备全能指令、全能参考、超多创意等功能亮点。测试显示,多图参考生成画面转场自然但AI对动词指令理解和特定地区数据学习不足,局部编辑能力出色,镜头延展和动作跟踪有一定表现但部分动作有缺失,还有OOTD换装等稳定玩法。次日又发布「图片」O1模型,在图片生成上表现不错。
拍我AI(PixVerse)V5.5:引领AI视频从素材生成迈向内容生成时代
拍我AI(PixVerse)V5.5更新带来AI视频生成领域重大突破。当前多数AI视频工具停留在「素材生成」阶段,存在画面破碎、静音、单一景别等问题,缺乏叙事能力。而拍我AI V5.5亮点显著,具备「导演思维」,能一键生成「分镜 + 音频」实现完整叙事;自带百万音效师,支持多角色音画同步,降低配乐配音门槛;可拿捏影视级镜头,摆脱「动态图片」标签。其应用场景广泛,对电影导演可作高效沟通工具,广告人能借此快速生成提案级别商业广告。该版本带来「叙事能力的觉醒」,推动AI视频从「素材生成」迈向「内容生成」时代,让创作者专注创意表达。
蔡浩宇新公司Anuttacon上线AnuNeko,或重塑游戏"制造"方式!
2025年12月1日,蔡浩宇在美国的AI新公司Anuttacon上线聊天产品"AnuNeko",名字结合其网络"说话带喵"习惯。该产品与主流AI不同,是针对未来游戏NPC的布局实验。交互特别,多日常对话,保持"真人感",擅长反问主导对话;有"Orange Cat"和"Exotic Shorthair"两种人格模型,回答意外;界面有评判按钮,团队或用早期数据训练模型。它砍掉联网搜索等,专注打磨性格和逻辑。Anuttacon约50人团队,一半是米哈游旧部,一半来自大厂。今年8月该公司曾发布语音AI互动实验游戏《群星低语》。AnuNeko可能只是开端,蔡浩宇或想做通用AI NPC生成平台改变游戏制作方式,但目前产品尚处早期,会胡言乱语,官方有免责声明。
英伟达推出Alpamayo-R1:让自动驾驶AI推理能力大升级
英伟达推出推理版VLA------Alpamayo-R1(AR1),旨在提升自动驾驶AI的推理能力。当前自动驾驶模型存在"想明白"的瓶颈,传统端到端系统在"长尾场景"表现不佳。AR1有多项核心创新,如引入因果链(CoC)数据集、采用扩散式轨迹解码器、实施多阶段训练策略等。实验显示,AR1在规划精度等方面有显著提升,尤其在"长尾场景",端到端延迟为99 ms。其输入经视觉编码成多模态token序列,CoC数据集采用"人机协同标注"。训练分监督微调、因果链监督、强化学习后训练优化三个阶段。未来,AR1将推动自动驾驶从"黑箱"到"白箱"转变。
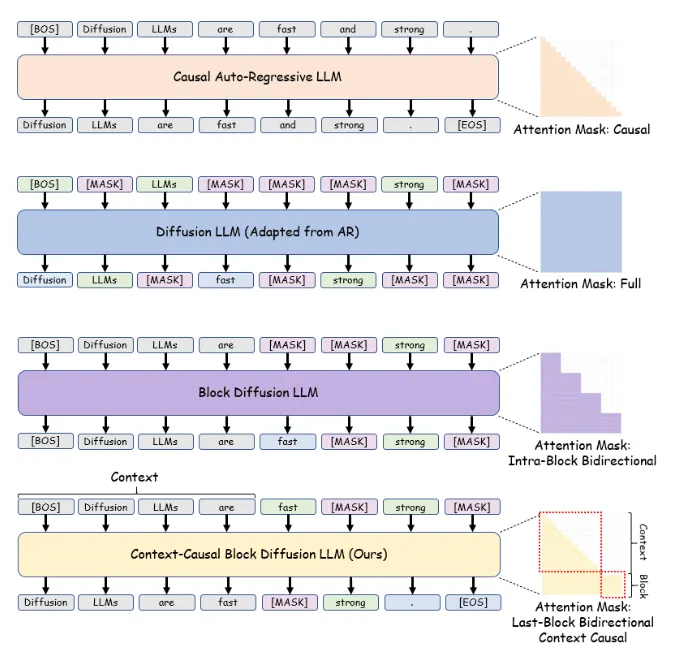
华为开源openPangu-R-7B-Diffusion:扩散语言模型新突破
华为新开源扩散语言模型openPangu-R-7B-Diffusion,今年文本生成领域正从自回归向扩散语言模型转变,但长序列训练不稳定和上下文窗口限制是扩散模型发展痛点。该模型基于openPangu-Embedded-7B少量数据续训练,将上下文长度扩展至32K,凭借"慢思考"能力在多学科知识、数学推理、代码生成等权威基准中创7B参数量级全新SOTA纪录。技术上,架构融合自回归的前文因果注意力掩码,消除适配壁垒、降低成本并继承预训练知识;训练与推理延续BlockDiffusion思路并优化,Context利用率达100%,有"自回归 + 扩散"双模式解码能力,并行解码速度最高达自回归解码的2.5倍。可视化实测中,输入数学逻辑推理题,模型4步内将MASK噪声去噪还原,Token标志"慢思考"模式启动。此模型发布回应了"扩散模型能否处理复杂长文本"难题,证明其可"快"可"深",且全流程在昇腾NPU集群完成,体现国产算力实力。
- Base模型链接:https://ai.gitcode.com/ascend-tribe/openPangu-7B-Diffusion-Base
- 慢思考模型链接:https://ai.gitcode.com/ascend-tribe/openPangu-R-7B-Diffusion
亚马逊云科技AWS re:Invent盛会发布多项重磅AI新品
智东西报道,亚马逊云科技(AWS)在年度云计算产业盛会AWS re:Invent上发布系列重磅AI新品。新基建方面,有采用英伟达GB300 NVL72系统、性能提升的P6e - GB300,满足企业私有化部署需求的AWS AI Factories,高性价比的Amazon EC2 Trainium3 UltraServers,以及预计性能大幅提升的下一代AI芯片Trainium4;新模型方面,Amazon Bedrock新增18款全托管开源模型,Nova 2系列首发4款不同特性模型;新服务方面,Amazon Nova Forge支持企业构建定制前沿模型;新工具方面,有设置agent行动边界的Policy in AgentCore预览版和监控分析Agent表现的AgentCore Evaluations全托管服务;新智能体方面,包含创建自定义代码转换智能体的AWS Transform Custom等4种智能体;还有7款新实例、6项Amazon S3存储升级等更新。
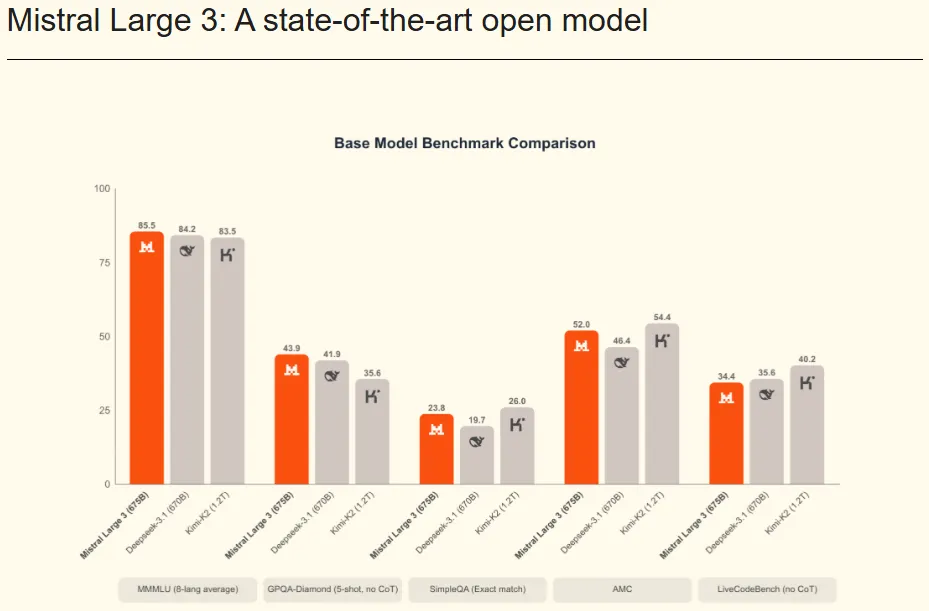
"欧洲的DeepSeek"Mistral AI发布Mistral 3系列开放模型
2025年12月3日,"欧洲的DeepSeek"Mistral AI发布新一代开放模型Mistral 3系列,全线采用Apache 2.0许可证。该系列包含Ministral 3(14B、8B、3B)和Mistral Large 3,前者号称"世界上最好的小型模型",有多种版本且性价比高,14B变体在AIME '25准确率达85%;后者是前沿级开源MoE,有图像理解和多语言对话能力,排名靠前。Mistral AI与vLLM、Red Hat、英伟达合作,提升模型运行和推理效率。模型即日起可在多个平台使用,即将在NVIDIA NIM和AWS SageMaker上线,还为组织提供定制服务。此外,Mistral此次回归Apache 2.0协议或受DeepSeek影响,是对其的正面追赶。
可灵2.6全量上线:首个音画同出模型震撼登场
2025年12月3日,可灵2.6全量上线并推出首个音画同出模型。该模型单次生成可同时产出画面、自然语音、匹配音效和环境氛围,打通"音""画"世界,且Web端与App端双端同步,方便创作。创作路径有文生音画(从一句话生成完整音视频)和图生音画(让静态画面开口说话、动起来,新手也能一键成片)。适配场景广泛,包括单人独白(如服装直播间主播展示卫衣)、旁白解说(如世界杯决赛赛场解说)、多人对白(如赌场VIP室男女对话)、音乐表演(如美裔rapper街头说唱)、创意场景(如直播桌面触发音场景)。目前官网介绍、论文、体验地址、Github、huggingface、下载地址均未提供。
阿里千问上线"最强"学习模型,免费功能对标OpenAI/谷歌!
据智东西2025年12月3日报道,阿里千问上线"最强"学习模型Qwen3-Learning,基于Qwen3训练。该模型面向学习场景发布拍题答疑、作业批改两项重要更新,功能对标OpenAI/谷歌付费功能且免费不限次。其独家资料库覆盖全学段、全学科,有海量真题和解析,答案准确率高,解题与批改能力强。从家长和学生角度,拍题答疑几秒出答案且步骤清晰,作业批改可整页多题同时进行,能识别不同字体还可总结答题情况;从大学生角度,它跨文理、能读图,可写专业论文,可准确识别复杂照片中的题目。此外,该模型结合多种能力,经针对性训练和适配可在工业检测、医疗辅助、金融分析等专业领域发挥价值。
理想AI眼镜Livis:轻快好兼具,开启AI眼镜新战局
理想汽车在AI眼镜领域的探索与布局。其推出的AI眼镜Livis亮点颇多,镜架仅重36克,为全球最轻,采用超轻新材料与超薄结构设计,且车控、抓拍、AI响应和充电速度快,还具备八大优势。研发方面,理想2020年开始相关研究,去年初判断可行后六七月份完成原型并立项,由歌尔负责生产且按汽车标准管控质量。战略上,AI眼镜是具身智能重要形态,发展分三步推进,应用策略短期内聚焦基础问题。理想加入AI眼镜战局,优势在于整合内部资源和车机联动体验,范皓宇预测"AI眼镜的iPhone时刻"或在2027 - 2028年到来。
2025 腾讯广告算法大赛收官:技术碰撞,推动行业进步
历时 4 个月的"腾讯广告算法大赛"落下帷幕,来自全球 30 个国家的 8400 多名技术精英、2800 余支战队参与其中,"Echoch""leejt""也许明天"战队分获前三甲,前十名全员获得鹅厂 Offer 意向书。本次大赛核心赛题为"全模态生成式推荐",直击广告行业痛点,腾讯提供了不同量级的脱敏"用户全模态序列"数据供选手挑战。选手们面临多模态噪声与缺失、超大规模稀疏 ID、冷启动、特征种类多且复杂等难题。冠军战队方案亮点十足,"Echoch"战队聚焦"生成式行为条件化建模","leejt"战队设计"Encoder-Decoder"架构,"也许明天"战队探讨广告推荐系统 Scaling Law。大赛在技术探索、人才培养、生态共建方面意义重大,选手采用"分布式"工业级做法处理数据,腾讯构建"以赛育才、以赛选才"生态,还将开源数据集推动多模态推荐领域进步。
OpenAI新模型、新功能与广告争议齐上阵,GPT-5.2发布引猜测
本周OpenAI动态不断,爆料称有四个"企鹅家族"神秘新模型在DesignArena测试,帝企鹅Emperor或为全新SOTA旗舰模型,发布时间未知;预计下一周推出代号"Shallotpeat"且领先谷歌Gemini 3的推理模型,代号"Garlic"的模型已完成预训练,预计明年初以GPT-5.2/GPT-5.5发布。同时,OpenAI推出"记忆搜索"功能优化ChatGPT体验,虽暂不可用但或在测试中。不过,ChatGPT推送广告引发付费用户争议,网友威胁若不能关闭广告将取消订阅。此外,许多人猜测OpenAI可能提速发布GPT-5.2,若记忆搜索和新模型前后脚上线,或借此抗压坐实ChatGPT"海量信息管理生产力工具"地位。
可灵数字人2.0全量上线,三大突破引领行业新高度
可灵数字人2.0于2025年12月4日23:00全量上线,用户在可灵官网即可体验其功能。通过上传角色图、添加配音内容、描述角色表现三步即可生成数字人。此次更新相比旧版有三大突破性改变:一是表现力显著提升,手部及口型精准控制,表演力全面进化,细节把控到位,告别AI感;二是打破时长限制,单次生成视频最长支持5分钟,适用于多种长内容场景;三是经多维度客观评测,效果胜负比综合得分远超同类产品,展现出行业领先实力。
火山引擎发布豆包图像创作模型Seedream 4.5,开启视觉创作新体验
2025年12月3日19:39,火山引擎正式发布豆包图像创作模型Seedream 4.5并开启公测。该模型升级亮点包括强化多图组合生成能力、优化海报排版与Logo设计功能,支持高精度图文混排,还全面支持多领域核心场景应用。其能力特性有极致一致性、精准指令遵循、通识与空间重构和电影级美学。在广告营销、电商运营、影视创作等场景能发挥重要作用,降低视觉创作门槛。
Meta挖角苹果大将,AI人才战升级
2025年12月4日,Meta首席执行官马克·扎克伯格官宣苹果人机交互设计副总裁艾伦·戴伊将加入Meta,12月31日起正式担任Meta首席设计官,其副手比利·索伦蒂诺也会一同加入。戴伊在苹果工作19年,参与过众多重要产品设计。Meta为其建立新设计工作室,他将负责硬件、软件及AI界面整合设计。今年苹果人事变动频繁,除戴伊外,还有AI业务主管等多位核心人员离职。此次人事变动体现了硅谷AI人才争夺战激烈,Meta全力押注AI硬件和超级智能,而苹果新品研发因核心成员流失面临更多不确定性。消息来源为彭博社、X、Instagram。
OpenAI新研究:让GPT-5-Thinking学会忏悔以解决大模型撒谎问题
OpenAI在GPT-5-Thinking上开展忏悔训练(Confessions)研究,旨在解决大模型撒谎问题。核心思路是让模型回答问题后生成"忏悔报告",实验显示在该模型上有效,"忏悔"比"原回答"诚实且不影响原任务表现。具体方法借鉴宗教告解室,关键在于奖励信号隔离,以25%概率进行告解训练。在12个诱发不良行为的评估数据集上测试,模型违规时忏悔承认概率高,"假阴性"概率仅4.36% ,训练后在部分评估上准确率提升但事实类幻觉评估改进有限。失败案例分析指出假阴性和假阳性原因,该方法存在不能阻止不良行为等局限性。未来OpenAI将其定位为监控和诊断工具,计划扩大训练规模并与其他安全技术配合使用。
杭州瞳行科技发布国内首款AI助盲眼镜,为视障人士出行带来新希望
在2025年12月3日国际残疾人日,杭州瞳行科技公司发布国内首款基于通义千问Qwen-VL、OCR等系列模型打造的AI助盲眼镜。该眼镜具有出行避障、找物读物等功能,出行场景能实现300ms超低延迟并每步给出道路提示。鉴于中国超1700万视力障碍人士出行存在诸多难题且缺乏普及助盲工具的背景,瞳行将自研视觉模型与通义千问结合,配合硬件打造低延时避障能力并针对不同场景调优模型。产品由眼镜主体、手机、遥控指环、盲杖四部分组成,已正式面市,借助通义千问可快速实现所需功能得益于大模型降低了算力成本。