目录
[一.SQLite3 C/C++ API 介绍](#一.SQLite3 C/C++ API 介绍)
SQLite 是一个遵循 ACID 特性的嵌入式关系型数据库引擎。
它的核心特点是作为一个进程内库运行,而不是一个独立的客户端-服务器数据库系统。
这意味着 SQLite 的数据库引擎被直接链接到应用程序中,成为应用程序的一部分。整个数据库(包括定义、表、数据和索引)完全存储在一个独立的、跨平台的标准磁盘文件中。应用程序通过直接调用 SQLite 库的 API 来读写这个文件,无需任何中介的服务器进程。
由于其设计简洁、可靠且无需外部依赖,SQLite 已成为全球部署最广泛的数据库引擎,内嵌于无数的应用程序、操作系统和嵌入式设备中。
选择 SQLite 的主要原因:
- 无服务器架构 (Serverless)
- 工作机制:与传统数据库(如 MySQL、PostgreSQL)不同,SQLite 没有单独的、需要启动和管理的数据库服务器进程。应用程序通过调用 SQLite 库(一个 .dll、.so 或 .dylib 文件)中的函数,直接与数据库文件进行交互。
- 优势:这极大地简化了部署和维护。您只需分发您的应用程序和数据库文件,无需在用户环境中安装、配置或维护一个数据库服务。这也减少了系统资源的开销和潜在的复杂性。
- 零配置 (Zero-Configuration)
- 具体表现:要开始使用 SQLite,您不需要进行任何"安装数据库系统"的操作。没有服务需要注册,没有配置文件需要编辑,也没有管理员账户需要创建。在代码中,您只需要指定一个文件路径(例如 myapp.db),如果文件不存在,SQLite 会自动创建它。
- 优势:这使得开发、测试和部署变得极其简单快捷,尤其适合原型开发、单机应用和嵌入式系统。
- 单一文件数据库 (Single-File Database)
- 存储方式:SQLite 将整个数据库(表结构、数据、索引、触发器、视图等,以及用于保障事务安全的日志信息)存储在一个普通的操作系统文件中。这个文件可以放在任何目录下,并像其他文件一样被复制、移动或备份。
- 优势:便携性极佳。迁移数据库只需拷贝一个文件。备份也简化为了文件备份。这种透明性让开发者能直观地理解和管理数据存储。
- 轻量级与紧凑性 (Lightweight & Compact)
- 量化说明:SQLite 的核心库代码体积非常小。在完整编译所有可选功能的情况下,其大小通常小于 500KB;如果仅启用核心功能,库文件可以缩小到 300KB 以下。运行时内存占用也较少。
- 优势:这种轻量级特性使其非常适合资源受限的环境,如移动应用(iOS/Android)、嵌入式设备(IoT)、小型桌面工具,或作为大型应用程序的本地缓存存储。
- 自给自足与无依赖性 (Self-Contained)
- 技术细节:SQLite 使用 ANSI-C 编写,其源代码不依赖于任何外部库(除标准 C 库外)。整个数据库引擎的逻辑,包括 SQL 编译器、虚拟机、B-tree 存储引擎和页面缓存,都包含在一个库文件中。
- 优势:确保了高度的可移植性和可靠性。您可以在几乎任何平台上编译和运行 SQLite,无需担心系统缺少特定的依赖项。
- 完整的 ACID 事务 (Fully ACID-Compliant Transactions)
- ACID 详解:
- 原子性:一个事务中的所有操作要么全部完成,要么全部不生效,即使系统发生崩溃或断电。
- 一致性:事务确保数据库从一个一致的状态转换到另一个一致的状态。
- 隔离性:SQLite 默认使用 串行化 隔离级别,这意味着在某一时刻,只有一个写操作可以访问数据库文件,从而确保了最高级别的数据一致性。它也支持通过"预写日志"模式实现更高级的并发读/写。
- 持久性:一旦事务提交,其对数据的修改就是永久性的,即使后续发生系统故障。
- 优势:这保证了数据的完整性和可靠性,即使在多线程或多进程环境下,也能安全地进行数据操作。
- 广泛的 SQL 支持 (Broad SQL Support)
- 能力范围:虽然名为 "SQLite",但它支持绝大部分 SQL-92 标准的核心特性,包括:
- 复杂的 SELECT 查询(含连接、子查询、聚合函数)。
- CREATE, ALTER, DROP 表与索引。
- INSERT, UPDATE, DELETE 数据操作。
- 触发器(Trigger)和视图(View)。
- 事务控制 (BEGIN, COMMIT, ROLLBACK)。
- 它支持大多数常见的数据类型(如 INTEGER, REAL, TEXT, BLOB, NULL)。
- 易于使用的 API (Simple API)
- 接口设计:SQLite 提供的 C语言 API 清晰且直观,通常只需几个核心函数(如 sqlite3_open, sqlite3_exec, sqlite3_prepare_v2, sqlite3_step, sqlite3_close)即可完成大部分工作。围绕这个核心 C API,社区为几乎所有编程语言(如 Python, Java, C#, PHP, JavaScript 等)提供了成熟、易用的封装接口。
- 优势:学习曲线平缓,开发者可以快速上手并集成到项目中。
- 卓越的跨平台性 (Cross-Platform)
- 运行环境:SQLite 几乎可以在所有现代操作系统上运行,包括 Windows, Linux, macOS, Android, iOS,以及各种 Unix 变体和嵌入式实时操作系统。数据库文件本身在不同平台间也是兼容的。
- 优势:使用 SQLite 开发的应用可以无缝地跨平台部署,数据文件可以在不同系统间直接交换使用。
典型应用场景
- 移动应用:作为本地数据存储(通讯录、聊天记录、应用配置)。
- 嵌入式系统与物联网设备:存储设备配置、日志和采集的数据。
- 桌面软件:存储用户数据、历史记录和缓存。
- 网站:作为低流量小型网站的数据库,或用作应用内的本地缓存数据库。
- 数据分析与数据处理:作为中间格式,方便地导入、导出和查询数据文件。
- 应用程序文件格式:许多应用程序使用 SQLite 数据库文件作为其私有文档格式(如 .db, .sqlite 文件)。
需注意的局限性
SQLite 并非适用于所有场景,以下情况不适合使用 SQLite:
- 高并发写操作:当存在大量需要同时写入数据库的客户端时(如大型网站后端),其文件锁机制可能成为瓶颈。
- 超大规模数据集:虽然理论上支持 TB 级数据库,但单个文件存储所有数据在管理和备份上可能变得笨拙。
- 需要网络访问的数据库:SQLite 是一个本地文件数据库,不原生支持通过网络协议进行远程访问。客户端-服务器数据库(如 PostgreSQL)在这方面是更佳选择。
- 需要高级数据库功能:如存储过程、自定义函数、复杂的用户权限管理系统等。
一.SQLite3 C/C++ API 介绍
C/C++ API是SQLite3数据库的一个客户端, 提供一种用C/C++操作数据库的方法。
我们可以去官网看看:List Of SQLite Functions
1.1.sqlite3_threadsafe()
函数定义与作用
int sqlite3_threadsafe(void);这是一个运行时查询函数,用于在程序运行时检查当前链接的 SQLite 库在编译阶段是否启用了线程安全特性。
返回值说明
- 返回 0:表示 SQLite 库编译时完全禁用了所有线程安全机制
- 返回 1 或 2:表示 SQLite 库编译时启用了线程安全支持
二、SQLite 的三种线程安全模式详解
- 模式一:单线程模式(非线程安全)
- 在这种模式下,SQLite 库完全不包含任何与线程同步相关的代码
- 所有内部的互斥锁(mutex)、临界区(critical section)等同步原语都被排除在编译之外
- 数据库连接句柄(sqlite3*)绝对不能在多个线程间共享
典型应用场景:
- 单线程应用程序
- 嵌入式设备中确定只有一个执行线程
- 对性能要求极高且可保证单线程访问的场景
- 模式二:多线程模式(线程安全,连接隔离)
技术细节:
- SQLite 库包含完整的线程同步代码
- 核心规则:一个数据库连接(sqlite3* 句柄)只能由创建它的线程使用
- 不同线程可以同时操作不同的数据库连接
- SQLite 内部使用互斥锁保护共享数据结构
线程使用规则表:
| 操作 | 是否允许 | 说明 |
|---|---|---|
| 线程A创建连接,线程A使用 | ✅ 允许 | 正常使用 |
| 线程A创建连接,线程B使用 | ❌ 禁止 | 违反规则 |
| 线程A创建连接A,线程B创建连接B | ✅ 允许 | 各自使用自己的连接 |
- 模式三:串行化模式(完全线程安全)
技术细节:
- 这是最严格的线程安全模式
- 允许同一个数据库连接在多个线程间共享
- SQLite 内部使用更细粒度的锁机制,确保所有操作串行执行
- 性能相比模式二有所降低,因为需要更多的锁操作
关键特性:
- 多个线程可以安全地使用同一个 sqlite3* 句柄
- SQLite 保证所有数据库操作是原子的、顺序执行的
- 应用程序不需要额外的同步机制来保护 SQLite 调用
1.2.sqlite3_open函数
函数原型:
int sqlite3_open(
const char *filename, /* 数据库文件名(UTF-8) */
sqlite3 **ppDb /* 输出参数:返回的数据库连接句柄 */
);功能:
这个函数用于打开一个SQLite数据库文件,并返回一个数据库连接句柄。如果指定的文件不存在,且没有设置其他限制,SQLite会创建一个新的数据库文件。
参数说明:
-
filename :数据库文件的路径。如果文件名是**:memory:** ,则表示在内存中创建一个临时数据库(只在当前连接的生命周期内存在)。如果文件名是空字符串"",则会创建一个临时的磁盘数据库(当连接关闭时会被删除)。
-
ppDb :一个指向
sqlite3*指针的指针。这个是一个输出型参数 ,函数将把打开的数据库连接的句柄写入这个指针。
返回值:
-
返回
SQLITE_OK(即0)表示成功。 -
如果发生错误,则返回一个错误代码(非零值),此时
*ppDb可能会被设置为一个错误句柄,可以通过sqlite3_errmsg()函数获取错误描述。
工作方式:
-
当调用
sqlite3_open时,SQLite会尝试打开或创建指定的数据库文件。 -
如果文件路径不存在,且目录可写,SQLite会创建一个新的数据库文件。
-
如果文件路径存在,SQLite会尝试打开它,并验证它是否是一个有效的SQLite数据库文件(除非使用了其他选项,如
SQLITE_OPEN_CREATE,否则不会自动创建)。
注意:
-
如果文件名是NULL,则行为是未定义的。
-
即使打开失败,也应该调用
sqlite3_close来关闭句柄,以释放资源。
示例代码:
cpp
#include <stdio.h>
#include <sqlite3.h>
int main() {
sqlite3 *db;
int rc;
rc = sqlite3_open("test.db", &db);
if (rc != SQLITE_OK) {
fprintf(stderr, "无法打开数据库: %s\n", sqlite3_errmsg(db));
sqlite3_close(db);
return 1;
}
printf("数据库打开成功\n");
// ... 使用数据库进行各种操作 ...
sqlite3_close(db);
return 0;
}然后我们直接编译运行

非常的完美
1.3.sqlite3_open_v2函数
函数原型:
cpp
int sqlite3_open_v2(
const char *filename, /* 数据库文件名(UTF-8) */
sqlite3 **ppDb, /* 输出参数:返回的数据库连接句柄 */
int flags, /* 标志位,控制打开行为 */
const char *zVfs /* 使用的VFS模块的名称,如果为NULL则使用默认 */
);功能:
这个函数是sqlite3_open的增强版本,允许通过flags参数指定更多的打开选项,并且可以选择使用特定的VFS(虚拟文件系统)模块。
参数说明:
-
filename :数据库文件的路径。如果文件名是**:memory:** ,则表示在内存中创建一个临时数据库(只在当前连接的生命周期内存在)。如果文件名是空字符串"",则会创建一个临时的磁盘数据库(当连接关闭时会被删除)。
-
ppDb :一个指向
sqlite3*指针的指针。这个是一个输出型参数 ,函数将把打开的数据库连接的句柄写入这个指针。 -
flags :一个整数,由多个标志位通过按位或(
|)组合而成,用于控制数据库的打开方式。常用的标志位包括:-
SQLITE_OPEN_READONLY:以只读方式打开数据库。 -
SQLITE_OPEN_READWRITE:以可读可写方式打开数据库,但如果文件不存在,不会自动创建。 -
SQLITE_OPEN_CREATE:如果数据库文件不存在,则创建它。必须与SQLITE_OPEN_READWRITE一起使用。 -
SQLITE_OPEN_NOMUTEX:**以多线程模式打开数据库连接,即连接句柄不能在多个线程间共享(每个线程必须使用自己的连接)。**但是,如果多个线程使用不同的连接,它们可以同时访问数据库。 -
SQLITE_OPEN_FULLMUTEX:以串行化模式打开数据库连接,允许连接句柄在多个线程间共享(但需要应用程序自己管理线程同步,实际上SQLite会保证同一时间只有一个线程使用该连接执行操作)。 -
还有其他一些标志,如
SQLITE_OPEN_URI、SQLITE_OPEN_MEMORY等,但以上是最常用的。
-
-
zVfs:指定要使用的VFS模块的名称。如果为NULL,则使用默认的VFS。
返回值:
-
返回
SQLITE_OK(即0)表示成功。 -
如果发生错误,则返回一个错误代码(非零值),此时
*ppDb可能会被设置为一个错误句柄,可以通过sqlite3_errmsg()函数获取错误描述。
工作方式:
-
根据
flags参数的要求打开或创建数据库。 -
如果
flags中指定了SQLITE_OPEN_CREATE,则当文件不存在时会创建新文件;否则,文件必须存在,否则打开失败。 -
线程安全模式的选择:
-
使用
SQLITE_OPEN_NOMUTEX:打开的连接句柄不能在多个线程间共享,但不同的连接可以在不同的线程中同时使用(前提是SQLite编译时启用了线程安全)。 -
使用
SQLITE_OPEN_FULLMUTEX:打开的连接句柄可以在多个线程间共享,但同一时间只能有一个线程使用该连接执行操作。
-
注意:
-
如果同时指定了
SQLITE_OPEN_READWRITE和SQLITE_OPEN_CREATE,则当文件不存在时会创建新文件,如果文件存在则正常打开。 -
如果只指定了
SQLITE_OPEN_READWRITE,而文件不存在,则打开失败。 -
线程安全模式的选择需要根据应用程序的需求。如果每个线程使用独立的连接,那么使用
SQLITE_OPEN_NOMUTEX(多线程模式)可以获得更好的性能。如果需要在多个线程间共享同一个连接,则必须使用SQLITE_OPEN_FULLMUTEX(串行化模式)。
示例代码:
示例1:以可读可写方式打开,如果不存在则创建
cpp
#include <stdio.h>
#include <sqlite3.h>
int main() {
sqlite3 *db;
int flags = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE;
int rc = sqlite3_open_v2("test.db", &db, flags, NULL);
if (rc != SQLITE_OK) {
fprintf(stderr, "无法打开数据库: %s\n", sqlite3_errmsg(db));
sqlite3_close(db);
return 1;
}
printf("数据库打开成功\n");
// ... 使用数据库进行各种操作 ...
sqlite3_close(db);
return 0;
}
示例2:以只读方式打开
cpp
sqlite3 *db;
int flags = SQLITE_OPEN_READONLY;
int rc = sqlite3_open_v2("test.db", &db, flags, NULL);
if (rc != SQLITE_OK) {
// 错误处理
}
示例3:以多线程模式打开(连接不能跨线程共享)
cpp
sqlite3 *db;
int flags = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | SQLITE_OPEN_NOMUTEX;
int rc = sqlite3_open_v2("test.db", &db, flags, NULL);
if (rc != SQLITE_OK) {
// 错误处理
}示例4:以串行化模式打开(连接可以跨线程共享,但需要串行使用)
cpp
sqlite3 *db;
int flags = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | SQLITE_OPEN_FULLMUTEX;
int rc = sqlite3_open_v2("test.db", &db, flags, NULL);
if (rc != SQLITE_OK) {
// 错误处理
}三、关于线程安全模式的补充说明
-
多线程模式(
SQLITE_OPEN_NOMUTEX):-
连接句柄只能由打开它的线程使用。
-
不同线程可以使用不同的连接句柄同时访问同一个数据库文件。
-
这种模式下,SQLite内部会使用较少的锁,因此性能更高。
-
-
串行化模式(
SQLITE_OPEN_FULLMUTEX):-
连接句柄可以在多个线程间传递,但同一时间只能有一个线程使用该连接执行操作。
-
这种模式下,SQLite内部会使用更多的锁来确保线程安全,因此性能稍低。
-
1.4.sqlite3_exec函数
sqlite3_exec 是 SQLite 库中用于执行 SQL 语句的函数。
它特别适合于执行不需要返回数据的 SQL 语句(如 INSERT、UPDATE、DELETE),但也可以用于执行查询语句(SELECT)并处理结果。
函数原型:
cpp
int sqlite3_exec(
sqlite3* db, /* 一个打开的数据库句柄 */
const char *sql, /* 要执行的SQL语句 */
int (*callback)(void*, int, char**, char**), /* 回调函数,用于处理查询结果 */
void *arg, /* 传递给回调函数的第一个参数 */
char **errmsg /* 错误信息指针的地址 */
);参数详解
sqlite3* db
- 这是一个已经打开的数据库连接句柄。它来自于之前调用 sqlite3_open 或 sqlite3_open_v2 获取的。所有操作都将在这个数据库连接上执行。
const char *sql
- 这是一个字符串,包含要执行的一条或多条SQL语句。多条语句之间可以用分号(;)分隔。注意,虽然可以执行多条,但一般不推荐,因为这样容易受到SQL注入攻击(如果SQL来自用户输入)。而且,如果其中一条语句失败,则后面的语句不会执行。
int (*callback)(void*, int, char**, char**)
这是一个函数指针,指向一个回调函数。**当执行SELECT等返回数据的SQL语句时,sqlite3_exec会为结果集中的每一行调用一次这个回调函数。**如果你执行的不是返回数据的语句(如INSERT, UPDATE, DELETE, CREATE等),则不会调用回调函数,可以传入NULL。
注意这个回调函数是系统在调用,不是我们手工调用的!!!
回调函数的参数和返回值如下:
- 第一个参数:由sqlite3_exec的第四个参数(void *arg)传递过来,你可以用它来传递任何数据给回调函数。
- 第二个参数:表示这一行有多少个列(字段)。
- 第三个参数:是一个字符串数组,表示这一行每一列的数据(以字符串形式,即使列类型不是字符串)。
- 第四个参数:是一个字符串数组,表示每一列的列名(字段名)。
- 返回值:回调函数应该返回0。如果返回非零,sqlite3_exec将中断执行并返回SQLITE_ABORT。
void *arg
- 这个参数会作为回调函数的第一个参数传递。你可以用它来传递任意数据给回调函数,比如一个结构体指针,这样在回调函数内部就可以访问到这个结构体。如果不需要传递,可以传入NULL。
char **errmsg
- 这是一个指向字符指针的指针,用于获取错误信息。如果执行过程中发生错误,sqlite3_exec会分配一段内存来存储错误描述字符串(通过sqlite3_malloc),并将错误字符串的地址赋值给*errmsg。因此,调用者需要负责使用sqlite3_free来释放这段内存。如果没有错误,*errmsg会被设置为NULL。
返回值
- 函数返回一个整数,表示执行的状态。如果成功,返回SQLITE_OK(即0);如果出现错误,则返回对应的错误代码(如SQLITE_ERROR等)。
话不多说,我们直接看例子
不会调用回调函数的实例
如果你执行的不是返回数据的语句(如INSERT, UPDATE, DELETE, CREATE等),则系统不会调用回调函数,可以传入NULL。
实例1:最简单的创建表操作
cpp
#include <stdio.h>
#include <sqlite3.h>
int main() {
sqlite3 *db;
char *errmsg = NULL;
// 打开或创建数据库
if(sqlite3_open("my.db", &db) != SQLITE_OK) {
printf("打开数据库失败\n");
return -1;
}
// 创建表(不需要回调函数,所以设为NULL)
const char *sql = "CREATE TABLE IF NOT EXISTS student(id INTEGER PRIMARY KEY, name TEXT, score REAL);";
if(sqlite3_exec(db, sql, NULL, NULL, &errmsg) != SQLITE_OK) {
printf("SQL错误: %s\n", errmsg);
sqlite3_free(errmsg);
} else {
printf("创建表成功!\n");
}
sqlite3_close(db);
return 0;
}
实例2:插入数据
cpp
#include <stdio.h>
#include <sqlite3.h>
int main() {
sqlite3 *db;
char *errmsg = NULL;
sqlite3_open("my.db", &db);
// 插入一条记录
const char *sql = "INSERT INTO student(name, score) VALUES('小明', 85.5);";
if(sqlite3_exec(db, sql, NULL, NULL, &errmsg) != SQLITE_OK) {
printf("插入失败: %s\n", errmsg);
sqlite3_free(errmsg);
} else {
printf("插入成功!\n");
}
sqlite3_close(db);
return 0;
}
实例3:批量执行多条SQL语句
cpp
#include <stdio.h>
#include <sqlite3.h>
int main() {
sqlite3 *db;
char *errmsg = NULL;
sqlite3_open("my.db", &db);
// 多条SQL语句,用分号分隔
const char *sql =
"INSERT INTO student(name, score) VALUES('小红', 92.0);"
"INSERT INTO student(name, score) VALUES('小刚', 78.5);"
"UPDATE student SET score = 88.0 WHERE name = '小明';";
if(sqlite3_exec(db, sql, NULL, NULL, &errmsg) != SQLITE_OK) {
printf("执行失败: %s\n", errmsg);
sqlite3_free(errmsg);
} else {
printf("批量执行成功!\n");
}
sqlite3_close(db);
return 0;
}
会调用回调函数的实例
当执行SELECT等返回数据的SQL语句时,sqlite3_exec会为结果集中的每一行调用一次这个回调函数。
首先我们要明白,这个sqlite3_exec()只有第4个参数是作为回调函数第一个参数的
回调函数也不是我们手动去调用的,而是系统在调用的!!
那么回调函数其余参数都是系统自己在填充的!!!我们直接拿来使用即可
实例1:简单查询(使用回调)
cpp
#include <stdio.h>
#include <sqlite3.h>
// 最简单的回调函数
int my_callback(void *data, int argc, char **argv, char **col_names) {
// argc: 列数
// argv: 每列的值
// col_names: 每列的字段名
for(int i = 0; i < argc; i++) {
printf("%s: %s ", col_names[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0; // 必须返回0
}
int main() {
sqlite3 *db;
char *errmsg = NULL;
sqlite3_open("my.db", &db);
// 查询所有学生
const char *sql = "SELECT * FROM student;";
printf("查询结果:\n");
printf("==========\n");
if(sqlite3_exec(db, sql, my_callback, NULL, &errmsg) != SQLITE_OK) {
printf("查询失败: %s\n", errmsg);
sqlite3_free(errmsg);
}
sqlite3_close(db);
return 0;
}
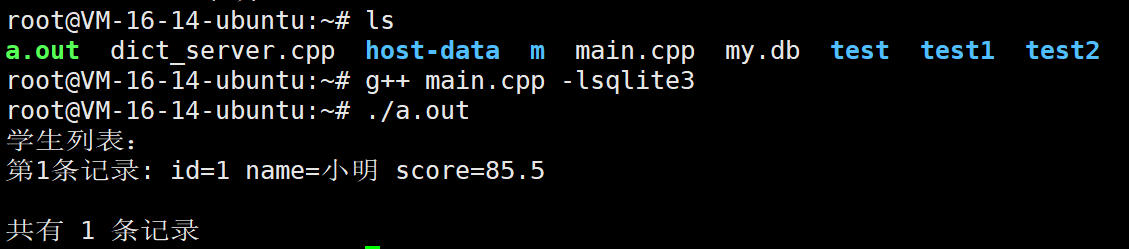
实例2:使用arg参数传递数据
cpp
#include <stdio.h>
#include <sqlite3.h>
int callback(void *data, int argc, char **argv, char **col_names) {
int *count = (int*)data; // 传入的计数变量
printf("第%d条记录: ", (*count) + 1);
for(int i = 0; i < argc; i++) {
printf("%s=%s ", col_names[i], argv[i]);
}
printf("\n");
(*count)++; // 记录数加1
return 0;
}
int main() {
sqlite3 *db;
char *errmsg = NULL;
int record_count = 0; // 用于统计记录数
sqlite3_open("my.db", &db);
// 查询并统计记录数
const char *sql = "SELECT id, name, score FROM student;";
printf("学生列表:\n");
sqlite3_exec(db, sql, callback, &record_count, &errmsg);
printf("\n共有 %d 条记录\n", record_count);
sqlite3_close(db);
return 0;
}可以看到我们调用sqlite3_exec的时候传递了一个&record_count给回调函数
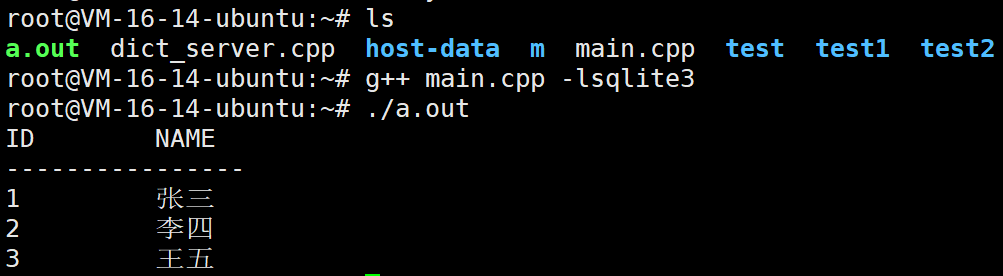
实例3:错误处理的完整示例
cpp
#include <stdio.h>
#include <sqlite3.h>
int callback(void *data, int argc, char **argv, char **col_names) {
for(int i = 0; i < argc; i++) {
printf("%-10s", argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
int main() {
sqlite3 *db;
char *errmsg = NULL;
int rc; // 返回码
// 1. 打开数据库
rc = sqlite3_open("test.db", &db);
if(rc != SQLITE_OK) {
printf("无法打开数据库: %s\n", sqlite3_errmsg(db));
return rc;
}
// 2. 创建表
rc = sqlite3_exec(db,
"CREATE TABLE IF NOT EXISTS users(id INTEGER PRIMARY KEY, name TEXT);",
NULL, NULL, &errmsg);
if(rc != SQLITE_OK) {
printf("创建表错误: %s\n", errmsg);
sqlite3_free(errmsg);
}
// 3. 插入数据
rc = sqlite3_exec(db,
"INSERT INTO users(name) VALUES('张三'), ('李四'), ('王五');",
NULL, NULL, &errmsg);
if(rc != SQLITE_OK) {
printf("插入错误: %s\n", errmsg);
sqlite3_free(errmsg);
}
// 4. 查询数据
printf("ID NAME\n");
printf("----------------\n");
rc = sqlite3_exec(db, "SELECT * FROM users;", callback, NULL, &errmsg);
if(rc != SQLITE_OK) {
printf("查询错误: %s\n", errmsg);
sqlite3_free(errmsg);
}
// 5. 关闭数据库
sqlite3_close(db);
return 0;
}
1.5.sqlite3_close函数
第一部分:核心概念 ------ "句柄"是什么?
sqlite3* db 这个参数,我们叫它"数据库句柄"或"连接句柄"。
它就像你从图书馆管理员那里拿到的一张"借书卡"或者"座位号"。
当你调用 sqlite3_open(打开数据库)时,就相当于图书馆给你分配了一个专属的座位(db),并把座位号(句柄)交给你。
之后,你在图书馆里的所有操作(找书、看书、做笔记),都必须通过这个座位号来进行。系统知道你在这个座位上做什么。
这个句柄 db 不是数据库文件本身,而是你当前和数据库之间的一个 活动连接、一个会话通道。
第二部分:销毁句柄 ------ 把"借书卡"还回去
书看完了,你得把卡还回去,腾出座位。在SQLite里,就是关闭连接,销毁句柄。
cpp
int sqlite3_close(sqlite3* db);这是什么? 这是最基本的关闭函数。
它怎么做?
- 它检查你这个"座位"(句柄db)上还有没有没做完的事(例如:有没有还没执行完的SQL语句,有没有没取完的查询结果)。
- 如果有未完成的事,它会直接拒绝还卡,返回一个错误码(不是SQLITE_OK)。 这时连接并不会关闭。
- 如果所有事都做完了,它就帮你清理座位,销毁句柄,然后说"好了",返回 SQLITE_OK。
缺点: 如果程序员不小心忘了做完某些事,sqlite3_close 可能会失败,但句柄又处于一个"半关闭"的奇怪状态,后续不好处理。
1.6.sqlite3_close_v2函数
其实这个sqlite3_close其实是有缺陷的,那么官方就对他进行了升级,也就是我们下面这个函数
cpp
int sqlite3_close_v2(sqlite3* db); (推荐使用这个)这是什么? 这是升级版的、更健壮的关闭函数。
它怎么做?
- 它无论如何都会先把你"借书卡"(句柄db)的权限标记为失效。从这一刻起,你再也不能用这张卡做任何操作了。
- 然后,它再去后台慢慢检查、清理你座位上留下的东西(未完成的任务)。
- 最后,它总是会返回 SQLITE_OK,告诉你"关闭流程已成功启动"。 至于清理工作,库会自己在后台妥善完成。
为什么推荐它? 因为它行为更可预测、更安全。你不会因为忘记处理某个细节而导致关闭函数"卡住"或失败。对于初学者来说,用 _v2 版本更省心。
简单比喻:
- sqlite3_close:管理员说:"把你桌上的书都还了,笔帽都盖好,我才收卡。" 如果你没做好,他就不收。
- sqlite3_close_v2:管理员二话不说,先把你的卡收走注销,然后说"你可以走了,剩下收拾桌子的活儿我来"。他总是会说"好的,卡已收回"。
所以,你的代码通常会这样写:
cpp
sqlite3 *db; // 声明一个"借书卡"
// ... (这里用 sqlite3_open 拿到"卡"db,并进行各种数据库操作) ...
// 最后,用推荐的方法还卡
int rc = sqlite3_close_v2(db); // rc 返回值,这里总是 SQLITE_OK
// 关闭后,db 指针就不要再使用了!1.7.sqlite3_errmsg函数
获取错误信息 ------ 问问"刚才为什么出错?"
cpp
const char *sqlite3_errmsg(sqlite3* db);这是什么? 这是一个 "问询函数"。
它怎么用?
- 当你进行某个操作(比如打开数据库、执行某条SQL语句)失败后,你需要知道具体错在哪里。
- 这时,你就拿着你的"借书卡"(句柄db),去问管理员(调用这个函数)。
- 管理员(函数)会根据你这张卡对应的、最近一次的操作记录,告诉你一个用文字描述的、人类可读的错误原因。
关键点:
- 它问的是"针对这个连接(db)的最后一次错误"。 错误信息是和你的句柄 db 绑定的。
- 它返回的是一个字符串(const char *),比如 "no such table: students"(没有叫students的表),这比一个单纯的错误数字代码好理解得多。
- 一定要在出错后、进行下一个可能覆盖错误的操作前,赶紧调用它来问。
使用例子:
cpp
sqlite3 *db;
// 尝试打开数据库
if (sqlite3_open("test.db", &db) != SQLITE_OK) {
// 打开失败了!立刻用对应的db句柄去问错误信息
printf("打开数据库失败:%s\n", sqlite3_errmsg(db));
// 这里不应该调用 close,因为打开失败时,db 可能没有被正确分配
return;
}
// 尝试执行一条错误的SQL
char *errMsg = NULL;
if (sqlite3_exec(db, "SELECT * FROM a_table_not_exist", NULL, NULL, &errMsg) != SQLITE_OK) {
// 执行失败了!
printf("执行SQL失败:%s\n", sqlite3_errmsg(db)); // 方式一:通过句柄问
// 或者,sqlite3_exec 已经把错误信息填到 errMsg 里了
printf("执行SQL失败(另一种方式):%s\n", errMsg); // 方式二
sqlite3_free(errMsg); // 记得释放 sqlite3_exec 给的这个错误消息内存
}
// ... 最后,正常关闭 ...
sqlite3_close_v2(db);二.封装SQLite3接口
在实际运用中,我们还是将上述接口全部封装到一个类里面
sqlite.h
cpp
#include <sqlite3.h>
#include<iostream>
#include<string>
/**
* SQLite 数据库帮助类
* 封装了常用的 SQLite 操作,简化数据库使用
*/
class SqliteHelper {
public:
// 定义回调函数类型别名,与 sqlite3_exec 的回调函数签名一致
typedef int (*sqlite_callback)(void*,int,char**,char**);
SqliteHelper(const std::string&filename):_db_handler(nullptr),_dbfile(filename){}
~SqliteHelper(){ close(); }
bool open(int thread_safe_level = SQLITE_OPEN_FULLMUTEX) {
// 设置打开标志------读写模式、不存在时创建、线程安全级别
int flag = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | thread_safe_level;
// 使用带标志的open函数打开数据库
int ret=sqlite3_open_v2(_dbfile.c_str(), &_db_handler, flag, nullptr);
// 检查数据库打开是否成功
if (ret != SQLITE_OK) {
// 输出错误信息
std::cout << "打开数据库文件 " << _dbfile << " 失败!\n";
std::cout << sqlite3_errmsg(_db_handler) << std::endl;
// 关闭失败的连接
sqlite3_close(_db_handler);
return false;
}
return true;
}
void close() {
if (_db_handler) sqlite3_close(_db_handler);
_db_handler = nullptr;
}
bool exec(const std::string &sql, sqlite_callback cb = nullptr, void *arg = nullptr) {
// 执行SQL语句
int ret = sqlite3_exec(_db_handler, sql.c_str(), cb, arg, nullptr);
// 检查执行结果
if (ret != SQLITE_OK) {
std::cout << "执行 sql: " << sql << " 失败!\n";
std::cout << "原因: " << sqlite3_errmsg(_db_handler) << std::endl;
return false;
}
return true;
}
private:
sqlite3 *_db_handler; // SQLite 数据库句柄,管理数据库连接
std::string _dbfile; // 数据库文件路径
};然后我们写一个main.cpp来测试
cpp
#include"sqlite.h"
#include <iostream>
#include <string>
int callback(void* data, int argc, char** argv, char** azColName) {
// 将传入的数据转换为字符串,作为输出前缀
std::string* prefix = static_cast<std::string*>(data);
for (int i = 0; i < argc; i++) {
// 打印列名和对应的值
std::cout << *prefix << azColName[i] << " = ";
// 检查值是否为NULL
if (argv[i]) {
std::cout << argv[i];
} else {
std::cout << "NULL";
}
std::cout << std::endl;
}
std::cout << "------------------------" << std::endl;
return 0;
}
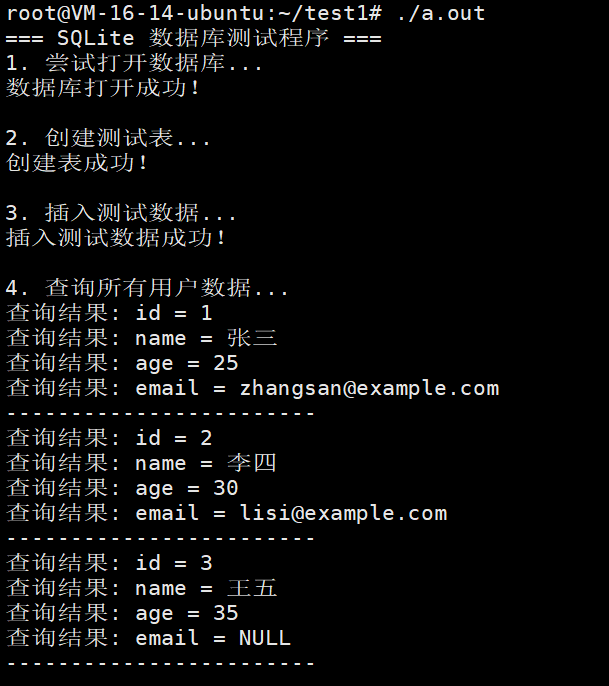
int main() {
std::cout << "=== SQLite 数据库测试程序 ===" << std::endl;
// 1. 创建SqliteHelper对象,指定数据库文件
SqliteHelper dbHelper("test.db");
std::cout << "1. 尝试打开数据库..." << std::endl;
// 2. 打开数据库连接
if (!dbHelper.open()) {
std::cout << "数据库打开失败,程序退出。" << std::endl;
return 1;
}
std::cout << "数据库打开成功!" << std::endl;
// 3. 创建测试表
std::cout << "\n2. 创建测试表..." << std::endl;
std::string createTableSQL =
"CREATE TABLE IF NOT EXISTS users ("
"id INTEGER PRIMARY KEY AUTOINCREMENT, "
"name TEXT NOT NULL, "
"age INTEGER, "
"email TEXT)";
if (!dbHelper.exec(createTableSQL)) {
std::cout << "创建表失败!" << std::endl;
} else {
std::cout << "创建表成功!" << std::endl;
}
// 4. 插入测试数据
std::cout << "\n3. 插入测试数据..." << std::endl;
// 先清空表,避免重复数据
dbHelper.exec("DELETE FROM users");
// 插入多条记录
std::string insertSQL1 = "INSERT INTO users (name, age, email) VALUES ('张三', 25, 'zhangsan@example.com')";
std::string insertSQL2 = "INSERT INTO users (name, age, email) VALUES ('李四', 30, 'lisi@example.com')";
std::string insertSQL3 = "INSERT INTO users (name, age, email) VALUES ('王五', 35, NULL)";
if (dbHelper.exec(insertSQL1) &&
dbHelper.exec(insertSQL2) &&
dbHelper.exec(insertSQL3)) {
std::cout << "插入测试数据成功!" << std::endl;
} else {
std::cout << "插入测试数据失败!" << std::endl;
}
// 5. 查询数据
std::cout << "\n4. 查询所有用户数据..." << std::endl;
std::string queryPrefix = "查询结果: ";
std::string selectSQL = "SELECT * FROM users";
if (!dbHelper.exec(selectSQL, callback, &queryPrefix)) {
std::cout << "查询数据失败!" << std::endl;
}
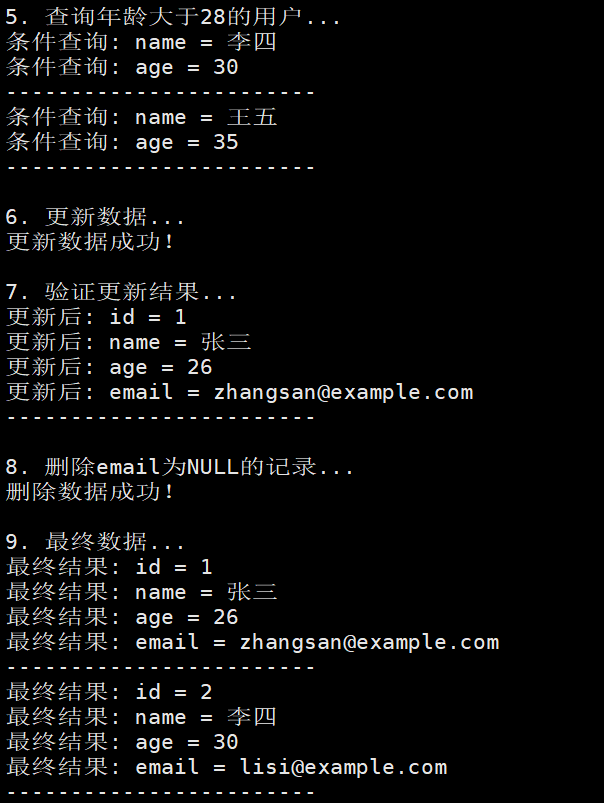
// 6. 条件查询
std::cout << "\n5. 查询年龄大于28的用户..." << std::endl;
std::string conditionPrefix = "条件查询: ";
std::string conditionSQL = "SELECT name, age FROM users WHERE age > 28";
if (!dbHelper.exec(conditionSQL, callback, &conditionPrefix)) {
std::cout << "条件查询失败!" << std::endl;
}
// 7. 更新数据
std::cout << "\n6. 更新数据..." << std::endl;
std::string updateSQL = "UPDATE users SET age = 26 WHERE name = '张三'";
if (dbHelper.exec(updateSQL)) {
std::cout << "更新数据成功!" << std::endl;
} else {
std::cout << "更新数据失败!" << std::endl;
}
// 8. 验证更新结果
std::cout << "\n7. 验证更新结果..." << std::endl;
std::string verifyPrefix = "更新后: ";
std::string verifySQL = "SELECT * FROM users WHERE name = '张三'";
if (!dbHelper.exec(verifySQL, callback, &verifyPrefix)) {
std::cout << "验证更新结果失败!" << std::endl;
}
// 9. 删除数据
std::cout << "\n8. 删除email为NULL的记录..." << std::endl;
std::string deleteSQL = "DELETE FROM users WHERE email IS NULL";
if (dbHelper.exec(deleteSQL)) {
std::cout << "删除数据成功!" << std::endl;
} else {
std::cout << "删除数据失败!" << std::endl;
}
// 10. 查询最终结果
std::cout << "\n9. 最终数据..." << std::endl;
std::string finalPrefix = "最终结果: ";
std::string finalSQL = "SELECT * FROM users";
if (!dbHelper.exec(finalSQL, callback, &finalPrefix)) {
std::cout << "查询最终数据失败!" << std::endl;
}
std::cout << "\n=== 数据库测试完成 ===" << std::endl;
std::cout << "数据库文件 'test.db' 已创建,可以使用 SQLite 工具查看。" << std::endl;
// 注意:数据库连接会在dbHelper析构时自动关闭
return 0;
}