文章目录
- 前言
- 介绍
- 目标硬件平台
- [模型推理:TensorRT VS Pytorch](#模型推理:TensorRT VS Pytorch)
- [Window11 安装 TensorRT(个人经验)](#Window11 安装 TensorRT(个人经验))
- [简单 Demo 尝试](#简单 Demo 尝试)
前言
本文章配套视频:TensorRT 10.14.1 初体验:介绍、安装与Demo尝试
本人有偿提供【Window平台上 TensorRT 开发环境搭建】服务,可咨询(练习方式:QQ- 736340716 雪天鱼 )
小店商品链接:Windows 平台上 TensorRT 开发环境搭建
介绍
GITHUB 链接: https://github.com/NVIDIA/TensorRT
官网:https://developer.nvidia.com/tensorrt
TensorRT 是NVIDIA推出的高性能深度学习推理SDK,旨在NVIDIA GPU上实现低延迟、高吞吐量的模型部署。
个人理解为针对 NVIDIA GPU 的专用 AI 编译器。
TensorRT 的工作流程:
- 输入: 它接收你训练好的深度学习模型(如 ONNX 格式)。
- 优化: 它对计算图进行分析,执行算子融合 (Layer Fusion)、死代码消除 、精度校准(FP32 -> INT8)等操作
- 代码生成: 它通过内核自动调整(Kernel Auto-Tuning),从算法库中搜索出在当前 GPU 上跑得最快的 CUDA 核函数,最终生成一个序列化文件(Engine)。
- 输出: 这个 Engine 文件就是针对该特定 GPU 的"二进制可执行程序"。
它与通用 AI 编译器(如 TVM/XLA)的区别
| 特性 | TensorRT | 通用 AI 编译器 (如 TVM, MLIR) |
|---|---|---|
| 硬件支持 | 仅限 NVIDIA GPU (闭源生态) | 跨硬件 (CPU, GPU, NPU, DSP 等) |
| 核心策略 | 依赖 NVIDIA 手写的高性能 CUDA 算子库 | 更多依赖自动代码生成 (Codegen) 技术 |
| 定位 | 极致挖掘自家硬件潜力的SDK | 解决模型部署碎片化的中间层工具 |
目标硬件平台
简单来说,它的硬件支持范围只有一条铁律:必须是 NVIDIA 的 GPU(或相关加速器如 DLA)。 它不支持 AMD 显卡、Intel 显卡,也不支持单纯在 CPU 上运行(除了一些极少数的 Fallback 情况)。
具体来说,TensorRT 主要针对以下四大类 NVIDIA 硬件平台进行深度优化。
(1) 嵌入式与边缘计算 (Embedded & Edge AI)
这是 TensorRT 相比其他编译器(如 OpenVINO)最具统治力的领域。
- 代表硬件: Jetson 系列 (AGX Orin, Orin NX, AGX Xavier, Xavier NX, Nano 等)。
- 针对性优化:
- 低功耗与低延迟:
- 异构加速支持: 只有在 Jetson 平台上,TensorRT 才能原生调用 DLA (Deep Learning Accelerator)。在 PC 显卡上是没有 DLA 的。
- 共享内存 (Unified Memory): 针对 Tegra SoC 的 CPU/GPU 共享内存架构进行了专门的零拷贝优化。
(2) 消费级与专业工作站 (PC / Workstation)
- 代表硬件: GeForce RTX 系列 (30/40/50系), RTX Professional (原Quadro) 系列。
- 针对性优化:
- 主要利用海量的 CUDA Cores 和高频的 Tensor Cores。
- 虽然主要用于打游戏和渲染,但因为架构(Ampere/Ada/Blackwell)与边缘端同源,所以是极佳的"原型验证平台"。
(3) 数据中心与云端 (Data Center / Cloud)
- 代表硬件: NVIDIA A100, H100, L40S, T4 等。
- 针对性优化:
- 极高吞吐量 (Throughput): 优化大 Batch Size 的并发处理。
- 多实例 GPU (MIG): 支持将一块卡切分成多个实例跑 TensorRT。
- INT8 / FP8 极限压榨: 在大模型服务中广泛使用。
(4) 自动驾驶 (Automotive)
- 代表硬件: NVIDIA DRIVE Orin / Thor。
- 针对性优化:
- 安全性 (Safety): 这一类 TensorRT 版本(TensorRT Safety)经过了 ISO 26262 车规级认证,代码更严谨,不允许动态内存分配等风险操作。
TensorRT 之所以快,是因为它在底层直接生成了 CUDA 汇编代码 和 SASS 指令 。
它知道 Orin 的 Tensor Core 有几个寄存器。它知道 RTX 5070 的 L2 缓存有多大。它能够控制具体的 Warp 调度。
模型推理:TensorRT VS Pytorch
在 RTX 5070 显卡上运行 TensorRT 和运行 PyTorch,虽然最终输出的"图片结果"是一样的,但底层的工作逻辑、资源消耗和执行效率有着本质的区别。
我们可以把 PyTorch 比作"一边翻译一边执行"的 Python 解释器 ,而把 TensorRT 比作"编译优化后"的 C++ 可执行文件。
以下是具体的四个核心维度对比:
(1)计算图层面的区别:碎片 vs. 融合 (Fusion)
- PyTorch (Eager Mode):
- 工作方式: 它是"即时"的。当你代码跑到
y = conv(x),它启动一个 CUDA Kernel;跑到y = relu(y),它读取上一步结果,再启动一个 Kernel。 - 劣势: 对于 GPU 来说,启动 Kernel 有固定开销。如果模型层数很深,且有大量简单的数学运算,这会导致 GPU 频繁地在"读显存 -> 算一点点 -> 写回显存"之间切换,显存带宽(Bandwidth)浪费严重。
- 工作方式: 它是"即时"的。当你代码跑到
- TensorRT:
- 工作方式: 它在"编译"阶段(生成 Engine 时)会查看整个网络图。
- 优势(Layer Fusion): 它会发现
Conv + Bias + ReLU可以合并成一个 CUDA Kernel。 - 对你的影响: 对于 GDN 层,如果你不写 Plugin,TensorRT 可能会把几十个碎片算子融合成几个较大的块;如果你写了 Plugin,它就是一个高效的大算子。这能大幅减少显存读写次数。
(2) 显存管理机制:动态 vs. 静态
-
PyTorch:
- 为了支持反向传播(训练)和动态图,PyTorch 会在显存中保留很多中间激活值(Activations),并且显存分配是动态的(Caching Allocator)。
- 现象: 显存占用较大且波动。
-
TensorRT:
- 显存复用 (Memory Aliasing): 它在编译时计算好每一步需要的显存,并且极其激进地复用显存。例如,Layer A 的输出用完后,Layer C 可能会直接覆盖这块内存。
- 现象: 显存占用通常只有 PyTorch 的 1/2 甚至更低。这在 Jetson AGX Orin 这种显存宝贵的设备上是决定生死的,但在 5070 上你可能感觉不明显。
(3)硬件指令优化:通用 vs. 特化 (Tuning)
- PyTorch:
- 主要调用 cuDNN 库。cuDNN 包含了很多通用的卷积算法,PyTorch 会在运行时选择一个"比较好"的算法。
- TensorRT:
- Kernel Auto-Tuning: 在运行
trtexec构建引擎的那几分钟里,TensorRT 实际上是在"试跑"。它会针对模型和RTX 5070,尝试几十种不同的卷积实现策略(Winograd, GEMM, Direct Conv 等),然后把跑得最快的那一个写死在 Engine 文件里。 - 结果: 它是为这块显卡"私人订制"的最优解。
- Kernel Auto-Tuning: 在运行
(4)精度控制:隐式 vs. 显式
- PyTorch: 即便是
fp16(AMP),往往也是混合精度,部分层为了安全会自动回退到 FP32。 - TensorRT:
- 如果你指定
--fp16,它会极其严格地执行 FP16 计算(除非你手动限制)。 - 如果你开启
--int8,它会直接调用专门的 INT8 Tensor Core 指令,这是 PyTorch 默认很难做到的(PyTorch 做 INT8 需要繁琐的 QAT 和校准流程,且推理速度往往不如 TRT)。
- 如果你指定
在 RTX 5070 上做对比时,可能会看到以下现象:
纯推理延迟 (Latency):
- PyTorch: 假设处理一张 1080p 图片需要 15ms。
- TensorRT (FP16): 可能只需要 3ms - 5ms。
- 感官差异: 在 5070 上都很快,感觉不明显。但在 Orin 上,这个差异就是 150ms vs 30ms 的区别,决定了能不能实时。
Window11 安装 TensorRT(个人经验)
依赖安装
python3.9,
(1)安装CUDA 12.9 (cmd中输入 nvcc -V 查看版本)
(2)安装 cuDNN 9.16.0
在NV官网 https://developer.nvidia.com/cudnn-downloads 下载 cuDNN 9.16.0 安装文件,双击执行安装即可。cuDNN for CUDA cuda13.0 不用勾选,cuda12.9的勾选上就行。安装路径为:C:\Program Files\NVIDIA\CUDNN\v9.16
然后将文件夹内的 bin, include, lib 三个文件夹下的文件,分别复制 到 CUDA 安装目录对应的文件夹中。(默认路径是: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9)
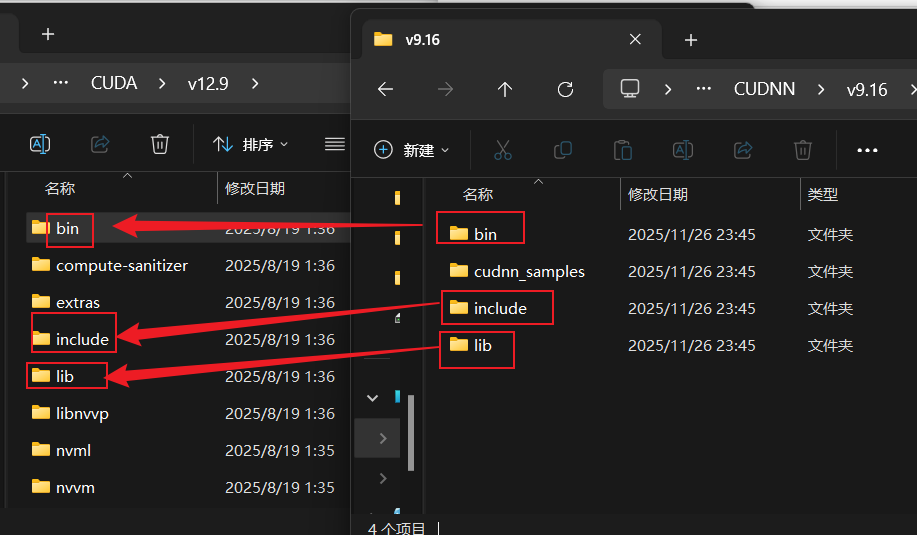
- CUDNN\v9.16\bin\12.9 下的文件都复制到 CUDA\v12.9\bin 下
- CUDNN\v9.16\include\12.9 下的文件都复制到 CUDA\v12.9\include 下
- CUDNN\v9.16\lib\12.9\x64 下的文件都复制到 CUDA\v12.9\lib\x64下
python 库安装
bash
pip install onnx
pip install pycuda # pycuda-2025.1.2
pip install opencv-python # opencv-python-4.12.0.88pycuda 安装:PyCUDA不是预编译好的 Python 包,需要在安装过程中从源码进行编译。如果环境没有配置好,这条命令通常会直接报错。确保已安装 CUDA Toolkit 并配置好了环境变量。
tensorRT安装
进入官网下载 https://developer.nvidia.com/tensorrt/download/10x, 会弹出登录页面,随便输入一个邮箱,进入到输入密码的页面,可选择微信登录。
选择合适版本,这里我选择 TensorRT 10.14.1, 下载得到ZIP压缩包,解压得到 TensorRT-10.14.1.48 文件夹(2.78GB)。

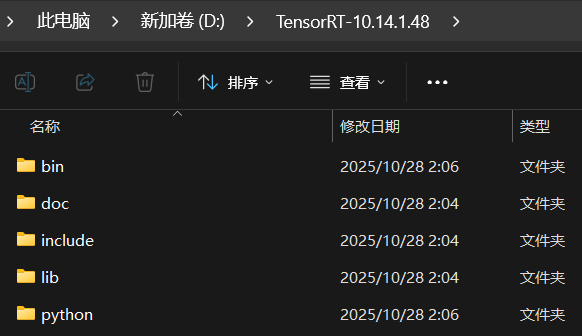
将该文件夹放到路径简单且不含中文或空格的目录中。示例: D:\TensorRT-10.14.1.48
配置系统环境变量 (Path):
- "编辑系统环境变量" -> "环境变量" -> 在"系统变量"中找到 Path -> 点击"编辑"。
- 点击"新建",将 TensorRT 的 lib 目录路径 和 bin 目录路径添加进去。
- 创建系统变量
TENSORRT_PATH指向TensorRT根目录
重要: 添加完后,建议重启电脑以生效。
【安装 Python 接口】
深度学习研究会通过 Python 调用 TensorRT。
-
打开CMD终端,激活 Python 虚拟环境
-
cd进入 TensorRT 解压目录下的 python 文件夹。 -
安装 TensorRT Wheel: 你会看到类似
tensorrt-10.14.1.48-cp3x-none-win_amd64.whl的文件。- 选择与 Python 版本(如 cp39 对应 Python 3.9)匹配的文件进行安装
bashpip install tensorrt-10.14.1.48-cp39-none-win_amd64.whl

【验证安装】
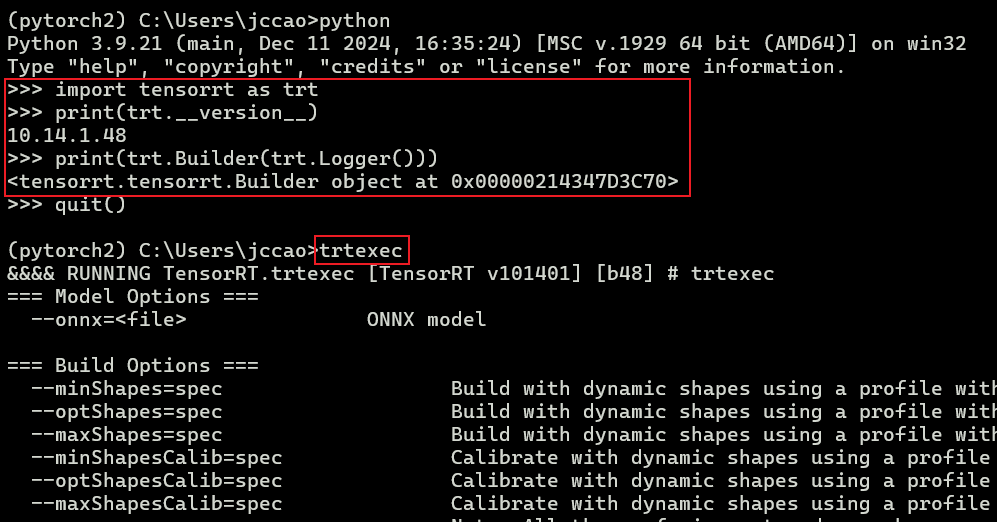
C++验证:检查 bin 目录是否被正确链接。在cmd上输入 trtexec 有显示则表示正常
Python验证:
在终端中输入 python 进入交互模式,尝试导入:
Python
import tensorrt as trt
print(trt.__version__) # 应输出10.14.0
print(trt.Builder(trt.Logger()))- 如果报错
FileNotFoundError或DLL load failed,通常是因为 环境变量 没有设置正确,或者 CUDA/cuDNN 版本不匹配。
简单 Demo 尝试
目标:
(1)验证环境搭建是否正确 ;
(2)熟悉 TensorRT开发流程(ONNX -> Engine -> 推理)
- Export: PyTorch -> ONNX
- Build: ONNX -> Engine (
trtexec) - Runtime: Load Engine -> Memcpy -> Execute -> Memcpy
(1)导出ResNet模型为ONNX : 运行 01_export_resnet.py 脚本
(2)trtexec 把"死"的 ONNX 编译为"活"的 engine : cmd中输入 trtexec --onnx=resnet18.onnx --saveEngine=resnet18.engine --fp16。这里使用fp16半精度,是因为在RTX5070上会很快。 如果最后输出 PASSED 和一大堆性能数据,说明 TensorRT 环境是完美的。
一定要在 目标onnx文件所在目录下打开 cmd, 再输入编译指令,否则找不到文件
(3)写Python 推理脚本:运行 02_infer_resnet.py 脚本
编写了个基准测试脚本(03_benchmark_comparison.py), 脚本功能:
- PyTorch (FP16模式): 使用 PyTorch 原生推理,开启半精度(为了公平对比)。
- TensorRT (FP16模式):
它会进行 Warmup(预热) ,然后连续跑 1000次 ,最后算出 平均延迟 (Latency) 和 吞吐量 (FPS) 。
测试结果如下:
python
=== 推理速度对比基准测试 (ResNet18, RTX 5070) ===
循环次数: 1000, 预热: 50
>>> 正在测试 PyTorch (FP16)...
PyTorch 结果: 耗时 2087.41ms / 1000次
>>> 正在测试 TensorRT (FP16)...
TensorRT 结果: 耗时 245.73ms / 1000次
========================================
Framework | Latency (ms) | FPS
----------------------------------------
PyTorch (FP16) | 2.0874 ms | 479.1
TensorRT (FP16) | 0.2457 ms | 4069.5
========================================
🚀 TensorRT 比 PyTorch 快了 8.49 倍!