MySQL 事务与 MVCC
1. 事务的隔离性
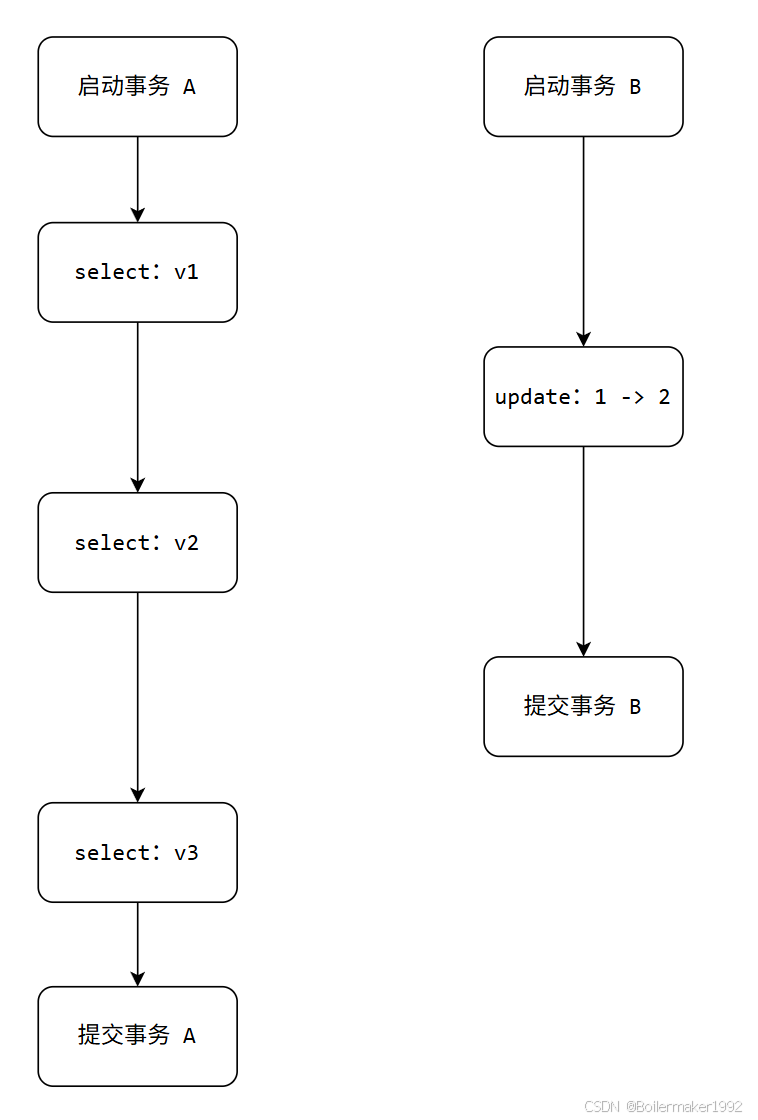
在没有任何隔离的情况下,"仅读事务" 与 "读写事务" 的并发执行可能会出现下面的问题:
v2 = 2:
如果你认为事务 B 还没有提交,它的修改就不能算,这个结果就是错误的。如果你认为,按照时间线来说,这个值是符合预期的,这个结果就没问题。这种情况叫 "脏读",也就是我可以读到未提交事务中进行的修改,所谓的 "读未提交"。
v1 != v2:
在一个事务中你读到了一个字段的不同值。这种情况叫 "不可重复读",因为不保证你在事务中每次读取数据都是一致的。
除此之外还有一种情况,就是如果我们的 WHERE 条件是一个范围查询,那么其他事务可能会同时进行一些插入操作,这样会导致返回的行数不一致。这种情况叫 "幻读",其实你也可以将它理解为不可重复读。
下面我们来看看 InnoDB 是如何解决这些问题的:
如果想解决 "脏读" 问题,就要保证:只要事务没提交,它的改变就不对其他事务可见。InnoDB 通过在每个 SQL 语句开始执行的时候创建一个 "视图" 来保证这点,这个视图保证,这条 SQL 语句只能看见已提交事务的修改。此时事务的隔离级别为 "读提交"。
如果想解决 "不可重复读" 和 "幻读" 问题,就要保证:从事务开启到提交这个过程中,它不会看到任何数据的改变。InnoDB 通过在每个事务开始执行的时候(事务的第一条 SQL 语句)创建一个视图来保证这点,也就是这个事务中全部的 SQL 语句共用一个视图。此时事务的隔离级别为 "可重复读"。
2. 隔离性实现原理
首先先来说一下刚刚反复提到的 "视图" 到底是一个什么东西,在 InnoDB 源码中它其实是一个这样的 C++ 数据结构:
c++
class ReadView {
/* ... */
private:
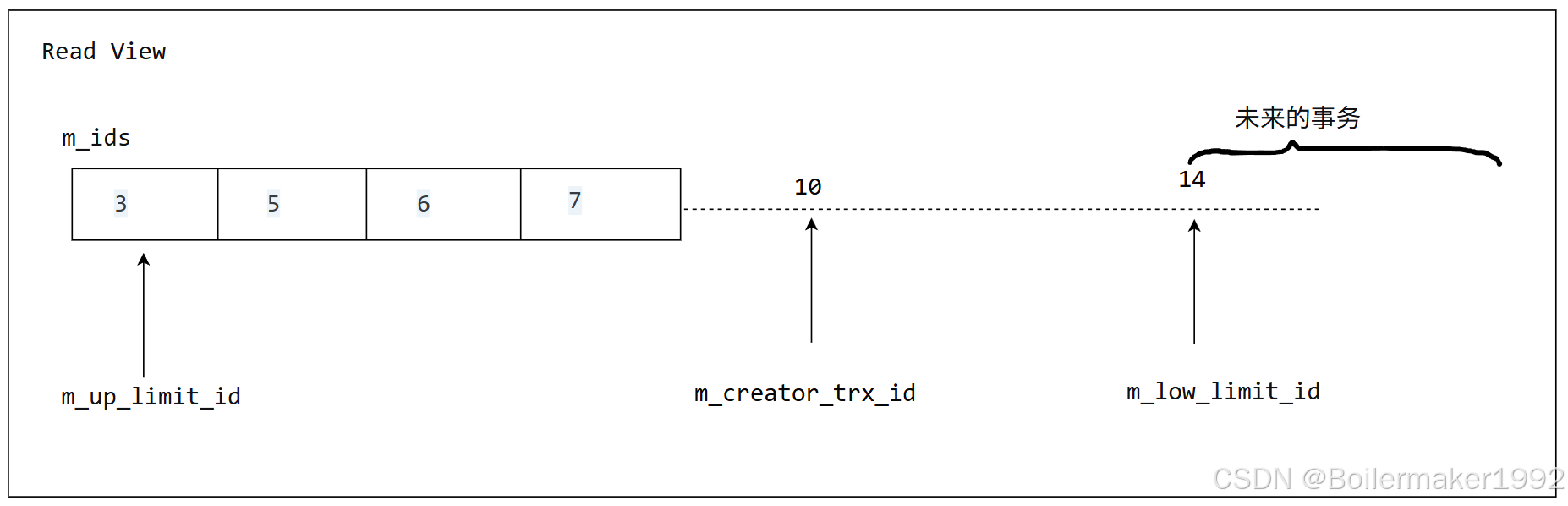
trx_id_t m_low_limit_id; /* 下一个待分配的事务 ID */
trx_id_t m_up_limit_id; /* 最小的未提交事务 ID */
trx_id_t m_creator_trx_id; /* 当前事务自己的 ID */
trx_id_t m_low_limit_no; /* 下一个待分配的事务 no */
ids_t m_ids; /* 创建 Read View 时的未提交事务 ID 列表 */
m_closed; /* 标记 Read View 是否 close */
}
InnoDB 为了使 "仅读事务" 与 "读写事务" 并发执行,会为数据库中的每条记录维护多个版本,这些版本实际上就是对该记录的每一次修改,它们构成了一个版本链。InnoDB 会为聚簇索引添加两个隐藏列用于维护这个版本链,分别是:
trx_id:对该记录改动的 SQL 所属的事务 ID。
roll_pointer:使用这个指针将一条记录的众多版本串成一个时间上的有序链表,实际上就是指向 Undo Log 的指针。
InnoDB 中当前数据页上存储的是最新版本的数据,旧版本的数据通过 Undo Log 构建。因此版本链直观来看是类似下面的数据结构:
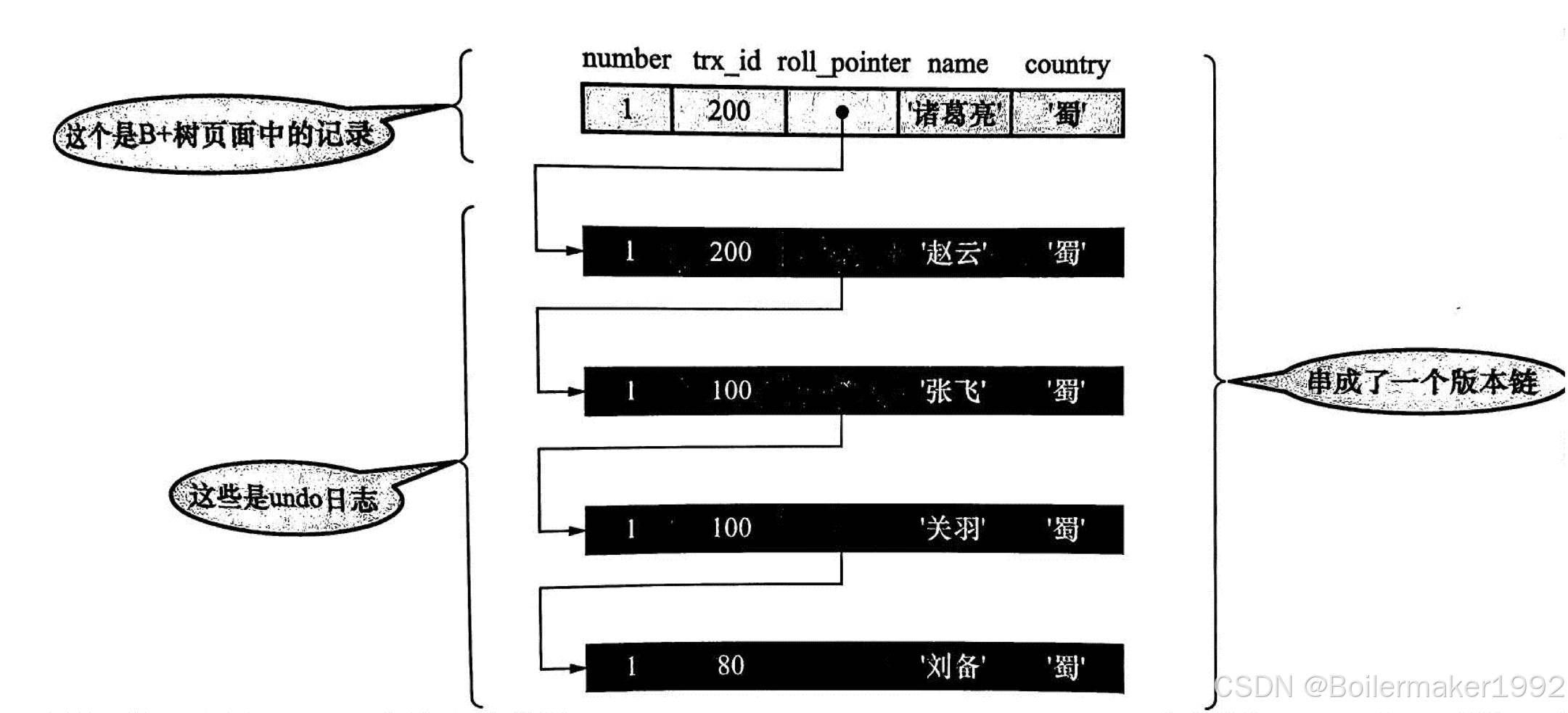
但注意,图上所示是 Undo Log 的逻辑结构,不是物理结构。实际上 Undo Log 的真正硬盘存储是以事务为维度的,每个事务都会被分配自己的 Undo Log 组。
介绍了 "版本链" 这个概念之后,就可以明确 Read View 的作用了:判断版本链中的哪个版本对当前事务可见。当我们执行一条 SELECT 时,InnoDB 会顺序遍历对应记录版本链中的 trx_id,对每个 trx_id 做如下判断:
如果 trx_id 小于 Read View 中的 m_up_limit_id,说明这个版本一定属于已提交事务,因此可见。
如果 trx_id 在 m_up_limit_id 和 m_low_limit_id 之间,那就要看 trx_id 是否在 m_ids 中可以找到, 如果可以找到,说明这个版本属于未提交事务,因此不可见。如果找不到,说明其依然属于已提交事务,因此可见。并且,我们知道 m_creator_trx_id 是一定位于这个范围的,如果 trx_id 等于 m_creator_trx_id,说明这个版本是当前事务创建的,因此可见。
如果 trx_id 大于等于 m_low_limit_id,说明这个版本所属事务的开启是晚于当前事务的,因此不可见。
这个循环一直进行,直到找到第一个可见版本,呈现给当前事务。这就是所谓的 MVCC,也就是在 "读提交" 和 "可重复读" 这两种隔离级别的事务执行 SELECT 操作时,访问记录版本链的过程。它的存在就是为了使 "仅读事务" 和 "读写事务" 可以安全地并发执行而无需加锁控制。
3.purge
现在还有一个问题,就是这个版本链越来越长,什么时候清理呢?我们先来想一下,Undo Log 有两个作用,一个是事务回滚,一个是 MVCC。从事务回滚的角度来说,当事务提交时,这个事务产生的全部 Undo Log 就都没用了,因为不存在回滚了,这个时候删除即可,但是因为 Undo Log 还要服务 MVCC,所以这个删除时机是不对的,正确的删除时机还要更复杂一些:
对于 INSERT 语句,它产生的 Undo Log 只用于回滚,也就是 DELETE,但是不需要服务 MVCC。为什么呢?因为插入是一个从无到有的过程,它没有所谓旧版本这一说。其他事务要么能 SELECT 出这一行,要么 SELECT 不出,没有版本选择问题。
对于 UPDATE 语句产生的 Undo Log,InnoDB 是这样处理的:
我们知道 Undo Log 是以事务为单位进行组织的,每个事务产生的众多 Undo Log 页面链接在一起。事务提交时,这组 Update Undo Log 会被转移到其所在回滚段的 History 链表中,这个链表就是为了支持 MVCC 而设计的,它会保留直至不被任何 Read View 需要为止。那么什么时候一条 Undo Log 才不被任何 Read View 需要呢?我们需要从下面两点来考虑:
1. 如果一个事务已提交,那么它对数据的修改一定对其提交之后产生的 Read View 可见。
2. 对整个系统现存最早生成的 Read View 可见的数据版本,一定对其他 Read View 都可见。
因此,如果一组 Undo Log 对应的事务提交是早于 Oldest Read View 的生成的,那么这组 Undo Log 就肯定没用了,这就是 InnoDB 的 purge 逻辑。
具体来说,InnoDB 是通过在每组 Undo Log 的 Header 中的 TRX_UNDO_TRX_NO 属性,与 Read View 中的 m_low_limit_no 属性来控制的。生成 Read View 的时候,m_low_limit_no 会被赋为当前系统中最大的 no + 1 的值。事务提交时,当前事务生成自己的 no,这个 no 是严格以事务提交为顺序的,提交越早的事务 no 被分配得越小,反之则越大,然后将这个值赋给 TRX_UNDO_TRX_NO。
可能听起来有点乱,但是只要记住这个 no 就是用来记录事务提交与 Read View 被创建之间的相对时间先后的就好,这与刚刚的第一点是呼应的。如果还是没理解可以看下面的图片:

这提醒了我们,影响 Undo Log 清理的是最老的 Read View,所以一个可重复读的长事务会严重拖慢 Undo Log 的清理效率。因为长事务很可能在使用最老的 Read View,那么任何比这个 Read View 的 no 值大的 Undo Log 都不能被清除。
4. 总结
MVCC 是用于保护一般 SELECT 语句进行 "快照读" 的机制,根本目的就是使这种 "仅读事务" 能够在不对表进行锁控制的情况下安全地与其他事务并发执行。
对于 "读写事务" 和 "读写事务" 的并发来说,MVCC 就无能为力了,还是要进行一定的锁控制。