目录
[Context Processor](#Context Processor)
[Lazy Decoder Block](#Lazy Decoder Block)
[Block Structure :](#Block Structure :)
[Lazy Cross-Attention: KV-Sharing](#Lazy Cross-Attention: KV-Sharing)
[Grouped Query Attention, GQA](#Grouped Query Attention, GQA)
背景:
- Encoder-Decoder 架构的适配性 :
- Encoder 专门负责编码历史物品序列(上下文),处理 "理解用户偏好" 的任务;
- Decoder 专门负责基于上下文生成最新物品(预测目标),处理 "生成推荐结果" 的任务;
- 两者通过交叉注意力机制联动,完美匹配 "历史上下文编码→最新物品生成" 的分工需求。
encoder的编码计算是 "辅助计算",但在传统架构中占用了大量资源(如 OneRec-V1 中占 97.66% FLOPs)。在参数量相同的情况下,编码器 - 解码器(Encoder-Decoder)架构相比经典纯解码器(Decoder-Only)架构节省近半数计算量
- OneRec-V1 的 Encoder-Decoder 架构虽适配该数据组织方式,但带来了计算资源分配低效(Encoder 占 97.66% FLOPs)的问题;
- OneRec-V2 的核心挑战是:如何在保持 "历史上下文编码 + 最新物品生成" 分工的前提下,移除独立 Encoder,实现更高效的架构;
- 最终 OneRec-V2 通过 "惰性上下文处理 + 轻量化交叉注意力" 实现了这一目标:将历史物品的编码逻辑融入 Decoder,既保留了 "上下文 - 目标分离" 的适配性,又解决了计算低效问题。
模型结构:
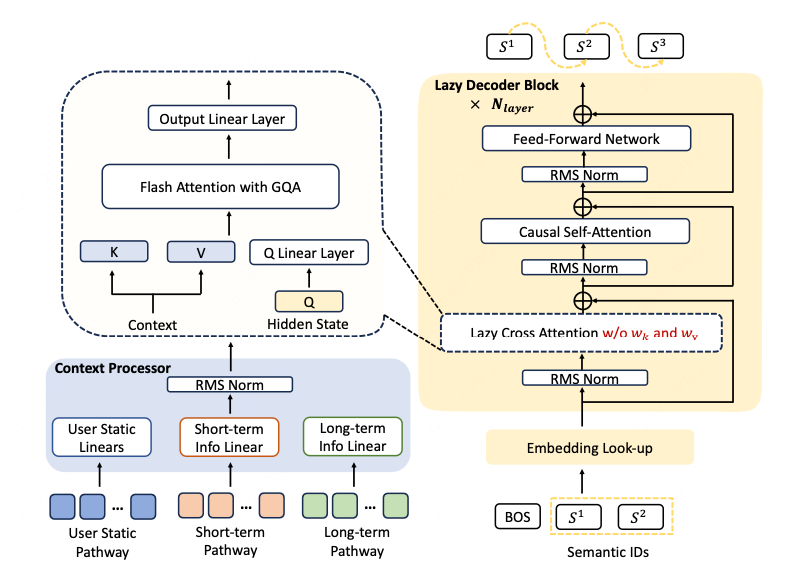
Context Processor
为了有效融合多模态用户行为,能够与下游解码器模块实现无缝集成。
具体而言,用户画像(user profile)、行为记录(behavior)等异构输入被拼接为一个统一序列(即上下文 context)。上下文序列中的每个元素均被映射至相同维度,满足:
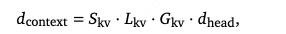
其中,表示注意力头维度,
为键值头组数,
为键值拆分系数,
为键值层数。
context会被切分为*
份,每一份的维度为
*
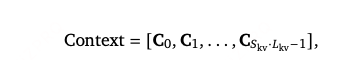
对于每一层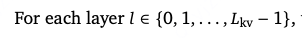
计算归一化后的key-value pairs:
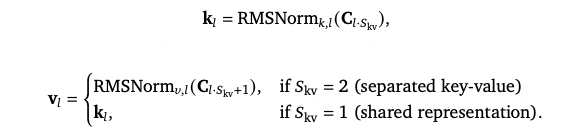
最终输出为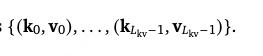
总结:在encoder-decoder的基础上,将context信息进行拆解,
拆解到L层中的key,value值,省去encoder部分;
所以是没有context之间的attention交互的,而是只计算了context与候选item之间的cross attention还有候选item之间的causal self-attention;
Lazy Decoder Block
Tokenizer:
对于每个目标物品,我们采用与 OneRec-V1(Zhou 等人,2025)一致的语义分词器,生成 3 个语义标识(semantic IDs,SID),以捕捉物品的多维度特征。训练阶段,我们使用前 2 个语义标识,并在序列头部添加一个序列起始标识(beginning-of-sequence, BOS),构成输入序列:
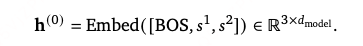
Block Structure :
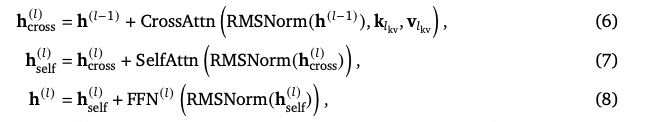
其中,(根均方层归一化)用于保障训练稳定性。
为在保持计算效率的同时提升模型容量,我们采用混合架构:将深层的稠密前馈网络替换为混合专家(Mixture-of-Experts, MoE)模块。借鉴 DeepSeek-V3(Liu 等人,2024)的设计,我们引入无辅助损失的负载均衡策略,确保专家网络的高效利用。
Lazy Cross-Attention: KV-Sharing


- 降低计算冗余:Context Processor 无需生成与解码器层数相同的 KV 对(如 12 组),仅需生成
组(如 6 组),内存减少 50%。
Grouped Query Attention, GQA
查询投影(query projection)仍保持 个注意力头,而键值对仅使用
个键值头组(key-value head groups),且通常满足
。该设计大幅降低了上下文表征的内存占用,同时减少了注意力计算过程中的内存访问开销,(为什么)使模型能够高效扩展至更长的上下文序列和更大的批量大小(batch sizes)。
输出层(Output Layer) 最后一个解码器模块的最终隐藏表征,经位置特异性 RMSNorm(position-specific RMSNorm) 和全连接层(Linear layer)处理后,生成每个语义标识(semantic ID)的预测结果。训练阶段,模型通过最大化目标物品的语义标识序列 \(s_1, s_2, s_3\) 的对数似然(log-likelihood)进行优化。
OneRec-V2 的 Lazy Cross-Attention 通过 "跨层 KV 复用、键值绑定、GQA" 三大创新,完美解决了生成式推荐模型的 "内存瓶颈" 和 "计算瓶颈":
- 内存层面:KV 缓存占用减少 80% 以上,支持更长上下文和更大批量;
- 计算层面:注意力计算量减少 94%,推理延迟降至 30ms 内;
- 性能层面:通过位置特异性归一化、键值绑定的性能补偿,确保推荐精度不下降。
实验部分:
fewer FLOPs and lower activation memory, our lazy decoder-only architecture achieves comparable losses compared to traditional approaches.
FLOPs 量化了模型完成一次训练迭代(或一次推理)所需的浮点运算总量(如加法、乘法),其本质是 "模型的计算复杂度"------FLOPs 越高,意味着需要越多的计算资源(GPU 算力、电力)来完成任务。
低 FLOPs 意味着用更少资源完成相同任务,或在相同资源下支撑更大规模、更高并发的业务。
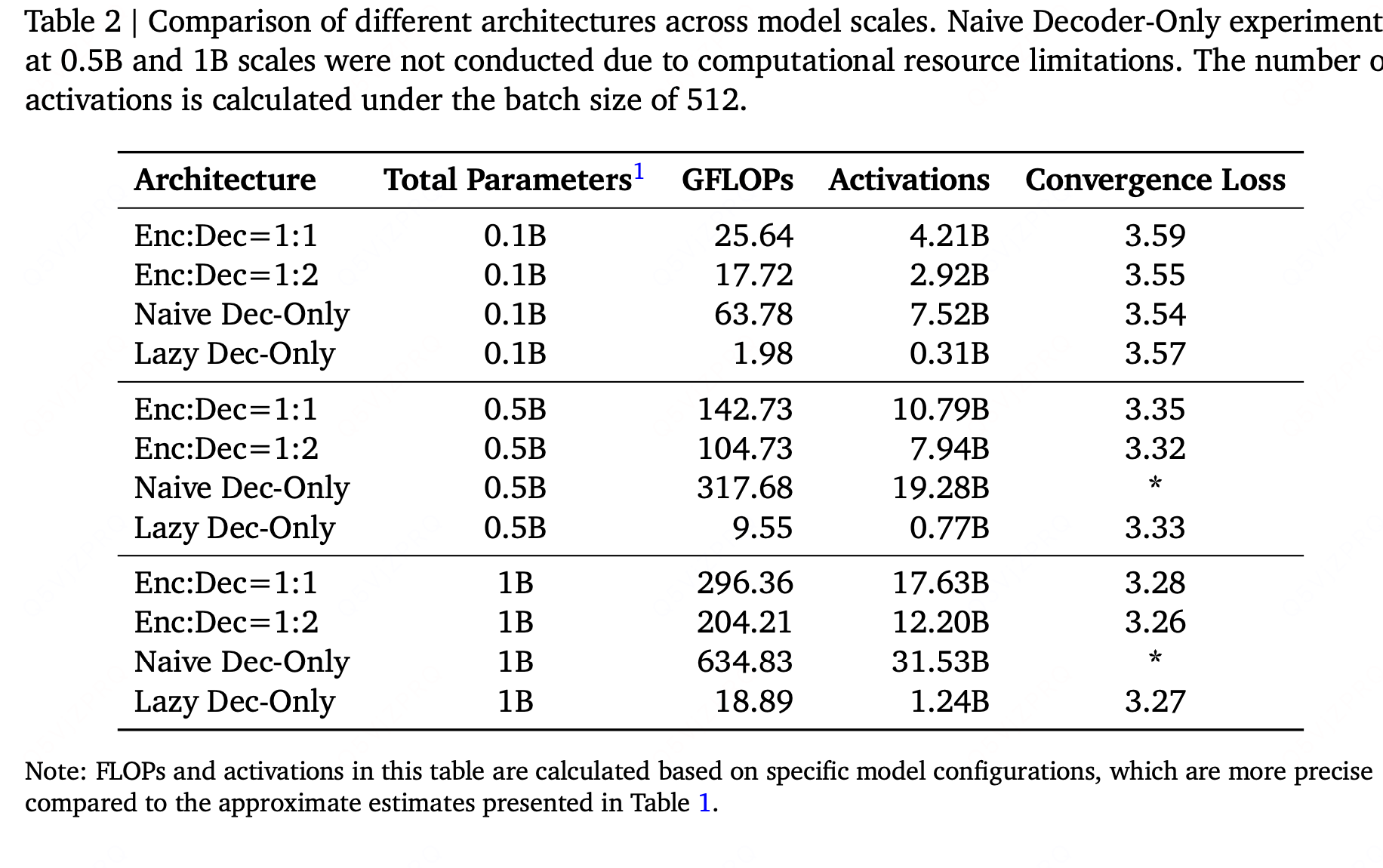
MOE变体:总参数量为 4B 的 MoE 变体(激活参数量 0.5B)收敛损失达 3.22,其性能优于 2B 稠密模型,且计算需求与 0.5B 稠密基准模型相当。该配置相比 0.5B 稠密模型的损失降低了 0.11,充分验证了稀疏架构在推荐任务中的有效性。
分组查询注意力(GQA)通过在多个查询头(query heads)间共享键值头(key-value heads)实现优化。在我们的惰性解码器架构中,该优化减少了交叉注意力操作中的激活内存(activation memory)占用与内存访问瓶颈,从而在对模型性能影响极小的前提下,显著提升了训练吞吐量(training throughput)。我们在一个含 14 个注意力头的 1B 参数稠密惰性解码器模型上,探究了不同键值头组数(\(G_{\text{kv}} \in \{1,2,7\}\))对模型的影响。
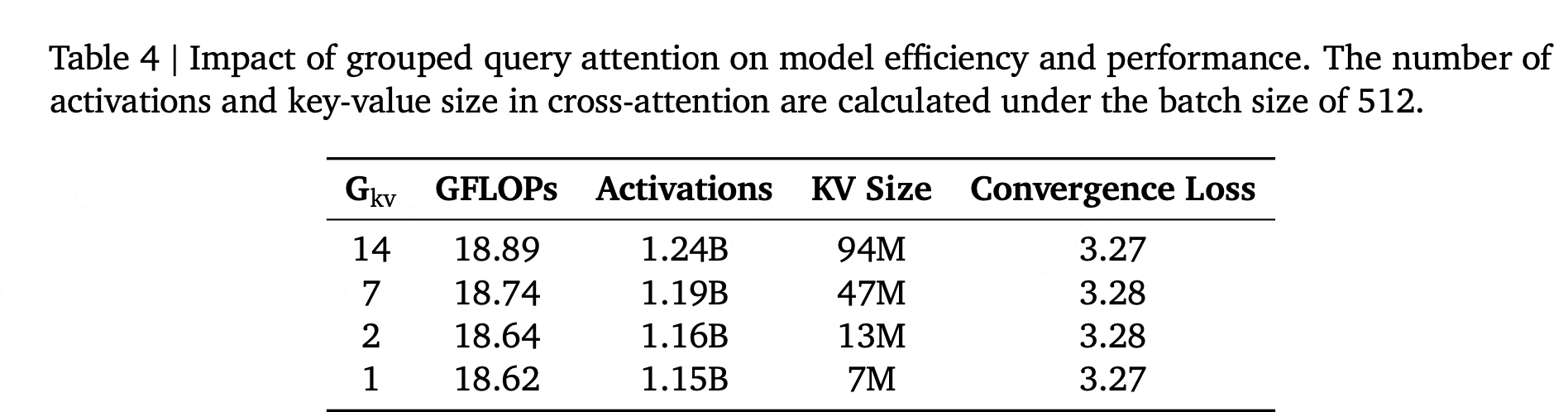
总结:
(1)计算效率飞跃
- 总计算量减少 94%,训练资源消耗降低 90%:通过剥离冗余辅助计算,目标解码的计算占比从 < 3% 提升至 90% 以上,资源利用率大幅提升;
- 推理延迟降低:上下文编码的轻量化与惰性更新,使实时推理 latency 从 200ms + 降至 30ms 内,满足工业级推荐的低延迟要求。
(2)可扩展性突破
- 支持 8B 参数规模:有效计算占比的提升,让相同计算预算下可分配给目标解码的参数量大幅增加,模型表征能力显著增强;
- 遵循缩放定律:随着参数量扩大,损失呈平滑下降趋势(无性能饱和),为后续扩展至 10B + 参数奠定基础。
问题:
- 为什么encoder-decoer但仍存在 97% 资源浪费?


- 为什么GQA可以降低内存访问开销?
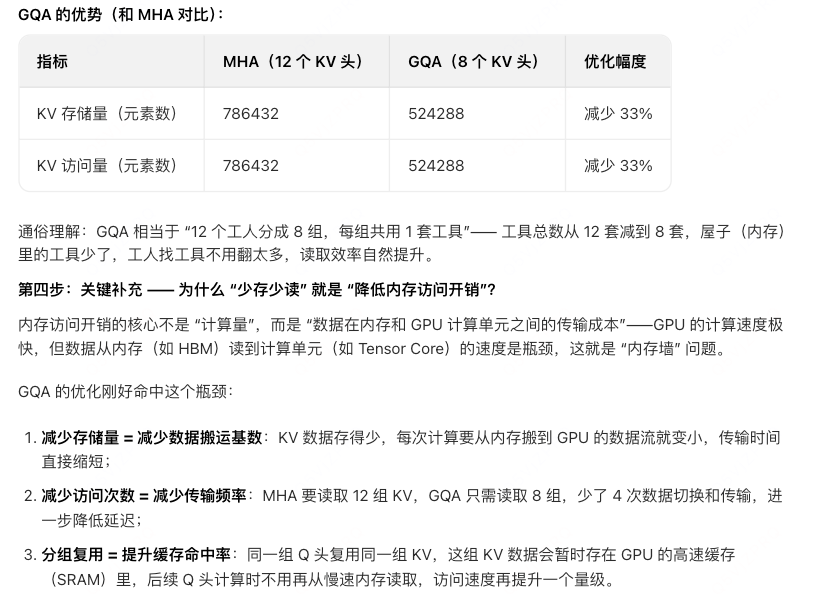
- 传统编码器是基于attetnion来建模context的相关信息的,但是one-vec v2没有对context进行attention计算,而是直接作为解码器的k,v值。所以相比encoder-decoer在相同的参数配置下,应该是减少了参数量的,对吧?比如encoder self-attention的k,v值与FFN。