1.为什么使用索引
索引就像书的目录,有目录添加了索引就能通过索引 快速查询,没目录就得全表扫描 ,数组查询快增删满,链表查询慢增删快,有没有查询和增删都还不错得数据结构?
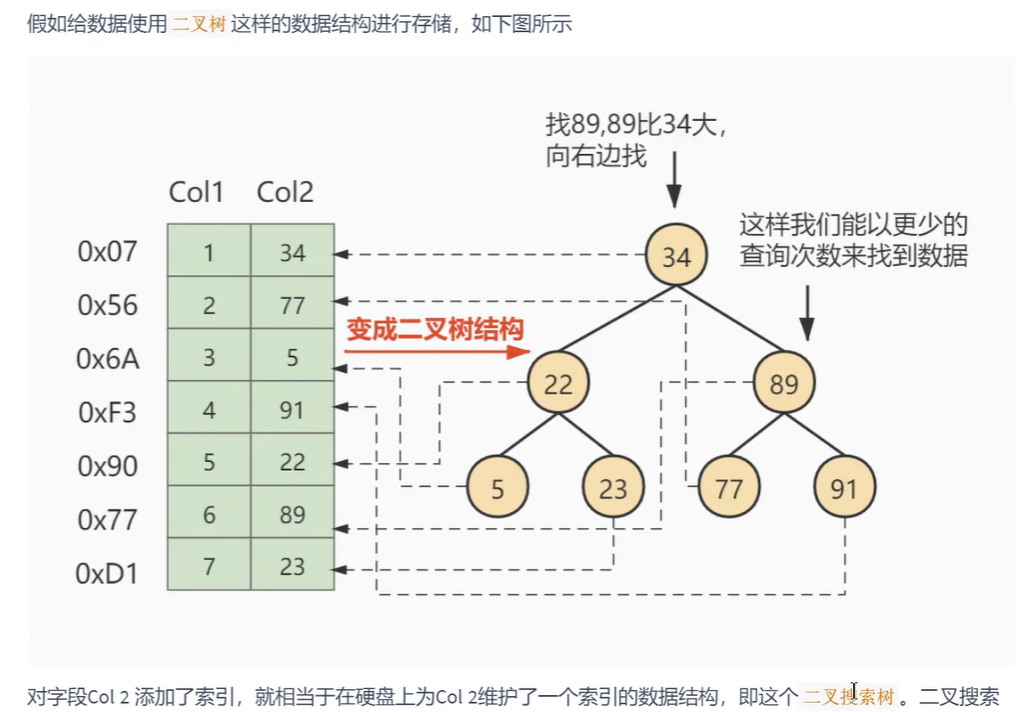
树可以均衡查询和增删效率 ,可以大幅度减少磁盘的IO次数
-
索引的优缺点


-
InnoDB索引推演
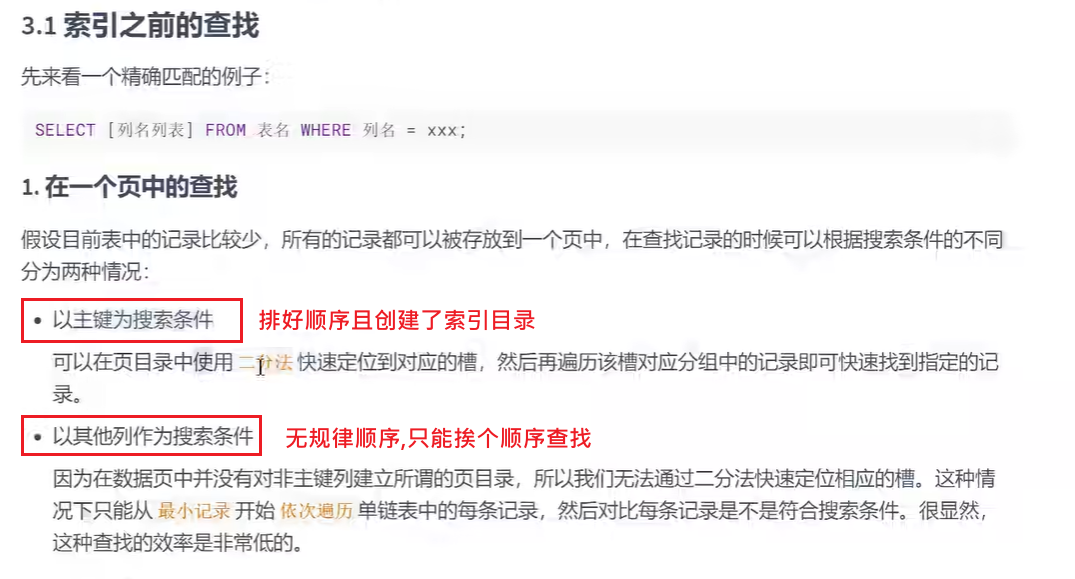
a.数据量较少时,在一个页(16KB)中查找即可
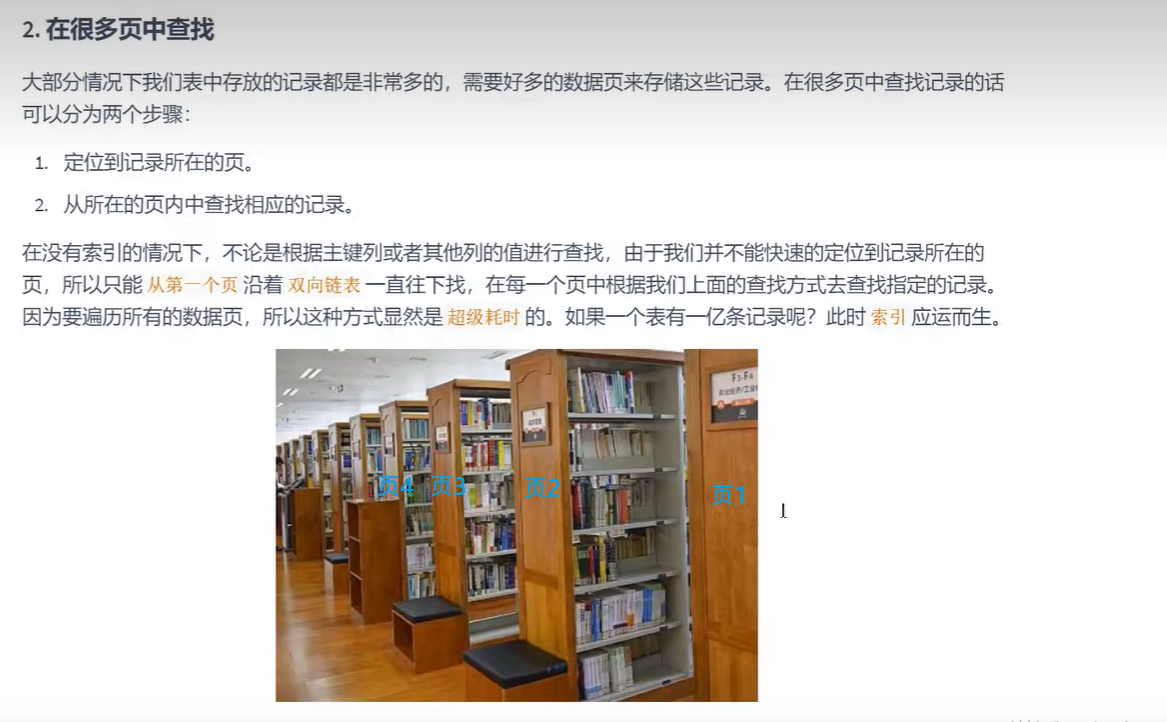
b.数据量比较大,在多个页当中去搜索,用索引快速定位在哪个页中,再从页中快速定位到哪个槽
4.设计索引
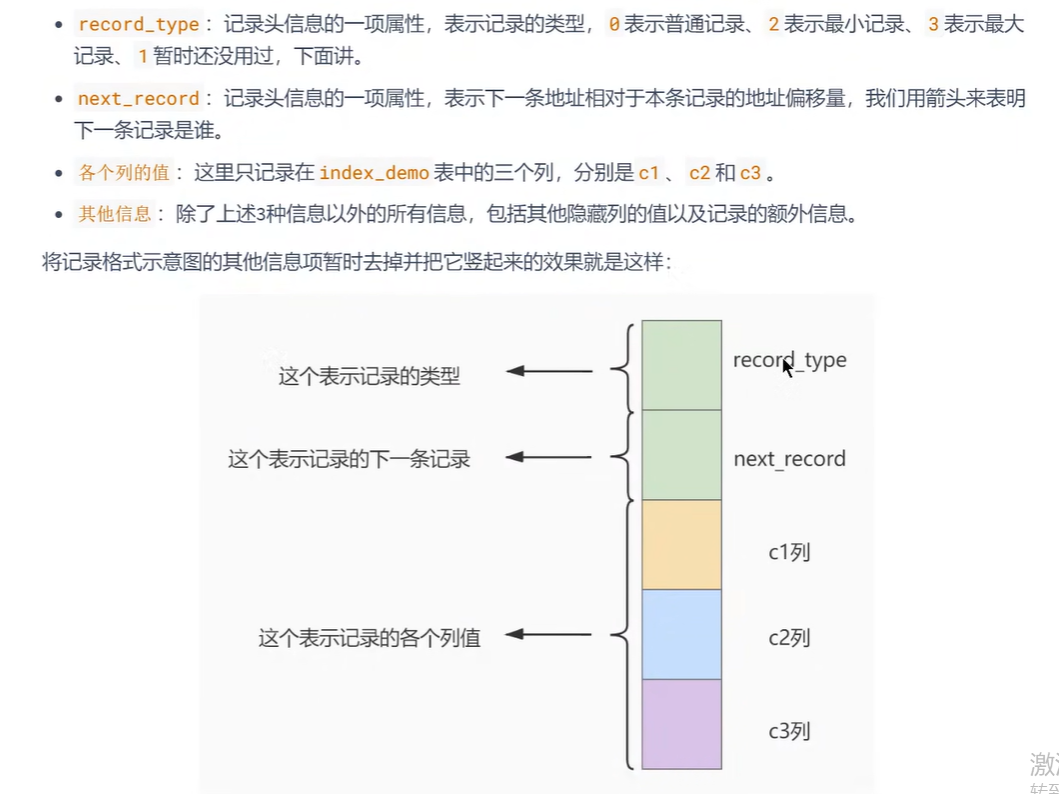
- 每一页的结构
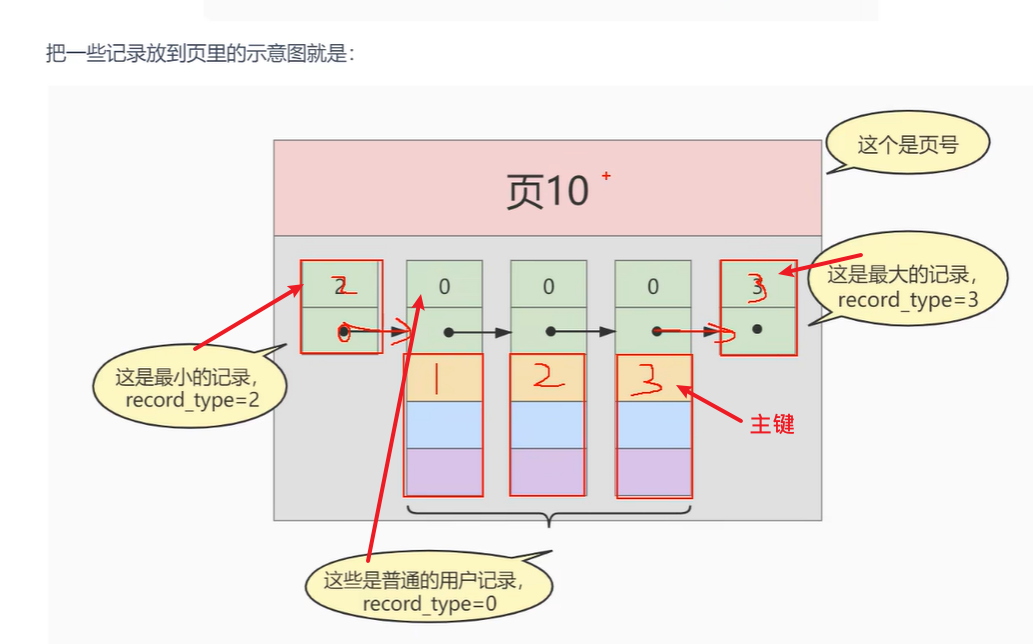
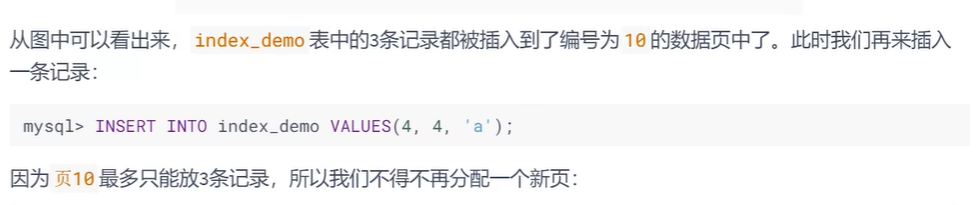
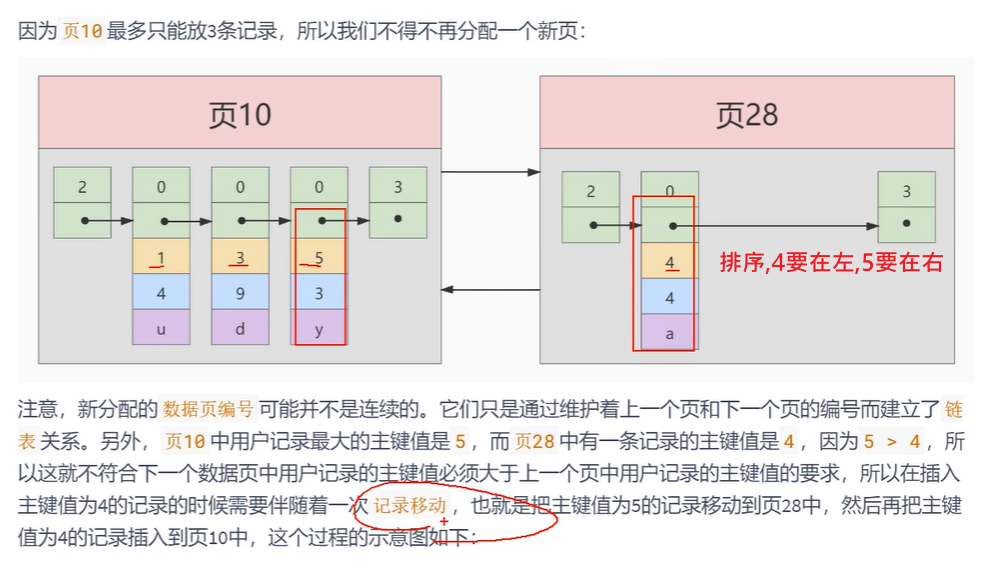
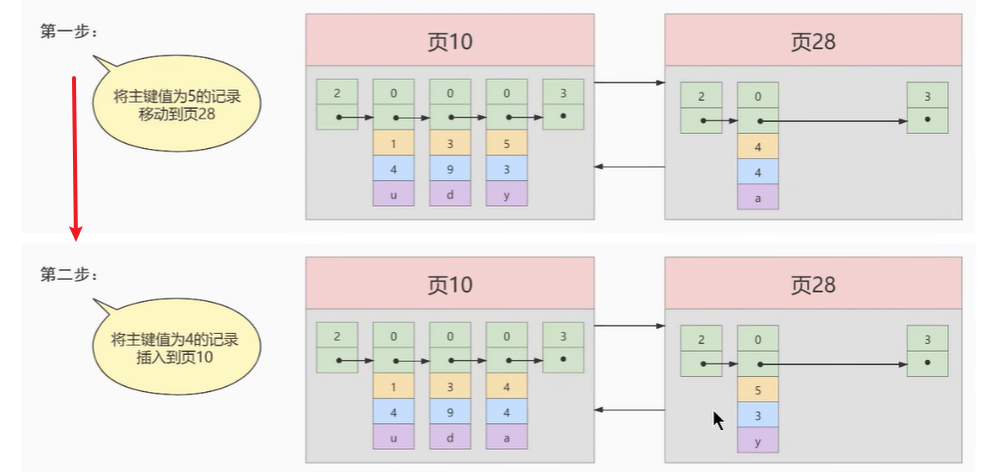
一页放不下,要多个页装载更多的数据,插入进去后,还要排序,所以要记录移动
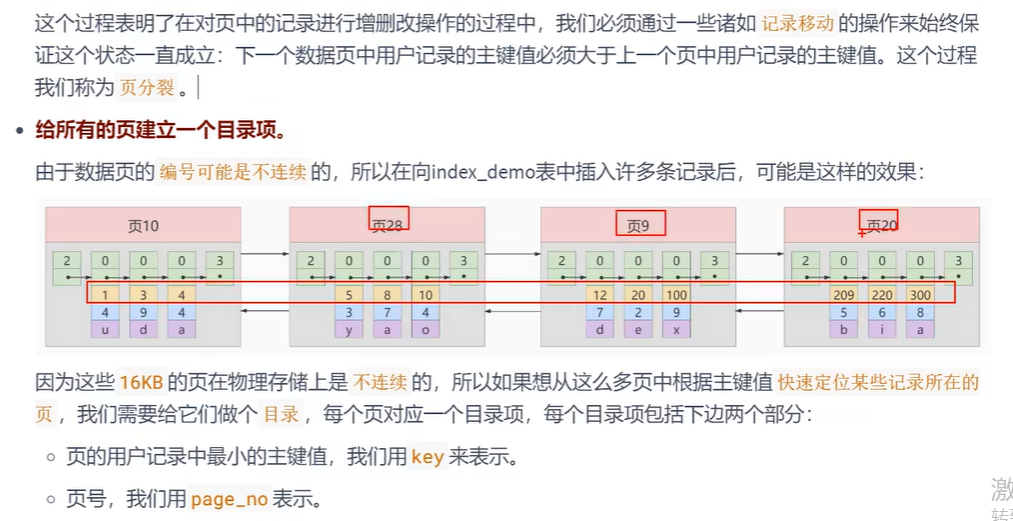
- 虽然上面页和页之间通过链表排好序了,但是如果通过从第一个页开始遍历,那查询效率就会很差.
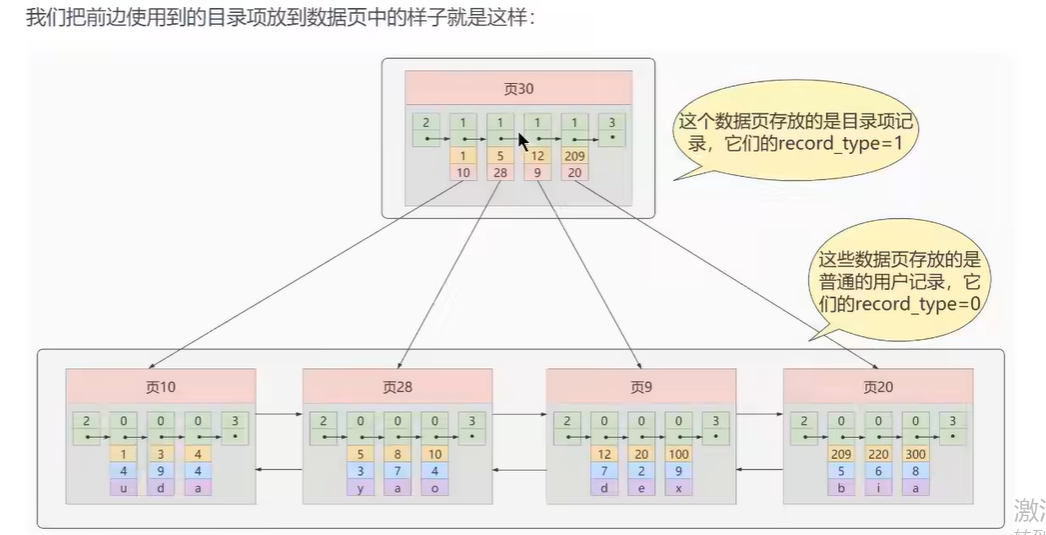
- 需要给所有的页再建立一个目录项,这个目录项就叫做索引

让目录项(索引)也以链表的形式连接起来,形成一个目录页(存的都是目录)

单个目录页 :可以快速通过扫描目录页,再通过目录页扫描数据页,只需要IO两次,加载2个页就能查到数据
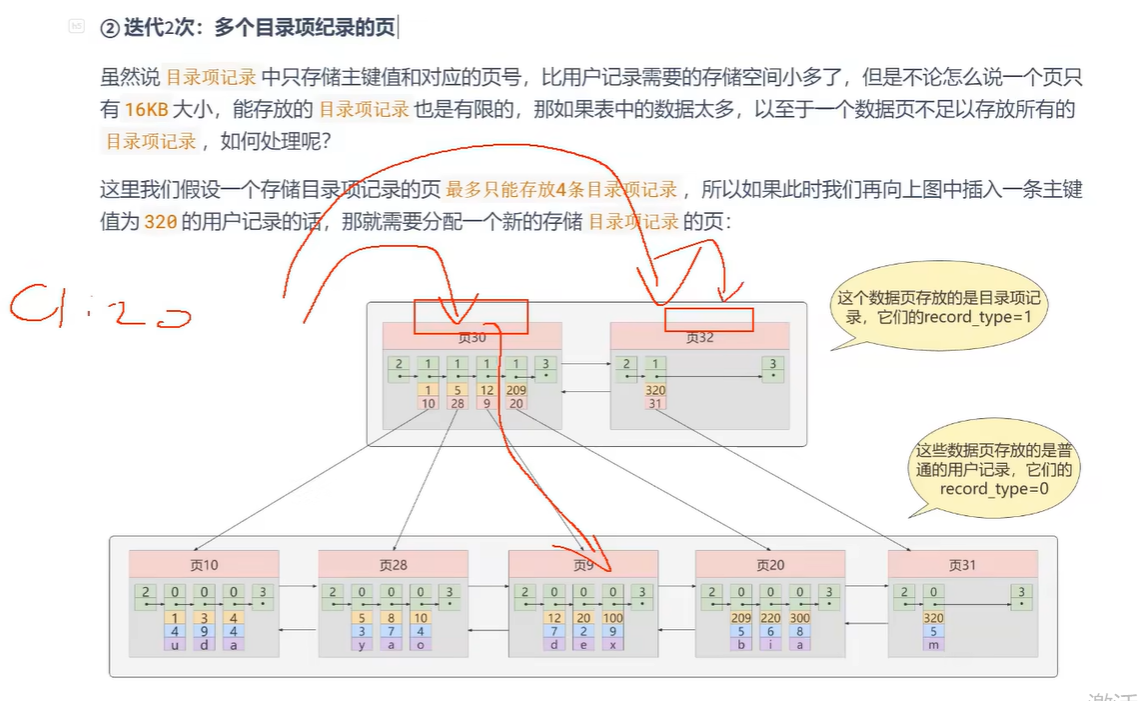
多个目录页 如果第一次IO,目录页没查到,就要加载第二个目录页
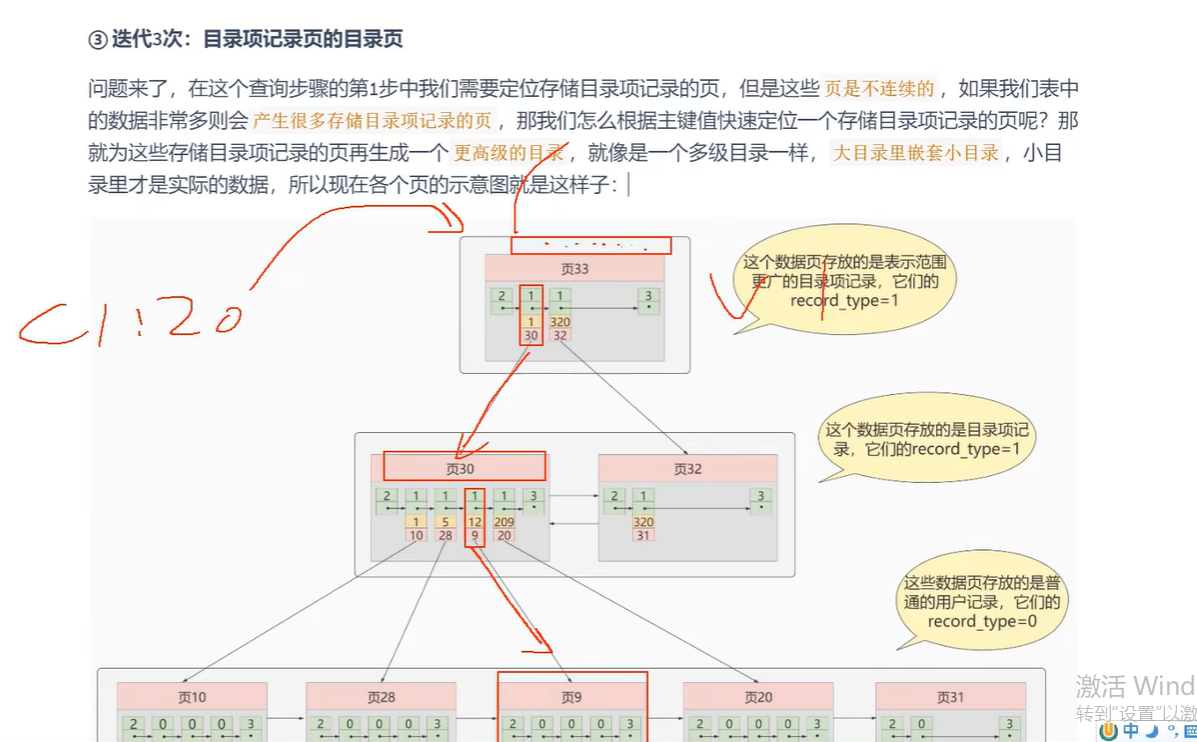
- 多级目录 在数据量非常大的情况,可以减少IO次数
- B+树的数据结构
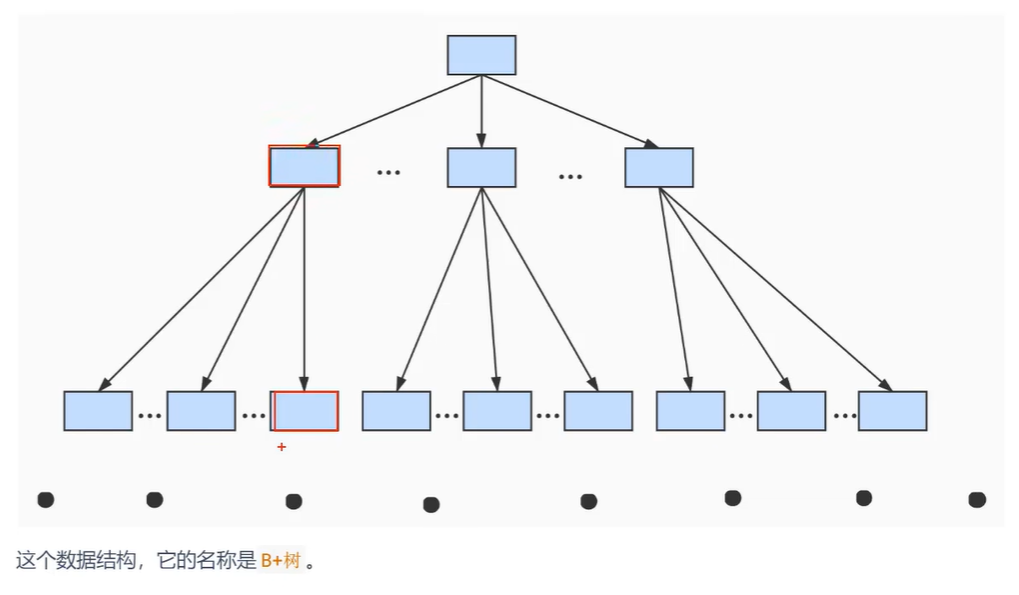
- B+树一般来说不会超过4层(4次IO) 有3层就能存1亿的数据

5.常见索引分类
- 聚簇索引和非聚簇索引





- 非聚簇索引(二级索引)
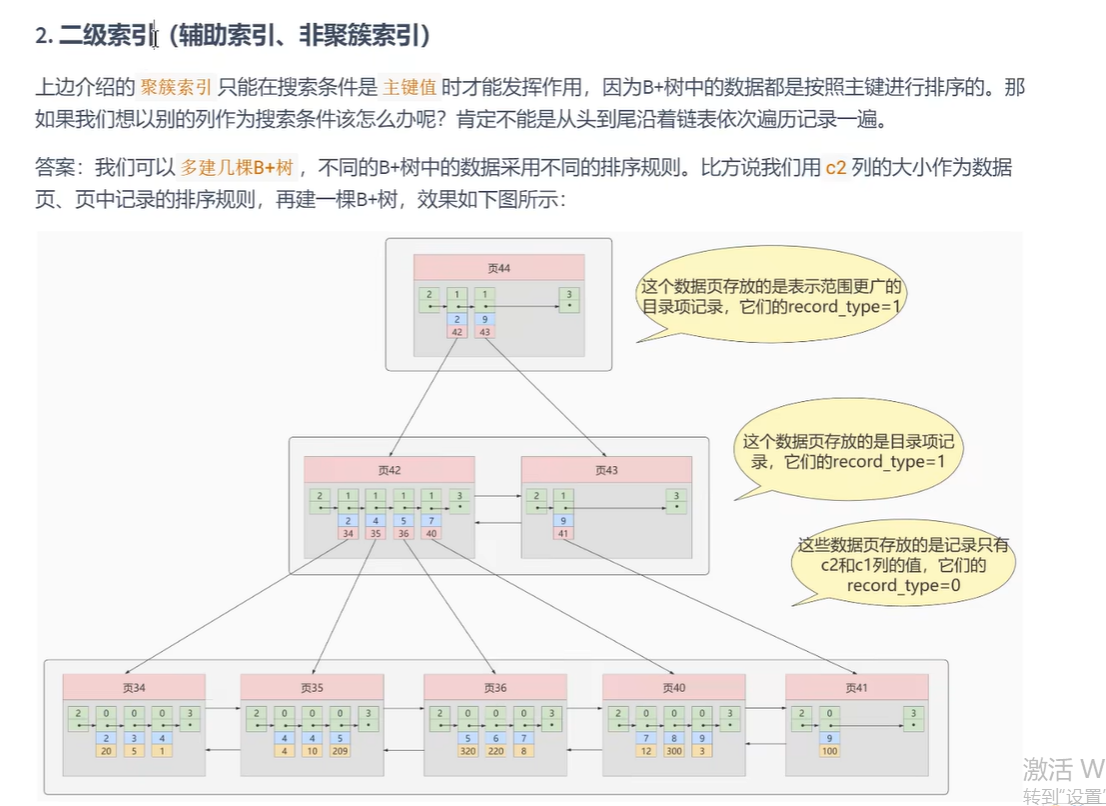

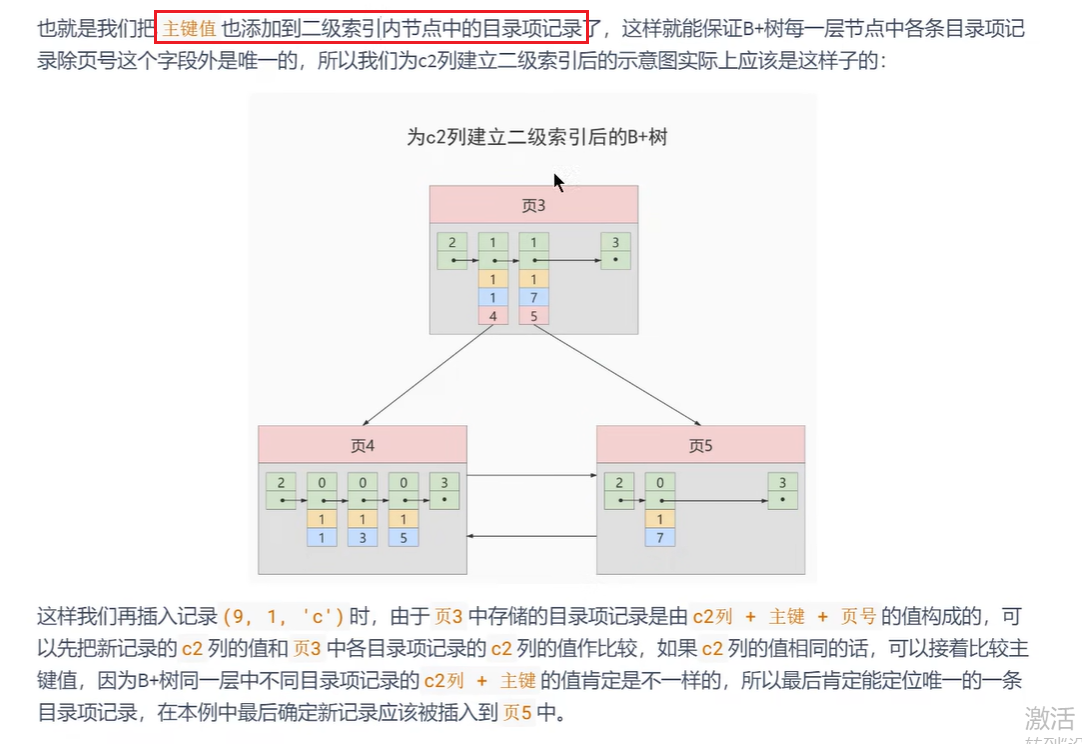
- 非聚簇索引c2的本质和c1没多少差别
- 回表,由于非聚簇索引只存了c2和c1字段,没有c3字段,所以要通过c2查到c1,通过c1再去查c3

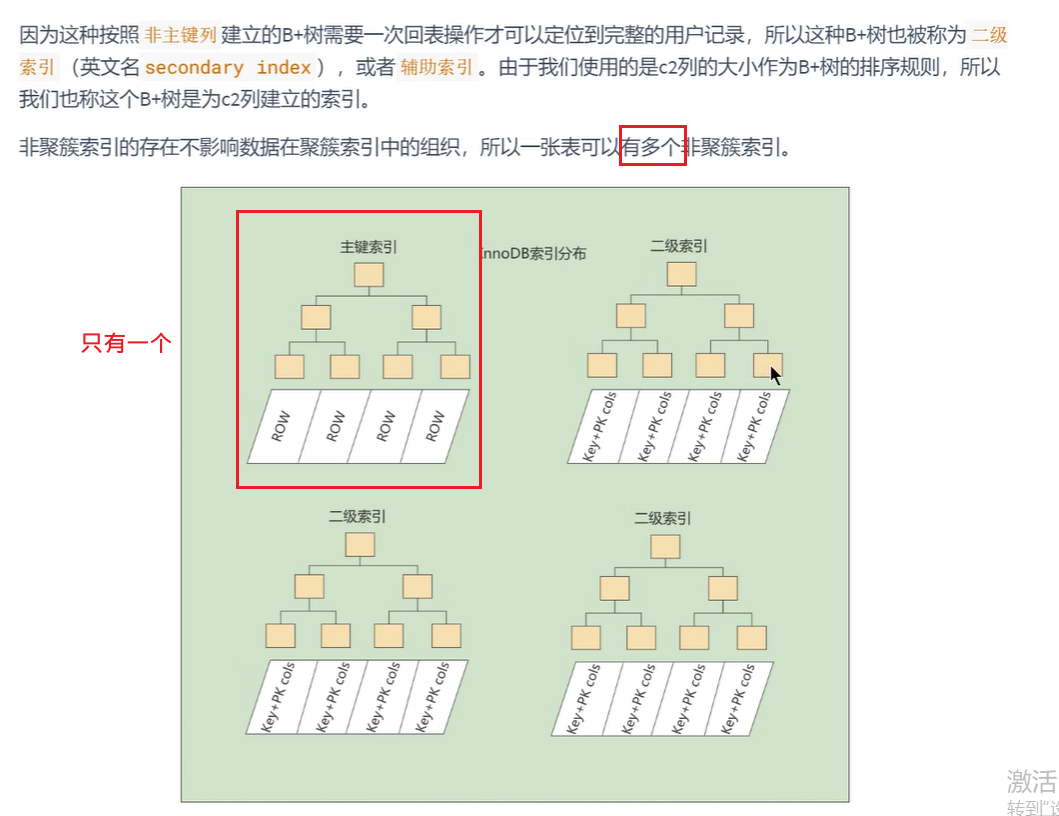
- 一个聚簇索引,多个非聚簇索引

- 联合索引

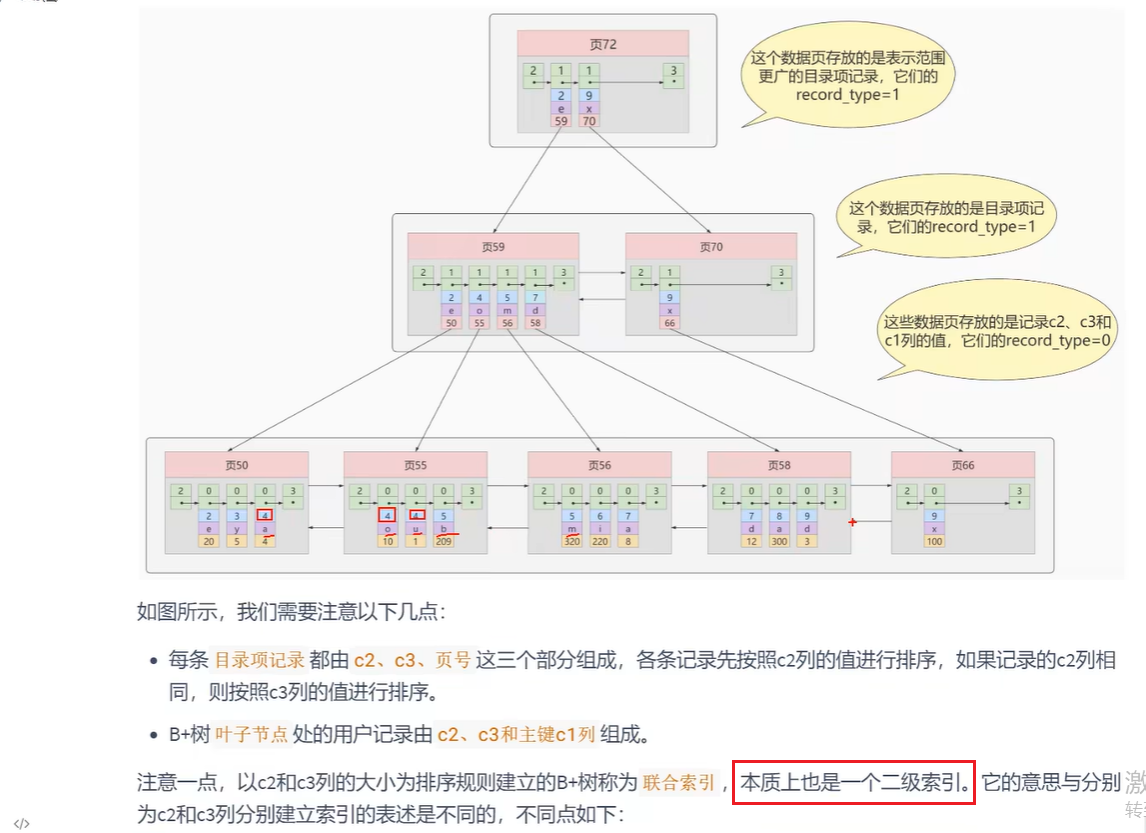

注意项 

MyISAM与InnoDB对比

- 索引的空间时间上的代价,要合理的去创建索引

Mysql数据结构选择的合理性


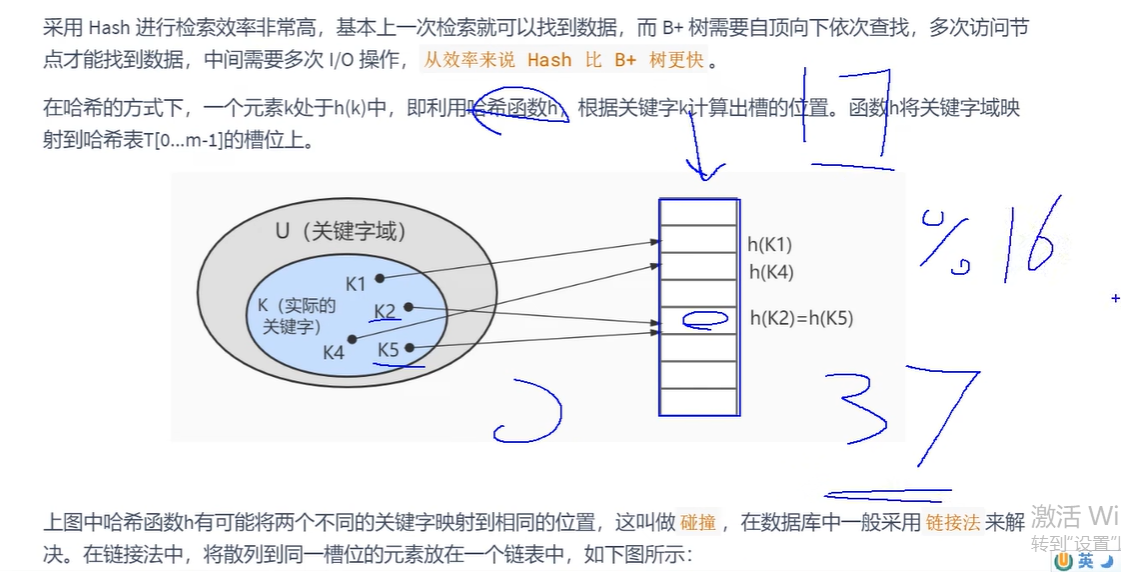
为什么不用Hash索引,而用B+树索引? 不够通用
