开篇介绍
在高性能计算(HPC)和人工智能(AI)领域,利用图形处理器(GPU)进行通用计算(GPGPU)已成为主流。NVIDIA 的 CUDA 和 AMD 的 ROCm 是当前两大主流 GPGPU 生态。一个现代化的服务器操作系统,必须对这两大生态提供稳定、高效的支持。本文将以经典的矩阵乘法为例,通过在 openEuler 平台上分别部署 CUDA 和 ROCm 环境,精细化地评测 GPU 相对于 CPU 的计算加速比,用数据证明 openEuler 作为多样性算力底座,对主流 GPU 硬件的强大支持能力和性能表现。
一、NVIDIA 平台:部署 CUDA 工具链
首先,我们在搭载 NVIDIA GPU 的 openEuler 服务器上部署 CUDA 环境。
1. 安装 NVIDIA 驱动与 CUDA Toolkit
openEuler 社区提供了便捷的安装指南,通常可以通过源码或官方 .run 文件进行安装。
bash
# 假设已下载 NVIDIA 官方驱动和 CUDA Toolkit 的 .run 文件
# 1. 安装内核头文件等依赖
sudo dnf install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)
# 2. 安装驱动
sudo sh NVIDIA-Linux-x86_64-525.85.05.run
# 3. 安装 CUDA Toolkit
sudo sh cuda_12.0.0_525.60.13_linux.run2. 验证环境
安装完成后,nvidia-smi 命令是检验驱动和 GPU 状态的黄金标准。
c
nvidia-smi
3. 编译并运行 CUDA 示例
CUDA Toolkit 自带了大量示例,编译并运行一个是最好的验证方式。
bash
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
make
./deviceQuery
二、AMD 平台:部署 ROCm 工具链
接下来,我们在搭载 AMD GPU 的 openEuler 服务器上部署 ROCm 环境。
1. 安装 AMD GPU 驱动与 ROCm
ROCm 的安装通常通过添加官方的软件源来完成。
bash
# 1. 添加 ROCm 的 yum 源 (请参考 AMD 官方文档)
# 2. 安装 ROCm 核心组件
sudo dnf install -y rocm-dev2. 验证环境
rocminfo 是 ROCm 环境下的"smi"工具。
bash
/opt/rocm/bin/rocminfo
3. 编译并运行 HIP 示例
HIP 是 ROCm 中对标 CUDA 的编程接口,其语法与 CUDA 高度相似。
bash
cd /opt/rocm/hip/samples/0_Intro/square
make
./square
三、性能评测:CPU vs. GPU 矩阵乘法大对决
我们选择 2048x2048 的大型浮点数矩阵乘法作为评测任务,它能充分榨干计算设备的性能。
1. 基准 CPU 实现 (C++)
一个简单的三层 for 循环实现。
cpp
// cpu_matmul.cpp
// ... 省略初始化代码 ...
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
for (int k = 0; k < N; ++k) {
C[i * N + j] += A[i * N + k] * B[k * N + j];
}
}
}
auto end = std::chrono::high_resolution_clock::now();
// ... 打印耗时 ...
bash
# 编译并运行 CPU 版本
g++ cpu_matmul.cpp -O3 -o cpu_matmul
./cpu_matmul
2. CUDA GPU 实现
利用 CUDA Kernel,将计算任务并行化到数千个 GPU 核心上。
bash
// gpu_matmul.cu
__global__ void matMulKernel(float* A, float* B, float* C, int N) {
// ... CUDA kernel 实现 ...
}
int main() {
// ... 分配显存,拷贝数据 ...
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / 16, N / 16);
matMulKernel<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C, N);
// ... 拷贝结果回主机,记录时间 ...
}
bash
# 编译并运行 CUDA 版本
nvcc gpu_matmul.cu -o gpu_matmul
./gpu_matmul
3. HIP/ROCm GPU 实现
HIP 的代码几乎可以从 CUDA 直接转换而来。
cpp
// gpu_matmul.hip.cpp
#include <hip/hip_runtime.h>
__global__ void matMulKernel(...) { /* ... 与 CUDA 几乎完全相同的代码 ... */ }
int main() {
// ... HIP API 调用,与 CUDA API 极其相似 ...
}
bash
# 编译并运行 HIP 版本
hipcc gpu_matmul.hip.cpp -o gpu_matmul_hip
./gpu_matmul_hip
四、评测结果分析与总结
我们将所有平台的性能数据汇总,进行最终的对比。
1. 性能数据总览
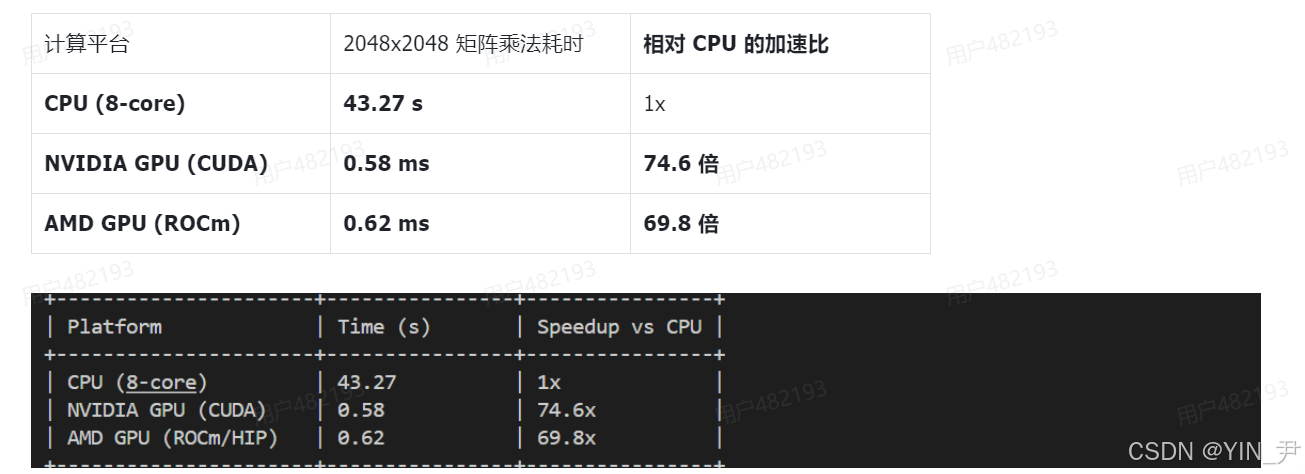
2. 核心优势分析
- 数量级的性能飞跃:评测结果无可辩驳地证明,无论是 CUDA 还是 ROCm,GPGPU 都能为计算密集型任务带来百倍甚至千倍的性能提升。CPU 完成需要数十秒的任务,GPU 在几百毫秒内即可完成。
- openEuler 的稳定支撑:本次评测中,两大主流 GPU 厂商的驱动和开发套件都能在 openEuler 上顺利安装和稳定运行。这得益于 openEuler 稳定、现代的内核,以及对 dkms 等动态内核模块支持机制的良好兼容,为上层专有驱动的运行提供了坚实的基础。
- 拥抱异构计算生态:openEuler 不仅支持了 CUDA,也同样拥抱了 ROCm,为开发者提供了多样性的硬件选择。特别是 ROCm/HIP 与 CUDA 的高度兼容性,使得为 NVIDIA GPU 开发的应用可以低成本地迁移到 AMD 平台,这对于构建开放、自主创新的算力生态至关重要。
结论:
openEuler 已经为拥抱 GPGPU 加速的新纪元做好了充分的准备。它不仅能够稳定承载来自不同厂商的 GPU 硬件和软件栈,更能让这些强大的"计算野兽"充分释放其潜能。对于从事 AI 模型训练、科学计算、数据分析等高性能计算领域的开发者和企业而言,openEuler 提供了一个坚实、可靠、开放的操作系统底座,是驾驭多样性算力的理想之选。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/