前言
在部署Stable Diffusion进行AI绘画时,ComfyUI以其节点式工作流和高效内存管理受到广泛欢迎。然而,许多用户在实际使用中常遇到两大痛点:GPU使用率低导致生成速度慢 ,或工作流完全运行在CPU上。本文将系统性地解决这些问题,从原理到实践,带你全面掌握ComfyUI的GPU配置。
目录
[1.1 环境层检查:PyTorch与CUDA](#1.1 环境层检查:PyTorch与CUDA)
[1.2 ComfyUI启动验证](#1.2 ComfyUI启动验证)
[2.1 启动参数精细化配置](#2.1 启动参数精细化配置)
[2.2 工作流节点级GPU配置](#2.2 工作流节点级GPU配置)
[2.2.1 常见节点类型与GPU配置方式](#2.2.1 常见节点类型与GPU配置方式)
[2.2.2 检查模型加载节点设备状态](#2.2.2 检查模型加载节点设备状态)
[2.2.3 排查CPU瓶颈节点](#2.2.3 排查CPU瓶颈节点)
[2.3 环境变量配置技巧](#2.3 环境变量配置技巧)
[4.1 TensorRT加速部署](#4.1 TensorRT加速部署)
[4.2 模型量化技术](#4.2 模型量化技术)
[4.3 多GPU负载均衡策略](#4.3 多GPU负载均衡策略)
[5.1 实时监控工具](#5.1 实时监控工具)
[5.2 常见性能瓶颈与解决](#5.2 常见性能瓶颈与解决)
[5.3 最佳实践配置示例](#5.3 最佳实践配置示例)
[Q1:启动时显示"Out of memory"但显存充足?](#Q1:启动时显示“Out of memory”但显存充足?)
一、核心问题诊断:为什么GPU没有被正确调用?
在深入配置之前,我们必须先理解ComfyUI的GPU调用机制。与Stable Diffusion WebUI不同,ComfyUI采用分散式节点架构,每个节点的运算设备可能不同,这为GPU配置带来了复杂性。
1.1 环境层检查:PyTorch与CUDA
这是所有GPU加速的基础,90%的GPU调用问题都源于此。首先需要验证你的PyTorch环境是否正确配置了GPU支持。
打开命令行工具,运行以下Python代码进行验证:
python
import torch
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA是否可用: {torch.cuda.is_available()}") # 重点检查此项!
print(f"CUDA版本: {torch.version.cuda}")
print(f"GPU设备数量: {torch.cuda.device_count()}")
print(f"当前GPU设备名: {torch.cuda.get_device_name(0) if torch.cuda.device_count() > 0 else '无'}")关键结果分析:
-
若
CUDA是否可用返回False:说明PyTorch安装的是CPU版本,需要重新安装 -
若CUDA版本为
None:PyTorch与CUDA驱动不匹配 -
若GPU设备数为
0:系统未识别到NVIDIA GPU
解决方案:访问PyTorch官网,根据你的CUDA版本选择正确的安装命令。 例如,CUDA 11.8对应的命令为:
bash
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1181.2 ComfyUI启动验证
即使PyTorch环境正常,ComfyUI也可能无法调用GPU。启动ComfyUI时,务必观察控制台输出的前几行日志,寻找关键信息:
bash
Using GPU: NVIDIA GeForce RTX 4090 (ID: 0) # 正确识别
# 或
Using CPU only # 有问题!如果日志中没有GPU信息,检查启动命令是否意外包含了--cpu参数。
二、高级配置:优化GPU使用率与性能
当GPU被正确识别后,下一步是优化其使用率。根据硬件配置不同,推荐以下策略:
2.1 启动参数精细化配置
ComfyUI提供了丰富的启动参数,针对不同场景优化GPU使用:
bash
# 高性能多GPU配置示例(适用于显存≥12GB)
CUDA_VISIBLE_DEVICES=0,1 python main.py --highvram --xformers --fp16-unet
# 中等配置优化(单卡,显存8-12GB)
python main.py --xformers --fp16-unet
# 低显存配置(显存<8GB)
python main.py --lowvram --xformers --fp16-unet --ckpt-cache 50参数详解:
| 参数 | 作用 | 推荐场景 |
|---|---|---|
--highvram |
保持所有模型在显存中 | 多卡/大显存(≥12GB) |
--lowvram |
智能拆分模型减少显存占用 | 中等显存(8-12GB) |
--xformers |
关键优化:使用高效注意力机制,提升速度20-50% | 所有NVIDIA GPU |
--fp16-unet |
UNet使用半精度计算,节省显存30% | 所有支持FP16的GPU |
--ckpt-cache <大小> |
缓存模型到内存,减少磁盘IO | 机械硬盘或模型多 |
2.2 工作流节点级GPU配置
这是ComfyUI特有的配置环节,直接影响GPU使用率。与WebUI不同,ComfyUI的每个模型加载节点可以独立设置设备。
2.2.1 常见节点类型与GPU配置方式
| 节点类型 | 核心节点示例 | GPU配置关键点 | 检查与设置方法 |
|---|---|---|---|
| 基础模型加载 | Checkpoint Loader, VAE Loader | 默认在GPU,受启动参数控制 | 右键菜单查看,应显示Convert to CPU(表示已在GPU) |
| 采样与解码 | KSampler, VAE Decode | 设备由输入模型决定 | 无直接设备选项,确保上游正确 |
| 控制网 & LoRA | ControlNet Loader, Lora Loader | 自动匹配主模型设备 | 同基础加载器 |
| 自定义节点 | 图像处理、AI抠图等插件 | 可能有独立设备设置 | 属性面板查找device、use_gpu参数 |
| 外部API节点 | GPT-4o、Flux调用节点 | 计算在云端 | 无需本地GPU设置 |
2.2.2 检查模型加载节点设备状态
-
在工作流中找到所有模型加载节点 :
Load Checkpoint、VAE Loader、CLIP Loader -
右键单击这些节点,查看上下文菜单
-
确认菜单显示为
Convert to CPU(表示当前在GPU上)
关键检查点:如果右键菜单显示的是Convert to GPU,说明该模型被强制加载到CPU上!点击此选项将其切换到GPU。
2.2.3 排查CPU瓶颈节点
某些自定义节点可能强制使用CPU,成为整个工作流的瓶颈:
-
图像处理节点:部分超分辨率(Upscale)、面部修复(Face Restoration)节点
-
后处理节点:某些VAE解码器的变体版本
-
自定义节点:从ComfyUI Manager安装的第三方节点
检查方法: 单击可疑节点,在属性面板中查找device、use_gpu、force_cpu等参数,确保其设置为gpu或cuda。
2.3 环境变量配置技巧
CUDA_VISIBLE_DEVICES环境变量是精确控制GPU使用的关键:
bash
# 仅使用第一块GPU
CUDA_VISIBLE_DEVICES=0 python main.py
# 使用前两块GPU
CUDA_VISIBLE_DEVICES=0,1 python main.py
# 排除有问题的GPU(如集成显卡)
CUDA_VISIBLE_DEVICES=1 python main.py # 跳过GPU 0诊断环境变量状态:
-
Windows:
echo %CUDA_VISIBLE_DEVICES% -
Linux/macOS:
echo $CUDA_VISIBLE_DEVICES
如果输出为空或意外值,取消设置后重试:
bash
# Windows
set CUDA_VISIBLE_DEVICES=
python main.py
# Linux/macOS
unset CUDA_VISIBLE_DEVICES
python main.py三、系统化诊断流程:从问题到解决
以下是解决GPU问题的标准化流程,可按步骤执行:
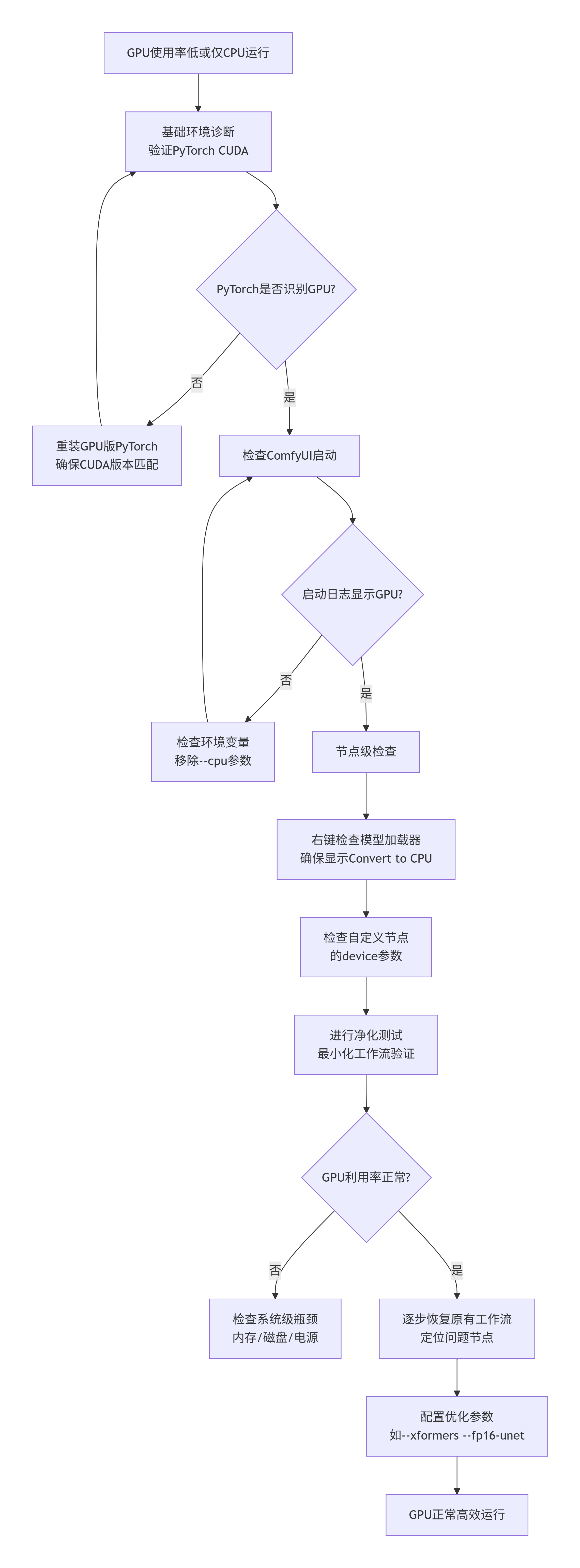
四、进阶优化:解锁GPU全部潜能
4.1 TensorRT加速部署
对于NVIDIA显卡用户,TensorRT可提供额外的30-100%性能提升:
1.安装ComfyUI-TensorRT扩展:
bash
cd ComfyUI/custom_nodes
git clone https://github.com/comfyanonymous/ComfyUI-TensorRT.git
cd ComfyUI-TensorRT && pip install -r requirements.txt2.将常用模型转换为TensorRT引擎(首次使用需要转换,耗时较久但一劳永逸)
3.在工作流中使用TensorRTLoader节点替代普通Load Checkpoint
4.2 模型量化技术
通过降低模型精度减少显存占用:
-
FP16模型:最推荐,几乎无质量损失,显存节省50%
-
INT8模型:进一步压缩,适合低显存卡(<6GB),可能有细微质量损失
-
QLoRA/LoRA适配器:将大模型适配到小显存
量化模型可从Civitai、HuggingFace等平台下载,放入ComfyUI/models/对应文件夹。
4.3 多GPU负载均衡策略
当拥有多张GPU时,可以优化资源配置:
bash
# 策略1:模型并行(大模型拆分到多卡)
python main.py --multi-gpu
# 策略2:工作流并行(不同工作流分配不同GPU)
# 启动两个ComfyUI实例,分别指定不同GPU
CUDA_VISIBLE_DEVICES=0 python main.py --port 8188
CUDA_VISIBLE_DEVICES=1 python main.py --port 8189五、性能监控与调优
5.1 实时监控工具
-
Windows任务管理器:查看GPU利用率、显存占用、电源限制
-
nvidia-smi (命令行工具):
nvidia-smi -l 1每秒刷新一次 -
GPU-Z:监控传感器数据,排查功耗和温度限制
-
ComfyUI系统信息 :访问
http://localhost:8188/system_stats
5.2 常见性能瓶颈与解决
| 瓶颈类型 | 症状 | 解决方案 |
|---|---|---|
| CPU瓶颈 | GPU利用率间歇性下降,CPU持续高负载 | 1. 简化复杂预处理节点 2. 增加--cpu-vae参数 3. 升级CPU或减少后台进程 |
| 显存瓶颈 | 显存接近100%,GPU利用率低且波动大 | 1. 启用--lowvram模式 2. 使用FP16模型 3. 降低图像分辨率或批次大小 |
| IO瓶颈 | 生成开始前有明显延迟 | 1. 增加--ckpt-cache值 2. 将模型移至SSD硬盘 3. 使用内存盘缓存常用模型 |
| 电源/温度限制 | GPU频率波动大,性能不稳定 | 1. 改善机箱散热 2. 调整电源管理模式为"最高性能" 3. 清理显卡灰尘和散热器 |
5.3 最佳实践配置示例
以下是根据不同硬件配置推荐的优化组合:
RTX 4090(24GB显存)顶级配置:
bash
CUDA_VISIBLE_DEVICES=0 python main.py --highvram --xformers --fp16-unet --fp16-vae --gpu-onlyRTX 3060(12GB显存)平衡配置:
bash
# Windows PowerShell
python -c "import torch; torch.cuda.empty_cache()"
# 或在启动参数中添加
python main.py --disable-cuda-cache
bash
python main.py --xformers --fp16-unet --ckpt-cache 100GTX 1660(6GB显存)入门配置:
bash
python main.py --lowvram --xformers --fp16-unet --always-gpu六、疑难问题专项解决
Q1:启动时显示"Out of memory"但显存充足?
原因 :内存碎片化或PyTorch缓存占用。
解决:在启动前清理缓存:
bash
# Windows PowerShell
python -c "import torch; torch.cuda.empty_cache()"
# 或在启动参数中添加
python main.py --disable-cuda-cacheQ2:特定工作流GPU利用率正常,但自己的很低?
原因 :工作流设计存在CPU-GPU频繁切换。
解决:
-
使用净化测试法:新建最小工作流测试GPU利用率
-
逐步添加原有节点,监控利用率变化
-
定位到导致下降的特定节点后,寻找替代方案
Q3:AMD显卡如何配置?
当前建议:使用DirectML后端(Windows)或ROCm(Linux)
bash
# DirectML(Windows)
python main.py --directml
# ROCm(Linux,需要特定版本)
HSA_OVERRIDE_GFX_VERSION=10.3.0 python main.py --use-pytorch-cross-attention结语
7.1 配置优先级
-
基础环境:PyTorch GPU版 + CUDA驱动
-
启动参数 :
--xformers+--fp16-unet+ 合适的内存模式 -
节点检查:模型加载器状态 + 自定义节点设备设置
-
进阶优化:TensorRT/量化模型 + 多GPU分配
7.2 维护建议
-
定期更新显卡驱动、CUDA、PyTorch
-
关注ComfyUI更新日志,及时调整配置
-
使用ComfyUI Manager管理自定义节点
-
备份优化后的工作流和配置
7.3 获取帮助
-
提供详细信息:显卡型号、显存、PyTorch版本、完整错误日志
-
使用
nvidia-smi和任务管理器截图 -
分享问题工作流的JSON文件
正确配置ComfyUI的GPU运算不仅需要理解各个参数的作用,更需要系统化的诊断思维。从环境基础(PyTorch+CUDA)到启动参数,再到工作流节点级优化,每一层都可能成为性能瓶颈。记住关键检查点:PyTorch CUDA验证 → 启动日志确认 → 模型节点右键检查 → 环境变量清理 → 性能参数调优。
随着ComfyUI生态快速发展,新的优化技术和插件不断涌现。建议定期关注官方GitHub和社区论坛,保持配置方案与时俱进。当遇到特定问题时,提供详细的硬件信息、软件版本和错误日志,社区通常能给出针对性建议。