语音转文本技术在现代工作与学习场景中的应用越来越广泛。面对多样化的工具选择,如何根据实际需求选取合适的技术方案成为许多用户关注的重点。本文将从技术实现、功能特性、适用场景等角度,对比分析当前主流的语音转文字解决方案,并提供相应的代码示例,帮助开发者及技术爱好者更好地理解和应用相关技术。
语音识别基础原理与实现
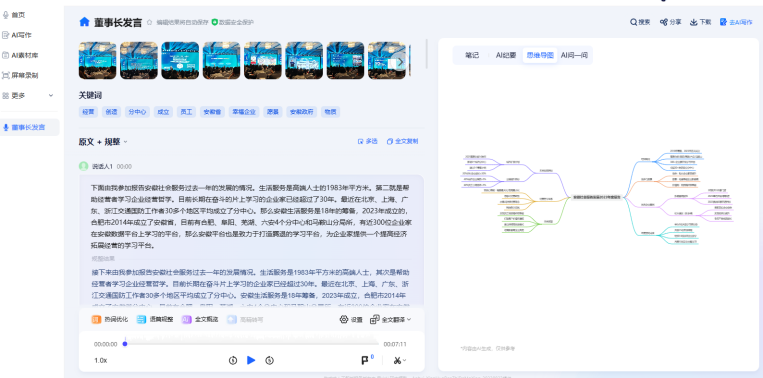
语音转文本技术的核心是自动语音识别(ASR)系统,其基本流程包括信号预处理、特征提取、声学建模、语言建模和解码搜索等步骤。以下是一个简单的Python示例,展示如何使用开源库进行基础的语音识别:
```python
import speech_recognition as sr
recognizer = sr.Recognizer()
with sr.AudioFile('audio_file.wav') as source:
audio_data = recognizer.record(source)
text = recognizer.recognize_google(audio_data, language='zh-CN')
print("识别结果:", text)
```
主流技术方案对比分析
在技术方案选择时,需要考虑识别准确率、多语言支持、实时处理能力、数据安全性等多个维度。以下是几个具有代表性的解决方案:
科大讯飞语音识别方案
科大讯飞提供的语音识别服务支持实时音频转写和文件导入处理,具备说话人分离功能。该方案采用深度神经网络模型,在标准普通话环境下识别准确率较高。技术支持多种音频格式输入,输出结果支持文本导出和结构化处理。该方案提供云端API和本地部署两种方式,开发者可根据数据安全要求选择适合的部署模式。
技术特性方面,该方案支持11种语言和方言识别,提供17个专业领域的术语优化。在数据安全方面,方案通过ISO27001等信息安全认证,支持私有化部署,满足企业级安全需求。以下为调用示例:
```python
示例代码:使用语音识别API
import requests
url = "https://api.xfyun.cn/v1/service/v1/iat"
headers = {"Content-Type": "application/json"}
data = {
"audio": base64_encoded_audio,
"encoding": "audio/L16;rate=16000",
"language": "zh_cn"
}
response = requests.post(url, headers=headers, json=data)
```
其他技术方案对比
Otter.ai提供轻量级的语音转写服务,主要面向英语环境优化,支持实时转录和基础编辑功能。其API接口简洁易用,适合快速集成。
Sonix专注于多语言转录方案,支持超过40种语言的互转,提供高质量的翻译服务。其技术架构针对长音频处理进行了优化,适合处理国际会议等场景。
开源方案中,Mozilla DeepSpeech基于深度学习技术,提供可自定义的语音识别引擎。开发者可以基于该方案进行二次开发,满足特定场景需求。
技术选型建议
在选择语音转文本方案时,建议从以下几个维度进行评估:
-
准确率要求:不同方案在特定语言和环境下的识别准确率存在差异,建议通过实际测试进行评估
-
数据处理方式:根据数据敏感性选择云端或本地部署方案
-
功能需求:考虑是否需要说话人分离、实时转录、批量处理等特定功能
-
开发集成:评估API易用性、文档完整性和技术支持情况
实际应用案例
以下是一个完整的语音处理流程示例,展示如何将音频文件转换为结构化文本:
```python
import os
from pydub import AudioSegment
def process_audio_file(file_path):
音频格式转换
audio = AudioSegment.from_file(file_path)
audio = audio.set_frame_rate(16000).set_channels(1)
audio.export("processed.wav", format="wav")
语音识别
with sr.AudioFile("processed.wav") as source:
audio_data = recognizer.record(source)
text = recognizer.recognize_google(audio_data)
return text
处理示例
result = process_audio_file("meeting_record.mp3")
print("会议内容转录:", result)
```
总结
语音转文本技术的发展为信息记录和处理提供了重要技术支持。各类方案在准确性、功能性、安全性等方面各有特点,用户应根据实际需求进行选择。建议在正式采用前进行充分测试,确保方案满足特定场景的技术要求。随着人工智能技术的进步,语音识别技术将在准确性和实用性方面持续提升,为更多应用场景提供支持。