AI agents 的未来是模型能够无缝地跨越数百甚至数千个工具进行工作。一个集成了 git 操作、文件操作、包管理器、测试框架和部署流水线的 IDE 助手。一个同时连接 Slack、GitHub、Google Drive、Jira、公司数据库和数十个 MCP 服务器的运营协调器。
为了构建有效的 agents,它们需要能够使用无限的工具库,而无需预先将每个定义都填充到上下文中。我们关于使用 MCP 执行代码的博客文章讨论了工具结果和定义有时会在 agent 读取请求之前消耗 50,000+ 个 token。Agents 应该按需发现和加载工具,只保留与当前任务相关的内容。
Agents 还需要从代码中调用工具的能力。当使用自然语言工具调用时,每次调用都需要完整的推理过程,中间结果无论是否有用都会在上下文中堆积。代码是编排逻辑的自然选择,例如循环、条件和数据转换。Agents 需要根据手头的任务灵活选择代码执行和推理。
Agents 还需要从示例中学习正确的工具使用方法,而不仅仅是模式定义。JSON 模式定义了结构上有效的内容,但无法表达使用模式:何时包含可选参数、哪些组合有意义,或者您的 API 期望什么约定。
今天,我们推出了三个实现这一目标的功能:
- 工具搜索工具:允许 Claude 使用搜索工具访问数千个工具而不会消耗其上下文窗口
- 程序化工具调用:允许 Claude 在代码执行环境中调用工具,减少对模型上下文窗口的影响
- 工具使用示例:为演示如何有效使用特定工具提供了通用标准
在内部测试中,我们发现这些功能帮助我们构建了使用传统工具使用模式无法实现的东西。例如,Claude for Excel 使用程序化工具调用读取和修改包含数千行的电子表格,而不会过载模型的上下文窗口。
基于我们的经验,我们相信这些功能为您可以用 Claude 构建的东西开辟了新的可能性。
工具搜索工具
挑战
MCP 工具定义提供了重要的上下文,但随着更多服务器的连接,这些 token 会累积起来。考虑一个五服务器设置:
- GitHub:35 个工具(约 26K tokens)
- Slack:11 个工具(约 21K tokens)
- Sentry:5 个工具(约 3K tokens)
- Grafana:5 个工具(约 3K tokens)
- Splunk:2 个工具(约 2K tokens)
这是 58 个工具在对话开始前消耗约 55K tokens。添加更多服务器如 Jira(仅它就使用约 17K tokens),您很快就会接近 100K+ token 的开销。在 Anthropic,我们看到优化前工具定义消耗了 134K tokens。
但 token 成本不是唯一的问题。最常见的失败是错误的工具选择和不正确的参数,特别是当工具有相似名称时,如 notification-send-user vs notification-send-channel。
我们的解决方案
工具搜索工具不是预先加载所有工具定义,而是按需发现工具。Claude 只看到它当前任务实际需要的工具。
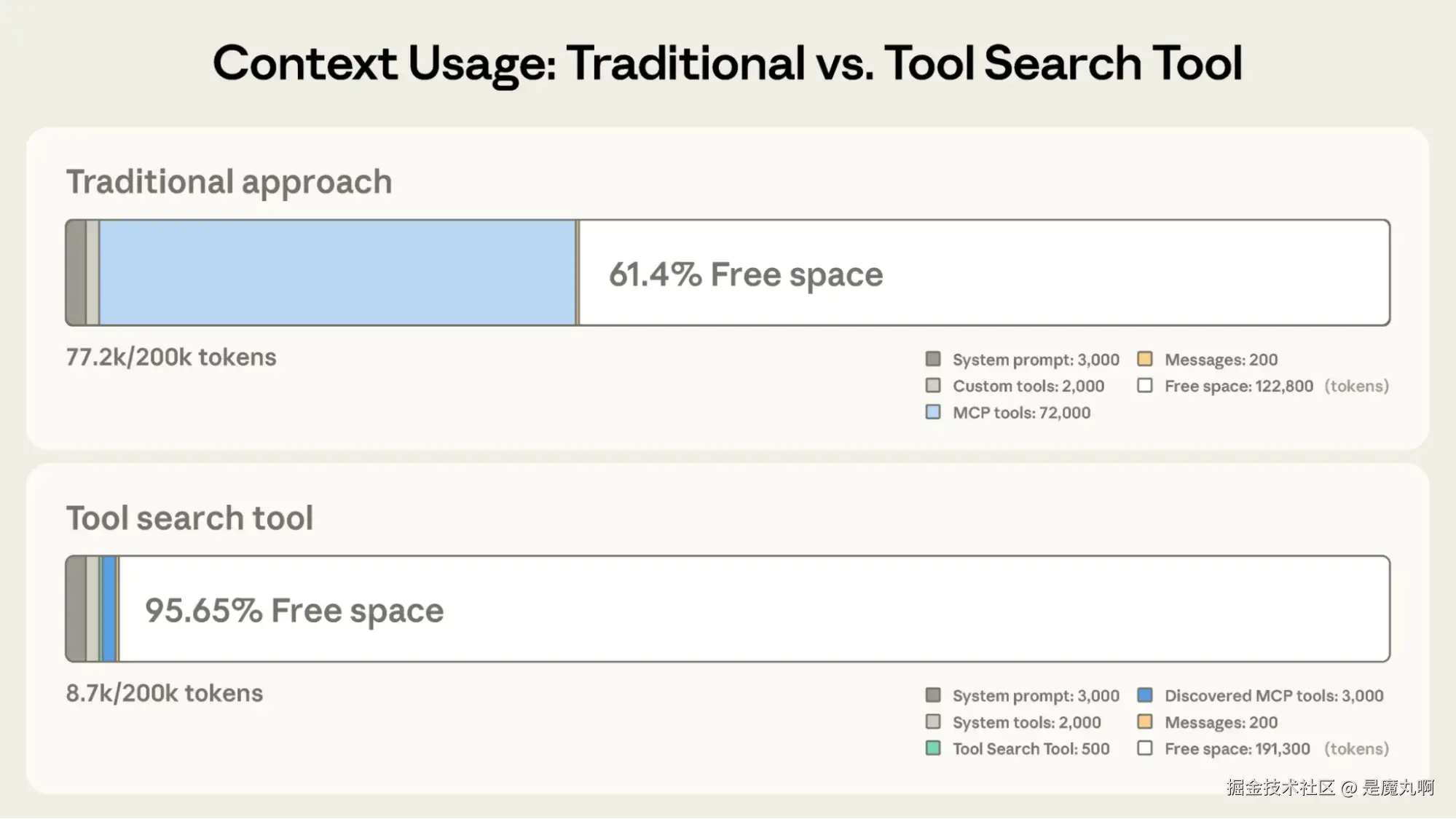
与 Claude 传统方法的 122,800 tokens 相比,工具搜索工具保留了 191,300 tokens 的上下文。
传统方法:
- 所有工具定义预先加载(50+ MCP 工具约 72K tokens)
- 对话历史和系统提示竞争剩余空间
- 总上下文消耗:开始任何工作前约 77K tokens
使用工具搜索工具:
- 仅工具搜索工具预先加载(约 500 tokens)
- 工具按需发现(3-5 个相关工具,约 3K tokens)
- 总上下文消耗:约 8.7K tokens,保留 95% 的上下文窗口
这代表了 85% 的 token 使用减少,同时保持对完整工具库的访问。内部测试显示,在使用大型工具库时,MCP 评估的准确性显著提高。Opus 4 从 49% 提高到 74%,Opus 4.5 从 79.5% 提高到 88.1%。
工具搜索工具的工作原理
工具搜索工具让 Claude 动态发现工具,而不是预先加载所有定义。您向 API 提供所有工具定义,但使用 defer_loading: true 标记工具使其可按需发现。延迟工具最初不会加载到 Claude 的上下文中。Claude 只看到工具搜索工具本身以及任何带有 defer_loading: false 的工具(您最关键、最常使用的工具)。
当 Claude 需要特定功能时,它会搜索相关工具。工具搜索工具返回匹配工具的引用,这些引用会在 Claude 的上下文中展开为完整定义。
例如,如果 Claude 需要与 GitHub 交互,它会搜索 "github",只有 github.createPullRequest 和 github.listIssues 会被加载------而不是您来自 Slack、Jira 和 Google Drive 的其他 50+ 工具。
这样,Claude 可以访问您的完整工具库,而只需为其实际需要的工具支付 token 成本。
提示缓存说明: 工具搜索工具不会破坏提示缓存,因为延迟工具完全从初始提示中排除。它们只在 Claude 搜索它们后才添加到上下文中,因此您的系统提示和核心工具定义保持可缓存。
实现方式:
json
{
"tools": [
// 包含工具搜索工具(regex、BM25 或自定义)
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
// 标记工具以按需发现
{
"name": "github.createPullRequest",
"description": "Create a pull request",
"input_schema": {...},
"defer_loading": true
}
// ... 数百个带有 defer_loading: true 的延迟工具
]
}对于 MCP 服务器,您可以延迟加载整个服务器,同时保持特定高使用工具的加载:
json
{
"type": "mcp_toolset",
"mcp_server_name": "google-drive",
"default_config": {"defer_loading": true}, # 延迟加载整个服务器
"configs": {
"search_files": {
"defer_loading": false
} // 保持最常用的工具加载
}
}Claude 开发者平台开箱即用地提供基于 regex 和 BM25 的搜索工具,但您也可以使用嵌入或其他策略实现自定义搜索工具。
何时使用工具搜索工具
像任何架构决策一样,启用工具搜索工具涉及权衡。该功能在工具调用之前添加了搜索步骤,因此当上下文节省和准确性改进超过额外延迟时,它提供最佳 ROI。
适用场景:
- 工具定义消耗 >10K tokens
- 经历工具选择准确性问题
- 构建具有多个服务器的 MCP 驱动系统
- 有 10+ 个可用工具
不太适用场景:
- 小型工具库(<10 个工具)
- 所有工具在每个会话中频繁使用
- 工具定义紧凑
程序化工具调用
挑战
传统工具调用在工作流变得更复杂时产生两个基本问题:
- 中间结果污染上下文:当 Claude 分析 10MB 日志文件的错误模式时,整个文件进入其上下文窗口,尽管 Claude 只需要错误频率的摘要。当获取跨多个表的客户数据时,每条记录在上下文中累积,无论相关性如何。这些中间结果消耗大量 token 预算,并可能完全将重要信息推出上下文窗口。
- 推理开销和手动综合:每个工具调用需要完整的模型推理过程。收到结果后,Claude 必须"目视检查"数据以提取相关信息,推理各部分如何组合,并决定下一步做什么------所有这些都通过自然语言处理。五工具工作流意味着五次推理过程加上 Claude 解析每个结果、比较值和综合结论。这既慢又容易出错。
我们的解决方案
程序化工具调用使 Claude 能够通过代码而不是通过单独的 API 往返来编排工具。Claude 不是逐一请求工具,每个结果都返回到其上下文,而是编写调用多个工具、处理它们的输出并控制哪些信息实际进入其上下文窗口的代码。
Claude 擅长编写代码,通过让它用 Python 而不是通过自然语言工具调用来表达编排逻辑,您获得更可靠、精确的控制流。循环、条件、数据转换和错误处理都在代码中明确,而不是在 Claude 的推理中隐含。
示例:预算合规检查
考虑一个常见的业务任务:"哪些团队成员超出了他们的 Q3 差旅预算?"
您有三个可用工具:
get_team_members(department)- 返回团队成员列表,包含 ID 和级别get_expenses(user_id, quarter)- 返回用户的费用行项目get_budget_by_level(level)- 返回员工级别的预算限制
传统方法:
- 获取团队成员 → 20 人
- 对每个人,获取他们的 Q3 费用 → 20 次工具调用,每次返回 50-100 个行项目(航班、酒店、餐食、收据)
- 按员工级别获取预算限制
- 所有这些都进入 Claude 的上下文:2000+ 费用行项目(50 KB+)
- Claude 手动汇总每个人的费用,查找他们的预算,比较费用与预算限制
- 更多的模型往返,显著的上下文消耗
使用程序化工具调用:
每个工具结果不是返回到 Claude,Claude 编写编排整个工作流的 Python 脚本。脚本在代码执行工具(沙盒环境)中运行,当需要来自您的工具的结果时暂停。当您通过 API 返回工具结果时,它们由脚本处理,而不是由模型消费。脚本继续执行,Claude 只看到最终输出。
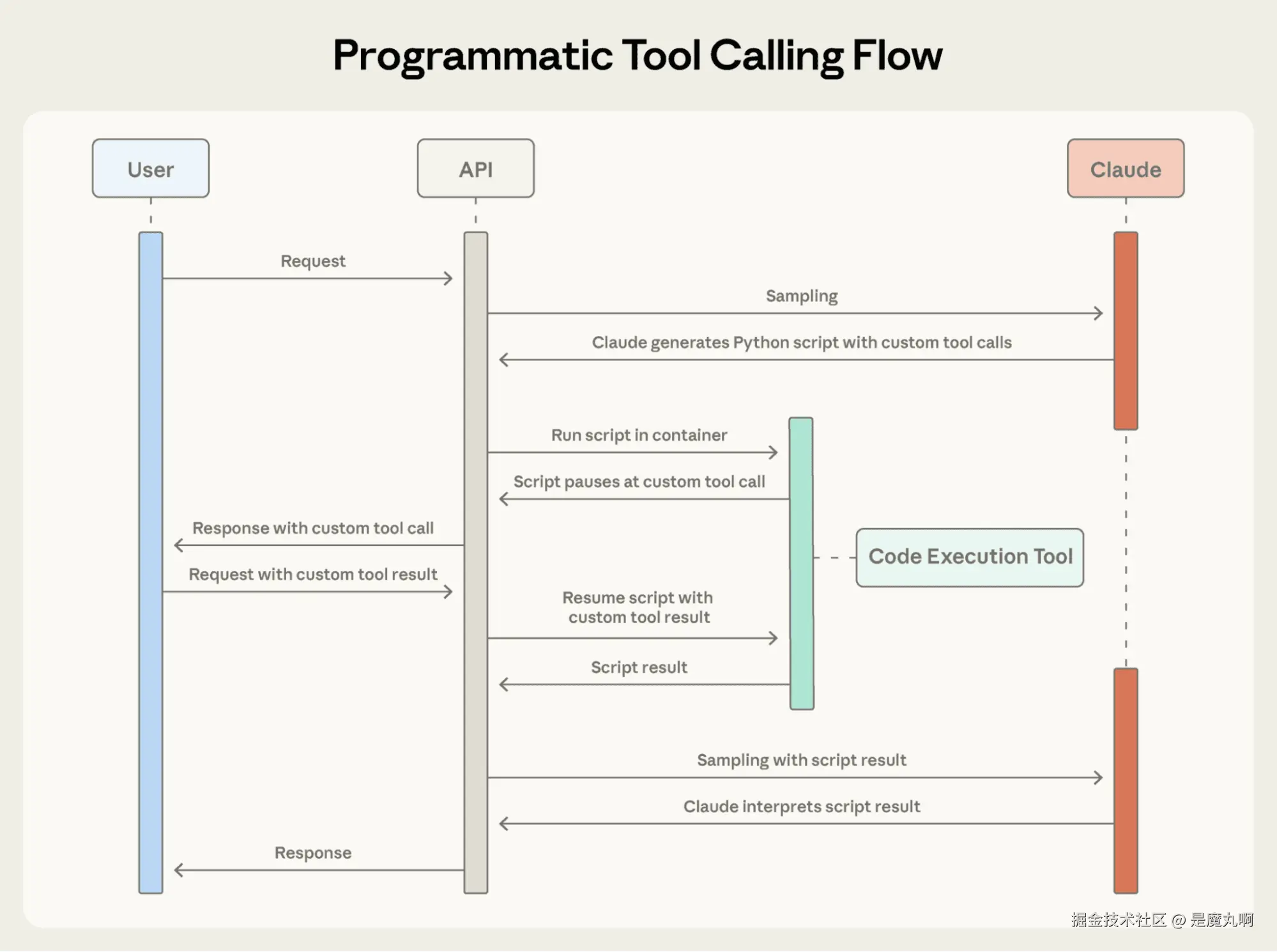
程序化工具调用使 Claude 能够通过代码而不是通过单独的 API 往返来编排工具,允许并行工具执行。
以下是 Claude 用于预算合规任务的编排代码:
python
team = await get_team_members("engineering")
# 为每个唯一级别获取预算
levels = list(set(m["level"] for m in team))
budget_results = await asyncio.gather(*[
get_budget_by_level(level) for level in levels
])
# 创建查找字典:{"junior": budget1, "senior": budget2, ...}
budgets = {level: budget for level, budget in zip(levels, budget_results)}
# 并行获取所有费用
expenses = await asyncio.gather(*[
get_expenses(m["id"], "Q3") for m in team
])
# 找出差旅预算超支的员工
exceeded = []
for member, exp in zip(team, expenses):
budget = budgets[member["level"]]
total = sum(e["amount"] for e in exp)
if total > budget["travel_limit"]:
exceeded.append({
"name": member["name"],
"spent": total,
"limit": budget["travel_limit"]
})
print(json.dumps(exceeded))Claude 的上下文只接收最终结果:两到三个预算超支的人。2000+ 行项目、中间汇总和预算查找不会影响 Claude 的上下文,将消耗从 200KB 原始费用数据减少到仅 1KB 结果。
效率收益是巨大的:
- Token 节省:通过保持中间结果不在 Claude 的上下文中,PTC 显著减少 token 消耗。复杂研究任务的平均使用量从 43,588 个 token 下降到 27,297 个 token,减少了 37%。
- 减少延迟:每次 API 往返需要模型推理(几百毫秒到几秒)。当 Claude 在单个代码块中编排 20+ 工具调用时,您消除了 19+ 次推理过程。API 处理工具执行而无需每次返回模型。
- 提高准确性:通过编写明确的编排逻辑,Claude 比用自然语言处理多个工具结果时犯更少的错误。内部知识检索从 25.6% 提高到 28.5%;GIA 基准从 46.5% 提高到 51.2%。
生产工作流涉及复杂的数据、条件逻辑和需要扩展的操作。程序化工具调用让 Claude 以编程方式处理该复杂性,同时保持其对可操作结果的关注,而不是原始数据处理。
程序化工具调用的工作原理
1. 将工具标记为可从代码调用
向工具添加 code_execution,并设置 allowed_callers 以选择加入程序化执行的工具:
json
{
"tools": [
{
"type": "code_execution_20250825",
"name": "code_execution"
},
{
"name": "get_team_members",
"description": "Get all members of a department...",
"input_schema": {...},
"allowed_callers": ["code_execution_20250825"] # 选择加入程序化工具调用
},
{
"name": "get_expenses",
...
},
{
"name": "get_budget_by_level",
...
}
]
}API 将这些工具定义转换为 Claude 可以调用的 Python 函数。
2. Claude 编写编排代码
Claude 不是逐一请求工具,而是生成 Python 代码:
json
{
"type": "server_tool_use",
"id": "srvtoolu_abc",
"name": "code_execution",
"input": {
"code": "team = get_team_members('engineering')\n..." # 上面的代码示例
}
}3. 工具执行而不影响 Claude 的上下文
当代码调用 get_expenses() 时,您收到带有 caller 字段的工具请求:
json
{
"type": "tool_use",
"id": "toolu_xyz",
"name": "get_expenses",
"input": {"user_id": "emp_123", "quarter": "Q3"},
"caller": {
"type": "code_execution_20250825",
"tool_id": "srvtoolu_abc"
}
}您提供结果,该结果在代码执行环境中处理,而不是在 Claude 的上下文中。此请求-响应循环对代码中的每个工具调用重复。
4. 只有最终输出进入上下文
当代码完成运行时,只有代码的结果返回给 Claude:
json
{
"type": "code_execution_tool_result",
"tool_use_id": "srvtoolu_abc",
"content": {
"stdout": "[{\"name\": \"Alice\", \"spent\": 12500, \"limit\": 10000}...]"
}
}这就是 Claude 看到的全部内容,而不是沿路处理的 2000+ 费用行项目。
何时使用程序化工具调用
程序化工具调用为工作流添加了代码执行步骤。当 token 节省、延迟改进和准确性收益显著时,这种额外开销得到回报。
最佳适用场景:
- 处理大型数据集,只需要聚合或摘要
- 运行具有三个或更多依赖工具调用的多步骤工作流
- 在 Claude 看到之前过滤、排序或转换工具结果
- 处理中间数据不应影响 Claude 推理的任务
- 在许多项目上运行并行操作(例如,检查 50 个端点)
不太有益时:
- 进行简单的单工具调用
- Claude 应该看到并推理所有中间结果的任务
- 运行具有小响应的快速查找
工具使用示例
挑战
JSON Schema 擅长定义结构------类型、必填字段、允许的枚举------但它无法表达使用模式:何时包含可选参数、哪些组合有意义,或者您的 API 期望什么约定。
考虑支持工单 API:
json
{
"name": "create_ticket",
"input_schema": {
"properties": {
"title": {"type": "string"},
"priority": {"enum": ["low", "medium", "high", "critical"]},
"labels": {"type": "array", "items": {"type": "string"}},
"reporter": {
"type": "object",
"properties": {
"id": {"type": "string"},
"name": {"type": "string"},
"contact": {
"type": "object",
"properties": {
"email": {"type": "string"},
"phone": {"type": "string"}
}
}
}
},
"due_date": {"type": "string"},
"escalation": {
"type": "object",
"properties": {
"level": {"type": "integer"},
"notify_manager": {"type": "boolean"},
"sla_hours": {"type": "integer"}
}
}
},
"required": ["title"]
}
}模式定义了什么是有效的,但留下了关键问题未回答:
- 格式歧义 :
due_date应该使用 "2024-11-06"、"Nov 6, 2024" 还是 "2024-11-06T00:00:00Z"? - ID 约定 :
reporter.id是 UUID、"USR-12345" 还是只是 "12345"? - 嵌套结构使用 :Claude 应该何时填充
reporter.contact? - 参数相关性 :
escalation.level和escalation.sla_hours与 priority 如何相关?
这些歧义可能导致格式错误的工具调用和不一致的参数使用。
我们的解决方案
工具使用示例让您可以直接在工具定义中提供示例工具调用。而不是仅依赖模式,您向 Claude 展示具体的使用模式:
json
{
"name": "create_ticket",
"input_schema": { /* 与上面相同的模式 */ },
"input_examples": [
{
"title": "Login page returns 500 error",
"priority": "critical",
"labels": ["bug", "authentication", "production"],
"reporter": {
"id": "USR-12345",
"name": "Jane Smith",
"contact": {
"email": "jane@acme.com",
"phone": "+1-555-0123"
}
},
"due_date": "2024-11-06",
"escalation": {
"level": 2,
"notify_manager": true,
"sla_hours": 4
}
},
{
"title": "Add dark mode support",
"labels": ["feature-request", "ui"],
"reporter": {
"id": "USR-67890",
"name": "Alex Chen"
}
},
{
"title": "Update API documentation"
}
]
}从这三个示例中,Claude 学习到:
- 格式约定:日期使用 YYYY-MM-DD,用户 ID 遵循 USR-XXXXX,标签使用 kebab-case
- 嵌套结构模式:如何构造带有嵌套联系人对象的报告者对象
- 可选参数相关性:关键错误有完整联系人信息 + 具有紧 SLA 的升级;功能请求有报告者但没有联系人/升级;内部任务只有标题
在我们自己的内部测试中,工具使用示例在复杂参数处理上将准确性从 72% 提高到 90%。
何时使用工具使用示例
工具使用示例为您的工具定义添加 tokens,因此当准确性改进超过额外成本时,它们最有价值。
最佳适用场景:
- 复杂嵌套结构,其中有效 JSON 不意味着正确使用
- 具有许多可选参数且包含模式很重要的工具
- 具有模式未捕获的特定领域约定的 API
- 相似工具,其中示例阐明使用哪一个(例如,
create_ticketvscreate_incident)
不太有益时:
- 具有明显使用的简单单参数工具
- Claude 已理解的标准格式,如 URL 或电子邮件
- 更适合由 JSON Schema 约束处理的验证问题
最佳实践
构建采取现实世界行动的 agents 意味着同时处理规模、复杂性和精确性。这三个功能共同解决工具使用工作流中的不同瓶颈。以下是有效结合它们的方法。
战略性地分层功能
并非每个 agent 都需要为给定任务使用所有三个功能。从您最大的瓶颈开始:
- 工具定义的上下文膨胀 → 工具搜索工具
- 大型中间结果污染上下文 → 程序化工具调用
- 参数错误和格式错误的调用 → 工具使用示例
这种专注的方法让您解决限制 agent 性能的特定约束,而不是预先添加复杂性。
然后根据需要分层附加功能。它们是互补的:工具搜索工具确保找到正确的工具,程序化工具调用确保高效执行,工具使用示例确保正确调用。
设置工具搜索工具以更好地发现
工具搜索匹配名称和描述,因此清晰、描述性的定义提高发现准确性。
javascript
// 好的
{
"name": "search_customer_orders",
"description": "Search for customer orders by date range, status, or total amount. Returns order details including items, shipping, and payment info."
}
// 坏的
{
"name": "query_db_orders",
"description": "Execute order query"
}添加系统提示指导,以便 Claude 知道可用的内容:
text
您有权访问 Slack 消息、Google Drive 文件管理、
Jira 工单跟踪和 GitHub 仓库操作的工具。使用工具搜索
查找特定功能。保持您最常用的三到五个工具始终加载,延迟其余的。这平衡了常见操作的即时访问和其他一切的按需发现。
设置程序化工具调用以正确执行
由于 Claude 编写代码来解析工具输出,请清楚地记录返回格式。这有助于 Claude 编写正确的解析逻辑:
json
{
"name": "get_orders",
"description": "Retrieve orders for a customer.
Returns:
List of order objects, each containing:
- id (str): Order identifier
- total (float): Order total in USD
- status (str): One of 'pending', 'shipped', 'delivered'
- items (list): Array of {sku, quantity, price}
- created_at (str): ISO 8601 timestamp"
}请参阅下面选择加入的程序化编排受益的工具:
- 可以并行运行的工具(独立操作)
- 可安全重试的操作(幂等)
设置工具使用示例以获得参数准确性
为行为清晰度精心设计示例:
- 使用真实数据(真实城市名称、合理价格,而不是 "string" 或 "value")
- 展示最少、部分和完整规范模式的多样性
- 保持简洁:每个工具 1-5 个示例
- 关注歧义(仅在正确使用从模式中不明显的地方添加示例)
开始使用
这些功能在 beta 中可用。要启用它们,添加 beta 标题并包含您需要的工具:
python
client.beta.messages.create(
betas=["advanced-tool-use-2025-11-20"],
model="claude-sonnet-4-5-20250929",
max_tokens=4096,
tools=[
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
{"type": "code_execution_20250825", "name": "code_execution"},
# 您的带有 defer_loading、allowed_callers 和 input_examples 的工具
]
)有关详细的 API 文档和 SDK 示例,请参阅:
- 工具搜索工具的文档和 cookbook
- 程序化工具调用的文档和 cookbook
- 工具使用示例的文档
这些功能将工具使用从简单的函数调用转向智能编排。当 agents 处理跨越数十个工具和大型数据集的更复杂工作流时,动态发现、高效执行和可靠调用成为基础。
我们期待看到您构建的东西。
致谢
由 Bin Wu 撰写,Adam Jones、Artur Renault、Henry Tay、Jake Noble、Nathan McCandlish、Noah Picard、Sam Jiang 和 Claude 开发者平台团队贡献。这项工作建立在 Chris Gorgolewski、Daniel Jiang、Jeremy Fox 和 Mike Lambert 的基础研究之上。我们也从整个 AI 生态系统中汲取灵感,包括 Joel Pobar 的 LLMVM、Cloudflare 的代码模式和代码执行作为 MCP。特别感谢 Andy Schumeister、Hamish Kerr、Keir Bradwell、Matt Bleifer 和 Molly Vorwerck 的支持。