这份指南将告诉你如何编写专业级别的 Agent Skills,如何用大语言模型(LLM)来验证它们,以及如何保持上下文窗口的精简高效。
(什么是 Agent Skills?简单来说,就是让 AI 助手学会某项特定技能的"说明书"和"工具包",比如让 AI 学会如何写 React 组件、如何操作数据库等。)
本文是创建 Agent Skills 的精华版最佳实践。如果你想看完整文档,可以参考 Claude 的官方文档。
Skill 的目录结构
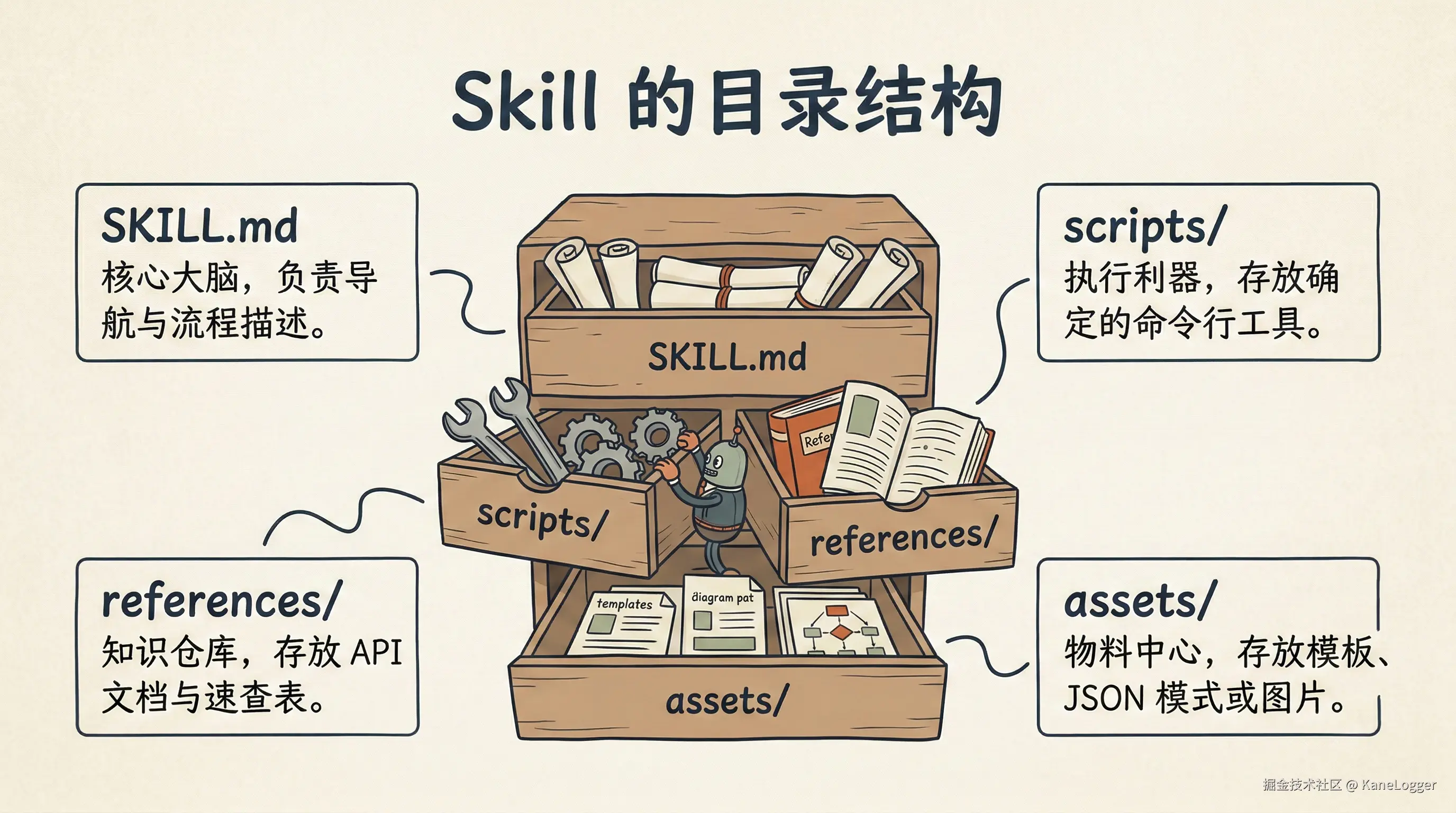
每个 skill 都必须遵循这样的目录结构:
bash
skill-name/
├── SKILL.md # 必需:元数据 + 核心指令(少于 500 行)
├── scripts/ # 可执行代码(Python/Bash),设计成小型命令行工具
├── references/ # 补充资料(API 文档、速查表等)
└── assets/ # 输出时使用的模板或静态文件- SKILL.md: 相当于 skill 的"大脑"。用它来做导航和描述高层级的操作流程。
- References: 直接从 SKILL.md 里链接过去。注意只放一层深度的文件。
- Scripts: 用于那些容易出错或重复性高的操作------在这些场景下,任何变化都是 bug。不要把库代码打包在这里。
优化 frontmatter,让 skill 更容易被发现
SKILL.md 文件 frontmatter 里的 name 和 description 是 Agent 在触发 skill 之前唯一能看到的字段。如果它们没有被优化得足够清晰具体,你的 skill 就等于"隐身"了。
(什么是 frontmatter?它是 Markdown 文件顶部用三个横线包裹的元数据区块,通常包含 name、description 等配置信息。)
- 严格遵守命名规则:
name字段必须是 1-64 个字符,只能包含小写字母、数字和连字符(不能有连续的连字符),而且必须和父目录名称完全一致 (例如name: angular-testing必须放在angular-testing/SKILL.md里)。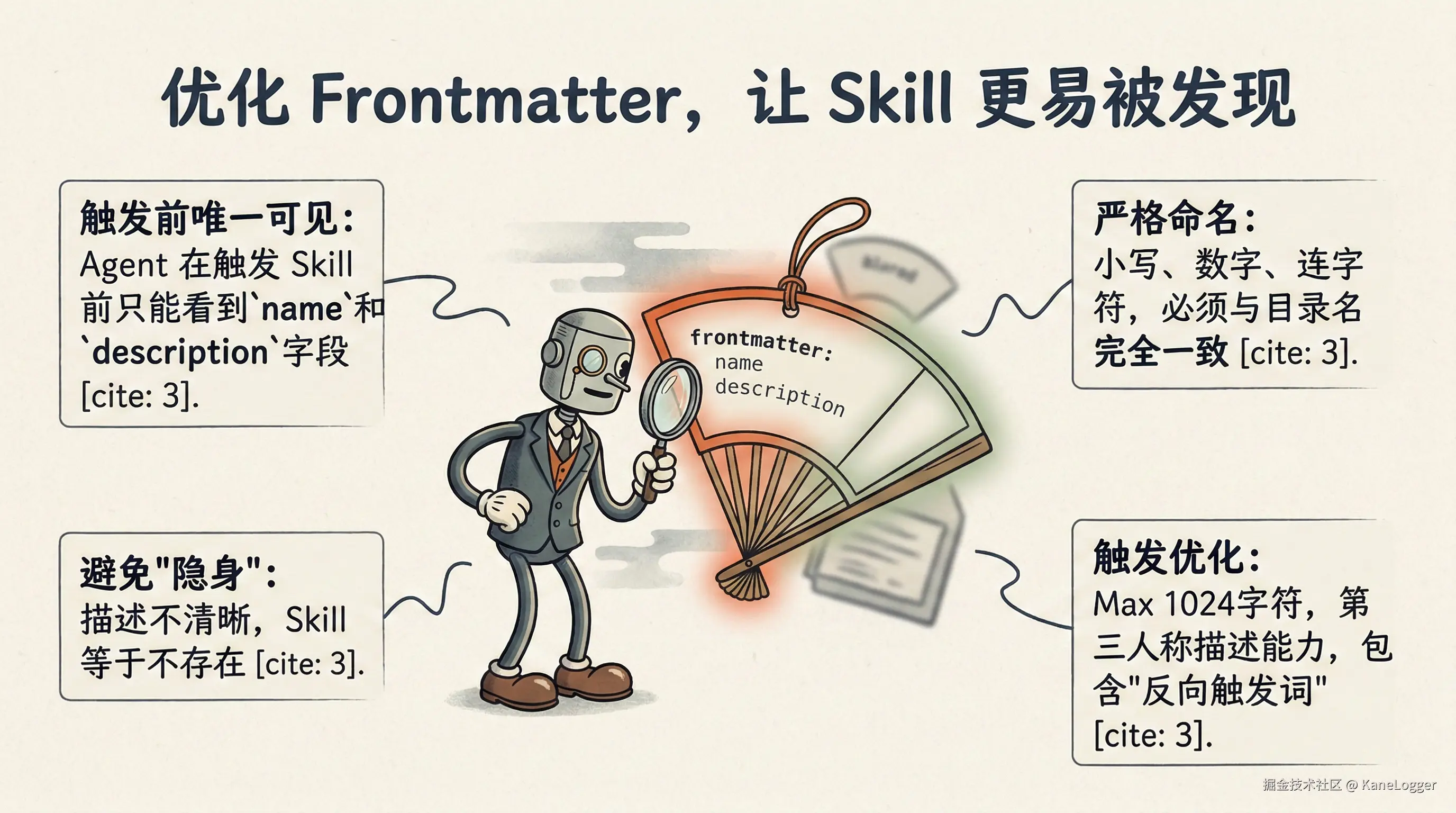
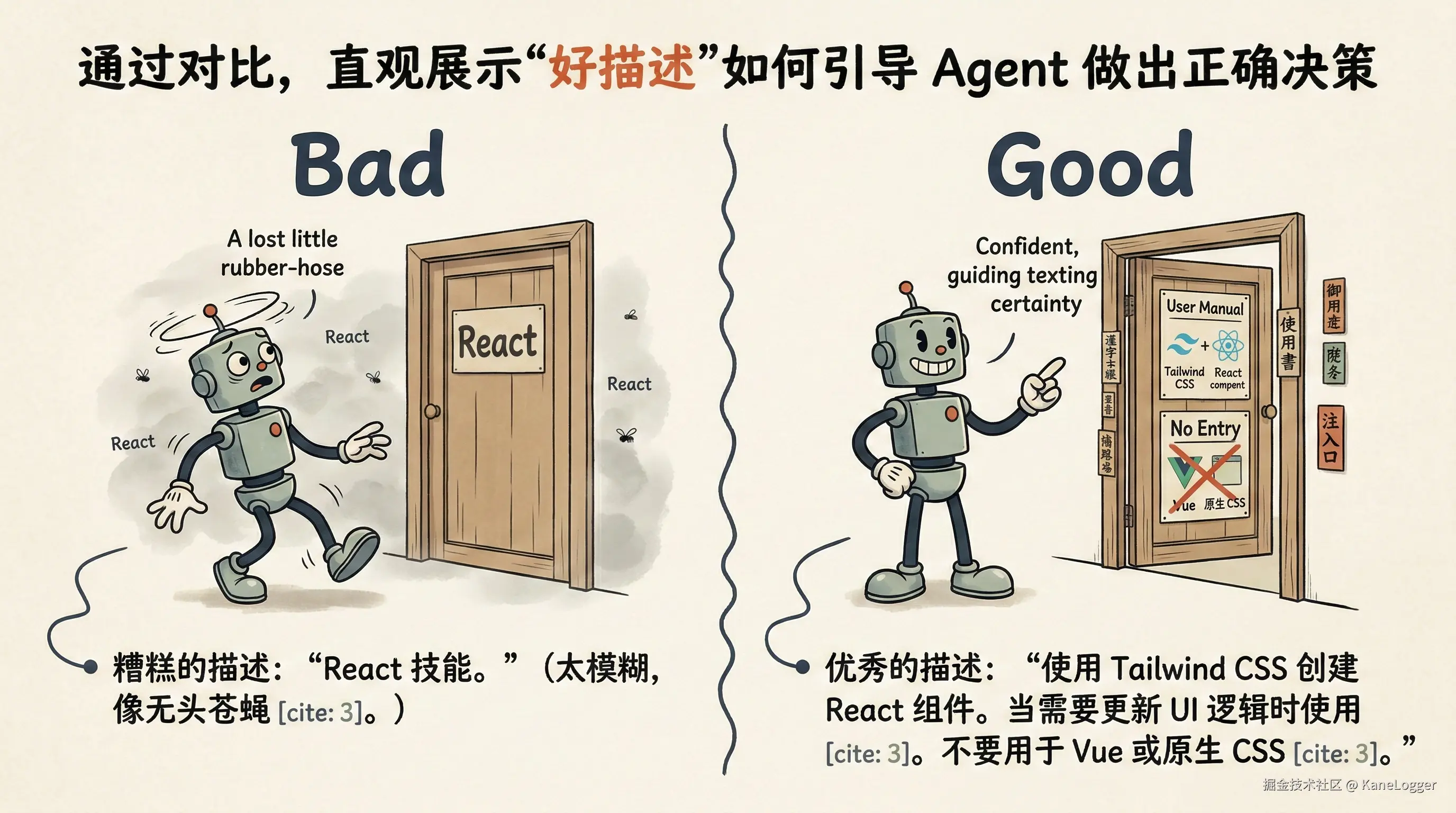
- 写触发优化的描述: (最多 1,024 个字符)。这是 Agent 用来做路由决策的唯一元数据。用第三人称描述能力,并包含"反向触发词"(即什么情况下不该用)。
- 不好的例子: "React 技能。"(太模糊了)
- 好的例子: "使用 Tailwind CSS 创建和构建 React 组件。当用户想要更新组件样式或 UI 逻辑时使用。不要用于 Vue、Svelte 或原生 CSS 项目。"
渐进式披露与资源管理
只在需要时才加载信息,保持上下文窗口的整洁。SKILL.md 是负责高层逻辑的"大脑";把细节卸载到子目录里。
- 保持 SKILL.md 精简: 主文件限制在 500 行以内。用它来做导航和主要流程。
- 使用扁平子目录: 把大块的内容移到标准文件夹里。文件只放一层深度 (例如
references/schema.md,而不是references/db/v1/schema.md)。references/:API 文档、速查表、领域逻辑。scripts/:确定性任务的可执行代码。assets/:输出模板、JSON 模式定义、图片。
- 即时加载(JiT): 明确指示 Agent 什么时候读取文件。在你指明之前,Agent 是看不到这些资源的(例如 "查看
references/auth-flow.md了解具体的错误码")。 - 显式路径: 始终使用相对路径 ,并用正斜杠(
/),不管操作系统是什么。
(JiT 是 Just-in-Time 的缩写,意思是"即时"或"按需"。这是一种编程中的常见策略------不一次性加载所有内容,而是等到真正需要时才去获取,这样可以节省内存和处理时间。)

Skills 是给 Agent 用的,不是给人类看的。为了保持上下文窗口精简,避免不必要的 token 消耗,不要创建:
- 文档文件:
README.md、CHANGELOG.md或INSTALLATION_GUIDE.md。 - 冗余逻辑: 如果 Agent 不用帮助就能可靠处理某个任务,那就删掉这条指令。
- 库代码: Skills 应该引用现有工具,或者包含小型、单一用途的脚本。长期维护的库代码应该放在标准的仓库 CLI 目录里。

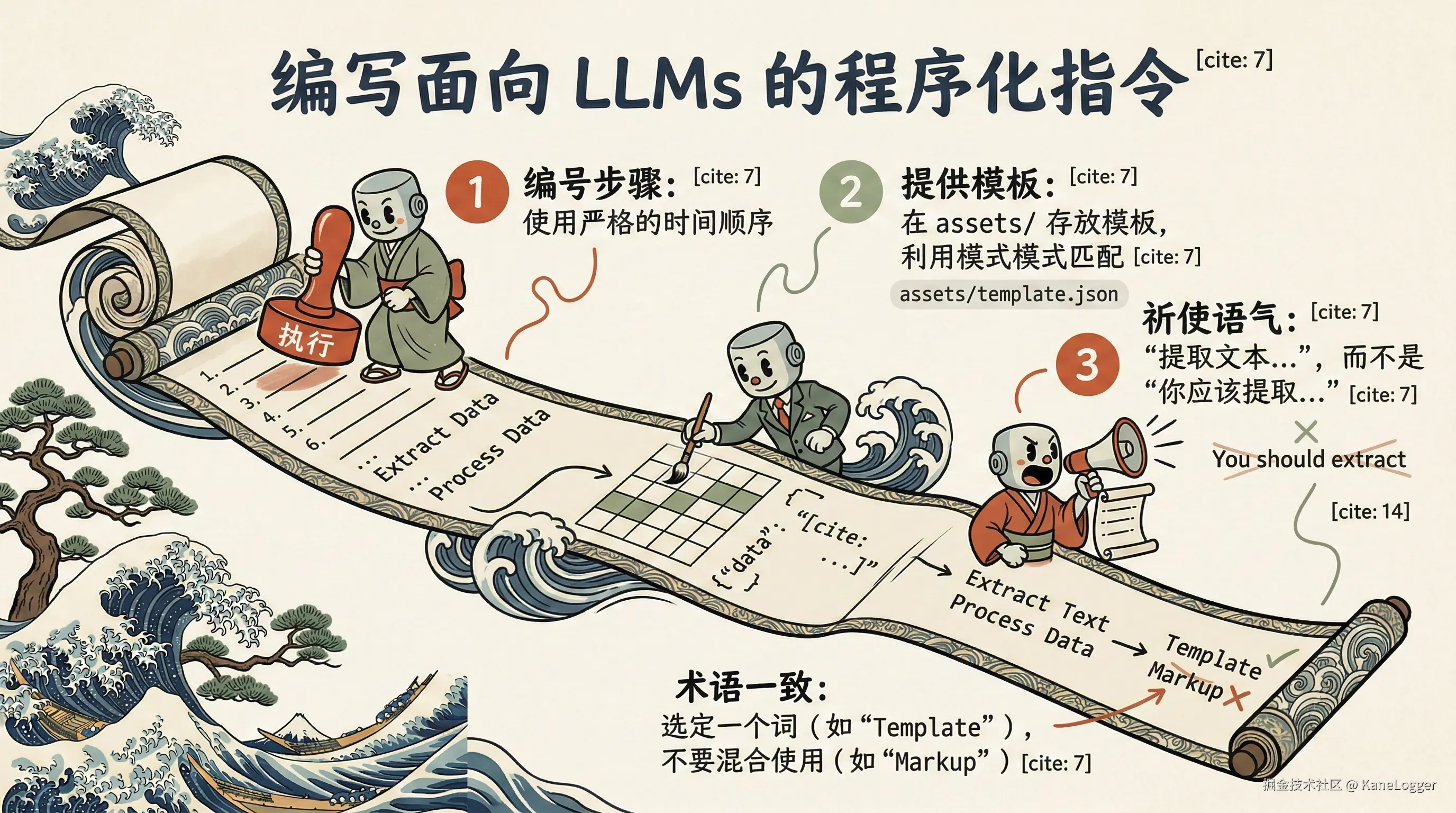
用具体的程序化指令,而不是散文式描述
为 LLM 写指令,而不是为人类写。
- 使用分步骤编号: 把工作流程定义成严格的时间顺序。如果有决策树,清晰地画出来(例如 "步骤 2:如果你需要 source map,运行
ng build --source-map。否则,跳到步骤 3。")。 - 提供具体模板: Agent 的模式匹配能力非常强。与其花好几段文字描述 JSON 输出应该长什么样,不如把模板放在 assets/ 文件夹里,然后指示 Agent 复制它的结构。
- 用第三人称祈使语气: 把指令框定为对 Agent 的直接命令(例如 "提取文本..." 而不是 "我将提取..." 或 "你应该提取...")。
在 skill 文件中引用概念时,要具体且一致。
- 使用一致的术语: 选一个单一的词来指代特定概念。
- 具体性: 使用你描述领域里最具体的、原生的术语。例如,在 Angular 里用"模板(template)"这个概念,而不是"html"、"markup"或"view"。
为重复性操作打包确定性脚本
别让 LLM 每次运行 skill 时都从 0 开始写复杂的解析逻辑或样板代码。
- 把易碎/重复的任务卸载出去: 如果 Agent 需要解析复杂数据集或查询特定数据库,给它一个放在 scripts/ 目录里的、经过测试的 Python、Bash 或 Node 脚本来运行。
- 优雅地处理边界情况: Agent 依赖标准输出(stdout/stderr)来判断脚本是否成功。写脚本时要返回高度描述性、人类可读的错误信息,这样 Agent 就能确切知道如何自我纠正,而不需要用户介入。

验证指南

既然 LLM 会使用你的 skills,我发现确保它们有用的最佳方式,就是和 LLM 一起协作验证。
为你的 skills 准备评估(evals)是至关重要的,这样你才能确保所做的改动有正面效果,不会导致回退。一个流行的 skill 基准测试是 SkillsBench,可以给你一些灵感。
(什么是 evals?它是 evaluations 的缩写,意思是"评估"或"测试"。在 AI 领域,evals 是一套用来衡量模型或系统表现的测试用例和标准。就像考试一样,用来检验你的 skill 是否真的管用。)
一旦你草拟好了 skill 的初版,可以通过以下步骤来验证你的工作:
发现性验证
Agent 严格根据 YAML frontmatter 来加载 skills。测试一下 LLM 在孤立环境下如何解读你的描述,以防止误触发(比如明明是用于 Angular 的 skill,却在 React 项目里被触发了)。
把下面这段文字原封不动地粘贴到一个全新的 LLM 对话里:
我正在基于 agentskills.io 规范构建一个 Agent Skill。Agent 会完全根据下面的 YAML 元数据来决定是否加载这个 skill。
makefilename: angular-vite-migrator description: 将 Angular CLI 项目从 Webpack 迁移到 Vite 和 esbuild。当用户想要更新构建器配置、用 rollup 插件替换 webpack 插件,或加速 Angular 编译时使用。严格基于这段描述:
- 生成 3 个你有 100% 信心应该触发这个 skill 的真实用户提示。
- 生成 3 个听起来类似但不应该触发这个 skill 的用户提示(例如,把 React 应用迁移到 Vite,或者只是更新 Angular 版本)。
- 评价这段描述:它是不是太宽泛了?给出一个优化后的重写建议。
此外,用你期望会触发 skill 读取的任务来提示 Agent,并检查它的思考过程。和 Agent 来回沟通,找出它为什么选(或没选)特定的 skills。

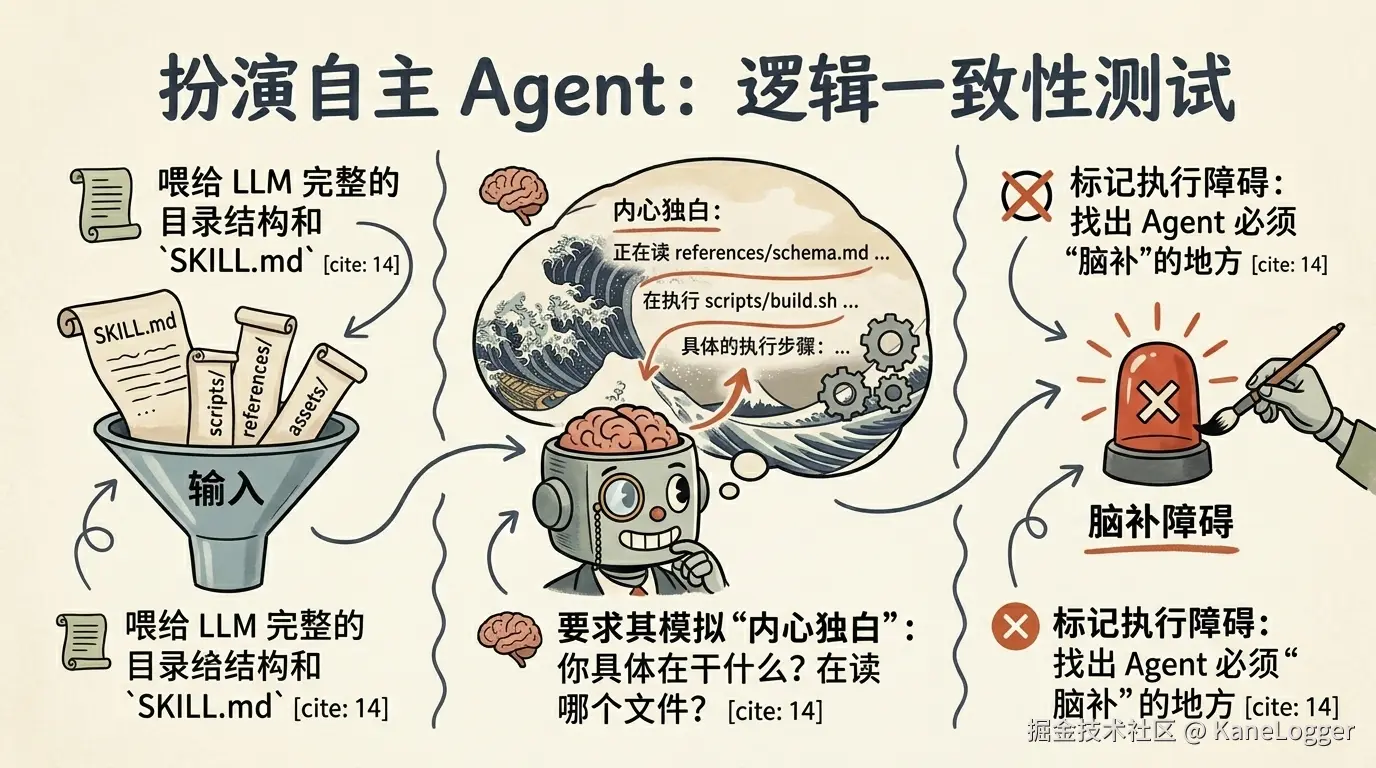
逻辑验证
确保你的分步骤指令是确定性的,不会强迫 Agent 去"脑补"缺失的步骤。
把你完整的 SKILL.md 和目录结构喂给 LLM:
这是我的 SKILL.md 完整草稿和支持文件的目录树。
sh├── SKILL.md ├── scripts/esbuild-optimizer.mjs └── assets/vite.config.template.ts在这里粘贴你的 SKILL.md 内容
扮演一个刚刚触发这个 skill 的自主 Agent。基于"把我的 Angular v17 应用迁移到 Vite"这个请求,一步步模拟你的执行过程。
对于每一步,写出你的内心独白:
- 你具体在做什么?
- 你在读取或运行哪个具体的文件/脚本?
- 标记任何执行障碍:指出你被迫猜测或"脑补"的确切行号,因为我的指令太模糊了(例如,如何把 Angular 环境文件映射到 Vite 的 import.meta.env)。
("脑补"在这里指的是 LLM 的幻觉(hallucination)现象------当指令不够明确时,AI 可能会编造出不存在的步骤或信息来填补空白。)
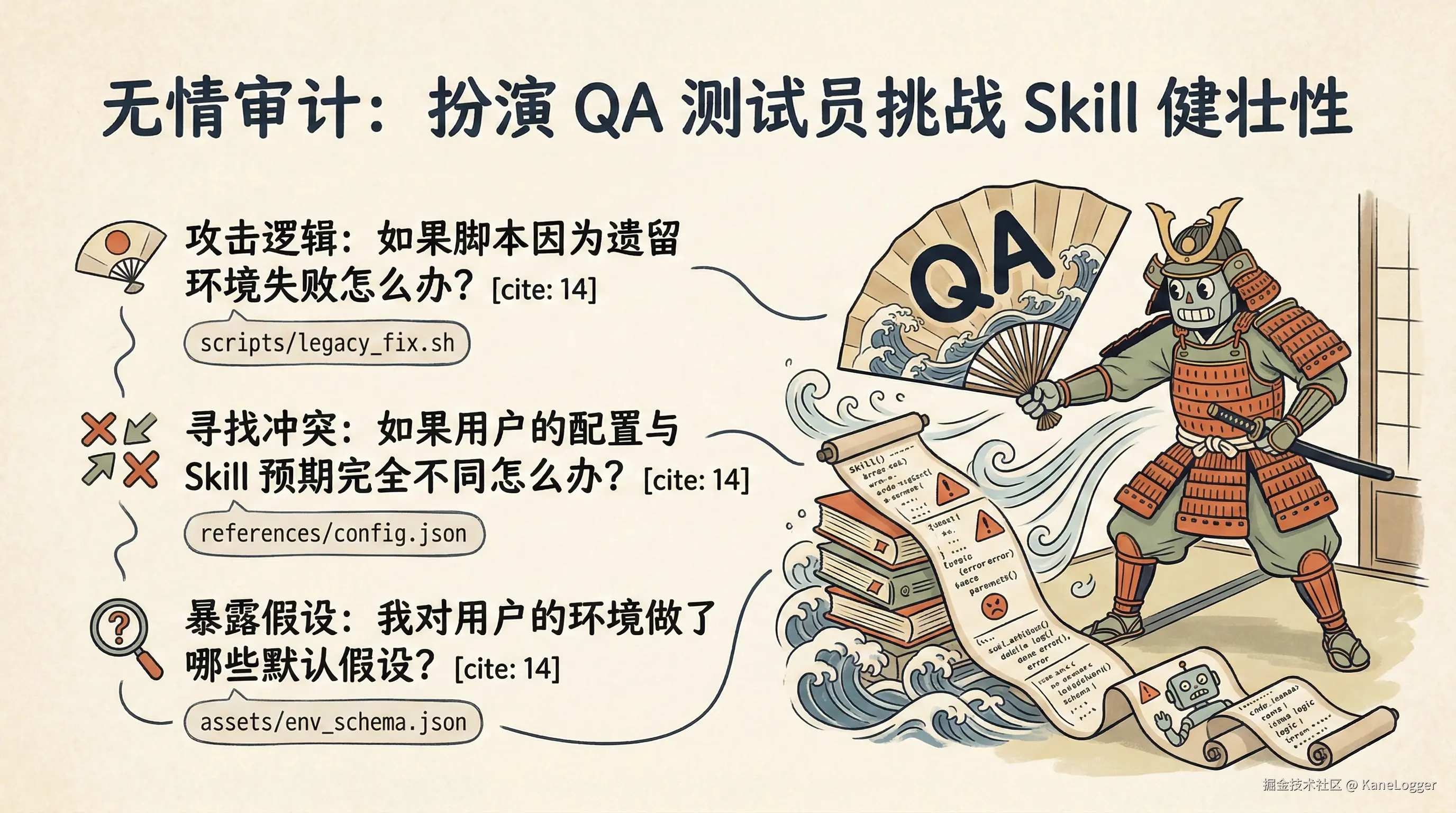
边界情况测试
强迫 LLM 去搜寻漏洞、不支持的配置,以及 web 工具固有的失败状态。
让 LLM 来"攻击"你的逻辑:
现在,换个角色。扮演一个无情的 QA 测试员。你的目标是搞砸这个 skill。 问我 3 到 5 个关于边界情况、失败状态或 SKILL.md 中缺失回退机制的高度具体、有挑战性的问题。重点关注:
- 如果
scripts/esbuild-optimizer.mjs因为遗留的 CommonJS 依赖而失败怎么办?- 如果用户的
angular.json包含 Vite 不支持的、重度定制的 Webpack 构建器(@angular-builders/custom-webpack)怎么办?- 我对用户的 Node 环境做了哪些隐含的假设?
先不要修复这些问题。只把编号的问题列出来,等我回答。
(QA 是 Quality Assurance 的缩写,意思是"质量保证"。QA 测试员的工作就是像"找茬游戏"一样,想尽办法发现软件或系统中的 bug 和漏洞。)
架构优化
LLM 经常试图把大型配置文件直接塞进主提示里。用这一步来强制执行渐进式披露,缩小 token 占用。
让 LLM 应用你的修复并重构 skill:
基于我对你的边界情况问题的回答,重写 SKILL.md 文件,严格执行渐进式设计模式:
- 保持主
SKILL.md严格作为高层步骤集合,使用第三人称祈使命令(例如,执行 esbuild 脚本,读取 Vite 配置模板)。- 如果文件里有密集的规则、大型的
vite.config.ts模板,或复杂的angular.json模式定义,把它们删掉。告诉我去references/或assets/里创建新文件,然后把 SKILL.md 里的文本替换成一个严格的命令,只在需要时读取那个特定文件。- 在底部添加一个专门的错误处理部分,把我关于 Webpack 回退和 CommonJS 解析的回答整合进去。