1.为什么分布式系统之间需要Kafka来完成数据交换?
-
线程和线程之间的交互是通过共享的堆内存来完成数据交换的

如果都往堆中放,就会数据大量积压,内存空间是非常宝贵的,不推荐用内存来存储;
-
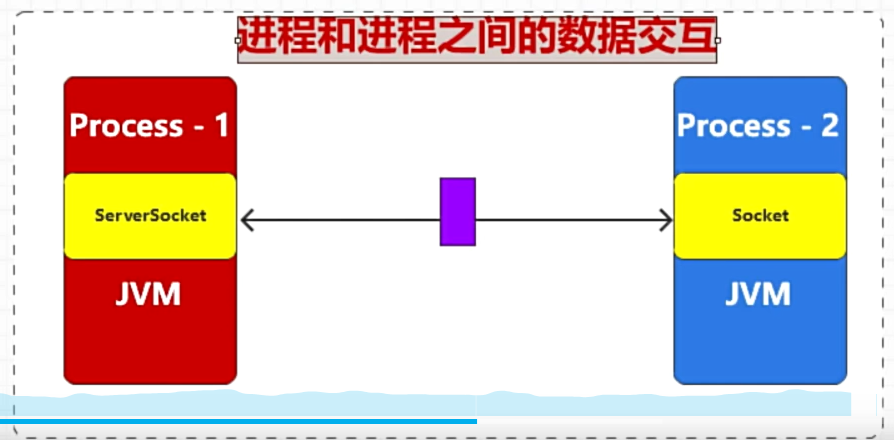
进程和进程之间的数据交互
-
Java进程和进程之间的采用消息中间件来解耦合

-
Java中定义了一个规范,JMS
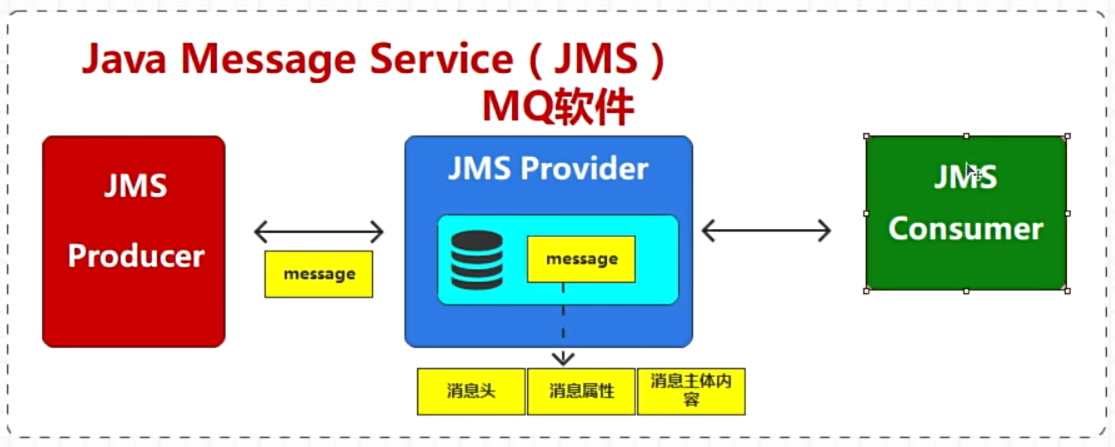
-
P2P 点对点模型:1条消息只能被1个消费者消费到并响应

-
PS 发布订阅模型-用Topic(主题)进行分类,1条消息可以被多个消费者同时消费到并响应
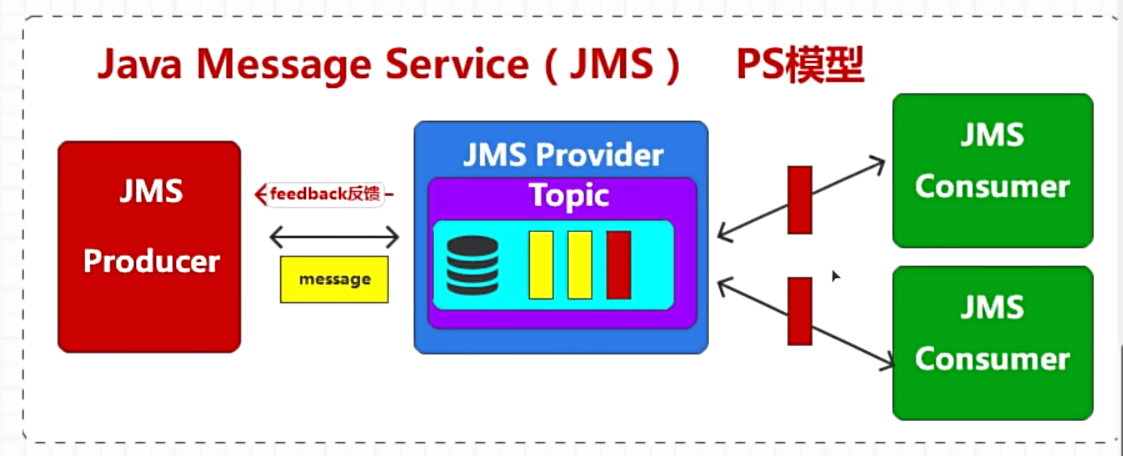
其他消息中间件

-
kafka的完整流程
-
为了防止宕机导致数据丢失,会将数据存入磁盘文件,一般叫做xxx.log文件
-
消息在队列中有个顺序索引,在kafka中叫做偏移量(offset)
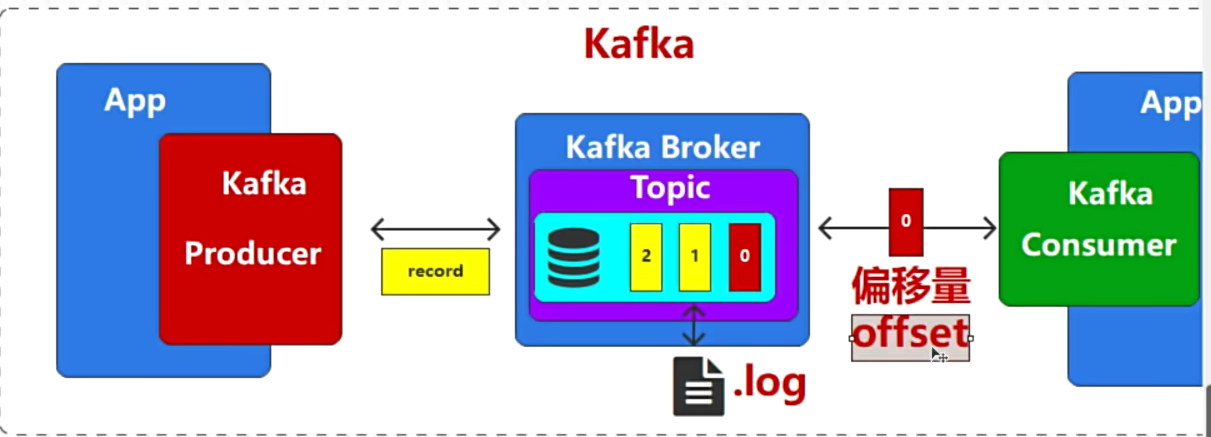
-
kafka的安装
-
kafka需要zookeeper进行多节点协调调度

-
启动zk.cmd
-
启动kfk.cmd
2.实操部分
-
数据的生产是需要主题Topic的,先创建主题Topic
-
先连接kafka服务器,并创建主题Topic

-
创建完,查看已有哪些主题Topic

-
详细查看某一个Topic详细信息

2.2 有了主题之后就可以进行生产消息了


2.3 在Java中集成Kafka
-
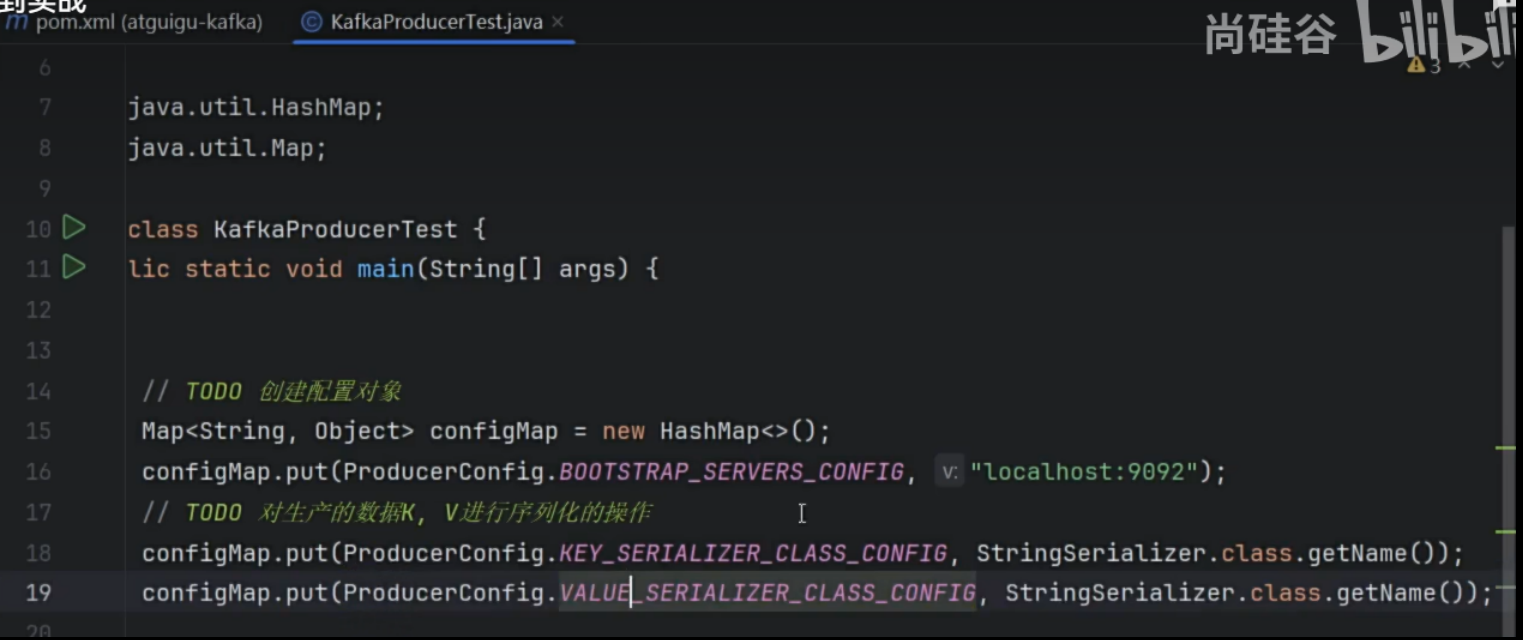
引包,配置连接参数,代码获取参数,连接kafka,设置主题,消息,发送,关闭连接

-
生产者代码
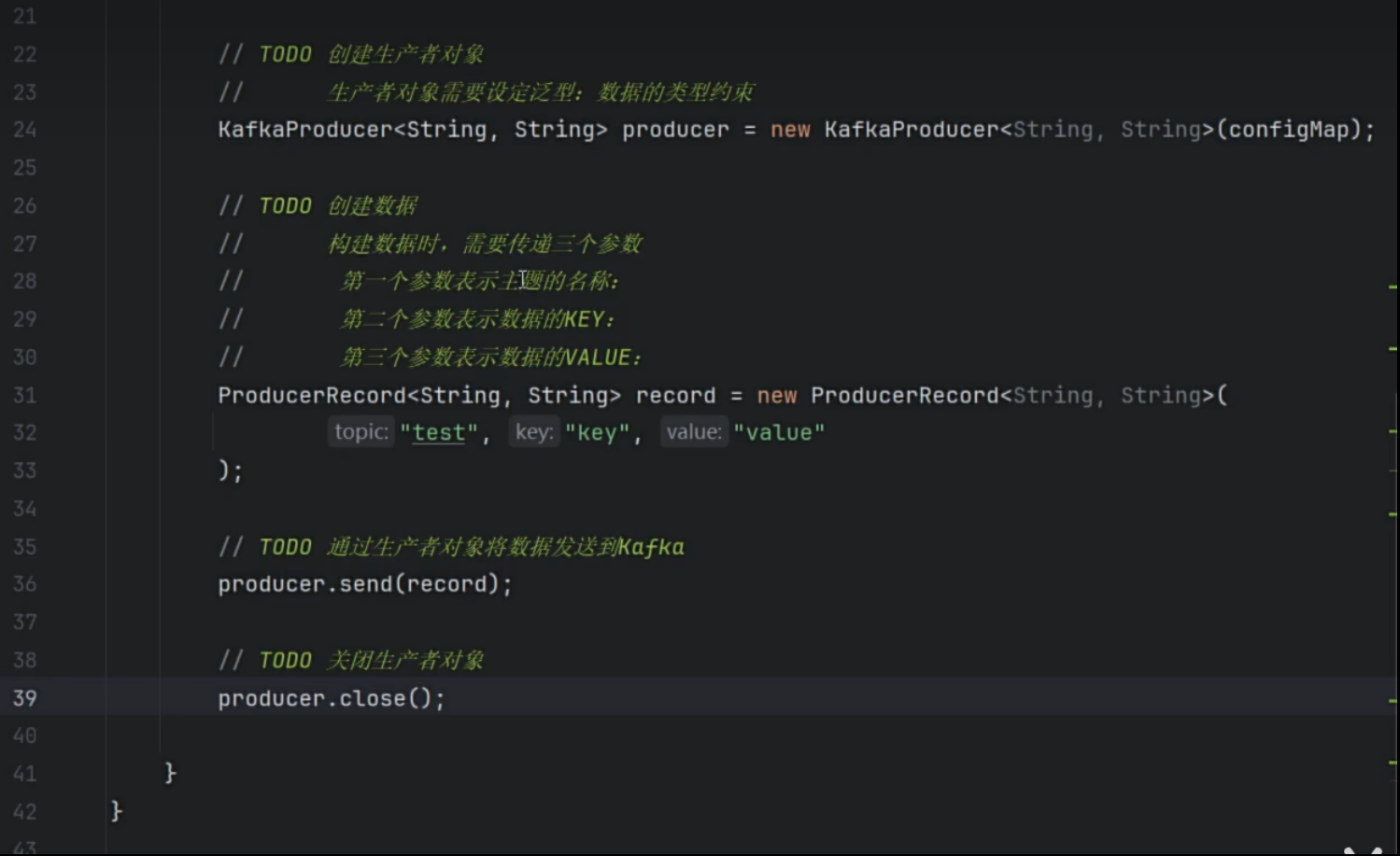
-
生产者发送多条消息
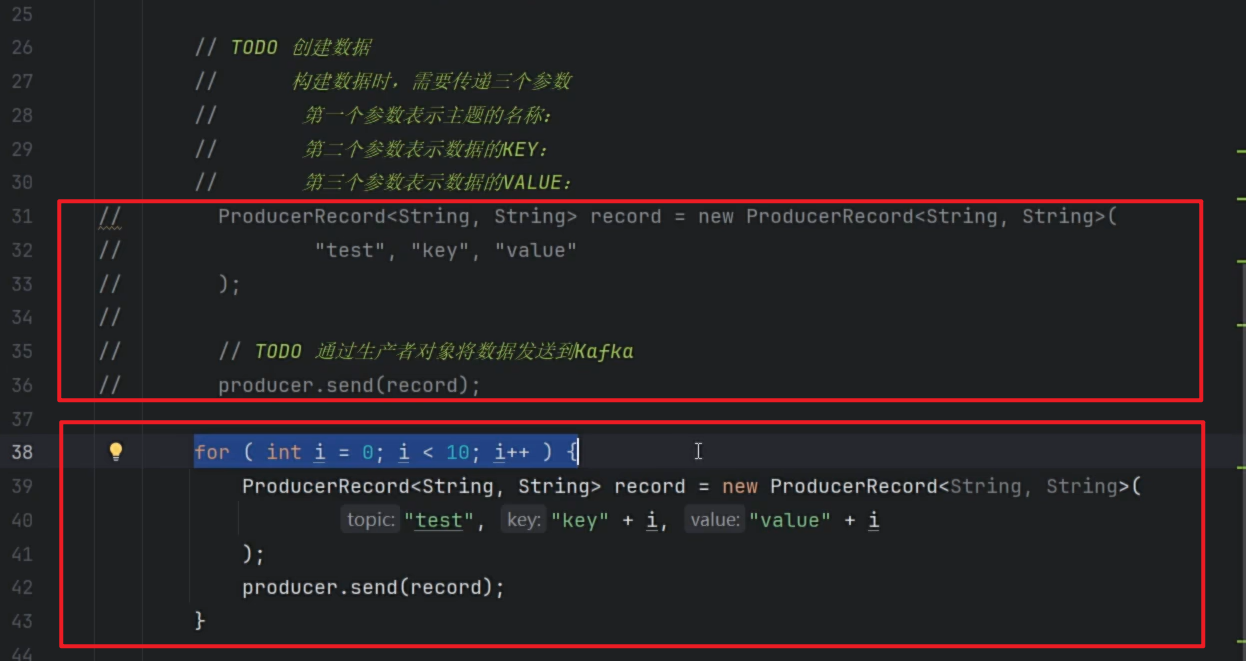
-
消费者代码
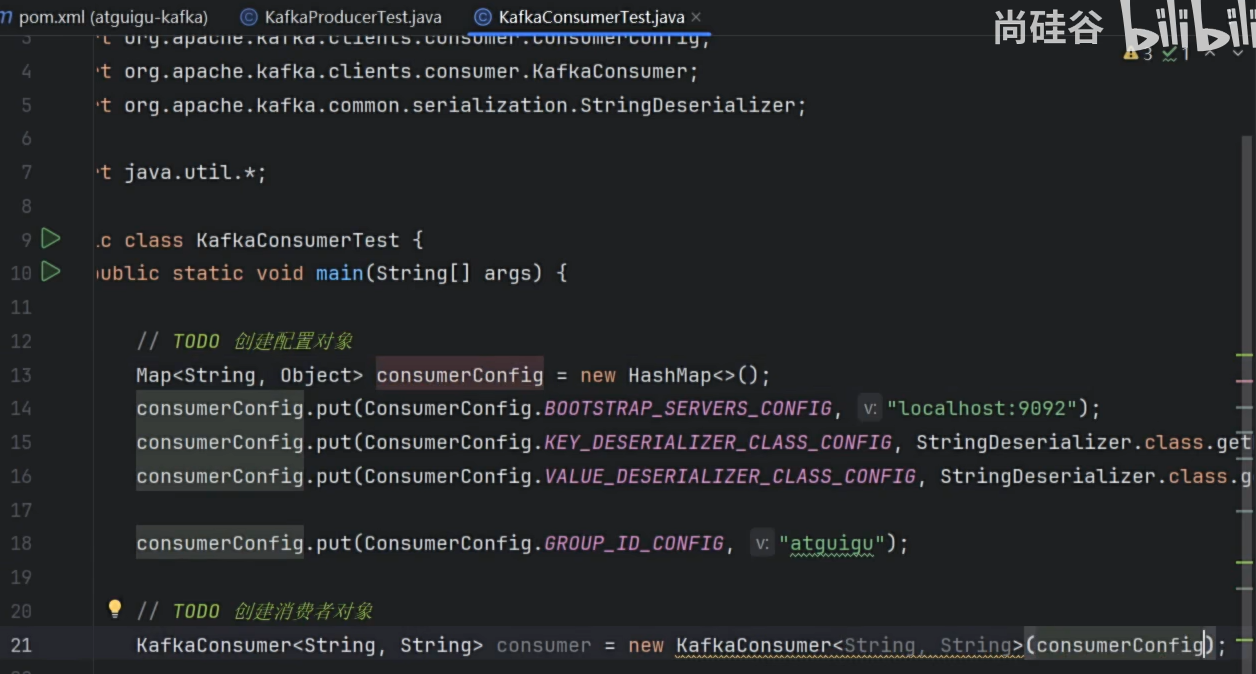
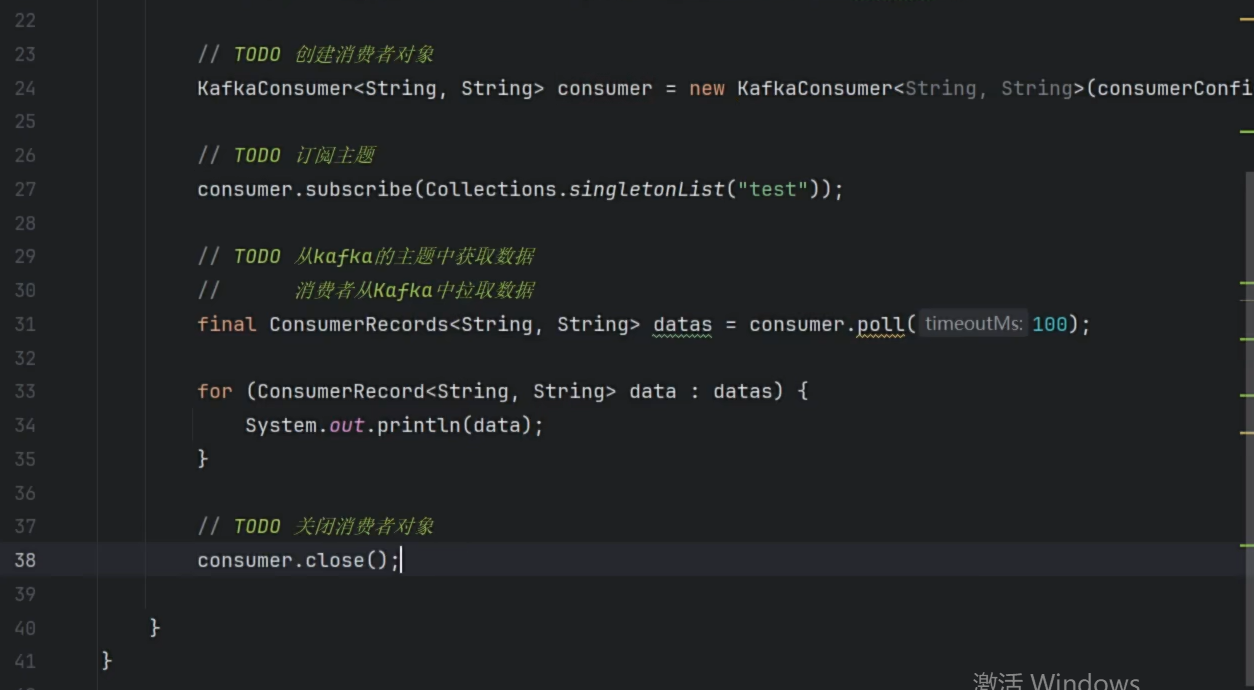
-
消费者多次消费
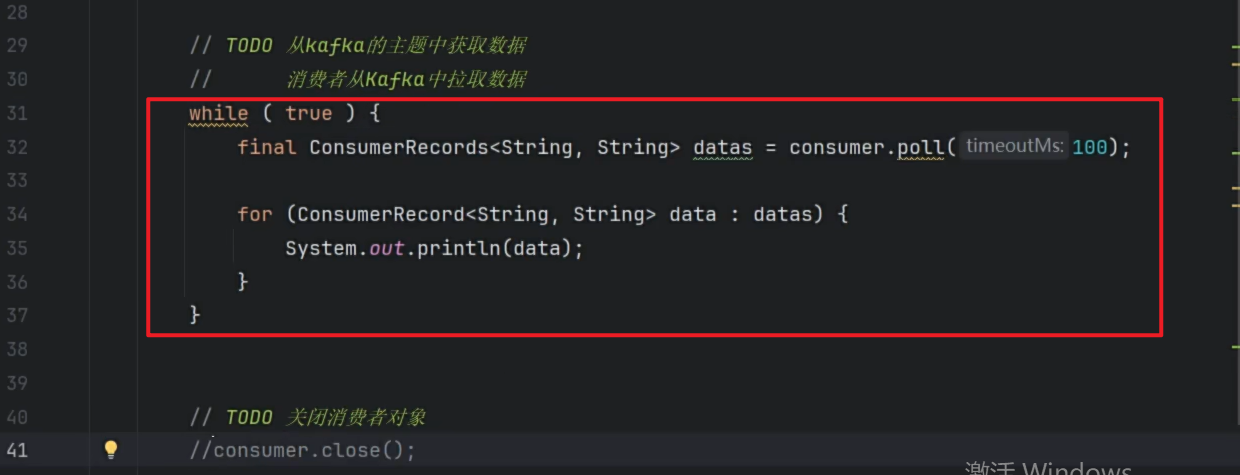
代码测试

- Kafkatool工具来操作Kafka
- 启动zk和kafka
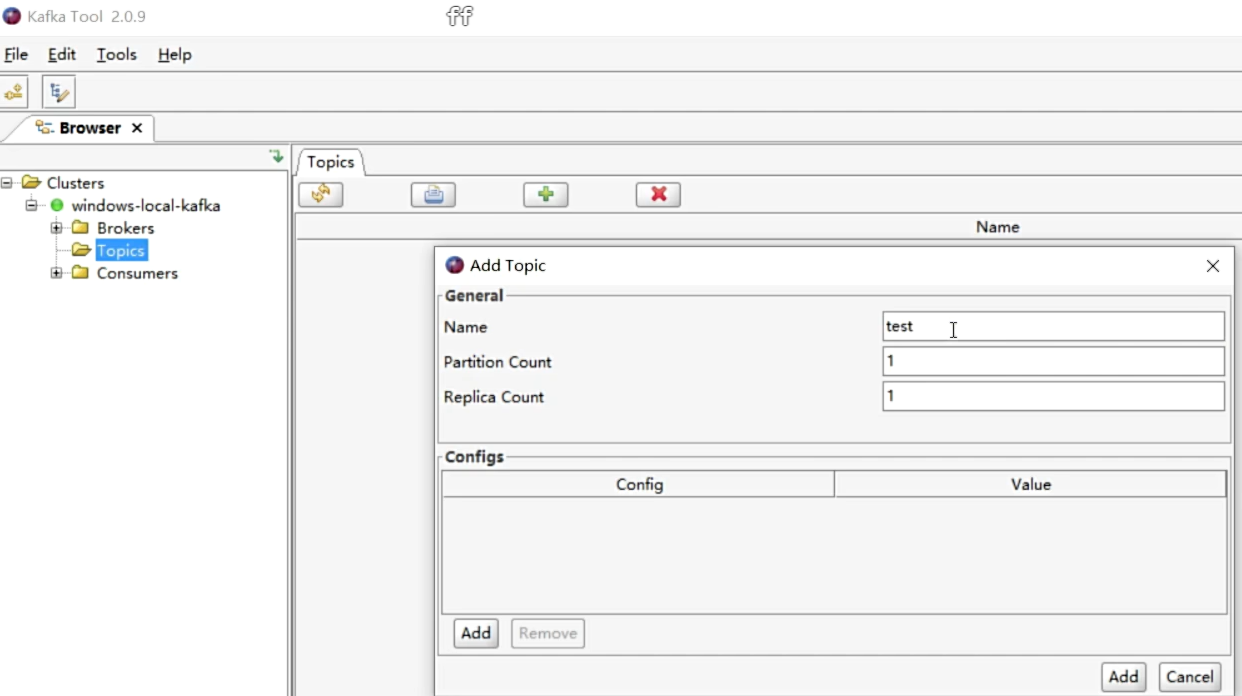
- 添加Topic
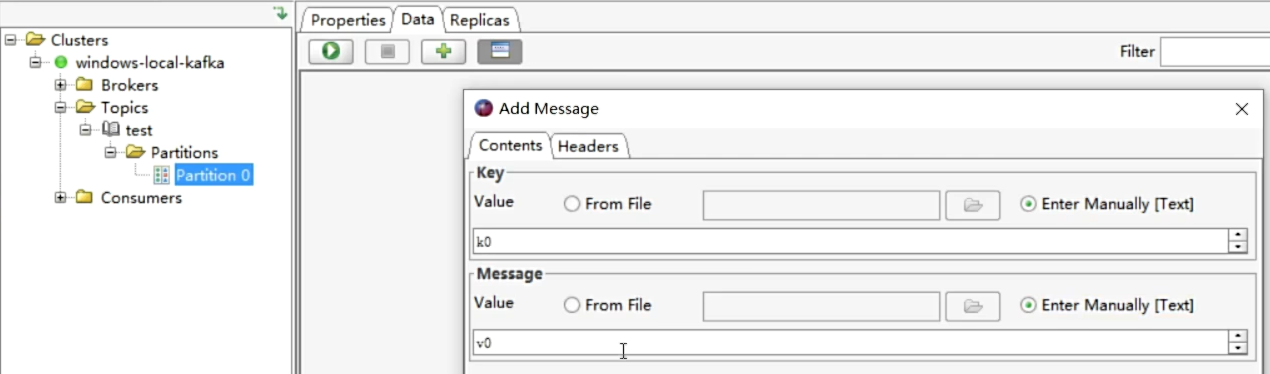
- 添加数据

- 通过Gradle可以看源码,JDK17+Scala插件 打开源码文件
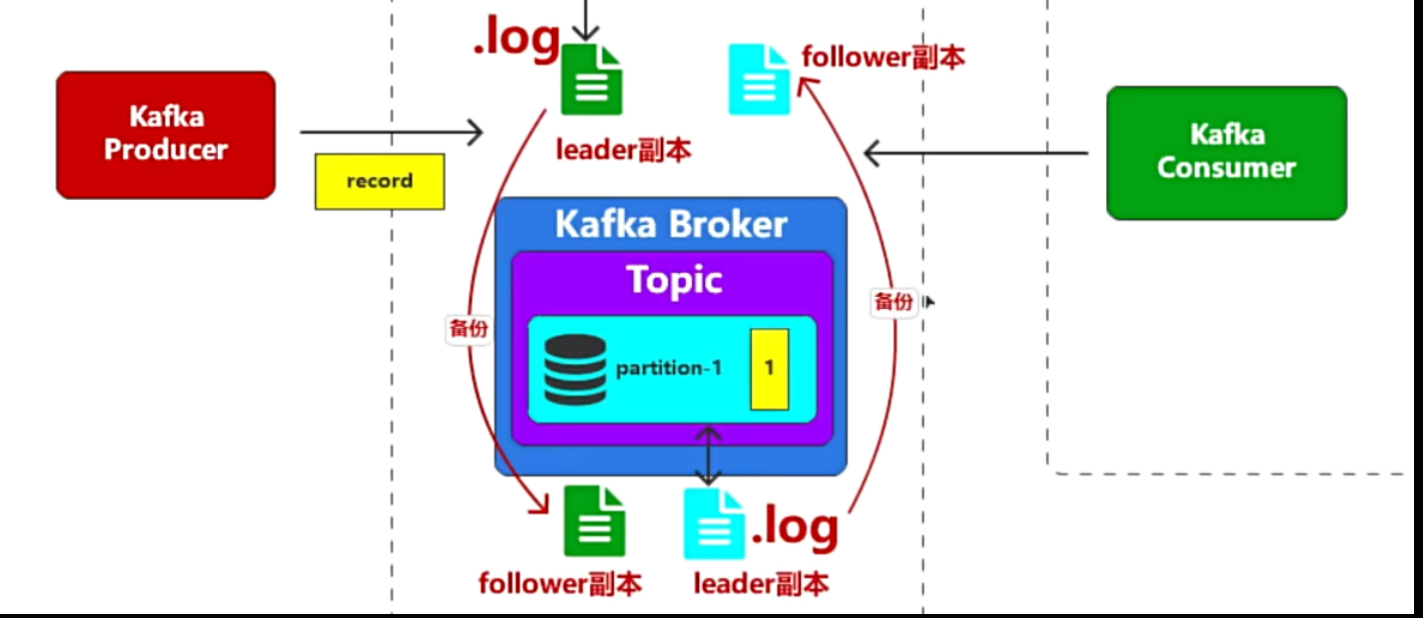
Kafka的系统架构
- 单个Kafka服务很容易出现性能瓶颈和高可用问题
- 采用集群部署,每个Kafka的Broker中都有同一个Topic
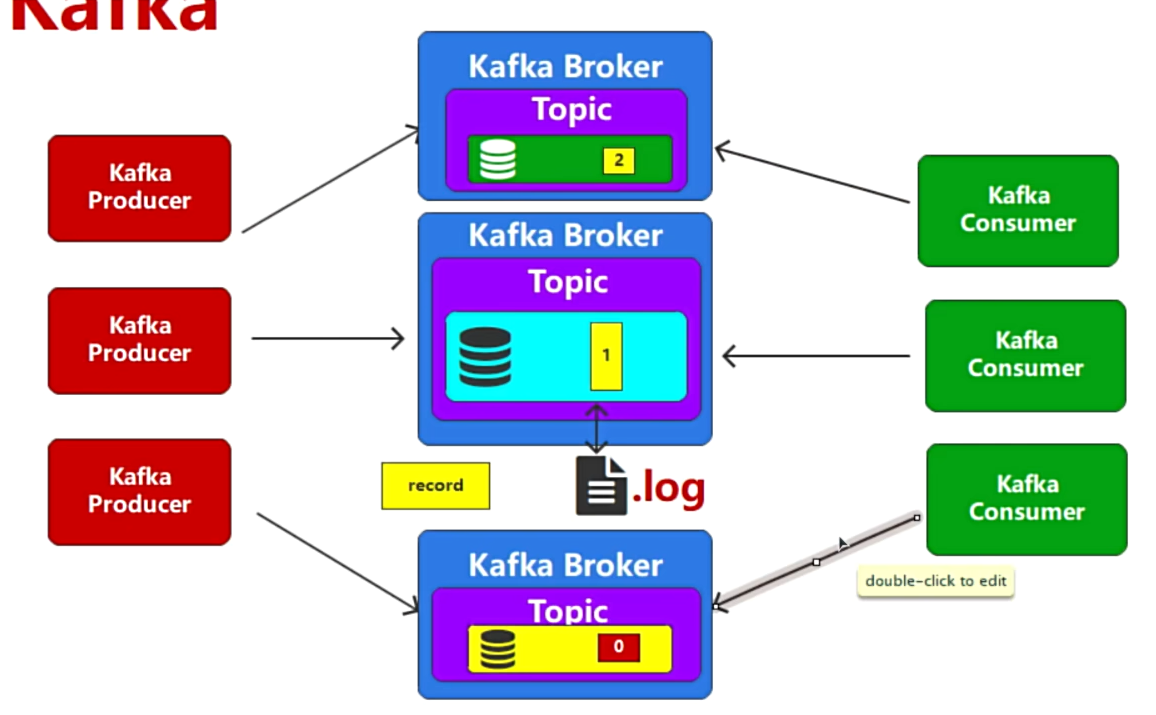
- 如何消费同一个主题Topic下不同分区的消息?
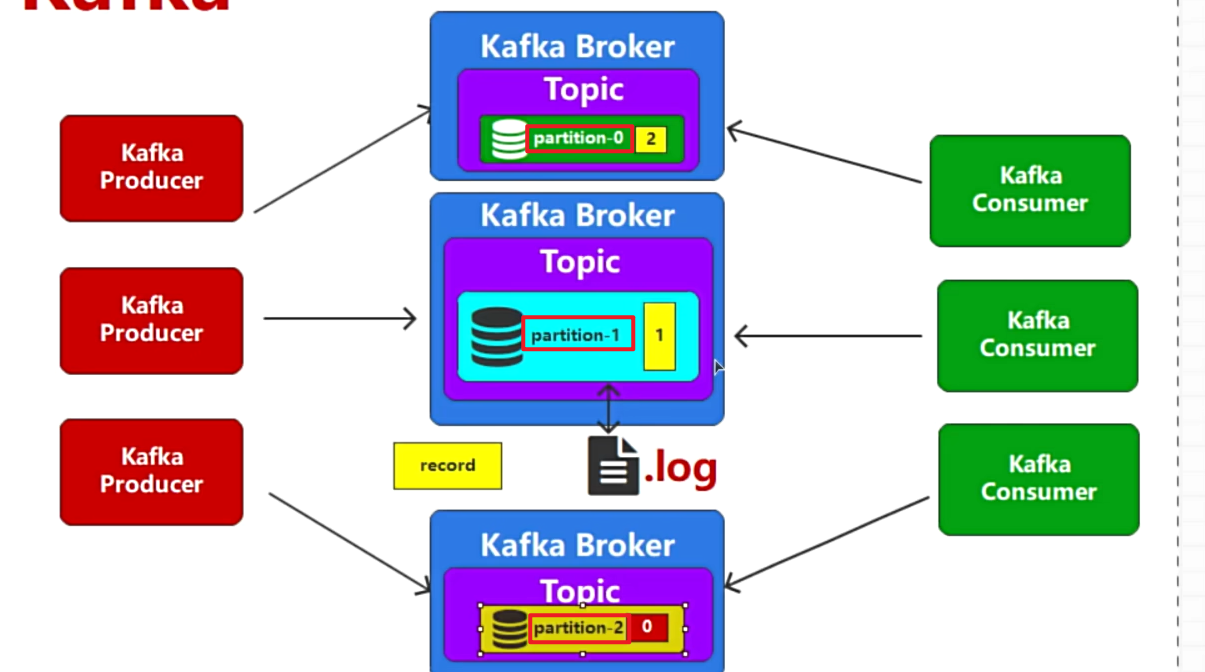
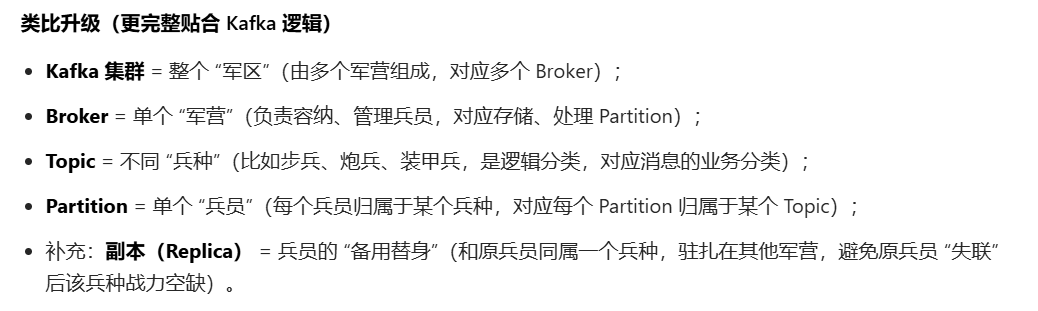
- 正常来说1个Topic是一个整体,现在却被划分到不同的broker的partition中,将partition编号,0-1-2-3
- 消费的时候,订阅1个Topic,这个Topic的partition分散在不同的Broker中,消费的时候不可能只消费某个broker,而是全部Topic,无论在哪个Broker中都要能消费到。
- 所以消费的时候,要将消费同一个Topic的多个消费者组成1个消费者组(整体)
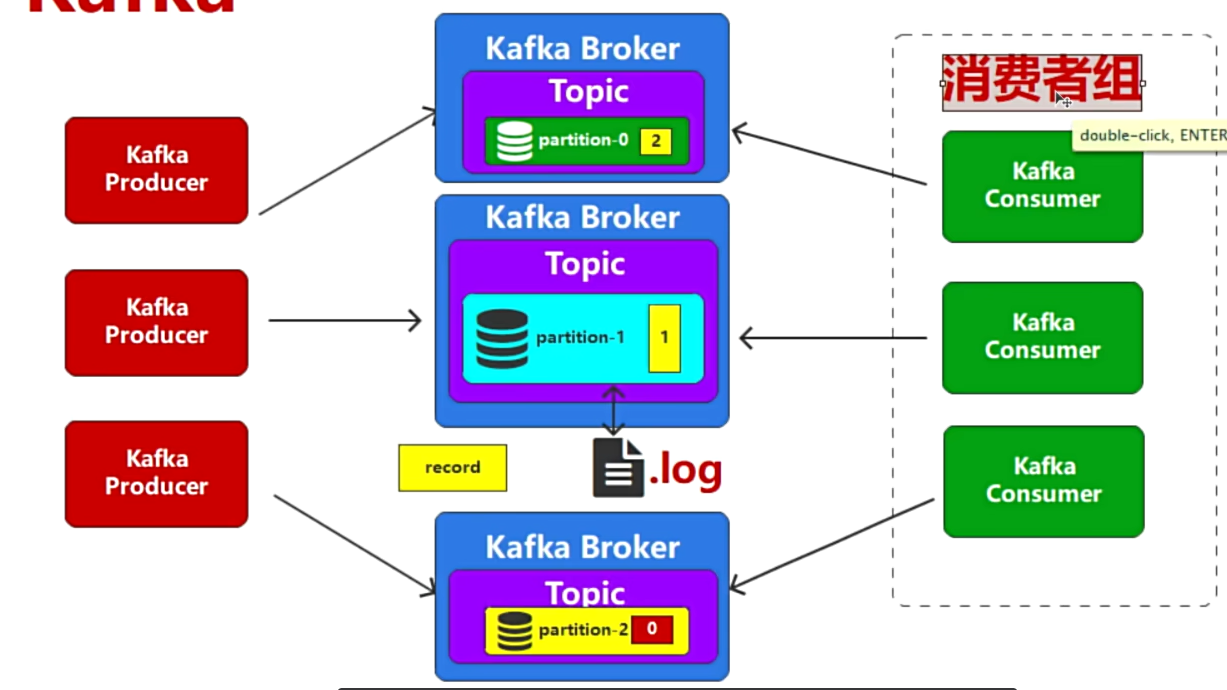
- 如果某个Broker宕机,那对应的partition的消息就无法消费了,所以要有个备份,保证其中一个宕机,也能消费到那个宕机的Broker的消息
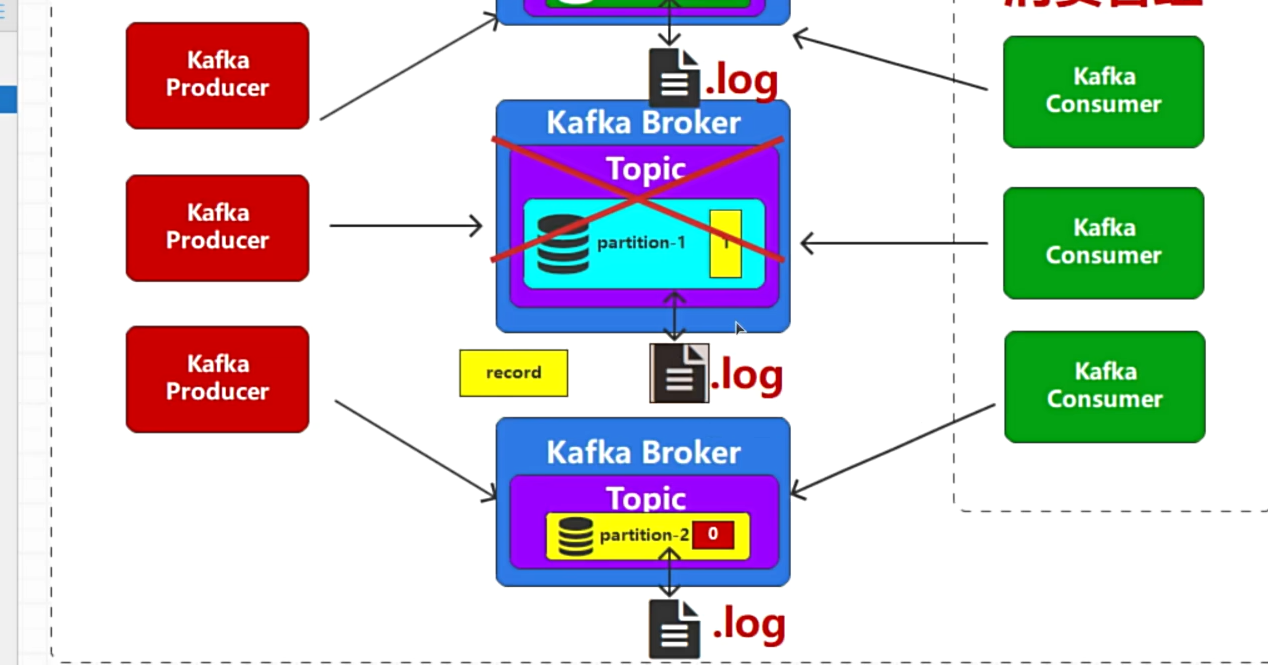
- 采用不同Broker之间互相备份,保证高可用
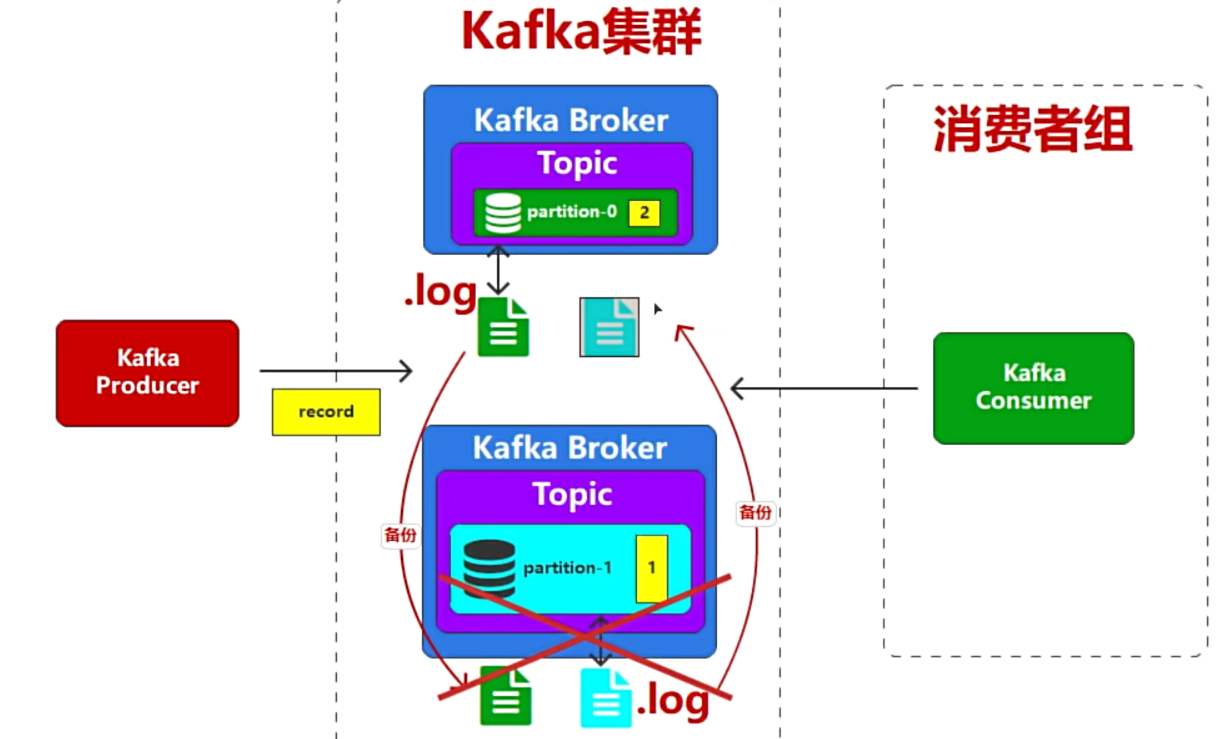
- 副本的概念(就是备份),不同的Broker互相存副本

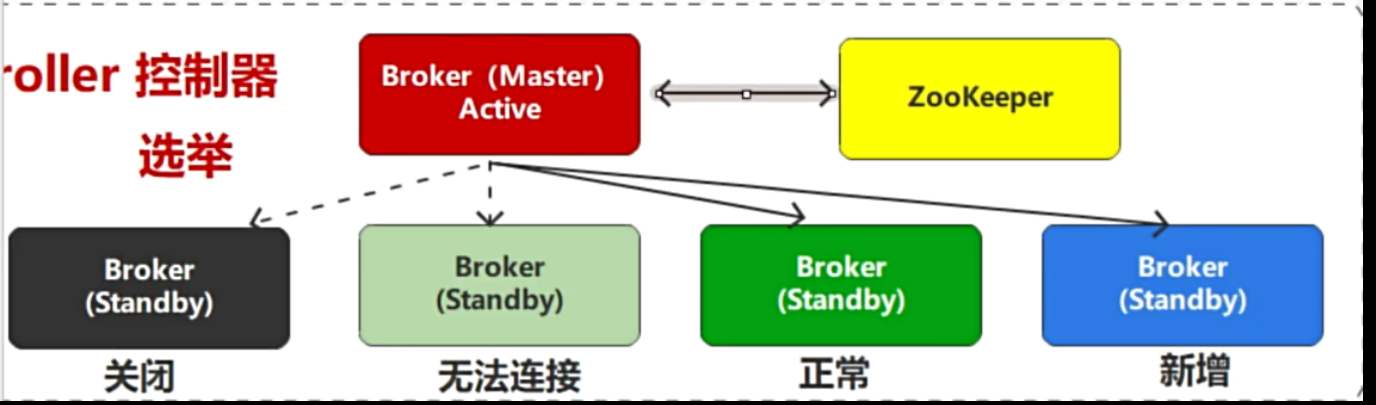
- 一旦Master宕机,靠Zookeeper重新选举
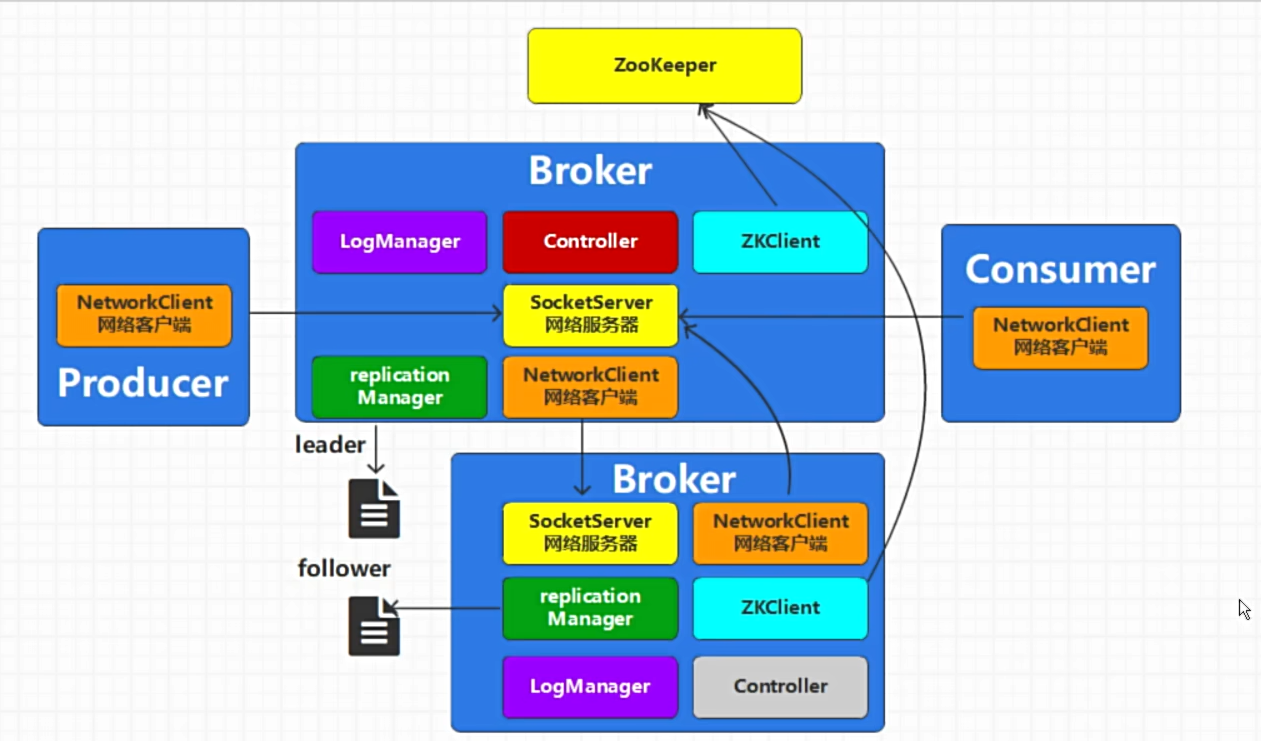
- Kafka集群图
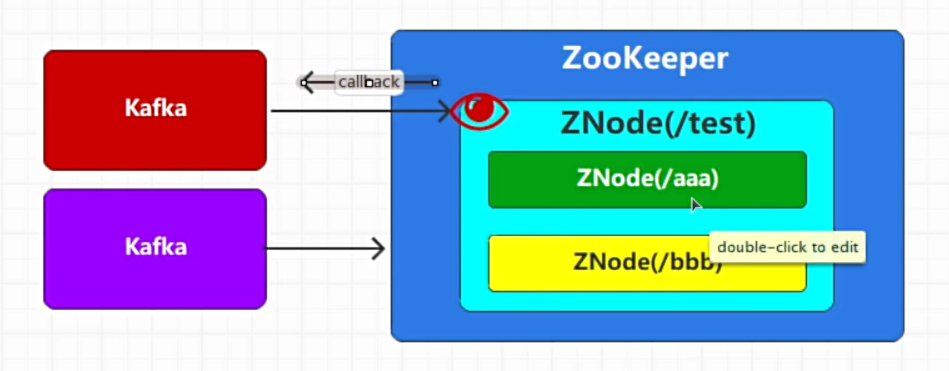
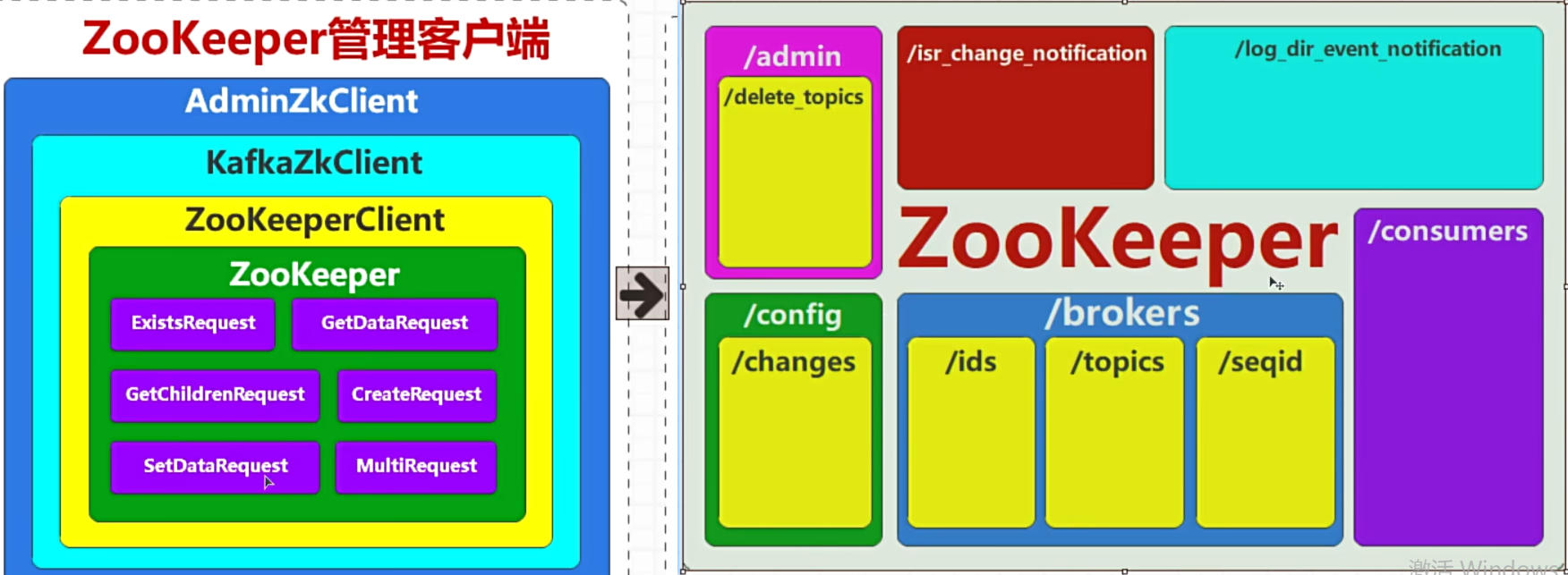
Zookeeper的核心功能
- 持久化节点,Kafka切断连接后,Zookeeper中的Znode节点依然会保留
- 临时节点,,Kafka切断连接后,Zookeeper中的Znode节点会消失
- Broker启动后Zookeeper节点的变化
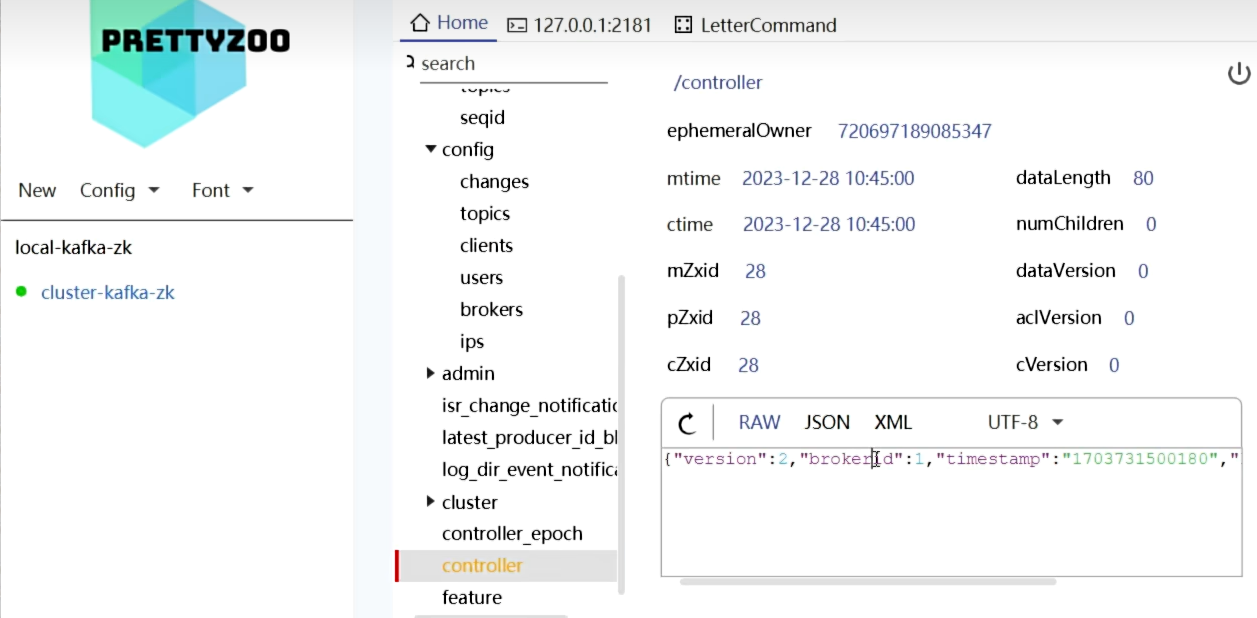
- 通过prettyZoo
- 未启用节点
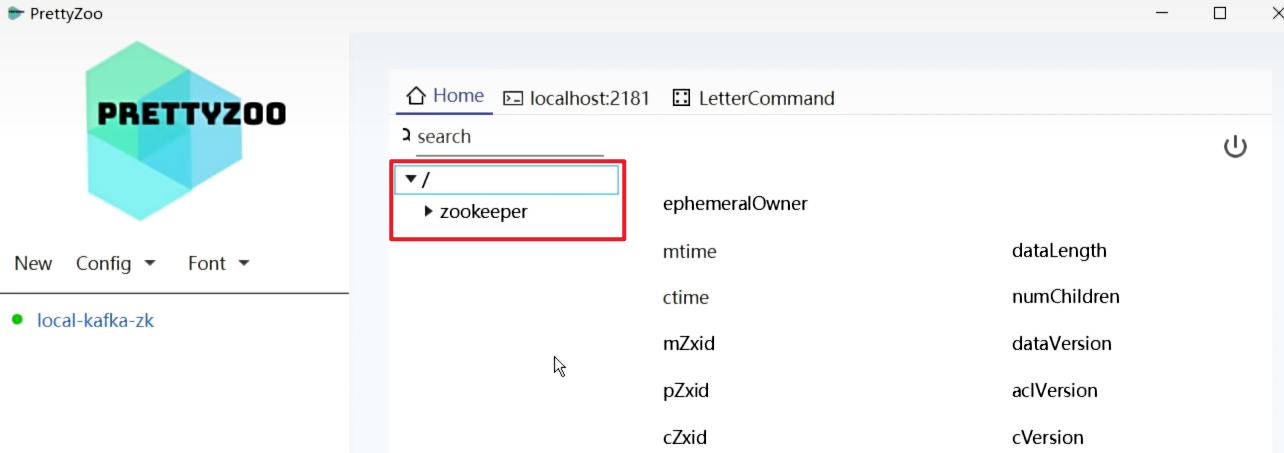
- 启动Kafka节点之后
- 启动3个节点,只在Brokers里增加了
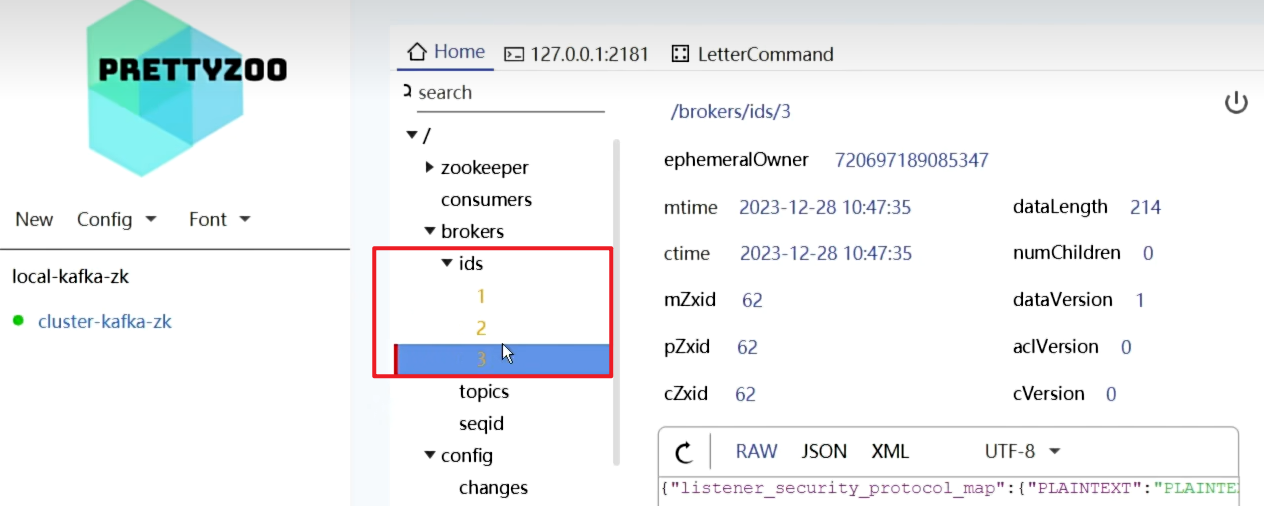
- 而Controller没有变化,只有一个
Zookeeper选举的过程
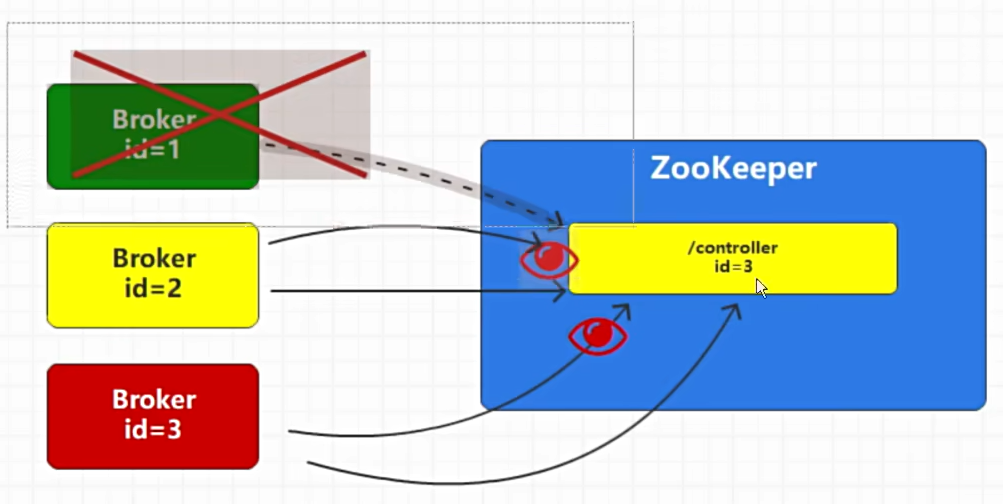
- Controller选举过程详解
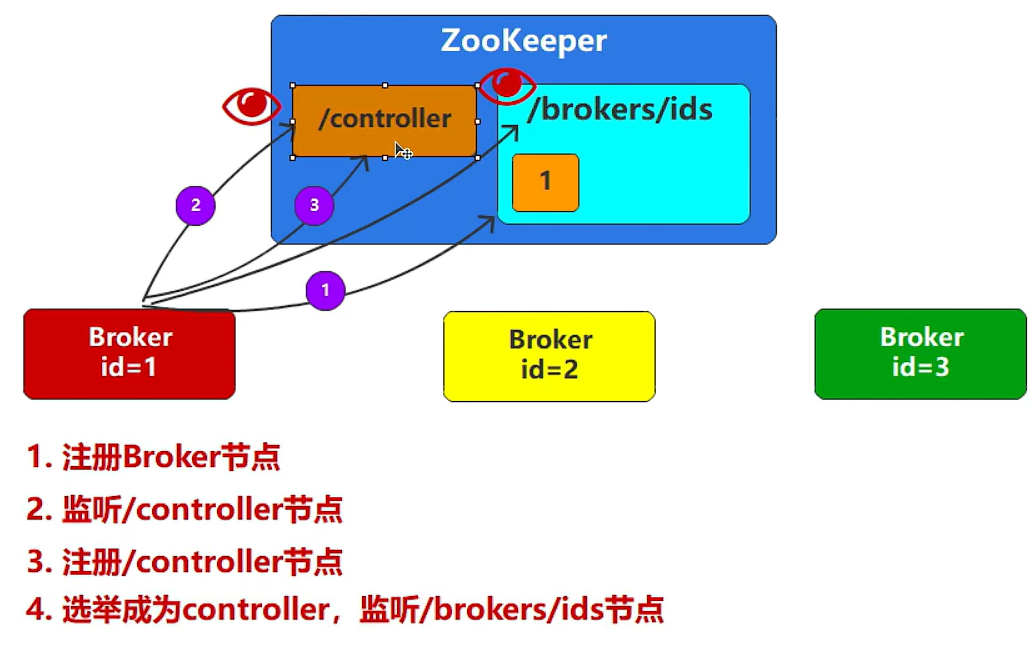
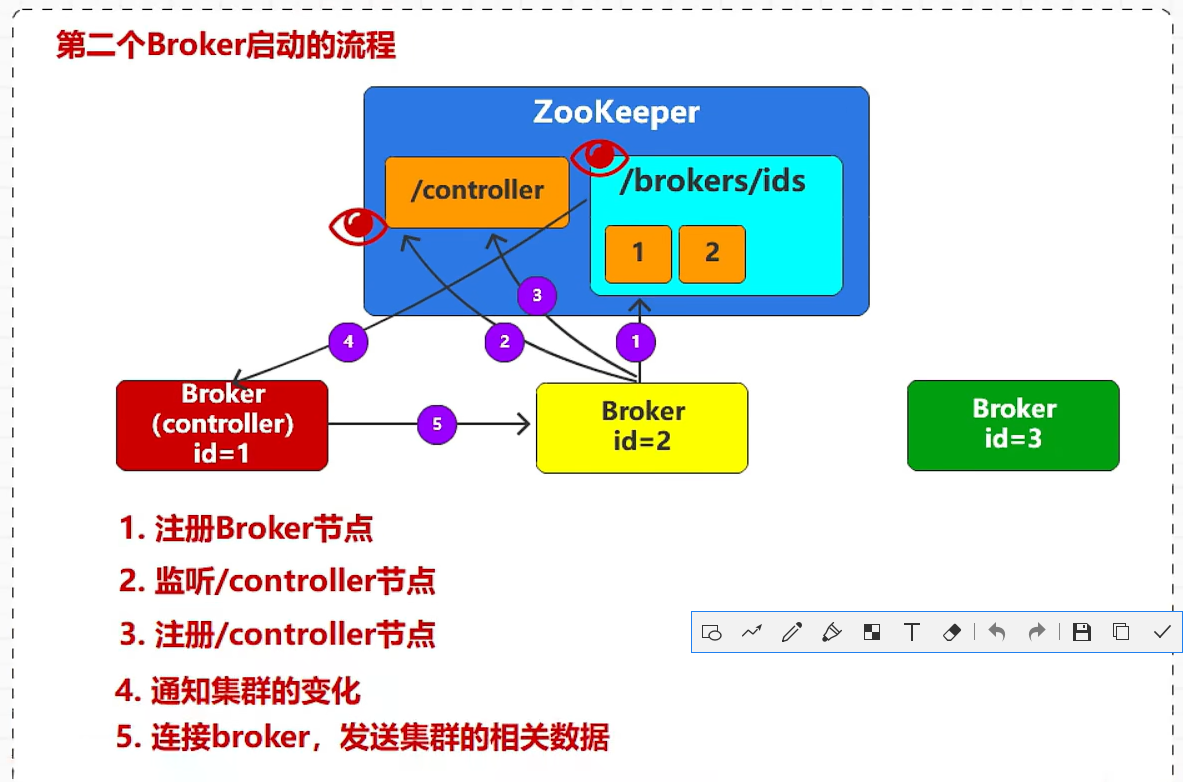
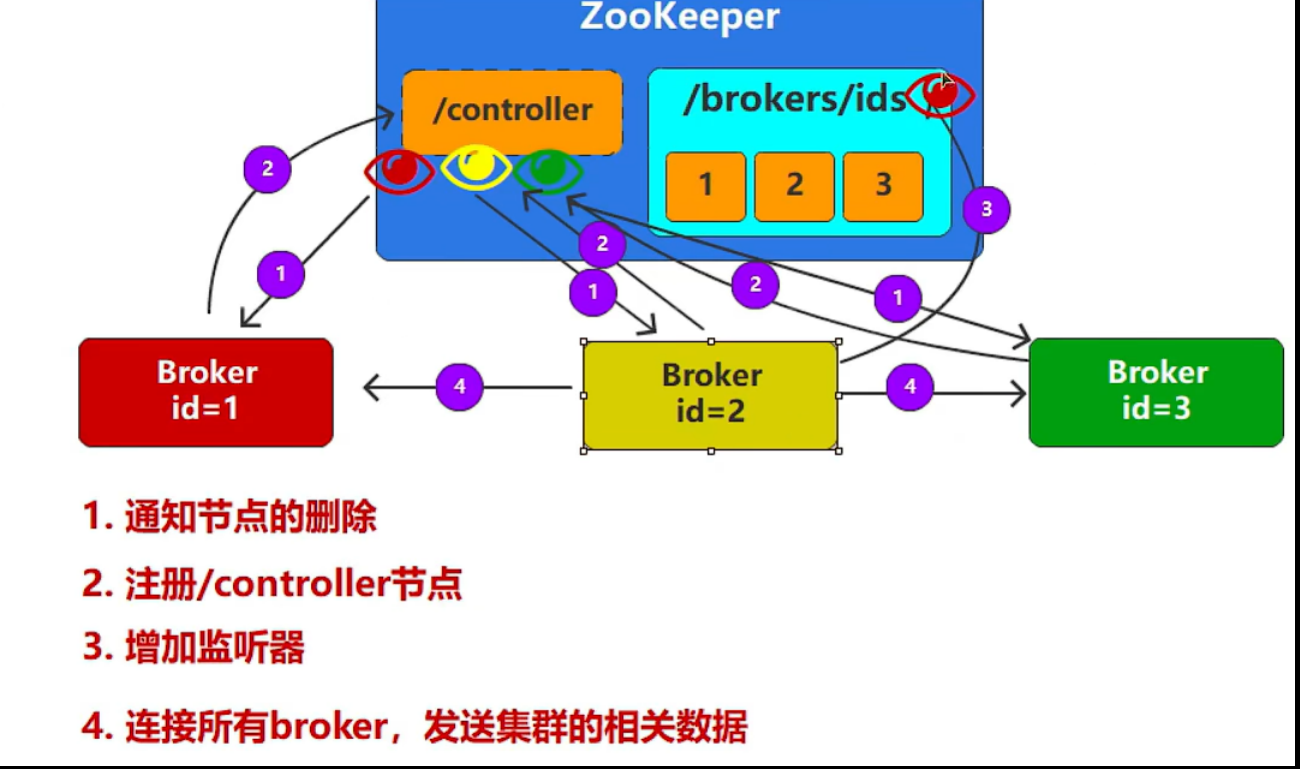
- Zookeeper中没有任何节点,此时启动第一个Broker,ZK当中创建第一个节点,id=1;成为集群的管理者;
- ZK有节点1了,启动Broker2,ZK当中创建第2个节点,id=2;
- ZK有节点1和2了,启动Broker3,ZK当中创建第3个节点,id=3;
一旦Broker1宕机,Broker2和Broker3就会竞争,成功者会成为集群的管理者;
- 第一个Broker启动的流程
- 第二个Broker启动的流程
- 第三个Broker启动的流程

- controller节点如果被删除的情况
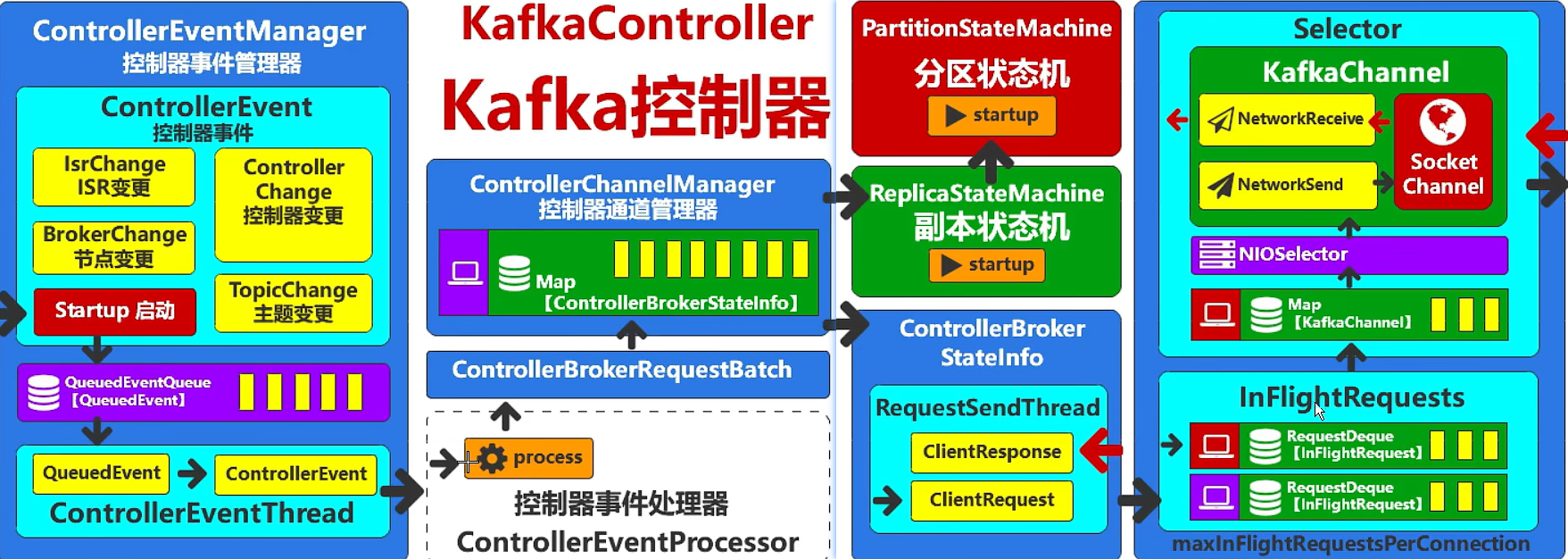
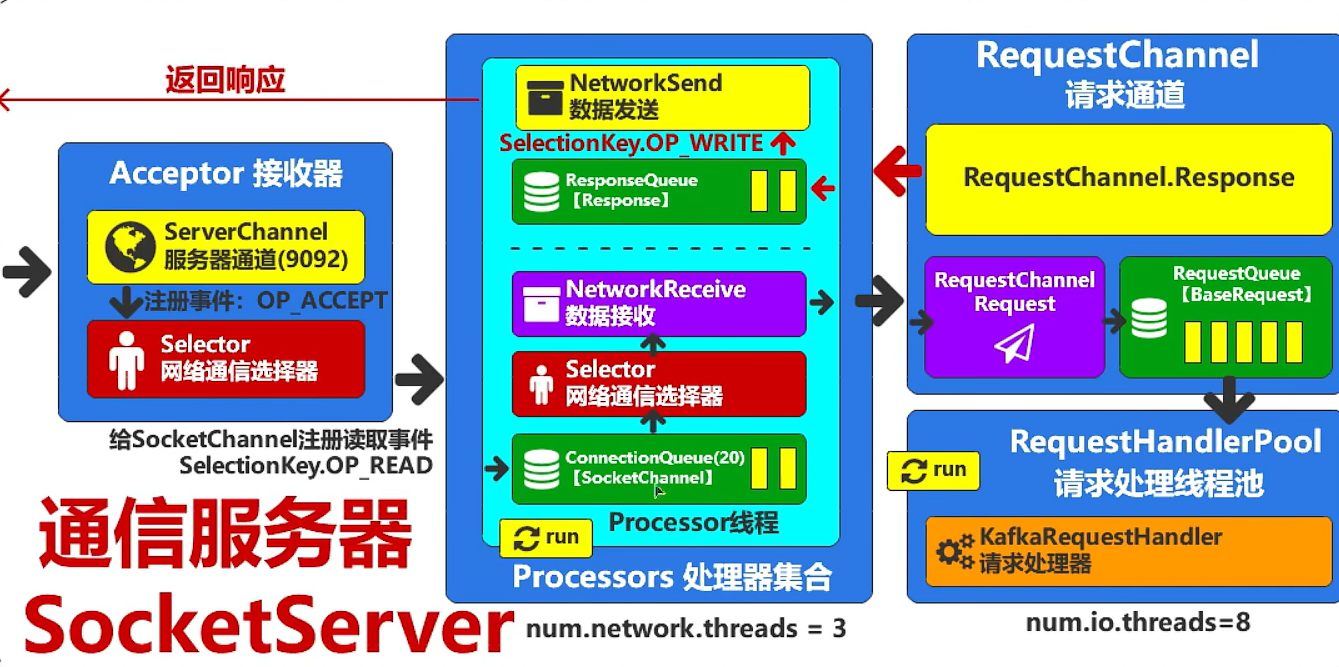
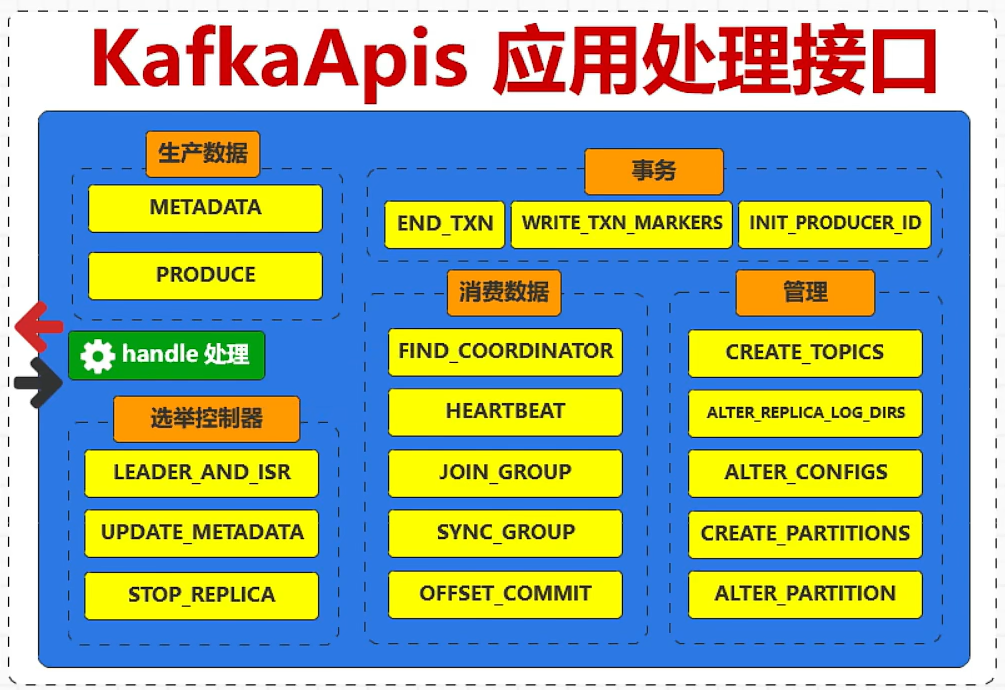
启动服务器底层实现
- Broker和ZK之间的通信