LARGE LANGUAGE MODELS ARE NOT ROBUST
ICLR2024
LLM在回答多项选择题时存在选择偏差问题(模型依赖选项"A/B/C/D"而非内容本身作答,模型爱选C)
提出名为PriDe (Prior Debiasing)推理时 使用的、无标签(不需要答案)的无监督去偏方法:
致偏原因:
1.主要原因:词元偏差 (Token Bias) 。模型在预训练阶段可能接触了某些标识符(如'A'、'B'、'C'、'D')作为正确答案的频率不均衡,导致它在生成答案时,会先验地(a priori)为特定的标识符分配更高的概率 。
2.次要原因:位置偏差 (Position Bias) 。模型有时会偏爱出现在特定位置(如第一个或最后一个)的选项,但研究发现这种偏差相比词元偏差规律性更差,且因模型和任务而异 。
去偏方法 : PriDe (Debiasing with Prior estimation) 。这是一种无需标签、在推理阶段进行的去偏方法 。核心思想是先用少量样本估算出模型对选项标识符(A/B/C/D)的"固有偏见"(即先验概率),然后在回答剩余问题时,从模型的原始预测中"除掉"这个偏见,从而得到更公正的答案 。
文中用到的LLM : 论文共测试了20种模型,包括:Llama (7B, 13B, 30B, 65B), Llama-2 (7B, 13B, 70B, 包含chat版本), Vicuna (v1.3 和 v1.5版本), Falcon (7B, 40B, 包含instruct版本) 以及 gpt-3.5-turbo 。
方法:
核心思想:
模型对一个选项的最终预测概率(P_{observed})可以被分解为两个部分的乘积:
- 模型对选项内容的"真实" (P_{debiased})
- 模型对选项ID(如 "A")的"先验偏好" (P_{prior})
PriDe 的目标就是估算出这个"先验偏好" P_{prior},然后用 P_{observed} 除以 P_{prior},从而得到去偏后的"真实信念" P_{debiased}
1.先验估计:
算出模型对每个编号(A/B/C/D)的"偏爱程度"。
随机选5%题目,打乱选项内容,估计模型对各选项ID(A/B/C/D)的先验偏好Pprior
-
排列构造 :对每个多选题的选项内容生成 n种循环排列(如ABCD → BCDA → CDAB → DABC),确保每个内容 oi与每个ID dj至少配对一次,仅对选项内容 {oi}进行重新排序,保持选项ID {di}的字母顺序(A/B/C/D)固定不变
-
计算先验 :
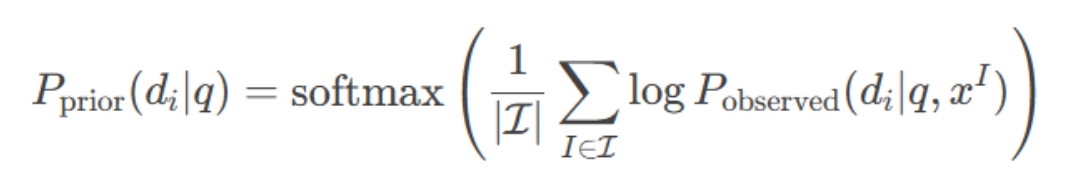
参数说明:
- I(排列) ∈(对一个问题 q 的选项内容进行 n 次循环排列)。这个排列的集合就是
- 选项集合 xI={(di,oi)}ni=1,
- di为固定选项ID(如A/B/C/D)
- Pobserved:每次排列 I后, 记录模型对ID di 的预测概率。(开源模型:直接读取模型对ID token(如"A"/"B")的预测概率。闭源API(如GPT-3.5):通过多次采样统计选项ID的出现频率)
全局先验:对所有估计样本取平均,得到先验偏好
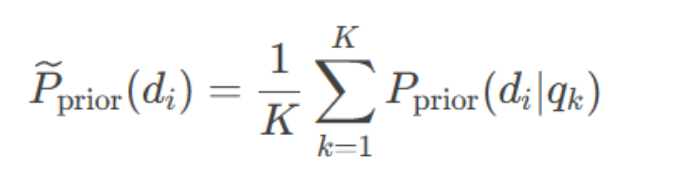
K:用于先验的样本数
2.去偏预测
对剩余样本,用公式 Pdebiased∝Pobserved/Pprior 消除ID偏好,保留对内容的真实置信度,先验p 调整剩余样本的预测分布,消除偏差
去偏预测:用"偏爱值"修正模型的答案
对剩余95%样本,先让模型正常预测,得到每个样本的原始概率Pobs(di)
用全局先验校正预测:
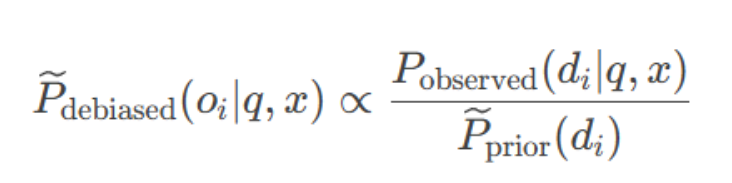
- P observed:原始模型对ID di的概率
- P~~prior~(di):全局平均先验
- x:默认选项顺序的输入
输出答案
选择去偏后概率最高的选项:
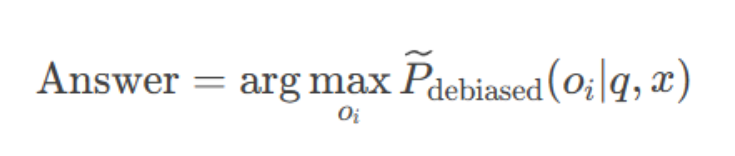
示例:
- 原始预测:{A:0.6, B:0.2, C:0.1}
- 偏爱值:{A:0.5, B:0.3, C:0.2}
- 修正计算:
A: 0.6/0.5=1.2
B: 0.2/0.3≈0.67
C: 0.1/0.2=0.5 - 最终选择:A(因为1.2最大)
mmlu
去id后,noid答案分布

原始答案分布

无 ID" 前提下 的三种文字顺序(原始noid、随机shuffle_both、循环cyclic)正是用来 暴露模型对选项顺序或位置的依赖。
permutation baseline:把输入里的选项内容随机打乱(permute),然后看模型输出是否正确。
多次随机置换融合:对同一道题,随机置换 多次(10 次),让模型回答多次,再进行"融合(fusion)"。
融合方式:
- 多数投票(majority voting)
模型在10次置换中,哪一个答案出现最多次,就认为是最终答案。 - 平均概率(probability averaging)
模型每次生成一个各选项的概率分布,最后对这些概率取平均,再选最大者。
这篇论文,研究共在 20 种来自不同系列和规模的大型语言模型(LLM)上进行了实验 。包括 :
-
Llama 系列:
- llama-7B
- llama-13B
- llama-30B
- llama-65B
-
Llama-2 系列:
- llama-2-7B
- llama-2-13B
- llama-2-70B
-
Llama-2-Chat 系列:
- llama-2-chat-7B
- llama-2-chat-13B
- llama-2-chat-70B
-
Vicuna 系列:
- vicuna-v1.3-7B
- vicuna-v1.3-13B
- vicuna-v1.3-33B
- vicuna-v1.5-7B
- vicuna-v1.5-13B
-
Falcon 系列:
- falcon-7B
- falcon-40B
-
Falcon-Instruct 系列:
- falcon-inst-7B
- falcon-inst-40B
-
OpenAI API 模型:
- gpt-3.5-turbo-0613 3
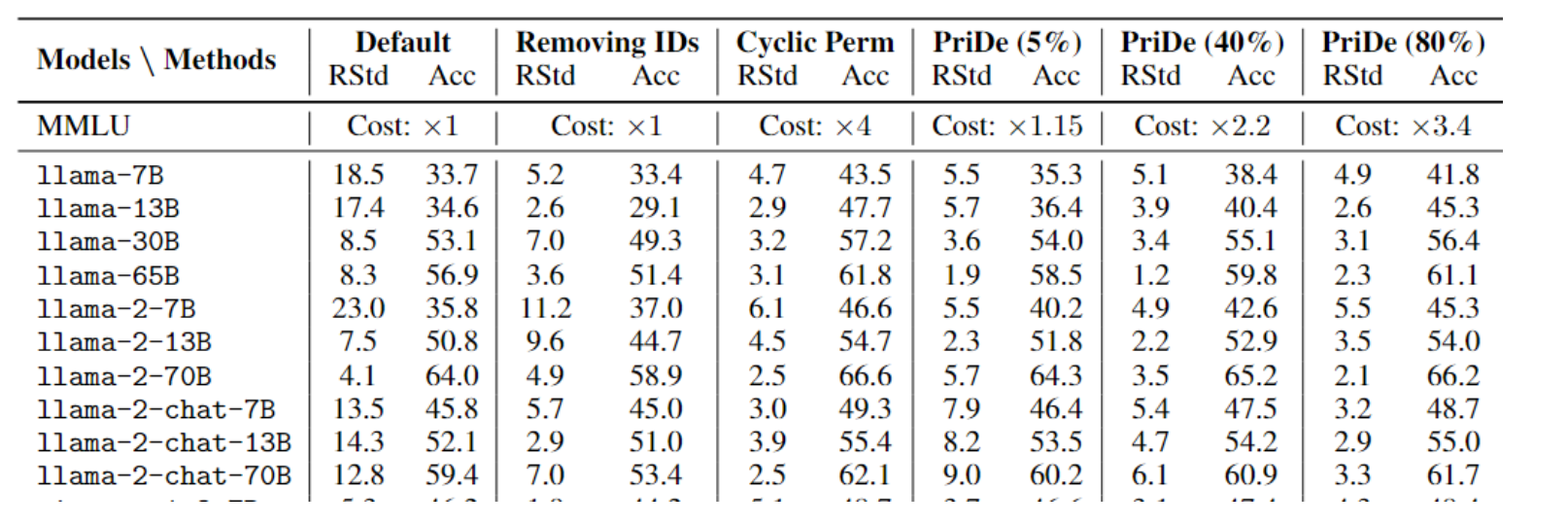
比较不同去偏方法(PriDe, Cyclic Perm, Full Perm)在不同计算成本下的"去偏效果"
Y 轴 (上排): Delta Recall Std (%)
- "召回率标准差的A变化量" 。用来衡量"选择偏差"的指标。这个值越低(越负)越好,代表偏差被消除得越彻底。
- Y 轴 (下排): Delta Accuracy (%) , "准确率的变化量" 。这个值越高越好,代表模型性能提升得越多。
Full Perm: 完全排列(成本最高,效果的理论上限)。4!种排列组合
Cyclic Perm: 循环排列(论文提出的基准方法)。(4种,ABCD,BCDA,CDAB,DABC)
PriDe: 论文提出的新方法(绿色曲线)。
X "计算成本"
"基准推理成本"(即不对样本做任何处理、只推理 1 次)为 x1
对于 Cyclic Perm / Full Perm (蓝色/橙色曲线):
- 成本是通过**改变"被去偏的样本比例"**来控制的。
- 例如,在 MMLU(4选项)中,
Cyclic Perm的成本是 x4。 - 如果要在图上找到 x2.2 的成本点,它们会选择只对 40% 的样本 执行 x4 的
Cyclic Perm,其余 60% 的样本执行 x1 的标准推理。 - 总成本 = (40% * x4) + (60% * x1) = x1.6 + x0.6 = x2.2。
对于 PriDe (绿色曲线):
- 它的成本是通过改变"用于估算先验的样本比例α" 来控制的。
- PriDe 的工作方式是:先用一小部分样本(比例为 α)来"估算偏差"(这部分样本本身也用
Cyclic Perm进行去偏),然后用这个估算出的偏差去"高效去偏"剩余的 (1-α)比例的样本。 - 例如,在 MMLU(4选项,
Cyclic Perm成本为 x4)上: - x1.15 成本点 (PriDe): 对应 α=5%
- 总成本 =(5% 样本 * x4 成本) + (95% 样本 * x1 成本) = x0.2 + x0.95 = x1.15。

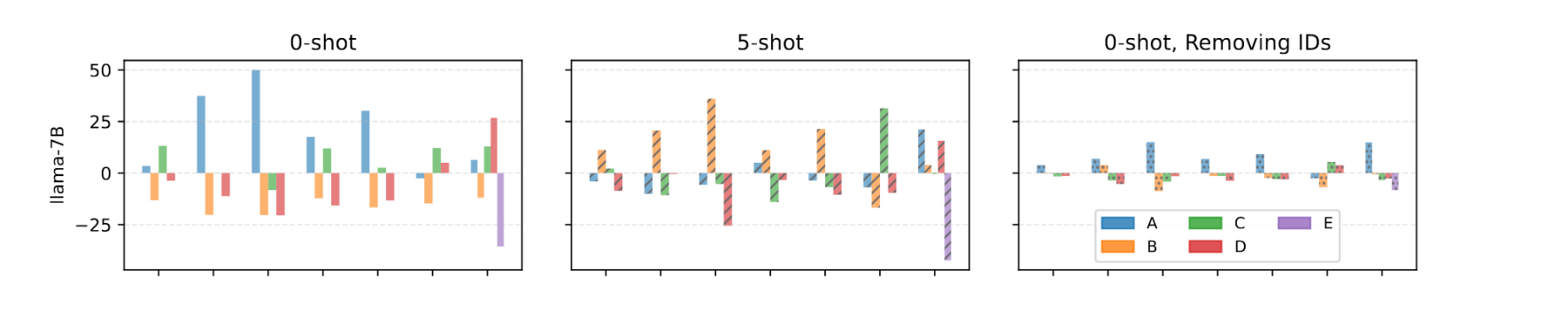
纵坐标 (Y-axis) 的含义: "归一化的召回率得分 (%)"
计算方法:(该选项的召回率) - (模型的整体准确率)
正值 (例如 +20): 假设模型在 "STEM" 数据集上的整体准确率是 50%。如果它在答案是 "A" 的问题上召回率 (Recall) 达到了 70%,那么 "A" 的纵坐标值就是 70 - 50 = +20。这表明模型强烈偏好 (bias towards) "A"。