目录
[Eureka Client](#Eureka Client)
[Eureka Server](#Eureka Server)
在 服务注册与发现------Eureka-CSDN博客 中,我们学习了 Eureka 的基本使用 ,在本篇文章中,我们就来进一步学习Eureka 是如何实现服务注册的
由于其中的代码量较多,我们只关注核心流程和关键代码,先来看Eureka Client的具体实现
Eureka Client
在 Eureka Client 启动时,会向 Eureka Server 发送注册请求
关键类:com.netflix.discovery.DiscoveryClient
我们找到DiscoveryClient 的构造函数 ,由于其中内容较多,我们直接找到注册相关逻辑:
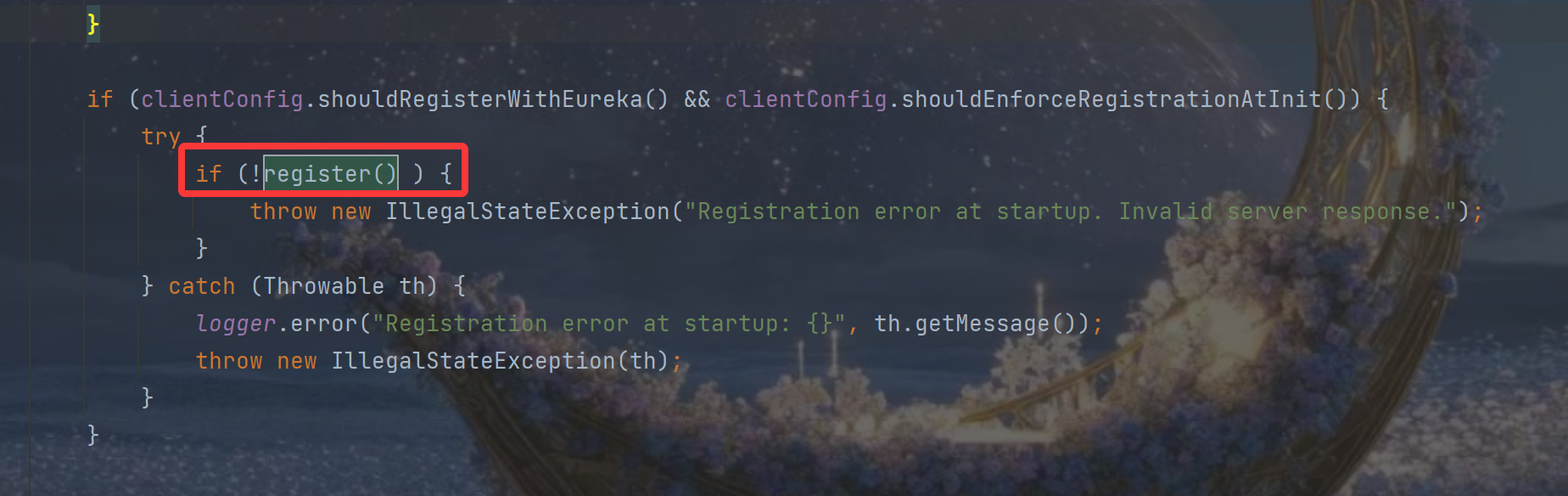
具体注册逻辑:
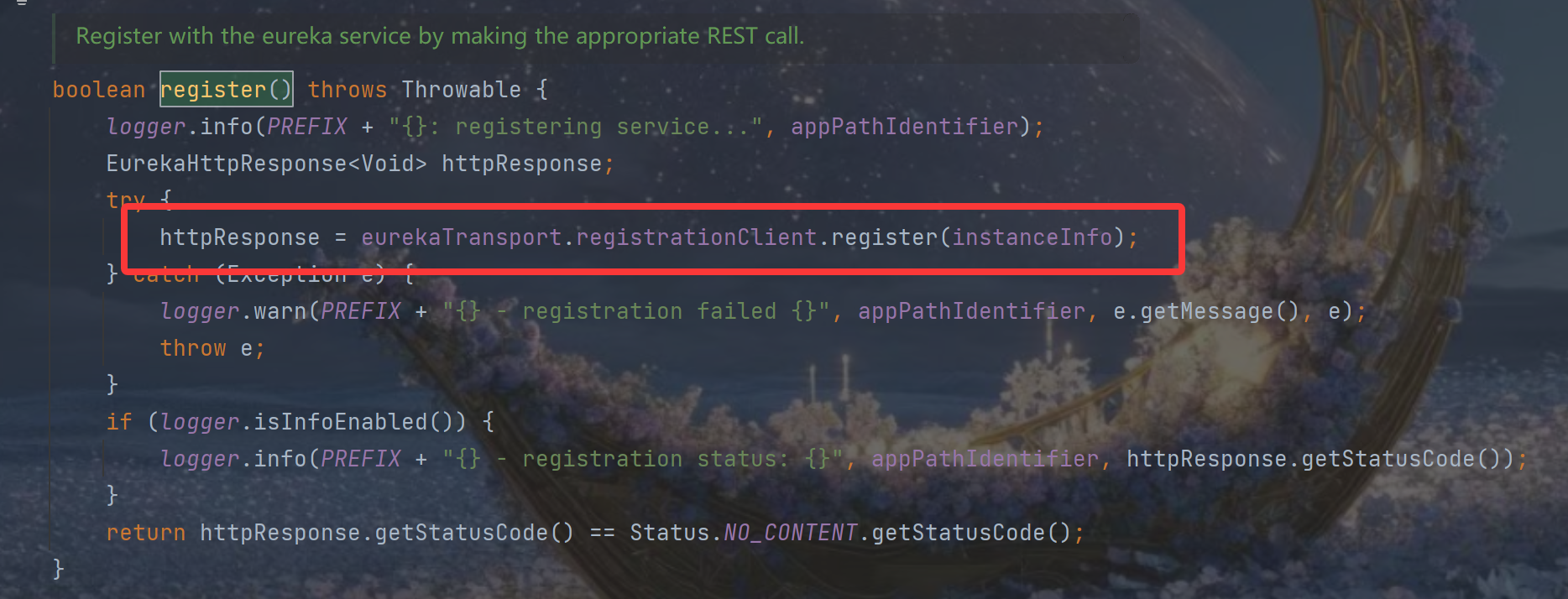
通过 eurekaTransport.registrationClient 发送注册请求,其中 InstanceInfo 包含了客户端实例的所有元数据:
java
public class InstanceInfo {
private String instanceId; // 实例ID
private String appName; // 应用名
private String ipAddr; // IP地址
private String vipAddress; // 虚拟IP
private String secureVipAddress; // 安全虚拟IP
private int port; // 端口
private InstanceStatus status; // 状态(UP/DOWN)
// ... 其他字段
}底层使用 RESTful 发送注册请求:POST /eureka/apps/{appName}
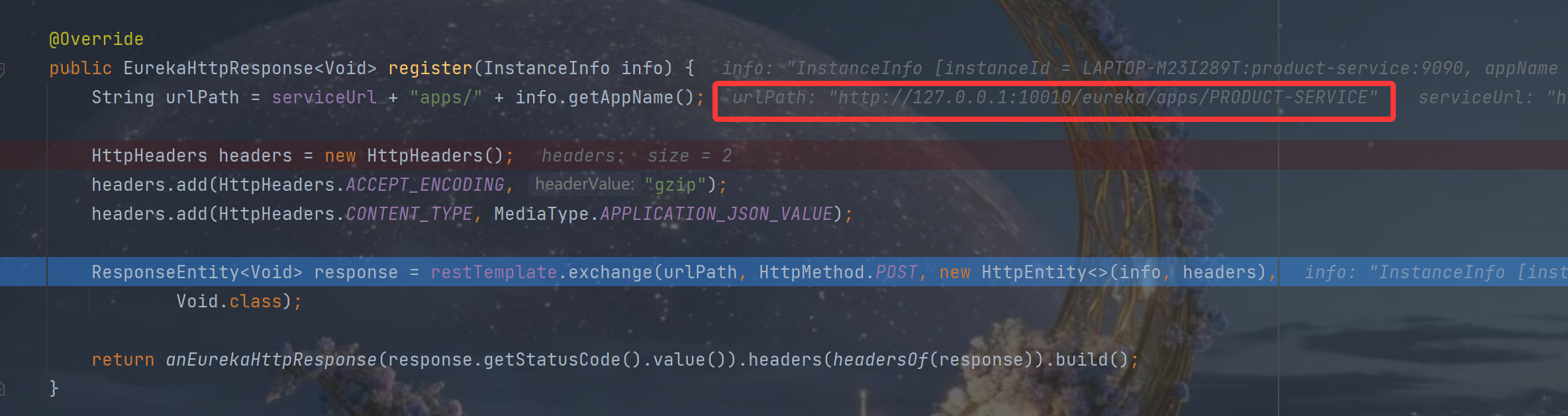
最后检查 HTTP 响应状态码是否为204(NO_CONTENT),判断是否注册成功
return httpResponse.getStatusCode() == Status.NO_CONTENT.getStatusCode();
上述Eureka Client 的实现比较简单,我们重点来看Eureka Server是如何实现具体的注册逻辑的
Eureka Server
Eureka Server 用作服务注册中心 ,负责微服务的注册与发现。设计遵循 CAP 理论中的AP 模型(高可用和分区容错),通过多级缓存、异步复制等机制实现高性能和高可用
关键类:com.netflix.eureka.registry.AbstractInstanceRegistry
我们找到**register()**方法:
java
/**
* Registers a new instance with a given duration.
*
* @see com.netflix.eureka.lease.LeaseManager#register(java.lang.Object, int, boolean)
*/
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
read.lock();
try {
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
REGISTER.increment(isReplication);
if (gMap == null) {
final ConcurrentHashMap<String, Lease<InstanceInfo>> gNewMap = new ConcurrentHashMap<String, Lease<InstanceInfo>>();
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
Lease<InstanceInfo> existingLease = gMap.get(registrant.getId());
// Retain the last dirty timestamp without overwriting it, if there is already a lease
if (existingLease != null && (existingLease.getHolder() != null)) {
Long existingLastDirtyTimestamp = existingLease.getHolder().getLastDirtyTimestamp();
Long registrationLastDirtyTimestamp = registrant.getLastDirtyTimestamp();
logger.debug("Existing lease found (existing={}, provided={}", existingLastDirtyTimestamp, registrationLastDirtyTimestamp);
// this is a > instead of a >= because if the timestamps are equal, we still take the remote transmitted
// InstanceInfo instead of the server local copy.
if (existingLastDirtyTimestamp > registrationLastDirtyTimestamp) {
logger.warn("There is an existing lease and the existing lease's dirty timestamp {} is greater" +
" than the one that is being registered {}", existingLastDirtyTimestamp, registrationLastDirtyTimestamp);
logger.warn("Using the existing instanceInfo instead of the new instanceInfo as the registrant");
registrant = existingLease.getHolder();
}
} else {
// The lease does not exist and hence it is a new registration
synchronized (lock) {
if (this.expectedNumberOfClientsSendingRenews > 0) {
// Since the client wants to register it, increase the number of clients sending renews
this.expectedNumberOfClientsSendingRenews = this.expectedNumberOfClientsSendingRenews + 1;
updateRenewsPerMinThreshold();
}
}
logger.debug("No previous lease information found; it is new registration");
}
Lease<InstanceInfo> lease = new Lease<>(registrant, leaseDuration);
if (existingLease != null) {
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
gMap.put(registrant.getId(), lease);
recentRegisteredQueue.add(new Pair<Long, String>(
System.currentTimeMillis(),
registrant.getAppName() + "(" + registrant.getId() + ")"));
// This is where the initial state transfer of overridden status happens
if (!InstanceStatus.UNKNOWN.equals(registrant.getOverriddenStatus())) {
logger.debug("Found overridden status {} for instance {}. Checking to see if needs to be add to the "
+ "overrides", registrant.getOverriddenStatus(), registrant.getId());
if (!overriddenInstanceStatusMap.containsKey(registrant.getId())) {
logger.info("Not found overridden id {} and hence adding it", registrant.getId());
overriddenInstanceStatusMap.put(registrant.getId(), registrant.getOverriddenStatus());
}
}
InstanceStatus overriddenStatusFromMap = overriddenInstanceStatusMap.get(registrant.getId());
if (overriddenStatusFromMap != null) {
logger.info("Storing overridden status {} from map", overriddenStatusFromMap);
registrant.setOverriddenStatus(overriddenStatusFromMap);
}
// Set the status based on the overridden status rules
InstanceStatus overriddenInstanceStatus = getOverriddenInstanceStatus(registrant, existingLease, isReplication);
registrant.setStatusWithoutDirty(overriddenInstanceStatus);
// If the lease is registered with UP status, set lease service up timestamp
if (InstanceStatus.UP.equals(registrant.getStatus())) {
lease.serviceUp();
}
registrant.setActionType(ActionType.ADDED);
recentlyChangedQueue.add(new RecentlyChangedItem(lease));
registrant.setLastUpdatedTimestamp();
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());
logger.info("Registered instance {}/{} with status {} (replication={})",
registrant.getAppName(), registrant.getId(), registrant.getStatus(), isReplication);
} finally {
read.unlock();
}
}register方法负责将服务实例注册到注册表,并处理各种边界条件和状态更新
其中:
registrant:要注册的服务实例信息(包含 IP、端口、状态等)
leaseDuration:租约持续时间(默认 90 秒)
isReplication:是否来自集群同步(避免循环复制)
并发冲突避免
register() 方法对注册操作进行了加锁:
java
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock read = readWriteLock.readLock();
read.lock();
try {
// 业务逻辑
} finally {
read.unlock();
}使用的锁类型是 ReentrantReadWriteLock 的读锁
在注册的过程中,会涉及到注册表的修改,那么,这里为什么使用的是读锁,而不是写锁呢?
我们首先来回顾读锁和写锁的特性:
读锁:允许多个读操作同时进行,但不允许进行写操作
写锁:获取锁的实例独占锁,阻塞所有其他读写操作
也就是说,在注册时不会阻塞其他读操作(如服务的查询、其他注册操作)
Eureka Client 会发送 其他注册请求 以及 定时发送心跳消息 ,也就意味着 Eureka Server 需要处理大量的服务注册和心跳请求,而这些操作都需要修改注册表(进行写操作)。如果使用写锁 ,那么每次只能有一个注册或心跳操作进行 ,其他操作都会被阻塞,就会极大降低并发性能,因此为了提高注册操作的并发性能,在这里采用了读锁,允许同时处理多个注册请求
那么,使用读锁,在修改注册表时,是否会存在并发安全问题?
关于这个问题,我们来看具体的业务逻辑实现代码:
java
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry
= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
// 获取该应用对应的租约映射
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
// 记录注册次数, 用于监控和诊断
REGISTER.increment(isReplication);
// gMap 为null,当前应用是首次注册
if (gMap == null) {
// 创建一个新的 ConcurrentHashMap 实例 gNewMap 用于存储实例租约
final ConcurrentHashMap<String, Lease<InstanceInfo>> gNewMap = new ConcurrentHashMap<String, Lease<InstanceInfo>>();
// 使用 putIfAbsent 方法将新创建的 gNewMap 安全地放入 registry
// 返回值 gMap 可能是null(表示插入成功)或其他线程已存入的Map
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
// 返回值 gMap 为null,说明新Map已成功插入,此时将 gMap 指向新创建的 gNewMap
if (gMap == null) {
gMap = gNewMap;
}
}可以看到,Eureka的注册表 使用了ConcurrentHashMap,它本身提供了并发安全性。
它是一个双层 Map 结构(ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>):
外层 Map - register:
key:应用名(如 ORDER-SERVER)
value:该应用的所有实例租约映射
内层 Map - gMap:
key:实例ID(如 order-server-1:8080)
value:租约信息(包含 InstanceInfo 和 租约时间)
使用 ConcurrentHashMap结构,使得多个注册操作可以并发进行,它们之间不会互相影响(因为每个服务实例的注册都是操作不同的键,即使同一个服务实例,也是先通过ConcurrentHashMap的原子操作来保证安全)
因此,Eureka Server 在注册时,使用读锁来提高注册操作的并发性能,允许同时处理多个注册请求,以及在注册时仍可以进行其他读取操作
同时,由于注册表使用了ConcurrentHashMap,它自身已经提供了足够的线程安全性,使得在并发注册时不会出现数据不一致的问题
我们继续看后续业务逻辑
租约冲突处理和自我保护阈值更新
java
// 获取应用租约信息
Lease<InstanceInfo> existingLease = gMap.get(registrant.getId());
// 已存在租约信息
if (existingLease != null && (existingLease.getHolder() != null)) {
// 获取存在的实例最后被修改的时间
Long existingLastDirtyTimestamp = existingLease.getHolder().getLastDirtyTimestamp();
// 获取要注册的服务实例最后修改时间
Long registrationLastDirtyTimestamp = registrant.getLastDirtyTimestamp();
// 比较时间戳:
// 现存的时间戳 > 新注册的时间戳 -> 保留现有数据
// 现存的时间戳 <= 新注册的时间戳 -> 使用新注册数据
// 在时间戳相等时,使用新传入的实例信息主要是因为:
// 1. 新注册的数据可能包含更新的状态(如从 STARTING 变为 UP)
// 2. 客户端时间戳更新可能滞后(时钟同步问题),优先信任新传入的数据
if (existingLastDirtyTimestamp > registrationLastDirtyTimestamp) {
registrant = existingLease.getHolder();
}
} else {
//不存在租约信息(新注册处理)
// protected final Object lock = new Object();
// 进行加锁操作, 保护非线程安全的 expectedNumberOfClientsSendingRenews (int类型)
synchronized (lock) {
// expectedNumberOfClientsSendingRenews: 预期会发送心跳的客户端数量, 新注册一个实例 → 预期心跳数 +1
if (this.expectedNumberOfClientsSendingRenews > 0) {
// 增加新注册实例(每个实例预期发送心跳)
this.expectedNumberOfClientsSendingRenews = this.expectedNumberOfClientsSendingRenews + 1;
// 重新计算自我保护触发的临界值
updateRenewsPerMinThreshold();
}
}
}上述逻辑主要负责进行 租约冲突处理与自我保护机制更新,解决了两个关键问题:
- 处理已存在的租约数据冲突
a. 若已存在租约信息,需要处理冲突(保留原有信息还是更新为新注册信息)
b. 通过比较现存信息和新注册信息的时间戳,来判断保留哪个数据
c. 现存的时间戳 > 新注册的时间戳 -> 保留现有数据
d. 现存的时间戳 < 新注册的时间戳 -> 使用新注册数据
e. 现存的时间戳 = 新注册的时间戳 -> 使用新注册数据(当时间戳相同时,信任最新收到的数据 且 新注册的数据可能包含更新的状态(如从 STARTING 变为 UP))
- 新注册时更新自我保护计数器
a. 使用 synchronized 同步块保护非线程安全的 expectedNumberOfClientsSendingRenews ,增加预期心跳数,并重新计算自我保护触发的临界值
其中的自我保护机制是什么?如何计算自我保护机制触发阈值?
在分布式系统中,网络分区 或 短暂网络故障 可能导致部分实例无法正常发送心跳。如果 Eureka Server 因此将这些实例剔除,可能会导致服务可用性降低。自我保护机制就是为了应对这种情况设计的。
当Eureka Server 在短时间 内丢失过多客户端(即心跳失败比例超过设定的阈值)时,就会触发自我保护机制,也就是满足以下条件时触发:
当前每分钟实际收到的心跳次数 < 每分钟期望心跳次数的阈值(numberOfRenewsPerMinThreshold)
当满足条件时,会进入 自我保护模式 ,此时Eureka Server不会剔除任何实例(即使某些实例没有发送心跳),也就是所有实例(包括健康和不健康的)都会被保留
而当心跳恢复 时(每分钟实际心跳次数高于阈值 ),Eureka Server 会自动退出自我保护模式
由于上述自我保护模式,在此期间,客户端可能拿到已经不健康的实例,就需要客户端具有容错机制(如重试、断路器)
对于短暂网络故障,自我保护机制能有效避免大规模实例注销;但如果是长时间故障,可能导致注册表中积累过多无效实例。
总而言之,Eureka Server 的自我保护机制能够确保在网络故障期间,Eureka Server不会错误地剔除过多实例,从而保证大多数服务仍能正常调用。这也是一种在可用性和一致性之间的权衡(AP系统)
其中,阈值的计算逻辑:
java
// 计算自我保护机制的心跳阈值,决定何时触发自我保护状态
protected void updateRenewsPerMinThreshold() {
// 阈值 = 预期客户端数 × (60 / 心跳间隔秒数) × 续约百分比阈值
this.numberOfRenewsPerMinThreshold = (int) (this.expectedNumberOfClientsSendingRenews
* (60.0 / serverConfig.getExpectedClientRenewalIntervalSeconds())
* serverConfig.getRenewalPercentThreshold());
}例如:
有 50 个实例,心跳间隔为 30 秒,阈值百分比为 85%
阈值计算:50 × (60/30) × 0.85 = 50 × 2 × 0.85 = 85
此时,需要每分钟心跳需≥85次才不会触发自我保护
租约存储与状态管理
java
// 创建服务租约对象(registrant:客户端实例信息, leaseDuration:租约持续时间)
Lease<InstanceInfo> lease = new Lease<>(registrant, leaseDuration);
// 已存在租约信息
if (existingLease != null) {
// 继承服务启动时间(实例变为 UP 状态的时间戳)
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
// 更新实例租约信息
gMap.put(registrant.getId(), lease);
// 更新最近注册队列(CircularQueue<Pair<Long, String>> recentRegisteredQueue)
recentRegisteredQueue.add(new Pair<Long, String>(
System.currentTimeMillis(),
registrant.getAppName() + "(" + registrant.getId() + ")"));
// 检查 registrant 的覆盖状态
if (!InstanceStatus.UNKNOWN.equals(registrant.getOverriddenStatus())) {
// ConcurrentMap<String, InstanceStatus> overriddenInstanceStatusMap
// 判断当前实例状态是否已存储到覆盖状态 Map 中
if (!overriddenInstanceStatusMap.containsKey(registrant.getId())) {
// 进行存储
overriddenInstanceStatusMap.put(registrant.getId(), registrant.getOverriddenStatus());
}
}
// 读取存储的覆盖状态
InstanceStatus overriddenStatusFromMap = overriddenInstanceStatusMap.get(registrant.getId());
if (overriddenStatusFromMap != null) {
// 应用覆盖状态至实例
registrant.setOverriddenStatus(overriddenStatusFromMap);
}
// 基于覆盖状态规则计算最终状态
InstanceStatus overriddenInstanceStatus = getOverriddenInstanceStatus(registrant, existingLease, isReplication);
// 设置状态但不更新 lastDirtyTimestamp, 避免服务端状态覆盖污染客户端时间戳, 保持客户端原始数据完整性
registrant.setStatusWithoutDirty(overriddenInstanceStatus);可以看到,仅当 overriddenInstanceStatusMap中不存在该实例覆盖状态时,才会存储该实例的覆盖状态
且 registrant 的覆盖状态 后续被更新为 overriddenInstanceStatusMap存储的状态,并根据覆盖状态来计算 registrant 的最终状态
那么,为什么要这样设计呢?
对于实例的状态,管理员可能通过 API 进行强制设置 (如强制下线),因此,需要保证管理员手动设置的实例状态高于客户端上报的状态
事件记录与缓存管理
java
// registrant 状态为 UP, 记录服务启动时间
if (InstanceStatus.UP.equals(registrant.getStatus())) {
lease.serviceUp();
}
// 标识本次操作是新增实例
registrant.setActionType(ActionType.ADDED);
// 更新最近变更队列
recentlyChangedQueue.add(new RecentlyChangedItem(lease));
// 设置最后更新时间
registrant.setLastUpdatedTimestamp();
// 多级缓存失效, 使缓存中相关的数据失效,确保后续请求能够获取到最新的数据
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());我们重点来看 invalidateCache 方法,它是 Eureka Server 中缓存一致性机制的核心 ,在服务注册、续约或状态变更时被调用,使缓存中相关的数据失效,确保后续请求能够获取到最新的数据,它最终调用了**invalidate()**方法:
java
// appName: 应用级缓存(按应用名称组织的实例信息缓存)失效
// vipAddress: Virtual IP地址缓存(按逻辑服务名组织的实例信息缓存)失效
// secureVipAddress: Secure VIP缓存(专用于HTTPS终端的服务发现缓存)失效
@Override
public void invalidate(String appName, @Nullable String vipAddress, @Nullable String secureVipAddress) {
// 双重循环遍历所有键类型和版本
for (Key.KeyType type : Key.KeyType.values()) {
for (Version v : Version.values()) {
// 应用相关缓存失效(6种组合)
invalidate(
// 1. 指定应用完整数据
new Key(EntityType.Application, appName, type, v, EurekaAccept.full),
// 2. 指定应用精简数据
new Key(EntityType.Application, appName, type, v, EurekaAccept.compact),
// 3. 全量应用列表完整数据
new Key(EntityType.Application, ALL_APPS, type, v, EurekaAccept.full),
// 4. 全量应用列表精简数据
new Key(EntityType.Application, ALL_APPS, type, v, EurekaAccept.compact),
// 5. 增量变更完整数据
new Key(EntityType.Application, ALL_APPS_DELTA, type, v, EurekaAccept.full),
// 6. 增量变更精简数据
new Key(EntityType.Application, ALL_APPS_DELTA, type, v, EurekaAccept.compact)
);
// VIP地址缓存失效
if (null != vipAddress) {
// 仅失效完整数据(full)
invalidate(new Key(Key.EntityType.VIP, vipAddress, type, v, EurekaAccept.full));
}
// 安全VIP缓存失效
if (null != secureVipAddress) {
// 仅失效完整数据(full)
invalidate(new Key(Key.EntityType.SVIP, secureVipAddress, type, v, EurekaAccept.full));
}
}
}
}其中相关的枚举类:
java
public class Key {
// 键类型:
// JSON: JSON格式响应
// XML: XML格式响应
public enum KeyType {
JSON, XML
}
// 实体类型
public enum EntityType {
// Application: 应用级数据
// VIP: 虚拟IP数据
// SVIP: 安全虚拟IP数据
Application, VIP, SVIP
}
}
// 版本
public enum Version {
// V1: 旧版 API
// V2: 新版 API
V1, V2;
}
// 数据格式
public enum EurekaAccept {
// full: 完整实例数据
// compact: 精简元数据(不含状态)
full, compact;
}应用完整数据键示例:
java
Key{
entityType=Application,
name="ORDER-SERVICE",
type=JSON,
version=V2,
eurekaAccept=full
}也就是说,应用实例的以下缓存都将被清除:
该应用本身的所有格式和版本的缓存
全量应用列表的缓存
增量变更信息的缓存
相关的VIP和安全VIP缓存
集群同步
在 Eureka 中,当服务实例向一个 Eureka Server 节点注册时,该节点会将注册信息同步到集群中的其他节点(peer nodes),**集群同步(peer replication)**是 Eureka 保证高可用和最终一致性的关键机制
那么,具体是如何实现集群同步的呢?
具体的同步逻辑位于 AbstractInstanceRegistry 的实现类 PeerAwareInstanceRegistryImpl中
同样找到其中的**register()**方法:
java
@Override
public void register(final InstanceInfo info, final boolean isReplication) {
// 确定租约时长
int leaseDuration = Lease.DEFAULT_DURATION_IN_SECS;
// 获取租约信息, 若 LeaseInfo 存在且 duration > 0, 使用客户端配置, 否则使用默认值(90s)
if (info.getLeaseInfo() != null && info.getLeaseInfo().getDurationInSecs() > 0) {
leaseDuration = info.getLeaseInfo().getDurationInSecs();
}
// 注册
super.register(info, leaseDuration, isReplication);
// 触发集群同步
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}我们重点来看同步逻辑replicateToPeers:
java
private void replicateToPeers(Action action, String appName, String id,
InstanceInfo info /* optional */,
InstanceStatus newStatus /* optional */, boolean isReplication) {
// 启动性能监控计时器
Stopwatch tracer = action.getTimer().start();
try {
// 复制请求计数
if (isReplication) {
numberOfReplicationsLastMin.increment();
}
// 终止条件检查, 防止循环复制
// 没有配置集群节点 或是 来自其他节点的复制请求(isReplication 标记),立即返回
if (peerEurekaNodes == Collections.EMPTY_LIST || isReplication) {
return;
}
// 遍历所有节点
for (final PeerEurekaNode node : peerEurekaNodes.getPeerEurekaNodes()) {
// 跳过自身节点
if (peerEurekaNodes.isThisMyUrl(node.getServiceUrl())) {
continue;
}
// 向节点同步
replicateInstanceActionsToPeers(action, appName, id, info, newStatus, node);
}
} finally {
// 停止计时
tracer.stop();
}
}我们继续看 replicateInstanceActionsToPeers:
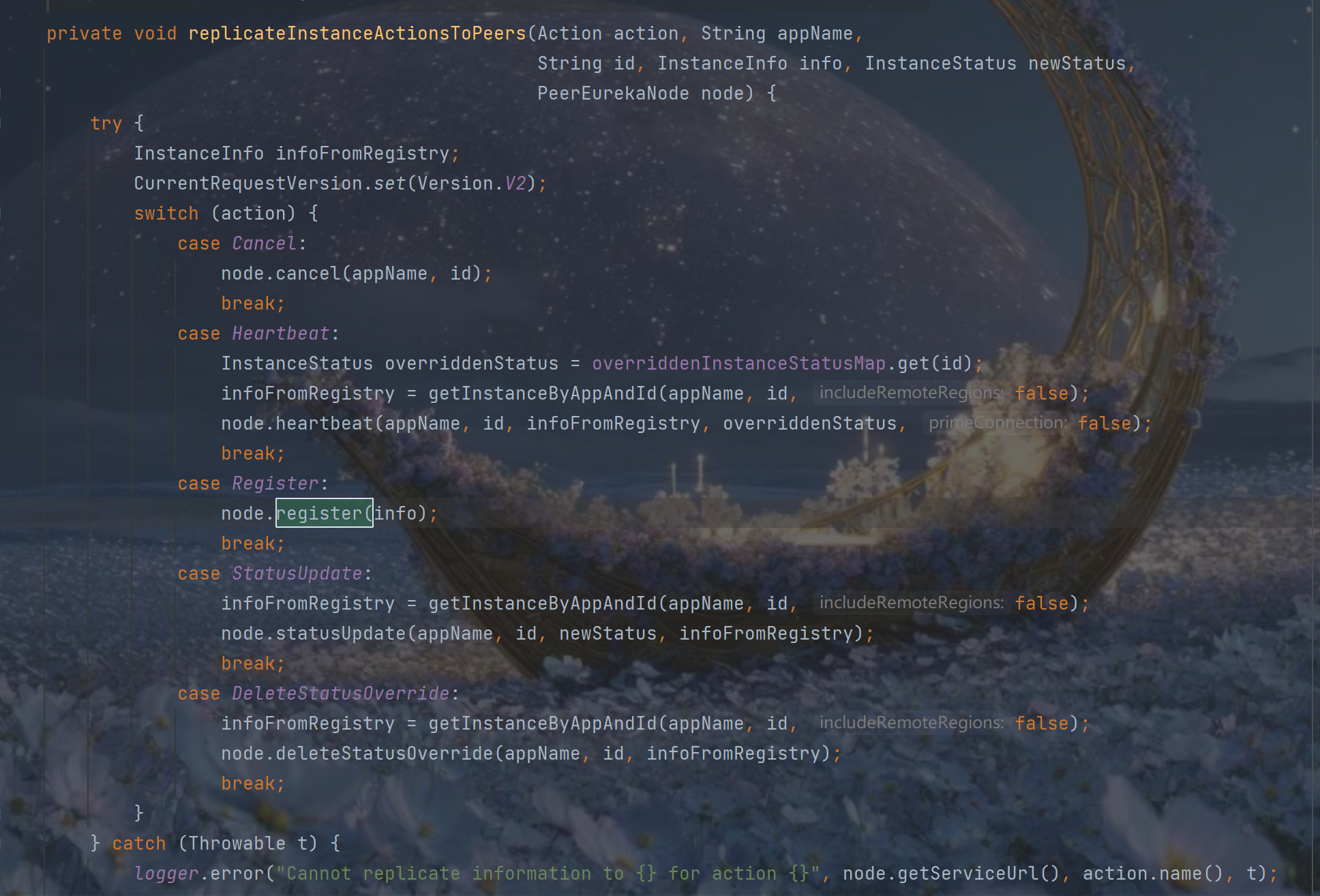
replicateInstanceActionsToPeers 根据操作类型来进行处理:
| 操作 | 触发场景 | 数据需求 |
|---|---|---|
| Cancel | 服务下线 | 仅需appName和id |
| Heartbeat | 心跳续约 | 需要实例信息+覆盖状态 |
| Register | 服务注册 | 完整实例信息 |
| StatusUpdate | 状态变更 | 实例信息+新状态 |
| DeleteStatusOverride | 删除状态覆盖 | 实例信息 |
服务注册的具体同步逻辑node.register(info):
java
public void register(final InstanceInfo info) throws Exception {
// 计算任务过期时间
long expiryTime = System.currentTimeMillis() + getLeaseRenewalOf(info);
// 创建并提交批处理任务
batchingDispatcher.process(
// 任务id
taskId("register", info),
// 任务实现
new InstanceReplicationTask(targetHost, Action.Register, info, null, true) {
public EurekaHttpResponse<Void> execute() {
// 同步注册任务
return replicationClient.register(info);
}
},
// 过期时间
expiryTime
);
}可以看到,Eureka Server 使用了一个 批处理调度器 batchingDispatcher(TaskDispatcher<String, ReplicationTask>),它负责将多个任务收集起来,然后批量发送,以减少网络开销。
在 register() 中,每个注册操作被包装成一个任务,然后交给 batchingDispatcher 处理,batchingDispatcher内部可能会将多个任务合并成一个批次,然后一次性发送
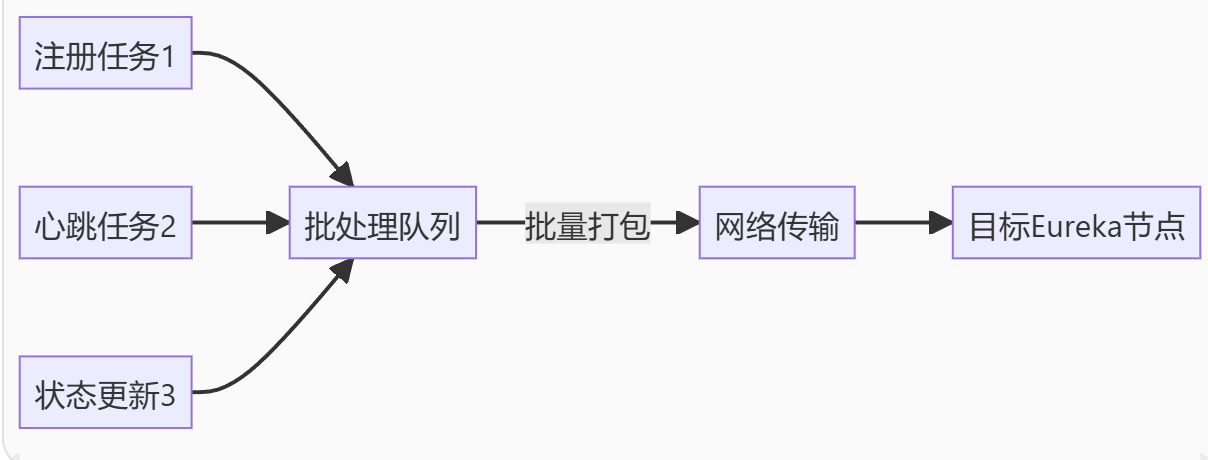
以上就是 Eureka服务注册的核心逻辑实现分析,最后,我们再来回顾一下其中的关键步骤
总结
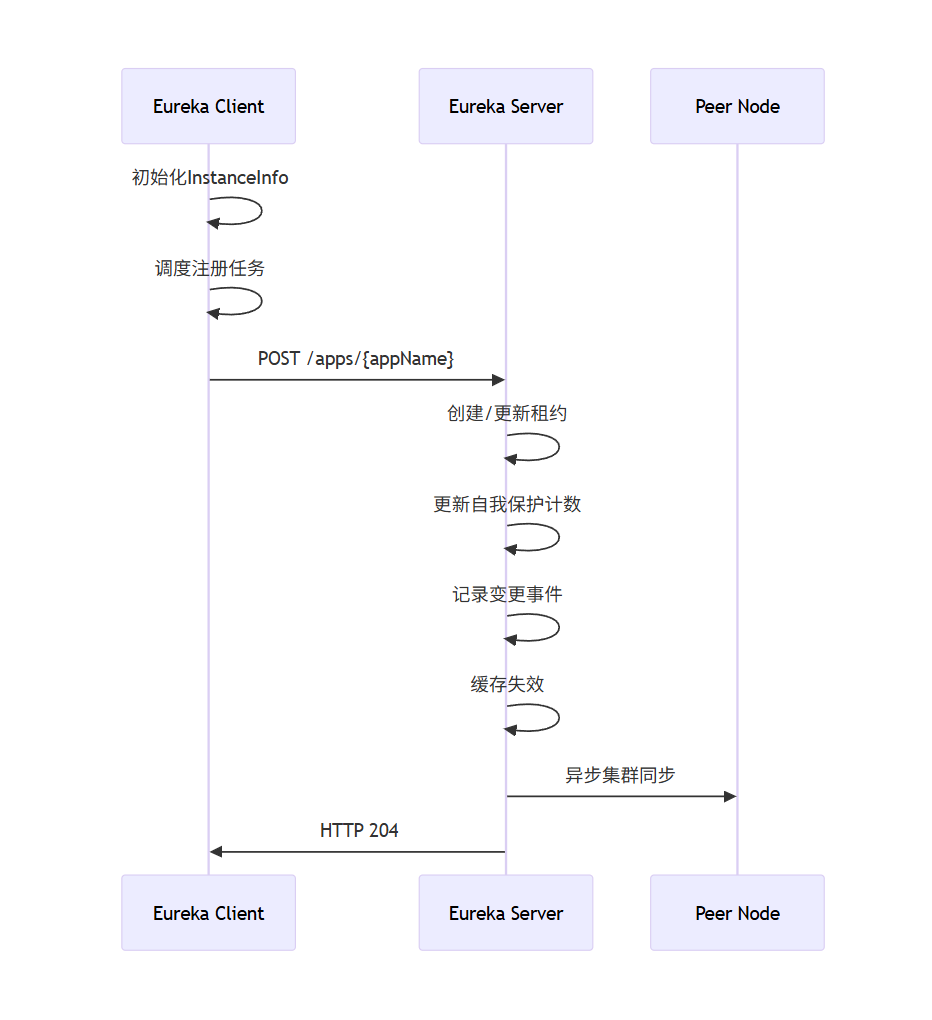
Eureka Client注册请求:
Eureka 客户端启动时,会创建 InstanceInfo对象(包含实例的元数据信息,如IP、端口L等)
通过 DiscoveryClient 类进行初始化,使用 EurekaTransport 的 registrationClient向Eureka Server发送注册请求(POST /eureka/apps/{appName})
Eureka Server注册处理:
Eureka Server内部维护了一个注册表(registry) ,它是一个双层 Map 结构:第一层key为应用名称,第二层key为实例ID,值为 Lease 对象(包含实例信息和租约信息)
根据应用名和实例ID获取现有的租约,若如果租约不存在,则创建新租约,设置租约持续时间,存放至注册表;若已存在租约信息,则处理冲突
更新自我保护机制的阈值(期望的最小续约数)
**更新对应状态(**更新租约的服务UP时间戳(如果实例状态为UP)、更新最近变更队列(用于增量拉取))并使缓存失效
如果不是复制操作(即该请求直接来自客户端,而不是其他Eureka Server节点同步过来的),则将注册事件同步到集群中的其他Eureka Server节点,同步通过向其他节点发送HTTP请求(同样是注册请求,但会带上isReplication=true的标记)
服务端返回204状态码给客户端
Eureka Client处理注册响应:
检查 HTTP 响应状态码是否为204(NO_CONTENT),判断是否注册成功
客户端启动定时任务,定期发送心跳(默认30秒一次)来续约