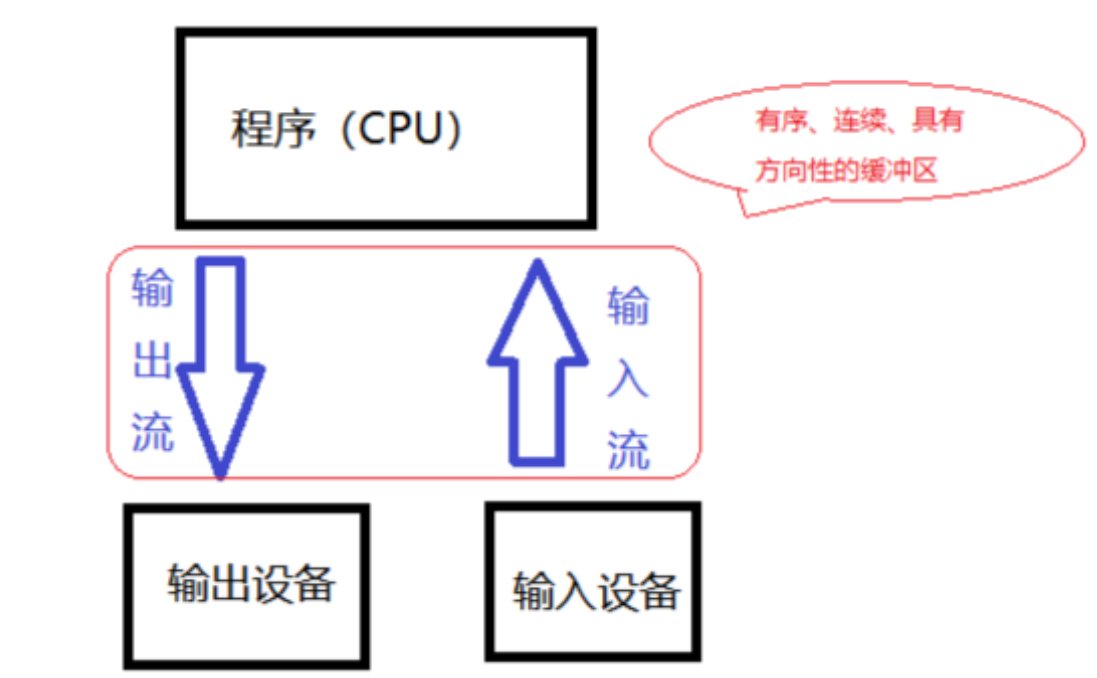
**流的概念:**C++ 中的输入与输出可以看做是一连串的数据流,输入即可视为从文件或键盘中输入程序中的一串数据流,而输出则可以视为从程序中输出一连串的数据流到显示屏或文件中。
**输入流:**从输入设备流向内存的字节序列
**输出流:**从内存流向输出设备的字节序列
cout和插入运算符<<
cout会自动解析基本数据类型。当然cout也可以格式化输出。
cin和析取运算符>>
在一条cin语句中可以同时为多个变量输入数据。 各输入数据之间用一个或多个空白作为间隔符。
cin具有自动识别数据类型的能力,析取运算符>>根据它后面的变量类型从输入流中为他们提取对应的数据。
名字空间:
在一个名字空间中,可以定义许多不同对象,并将这些对象的有效范围局限在名字空间内。不同名字空间中,可以定义相同名称的对象,只要两个同名对象不在同一名字空间中,就不会引起突。
语法格式:
namespace xxx_name{
members;
}
名字空间成员的访问有主要有三种方法:
通过作用域限定符(::)
namespace ns1{
void func(void){
cout << "ns1 func" << endl;
}
}
ns1::func();
using引用名字空间单个成员
using ns1::func;
using引用名字空间全部成员
using namespace ns1;
func();
未命名的名字空间称作无名名字空间。
namespace{
int a = 300;
}
cout << ::a<< endl;
名字空间嵌套
namespace ns1{
void func(void){
std::cout << "ns1 func" << std::endl;
}
int a = 100;
namespace ns2{
int b = 111;
}
}
cout << ns1::ns2::b << endl;
结构体
C++中定义结构型变量,可以省略struct关键字
C++结构体中可以直接定义函数,谓之成员函数(方法)
struct stu{
int age;
char name20;
void who(void){
cout <<"我是:" << name << " 我今年:" << age <<endl;
}
};
stu s1;
s1.age = 21;
strcpy(s1.name, "张飞");
s1.who();
联合
C++中定义联合体变量,可以省略union关键字
union XX{......};
XX x;//定义联合体变量直接省略union
匿名联合
union{ //匿名联合
int num;
char c4;
};
num = 0x12345678;
cout << hex << (int)c0 <<" " << (int)c1 << endl;
枚举
C++中定义枚举变量,可以省略enum关键字
C++中枚举是独立的数据类型,不能当做整型数使用
enum COLOR{RED, GREEN, BLUE};
COLOR c = GREEN;
//c = 2; //error
cout << c << endl;
布尔
C++中布尔(bool)是基本数据类型,专门表示逻辑值
true 表示逻辑真
false表示逻辑假
布尔类型的本质: 单字节的整数,使用1表示真,0表示假
bool b = true;
cout << b <<endl;
cout <<boolalpha << b <<endl;
字符串
C++兼容C中的字符串表示方法和操作函数
C++专门设计了string类型表示字符串
string类型字符串定义
string s; //定义空字符串
string s("hello");
string s = "hello";
string s = string("hello");
字符串拷贝
string s1 = "hello";
string s2 = s1;
字符串连接
string s1 = "hello", s2 = " world";
string s3 = s1 + s2;//s3:hello world
s1 += s2;//s1:hello world
字符串比较
string s1 = "hello", s2 = " world";
if(s1 == s2){ cout << "false"<< endl; }
if(s1 != s2){ cout << "true"<< endl; }
随机访问
string s = "hello";
s0 ="H"; //Hello
获取字符串长度
size_t size();
size_t length();
转换为C风格的字符串
const char* c_str();
字符串交换
void swap(string s1,string s2)
类型转换
类型转换分为隐式转换和显示转换。
隐式类型转换
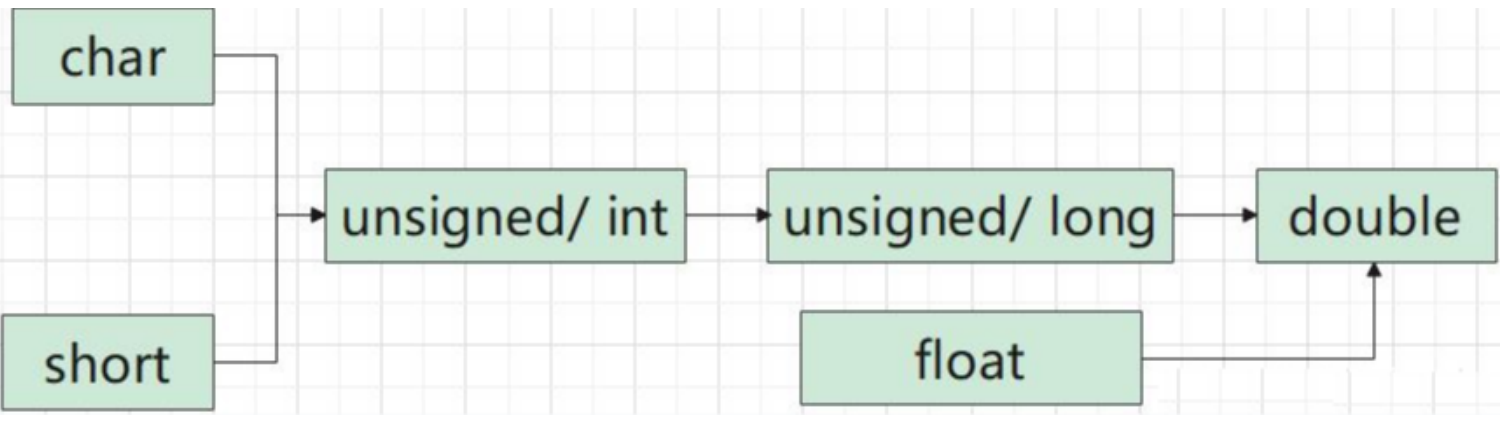
常见类型会发生隐式转换:
1.多种数据类型的算术表达式中
2.将一种数据类型赋值给另外一种数据类型变量
3.函数调用时,若实参表达式与形参的类型不相符
4.函数返回时,如果返回表达式的值与函数返回类型不同
显示类型转换
显示类型转换也称为强制类型转换,是指把一种数据类型强制转换为指定的另一种数据类型
int a = 4;
float c = (float) a; //C风格 c++也支持
float d = float(a); //C++风格 C不支持
静态类型转换 static_cast
目标类型变量 = static_cast<目标类型> (源类型变量)。
用于隐式转换的逆转换,常用于基本数据类型之间的转换、void* 转换为其它类型的指针。
不能用于整型和指针之间的互相转换 , 不能用于不同类型的指针、引用之间的转换 (风险高)。
用于自定义类型的转换(向上造型)。
重解释类型转换 reinterpret_cast
目标类型变量 = reinterpret_cast<目标类型> (源类型变量)。
用于任意类型指针或引用之间的转换。
指针和整型数之间的转换。
常类型转换 const_cast
目标类型变量 = const_cast<目标类型> (源类型变量)。
用于去除指针或引用的常属性。
动态类型转换 dynamic_cast
目标类型变量 = dynamic_cast<目标类型> (源类型变量)。
主要用于多态中类指针的向下转型,可以检测是否可以转型成功。
引用
语法格式:
类型 &引用名 = 变量名;
int &ir = i; // 给变量i起了被别名 叫ir
引用的用途:
1)简化编程, 用指针的场景可以用引用替换 (尽量减少指针的使用)
2)系统开销更小
引用必须定义时初始化
引用的本质就是指针常量
const引用(常引用)。在定义引用时一般为左值(变量)。
左值,是指变量对应的那块内存区域,是可以放在赋值符号左边的值。
右值,是指变量对应的内存区域中存储的数据值,是可以"放在赋值符号右边的值"。
可以使用const进行限制,使他成为不允许被修改的常量引用。
int &i = 3; //错误
const int &i = 3;// 正确
int a = 100;
char &c = a; //错误,将a转换char类型,转换结果保存到临时变量中,实际引用临时变量,而临时变量是右值
函数缺省参数
在C++中,函数的形参列表中的形参是可以有默认值的。有默认值的参数即为默认参数 。
在函数调用时,有默认参数可以缺省。
语法:返回值类型 函数名 (参数= 默认值){函数体}
int add(int x, int y, int z=100){
return x + y + z;
}
cout << add(1,2) << endl;
靠右原则:如果某个位置参数有默认值,那么从这个位置往后,从左向右,必须都要有默认值。
函数声明和函数实现(即函数定义),只允许其中一个有默认值,即如果函数声明有默认值,则函数实现的时候就不能有缺省参数。一般先定义后实现函数时就在声明中定义默认值,否则会报错。
哑元
只有类型而没有变量名的参数称为"哑元"。
int func(int a, int ){
...
}
需要使用哑元的场景: 兼容旧代码,保证函数的向下兼容性。
引用参数
可以将引用用于函数的参数,这时形参就是实参的别名。
引用型函数参数作用:
1.在函数中修改实参的值。
2.避免实参到形参数值复制的开销,提高传参效率。
3.引用型函数参数可能意外修改实参,如果不希望通过引用修改实参本身,可以将其声明为常引用,在提高传参效率的同时还可以接收常量型实参。
返回引用
可以将函数的返回类型声明为引用型,这时函数的返回结果就是return后面数据的别名,避免了函数返回值的开销。
函数中返回引用,一定要保证在函数返回以后,该引用的目标依然有效。
可以返回全局变量、静态变量和成员变量的引用。
可以返回引用型参数的本身。
可以返回调用对象自身的引用。
可以返回堆中动态创建对象的引用。
不能返回局部变量的引用//非常危险。
int& add(const int &a, const int &b)
{
int tmp = 0;
tmp = a + b;
return tmp; //风险 函数结束对应内存空间回收
}
函数的重载
同一作用域,函数名相同,但是的参数表必须有所区分(类型、个数、顺序),将构成重载关系。
nm命令可查看目标文件的信息(nm a.out)。
形参变量名不同,不构成重载的要素。
函数返回类型不同,不构成重载的要素。
当前g++编译器函数匹配优先级的一般规则:
1)完全匹配 //最高
2)常量转换 //较好
3)升级转换 //一般
4)降级转换 //较差
5)省略号匹配 //最差
void bar(const char c){
cout << "bar(const char)" <<endl;
}
void foo(char c){
cout << "foo(char)" << endl;
}
void foo(int i){
cout << "foo(int)" << endl;
}
void hum(int i, ...){
cout <<"hum(int, ...)" << endl;
}
void hum(int i, int j){
cout << "hum(int, int)" << endl;
}
int main(){
char c = 'A';
bar(c); //常量转换 char -----> const char
short s = 10;
foo(s); // short ----> int
hum(10, 1.23); // double -----> int 降级转换
return 0;
}
默认类型转换带来的二义性(当编译器需要升级转换时,你重载的两个函数都是升级的类型,error)
int func(unsigned int x){
return x;
}
double func(double x){
return x;
}
int n = 12;
func(n); // error
缺省参数带来的二义性
void f(int a, int b , int c=100){
}
void f(int a, int b){
}
f(1,2); // ambigous不确定的,error
内联函数
在函数声明或定义时,将inline关键字加在函数返回类型前面就是内联函数。
inline int add(int x, int y){ //内联函数
return x+y;
}
不需要建立函数调用时的运行环境,不需要进行参数传递 , 不需要跳转,效率更高。
注意:
inline关键字只是建议编译器做内联优化,编译器不一定做内联。
内联函数的声明或定义必须在函数调用之前完成。
一般几行代码适合作为内联函数, 像递归函数,包含循环,switch,goto复杂逻辑的函数不适合内联。
new和delete
new的用法:
p = new type
p = new type(x)
p = new typen
其中p是指针变量,type是数据类型。用法1 只分配内存, 用法2将分配的堆内存初始化为x,用法3分配具有n个元素的数组。分配不成功返回空指针(NULL)。
delete的用法:
delete p;
delete \[\] p;
其中p是用new分配到的堆空间指针变量。用法1用于释放动态分配的单个内存,用法2用于释放动态分配的数组存储区。