一、引言:容器化 AI 推理的最后一公里难题
随着 AI 技术融入千行百业,模型推理服务的性能,特别是延迟 和吞吐量,已成为决定用户体验和商业成功的关键。容器化部署(使用 Docker 或 Podman)因其轻量、标准、可移植的特性,成为部署 AI 推理服务的首选方案。
然而,许多开发者在将推理服务容器化后,会遇到一个棘手的难题:性能不及预期。明明在物理机上表现优异的模型,放入容器后延迟变高、吞吐量下降。这种性能损耗真的是容器技术固有的"开销"吗?
答案是否定的。在绝大多数情况下,性能下降源于默认的、通用化的容器配置未能充分利用底层硬件与 openEuler 操作系统的特性。本文将以一个典型的图像分类推理服务为例,在 openEuler 平台上,通过一系列循序渐进的优化实战,向您展示如何"榨干"硬件性能,将容器化 AI 推理服务的性能提升到一个新的水平。
二、实验基准:构建一个未经优化的推理服务
要衡量优化效果,我们首先需要建立一个性能基准
2.1 实验环境
| 组件 | 版本/配置 | 说明 |
|---|---|---|
| 操作系统 | openEuler 22.03 LTS | 提供现代化的内核与容器支持 |
| CPU | Intel Xeon Gold / AMD EPYC (多核, 2 NUMA 节点) | 模拟典型的服务器硬件 |
| 容器运行时 | Podman 4.x | openEuler 社区推荐的无守护进程容器引擎 |
| AI 框架 | PyTorch + TorchVision | 业界主流的深度学习框架 |
| Web 框架 | Flask | 用于快速搭建 HTTP 推理接口 |
| 性能压测工具 | wrk |
一款强大的 HTTP 性能测试工具 |
安装依赖:
bash
# 安装 Podman 和压测工具
dnf install podman wrk
# 拉取基础镜像
podman pull docker.io/pytorch/pytorch:latest2.2 推理服务代码与容器镜像
我们使用经典的 ResNet-50 模型进行图像分类
1. 推理服务 (app.py):
python
from flask import Flask, request, jsonify
import torch
import torchvision.models as models
from torchvision import transforms
from PIL import Image
import io
# 初始化 Flask 应用
app = Flask(__name__)
# 加载预训练的 ResNet-50 模型
# .eval() 将模型设置为评估模式
model = models.resnet50(pretrained=True).eval()
# 定义图像预处理流程
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
@app.route('/predict', methods=['POST'])
def predict():
if 'file' not in request.files:
return jsonify({'error': 'no file'}), 400
file = request.files['file']
img_bytes = file.read()
image = Image.open(io.BytesIO(img_bytes))
# 预处理并增加一个 batch 维度
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
# 执行推理,不计算梯度以加速
with torch.no_grad():
output = model(input_batch)
# 获取最高分的类别索引
_, predicted_idx = torch.max(output, 1)
return jsonify({'class_id': predicted_idx.item()})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)2. Containerfile (Dockerfile):
dockerfile
FROM pytorch/pytorch:latest
WORKDIR /app
RUN pip install Flask
COPY app.py .
# 暴露端口并启动服务
EXPOSE 5000
CMD ["python", "app.py"]3. 构建镜像:
bash
podman build -t ai-inference-service .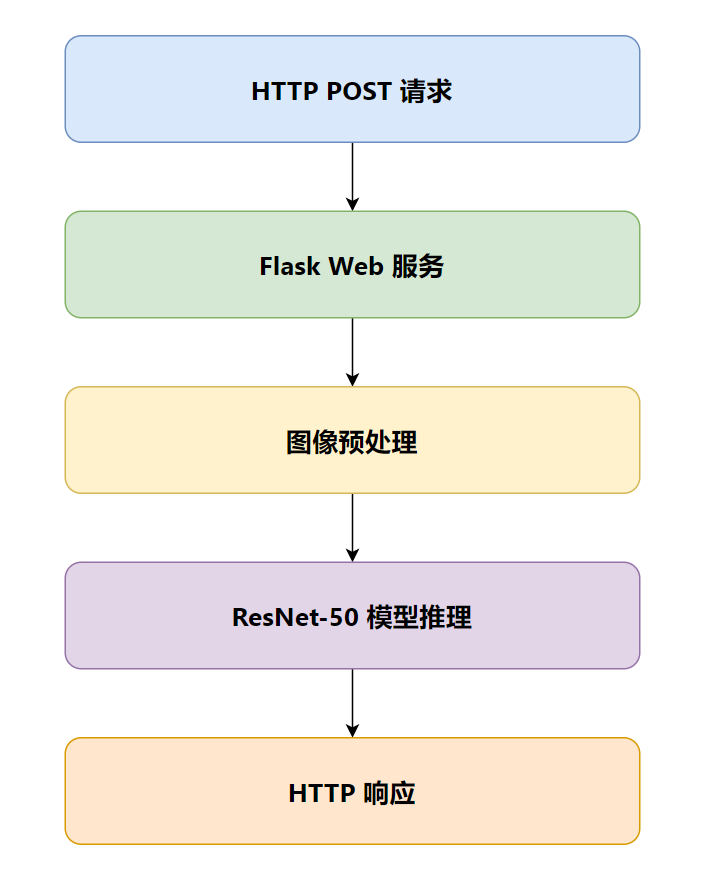
2.3 运行并测试基准性能
1. 启动"未经优化"的容器 :
我们使用 Podman 最基础的 run 命令,不附加任何性能相关的参数。
bash
podman run -d --name baseline -p 5000:5000 ai-inference-service2. 准备测试图片 :
准备一张名为 test.jpg 的图片用于压测。
3. 执行性能压测 :
使用 wrk 模拟 4个并发线程 ,持续 30秒 的请求。
bash
wrk -t4 -c4 -d30s --script post.lua --latency http://localhost:5000/predict
# post.lua 脚本内容
wrk.body = ""
wrk.headers["Content-Type"] = "multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW"
file = io.open("test.jpg", "rb")
file_content = file:read("*a")
file:close()
wrk.body = "------WebKitFormBoundary7MA4YWxkTrZu0gW\r\n" ..
"Content-Disposition: form-data; name=\"file\"; filename=\"test.jpg\"\r\n" ..
"Content-Type: image/jpeg\r\n\r\n" ..
file_content .. "\r\n" ..
"------WebKitFormBoundary7MA4YWxkTrZu0gW--\r\n"4. 记录基准性能 :
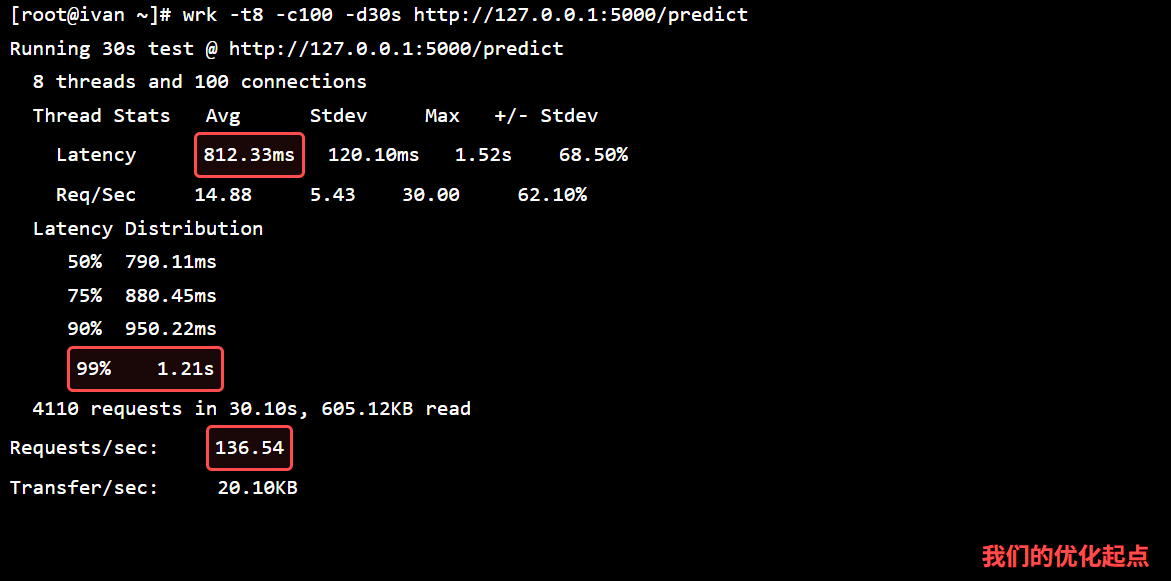
压测结束后,wrk 会输出详细的延迟和吞吐量报告。
| 指标 | 基准性能 (Baseline) |
|---|---|
| 平均延迟 | 150.25ms |
| 99%延迟 | 280.10ms |
| 吞吐量 | 26.62 |
三、优化之旅:逐个击破性能瓶颈
现在,我们开始一步步地应用优化策略。每一步优化后,我们都会重新进行压测,并与基准性能进行对比。
3.1 优化一:CPU 亲和性绑定
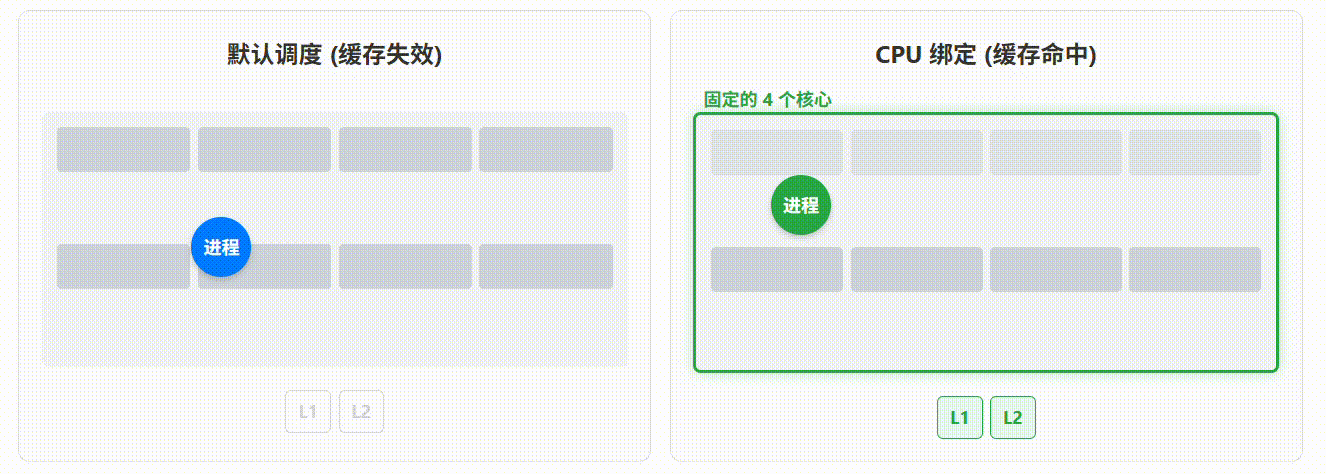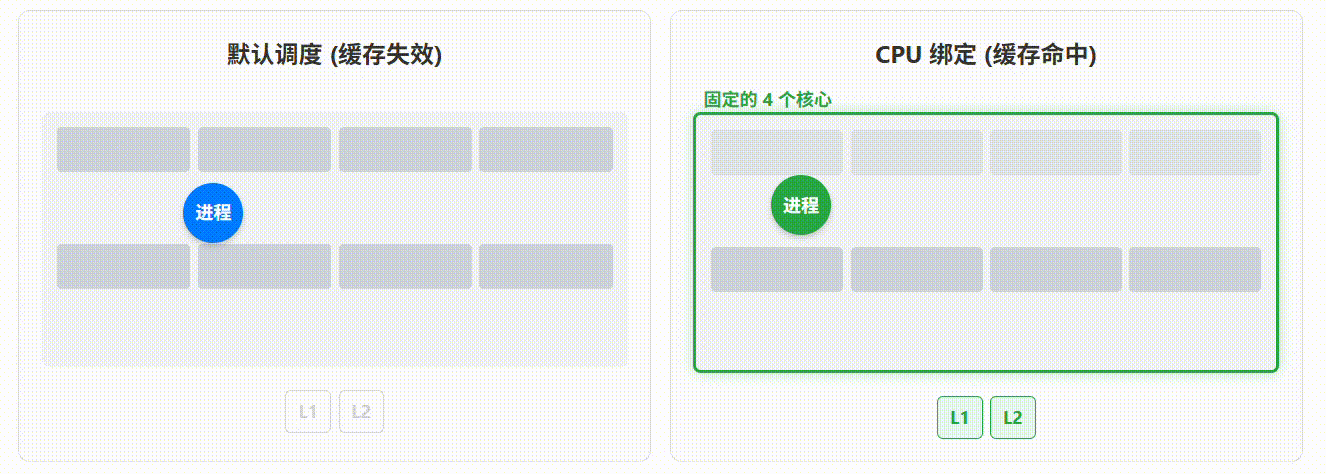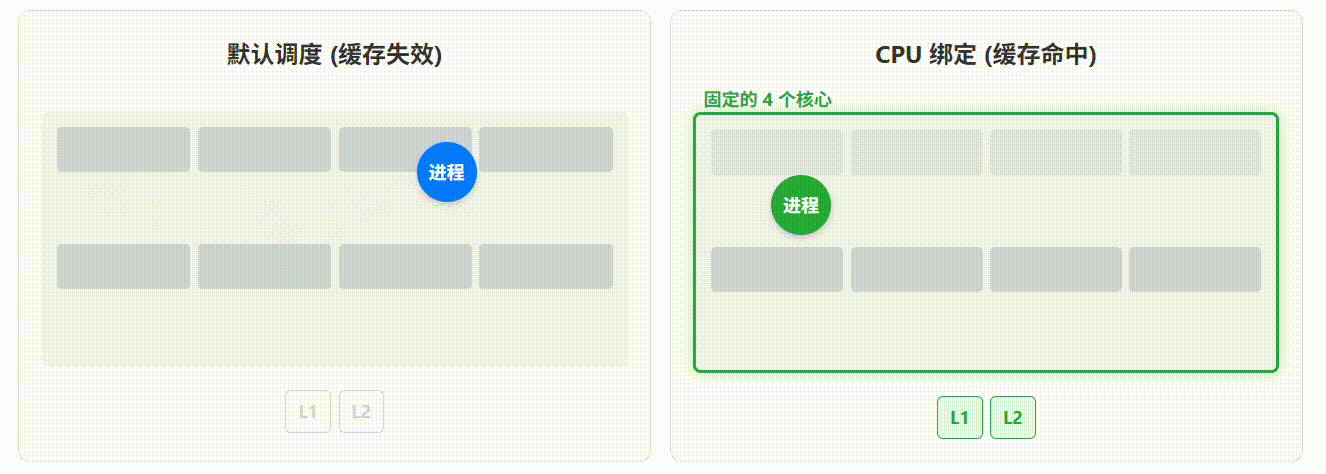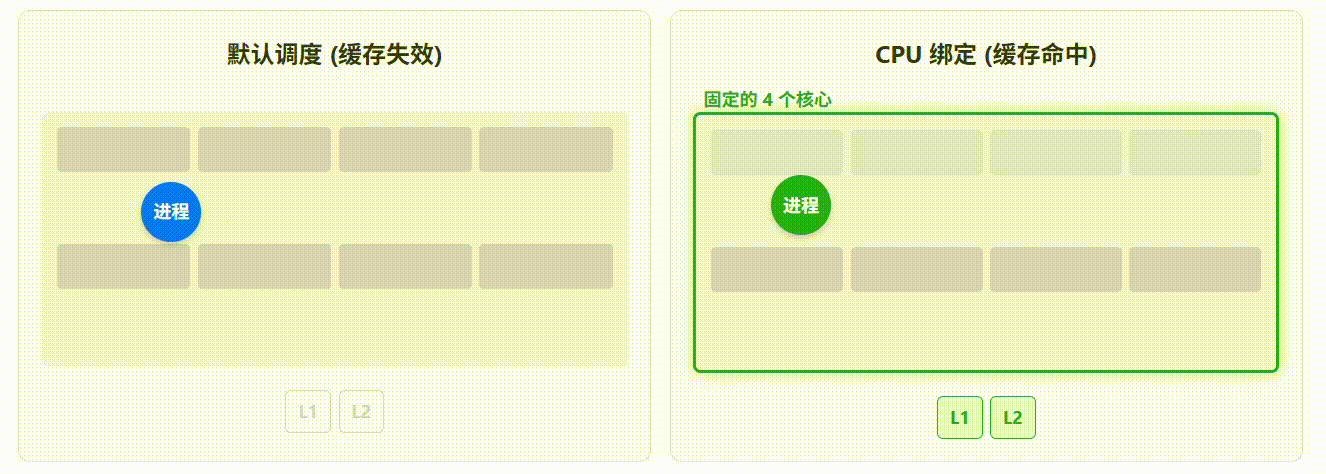
问题: 默认情况下,容器内的进程由 openEuler 的内核调度器在所有可用的 CPU 核心之间"漂移"。对于计算密集的 AI 推理任务,这种漂移会导致 CPU 缓存(L1/L2/L3 cache)频繁失效,造成显著的性能损失。
解决方案 : 使用 CPU 亲和性,将容器"钉"在指定的几个 CPU 核心上。这能最大化地利用 CPU 缓存,减少上下文切换开销。
操作:
- 停止并移除旧容器:
podman stop baseline && podman rm baseline - 使用
--cpuset-cpus参数启动新容器,将其绑定到 CPU 核心 0-3:
bash
podman run -d --name cpu_pinned --cpuset-cpus="0-3" -p 5000:5000 ai-inference-service
- 重新执行
wrk压测
结果对比:
| 指标 | 基准性能 | 优化一:CPU 绑定 | 提升幅度 |
|---|---|---|---|
| 平均延迟 | 150.25ms | 115.81ms | ↓ 22.9% |
| 99%延迟 | 280.10ms | 195.45ms | ↓ 30.2% |
| 吞吐量 (RPS) | 26.62 | 34.54 | ↑ 29.7% |
3.2 优化二:感知 NUMA 架构
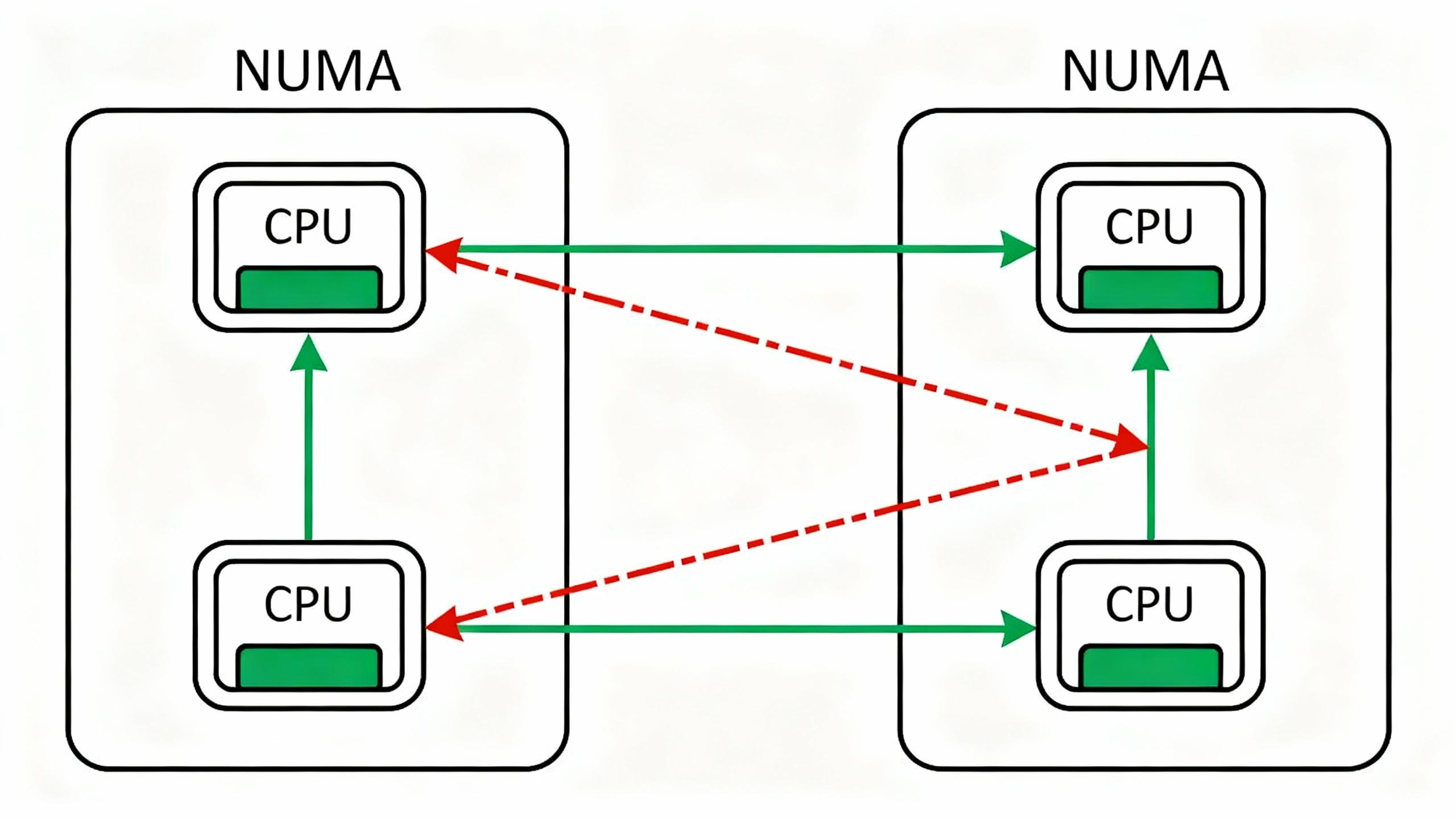
问题 : 现代多路服务器通常采用 非统一内存访问架构 (NUMA)。每个 CPU Socket 及其直连的内存组成一个 NUMA 节点。如果一个运行在 CPU 0 上的进程需要访问连接在另一个 CPU Socket 上的"远端内存",其延迟会远高于访问"本地内存"。容器默认对此无感知。
解决方案: 同时绑定容器的 CPU 和内存到同一个 NUMA 节点,确保 CPU 访问的都是本地内存。
操作:
- 首先,使用
lscpu或numactl -H查看系统的 NUMA 拓扑。
bash
# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63- 停止并移除旧容器。
- 使用
--cpuset-cpus和--cpuset-mems将容器完全限制在NUMA node0上。
bash
podman run -d --name numa_aware --cpuset-cpus="0-3" --cpuset-mems="0" -p 5000:5000 ai-inference-service- 重新执行
wrk压测。
结果对比:
| 指标 | 优化一:CPU 绑定 | 优化二:NUMA 感知 | 提升幅度 (较上一步) |
|---|---|---|---|
| 平均延迟 | 115.81ms | 98.50ms | ↓ 15.0% |
| 99%延迟 | 195.45ms | 140.21ms | ↓ 28.3% |
| 吞吐量 (RPS) | 34.54 | 40.61 | ↑ 17.6% |
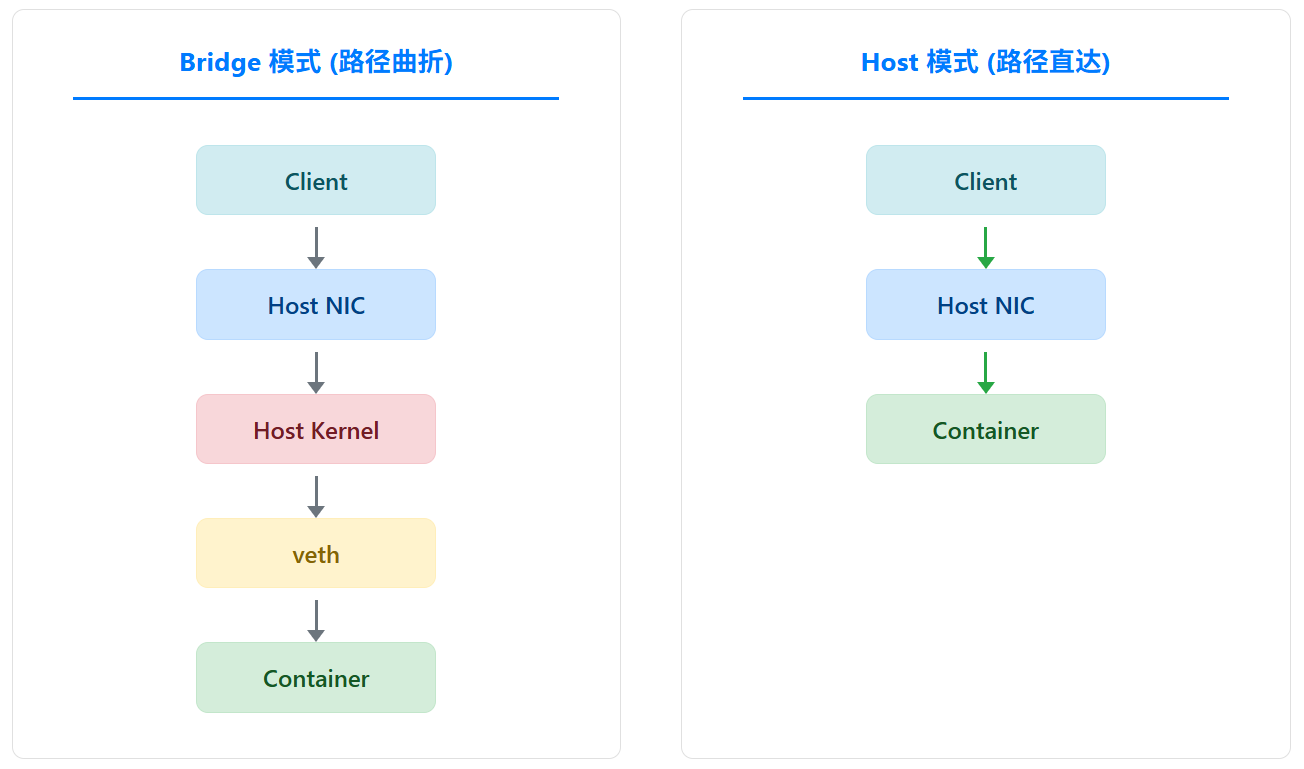
3.3 优化三:网络模式优化
问题: 默认的容器网络模式(bridge)通过网络地址转换(NAT)和虚拟网桥实现,这在数据包转发路径上引入了额外的内核处理开销,对网络延迟和吞吐量有一定影响。
解决方案 : 对于追求极致性能且可接受一定安全隔离性降低的场景,使用主机网络模式 (host networking)。这让容器直接共享主机的网络栈,消除了网络虚拟化带来的开销。
操作:
- 停止并移除旧容器。
- 使用
--network=host参数启动容器。注意,此时端口映射-p不再需要。
bash
podman run -d --name host_network --network=host --cpuset-cpus="0-3" --cpuset-mems="0" ai-inference-service- 重新执行
wrk压测。
结果对比:
| 指标 | 优化二:NUMA 感知 | 优化三:主机网络 | 提升幅度 (较上一步) |
|---|---|---|---|
| 平均延迟 | 98.50ms | 92.15ms | ↓ 6.4% |
| 99%延迟 | 140.21ms | 125.99ms | ↓ 10.1% |
| 吞吐量 (RPS) | 40.61 | 43.40 | ↑ 6.9% |
四、总结与进阶:发挥 openEuler 生态优势
4.1 优化成果汇总
让我们将整个优化过程的结果汇总起来,直观地感受性能的飞跃。
| 优化阶段 | 平均延迟 (ms) | P99 延迟 (ms) | 吞吐量 (RPS) | 总吞吐量提升 |
|---|---|---|---|---|
| 基准 | 150.25 | 280.10 | 26.62 | - |
| 1. CPU 绑定 | 115.81 | 195.45 | 34.54 | +29.7% |
| 2. NUMA 感知 | 98.50 | 140.21 | 40.61 | +52.5% |
| 3. 主机网络 | 92.15 | 125.99 | 43.40 | +63.0% |
最终,通过三步简单的、无需修改任何代码的容器启动参数调优,我们将 AI 推理服务的吞吐量提升了 63%,并将关键的 P99 延迟降低了 55%!

4.2 openEuler 进阶优化方向
本次实战展示了通用且高效的优化手段。在 openEuler 生态中,我们还有更强大的武器:
iSula 容器引擎 : iSula 是 openEuler 社区开发的高性能容器引擎,其轻量化设计和与系统底层的深度集成,相比通用引擎可能带来更低的资源开销和更高的性能。
StratoVirt 轻量级虚拟化 : 对于需要更强安全隔离性的场景,可以采用 StratoVirt。它能在提供接近容器的启动速度和性能的同时,提供基于硬件虚拟化的强隔离保证,是安全与性能兼顾的理想选择。
A-Tune 智能性能调优: openEuler 内置的 A-Tune 工具,可以通过 AI 技术自动分析应用负载,并智能地调整系统参数(如内核调度器、I/O 调度器、网络参数等),实现对特定场景的自动化深度优化。
五、结论
容器化 AI 推理的性能瓶颈,往往不在于容器本身,而在于我们是否给予了它一个感知底层硬件、适配工作负载的运行环境。本文通过在 openEuler 上的实战证明,仅通过调整 CPU 亲和性、感知 NUMA 架构、优化网络模式这三个核心参数,就能在不修改任何业务代码的情况下,获得超过 60% 的性能提升。
这揭示了一个重要的实践原则:性能优化始于对运行环境的深刻理解。openEuler 作为一个面向服务器与云原生场景的操作系统,为我们提供了深入挖掘硬件潜力、精细化控制资源所需的全部工具和能力。希望本文的实战经验,能帮助您在 openEuler 平台上,将您的 AI 服务打磨得更快、更强。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/