思考,输出,沉淀。用通俗的语言陈述技术,让自己和他人都有所收获。
作者:毅航😜
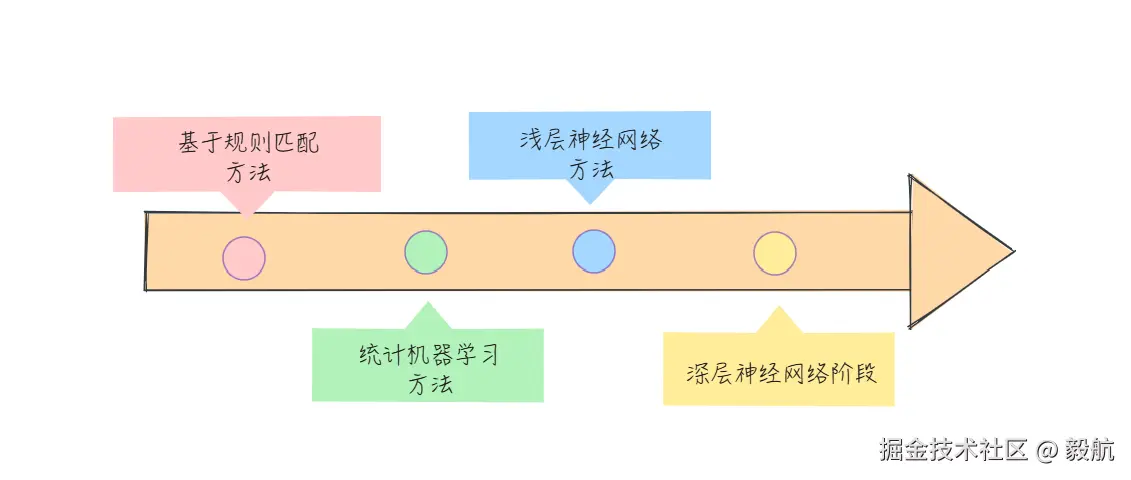
从基于人工规则的 "照本宣科",到统计机器学习的 "概率匹配",再到浅层神经网络的 "初步语义捕捉",最终抵达深层神经网络的 "通透理解与生成",
NLP的发展历程,本质是一场 "让机器从'看懂文字'到'读懂世界'" 的持续进化。
前言
AI 技术的兴起,正在深刻改变程序员的工作方式。
如今,我们不必再深陷于繁琐的脚本编写、晦涩的底层接口与复杂的环境配置,只需通过自然对话,就能借助AI高效完成各类开发任务。
有时,我们常心安理得地享受技术带来的便利,却很少去追问它从何演变而来。
事实上,NLP 的发展并非一蹴而就,其背后的理论体系与技术脉络层层递进、相互环环相扣。
接下来的内容里,我们将系统梳理自然语言处理的完整发展历程。读懂这条脉络,你将理解NLP的发展之路,并对自然语言处理建立起更深刻、更通透的认知。
现代自然语言处理:从规则到统计
自然语言处理(Natural Language Processing, NLP)作为人工智能的核心子领域,其核心目标是让计算机具备理解、解释与生成人类语言的能力。
在阅读之前,大家不妨先思考一个基础问题:人与人之间的沟通,依赖的什么?
回顾历史你会发现,其实人类最早的交流并非始于文字,而是依靠语音。
同一部落、族群能够顺畅沟通,关键在于他们共用一套稳定的语义与发音约定。
这一点和编程高度相似:只有先达成统一的语法、格式与行为约定,信息才能被准确解析与传递,没有标准,沟通便无从谈起。
换句话说:先有统一的语言标准,才有大规模的知识传递与协作。
这与我们今天强调统一编程范式、编码规范、接口标准,底层逻辑完全一致。
从编程语言的语法、词法、类型系统,到团队的编码规范、接口契约、数据交换格式,再到操作系统层面的二进制接口、调用约定,本质都是在构建一套通用、可互理解、可稳定协作的 "技术通用语" 。
语言为信息沟通提供了载体,但仅有载体还远远不够。一次完整的信息传递,还离不开通道中的编码与解码机制。
一个只说英语的人和一个不懂英语的人,即便都使用语言,也因无法互相解码而无法交流。同理,计算机也不能直接理解人类自然语言,核心正是缺少这套编码与解码过程。
因此,要让计算机理解人类语言,就必须对自然语言进行结构化编码,将其转换为计算机可识别、可处理的形式。而这一编码、传输、解码的核心流程,正是 NLP 要解决的根本问题。
NLP的发展历程
既然编码与解码是计算机理解人类语言的关键,那如果能让计算机深度理解语言背后的语义与意图,是不是就能真正实现人机之间的畅快沟通了?
而NLP的本质就是为人类语言建立一套高效的编码与解码体系。
只有让计算机真正 "读懂" 语言、理解语义,它才具备承接复杂任务的基础,进而完成那些原本只有人类才能胜任的决策、创作与协作类工作。
1.基于规则的方法。
早在 20 世纪 50 年代,当计算机科学和人工智能刚刚兴起的时候,自然语言处理的研究领域就出现了用语言学家制定的规则来书写程序,从而完成语言理解和机器翻译等任务。
比如想让机器翻译:
我喜欢吃苹果。
人们就手写规则:
- 我 → I
- 喜欢 → like
- 吃 → eat
- 苹果 → apple
- 主谓宾顺序调整
机器就能输出:
I like eating apples.
那时候的程序包含很多条件语句,它们都是属于基于规则的系统。然而自然语言充满了歧义性,同样一个词可能有不同的意思,同样一个短语可能表达不同的看法,这些歧义性给语言学家书写规则提出了很大的挑战。
例如,"小红告诉小丽,她的书包丢了",对于这个表达,其实我们大致有如下两种理解:
- 理解 1:小红的书包丢了
- 理解 2:小丽的书包丢了
谁的书包?只看文字永远分不清,必须看上下文语境。
因此很少有套规则系统能够解决所有的歧义性。
2. 统计机器学习方法阶段
后来,随着互联网的兴起,海量文本数据开始涌现,自然语言处理领域逐渐抛弃了纯人工编写规则的思路,转向了基于统计机器学习的方法。
这一阶段的核心逻辑是:不依赖语言学家制定的固定规则,而是让模型从大规模标注文本中自动学习语言规律,通过统计概率来解决歧义、分类、翻译等任务。
主流的方法除了朴素贝叶斯、支持向量机(SVM)、隐马尔可夫模型(HMM)外,词统计算法是核心基础。
其中 N-Gram、TF-IDF、互信息等算法尤为关键,它们通过捕捉词语的统计特征,为后续模型提供了核心输入。
N-Gram
先说说最基础的N-Gram 算法 :它的核心思想是 "通过相邻词语的共现概率判断语义合理性"。
这里的 N 表示连续词语的数量。例如:
- 2‑Gram(二元语法) :根据前 1 个词预测下一个词
- 3‑Gram(三元语法) :根据前 2 个词预测下一个词
为了让你直观理解它的工作过程,我们不妨构造一个极小的语料库 来详细说明N-Gram 的统计逻辑。
首先,假设我们的训练语料只有以下 3 个句子:
- 我 喜欢 吃 苹果
- 我 喜欢 吃 香蕉
- 我 喜欢 喝 牛奶
我们先从中统计出连续词语的出现次数:
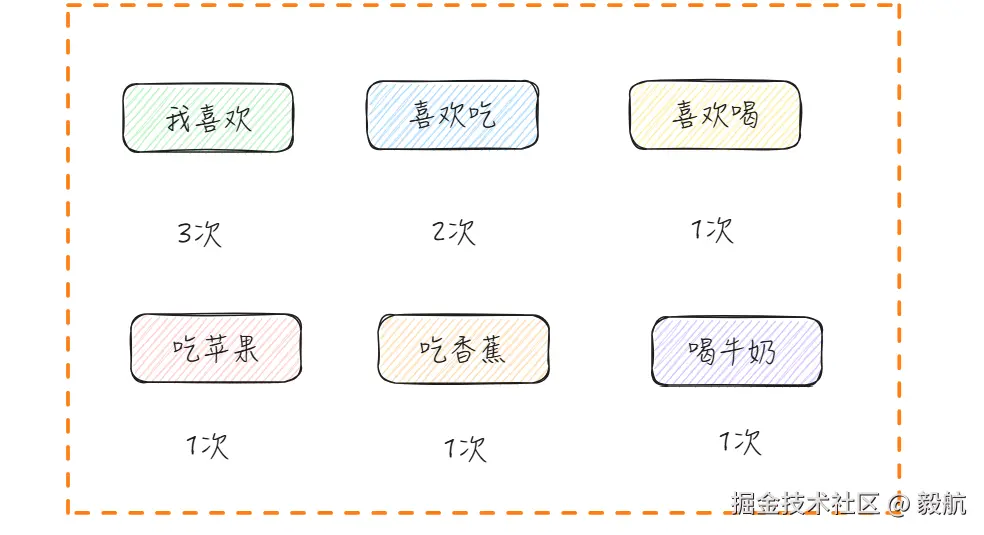
3‑Gram 的概率可以用下面的思路计算:在看到前两个词的前提下,第三个词出现的概率 = 这三个词一起出现的次数 ÷ 前两个词出现的次数。
代入我们的小语料,就能得到真实概率:
- P (吃 | 我,喜欢) = 2/3
- P (喝 | 我,喜欢) = 1/3
- P (苹果 | 喜欢,吃) = 1/2
- P (香蕉 | 喜欢,吃) = 1/2
- P (牛奶 | 喜欢,喝) = 1
有了这些概率,模型就可以真正 "预测" 和 "判断" 了。
比如输入 "我 喜欢" ,模型会预测:下一个词是 吃 的概率更高。
再比如,我们让模型判断两句话:
- 我 喜欢 吃 苹果
- 我 吃 喜欢 苹果
对第一句,每一步的概率都很高,模型认为通顺合理 ;对第二句,"我 吃""吃 喜欢" 在语料中几乎不存在,概率接近 0,模型判定极不通顺。
这就是 N‑Gram 的核心价值:不靠人工编写语法规则,只靠统计概率,就能完成下一词预测、句子通顺度判断、文本自动补全等任务。它也是早期机器翻译、语音识别、拼写纠错等系统的重要基础。
TF-IDF
再看TF-IDF 算法:它主要解决 "词语在文本中的重要性" 问题 。TF-IDF由两部分组成 ------TF(词频)指一个词在当前文本中出现的次数,IDF(逆文档频率)指这个词在所有文本中出现的稀缺程度。
比如,在新闻分类任务中,"的、是、在" 这类高频词 TF 高但 IDF 低,重要性低;而 "人工智能""量子计算" 这类词在科技新闻中 TF 高、在娱乐新闻中极少出现(IDF 高)。
进一步,垃圾邮件过滤也依赖 TF-IDF。例如,"发票""转账""中奖" 在垃圾邮件中 TF 高且在正常邮件中 IDF 高,自然成为判断垃圾邮件的关键指标。 而且
但统计机器学习方法的局限性也十分明显:一方面,它依赖人工选择的统计特征(比如要手动决定用 N-Gram 还是 TF-IDF),无法自动捕捉深层语义。
另一方面,这些算法本质是 "基于词语表面的概率匹配",完全不懂语义关联。
例如,面对句子 "这部电影好看到让我哭了,可惜结局烂尾到想吐" 。TF-IDF 会提取 "好看"、"哭"、"烂尾"、"想吐" 等关键词,统计模型因 "好看""哭" 的正面词频略高,误判为正面情感,却无法理解 "可惜" 带来的语义转折;
再比,如翻译任务中,N-Gram 能处理 "我吃苹果" 这类简单句式,但遇到 "他打破了世界纪录" 时,因 "打破 + 纪录" 的互信息值未覆盖隐喻用法,会直译成 "他把世界纪录打碎了",完全忽略语言的深层含义。
N-Gram 则无法处理长距离依赖。例如,面对 "小明告诉小红,她昨天买的书很好看",2-Gram 只能捕捉 "小红 + 她" 的相邻关联,却无法判断 "她" 指代的是小红而非小明,这也暴露了统计方法 "只看字面搭配、不悟语义内涵" 的核心短板。
3. 浅层神经网络阶段
进入 21 世纪初,随着计算能力的提升和神经网络理论的复苏,NLP 领域迎来了浅层神经网络时代。
此时,不再依赖人工设计统计特征(比如 N-Gram、TF-IDF),而是让模型通过简单的神经网络结构自动提取语言特征;
同时, "词嵌入(Word Embedding)" 技术的引入,将原本孤立的词语转化为低维稠密向量,让意思相近的词在向量空间中距离更近,从而首次实现了对 "语义关联" 的捕捉。
一般来看,主流模型包括循环神经网络(RNN)、长短期记忆网络(LSTM)等。
一般来看,浅层神经网络的核心逻辑是:
- 词嵌入:把每个词变成固定长度的向量(比如 3 维),向量值通过数据学习得到;
- 序列建模:用 RNN/LSTM 按顺序处理词语向量,每一步都结合 "当前词信息 + 之前的记忆信息";
- 输出预测:通过最后一层网络输出结果(比如判断句子情感、预测下一个词)。
接下来,我们通过一个 LSTM 模型判断句子是 "正面" 还是 "负面"的 例子,来全程拆解推演过程。
假设我们现在有一个3 个词:喜欢,讨厌,苹果的词表,同时 词嵌入后得到 的向量如下:
css
- 喜欢 = [0.9, 0.1, 0.2](正面情感相关)
- 讨厌 = [0.1, 0.9, 0.3](负面情感相关)
- 苹果 = [0.3, 0.2, 0.8](中性名词)-
LSTM 隐藏层维度:2 维,激活函数用 tanh(输出范围 -1,1)
-
输出层:1 个神经元,输出 > 0 为正面,<0 为负面
(注:假设向量维度为3维)
此时,输入句子"我喜欢吃苹果",句子分词后为 喜欢,苹果,对应的向量为:
- 喜欢:0.9, 0.1, 0.2
- 苹果:0.3, 0.2, 0.8
-
LSTM 第一层(处理 "喜欢") :LSTM 接收 "喜欢" 的向量,结合初始记忆(全 0 向量),经过线性变换和 tanh 激活后,得到隐藏层输出(记忆信息):隐藏层 1 = 0.85, 0.12(正面信息占比高)
-
LSTM 第二层(处理 "苹果") :接收 "苹果" 的向量,结合上一步的记忆 0.85, 0.12,再次计算:隐藏层 2 = 0.82, 0.15(依然保留强烈的正面信息)
-
输出层计算 :隐藏层 2 的向量传入输出层,经过简单线性变换(比如权重 0.9, 0.1,偏置 0.05)。输出值 = 0.82×0.9 + 0.15×0.1 + 0.05 = 0.738 + 0.015 + 0.05 = 0.803 > 0模型判定:正面情感
4. 深层神经网络阶段
2017 年,Transformer 模型的诞生标志着 NLP 正式进入深层神经网络阶段。这一阶段的核心突破是:采用 "自注意力机制",让模型能同时关注输入文本的所有位置,高效捕捉长距离语义依赖。
同时,通过 "预训练 + 微调" 的范式,在海量无标注文本上预先训练出通用语言模型,再针对具体任务进行微调,从而具备强大的泛化能力。
深层神经网络的层数可达数十层甚至上百层,能逐层提取从浅层到深层的语义特征,从词语、短语、句子结构到篇章逻辑,全方位捕捉语言的复杂关联。
换言之,深层神经网络的出现,让 NLP 真正实现了从 "处理语言" 到 "理解语言" 再到 "生成语言" 的跨越。
总结
从基于人工规则的 "照本宣科",到统计机器学习的 "概率匹配",再到浅层神经网络的 "初步语义捕捉",最终抵达深层神经网络的 "通透理解与生成",NLP 的发展历程,本质是一场 "让机器从'看懂文字'到'读懂世界'" 的持续进化。
重新回顾这段发展脉络,不仅能让我们看清技术的过去与现在,更能让我们在 AI时代,以更理性、更深刻的视角,拥抱技术带来的无限可能。