车牌识别技术:从深度学习到产业应用的全面解析
车牌识别(License Plate Recognition, LPR)作为计算机视觉领域的一项经典任务,已从早期的图像处理算法发展到如今以深度学习为核心的技术体系。它不仅广泛应用于高速公路收费站、停车场管理、违章抓拍等智能交通场景,更成为智慧城市感知层的关键技术之一。本文将深入剖析当前车牌识别的主流技术方案、发展趋势以及工业界的实践应用。
一、核心技术框架:检测、矫正与识别的三部曲
现代车牌识别系统通常遵循一个标准且高效的流程链:首先定位车辆图像中的车牌位置,然后对定位到的倾斜或透视变形的车牌进行几何校正,最后对校正后的车牌图像进行字符识别 。下图清晰地描绘了这一核心流程:
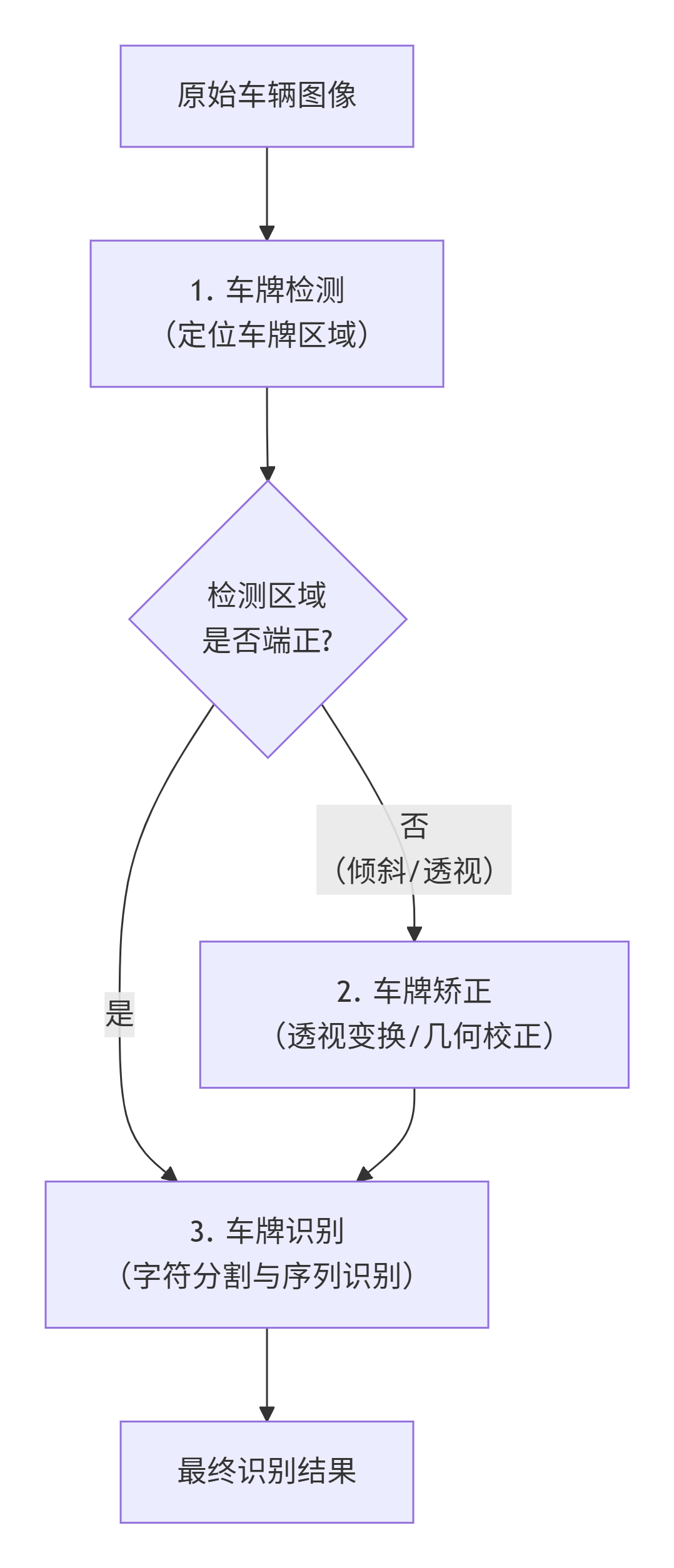
1. 车牌检测:从YOLO到大模型的演进
车牌检测的目标是从复杂背景中精确找出车牌区域,是后续所有步骤的基础。
-
以YOLO为代表的单阶段检测器:目前工业界的首选方案,因其极佳的"速度-精度"平衡。从YOLOv5到最新的v11版本,模型通过更高效的网络结构(如CSPNet)、更强大的特征金字塔(如PANet)以及更先进的训练策略,持续提升对极小、模糊或部分遮挡车牌的检测能力。其轻量化版本(如YOLOv5s)可轻松部署至前端摄像头或边缘计算设备,实现实时处理。
-
新兴的视觉大模型 :针对传统算法难以解决的长尾问题 (如严重污损、极端光照、异形车牌),以大参数模型(如"梧桐"大模型)为代表的新方案展现出强大的场景泛化 和零样本/小样本学习能力。它们通过在海量多源数据上预训练,获得对车辆和车牌的深刻理解,能在极少针对性训练数据的情况下,出色地完成复杂场景下的检测任务,代表了技术发展的前沿方向。
2. 车牌矫正:几何变换的妙用
检测出的车牌常因拍摄角度问题产生透视变形或倾斜。透视变换是解决此问题的标准方法。通过定位车牌的四个角点,计算出一个将车牌区域"拉正"为规则矩形的最优变换矩阵,从而为字符识别提供规范的输入,显著提升识别率。
3. 车牌识别:从CRNN到端到端的优化
字符识别是整个流程的最终输出环节,技术路线已从早期的字符分割后单独识别,发展为更鲁棒的序列识别。
- CRNN(卷积循环神经网络) :经典且广受认可的方案。它结合了CNN(提取图像特征) 、RNN(学习字符序列间的上下文关系) 和CTC损失函数(解决序列对齐问题),能够直接处理不定长的车牌字符序列,避免了繁琐且易错的分割步骤。
- LPRNet:为车牌识别量身定制的轻量级全卷积网络。它摒弃了RNN结构,推理速度更快,在嵌入式设备上表现优异,是高性能嵌入式应用(如智能门禁、手持终端)的理想选择。
- 通用OCR工具的融合 :以百度PaddleOCR 为代表的开源OCR工具包,因其强大的泛化能力、对多语言的支持和活跃的社区,常被用于构建车牌识别系统或作为基线方案。而OpenAI最新推出的GPT-4o Mini等通用视觉-语言模型,也展示了在无需专门训练的情况下,通过自然语言指令完成车牌识别的潜力,为技术路径提供了新思路。
为了方便对比,我们将上述关键环节的主流技术方案总结如下:
| 技术环节 | 主流方案/模型 | 核心特点与优势 | 典型应用/备注 |
|---|---|---|---|
| 🚗 车牌检测 | YOLO系列 (v5, v8, v11等) | 速度与精度兼备,生态完善,轻量化版本适合边缘部署。 | 工业界实时系统的中流砥柱。 |
| 视觉大模型 (如"梧桐") | 强大的泛化与复杂场景理解能力,解决传统模型的长尾问题。 | 应对极端场景的未来方向。 | |
| 🔄 图像矫正 | 透视变换 | 数学模型成熟稳定,能有效校正倾斜、侧拍等问题。 | 预处理的关键一步。 |
| 🔤 字符识别 | CRNN | 结构经典,精度高,善于学习字符序列上下文。 | 学术与工业界广泛采用的基准模型。 |
| LPRNet | 专为车牌设计,轻量快速,无需RNN,适合嵌入式部署。 | 对实时性要求极高的前端设备。 | |
| PaddleOCR / 通用大模型 | 开源易用、泛化能力强 (PaddleOCR);指令零样本识别(GPT-4o Mini)。 | 快速集成与验证,或探索新型交互范式。 |
二、核心挑战与技术发展趋势
尽管技术已相当成熟,但在实际应用中仍面临诸多挑战,驱动着技术不断演进:
-
应对复杂场景的鲁棒性 :恶劣天气 (雨雪雾)、极端光照 (强光、暗光)、运动模糊 以及车牌本身的老化、污损 是影响识别率的首要因素。当前主要通过大规模、高质量的场景化数据增强 和针对性的模型训练策略(如注意力机制、对抗训练)来提升模型在这些"角落案例"下的表现。
-
模型轻量化与工程化部署 :在实际产业中,算法必须部署在资源受限的环境(如ARM芯片的摄像机、停车场闸机)。这推动了模型压缩 (剪枝、量化、知识蒸馏)和高性能推理引擎(如NVIDIA TensorRT、Intel OpenVINO)的广泛应用,力求在有限的计算资源和存储空间下,实现最快的推理速度。
-
端到端一体化:将检测、矫正、识别多个模型整合优化为一个紧凑的、端到端的网络,已成为研究热点。这类方案可以共享特征、联合优化,减少冗余计算,在保持精度的同时进一步提升整体效率。
三、行业应用与厂商实践
技术最终服务于应用。国内众多安防与人工智能企业已将这些先进技术深度融合到产品中:
-
宇视科技(Uniview):发布基于"梧桐"大模型的交通抓拍系列产品,将大模型的复杂场景解析能力集成于前端摄像机,显著提升了在非规范卡口、夜间低照度等条件下的车牌及车辆特征识别准确率。
-
捷顺科技 :作为智慧停车领域的领导者,通过自研的深度学习算法与海量场景数据训练,宣称其车牌识别率在标准场景下可达99.99%。其系统还能有效应对无牌车、套牌车等特殊场景,并支持对新能源车牌、特种车牌的精准识别。
四、如何选择技术方案?
面对众多技术选项,最佳路径取决于具体的应用需求、资源约束和开发周期:
- 学术研究或快速原型验证 :推荐从 YOLOv8 + CRNN 或直接使用 PaddleOCR 开始。这两个组合社区资源极其丰富,有大量开源代码和预训练模型,便于快速搭建基准系统并进行针对性优化。
- 工业级大规模部署(侧重性价比与实时性) :轻量化YOLO(如YOLOv5s) + LPRNet 是经过市场验证的黄金组合。结合TensorRT等工具进行推理加速,能在成本可控的前提下满足绝大多数场景的实时性要求。
- 应对极端复杂场景或前瞻性探索 :可以重点关注 YOLO最新版本 或探索 视觉大模型 的落地方式。虽然对算力要求更高,但它们是突破现有性能瓶颈、解决传统难题的关键。
总结与展望
车牌识别技术正从一个相对独立的计算机视觉任务,演变为融合了高性能深度学习算法、系统工程化优化和垂直场景深度理解 的综合性解决方案。未来的发展将不仅局限于算法精度的"小数点后几位"的提升,更会向着 "全天候、全场景、端到端智能" 的方向迈进。随着多模态大模型和芯片算力的发展,未来的车牌识别系统可能会更加"傻瓜化"和"通用化",以更简洁的架构和更低的部署成本,实现更强大、更稳定的性能。
版权声明:本文为技术解析文章,仅代表个人观点。文中提及的相关技术、模型及公司名称,版权均归其各自所有者所有。