文章目录
- zjjy20251205一面
- wx20251205一面
- xykj20251203go三面
- xykj20251202go二面
- xykj20251127go一面
- [2025.11.12 ah二面](#2025.11.12 ah二面)
- [2025.11.07实习 ah-Java-一面](#2025.11.07实习 ah-Java-一面)
- [2025.11.07实习 yjhz Java 一面](#2025.11.07实习 yjhz Java 一面)
- [2025.10.31实习 xskj Java 一面](#2025.10.31实习 xskj Java 一面)
- 2025.09字节一面挂
- [2025.07 高德一面挂](#2025.07 高德一面挂)
- 回答汇总
-
- 为什么要三次握手
- 为什么要四次握手
- 先删缓存还是先修改数据库?
- 加锁能否完全避免?
- 前端到服务端全链路流程(含域名、IP、传输层、安全层)
- [DNS 域名解析的核心](#DNS 域名解析的核心)
- DNS寻址过程是怎样的?如果中间有服务器断联了怎么办?DNS劫持是什么?
- DNS寻址、断联处理与DNS劫持全解
-
- 一、DNS寻址完整流程(递归+迭代)
-
- [1. 核心角色分工](#1. 核心角色分工)
- [2. 详细寻址步骤(以`www.example.com`为例)](#2. 详细寻址步骤(以
www.example.com为例)) - [3. 核心原则](#3. 核心原则)
- 二、中间服务器断联的处理机制
-
- [1. 不同服务器断联的应对](#1. 不同服务器断联的应对)
- [2. 关键保障技术](#2. 关键保障技术)
- 三、DNS劫持是什么(原理、类型与危害)
-
- [1. 定义](#1. 定义)
- [2. 常见劫持类型](#2. 常见劫持类型)
- [3. 主要危害](#3. 主要危害)
- [4. 防范措施](#4. 防范措施)
- 四、面试简洁回答模板
- [如果客户端发大量 SYN 却不发第三次握手,会发生什么?](#如果客户端发大量 SYN 却不发第三次握手,会发生什么?)
- linux指令
-
- [一、Linux 核心指令与概念详解](#一、Linux 核心指令与概念详解)
-
- [1. 查看内存和 CPU 使用情况](#1. 查看内存和 CPU 使用情况)
-
- (1)查看内存使用
- [(2)查看 CPU 使用](#(2)查看 CPU 使用)
- [2. load average(系统负载)](#2. load average(系统负载))
- [3. 查找目标进程并 kill](#3. 查找目标进程并 kill)
- [4. top 指令可以 grep 吗?](#4. top 指令可以 grep 吗?)
- [5. 文件权限:rwx 含义 & 用户权限分类](#5. 文件权限:rwx 含义 & 用户权限分类)
-
- [(1)rwx 含义(读/写/执行)](#(1)rwx 含义(读/写/执行))
- (2)用户权限分类
- [6. 查看端口是否被占用(lsof / netstat)](#6. 查看端口是否被占用(lsof / netstat))
-
- [(1)lsof(列出打开的文件,Linux 万物皆文件,端口也属于文件)](#(1)lsof(列出打开的文件,Linux 万物皆文件,端口也属于文件))
- (2)netstat(备选,部分系统默认未安装)
- [7. 设定定时任务(crontab)](#7. 设定定时任务(crontab))
- [8. 软链接 vs 硬链接(核心区别)](#8. 软链接 vs 硬链接(核心区别))
- 二、面试简洁回答模板(关键问题)
-
- [1. 查看内存/CPU 使用](#1. 查看内存/CPU 使用)
- [2. load average 含义](#2. load average 含义)
- [3. 查找并 kill 进程](#3. 查找并 kill 进程)
- [4. 文件权限 rwx & 用户分类](#4. 文件权限 rwx & 用户分类)
- [5. 查看端口占用](#5. 查看端口占用)
- [6. 定时任务](#6. 定时任务)
- [7. 软/硬链接区别](#7. 软/硬链接区别)
- 三、总结
- [ES 慢查询优化](#ES 慢查询优化)
- mysql会出现死锁吗?大概什么场景,什么原因?有什么解决的办法吗?
-
- [一、MySQL 会出现死锁吗?](#一、MySQL 会出现死锁吗?)
- 二、死锁的核心原因与典型场景
-
- [1. 死锁的核心条件(必须同时满足)](#1. 死锁的核心条件(必须同时满足))
- [2. 典型死锁场景](#2. 典型死锁场景)
- 三、死锁的排查方法
-
- [1. 查看死锁日志](#1. 查看死锁日志)
- [2. 开启死锁监控](#2. 开启死锁监控)
- 四、死锁的解决与预防方案
-
- [1. 核心原则:打破"循环等待条件"(最有效)](#1. 核心原则:打破“循环等待条件”(最有效))
- [2. 优化事务设计](#2. 优化事务设计)
- [3. 代码层面的防护](#3. 代码层面的防护)
- [4. 数据库配置优化](#4. 数据库配置优化)
- [5. 事后处理:分析死锁日志并优化](#5. 事后处理:分析死锁日志并优化)
- 五、面试简洁回答模板
- 六、总结
- 锁的级别有哪些?
- 从锁的角度分析慢查询的原因及解决方法?
- websocket
-
- [一、WebSocket 的典型应用场景](#一、WebSocket 的典型应用场景)
- [二、WebSocket 与 HTTP 轮询的核心差异](#二、WebSocket 与 HTTP 轮询的核心差异)
- [三、WebSocket 性能优于 HTTP 轮询的核心原因](#三、WebSocket 性能优于 HTTP 轮询的核心原因)
- 总结
zjjy20251205一面
工作/实习:
- 用kafka的好处?
- 有考虑过用RDB和RabbitMQ吗?
- 数量级多大?
- 项目的难点?
- websocket什么场景会使用到?
- websocket跟HTTP轮询主要差别在哪,为什么性能比HTTP更好?回答的是三握四挥不知道对不对
项目:
- 是否已经投产?
- Redis多级缓存机制是怎么做的?
- @Cacheable具体是怎么起作用的?
- Redis如何保证一致性?
- 可以先删除缓存再更新DB吗?
- 可以先更新DB再删除缓存吗?
- 大概介绍一下ES的原理?用的什么索引?倒排索引原理?用过哪些分词器?
- 如果ES查询变慢了,你有什么排查思路吗?
- Mysql慢查询讲讲?
- 水平分库分表数据量?
- 慢查询除了SQL本身的原因还有什么可能?
- 事务隔离级别,MVCC,原理,readview、undolog等等。
- redolog是什么?使用场景?
- 间隙锁这些了解吗?(间隙锁就是锁定索引之间的间隙,防止其他事务在这个间隙插入数据,主要用来解决幻读的问题)
- mysql会出现死锁吗?大概什么场景,什么原因?有什么解决的办法吗?
- mysql量级多少?几千条还涉及到分库分表和慢查询吗?
八股
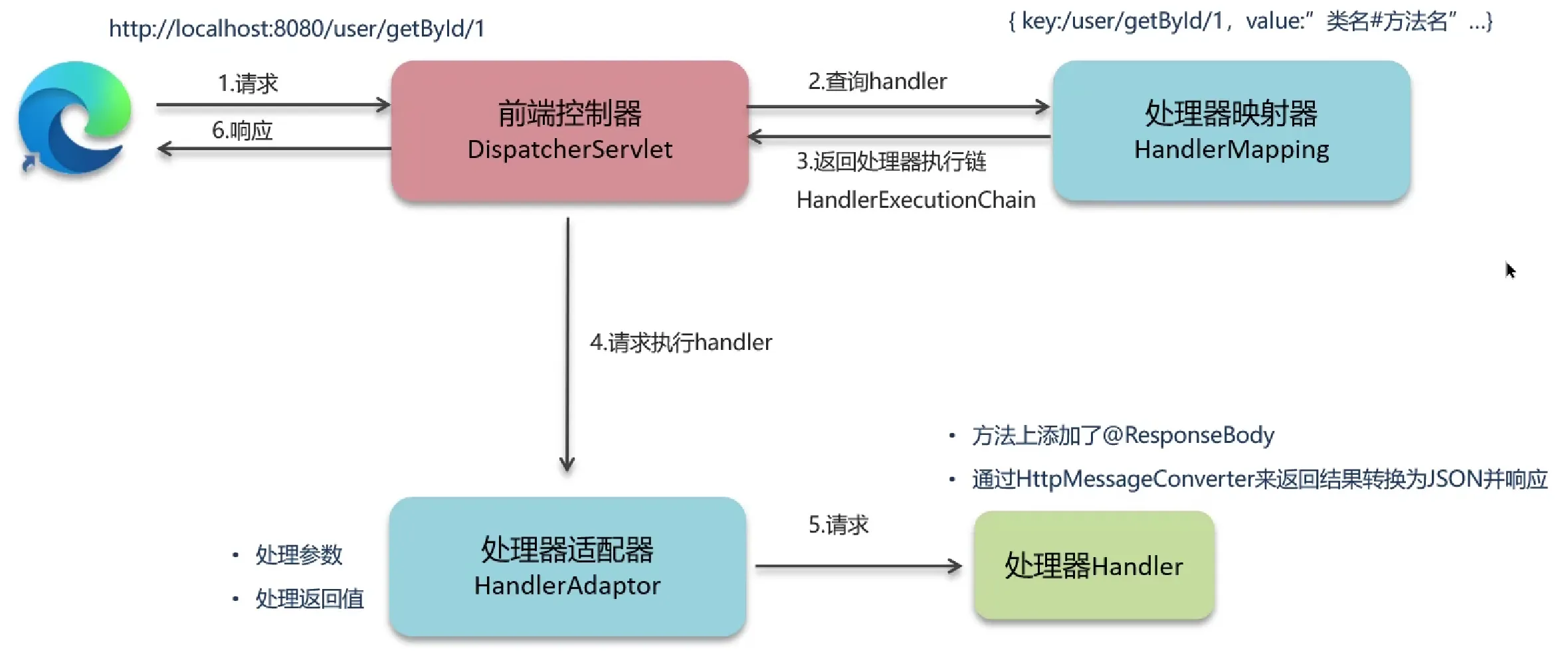
- 前端到服务端整个流程大概讲一下?域名,ip,传输层,安全层这个流程是怎么运转的?
- TCP讲一下三握手的过程?为什么要三次握手?
- 讲一下kafka的架构和消息存储机制?zookeeper主要存什么信息或者说为什么要用zookeeper?新版本好像老早不用zookeeper了?
手撕代码
最大不重复子串-滑动窗口
wx20251205一面
** 八股**
-
TCP为什么要三次握手?四次挥手的过程是什么?能不能三次挥手就行?Time wait的作用?TCP的拥塞控制是什么?
-
从浏览器输入一个URL到页面加载完成这个过程中会发生什么?
-
DNS寻址过程是怎样的?如果中间有服务器断联了怎么办?DNS劫持是什么?
-
HTTPS加密过程?
-
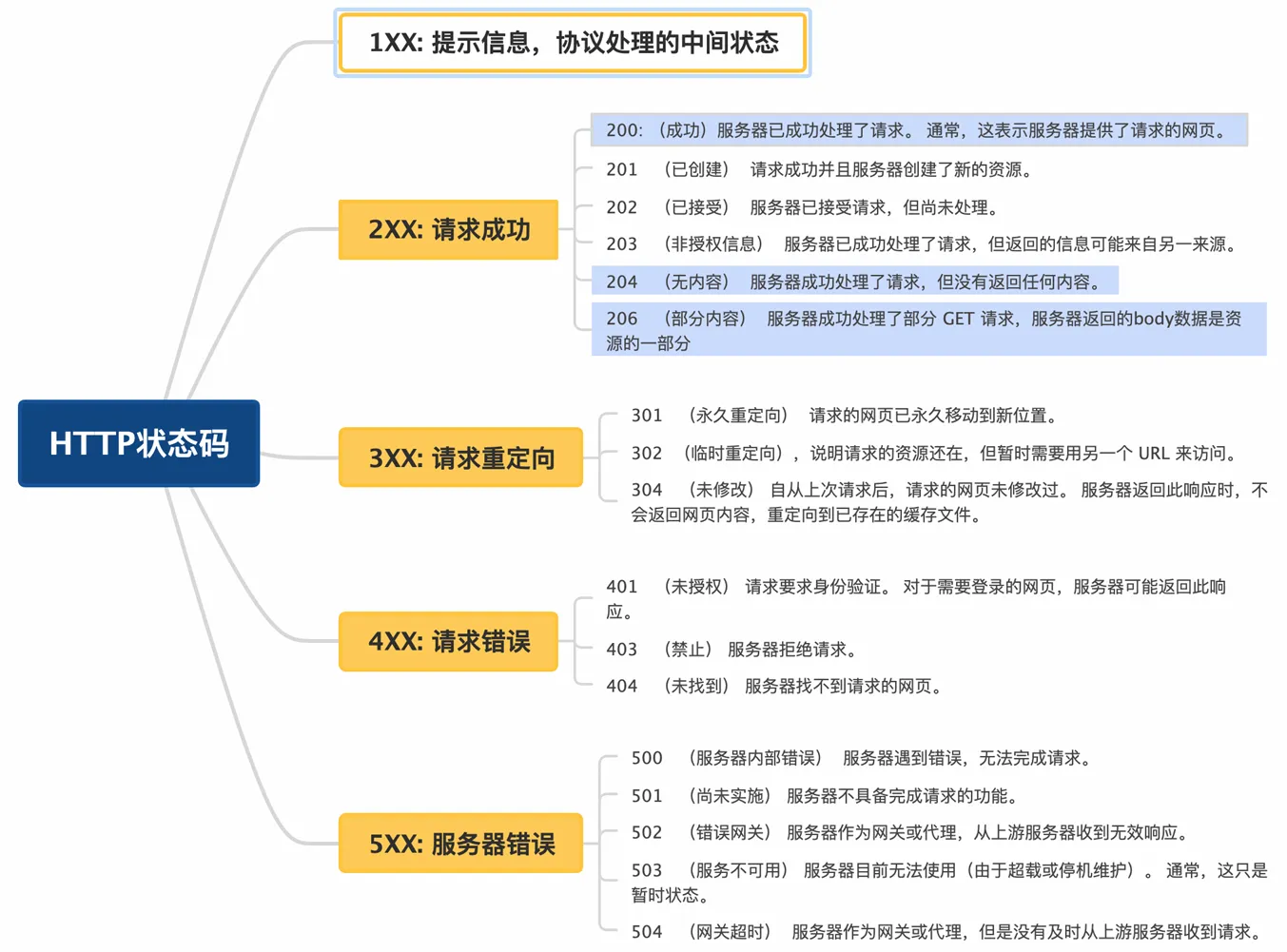
状态码之间比如说有500 501 502?400开头和500开头的状态码一般会用在什么场景?
-
TCP三次握手过程?如果TCP给服务端发送大量的SYN报文不给最后一次握手怎么办?
-
linux指令:如何查看当前系统的内存和CPU的使用?load average知道吗?linux如何查到目标进程然后kill?top指令可以grep吗?linux里面的文件权限有rwx分别代表什么意思?权限分成哪几种用户权限?怎么看一个端口是否被占用(lsof)?怎么在linux设定一个定时任务?软连接和硬连接的区别?
-
String StringBuild StringBuffer区别?
-
介绍threadlocal和可能的问题?
-
MYSQL索引结构?B+树特点?
手撕代码
匹配括号是否一致-栈
xykj20251203go三面
- go和java区别?
- 用过什么AI工具?
xykj20251202go二面
工作/实习
- kafka有做幂等性吗?如何防止数据丢失?
- 线程池参数怎么设置的?最大线程数,核心线程数,线程工厂,阻塞队列都怎么设置的?为什么这么设置?
- 虚拟机栈调优
八股
- mysql索引失效?索引创建原则?
手撕代码
- 查询11~15条数据
- 查询有相同生日的人
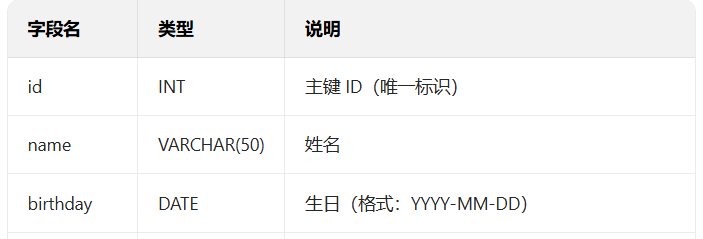
sql
-- 适用于 ID 无断层的情况,直接通过 LIMIT 偏移量+条数实现
SELECT * FROM users
ORDER BY id ASC
LIMIT 10, 5; -- LIMIT 偏移量(从0开始), 查询条数 → 偏移10条后取5条(即11-15条)
sql
SELECT * FROM users
WHERE birthday IN (
SELECT birthday FROM users GROUP BY birthday HAVING COUNT(id) > 1
) xykj20251127go一面
- undolog redolog binlog?→MVCC隔离、主从同步mysql?
- go map是否线程安全→sync.map原理→java concurrent hashmap
- 慢查询
- 水平分库分表
- channel如何限制次数使用?(waitgroup)
- channel关掉还能写吗,会怎样?
2025.11.12 ah二面
工作经历:
Mysql大批量插入。
所有接口都卡住怎么办?
八股:
Reentrentlock synchronize aqs
jvm 内存结构
jstack
Arthas 、慢查询
索引失效
多线程处理慢
2025.11.07实习 ah-Java-一面
八股:
Spring如何装配?答:@ComponentScan注解扫描 + Bean生命周期
Kafka如何保证消息不丢失?
Hashmap和ConcurrentHashMap 哪个线程安全?数据结构有何不同?
Redis穿透、雪崩、击穿? 但回答击穿加锁,面试官说就是为了缓存干嘛加锁。。。
docker如何优化镜像,如何加速部署,容器间如何通信? 这个挺冷门的
项目&场景:
Websocket和HTTP中和的半双工通信方式??
websocket如何保证可靠?
如何统计在线人数?答websocket/消息队列/定时任务扫描都不行
langchain4j、langchain、springai区别?如何开发?
mybatis批量插入是怎么做优化的。
2025.11.07实习 yjhz Java 一面
String StirngBuilder StringBuffer?
Springboot装配流程?
SpringbootApplication启动注解可以加什么参数?
List Set区别?Set特性?
线程的几种创建方式?
2025.10.31实习 xskj Java 一面
八股:
b+树索引
回表查询,二级索引
redis基本数据类型,项目中用了哪些
项目:
一主多从架构
功能介绍。
2025.09字节一面挂
八股:
索引最左前缀原则
举例说下死锁情景
分布式锁举例一种实现
redis基本数据类型
手撕代码:力扣 重排序
2025.07 高德一面挂
八股:
事务何时失效?
springboot为何比spring好?为何选springboot
其他忘了。
回答汇总
为什么要三次握手
一、三次握手核心目的:双向确认双方收发能力正常,同步初始序列号(ISN)
TCP是可靠传输,需确保「客户端能发、服务器能收;服务器能发、客户端能收」,三次握手刚好完成双向校验,且能避免历史无效连接干扰。
二、三次握手完整逻辑(极简版)
- 客户端→服务器(SYN=1,Seq=x):客户端说"我能发,我的初始序号是x"(请求建立连接);
- 服务器→客户端(SYN=1,ACK=1,Seq=y,Ack=x+1):服务器说"我能收(确认收到x),我也能发(我的序号是y)"(同意建立连接);
- 客户端→服务器(ACK=1,Seq=x+1,Ack=y+1):客户端说"我能收(确认收到y)"(连接正式建立)。
三、为什么必须三次?两次会有两个致命问题
问题1:无法确认「客户端的接收能力」,服务器资源被浪费
若只两次握手,流程是:客户端发SYN→服务器发SYN+ACK(连接建立),但客户端收不到服务器的SYN+ACK(如网络丢包),服务器会误以为连接已建立,一直占用端口、内存等资源,直到超时释放------大量此类无效连接会耗尽服务器资源,导致正常连接无法建立。
问题2:无法避免「历史无效连接请求」,导致数据错乱
TCP连接的SYN包可能因网络延迟滞留(比如客户端发的SYN卡了10分钟),客户端超时后会重发SYN建立新连接。若两次握手:
- 滞留的旧SYN 10分钟后到达服务器,服务器直接建立连接,向客户端发数据;
- 但客户端此时的新连接已正常通信,旧连接的无效数据会干扰新连接,导致数据错乱;
- 三次握手时,客户端收到旧SYN对应的SYN+ACK后,会发ACK拒绝(因为序号不匹配),服务器会释放连接,避免无效连接生效。
四、面试简洁回答模板
Q:TCP三次握手为什么要三次?两次会怎么样?
三次握手核心是双向确认双方收发能力,同步初始序列号,保证可靠连接。两次握手会有两个问题:①无法确认客户端接收能力,服务器会因收不到客户端确认,一直占用资源,导致资源浪费;②无法过滤历史滞留的无效连接请求,可能干扰正常连接,导致数据错乱。三次握手刚好完成双向校验,还能规避这些问题,确保连接可靠。
为什么要四次握手
Q:TCP四次挥手为什么要四次?不能三次吗?
核心原因是TCP是全双工通信,双方的发送通道需要独立关闭。四次挥手的关键是:服务器收到客户端的关闭请求(FIN)时,可能还在发送剩余数据,无法同时确认关闭和自己关闭,因此需要分两步:先回复ACK确认客户端关闭(让客户端等待),等自己数据发完后,再发FIN关闭自己的发送通道。
若强行三次挥手,服务器会被迫同时关闭发送通道,导致未发完的数据丢失;四次挥手通过"确认→发完数据→再关闭"的流程,保证双方数据都能完整传输,优雅释放连接。
先删缓存还是先修改数据库?
可以先删除缓存再更新DB吗?
正常情况
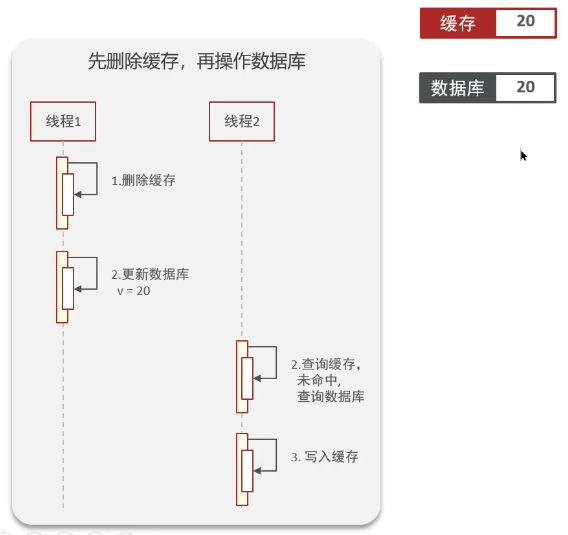
异常情况
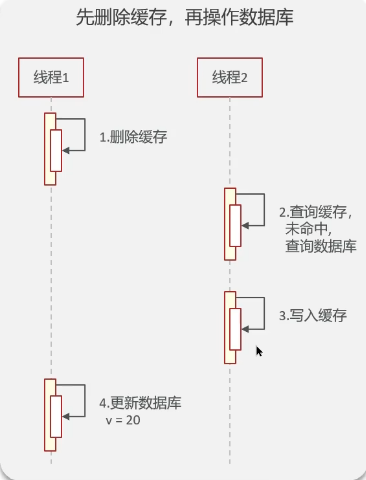
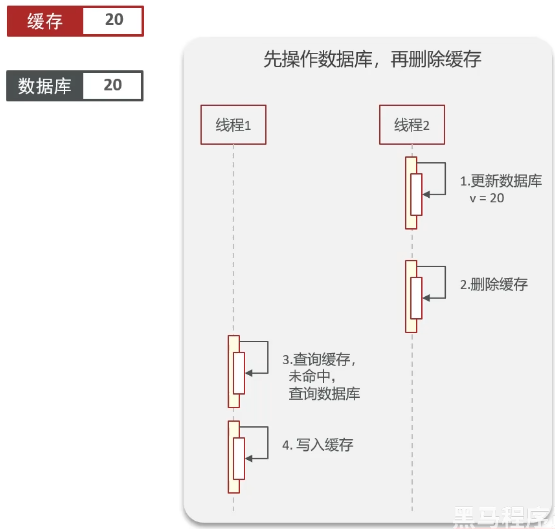
可以先更新DB再删除缓存吗?
正常情况
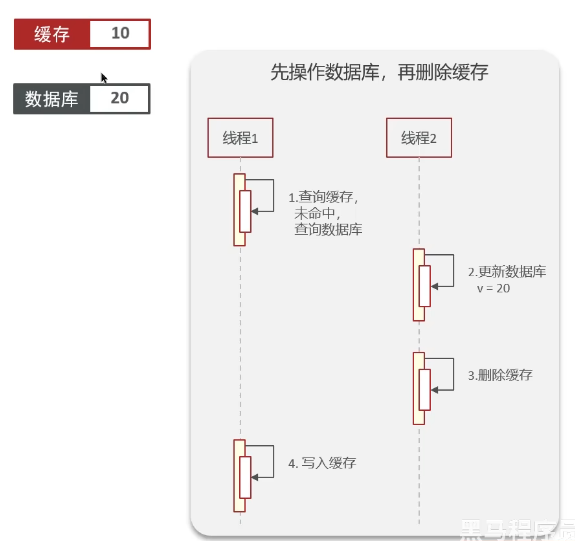
异常情况
加锁能否完全避免?
加锁能通过串行化操作消除并发竞争,缓解大部分一致性问题,但无法完全避免:一是锁可能失效 / 超时,二是删缓存失败仍会导致脏数据,三是加锁会牺牲性能且无法约束外部系统写入。
前端到服务端全链路流程(含域名、IP、传输层、安全层)
Q:请讲一下前端到服务端的整个流程,以及域名、IP、传输层、安全层是怎么运转的?
整个流程核心是"地址解析→连接建立→数据传输→连接释放":
- 前端构造请求后,先通过DNS将域名解析为IP(解决"域名易记但网络认IP"的问题);
- 基于IP,通过TCP三次握手建立可靠连接,若为HTTPS则额外通过TLS四次握手协商加密(保证数据安全);
- 连接建立后,前端通过HTTP/HTTPS协议将请求数据发送到服务端,服务端处理后返回响应(传输层保证可靠,安全层保证加密);
- 响应返回后,通过TCP四次挥手释放连接,前端渲染结果。
其中:域名是易记标识,IP是网络设备唯一标识,传输层(TCP)保证数据可靠传输,安全层(TLS)通过加密和证书验证保证传输安全,四层配合完成从请求到响应的全链路。
DNS 域名解析的核心
DNS域名解析的核心是"先查本地缓存→再由本地DNS递归代理→通过根/顶级/权威服务器迭代指引→最终拿到IP并缓存",全程遵循"递归查结果、迭代指方向"的分工原则,确保高效与可靠。
整个流程分两步:
- 客户端先查浏览器/OS缓存,未命中则请求本地DNS递归查询;
- 本地DNS先查自身缓存,无则向根服务器问TLD地址,再向TLD问权威地址,最后向权威拿到IP并缓存返回;
核心是"递归查结果、迭代指方向",根/TLD/权威各司其职,缓存加速查询。
DNS寻址过程是怎样的?如果中间有服务器断联了怎么办?DNS劫持是什么?
DNS寻址、断联处理与DNS劫持全解
一、DNS寻址完整流程(递归+迭代)
DNS寻址核心是"先查本地缓存→本地DNS递归代理→根/TLD/权威迭代指引→最终拿IP并缓存",分工明确、高效可靠。
1. 核心角色分工
| 角色 | 定位 | 核心职责 |
|---|---|---|
| 客户端 | 发起方 | 查浏览器/OS缓存→向本地DNS发递归查询→接收IP并缓存 |
| 本地DNS | 递归代理 | 代客户端查到底,先查自身缓存,无则逐级迭代查询 |
| 根服务器 | 顶层指引 | 全球13组(A‑M),只返回顶级域(TLD)地址,不存具体IP |
| TLD服务器 | 二级指引 | 如.com/.cn,返回权威服务器地址 |
| 权威服务器 | 数据源 | 存储域名与IP的权威映射,返回最终IP(A/AAAA/CNAME等) |
2. 详细寻址步骤(以www.example.com为例)
- 本地快速命中
客户端先查浏览器缓存 →OS缓存 (含hosts文件)→本地DNS缓存,命中则直接返回IP,流程终止。 - 本地DNS递归查询
未命中时,本地DNS向根服务器 发起迭代查询:"www.example.com的IP?" - 根→TLD指引
根服务器回复:"去问.comTLD服务器,地址是X.X.X.X"。 - TLD→权威指引
本地DNS向.comTLD查询,TLD回复:"example.com的权威服务器是ns1.example.com,地址Y.Y.Y.Y"。 - 权威返回IP
本地DNS向权威服务器查询,权威返回最终IP(如192.0.2.1)。 - 结果缓存与返回
本地DNS缓存结果(按TTL)并返回给客户端,客户端缓存后用于TCP连接。
3. 核心原则
- 递归+迭代:客户端对本地DNS是递归(要结果),本地DNS对根/TLD/权威是迭代(要指引)。
- 缓存链:浏览器→OS→本地DNS,缓存由TTL控制,命中可大幅降低解析耗时。
二、中间服务器断联的处理机制
DNS通过冗余设计 和超时重试保证高可用,某一环节断联时自动切换,具体如下:
1. 不同服务器断联的应对
| 断联节点 | 影响范围 | 系统应对机制 | 用户/运维处理 |
|---|---|---|---|
| 本地DNS | 单网络/用户 | 客户端切换备用DNS(如8.8.8.8/114.114.114.114);本地DNS重试其他上游 | 更换公共DNS,刷新缓存(ipconfig /flushdns) |
| 根服务器 | 全局(极少) | 本地DNS自动重试其他根节点(Anycast技术,多节点共享同一IP) | 无需操作,依赖DNS软件内置根列表 |
| TLD服务器 | 某顶级域 | 本地DNS重试同TLD的其他节点(如.com有多个镜像) |
等待TLD恢复,或使用备用DNS |
| 权威服务器 | 单域名 | 本地DNS返回缓存结果(若未过期);过期则返回解析失败 | 域名持有者切换权威服务器,或启用多权威节点冗余 |
2. 关键保障技术
- Anycast:多服务器共享同一IP,路由自动引导至最近可用节点,提升冗余与性能。
- 超时与重试:DNS查询默认超时约5秒,超时后自动重试其他节点或备用DNS。
- 缓存兜底:各级缓存(尤其本地DNS)在服务器断联时可返回过期但仍可用的结果(视TTL策略)。
三、DNS劫持是什么(原理、类型与危害)
1. 定义
DNS劫持(又称域名劫持)是攻击者通过篡改DNS解析结果,将域名指向恶意IP,导致用户访问被重定向至假冒网站,以窃取信息、植入广告或破坏服务的攻击手段。
2. 常见劫持类型
| 劫持类型 | 攻击方式 | 典型场景 |
|---|---|---|
| 本地劫持 | 恶意软件篡改OS DNS设置或hosts文件 | 单设备跳转到广告页,修改DNS为恶意服务器 |
| 路由器劫持 | 入侵路由器修改DNS配置 | 同一局域网内多设备受影响 |
| 中间人劫持 | 拦截DNS查询并返回伪造响应 | 公共Wi‑Fi下用户被诱导至钓鱼网站 |
| 服务器劫持 | 攻击本地DNS或权威服务器,篡改缓存/记录 | 大范围用户解析异常 |
3. 主要危害
- 信息窃取:诱导用户输入账号密码、银行卡信息等。
- 恶意植入:强制访问含病毒、木马的网站。
- 服务中断:合法网站被劫持导致无法访问。
- 广告导流:强制推送广告,影响用户体验。
4. 防范措施
- 使用安全DNS:如Cloudflare(1.1.1.1)、Google DNS(8.8.8.8),避免ISP DNS劫持。
- 启用加密DNS:DNS over HTTPS(DoH)、DNS over TLS(DoT),防止中间人篡改。
- 加固本地与路由:定期杀毒,修改路由器默认密码,禁用远程管理。
- 验证网站证书:访问HTTPS网站时,检查证书是否合法(如域名匹配、颁发机构可信)。
四、面试简洁回答模板
DNS寻址流程
客户端先查本地缓存(浏览器/OS/本地DNS),未命中则由本地DNS递归代理,通过根服务器→TLD服务器→权威服务器的迭代指引拿到最终IP,缓存后返回客户端;核心是"递归查结果、迭代指方向"。
服务器断联处理
DNS通过Anycast冗余、超时重试和缓存兜底应对断联:本地DNS会自动切换备用节点或备用DNS,缓存未过期时可返回旧结果,保障解析可用性。
DNS劫持
攻击者篡改DNS解析结果,将域名指向恶意IP,导致用户访问被重定向至假冒网站;常见类型有本地劫持、路由器劫持、中间人劫持,可通过安全DNS、加密DNS(DoH/DoT)和证书验证防范。
如果客户端发大量 SYN 却不发第三次握手,会发生什么?
这是 SYN 洪水攻击,会耗尽服务端的半连接队列资源:服务端收到 SYN 后会分配资源并进入半连接状态,等待 ACK 超时;大量虚假 SYN 会占满队列,导致正常请求无法建立连接。防御手段包括启用 SYN Cookie、增大半连接队列、防火墙限流等。
应对 SYN 洪水攻击有三种核心手段:① 增大半连接队列,通过调整内核参数扩容队列,容纳更多半连接请求,适合小规模攻击;② SYN Cookie,内核不预先分配资源,通过哈希算法验证合法请求,是大规模攻击的兜底方案;③ 防火墙限流,在前端拦截高频 SYN 报文,从源头减少恶意流量。生产环境通常组合使用这三种方式,层层防护。
linux指令
一、Linux 核心指令与概念详解
1. 查看内存和 CPU 使用情况
(1)查看内存使用
-
free:最常用,展示物理内存/交换分区使用情况
bashfree -h # -h 人性化显示单位(KB/MB/GB)输出说明:
total:总内存;used:已使用;free:空闲;available:可用(含缓存/缓冲区)Swap:交换分区(虚拟内存)使用情况
-
top:实时监控(内存+CPU),默认按 CPU 使用率排序
- 第一行:系统负载;第二行:进程统计;第三行:CPU 使用率;第四/五行:内存/交换分区使用
(2)查看 CPU 使用
-
top:实时查看 CPU 核心使用率、进程 CPU 占用
%Cpu(s)行:us(用户态)、sy(内核态)、id(空闲)、wa(IO 等待)等
-
mpstat:查看多核 CPU 详细使用率
bashmpstat -P ALL # 展示所有 CPU 核心的使用率 -
pidstat:按进程查看 CPU 使用率
bashpidstat -u 1 # 每秒刷新一次进程 CPU 使用
2. load average(系统负载)
-
含义 :
load average是 top/uptime 中展示的 3 个数值(1 分钟、5 分钟、15 分钟),表示系统平均负载,即单位时间内处于可运行(R)和不可中断(D)状态的进程数。 -
解读 :
- 对于 N 核 CPU,
load average ≤ N表示负载正常;load average > N表示系统过载(需结合 1/5/15 分钟趋势,若 15 分钟值持续高,说明负载长期偏高)。 - 示例:4 核 CPU,
load average: 3.2, 4.5, 5.1→ 15 分钟负载 5.1 > 4,系统过载。
- 对于 N 核 CPU,
-
查看方式 :
bashuptime # 直接展示 load average top # 第一行开头也会显示
3. 查找目标进程并 kill
(1)查找进程
-
ps :列出进程(常用组合:
ps -ef)bashps -ef | grep java # 查找包含 java 的进程(grep 过滤) # 输出:UID(用户) PID(进程ID) PPID(父进程ID) CMD(命令) -
pgrep:直接按进程名查 PID(更简洁)
bashpgrep java # 输出所有 java 进程的 PID
(2)终止进程
-
kill:发送信号终止进程(默认 SIGTERM 15,优雅退出;SIGKILL 9 强制杀死)
bashkill 12345 # 优雅终止 PID=12345 的进程 kill -9 12345 # 强制杀死(无法被进程捕获,慎用) -
killall:按进程名批量终止
bashkillall -9 java # 强制杀死所有 java 进程
4. top 指令可以 grep 吗?
- 直接 grep 不行 :top 是交互式实时界面,stdout 输出特殊,直接
top | grep java会无正常输出。 - 替代方案 :
-
top 内置过滤 :进入 top 后,按
o输入COMMAND=java(按进程名过滤),或按u输入用户名(按用户过滤)。 -
批处理模式 :top 加
-b(批处理)、-n 1(只输出一次),再 grep:bashtop -b -n 1 | grep java # 非交互式输出一次,再过滤
-
5. 文件权限:rwx 含义 & 用户权限分类
(1)rwx 含义(读/写/执行)
| 符号 | 权限 | 数字标识 | 文件含义 | 目录含义 |
|---|---|---|---|---|
| r | 读 | 4 | 可读取文件内容 | 可列出目录下文件(ls) |
| w | 写 | 2 | 可修改/删除文件 | 可创建/删除/重命名目录内文件 |
| x | 执行 | 1 | 可执行文件(如脚本/二进制) | 可进入目录(cd) |
- 示例:
-rwxr-xr--解析:- 第一位
-:文件类型(-普通文件,d目录,l软链接); - 第2-4位
rwx:文件所有者(user)权限; - 第5-7位
r-x:所属组(group)权限; - 第8-10位
r--:其他用户(other)权限。
- 第一位
(2)用户权限分类
Linux 文件权限分为三类用户:
- 所有者(User) :文件/目录的创建者或指定用户(
chown修改); - 所属组(Group) :用户组(
chgrp修改); - 其他用户(Other):既非所有者,也不在所属组的所有用户。
- 查看权限:
ls -l 文件名 - 修改权限:
chmod 755 文件名(7=4+2+1,即 rwx;5=4+1,即 r-x)
6. 查看端口是否被占用(lsof / netstat)
(1)lsof(列出打开的文件,Linux 万物皆文件,端口也属于文件)
bash
lsof -i:8080 # 查看 8080 端口被哪个进程占用
# 输出:COMMAND(进程名) PID(进程ID) USER(用户) FD(文件描述符) TYPE DEVICE SIZE/OFF NODE NAME- 参数:
-i表示网络连接,:端口号指定端口;-i tcp可过滤 TCP 端口。
(2)netstat(备选,部分系统默认未安装)
bash
netstat -tulpn | grep 8080
# -t:TCP;-u:UDP;-l:监听中;-p:显示进程;-n:数字显示端口/IP7. 设定定时任务(crontab)
(1)crontab 基本语法
bash
crontab -e # 编辑当前用户的定时任务(首次编辑需选择编辑器,推荐 vim)- 任务格式:
* * * * * 命令/脚本路径
五个*分别代表:分(0-59)、时(0-23)、日(1-31)、月(1-12)、周(0-7,0/7 均为周日)。 - 特殊符号:
*:每单位时间;*/5:每 5 个单位(如*/5 * * * *每 5 分钟);,:枚举(如1,30 * * * *每分钟 1 和 30 分);-:范围(如1-5 * * * *每小时 1-5 分)。
(2)示例
bash
# 每天凌晨 2 点执行备份脚本
0 2 * * * /usr/local/backup.sh
# 每周一到周五 18:00 清理日志
0 18 * * 1-5 rm -rf /var/log/app/*.log
# 每 10 分钟检查一次服务状态
*/10 * * * * /usr/local/check_service.sh(3)其他常用命令
bash
crontab -l # 列出当前用户的定时任务
crontab -r # 删除当前用户的所有定时任务- 注意:定时任务的输出默认会发邮件给用户,可在命令后加
> /dev/null 2>&1屏蔽输出(/dev/null是黑洞,2>&1重定向错误输出到标准输出)。
8. 软链接 vs 硬链接(核心区别)
| 维度 | 硬链接(Hard Link) | 软链接(Symbolic Link,符号链接) |
|---|---|---|
| 本质 | 给文件 inode 新增文件名映射(共享 inode) | 独立文件,存储原文件的路径(类似快捷方式) |
| inode | 与原文件相同 | 独立 inode |
| 跨文件系统 | 不支持(仅同一分区) | 支持(可跨分区/远程) |
| 链接对象 | 仅支持文件(不可链接目录) | 支持文件/目录 |
| 原文件删除 | 硬链接仍有效(inode 引用计数 > 0) | 软链接失效(红色闪烁) |
| 文件大小 | 与原文件一致 | 极小(仅存储路径字符串) |
| 创建命令 | ln 原文件 硬链接文件 |
ln -s 原文件 软链接文件 |
-
示例:
bash# 硬链接 ln /test/file.txt /test/file_hard # 软链接 ln -s /test/file.txt /test/file_soft
二、面试简洁回答模板(关键问题)
1. 查看内存/CPU 使用
查看内存用
free -h人性化展示,top实时监控;查看 CPU 用top看核心使用率,mpstat看多核详情,pidstat按进程统计。
2. load average 含义
系统平均负载,代表单位时间内可运行和不可中断的进程数,N 核 CPU 下,值 ≤ N 正常,> N 表示过载,需结合 1/5/15 分钟趋势判断。
3. 查找并 kill 进程
用
ps -ef | grep 进程名或pgrep 进程名查 PID,再用kill PID优雅终止,kill -9 PID强制杀死。
4. 文件权限 rwx & 用户分类
r 读、w 写、x 执行,对应数字 4、2、1;权限分所有者(User)、所属组(Group)、其他用户(Other)三类,用
ls -l查看。
5. 查看端口占用
用
lsof -i:端口号或netstat -tulpn | grep 端口号,lsof更常用,能直接显示占用进程。
6. 定时任务
用
crontab -e编辑,格式为分 时 日 月 周 命令,crontab -l查看,crontab -r删除。
7. 软/硬链接区别
硬链接共享 inode,删原文件仍有效,不支持目录和跨分区;软链接是独立文件,存原路径,删原文件失效,支持目录和跨分区,日常用软链接更多。
三、总结
以上是 Linux 运维/开发高频指令和概念,核心需掌握:
- 资源监控(top/free/mpstat)、进程/端口管理(ps/lsof/netstat/kill);
- 权限与链接(rwx/用户分类/软硬链接);
- 定时任务(crontab 语法);
- 负载解读(load average)。
ES 慢查询优化
ES 查询变慢的排查思路分四步:① 先通过慢查询日志和 Profile 分析定位慢查询的语句和耗时步骤;② 优化查询语句,避免 wildcard 前缀、深度分页、复杂脚本等低效写法;③ 检查索引设计,合理设置 Mapping、分词器和分片;④ 排查集群资源瓶颈,包括 CPU、内存、磁盘 IO、网络,针对性扩容或优化配置。核心原则是 "先优化软件,再扩容硬件"。
mysql会出现死锁吗?大概什么场景,什么原因?有什么解决的办法吗?
一、MySQL 会出现死锁吗?
会 ,且死锁是 MySQL(尤其是 InnoDB 存储引擎)在并发场景下的常见问题。
InnoDB 是行级锁引擎,并发事务对不同行/间隙加锁时,若出现循环等待锁资源的情况,就会触发死锁。MyISAM 因是表级锁,锁冲突时只会出现阻塞而非死锁,因此死锁主要发生在 InnoDB 中。
二、死锁的核心原因与典型场景
1. 死锁的核心条件(必须同时满足)
根据经典的"死锁四大条件",MySQL 死锁需满足:
- 互斥条件:锁资源只能被一个事务持有(如行锁排他);
- 请求与保持条件:事务持有部分锁,又请求新的锁;
- 不可剥夺条件:锁不能被强制剥夺,只能由持有事务主动释放;
- 循环等待条件:多个事务形成锁资源的循环等待链(核心条件,打破即可避免死锁)。
2. 典型死锁场景
场景1:事务加锁顺序不一致(最常见)
两个事务对同一批记录的加锁顺序相反,形成循环等待。
sql
-- 表结构:user(id INT PRIMARY KEY, name VARCHAR(20))
-- 数据:id=1, id=2
-- 事务 A
BEGIN;
UPDATE user SET name='A1' WHERE id=1; -- 持有 id=1 的行锁
UPDATE user SET name='A2' WHERE id=2; -- 请求 id=2 的行锁,被事务 B 阻塞
-- 事务 B
BEGIN;
UPDATE user SET name='B2' WHERE id=2; -- 持有 id=2 的行锁
UPDATE user SET name='B1' WHERE id=1; -- 请求 id=1 的行锁,被事务 A 阻塞结果:事务 A 等事务 B 释放 id=2,事务 B 等事务 A 释放 id=1,形成循环等待,触发死锁。
场景2:间隙锁导致的循环等待
InnoDB 可重复读隔离级别下,间隙锁与行锁结合(临键锁),扩大了锁范围,易引发死锁。
sql
-- 表结构:user(id INT, age INT, INDEX idx_age(age))
-- 数据:age=10, age=20
-- 事务 A
BEGIN;
SELECT * FROM user WHERE age > 10 AND age < 20 FOR UPDATE; -- 锁定间隙 (10,20)
INSERT INTO user(age) VALUES(15); -- 若事务 B 已锁定部分间隙,会阻塞
-- 事务 B
BEGIN;
SELECT * FROM user WHERE age > 5 AND age < 15 FOR UPDATE; -- 锁定间隙 (5,10)
INSERT INTO user(age) VALUES(12); -- 被事务 A 的间隙锁阻塞,同时事务 A 也等待事务 B,形成死锁场景3:跨表加锁顺序不一致
多个事务操作多张表,加表锁/行锁的顺序相反。
sql
-- 事务 A:先锁 user 表,再锁 order 表
BEGIN;
UPDATE user SET name='A' WHERE id=1;
UPDATE `order` SET status=1 WHERE user_id=1;
-- 事务 B:先锁 order 表,再锁 user 表
BEGIN;
UPDATE `order` SET status=2 WHERE user_id=1;
UPDATE user SET name='B' WHERE id=1;结果:事务 A 持有 user 锁、等 order 锁;事务 B 持有 order 锁、等 user 锁,触发死锁。
场景4:长事务持有锁过久
长事务长时间占用锁资源,其他事务排队等待锁时,易形成复杂的锁等待链,最终触发死锁。
- 例如:事务 A 执行后未及时提交(如忘记
COMMIT),持有 id=1 的锁;事务 B 持有 id=2 的锁并等待 id=1;事务 C 持有 id=3 的锁并等待 id=2;事务 A 此时请求 id=3 的锁,形成循环等待。
三、死锁的排查方法
1. 查看死锁日志
MySQL 会记录死锁信息到日志,可通过以下方式查看:
sql
-- 方式1:查看最新死锁详情(InnoDB 内置)
SHOW ENGINE INNODB STATUS;输出中 LATEST DETECTED DEADLOCK 部分会包含:
- 死锁涉及的事务 ID、加锁语句;
- 锁等待的资源、循环等待链;
- 最终被回滚的事务(InnoDB 会自动回滚其中一个事务,打破死锁)。
2. 开启死锁监控
sql
-- 开启死锁监控(MySQL 8.0+ 推荐)
SET GLOBAL innodb_print_all_deadlocks = ON;该参数会将所有死锁信息写入 MySQL 错误日志(默认路径:/var/log/mysqld.log),方便长期排查。
四、死锁的解决与预防方案
1. 核心原则:打破"循环等待条件"(最有效)
- 统一加锁顺序 :所有事务对记录/表的加锁顺序保持一致(如按 ID 升序、表名字典序加锁)。
示例:无论哪个事务,都先更新 id=1 再更新 id=2,避免顺序相反。 - 缩小锁范围 :
- 尽量使用唯一索引(避免间隙锁,临键锁降级为行锁);
- 避免大范围
UPDATE/DELETE(如WHERE age > 0会锁定全表间隙); - 非必要时,将隔离级别从
REPEATABLE READ降为READ COMMITTED(关闭间隙锁,仅用行锁)。
2. 优化事务设计
- 缩短事务时长:事务仅包含必要的 SQL 语句,避免在事务中执行耗时操作(如 RPC 调用、用户交互),减少锁持有时间。
- 批量操作拆分:大批量更新拆分为多个小事务(如每次更新 100 条记录),降低锁冲突概率。
- 主动释放锁 :及时
COMMIT/ROLLBACK,避免长事务占用锁资源。
3. 代码层面的防护
-
添加重试机制 :捕获死锁错误(MySQL 错误码:1213),自动重试事务(注意重试次数,避免无限循环)。
示例(Java):javaint retryCount = 3; while (retryCount > 0) { try (Connection conn = getConnection()) { // 执行事务逻辑 conn.setAutoCommit(false); updateUser(conn, 1); updateUser(conn, 2); conn.commit(); break; } catch (SQLTransactionRollbackException e) { // 捕获死锁异常,重试 retryCount--; Thread.sleep(100); // 短暂等待后重试 } } -
使用乐观锁替代悲观锁 :对并发更新的场景,用版本号(
version)实现乐观锁,避免加行锁。sql-- 乐观锁更新:仅当版本号匹配时更新,无锁冲突 UPDATE user SET name='new', version=version+1 WHERE id=1 AND version=5;
4. 数据库配置优化
-
设置锁等待超时 :避免事务无限期等待锁,超时后主动回滚。
sqlSET GLOBAL innodb_lock_wait_timeout = 5; -- 单位:秒,默认 50 秒,可根据业务调整 -
关闭不必要的间隙锁 :将隔离级别设为
READ COMMITTED(需业务接受不可重复读)。sqlSET GLOBAL transaction_isolation = 'READ-COMMITTED';
5. 事后处理:分析死锁日志并优化
- 从死锁日志中定位冲突的 SQL 和锁资源;
- 调整 SQL 语句(如添加索引、缩小查询范围),避免不必要的锁;
- 优化事务逻辑,消除循环等待的可能。
五、面试简洁回答模板
Q:MySQL 会出现死锁吗?什么场景、原因?如何解决?
MySQL(InnoDB)会出现死锁,核心原因是并发事务形成循环等待锁资源的闭环(满足死锁四大条件)。
典型场景:① 事务加锁顺序不一致;② 间隙锁导致锁范围扩大;③ 跨表加锁顺序相反;④ 长事务持有锁过久。
解决与预防方案:① 统一加锁顺序,打破循环等待;② 缩小锁范围(用唯一索引、降低隔离级别);③ 缩短事务时长,避免长事务;④ 代码层添加死锁重试机制,或用乐观锁替代悲观锁;⑤ 配置锁等待超时,及时排查死锁日志并优化 SQL。
六、总结
死锁的本质是"循环等待锁资源",因此预防的核心是打破循环等待 (统一加锁顺序),辅以缩小锁范围、优化事务设计等手段;排查的关键是利用 SHOW ENGINE INNODB STATUS 分析死锁日志,定位根因后针对性优化。
锁的级别有哪些?
锁的级别主要从粒度、读写属性、场景三个维度划分:
按粒度:表级锁(粒度大、并发低)、行级锁(粒度小、并发高,InnoDB 核心)、页级锁(介于两者之间,极少用),InnoDB 还特有间隙锁 / 临键锁(解决幻读);
按读写属性:共享锁(读锁,不互斥)、排他锁(写锁,互斥),以及 InnoDB 意向锁(协调表锁与行锁);
按场景:乐观锁(版本号机制,无锁)、悲观锁(传统加锁,阻塞),还有分布式锁(跨节点资源协调)。
其中,InnoDB 以行级锁为核心,结合间隙锁 / 临键锁实现高并发与数据一致性,是生产环境的主流选择。
从锁的角度分析慢查询的原因及解决方法?
从锁的角度,慢查询的核心原因是查询等待锁资源的时间过长:① 行锁竞争(高并发更新同一行、非索引查询导致行锁升级为表锁);② 间隙锁 / 临键锁扩大锁范围,增加冲突;③ 表锁(MyISAM 或显式表锁)导致读写阻塞;④ 长事务持有锁过久,阻塞后续操作。解决方法:① 确保 SQL 命中索引,缩小锁范围,统一加锁顺序;② 缩短事务时长,拆分长事务,及时提交;③ 改用 InnoDB 引擎,降低隔离级别关闭间隙锁;④ 高并发场景用乐观锁替代悲观锁,或分库分表分散锁竞争;⑤ 设置锁等待超时,监控并处理长事务。
websocket
一、WebSocket 的典型应用场景
WebSocket 是全双工、长连接 的通信协议,核心解决了 HTTP 无法主动推送数据的痛点,适用于需要实时双向交互的场景,具体包括:
- 实时消息与通信类
- 即时聊天:网页版聊天工具、在线客服系统(如网页微信、钉钉客服)。客户端发送消息后,服务器可实时推送给接收方,无需客户端频繁查询。
- 协同办公:多人在线文档(腾讯文档、飞书文档)、共享白板。用户的编辑操作可实时同步给其他协作者,实现无延迟协作。
- 实时数据推送类
- 金融行情:股票、期货、加密货币的实时价格推送。服务器数据更新后立即推送给客户端,延迟可低至毫秒级,远优于轮询。
- 物联网(IoT)监控:智能设备状态上报(如电表读数、工业传感器数据)、远程设备控制。设备可主动上报数据,服务器也可下发控制指令,双向实时通信。
- 系统监控告警:运维监控面板(如服务器 CPU/内存使用率)、故障告警。服务器发现异常后立即推送告警信息,无需客户端定时拉取。
- 实时互动类
- 在线游戏:网页版多人游戏(棋牌、休闲竞技)。玩家操作需实时同步到服务器,并推送给其他玩家,低延迟是关键。
- 直播互动:直播弹幕、礼物打赏通知。弹幕消息可实时推送给所有观众,提升互动体验。
- 高频数据交互类
- 实时表单验证:注册时实时检查用户名是否已被占用,无需用户点击"验证"按钮。
- 投票/抽奖实时结果:活动投票数据实时更新,中奖信息即时推送。
二、WebSocket 与 HTTP 轮询的核心差异
HTTP 轮询是基于"请求-响应"模型的伪实时 方案,分为 短轮询 和 长轮询(Long Polling),与 WebSocket 的差异主要体现在以下维度:
| 特性 | WebSocket | HTTP 短轮询 | HTTP 长轮询(Long Polling) |
|---|---|---|---|
| 连接模式 | 一次握手建立长连接,连接持续至主动关闭 | 每次请求建立新 HTTP 连接,响应后立即断开 | 建立连接后服务器挂起请求,有数据/超时后断开,再重连 |
| 通信方向 | 全双工(客户端/服务器可同时收发) | 半双工(客户端主动请求,服务器被动响应) | 半双工(仍需客户端先发起请求) |
| 数据推送方式 | 服务器可主动推送,无需客户端触发 | 客户端定时发起请求拉取数据 | 服务器有数据时响应,无数据则挂起请求 |
| 协议开销 | 握手用 HTTP,后续传输轻量级帧(头部仅 2~10 字节) | 每次请求携带完整 HTTP 头部(Cookie、User-Agent 等),冗余数据多 | 仍需携带完整 HTTP 头部,仅减少请求频率 |
| 延迟 | 极低(毫秒级,实时推送) | 高(延迟等于轮询间隔,如 5 秒轮询则最大延迟 5 秒) | 较低(有数据时立即响应,无数据则超时延迟) |
| 服务器资源消耗 | 单连接处理双向通信,连接数少,资源消耗低 | 频繁建立/断开 TCP 连接,握手/挥手开销大 | 连接挂起时占用服务器线程,高并发下线程易耗尽 |
三、WebSocket 性能优于 HTTP 轮询的核心原因
WebSocket 性能更优的本质是减少了底层网络开销和协议冗余,具体可拆解为 4 点:
-
减少 TCP 三次握手/四次挥手的开销(核心)
- HTTP 轮询(短/长):每次请求都要经历 TCP 三次握手建立连接 → 传输数据 → TCP 四次挥手断开连接。高频轮询下,服务器需要频繁处理连接的建立与销毁,CPU 和端口资源消耗巨大。
- WebSocket:仅在初始化时进行一次 HTTP 握手(底层是 TCP 三次握手),之后复用该 TCP 长连接进行双向通信,直到主动关闭才触发四次挥手,彻底避免了频繁连接的开销。
-
降低协议头部的冗余数据
- HTTP 协议:每次请求/响应都携带完整的头部信息(如 Host、Cookie、Content-Type 等),头部大小通常远大于实际传输的数据(例如 1 字节的"心跳"数据,HTTP 头部可能占几百字节),带宽利用率极低。
- WebSocket:握手完成后,数据传输采用轻量级的帧协议,头部仅 2~10 字节,还支持数据压缩,大幅减少了冗余数据,提升了传输效率。
-
消除轮询延迟,实现真正实时
- HTTP 短轮询:客户端需定时发起请求(如每 1 秒/5 秒),若服务器数据在两次轮询之间更新,客户端无法立即获取,存在"轮询间隔延迟",且频繁请求会浪费带宽。
- HTTP 长轮询:虽减少了请求频率,但服务器挂起请求时会占用线程资源,高并发下易导致线程池耗尽;且请求超时后仍需重连,存在一定延迟。
- WebSocket:服务器数据更新时可立即推送,无需客户端触发,延迟几乎为零,完美适配实时场景。
-
全双工通信提升交互效率
HTTP 轮询(包括长轮询)本质是半双工 ,客户端和服务器无法同时收发数据;而 WebSocket 是全双工,客户端发送消息的同时,服务器可推送其他数据,例如聊天时,你发送消息的同时,能实时收到其他人的消息,无需等待当前请求完成。
总结
- WebSocket 适用于高实时性、双向交互的场景,核心优势是服务器可主动推送、低延迟、低开销;
- 与 HTTP 轮询的核心差异在于连接模式(长连接 vs 短连接)、通信方向(全双工 vs 半双工)、协议开销;
- 性能更优的根本原因是减少了 TCP 连接的建立/销毁开销、降低了协议冗余、消除了轮询延迟。
要不要我帮你整理一份 WebSocket 与 HTTP 轮询的选型对比表,方便你在项目中快速决策?