目录
被围绕的区域
解法:递归
从四个边,以当前位置为'O'为起始位置进行递归标记
后面再次遍历时,如果该区域为'O'且被没有标记,说明该地方是被围绕的区域,修改'O' 为 'X',往后进行枚举...
cpp
class Solution
{
public:
bool vis[201][201] = {false};
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
int n, m;
void dfs(vector<vector<char>> &board, int i, int j)
{
vis[i][j] = true;
for (int k = 0; k < 4; k++)
{
int x = dx[k] + i, y = dy[k] + j;
if (x >= 0 && x < n && y >= 0 && y < m && !vis[x][y] && board[x][y] == 'O')
{
dfs(board, x, y);
}
}
}
void solve(vector<vector<char>> &board)
{
n = board.size(), m = board[0].size();
for (int i = 0; i < n; i++)
{
if (board[i][0] == 'O' && !vis[i][0])
{
dfs(board, i, 0);
}
if (board[i][m - 1] == 'O' && !vis[i][m - 1])
{
dfs(board, i, m - 1);
}
}
for (int j = 0; j < m; j++)
{
if (board[0][j] == 'O' && !vis[0][j])
{
dfs(board, 0, j);
}
if (board[n - 1][j] == 'O' && !vis[n - 1][j])
{
dfs(board, n - 1, j);
}
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
// 是 O 且没有被递归到说明就是被环绕的区域
if (board[i][j] == 'O' && !vis[i][j])
{
board[i][j] = 'X';
}
}
}
}
};克隆图
前提:使用 hash 来储存原节点与克隆节点的映射
思路1:dfs
当前节点为 nullptr,返回 nullptr
当前节点在 hash 中找到了,说明当前递归的节点被克隆了,通过原节点返回克隆节点
此时当前节点 node 一定没有被克隆,克隆节点 clone 进行 new,之后加入到 hash 中
遍历当前节点的邻居节点进行递归,把递归结果保存到 clone 的 neighbors 中
cpp
class Solution
{
public:
// 原节点 -> 克隆节点
unordered_map<Node *, Node *> hash;
Node *cloneGraph(Node *node)
{
if (node == nullptr)
return nullptr;
// 递归时克隆过了直接返回
if (hash.contains(node))
{
return hash[node];
}
Node *cloneNode = new Node(node->val);
hash[node] = cloneNode;
// 遍历原节点的邻居
for (auto &neighbor : node->neighbors)
{
// 收集克隆节点的邻居
cloneNode->neighbors.push_back(cloneGraph(neighbor));
}
return cloneNode;
}
};思路2:bfs
创建队列保存被克隆的原节点
每次获取队头节点 tmp,遍历该节点的所有邻居节点:
如果当前邻居节点没有被克隆,就要进行克隆 clone,之后保存到 hash 中
此时通过原节点一定能找到克隆节点 hashtmp,把邻居节点的克隆节点 clone保存在 hashtmp 中
cpp
class Solution
{
public:
// 原节点 -> 克隆节点
unordered_map<Node *, Node *> hash;
Node *cloneGraph(Node *node)
{
if (node == nullptr)
{
return nullptr;
}
queue<Node *> q;
// 初始化条件
q.push(node);
Node *clone = new Node(node->val);
hash[node] = clone;
while (!q.empty())
{
Node *tmp = q.front();
q.pop();
for (auto &neighbor : tmp->neighbors)
{
// 哈希表找不到映射说明当前节点neighbor还没有被克隆
if (!hash.contains(neighbor))
{
Node *clone = new Node(neighbor->val);
hash[neighbor] = clone;
// 把克隆后的原节点放入到队列中
q.push(neighbor);
}
// 到这里,当前节点neighbor一定被克隆了
// 把它加入到克隆节点tmp的邻居中(隐藏条件:队列中的节点一定被克隆过的)
hash[tmp]->neighbors.push_back(hash[neighbor]);
}
}
return clone;
}
};除法求值
解法:dfs
建图,比如 a,b = 3,就要建 a->b 3 和 b->a 1/3,使用hash<string,vector<pair<string,double>> 进行储存
图遍历,比如求 a,c 那我就从 a 开始一直递归,直到找到c,也就是 a->b->c,此时累乘的结果是答案(注意处理边界,因为还要 a->b->a 的情况,要使用vis对当前遍历节点进行标记)
cpp
class Solution
{
public:
unordered_map<string, vector<pair<string, double>>> hash;
unordered_set<string> vis;
double tmp1;
double dfs(const string &begin, const string &end, double tmp)
{
if (begin == end)
{
return tmp;
}
if (vis.contains(begin))
{
return -1;
}
vis.insert(begin);
for (auto &[beginNext, val] : hash[begin])
{
double ans = dfs(beginNext, end, tmp * val);
if (ans != -1)
{
return ans;
}
}
return -1;
}
vector<double> calcEquation(vector<vector<string>> &equations, vector<double> &values, vector<vector<string>> &queries)
{
// 建图
for (int i = 0; i < equations.size(); i++)
{
hash[equations[i][0]].push_back({equations[i][1], values[i]});
hash[equations[i][1]].push_back({equations[i][0], 1 / values[i]});
}
vector<double> ret;
for (int i = 0; i < queries.size(); i++)
{
string begin = queries[i][0];
string end = queries[i][1];
if (!hash.contains(begin))
{
ret.push_back(-1);
}
else
{
vis.clear();
ret.push_back(dfs(begin, end, 1));
}
}
return ret;
}
};课程表
解法:拓扑排序
建图,存入度
使用拓扑排序(入度为0的入队列,bfs遍历)判断是否有课程入度不为0,有就完成返回false
cpp
class Solution
{
public:
bool canFinish(int numCourses, vector<vector<int>> &prerequisites)
{
unordered_map<int, vector<int>> hash;
vector<int> in(numCourses);
for (int i = 0; i < prerequisites.size(); i++)
{
// b->a
int a = prerequisites[i][0];
int b = prerequisites[i][1];
hash[b].push_back(a);
in[a]++;
}
queue<int> q;
for (int i = 0; i < numCourses; i++)
{
if (in[i] == 0)
{
q.push(i);
}
}
if (q.size() == 0)
{
return false;
}
int cnt = 0;
while (!q.empty())
{
cnt++;
int tmp = q.front();
q.pop();
for (auto &numCourse : hash[tmp])
{
if ((--in[numCourse]) == 0)
{
q.push(numCourse);
}
}
}
// 或者是再遍历一遍来看看是否in中还有不等于0的课桌存在
return cnt == numCourses;
}
};课程表②
解法:拓扑排序
按照拓扑排序的顺序依次当前课程即可,如果不能完成就返回{}
cpp
class Solution
{
public:
vector<int> findOrder(int numCourses, vector<vector<int>> &prerequisites)
{
vector<vector<int>> hash(numCourses);
vector<int> in(numCourses);
for (int i = 0; i < prerequisites.size(); i++)
{
// b->a
int a = prerequisites[i][0];
int b = prerequisites[i][1];
hash[b].push_back(a);
in[a]++;
}
queue<int> q;
vector<int> ret;
for (int i = 0; i < numCourses; i++)
{
if (in[i] == 0)
{
q.push(i);
ret.push_back(i);
}
}
if (q.size() == 0)
{
return ret;
}
int cnt = 0;
while (!q.empty())
{
cnt++;
int tmp = q.front();
q.pop();
for (auto &numCourse : hash[tmp])
{
if ((--in[numCourse]) == 0)
{
ret.push_back(numCourse);
q.push(numCourse);
}
}
}
if (cnt != numCourses)
{
return {};
}
return ret;
}
};最小基因变化

cpp
class Solution
{
public:
unordered_map<string, bool> hash;
queue<string> q;
char gene[4] = {'A', 'G', 'C', 'T'};
bool IsEnd(const string &s, const string &end)
{
// 遍历出所有的情况
for (int i = 0; i < s.size(); i++)
{
for (int j = 0; j < 4; j++)
{
string tmp = s;
tmp[i] = gene[j];
// 找到终点直接返回变化次数
if (tmp == end)
{
return true;
}
if (hash.contains(tmp) && hash[tmp] == false)
{
q.push(tmp);
hash[tmp] = true;
}
}
}
return false;
}
int minMutation(string startGene, string endGene, vector<string> &bank)
{
bool vis = false;
for (auto &b : bank)
{
if (b == endGene)
{
vis = true;
}
hash[b] = false;
}
if (!vis)
{
return -1;
}
q.push(startGene);
int ret = 0;
while (!q.empty())
{
ret++;
int sz = q.size();
while (sz--)
{
string tmp = q.front();
q.pop();
if (IsEnd(tmp, endGene))
{
return ret;
}
}
}
return -1;
}
};蛇梯棋
解法:bfs
与上题思路类似:都是通过队列的方式进行bfs,同时使用数组进行标记走过的位置
但是关键是要解决:如何把值转化成对应坐标?

队列放值还是坐标?
放值好:值转成坐标后,如果坐标不为-1,需要进行跳转,这里就直接值入队列完成跳转操作
cpp
class Solution
{
public:
int snakesAndLadders(vector<vector<int>> &board)
{
int n = board.size();
bool vis[410] = {false};
queue<int> q;
int ret = 0;
// 起点也要进行标记
vis[1] = true;
q.push(1);
while (!q.empty())
{
ret++;
int sz = q.size();
while (sz--)
{
int tmp = q.front();
q.pop();
for (int i = tmp + 1; i <= min(tmp + 6, n * n); i++)
{
// 值转换成坐标
int x1 = (i - 1) / n, y1 = (i - 1) % n;
int x = n - 1 - x1, y = y1;
if (x1 % 2 != 0)
{
y = n - 1 - y1;
}
// 标记下一个位置
int next = i;
if (board[x][y] > 0)
{
next = board[x][y];
}
if (!vis[next])
{
vis[next] = true;
// 走到了终点直接返回
if (next == n * n)
{
return ret;
}
q.push(next);
}
}
}
}
return -1;
}
};单词接龙
最小基因变化的别的场景
前缀树
解法:根据前缀树
单纯靠前缀树(多叉数)的构建:数组开辟26个位置或者哈希表的方式储存节点,使用bool对当前是否是结尾字符的标记
cpp
class Trie
{
public:
struct Node
{
Node *son[26] = {nullptr};
bool end = false;
};
Node *root = new Node;
Trie()
{
}
void insert(string word)
{
Node *cur = root;
int n = word.size();
for (int i = 0; i < n; i++)
{
Node *tmp = cur->son[word[i] - 'a'];
if (tmp == nullptr)
{
tmp = new Node;
// 赋值
cur->son[word[i] - 'a'] = tmp;
}
// 标记放循环外面
if (i == n - 1)
{
tmp->end = true;
}
cur = tmp;
}
}
int find(const string &tmp)
{
Node *cur = root;
for (auto &ch : tmp)
{
Node *t = cur->son[ch - 'a'];
if (t == nullptr)
{
return 0;
}
cur = t;
}
// 完整
if (cur->end == true)
{
return 1;
}
// 前缀
return 2;
}
bool search(string word)
{
int ret = find(word);
if (ret == 0 || ret == 2)
{
return false;
}
return true;
}
bool startsWith(string prefix)
{
int ret = find(prefix);
if (ret == 0)
{
return false;
}
// 返回1和返回2都是前缀
return true;
}
};添加和搜索单词
解法:前缀树
在前缀树的基础上多了一步.的处理:
遍历26个节点,看看当前节点不为空且能让剩下的单词在前缀树上,那么他就可以构建成功
cpp
class WordDictionary
{
public:
struct Node
{
Node *son[26] = {nullptr};
bool end = false;
};
Node *root = new Node;
int n = 0;
WordDictionary()
{
}
void addWord(string word)
{
Node *cur = root;
for (auto &ch : word)
{
Node *tmp = cur->son[ch - 'a'];
if (tmp == nullptr)
{
tmp = new Node;
cur->son[ch - 'a'] = tmp;
}
cur = tmp;
}
cur->end = true;
}
bool dfs(Node *r, const string &word, int i)
{
if (i == n)
{
return r->end;
}
if (word[i] == '.')
{
for (int j = 0; j < 26; j++)
{
if (r->son[j] != nullptr && dfs(r->son[j], word, i + 1))
{
return true;
}
}
}
else
{
Node *tmp = r->son[word[i] - 'a']; // 这里i为4?
if (tmp != nullptr && dfs(tmp, word, i + 1))
{
return true;
}
}
return false;
}
bool search(string word)
{
Node *cur = root;
n = word.size();
if (dfs(root, word, 0))
{
return true;
}
return false;
}
};任务调度器
解法:构造
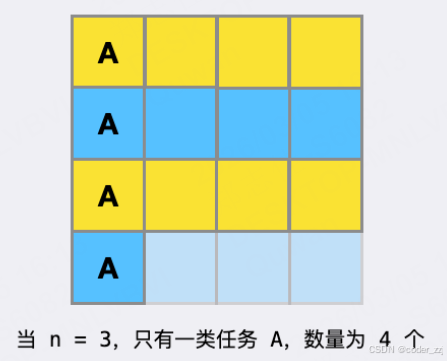
此时最短间隔: (n + 1) * (m - 1) + 1 = 4 * 3 + 1 = 13,第一行到第三个行剩下的位置就可以安排任务进行填充;如果个数超过 9 个就填充在每一行的最后一个
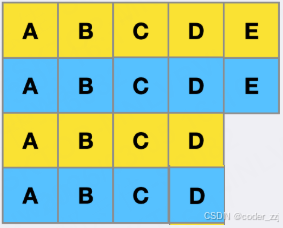
总任务个数 - 最短间隔 + 最短间隔,其实答案也就是总任务个数;而上面的 (n + 1) * (m - 1) + 1 中的 + 1并不一定每次都使用,这个要根据最多任务的个数进行计算(我理解的就是最后一行的个数),所有最终答案是 (总任务个数,(n + 1) * (m - 1) + lastLineCnt)取最大值
cpp
class Solution
{
public:
int leastInterval(vector<char> &tasks, int n)
{
int arr[26] = {0};
int maxTask = INT_MIN;
for (auto task : tasks)
{
int pos = task - 'A';
arr[pos]++;
if (maxTask < arr[pos])
{
maxTask = arr[pos];
}
}
int LastTaskCnt = 0;
for (auto &ch : arr)
{
if (ch == maxTask)
{
LastTaskCnt++;
}
}
// n + 1 每行需要安排多少个任务
// maxTask - 1 最多要安排多少行任务
// 最后一行安排的任务个数 LastTaskCnt
return max((int)tasks.size(), (n + 1) * (maxTask - 1) + LastTaskCnt);
}
};单词搜索二
解法:dfs + 前缀树
单纯使用 dfs 进行暴搜的话会超时,要先进行预处理,也就是通过单词列表中的每个单词构建前缀树,再dfs过程就可以直接判断当前节点的指定子节点是否为空,为空直接返回就不需要再往下递归了,不为空就往上下左右四个方向找下一个字符...
cpp
class Solution
{
public:
struct Node
{
Node *son[26] = {0};
string w;
};
Node *root = new Node;
int dx[4] = {0, 0, 1, -1}, dy[4] = {1, -1, 0, 0};
int n, m;
vector<vector<char>> _board;
vector<string> ret;
void dfs(Node *cur, int i, int j)
{
Node *tmp = cur->son[_board[i][j] - 'a'];
if (tmp == nullptr)
{
return;
}
if (!tmp->w.empty())
{
ret.push_back(tmp->w);
tmp->w = ""; // 剪枝
// return; 可能存在app apple
}
// 在这里进行标记
char ch = _board[i][j];
_board[i][j] = '#';
for (int k = 0; k < 4; k++)
{
int x = dx[k] + i, y = dy[k] + j;
if (x >= 0 && x < n && y >= 0 && y < m && _board[x][y] != '#' && tmp->son[_board[x][y] - 'a'] != nullptr)
{
dfs(tmp, x, y);
}
}
// 递归结束这里进行复原
_board[i][j] = ch;
}
void CreateNode(const string &s)
{
Node *tmp = root;
for (int i = 0; i < s.size(); i++)
{
int pos = s[i] - 'a';
if (tmp->son[pos] == nullptr)
{
tmp->son[pos] = new Node;
}
tmp = tmp->son[pos];
}
tmp->w = s;
}
vector<string> findWords(vector<vector<char>> &board, vector<string> &words)
{
n = board.size(), m = board[0].size();
_board = board;
for (auto &word : words)
{
CreateNode(word);
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
dfs(root, i, j);
}
}
return ret;
}
};电话号码的自由组合
解法:递归暴搜
cpp
class Solution
{
public:
string hash[10] = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
vector<string> ret;
string path, _digits;
void dfs(int pos)
{
if (path.size() == _digits.size())
{
ret.push_back(path);
return;
}
string s = hash[_digits[pos] - '0'];
for (int i = 0; i < s.size(); i++)
{
path += s[i];
dfs(pos + 1);
path.pop_back();
}
}
vector<string> letterCombinations(string digits)
{
_digits = digits;
dfs(0);
return ret;
}
};组合
解法:递归
从当前位置开始往后递归收集组合
cpp
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
int _n, _k;
void dfs(int pos)
{
if (path.size() == _k)
{
ret.push_back(path);
return;
}
for (int i = pos; i <= _n; i++)
{
path.push_back(i);
// i往后递归,就不会出现数字重复出现在path中
dfs(i + 1);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k)
{
_n = n;
_k = k;
dfs(1);
return ret;
}
};全排列
解法:递归
递归暴搜,但要当前位置收集后要进行标记,防止重复递归收集
cpp
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path, _nums;
bool vis[7] = {false};
int n;
void dfs()
{
if (path.size() == n)
{
ret.push_back(path);
return;
}
for (int i = 0; i < n; i++)
{
if (!vis[i])
{
// 标记位置,相同位置不能递归
vis[i] = true;
path.push_back(_nums[i]);
dfs();
vis[i] = false;
path.pop_back();
}
}
}
vector<vector<int>> permute(vector<int> &nums)
{
n = nums.size();
_nums = nums;
dfs();
return ret;
}
};全排列二
解法:递归
特殊判断:除了当前位置标记后不能递归外,还有 numsi == numsi-1 且 i-1 位置被标记过,这种情况也是不能递归的
cpp
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
bool vis[9] = {false};
int n;
void dfs(const vector<int> &_nums)
{
if (path.size() == n)
{
ret.push_back(path);
return;
}
for (int i = 0; i < n; i++)
{
if (vis[i] || (i - 1 >= 0 && _nums[i] == _nums[i - 1] && vis[i - 1]))
{
continue;
}
// 标记位置,相同位置不能递归
vis[i] = true;
path.push_back(_nums[i]);
dfs(_nums);
vis[i] = false;
path.pop_back();
}
}
vector<vector<int>> permuteUnique(vector<int> &nums)
{
n = nums.size();
sort(nums.begin(), nums.end());
dfs(nums);
return ret;
}
};组合总和
思路1
收集到的组合先排序,在放到set进行去重,得到的答案才正确
思路2
先排序,从当前位置往后开始递归,就不需要去重和在加入ret时排序了
cpp
class Solution
{
public:
set<vector<int>> ret;
vector<int> path;
int n;
void dfs(vector<int> &candidates, int target)
{
if (target <= 0)
{
if (target == 0)
{
// 直接排序恢复现场的逻辑就错了
vector<int> _path = path;
sort(_path.begin(), _path.end());
ret.insert(_path);
}
return;
}
for (int i = 0; i < n; i++)
{
path.push_back(candidates[i]);
dfs(candidates, target - candidates[i]);
path.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int> &candidates, int target)
{
n = candidates.size();
dfs(candidates, target);
vector<vector<int>> ans(ret.begin(), ret.end());
return ans;
}
};
// 先排序,从当前位置往后开始递归,就不需要去重和在加入ret时排序了
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
int sum = 0;
void dfs(vector<int> &candidates, int target, int pos)
{
if (sum >= target || pos == candidates.size())
{
if (sum == target)
ret.push_back(path);
return;
}
for (int i = pos; i < candidates.size(); i++)
{
path.push_back(candidates[i]);
sum += candidates[i];
dfs(candidates, target, i);
sum -= candidates[i];
path.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int> &candidates, int target)
{
sort(candidates.begin(), candidates.end());
dfs(candidates, target, 0);
return ret;
}
};N皇后二
与N皇后思路一致,也是要解决坐标之间怎么判断在同一个正副斜线上
cpp
class Solution
{
public:
int ret;
vector<string> path;
int _n;
bool col[9] = {false}, slash[81] = {false}, subtline[81] = {false};
void dfs(int i)
{
if (i == _n)
{
ret++;
return;
}
for (int j = 0; j < _n; j++)
{
// if(path[i][j] == '.' && !col[j] && !slash[j + i] && !subtline[j - i])
if (!col[j] && !slash[j + i] && !subtline[j - i])
{
path[i][j] = 'Q';
col[j] = slash[j + i] = subtline[j - i] = true;
dfs(i + 1);
path[i][j] = '.';
col[j] = slash[j + i] = subtline[j - i] = false;
}
}
}
int totalNQueens(int n)
{
_n = n;
for (int i = 0; i < n; i++)
{
path.emplace_back(n, '.');
}
dfs(0);
return ret;
}
};括号生成
解法:dfs
思考:什么情况下括号不需要再往下递归了?
当左括号 < 右括号,左括号 > n,右括号 > n 这三种情况下一定不能收集到正确的括号匹配
cpp
class Solution
{
public:
vector<string> ret;
string path;
int left = 0, right = 0, _n;
void dfs()
{
if (left < right || left > _n || right > _n)
{
return;
}
if (left == _n && right == _n)
{
ret.push_back(path);
return;
}
left++;
path += '(';
dfs();
left--;
path.pop_back();
right++;
path += ')';
dfs();
right--;
path.pop_back();
}
vector<string> generateParenthesis(int n)
{
_n = n;
dfs();
return ret;
}
};单词搜索
解法:dfs
cpp
class Solution
{
public:
int n, m;
bool vis[6][6] = {false};
int dx[4] = {0, 0, 1, -1}, dy[4] = {1, -1, 0, 0};
bool dfs(vector<vector<char>> &board, const string &word, int i, int j, int pos)
{
if (pos == word.size())
{
return true;
}
for (int k = 0; k < 4; k++)
{
int x = dx[k] + i, y = dy[k] + j;
if (x >= 0 && x < n && y >= 0 && y < m && board[x][y] == word[pos] && !vis[x][y])
{
vis[x][y] = true;
if (dfs(board, word, x, y, pos + 1))
{
return true;
}
vis[x][y] = false;
}
}
return false;
}
bool exist(vector<vector<char>> &board, string word)
{
n = board.size(), m = board[0].size();
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
if (word[0] == board[i][j])
{
vis[i][j] = true;
if (dfs(board, word, i, j, 1))
{
return true;
}
vis[i][j] = false;
}
}
}
return false;
}
};以上便是全部内容,有问题欢迎在评论区指正,感谢观看!