移除 GIL 的核心挑战
Python 自由线程模式的实现并非简单地"关闭"全局解释器锁(GIL)那么简单。GIL 的存在有其深刻的技术原因------它保护着 CPython 最核心的内存管理机制:引用计数(Reference Counting)。
CPython 使用引用计数来追踪每个对象的生命周期。每个 PyObject 都维护着一个引用计数器(ob_refcnt),当有新的引用指向该对象时计数加 1,当引用消失时计数减 1。一旦计数归零,对象的内存立即被释放。这个机制简单高效,但存在一个致命问题:它不是线程安全的。
在多线程环境下,如果两个线程同时对同一个对象的引用计数进行修改(例如一个线程执行 +1,另一个线程执行 -1),就会发生竞态条件(race condition),导致引用计数不准确,进而引发内存泄漏或过早释放,造成程序崩溃。GIL 通过确保同一时刻只有一个线程执行 Python 代码,从而巧妙地回避了这个问题。
但 GIL 也付出了巨大代价:它使得 Python 无法在多核 CPU 上真正并行执行 CPU 密集型任务。PEP 703 的核心任务,就是在移除 GIL 的同时,重新设计内存管理机制,确保在多线程环境下的正确性与性能。这涉及一系列精妙的技术创新,其中最关键的三项技术是:偏向引用计数 、延迟引用计数 和不朽对象。
偏向引用计数(Biased Reference Counting)
核心思想
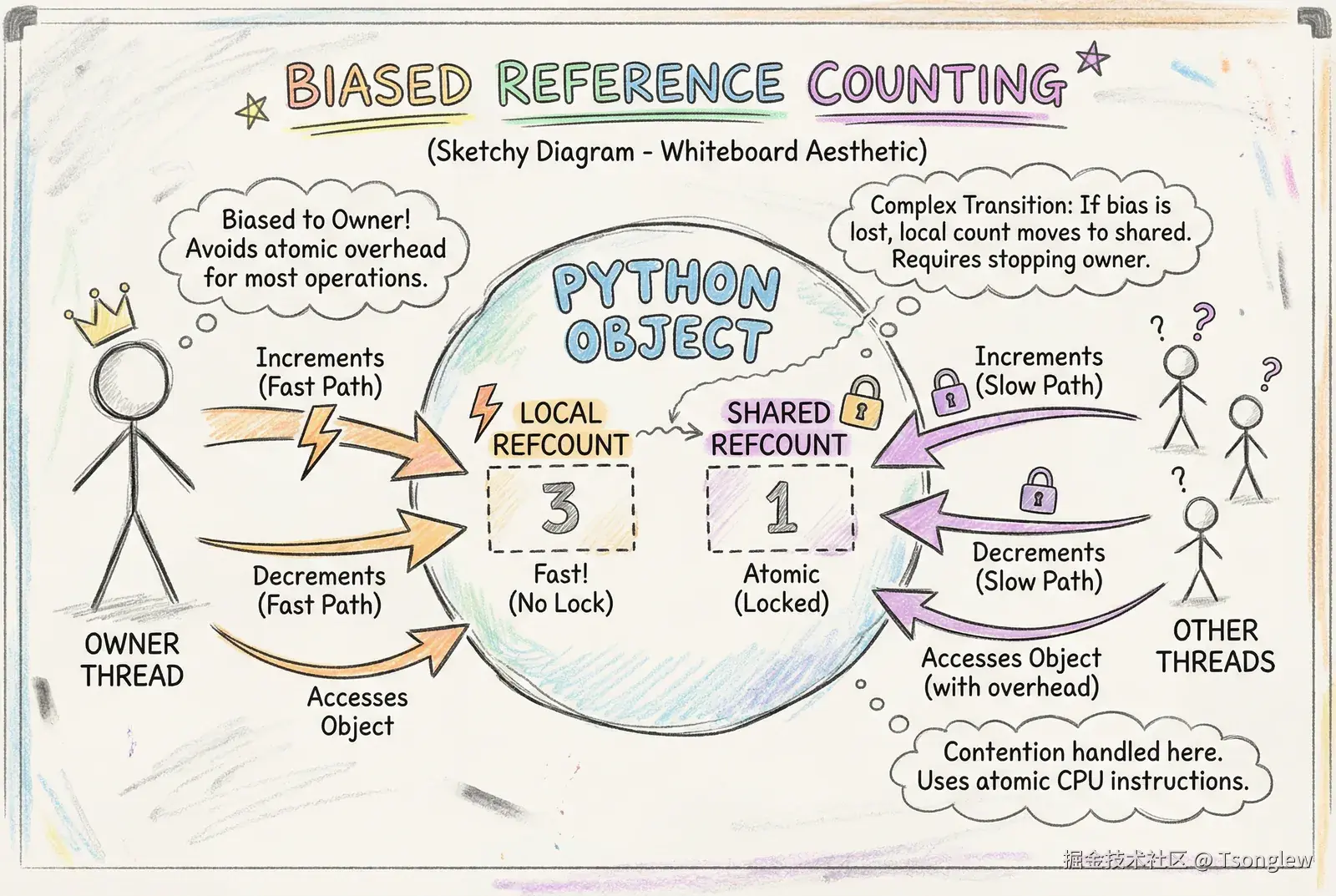
偏向引用计数(Biased Reference Counting, BRC)是自由线程 Python 的基石技术之一。它基于一个关键观察:即使在多线程程序中,大多数对象实际上只被单个线程访问和修改 。citation citation
传统的线程安全引用计数需要使用原子操作(atomic operations),每次修改引用计数都需要通过硬件级别的原子指令(如 x86 的 LOCK INCR)来确保线程安全。这些原子操作虽然安全,但开销很大,会导致 CPU 缓存失效、内存屏障开销等性能损失。
偏向引用计数的核心策略是:为每个对象维护两个引用计数:
- 本地引用计数 (Local Reference Count):由"拥有"该对象的线程(通常是创建该对象的线程)独占维护,无需任何同步机制,可以像单线程程序一样快速地进行
+1和-1操作。 - 共享引用计数(Shared Reference Count):记录所有其他线程对该对象的引用总数,使用原子操作维护。
工作机制
在 PyObject 结构中,引用计数字段被重新设计。在自由线程构建中,引用计数被拆分为两部分信息:
c
typedef struct _object {
// ... 其他字段
Py_ssize_t ob_ref_local; // 本地(偏向)引用计数
Py_ssize_t ob_ref_shared; // 共享引用计数(原子操作)
// ... 其他字段
} PyObject;当所属线程修改引用计数时:
- 直接修改
ob_ref_local,无需原子操作,速度极快。
当其他线程修改引用计数时:
- 使用原子操作修改
ob_ref_shared。 - 如果检测到跨线程访问,对象会从"偏向模式"退化为"共享模式",后续所有操作都使用原子操作。
性能优势
偏向引用计数的最大优势在于:它为常见情况(单线程访问对象)提供了零开销的性能 ,同时在罕见情况(跨线程共享对象)下能够安全地回退到原子操作。根据 Choi 等人的研究,这项技术最初为 Swift 语言设计,能够显著减少多线程程序中 70-90% 的原子操作开销。citation
在实际的 Python 程序中,大量对象(如局部变量、临时计算结果)只在创建它们的线程内部使用,偏向引用计数让这些对象的内存管理开销与单线程 Python 几乎相同。
延迟引用计数(Deferred Reference Counting)
设计动机
即使有了偏向引用计数,某些特殊对象仍然会成为性能瓶颈。特别是那些被大量线程频繁访问,但几乎永远不会被销毁的对象,例如:
- 函数对象(function objects)
- 代码对象(code objects)
- 模块对象(module objects)
- 类型对象(type objects)
这些对象通常存储在全局字典中,每次函数调用、属性访问都会导致引用计数的频繁变化。即使使用原子操作,在高并发场景下,这些对象的引用计数字段会成为热点争用(hot contention)------大量线程同时尝试修改同一内存地址,导致 CPU 缓存不断失效,性能急剧下降。
延迟引用计数(Deferred Reference Counting)通过一个激进的策略解决这个问题:暂时不更新这些对象的引用计数 ,而是将引用计数的维护工作推迟到垃圾回收(GC)阶段统一处理。citation citation
实现机制
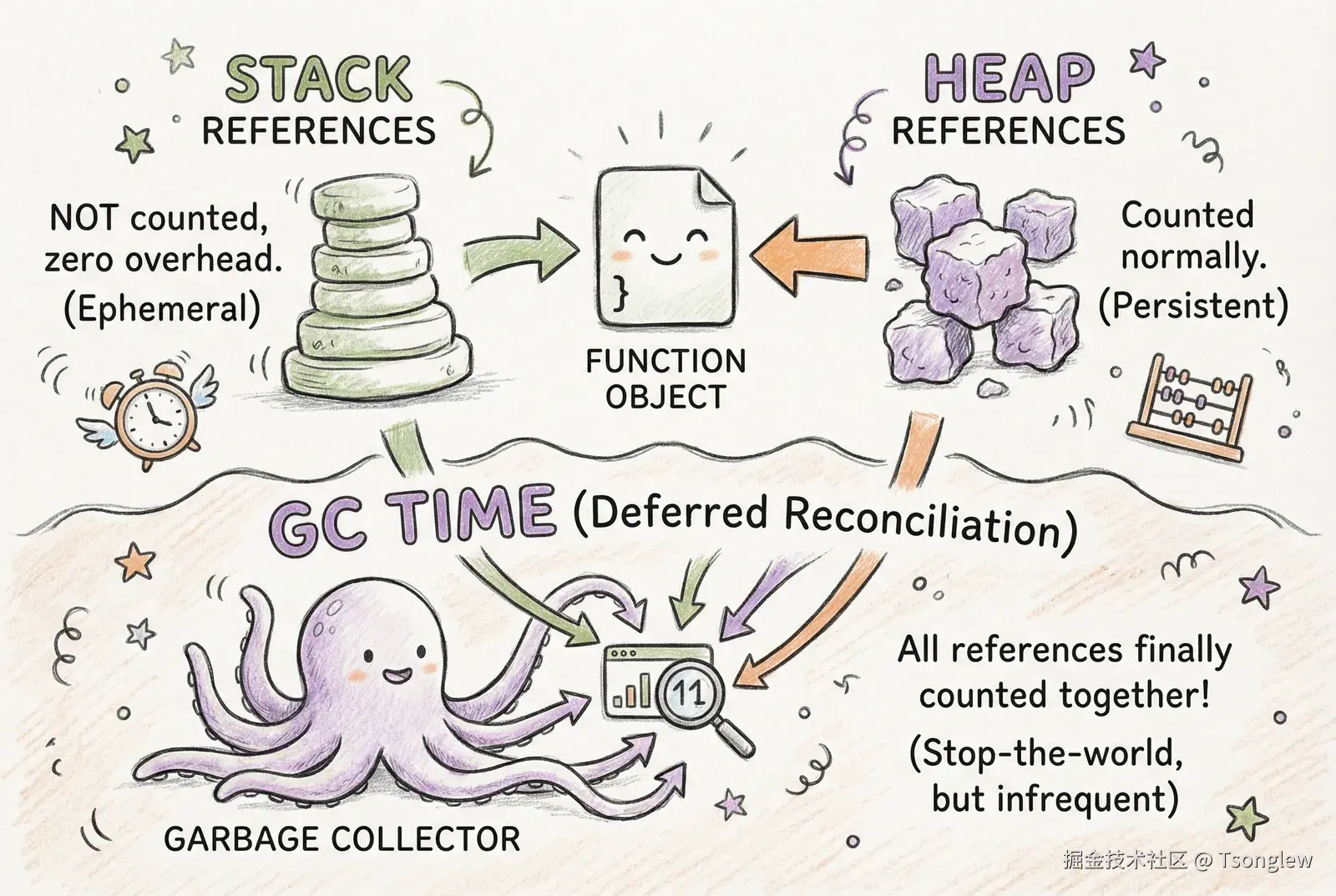
延迟引用计数的核心是将引用分为两类:
- 堆引用(Heap References):存储在堆分配的对象中的引用,正常计数。
- 栈引用 (Stack References):存储在线程调用栈、局部变量、求值栈中的引用,不计数。
在 PyObject 结构中,使用引用计数字段的特定位来标记对象是否启用延迟引用计数:
c
#define _PyGC_BITS_DEFERRED (1 << 1) // 第二个最低位
// 判断对象是否使用延迟引用计数
if (ob_ref_local & _PyGC_BITS_DEFERRED) {
// 这是一个延迟引用计数对象
// 来自栈的引用不更新计数
}当一个使用延迟引用计数的对象被访问时:
- 从堆对象引用:正常增减引用计数(使用原子操作)。
- 从栈帧引用:不修改引用计数,零开销。
垃圾回收阶段的处理
由于栈引用不计数,对象的引用计数字段只反映部分真实引用:
scss
真实引用计数 = 计数的引用 + 延迟的引用(栈引用)在垃圾回收阶段,GC 会执行以下步骤:
- Stop-the-World:暂停所有 Python 线程。
- 扫描所有线程的栈:遍历每个线程的调用栈、局部变量、求值栈,找出所有对延迟引用计数对象的引用。
- 计算真实引用计数:将栈引用数量加到对象的引用计数上,得到对象的真实引用计数。
- 回收不可达对象:引用计数为零的对象被标记为可回收。
这个设计的巧妙之处在于:将高频操作(引用计数修改)的开销转移到低频操作(垃圾回收) ,大幅减少了热点对象的争用问题。citation
哪些对象使用延迟引用计数
根据 PEP 703 和相关实现,以下类型的对象默认启用延迟引用计数:
- 函数对象(
PyFunctionObject) - 代码对象(
PyCodeObject) - 模块对象(
PyModuleObject) - 方法对象(
PyMethodObject) - 堆类型对象(Heap Type Objects)
这些对象的共同特点是:生命周期长、被频繁访问、很少被销毁 。citation citation
不朽对象(Immortal Objects)
永生化的概念
不朽对象(Immortal Objects,或称"永生对象")是自由线程实现中的第三项关键技术。它针对的是生命周期与解释器相同的全局对象,例如:
- 内置类型对象(
int、str、list等) - 单例对象(
None、True、False) - 小整数池(
-5到256的整数) - 内置函数和模块
这些对象在整个程序运行期间都不应该被销毁。传统 CPython 通过非常高的初始引用计数(如 Py_REFCNT_IMMORTAL = INT_MAX)来"伪造"永生效果,但在多线程环境下,即使是读取这些对象的引用计数也可能导致缓存争用。
自由线程的解决方案是:在引用计数字段中设置特殊标记,让所有引用计数操作都跳过这些对象。
在 Python 3.13 中的实现
在 Python 3.13 的自由线程构建中,不朽对象通过设置引用计数的最高位来标记:
C
#define _Py_IMMORTAL_REFCNT_BIT (1UL << (sizeof(Py_ssize_t) * 8 - 1))
// 标记对象为不朽
ob->ob_ref_local |= _Py_IMMORTAL_REFCNT_BIT;
// 检查对象是否不朽
if (ob->ob_ref_local & _Py_IMMORTAL_REFCNT_BIT) {
// 跳过引用计数操作
return;
}这个设计非常高效:每次引用计数操作只需一次位测试,就可以决定是否跳过操作。
副作用 :在 Python 3.13 中,许多对象被激进地标记为不朽,包括函数对象、类对象等。这导致这些对象即使不再被使用也不会被回收,可能导致内存使用增加 。citation
在 Python 3.14 中的改进
Python 3.14 通过与延迟引用计数的深度集成,显著减少了需要永生化的对象数量:
- 大多数函数、类对象不再需要永生化,而是使用延迟引用计数。
- 只有真正的全局单例对象(如
None、内置类型)保持不朽状态。
这一改进大幅降低了内存占用,同时保持了性能优势。citation
内存分配器的变革:从 pymalloc 到 mimalloc
为什么要更换分配器
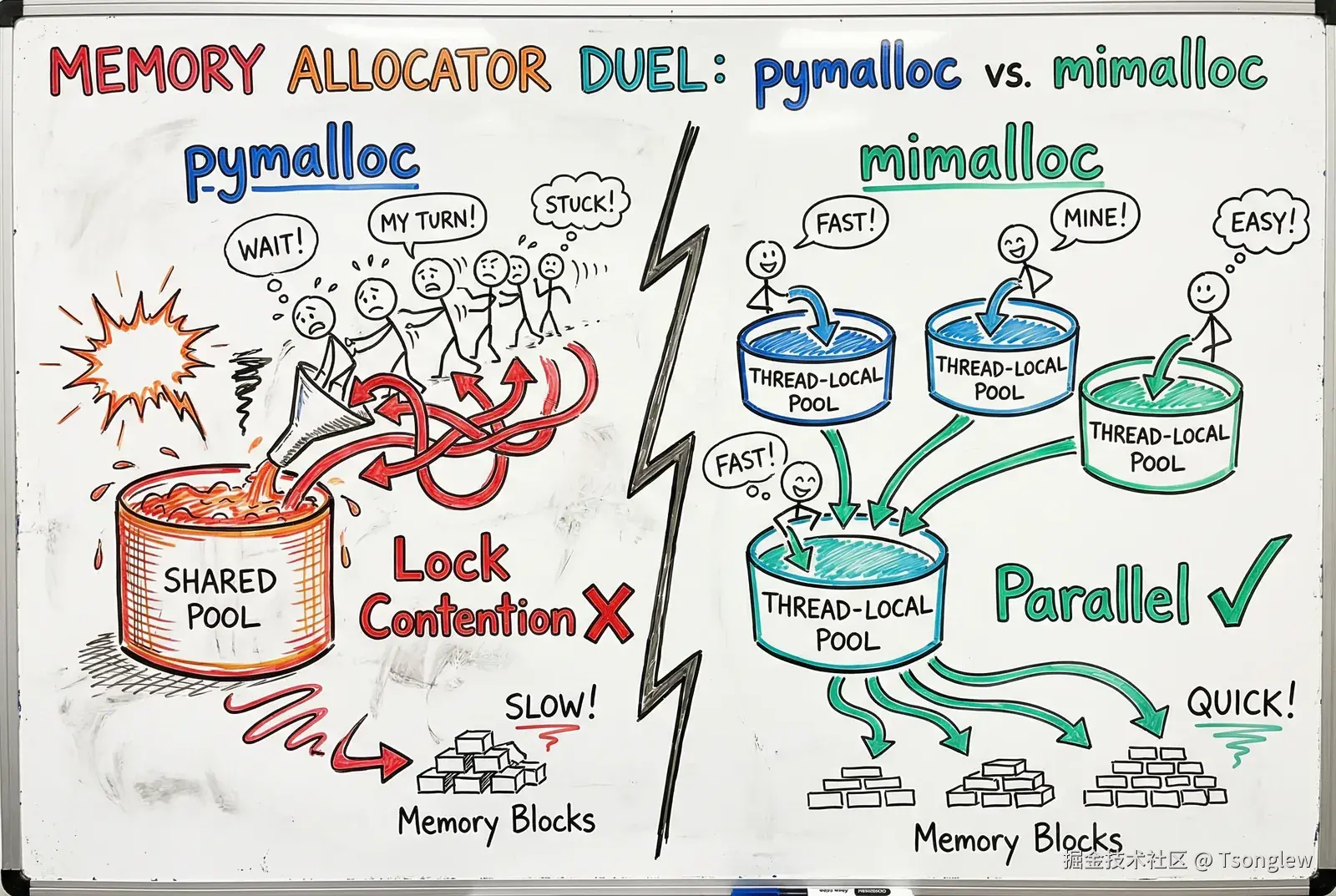
传统 CPython 使用 pymalloc 作为小对象内存分配器。pymalloc 针对单线程环境优化,通过内存池(memory pool)技术减少系统调用开销,性能优异。但它有一个致命缺陷:不是线程安全的。
在自由线程环境下,多个线程可能同时分配和释放内存。为了保证 pymalloc 的线程安全,需要为整个分配器加锁,这会导致严重的性能瓶颈------内存分配器会成为新的"全局锁"。
mimalloc 的优势
PEP 703 选择了 mimalloc(pronounced "me-malloc")作为自由线程构建的默认分配器。mimalloc 是微软研究院为 Koka 和 Lean 语言开发的高性能分配器,具有以下特性:
- 线程安全且无锁:每个线程拥有独立的内存池,大多数分配操作无需全局同步。
- 缓存友好:利用现代 CPU 的缓存层次结构,减少缓存缺失。
- 低碎片率:通过智能的分配策略,减少内存碎片。
- 成熟稳定:已在多个生产环境中验证,性能和可靠性有保障。
通过切换到 mimalloc,自由线程 Python 在多线程场景下的内存分配性能大幅提升,避免了内存分配器成为新的瓶颈。citation citation
配置方式
在自由线程构建中,mimalloc 是默认启用的:
Bash
./configure --disable-gil
make用户无需额外配置,构建系统会自动链接 mimalloc 库。
内置类型的内部锁机制
线程安全的挑战
移除 GIL 后,Python 内置类型(如 dict、list、set)的线程安全成为新的挑战。这些类型的内部数据结构(哈希表、动态数组)在并发修改时容易出现数据不一致、内存损坏等问题。
细粒度锁的设计
自由线程 Python 为这些内置类型引入了细粒度的内部锁。每个容器对象都拥有自己的锁,用于保护其内部状态:
C
typedef struct {
PyObject_HEAD
Py_ssize_t ob_size;
PyObject **ob_item;
PyMutex lock; // 每个 list 对象独有的锁
} PyListObject;关键操作(如元素插入、删除、查找)会自动获取和释放这些内部锁:
C
PyObject* PyList_GetItem(PyObject *op, Py_ssize_t i) {
PyListObject *list = (PyListObject *)op;
PyMutex_Lock(&list->lock); // 获取锁
PyObject *item = list->ob_item[i];
Py_INCREF(item);
PyMutex_Unlock(&list->lock); // 释放锁
return item;
}锁的设计借鉴 WebKit
CPython 的内部锁实现受到了 WebKit 浏览器引擎的启发。WebKit 在多线程渲染引擎中使用了高效的锁机制,能够在低争用场景下提供接近无锁的性能,在高争用场景下保证公平性。citation
核心特点:
- 自适应自旋锁:在短暂等待时使用忙等待(busy-waiting),避免线程上下文切换开销。
- 快速路径优化:无争用时的获取/释放操作只需少量原子操作。
- 公平性保证:长时间等待时退化为操作系统级互斥锁,避免饥饿。
行为一致性
重要的是,自由线程 Python 并不保证内置类型在并发修改下的特定行为 。官方文档明确指出:Python 历史上从未对并发修改这些类型的行为提供保证,开发者不应依赖当前的实现细节。citation
这意味着,虽然内部锁保证了不会出现内存损坏或崩溃,但并发修改 dict 或 list 的结果可能是未定义的 。开发者仍需使用显式的同步机制(如 threading.Lock)来保护共享可变状态。
垃圾回收器的重新设计
传统分代回收的局限
CPython 传统的垃圾回收器采用分代回收(generational GC)策略,基于"弱代假设"(weak generational hypothesis):大多数对象在年轻时就会死亡。对象被分为三代(generation 0、1、2),年轻代的回收频率远高于老年代。
但在自由线程环境下,分代回收面临新的挑战:
- 对象在不同线程间传递时,其"年龄"的概念变得模糊。
- 延迟引用计数使得某些对象的生命周期判断变得复杂。
- 分代回收需要扫描跨代引用,在多线程环境下开销很大。
新的 Stop-the-World GC
自由线程构建采用了更简洁的垃圾回收策略:Stop-the-World + 精确引用计数扫描 。citation
核心流程:
- 暂停所有线程:使用类似 Go 语言的"安全点"(safepoint)机制,确保所有线程在安全状态下暂停。
- 扫描所有线程的栈:遍历每个线程的调用栈、局部变量、求值栈,找出所有活跃引用。
- 计算精确引用计数:结合偏向引用计数、延迟引用计数和栈扫描结果,计算每个对象的真实引用计数。
- 回收不可达对象:引用计数为零的对象被回收,其内存被释放。
- 恢复所有线程:GC 完成后,所有线程恢复执行。

QSBR(Quiescent State Based Reclamation)
为了减少 GC 暂停时间,自由线程 Python 引入了 QSBR 技术,这是一种源自 FreeBSD 的内存回收策略。citation
QSBR 的核心思想:如果一个对象在所有线程都经历了至少一次"静默期"(quiescent state)后才被回收,那么可以保证没有线程正在访问该对象。
这允许 GC 延迟某些对象的实际内存释放,将回收工作分散到多个 GC 周期,减少单次 GC 的暂停时间。
放弃分代假设
与传统的三代回收不同,自由线程 GC 不再区分对象代际,所有对象都平等对待。这简化了实现,减少了跨代引用的扫描开销,且在实际测试中,性能并未显著下降。
专用自适应解释器(PEP 659)的取舍
PEP 659 的背景
PEP 659 引入了专用自适应解释器(Specializing Adaptive Interpreter),是 Python 3.11 的重大性能突破。它通过在运行时观察代码的实际类型,将通用字节码指令"专化"(specialize)为针对特定类型优化的快速指令。
例如,通用的 BINARY_ADD 指令可能被专化为:
BINARY_ADD_INT:专门处理整数加法,跳过类型检查。BINARY_ADD_FLOAT:专门处理浮点数加法。BINARY_ADD_UNICODE:专门处理字符串拼接。
这项技术在 Python 3.11 和 3.12 中带来了 10-25% 的性能提升。
在 Python 3.13 中被禁用
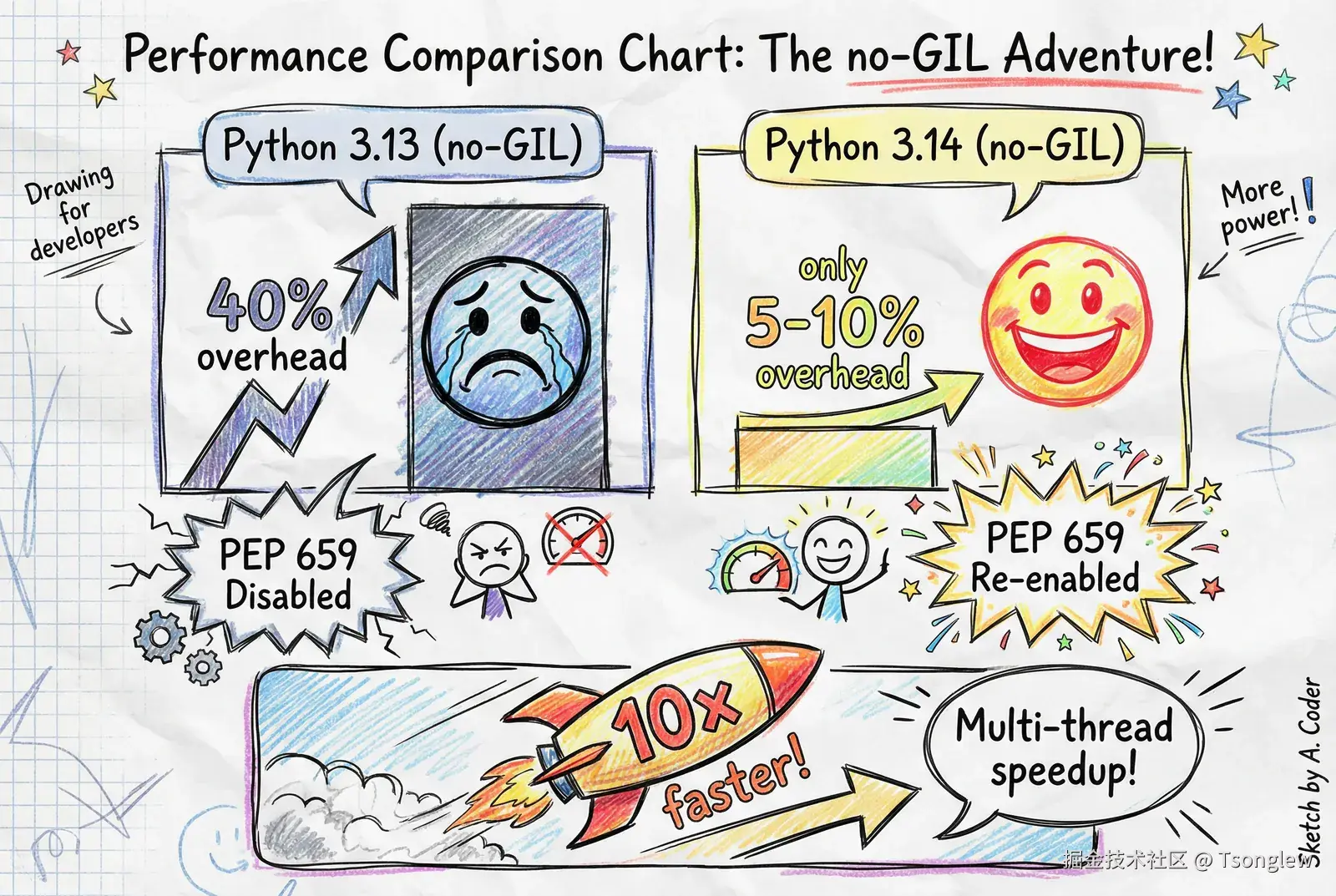
然而,在 Python 3.13 的自由线程构建中,PEP 659 被完全禁用 。citation 原因有二:
- 线程安全问题:专化的字节码缓存(inline cache)是可变的,多个线程可能同时读写同一个缓存条目,需要复杂的同步机制。
- 实现优先级:为了尽快推出自由线程的实验版本,团队决定先禁用这一特性,专注于核心的 GIL 移除工作。
这导致自由线程 Python 3.13 的单线程性能下降约 40% ,这是一个巨大的代价。
在 Python 3.14 中重新启用
经过一年的努力,Python 3.14 成功重新启用了专用自适应解释器 ,同时保持线程安全。citation 技术要点:
- 线程本地缓存:每个线程维护自己的专化字节码缓存,避免跨线程争用。
- 延迟同步:缓存的更新采用懒惰策略,减少同步开销。
- 保守专化:在多线程环境下,某些难以专化的操作保持通用指令,避免过度优化。
重新启用 PEP 659 后,自由线程 Python 3.14 的单线程性能损失降至 5-10% ,基本达到了可接受的水平。citation
技术权衡与性能影响
单线程性能的代价
自由线程模式的实现不可避免地引入了额外开销:
| 开销来源 | 影响 | Python 3.13 | Python 3.14 |
|---|---|---|---|
| 偏向引用计数的位测试 | 每次引用计数操作 | ~5% | ~3% |
| 内部锁的获取/释放 | 容器操作 | ~10% | ~5% |
| 延迟引用计数的标记检查 | 对象访问 | ~5% | ~3% |
| 禁用 PEP 659(仅 3.13) | 所有操作 | ~40% | 0%(已重新启用) |
| 总体单线程开销 | ~40% | ~5-10% |
可以看到,Python 3.14 通过重新启用 PEP 659 和大量优化,将单线程性能损失控制在可接受的范围内。
多线程性能的巨大收益
在多线程 CPU 密集型场景下,自由线程带来的性能提升是颠覆性的:
Python
# 质数计算基准测试(32 核 CPU)
# 标准 Python 3.12: 3.70 秒
# 自由线程 3.13t: 0.35 秒 (10.5x 加速)
# 自由线程 3.14t: 0.32 秒 (11.6x 加速)在数据科学场景(DataFrame 行处理):
Python
# StaticFrame DataFrame 处理(1000x1000)
# 标准 Python 3.13 多线程: 39.9 ms (GIL 导致性能退化)
# 自由线程 3.13t 多线程: 7.89 ms (5x 加速)这些数字充分证明:对于能够并行化的 CPU 密集型任务,自由线程带来的性能提升远超单线程的性能损失。
适用场景
| 场景 | 建议 |
|---|---|
| CPU 密集 + 可并行 | 强烈推荐自由线程 |
| I/O 密集 | 两者差异不大,可用自由线程 |
| CPU 密集 + 单线程 | 传统 Python 更优(避免 5-10% 损失) |
| 混合负载 | 评估多线程部分的收益 |
总结:技术实现的整体架构
Python 自由线程的实现是一项系统工程,涉及解释器的方方面面。以下是核心技术的整体架构:
yaml
┌─────────────────────────────────────────────────────────────────┐
│ Python 自由线程架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────────┐ ┌──────────────────┐ │
│ │ 内存管理层 │ │ 解释器层 │ │
│ ├───────────────────┤ ├──────────────────┤ │
│ │ • 偏向引用计数 │ │ • 字节码执行 │ │
│ │ • 延迟引用计数 │ │ • PEP 659 专化 │ │
│ │ • 不朽对象标记 │ │ • 栈帧管理 │ │
│ │ • mimalloc 分配器 │ │ • 异常处理 │ │
│ └───────────────────┘ └──────────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────────────────────────────────────┐ │
│ │ 垃圾回收器 (GC) │ │
│ ├─────────────────────────────────────────────┤ │
│ │ • Stop-the-World 暂停 │ │
│ │ • 精确引用计数扫描 │ │
│ │ • QSBR 延迟回收 │ │
│ │ • 放弃分代假设 │ │
│ └─────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────┐ │
│ │ 内置类型层 │ │
│ ├─────────────────────────────────────────────┤ │
│ │ • dict: 细粒度哈希表锁 │ │
│ │ • list: 动态数组保护锁 │ │
│ │ • set: 集合操作锁 │ │
│ │ • tuple: 不可变,无需锁 │ │
│ └─────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘这些技术相互配合,共同实现了以下目标:
- 正确性:通过偏向引用计数、细粒度锁、GC 扫描,确保多线程环境下的内存安全。
- 性能:通过延迟引用计数、mimalloc、PEP 659,最大化单线程和多线程性能。
- 兼容性:保持 Python 语义不变,现有代码无需修改即可运行。
PEP 703 的实现是 Python 社区多年努力的结晶,它借鉴了 Swift、WebKit、Go、FreeBSD 等多个项目的先进技术,代表了动态语言在多核时代的一次重大进化。随着 Python 3.14 的发布和生态系统的逐步适配,自由线程将为 Python 在高性能计算、人工智能、科学计算等领域开辟全新的可能性。