请介绍 C++ 中 static 关键字的作用
C++ 中的 static 关键字是多场景下的核心修饰符,其作用覆盖变量、函数、类成员等维度,核心特征是改变作用域、存储周期或链接属性,不同使用场景下的行为差异是面试考察的重点,以下分场景详细说明:
1. 修饰全局作用域的变量/函数
全局作用域下的变量和函数默认具有"外部链接属性",即能被其他编译单元(. 文件)通过 extern 引用。static 修饰后会将其链接属性改为"内部链接",仅当前编译单元可见,避免多文件同名符号冲突。示例代码:
// file1.cpp
static int global_static_var = 10; // 仅file1.cpp可见
static void static_func() { // 仅file1.cpp可见
global_static_var++;
}
// file2.cpp
extern int global_static_var; // 编译报错:无法解析的外部符号
extern void static_func(); // 编译报错:无法解析的外部符号关键点 :该场景下 static 解决"全局符号污染"问题,是模块化编程的基础手段,面试中提及"编译单元隔离"可加分。
2. 修饰局部变量(函数内)
函数内的局部变量默认是"自动存储周期"(栈上分配,函数执行完销毁),static 修饰后变为"静态存储周期"(数据段/全局区分配,程序启动时初始化,退出时销毁),且仅初始化一次 ,后续函数调用会保留上一次的值。示例代码:
#include <iostream>
void count_call() {
static int call_count = 0; // 仅第一次调用时初始化
call_count++;
std::cout << "调用次数:" << call_count << std::endl;
}
int main() {
count_call(); // 输出:调用次数:1
count_call(); // 输出:调用次数:2
return 0;
}关键点:静态局部变量的初始化线程安全(C++11 及以上),面试中提及这一细节可加分;其生命周期与程序一致,但作用域仍局限于函数内。
3. 修饰类的成员变量
类内的 static 成员变量属于"类级别的变量",而非"对象级别的变量"------所有类的实例共享同一个 static 成员变量,不占用对象的内存空间,需在类外单独初始化(否则链接报错)。示例代码:
class Student {
public:
static int total_count; // 类内声明
Student() { total_count++; }
};
int Student::total_count = 0; // 类外初始化(必须)
int main() {
Student s1;
Student s2;
std::cout << Student::total_count << std::endl; // 输出:2(直接通过类访问)
std::cout << s1.total_count << std::endl; // 输出:2(通过对象访问,不推荐)
return 0;
}关键点 :static 成员变量可通过 类名::变量名 直接访问,无需创建对象;若为 private 修饰,需通过 static 成员函数访问。
4. 修饰类的成员函数
类内的 static 成员函数属于类本身,而非对象,因此有两个核心特征:① 没有隐含的 this 指针;② 只能访问类的 static 成员变量/函数,无法访问非静态成员(因为非静态成员依赖具体对象)。示例代码:
class MathUtil {
private:
static const double PI; // 静态常量成员
public:
static double circle_area(double r) { // 静态成员函数
return PI * r * r; // 仅能访问静态成员PI
}
};
const double MathUtil::PI = 3.1415926;
int main() {
// 无需创建对象,直接调用静态成员函数
std::cout << MathUtil::circle_area(2) << std::endl; // 输出:12.5663704
return 0;
}关键点 :static 成员函数常用来实现"工具类"的无状态方法,面试中结合"单例模式"(如通过 static 函数返回唯一实例)举例可加分。
记忆法推荐
- 场景分类记忆法 :将
static分为"全局/局部/类成员"三大场景,每个场景记住"核心改变的属性"(全局:链接属性;局部:存储周期;类成员:归属关系)。 - 关键词联想记忆法:用"共享、隔离、持久"三个关键词概括------类静态成员是"共享",全局静态是"隔离",局部静态是"持久"。
请阐述 C++ 智能指针的设计思想和核心作用(提示:基于 RAII 思想,防止内存泄漏)
C++ 智能指针是解决手动内存管理缺陷的核心工具,其设计完全基于 RAII(Resource Acquisition Is Initialization,资源获取即初始化) 思想,核心目标是消除内存泄漏、野指针等问题,以下从设计思想到核心作用逐层拆解:
一、RAII 思想的核心逻辑
RAII 是 C++ 特有的资源管理范式,其核心原理是:将资源的生命周期绑定到对象的生命周期 ------在对象构造时获取资源(如分配内存、打开文件、获取锁),在对象析构时自动释放资源(无需手动调用 delete/close 等)。因为 C++ 中栈对象的析构是编译器自动触发的(离开作用域时必然执行),因此通过 RAII 可确保资源"有获取必有释放",从根本上避免因忘记释放、异常中断等导致的资源泄漏。
智能指针是 RAII 思想在"动态内存管理"场景的具体实现:智能指针本身是栈上的对象,其内部封装了裸指针(T*),构造时接管裸指针指向的堆内存,析构时自动调用 delete 释放该内存(或根据类型执行其他释放逻辑)。
二、智能指针的核心设计思想
智能指针并非单一类型,C++ 标准库(<memory> 头文件)提供了 unique_ptr、shared_ptr、weak_ptr 三种核心智能指针,其设计各有侧重,但底层遵循统一的 RAII 框架,具体设计要点如下:
| 智能指针类型 | 核心设计逻辑 | 底层实现关键 |
|---|---|---|
unique_ptr |
独占式所有权:同一时刻仅一个 unique_ptr 指向某块内存,禁止拷贝(C++11 仅支持移动),析构时直接释放内存 |
禁用拷贝构造/赋值运算符,实现移动语义(std::move) |
shared_ptr |
共享式所有权:多个 shared_ptr 可指向同一块内存,通过"引用计数"追踪指向该内存的指针数量,计数为 0 时释放内存 |
内部维护两个指针:指向数据的裸指针 + 指向控制块(存储引用计数、析构函数等)的指针 |
weak_ptr |
弱引用:配合 shared_ptr 使用,不拥有内存所有权,不增加引用计数,用于解决 shared_ptr 的循环引用问题 |
指向 shared_ptr 的控制块,仅观察内存状态,需通过 lock() 转为 shared_ptr 才能访问数据 |
三、智能指针的核心作用
-
自动释放内存,杜绝内存泄漏 手动管理内存时,常见泄漏场景包括:忘记调用
delete、函数执行中抛出异常导致delete未执行。智能指针的析构函数由编译器自动调用,无论正常退出还是异常退出,都能确保内存释放。反例(手动管理的问题):void risky_func() {
int* p = new int(10);
if (some_condition) {
return; // 提前返回,p未释放,内存泄漏
}
// 若此处抛出异常,后续delete无法执行
do_something();
delete p;
}
正例(智能指针解决):
#include <memory>
void safe_func() {
std::unique_ptr<int> p(new int(10)); // 构造时获取内存
if (some_condition) {
return; // p离开作用域,析构自动释放内存
}
do_something(); // 即使抛出异常,p析构仍执行
}-
避免野指针问题 野指针是指指向已释放内存的指针,手动管理时若重复释放、释放后未置空,易导致程序崩溃。智能指针通过所有权管理避免该问题:
unique_ptr释放内存后会将内部裸指针置空,shared_ptr计数为 0 时才释放,且释放后所有指向该内存的shared_ptr内部裸指针均置空。示例:std::shared_ptr
sp1(new int(20));
std::shared_ptrsp2 = sp1;
sp1.reset(); // 释放sp1的所有权,引用计数变为1
sp2.reset(); // 引用计数变为0,内存释放,内部裸指针置空
// 此时sp1、sp2均指向nullptr,无野指针风险 -
简化内存管理逻辑,降低编码复杂度 手动管理动态数组、自定义析构逻辑时,需编写大量冗余代码,智能指针可简化这一过程。例如
unique_ptr支持自定义删除器,可用于管理非内存资源(如文件句柄、线程句柄)。示例(自定义删除器管理文件):#include
#include
// 自定义删除器:关闭文件
auto file_deleter = [](std::ofstream* f) {
f->close();
delete f;
};void manage_file() {
std::unique_ptr<std::ofstream, decltype(file_deleter)> fp(new std::ofstream("test.txt"), file_deleter);
*fp << "hello world";
} // fp析构时,自动调用自定义删除器关闭文件并释放内存 -
解决循环引用问题(
weak_ptr的核心价值)shared_ptr的循环引用会导致引用计数无法归 0,内存永远无法释放。例如两个对象互相持有对方的shared_ptr,析构时彼此的计数都无法减到 0。weak_ptr作为弱引用,不增加计数,可打破循环。示例(循环引用问题):struct Node {
std::shared_ptrnext; // 循环引用
~Node() { std::cout << "Node析构" << std::endl; }
};void cycle_ref() {
std::shared_ptrn1(new Node);
std::shared_ptrn2(new Node);
n1->next = n2;
n2->next = n1;
} // 函数结束后,n1、n2析构,但引用计数均为1,内存泄漏,无析构输出
解决(改用 weak_ptr):
struct Node {
std::weak_ptr<Node> next; // 弱引用,不增加计数
~Node() { std::cout << "Node析构" << std::endl; }
};
void no_cycle_ref() {
std::shared_ptr<Node> n1(new Node);
std::shared_ptr<Node> n2(new Node);
n1->next = n2;
n2->next = n1;
} // 函数结束后,n1、n2析构,计数归0,内存释放,输出两次"Node析构"面试加分点
- 提及
shared_ptr的控制块不仅存储引用计数,还存储"弱引用计数"(weak_ptr依赖),析构时机为"引用计数和弱引用计数均为 0"; - 说明
unique_ptr是轻量级智能指针(无额外计数开销),性能优于shared_ptr,优先使用unique_ptr; - 指出智能指针不能管理栈内存(如
std::unique_ptr<int> p(&x),析构时会调用delete释放栈内存,导致崩溃)。
记忆法推荐
- 框架记忆法:先记住 RAII 核心(对象绑定资源,析构释放),再按"所有权类型"分类记忆三种智能指针:独占(unique)、共享(shared)、弱引用(weak),每个类型对应一个核心问题(unique 解决独占,shared 解决共享,weak 解决循环引用)。
- 口诀记忆法:"RAII 绑定生命周期,unique 独占不拷贝,shared 计数管共享,weak 破环不计数"。
C++ 智能指针离开作用域就会释放内存吗?(补充:shared_ptr 需引用计数器为 0 时,才会调用 delete 释放内存)
C++ 智能指针离开作用域时是否释放内存,取决于智能指针的类型、所有权状态以及引用计数(针对 shared_ptr),不能简单判定"一定会释放"或"一定不会释放",需分类型、分场景详细分析,核心结论是:仅当智能指针对内存的"所有权"完全失效时,才会触发内存释放,离开作用域只是触发智能指针析构的条件,而非释放内存的充分条件。
一、unique_ptr:离开作用域通常释放内存(特殊场景除外)
unique_ptr 是"独占式智能指针",其核心规则是"同一时刻仅一个 unique_ptr 拥有对某块内存的所有权",且不支持拷贝(C++11 起仅支持移动语义)。当 unique_ptr 离开作用域时,会触发析构函数执行,析构逻辑为:若内部封装的裸指针非空(即拥有内存所有权),则调用 delete 释放内存,并将裸指针置空;若裸指针为空(已释放或未接管内存),则不执行任何操作。
1. 正常场景:离开作用域释放内存
unique_ptr 接管内存后,未发生所有权转移,离开作用域时析构释放内存。示例代码:
#include <memory>
#include <iostream>
void test_unique_normal() {
std::unique_ptr<int> up(new int(100)); // up接管堆内存
std::cout << *up << std::endl; // 输出:100
} // up离开作用域,析构调用delete释放内存
int main() {
test_unique_normal();
// 此处内存已释放,无泄漏
return 0;
}2. 特殊场景:离开作用域不释放内存
以下场景中,unique_ptr 离开作用域时已失去内存所有权,因此不会释放内存:
-
场景1:通过
std::move转移所有权std::move会将unique_ptr的所有权转移给另一个unique_ptr,原unique_ptr内部裸指针置空,析构时无内存可释放。示例代码:void test_unique_move() {
std::unique_ptrup1(new int(200));
std::unique_ptrup2 = std::move(up1); // up1所有权转移给up2,up1变为空
} // up1析构:裸指针为空,不释放;up2析构:释放内存(200所在堆空间) -
场景2:手动调用
reset()释放所有权reset()是unique_ptr的成员函数,调用后会释放当前管理的内存(若有),并将裸指针置空;若传入新的裸指针,则接管新内存。若在离开作用域前调用reset()且未传入新指针,析构时无内存可释放。示例代码:void test_unique_reset() {
std::unique_ptrup(new int(300));
up.reset(); // 释放300所在内存,up变为空
} // up离开作用域,析构时裸指针为空,不释放内存 -
场景3:手动调用
release()释放所有权release()会返回unique_ptr内部的裸指针,并将自身裸指针置空,但不会释放内存(需手动接管返回的指针)。若未接管,会导致内存泄漏;若接管,原unique_ptr析构时不释放。示例代码:void test_unique_release() {
std::unique_ptrup(new int(400));
int* raw_ptr = up.release(); // up裸指针置空,返回400的地址
delete raw_ptr; // 手动释放内存,避免泄漏
} // up离开作用域,析构时裸指针为空,不释放内存
二、shared_ptr:离开作用域仅减少引用计数,计数为0时才释放内存
shared_ptr 是"共享式智能指针",其内部维护一个控制块 (存储引用计数、弱引用计数、析构函数等),引用计数表示当前有多少个 shared_ptr 指向同一块内存。当 shared_ptr 离开作用域触发析构时,核心逻辑是:
- 将控制块中的引用计数减 1;
- 若减 1 后引用计数为 0,则调用
delete释放内存,并清理控制块(弱引用计数为 0 时); - 若减 1 后引用计数仍大于 0,则仅更新计数,不释放内存。
1. 场景1:引用计数为1,离开作用域释放内存
仅一个 shared_ptr 指向内存,离开作用域时计数减为 0,释放内存。示例代码:
#include <memory>
#include <iostream>
void test_shared_single() {
std::shared_ptr<int> sp(new int(500));
std::cout << sp.use_count() << std::endl; // 输出:1
} // sp析构,计数减为0,释放500所在内存2. 场景2:引用计数大于1,离开作用域仅减计数,不释放内存
多个 shared_ptr 共享同一块内存,其中一个离开作用域时,计数减少但未到 0,内存仍保留。示例代码:
void test_shared_multi() {
std::shared_ptr<int> sp1(new int(600));
{
std::shared_ptr<int> sp2 = sp1; // 计数变为2
std::cout << sp1.use_count() << std::endl; // 输出:2
} // sp2离开作用域,计数减为1,内存未释放
std::cout << *sp1 << std::endl; // 输出:600(内存仍可用)
} // sp1离开作用域,计数减为0,释放内存3. 特殊场景:循环引用导致计数无法归0,离开作用域也不释放
若两个 shared_ptr 管理的对象互相持有对方的 shared_ptr,会形成循环引用,导致引用计数永远无法归 0,即使所有 shared_ptr 都离开作用域,内存也不会释放(内存泄漏)。示例代码:
struct A {
std::shared_ptr<B> b_ptr;
~A() { std::cout << "A析构" << std::endl; }
};
struct B {
std::shared_ptr<A> a_ptr;
~B() { std::cout << "B析构" << std::endl; }
};
void test_shared_cycle() {
std::shared_ptr<A> a(new A);
std::shared_ptr<B> b(new B);
a->b_ptr = b; // a的b_ptr指向b,b的计数变为2
b->a_ptr = a; // b的a_ptr指向a,a的计数变为2
} // a、b离开作用域,计数各减1(变为1),未释放内存,无析构输出该问题需通过 weak_ptr 解决:将其中一个对象的成员改为 weak_ptr(弱引用,不增加计数),打破循环。
三、weak_ptr:离开作用域不释放内存(仅影响弱引用计数)
weak_ptr 是"弱引用智能指针",不拥有内存所有权,仅观察 shared_ptr 管理的内存。其析构逻辑为:将控制块中的弱引用计数 减 1,若弱引用计数和引用计数均为 0,则清理控制块,但不会释放数据内存(数据内存的释放仅由 shared_ptr 的引用计数决定)。因此无论 weak_ptr 是否离开作用域,都不会直接触发内存释放。示例代码:
void test_weak() {
std::shared_ptr<int> sp(new int(700));
std::weak_ptr<int> wp = sp; // 弱引用计数+1,引用计数仍为1
std::cout << sp.use_count() << std::endl; // 输出:1
} // wp析构:弱引用计数-1;sp析构:引用计数-1=0,释放内存面试加分点
- 区分"数据内存释放"和"控制块释放":
shared_ptr的控制块包含引用计数、弱引用计数等信息,数据内存释放由引用计数决定,控制块释放由"引用计数 + 弱引用计数"均为 0 决定; - 指出
unique_ptr的release()仅转移所有权不释放内存,而reset()会释放内存(若未传入新指针),这是容易混淆的细节; - 说明智能指针释放内存的本质是"所有权失效",离开作用域只是触发析构的条件,而非释放内存的充分条件。
记忆法推荐
- 条件拆分记忆法:将"释放内存"拆分为两个条件------① 智能指针析构(离开作用域);② 所有权失效(unique_ptr 未转移/reset,shared_ptr 计数归 0),两个条件同时满足才释放。
- 类型对比记忆法 :用表格对比三种智能指针的析构行为:
- unique_ptr:析构 → 有所有权则释放;
- shared_ptr:析构 → 计数-1 → 计数=0则释放;
- weak_ptr:析构 → 弱计数-1 → 不释放数据内存。
请解释 C++ 中的虚函数概念,并说明其底层实现原理
C++ 中的虚函数是实现"多态"(运行时多态/动态多态)的核心机制,其核心价值是让程序在运行时根据对象的实际类型(而非指针/引用的静态类型)调用对应的成员函数,是面向对象编程中"封装、继承、多态"三大特性的关键支撑,以下从概念定义、使用规则到底层实现逐层解析:
一、虚函数的核心概念
虚函数是在基类中用 virtual 关键字修饰的成员函数,满足以下核心特征:
- 动态绑定:调用虚函数时,编译器不会在编译期确定调用哪个函数,而是在运行期根据对象的实际类型决定(静态绑定则是编译期根据指针/引用的类型确定);
- 继承覆盖 :派生类可重写(override)基类的虚函数,重写时
virtual关键字可省略(但推荐显式添加,增强可读性); - 必须是成员函数 :虚函数不能是
static成员函数(无this指针)、全局函数或友元函数。
1. 虚函数的基本使用(多态示例)
示例代码:
#include <iostream>
using namespace std;
// 基类
class Animal {
public:
// 虚函数:动物叫声
virtual void make_sound() {
cout << "未知动物叫声" << endl;
}
// 非虚函数
void eat() {
cout << "动物进食" << endl;
}
};
// 派生类1:猫
class Cat : public Animal {
public:
// 重写基类虚函数(virtual可省略)
void make_sound() override { // override关键字(C++11):检查是否正确重写
cout << "喵喵喵" << endl;
}
// 重写基类非虚函数(静态绑定)
void eat() {
cout << "猫吃小鱼干" << endl;
}
};
// 派生类2:狗
class Dog : public Animal {
public:
void make_sound() override {
cout << "汪汪汪" << endl;
}
};
int main() {
// 基类指针指向派生类对象(多态核心场景)
Animal* a1 = new Cat();
Animal* a2 = new Dog();
// 虚函数:动态绑定,调用实际对象类型的函数
a1->make_sound(); // 输出:喵喵喵
a2->make_sound(); // 输出:汪汪汪
// 非虚函数:静态绑定,调用指针类型(Animal)的函数
a1->eat(); // 输出:动物进食
a2->eat(); // 输出:动物进食
delete a1;
delete a2;
return 0;
}关键点:
override关键字(C++11 引入):强制检查派生类函数是否正确重写基类虚函数(如函数名、参数、返回值不匹配时编译报错),面试中提及可加分;- 虚函数的重写要求"函数签名完全一致"(函数名、参数类型/个数/顺序、const 修饰符均一致),返回值需满足"协变"(如基类返回
Animal*,派生类可返回Cat*)。
2. 纯虚函数与抽象类
若基类的虚函数仅用于被派生类重写,无需实现,则可声明为"纯虚函数",格式为 virtual 返回值 函数名(参数) = 0;。包含纯虚函数的类称为"抽象类",抽象类无法实例化对象,仅能作为基类被继承。示例代码:
class Shape { // 抽象类
public:
virtual double area() = 0; // 纯虚函数:无实现
virtual ~Shape() {} // 基类析构函数建议设为虚函数(下文说明)
};
class Circle : public Shape {
private:
double r;
public:
Circle(double r_) : r(r_) {}
double area() override {
return 3.14 * r * r;
}
};
int main() {
// Shape s; // 编译报错:抽象类无法实例化
Shape* c = new Circle(2);
cout << c->area() << endl; // 输出:12.56
delete c;
return 0;
}面试加分点 :抽象类是"接口"的体现,C++ 无专门的 interface 关键字,通过纯虚函数实现接口功能,可结合"接口隔离原则"举例。
二、虚函数的底层实现原理
C++ 标准未规定虚函数的具体实现方式,但主流编译器(如 GCC、Clang、MSVC)均采用"虚函数表(vtable)+ 虚函数指针(vptr)"的方式实现,核心逻辑如下:
1. 核心结构:虚函数表(vtable)
- 虚函数表是一个全局只读的函数指针数组,每个包含虚函数的类(基类/派生类)都有独立的虚函数表;
- 虚函数表中存储的是该类所有虚函数的地址(按声明顺序排列);
- 若派生类重写了基类的虚函数,则派生类虚函数表中对应位置会替换为派生类函数的地址;未重写的虚函数则继承基类的函数地址;
- 纯虚函数在虚函数表中对应的位置通常存储
nullptr或指向一个"纯虚函数调用终止函数"的地址(调用会崩溃)。
2. 核心指针:虚函数指针(vptr)
- 每个包含虚函数的类的对象,其内存布局的起始位置(或固定位置)会包含一个隐藏的指针
vptr(虚函数指针),大小为一个指针的长度(32位系统4字节,64位系统8字节); - 对象构造时,编译器会根据对象的实际类型,将
vptr指向该类对应的虚函数表; vptr是对象级别的,每个对象有自己的vptr,但所有同类型对象的vptr指向同一个虚函数表。
3. 调用流程(以基类指针指向派生类对象为例)
Animal* a = new Cat();
a->make_sound(); // 虚函数调用调用步骤拆解:
- 编译器编译时,发现
make_sound()是虚函数,因此不直接确定函数地址,而是生成"通过 vptr 查找 vtable"的代码; - 运行时,获取指针
a指向的对象的vptr(该对象是Cat类型,vptr指向Cat的虚函数表); - 根据
make_sound()在虚函数表中的索引,从Cat的 vtable 中取出对应的函数地址; - 调用该地址对应的函数(
Cat::make_sound())。
4. 内存布局示例(64位系统)
以 Animal 和 Cat 类为例,内存布局简化如下:
| 类 | 内存布局(8字节为单位) | 虚函数表内容 |
|---|---|---|
| Animal | vptr(8字节) | \&Animal::make_sound |
| Cat | vptr(8字节) | \&Cat::make_sound |
若 Animal 有多个虚函数(如 make_sound()、move()),Cat 仅重写 make_sound(),则 Cat 的 vtable 为 [&Cat::make_sound, &Animal::move]。
5. 关键细节:虚析构函数
若基类析构函数不是虚函数,当用基类指针指向派生类对象并 delete 时,仅会调用基类析构函数,派生类析构函数不会执行,导致派生类的资源泄漏。将基类析构函数设为虚函数后,析构过程会通过 vtable 动态绑定,先调用派生类析构函数,再调用基类析构函数。反例(非虚析构):
class Base {
public:
~Base() { cout << "Base析构" << endl; } // 非虚析构
};
class Derived : public Base {
private:
int* p;
public:
Derived() { p = new int(10); }
~Derived() {
delete p;
cout << "Derived析构" << endl;
}
};
int main() {
Base* b = new Derived();
delete b; // 仅调用Base析构,Derived析构未执行,p指向的内存泄漏
return 0;
}正例(虚析构):
class Base {
public:
virtual ~Base() { cout << "Base析构" << endl; } // 虚析构
};
// Derived类同上
int main() {
Base* b = new Derived();
delete b;
// 输出:Derived析构 → Base析构,资源正常释放
return 0;
}面试加分点:虚析构函数是虚函数的重要应用场景,几乎是必考点,需重点掌握。
三、虚函数的性能开销
虚函数的动态绑定带来了少量性能开销,主要体现在:
- 内存开销 :每个含虚函数的对象增加一个
vptr的内存占用; - 运行时开销 :调用虚函数需通过
vptr查找vtable,比直接调用函数多1-2次内存访问(但现代编译器优化后,开销可忽略,除非是高频调用的核心函数); - 编译优化限制:编译器无法对虚函数进行内联优化(编译期无法确定函数地址),但部分编译器支持"去虚拟化"优化(如能确定对象类型时)。
记忆法推荐
- 流程拆解记忆法:将虚函数实现拆分为"表(vtable)+ 指针(vptr)+ 调用(查地址)"三步,先记住vtable是类级别的函数指针数组,vptr是对象级别的指针,再记住调用时"先找vptr→再查vtable→最后调函数"。
- 对比记忆法:将虚函数(动态绑定)与非虚函数(静态绑定)对比,记住"静态绑定看类型,动态绑定看对象;静态绑定编译期定,动态绑定运行期定"。
请对比 Python 和 C++ 的核心区别
Python 和 C++ 是两种设计理念、应用场景、底层机制差异极大的编程语言,核心区别覆盖类型系统、内存管理、执行方式、编程范式、性能、应用场景等多个维度,以下从核心维度展开对比,结合具体示例和面试关注点分析:
一、类型系统:动态类型 vs 静态类型
类型系统是两者最核心的区别之一,直接决定了编码风格、编译/运行时错误检测能力:
| 维度 | Python(动态类型) | C++(静态类型) |
|---|---|---|
| 类型确定时机 | 运行时确定变量类型(变量无类型,值有类型) | 编译期确定变量类型(变量有类型,值需匹配) |
| 变量声明 | 无需声明类型,直接赋值(如 x = 10) |
必须声明类型(如 int x = 10;) |
| 类型修改 | 运行时可修改变量类型(如 x = "hello") |
编译期确定类型,运行时不可修改 |
| 错误检测 | 类型错误仅在运行时暴露(如 1 + "2" 运行报错) |
类型错误在编译期暴露(如 int x = "10" 编译报错) |
示例对比:
# Python:动态类型
x = 10 # x绑定int类型的值
print(type(x)) # <class 'int'>
x = "python" # x重新绑定str类型的值
print(type(x)) # <class 'str'>
x + 5 # 运行时报错:TypeError: can only concatenate str (not "int") to str
// C++:静态类型
int x = 10; // 声明x为int类型
// x = "c++"; // 编译报错:无法从"const char [4]"转换为"int"
x + 5; // 编译通过,运行正常面试加分点:
- 动态类型的优势是"灵活、开发效率高",劣势是"类型错误晚发现、代码可读性依赖注释";
- 静态类型的优势是"编译期错误检测、性能优化空间大",劣势是"编码繁琐、灵活性低";
- C++11 引入的
auto关键字(如auto x = 10;)仅简化类型声明,仍为静态类型(编译期确定x为int),并非动态类型。
二、内存管理:自动垃圾回收 vs 手动/智能指针管理
内存管理的差异直接影响内存泄漏风险、编程复杂度:
| 维度 | Python | C++ |
|---|---|---|
| 核心机制 | 自动垃圾回收(GC):基于"引用计数"为主,"标记-清除""分代回收"为辅 | 手动管理(new/delete)+ 智能指针(RAII),无内置GC |
| 回收时机 | 引用计数为0时回收(循环引用通过GC解决) | 手动调用 delete 或智能指针析构时回收(循环引用需手动处理) |
| 开发者责任 | 无需关注内存释放,仅需注意循环引用(如列表互相引用) | 需手动管理内存(或使用智能指针),否则易导致泄漏/野指针 |
| 开销 | GC 带来运行时开销(暂停、内存碎片) | 无GC开销,但手动管理易出错 |
示例对比:
# Python:自动回收
def test_gc():
a = [1,2,3] # 引用计数=1
b = a # 引用计数=2
del a # 引用计数=1
b = None # 引用计数=0,内存被回收
# 无需手动释放,GC自动处理
// C++:手动/智能指针管理
void test_memory() {
// 手动管理:需手动delete,否则泄漏
int* p = new int(10);
delete p; // 必须释放,否则内存泄漏
// 智能指针:自动释放
std::unique_ptr<int> up(new int(20));
} // up离开作用域,自动析构释放内存面试加分点:
- Python 的循环引用(如
a = []; b = []; a.append(b); b.append(a))无法通过引用计数回收,需依赖"标记-清除"GC; - C++ 的智能指针是 RAII 思想的实现,是解决手动内存管理缺陷的核心,需重点掌握。
三、执行方式:解释型(字节码)vs 编译型
执行方式决定了运行效率、跨平台性和调试体验:
| 维度 | Python | C++ |
|---|---|---|
| 执行流程 | 源代码 → 字节码(.pyc)→ 解释器(CPython)执行字节码 | 源代码 → 编译器(GCC/Clang)→ 机器码(可执行文件)→ 直接运行 |
| 跨平台性 | 一次编写,到处运行(依赖Python解释器) | 需针对不同平台编译(如Windows编译为.exe,Linux编译为ELF) |
| 运行效率 | 字节码解释执行,效率低(比C++慢10-100倍) | 机器码直接执行,效率极高(接近硬件原生速度) |
| 调试体验 | 交互式解释器,支持动态调试(如ipython),修改代码无需重新编译 | 需重新编译才能运行修改后的代码,调试依赖IDE/调试器(如GDB) |
面试加分点:
- Python 并非纯解释型,CPython 会将源代码编译为字节码(.pyc),再由解释器执行,字节码是跨平台的;
- C++ 的编译优化(如 O2/O3 优化)可大幅提升性能,是高性能计算、游戏引擎等场景的首选。
四、编程范式:多范式(动态)vs 多范式(静态)
两者均支持多范式,但侧重点和实现方式不同:
| 范式 | Python | C++ |
|---|---|---|
| 面向对象 | 纯面向对象(一切皆对象,包括int/str等基本类型),仅支持单继承 | 支持面向对象(需显式定义类),支持多继承(通过虚继承解决菱形继承) |
| 函数式编程 | 原生支持(lambda、map/filter/reduce、生成器、装饰器) | C++11 后支持(lambda、std::function、std::bind),但语法繁琐 |
| 过程式编程 | 支持(无类的函数),但更推荐面向对象/函数式 | 原生支持(C++兼容C的过程式),是核心范式之一 |
| 泛型编程 | 动态类型天然支持泛型(如函数可接收任意类型参数) | 显式泛型(模板Template),编译期实例化,类型安全 |
示例对比(泛型编程):
# Python:动态泛型(无需声明,支持任意类型)
def add(a, b):
return a + b
print(add(1, 2)) # 3(int)
print(add("hello", "world")) # helloworld(str)
print(add([1,2], [3,4])) # [1,2,3,4](list)
// C++:模板泛型(编译期实例化,类型安全)
template <typename T>
T add(T a, T b) {
return a + b;
}
int main() {
std::cout << add(1, 2) << std::endl; // 3(实例化add<int>)
std::cout << add(std::string("hello"), std::string("world")) << std::endl; // helloworld(实例化add<string>)
// std::cout << add(1, "2") << std::endl; // 编译报错:模板参数推导失败
return 0;
}面试加分点:
- C++ 的模板是"编译期多态"(静态多态),与虚函数的"运行期多态"互补;
- Python 的装饰器是函数式编程的核心,可实现AOP(面向切面编程),而 C++ 需通过模板/宏实现类似功能。
五、性能与应用场景
性能差异是两者应用场景分化的核心原因:
| 维度 | Python | C++ |
|---|---|---|
| 运行性能 | 低(解释执行,动态类型开销) | 高(编译为机器码,静态类型,可直接操作内存) |
| 开发效率 | 高(语法简洁,无需声明类型,内置库丰富) | 低(语法繁琐,需手动管理内存,编译耗时) |
| 底层操作 | 无法直接操作内存(如指针),需通过C扩展(如ctypes) | 支持指针、内存地址操作,可直接访问硬件/操作系统接口 |
| 应用场景 | 数据分析(Pandas/Numpy)、Web开发(Django/Flask)、AI/ML(TensorFlow/PyTorch)、脚本工具 | 游戏引擎(Unreal/Unity)、嵌入式开发、高性能计算(科学计算/金融)、操作系统/编译器开发 |
面试加分点:
- 两者可互补使用:用 C++ 编写高性能核心模块(如 AI 模型的推理引擎),用 Python 编写上层逻辑(如数据预处理、接口调用),通过
pybind11/Cython实现交互; - Python 的 GIL(全局解释器锁)导致多线程无法利用多核CPU,CPU密集型任务需用多进程或 C++ 扩展,而 C++ 支持真正的多线程/多核并行。
六、其他核心区别
- 异常处理 :Python 强制捕获异常(未捕获的异常会终止程序),语法为
try-except-finally;C++ 异常为可选(可忽略),语法为try-catch-throw,且不推荐在性能敏感场景使用异常。 - 内置库:Python 内置库极其丰富("电池已包含"),无需额外安装即可实现大部分功能;C++ 标准库(STL)侧重基础数据结构/算法,高级功能需依赖第三方库(如 Boost)。
- 继承机制 :Python 支持单继承 + 多继承(通过Mixin实现),C++ 支持多继承(需处理菱形继承问题,通过
virtual继承解决)。
记忆法推荐
- 维度分类记忆法:将核心区别分为"类型、内存、执行、范式、性能、场景"六大维度,每个维度记住"Python 关键词(动态、自动、解释、灵活、低效、上层)"和"C++ 关键词(静态、手动、编译、严谨、高效、底层)"。
- 对比表格记忆法:将每个核心维度制作成对比表格,重点记忆"对立特征"(如动态vs静态、解释vs编译、自动GCvs手动管理)。
请说明 C++ 中指针和引用的区别
C++ 中的指针(pointer)和引用(reference)是两种用于间接访问变量的语法机制,虽功能相似,但在定义方式、内存占用、生命周期、可空性、可修改性等核心维度存在本质差异,是面试高频考点,以下从全维度拆解区别,并结合示例和面试加分点分析:
一、核心定义与语法形式
指针是"存储变量内存地址的变量",语法上用 * 声明,通过 & 获取变量地址,通过 * 解引用访问变量;引用是"变量的别名",语法上用 & 声明,声明时必须初始化,且直接通过引用名访问原变量。示例对比:
// 指针示例
int a = 10;
int* p = &a; // p是指针,存储a的地址
*p = 20; // 解引用,修改a的值(a变为20)
p = nullptr; // 指针可赋值为nullptr
// 引用示例
int b = 10;
int& ref = b; // ref是b的别名,声明时必须初始化
ref = 20; // 直接修改b的值(b变为20)
// ref = nullptr; // 编译报错:引用不能赋值为nullptr
// int& ref2; // 编译报错:引用声明时必须初始化二、核心区别全维度解析
| 维度 | 指针(Pointer) | 引用(Reference) |
|---|---|---|
| 内存占用 | 占用内存(大小为指针长度,64位系统8字节) | 不占用额外内存(编译器层面的别名,无独立存储) |
| 初始化要求 | 声明时可不初始化(野指针风险) | 声明时必须初始化(绑定到具体变量) |
| 可空性 | 可赋值为nullptr(空指针) | 不可为空(必须绑定有效变量) |
| 指向/绑定目标 | 可随时修改指向的变量(如 p = &c) |
一旦绑定,无法修改绑定的变量 |
| 多级形式 | 支持多级指针(如 int** pp = &p) |
不支持多级引用(无 int&&& 形式) |
| 运算支持 | 支持指针运算(如 p++、p+1) |
不支持运算(运算等价于对原变量运算) |
| 函数参数 | 传指针需解引用才能修改原变量(void func(int* p) { *p = 20; }) |
传引用直接修改原变量(void func(int& ref) { ref = 20; }) |
| 函数返回值 | 可返回局部变量的指针(但会导致野指针) | 可返回局部变量的引用(但会导致悬垂引用) |
| 重载/多态 | 指针可用于多态(Base* p = new Derived()) |
引用也可用于多态(Base& ref = Derived()) |
三、关键场景与面试易错点
-
野指针 vs 悬垂引用
-
野指针:指针声明未初始化、指向已释放内存、赋值为随机地址,访问野指针会导致程序崩溃(如
int* p; *p = 10;); -
悬垂引用:引用绑定的变量已销毁(如函数返回局部变量的引用),访问悬垂引用会导致未定义行为。示例(悬垂引用):
int& bad_func() {
int x = 10;
return x; // 返回局部变量x的引用,函数结束后x销毁,引用悬垂
}int main() {
int& ref = bad_func();
ref = 20; // 未定义行为(访问已销毁的内存)
return 0;
}
-
-
函数参数传递场景 指针和引用均可实现"传址调用"(修改原变量),但引用语法更简洁,且无空指针风险,是更推荐的方式;指针的优势是可传递nullptr,适用于"可选参数"场景。示例对比:
// 指针传参(支持nullptr) void set_value(int* p) { if (p != nullptr) { // 必须判空,否则解引用nullptr崩溃 *p = 100; } } // 引用传参(无需判空) void set_value_ref(int& ref) { ref = 100; // 直接修改原变量,无空指针风险 } int main() { int a = 0; set_value(&a); // 需传地址 set_value_ref(a); // 直接传变量 set_value(nullptr); // 合法(指针支持) // set_value_ref(nullptr); // 编译报错(引用不支持) return 0; } -
函数返回值场景
- 指针:可返回动态分配的内存(如
int* func() { return new int(10); }),但需手动释放,否则泄漏; - 引用:可返回类的成员变量(如
class A { int x; public: int& get_x() { return x; } };),避免拷贝,提升性能。
- 指针:可返回动态分配的内存(如
四、面试加分点
- 指出引用的本质:编译器层面,引用是"const指针"的语法糖(
int& ref = a等价于int* const p = &a),但语法上不可等价替换(如引用不可为空); - 说明引用在运算符重载中的必要性:如
operator[]需返回引用(int& operator[](int idx) { return arr[idx]; }),才能支持arr[0] = 10这样的赋值操作; - 强调"引用一旦绑定不可修改"的细节:如
int a=10, b=20; int& ref=a; ref=b;并非修改引用的绑定目标,而是将b的值赋给a(ref始终是a的别名)。
记忆法推荐
- 特征对比记忆法:用"三可三不可"总结指针和引用------指针可空、可改指向、可多级;引用不可空、不可改绑定、不可多级;
- 语法联想记忆法:指针是"地址容器"(占内存、可空、可移动),引用是"变量外号"(不占内存、必须绑定、终身不变)。
请详细介绍 C++ 中 new 和 malloc 的区别
C++ 中的 new 和 malloc 均用于动态分配内存,但 malloc 是C语言的标准库函数,new 是C++的关键字(运算符),二者在内存分配机制、类型安全、构造/析构调用、异常处理等核心维度存在本质差异,是面试中考察C++内存管理的核心考点,以下全维度拆解区别:
一、核心定义与基本用法
malloc:定义在<cstdlib>头文件中,函数原型为void* malloc(size_t size),接收"字节数"作为参数,返回void*类型指针,需手动强制类型转换,分配失败返回nullptr;new:C++关键字,语法为new 类型(如int* p = new int;)或new 类型[大小](数组),自动计算类型大小,返回对应类型指针,无需强制转换,分配失败抛出std::bad_alloc异常(C++11前)。
示例对比:
// malloc用法
#include <cstdlib>
int* p1 = (int*)malloc(sizeof(int)); // 需手动计算大小、强制类型转换
if (p1 == nullptr) { // 需手动判空
// 处理分配失败
}
*p1 = 10; // 仅分配内存,未初始化
free(p1); // 手动释放
// new用法
int* p2 = new int; // 自动计算大小,返回int*
// new int(10); // 分配内存并初始化(值为10)
*p2 = 20;
delete p2; // 手动释放
// 数组分配
int* arr1 = (int*)malloc(5 * sizeof(int)); // malloc数组
free(arr1);
int* arr2 = new int[5]; // new数组
delete[] arr2; // 数组释放需加[]二、核心区别全维度解析
| 维度 | malloc(C库函数) | new(C++运算符) |
|---|---|---|
| 所属语言 | C语言核心函数,C++兼容使用 | C++关键字,仅C++支持 |
| 类型安全 | 返回void*,需强制类型转换(非类型安全) | 返回对应类型指针,无需转换(类型安全) |
| 大小计算 | 需手动计算字节数(如 sizeof(int)) |
自动计算类型大小(如 new int 自动算4/8字节) |
| 初始化 | 仅分配内存,不初始化(内存内容为随机值) | 可初始化(如 new int(10)),类对象会调用构造函数 |
| 构造/析构 | 不调用构造函数(类对象分配后需手动调用构造) | 分配类对象时自动调用构造函数 |
| 异常处理 | 分配失败返回nullptr,需手动判空 | 默认分配失败抛出 std::bad_alloc 异常,可指定 nothrow 返回nullptr |
| 重载支持 | 不可重载 | 可重载(自定义类的operator new/operator delete) |
| 数组处理 | 仅分配连续内存,无数组语义 | 支持数组分配(new T[n]),释放需 delete[] |
| 内存对齐 | 遵循基本对齐规则,复杂对齐需手动处理 | 自动遵循C++对象的内存对齐规则(如类的对齐要求) |
三、关键场景与面试易错点
-
类对象的分配与构造
malloc仅分配内存,不会调用类的构造函数,直接使用会导致对象未初始化;new会在分配内存后自动调用构造函数,释放时delete会调用析构函数。示例对比:class Person {
public:
std::string name;
Person() { name = "default"; } // 构造函数
~Person() { std::cout << "析构" << std::endl; } // 析构函数
};// malloc分配类对象(错误示例)
Person* p1 = (Person*)malloc(sizeof(Person));
// p1->name = "Tom"; // 未调用构造函数,name未初始化,未定义行为
// free(p1); // 仅释放内存,不调用析构函数// new分配类对象(正确示例)
Person* p2 = new Person(); // 分配内存 + 调用构造函数
p2->name = "Tom"; // 合法
delete p2; // 调用析构函数 + 释放内存 -
异常处理与nothrow版本 默认情况下,
new分配失败会抛出std::bad_alloc异常,若不想处理异常,可使用nothrow版本,返回nullptr(类似malloc)。示例:#include
// 包含nothrow
int* p = new (std::nothrow) int[1000000000]; // 超大数组,分配失败
if (p == nullptr) {
std::cout << "分配失败" << std::endl;
} else {
delete[] p;
} -
重载operator new/operator delete C++ 允许自定义类的
operator new和operator delete,实现内存池、自定义对齐等高级功能,而malloc无法重载。示例(自定义operator new):class MyClass {
public:
void* operator new(size_t size) {
std::cout << "自定义new,分配" << size << "字节" << std::endl;
void* p = malloc(size); // 底层仍用malloc
if (!p) throw std::bad_alloc();
return p;
}void operator delete(void* p) { std::cout << "自定义delete" << std::endl; free(p); }};
int main() {
MyClass* obj = new MyClass(); // 调用自定义operator new
delete obj; // 调用自定义operator delete
return 0;
}
四、面试加分点
- 指出
new的底层实现:多数编译器中,new底层调用malloc分配内存,再调用构造函数;delete先调用析构函数,再调用free释放内存; - 说明
new[]和delete[]的匹配要求:数组分配必须用delete[]释放(否则类对象仅第一个元素调用析构函数),而malloc分配的数组直接用free即可; - 强调"类型安全"的重要性:
malloc的强制类型转换可能导致类型不匹配(如char* p = (char*)malloc(sizeof(int))),而new编译期即可检测类型错误。
记忆法推荐
- 维度分类记忆法 :将区别分为"语法、类型、初始化、构造、异常、重载"六大维度,每个维度记住
malloc的"手动、非安全、无构造"和new的"自动、安全、有构造"; - 口诀记忆法:"malloc是C的函数,手动算大小、强制转类型、只分配不构造;new是C++的运算符,自动算大小、类型保安全、分配加构造"。
在 C++ 中,delete 应使用什么方式释放数组类型的内存?
在 C++ 中,释放数组类型的动态内存必须使用 delete[](带方括号的 delete 运算符),而非普通的 delete,若混用 new[] 和 delete(或 malloc 和 delete),会导致未定义行为(如内存泄漏、析构函数调用不全、程序崩溃),以下从释放规则、底层原理、错误场景、面试易错点全维度解析:
一、核心规则:数组内存释放必须匹配 new[] + delete[]
C++ 规定动态内存分配与释放必须严格匹配:
- 单个对象分配(
new 类型)→ 单个对象释放(delete 指针); - 数组对象分配(
new 类型[大小])→ 数组对象释放(delete[] 指针); malloc分配(任意内存)→free释放(不可用delete/delete[])。
正确示例:
// 1. 基本类型数组(int/float等)
int* arr1 = new int[5]; // 分配5个int的数组内存
delete[] arr1; // 正确释放:释放整个数组
// 2. 类对象数组
class Student {
public:
std::string name;
Student() { std::cout << "构造:" << name << std::endl; }
~Student() { std::cout << "析构:" << name << std::endl; }
};
Student* arr2 = new Student[3]; // 分配3个Student对象,调用3次构造函数
delete[] arr2; // 正确释放:调用3次析构函数,释放整个数组二、错误场景:混用 new[] 和 delete 的后果
混用释放方式的后果因内存中存储的类型(基本类型/类对象)而异,但均属于未定义行为,具体表现为:
1. 基本类型数组(int/float/char等):看似正常,实则风险
基本类型(POD类型,Plain Old Data)无构造/析构函数,混用 new[] 和 delete 时,编译器通常能正确释放内存(仅释放整块内存),但这是编译器的"容错行为",并非标准规定,在不同编译器/平台下可能导致内存碎片或崩溃。错误示例:
int* arr = new int[5];
delete arr; // 错误:未用delete[],但基本类型可能不崩溃
// 风险:非标准行为,移植性差,不可依赖2. 类对象数组:析构函数调用不全,内存泄漏
类对象数组分配时,new[] 会为每个元素调用构造函数;释放时,delete[] 会为每个元素调用析构函数,而普通 delete 仅调用第一个元素的析构函数,剩余元素的析构函数未调用,导致资源泄漏(如类内的动态内存、文件句柄等未释放)。错误示例:
class MyClass {
private:
int* data;
public:
MyClass() {
data = new int[10]; // 构造时分配动态内存
std::cout << "构造" << std::endl;
}
~MyClass() {
delete[] data; // 析构时释放动态内存
std::cout << "析构" << std::endl;
}
};
int main() {
MyClass* arr = new MyClass[3]; // 调用3次构造函数
delete arr; // 错误:仅调用1次析构函数,剩余2个对象的data未释放,内存泄漏
return 0;
}输出结果:
构造
构造
构造
析构(仅1次析构,2个对象的 data 内存泄漏)
3. 更严重的错误:malloc 分配 + delete/delete[] 释放
malloc 是C语言的内存分配函数,仅分配内存,不调用构造函数;delete/delete[] 会先调用析构函数,再释放内存,混用会导致析构函数调用到未初始化的内存,直接触发程序崩溃。错误示例:
int* arr = (int*)malloc(5 * sizeof(int));
delete[] arr; // 未定义行为:可能崩溃(malloc分配的内存无析构信息)
// free(arr); // 正确方式三、底层原理:new[] 和 delete[] 的内存布局
编译器在处理 new[] 时,会在数组内存的"头部"额外分配一小块内存(通常4/8字节),存储数组元素个数 ,delete[] 会读取该数值,遍历数组并为每个元素调用析构函数,再释放整块内存;而普通 delete 不会读取该数值,仅认为指针指向单个对象,因此仅调用一次析构函数(或直接释放内存)。
内存布局示意图(64位系统,Student3数组):
地址:低 → 高
+------------+ 额外存储:数组元素个数(3)
| 0x00000003 |
+------------+
| Student[0] | 第一个对象(构造/析构)
+------------+
| Student[1] | 第二个对象(构造/析构)
+------------+
| Student[2] | 第三个对象(构造/析构)
+------------+delete[]:读取头部的"3",调用3次析构函数,释放从头部开始的整块内存;delete:忽略头部,仅调用Student0的析构函数,释放从Student0开始的内存,导致头部内存泄漏 + 剩余对象析构不全。
四、面试易错点与加分点
- 易错点1:认为"基本类型数组可用delete释放"------需强调即使不崩溃,也是未定义行为,不符合C++标准,严禁使用;
- 易错点2 :忘记
delete[]的方括号------如delete arr而非delete[] arr,是面试中最常见的笔误; - 加分点1 :指出
std::vector等容器可替代手动数组分配,避免new[]/delete[]混用问题(容器析构时自动释放内存); - 加分点2 :说明
operator delete[]可重载,自定义数组释放逻辑(如内存池管理)。
记忆法推荐
- 匹配记忆法:将分配和释放方式绑定记忆------"单个new配delete,数组new\[\]配delete\[\],malloc配free",形成"一一对应"的条件反射;
- 场景联想记忆法 :记住"类对象数组"的反例,通过"析构不全导致泄漏"的后果,强化
delete[]的必要性。
请描述 C++ 的内存布局(包含栈区、堆区、全局区、常量区、代码区),并说明各个区域的作用
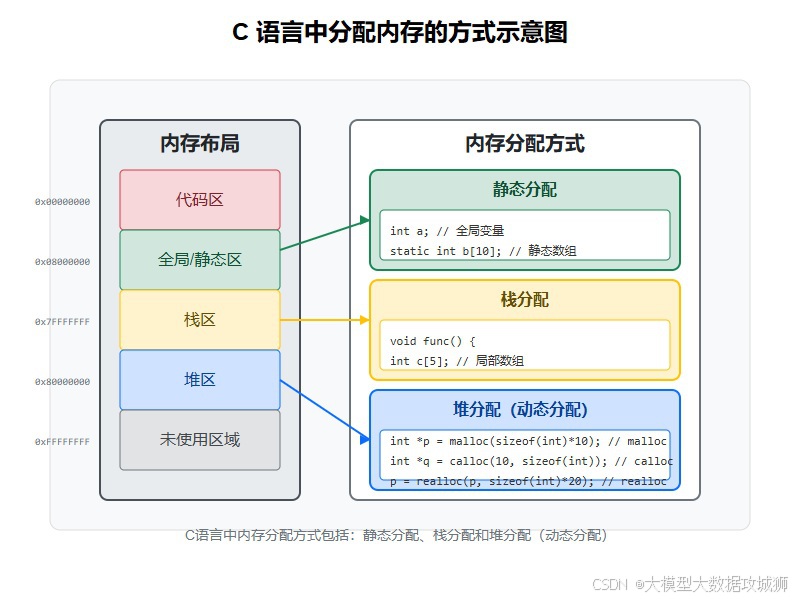
C++ 程序运行时的内存布局由操作系统和编译器共同划分,核心分为栈区、堆区、全局/静态区、常量区、代码区五大区域,不同区域的内存分配方式、生命周期、访问权限、管理机制差异显著,是理解内存泄漏、野指针、变量生命周期的核心基础,以下逐一解析:
一、代码区(Code Segment/Text Segment)
1. 核心作用
存储程序的机器码指令(编译后的二进制代码)、只读常量(如CPU的指令操作码),是程序运行的核心载体。
2. 关键特征
- 只读属性:内存权限为只读(防止程序运行时修改指令,避免恶意篡改);
- 生命周期:程序启动时加载,程序退出时释放;
- 内存分配:编译期确定大小,运行时不可修改;
- 共享性:多个进程运行同一程序时,代码区可共享(如多个终端运行同一个可执行文件,仅加载一份代码区)。
3. 示例与面试要点
int add(int a, int b) {
return a + b; // add函数的机器码存储在代码区
}
int main() {
add(1,2); // 执行代码区中的add指令
return 0;
}- 面试加分点:代码区通常与常量区合并为"只读数据段(RODATA)",部分编译器将字符串常量也存储在此区域。
二、常量区(Constant Data Segment)
1. 核心作用
存储程序中的只读常量 ,包括字符串常量(如 "hello world")、const 修饰的全局常量(如 const int MAX = 100)。
2. 关键特征
- 只读属性:内存权限为只读,修改常量区数据会触发程序崩溃(如试图修改字符串常量);
- 生命周期:程序启动时加载,程序退出时释放;
- 内存分配:编译期确定大小,存储在只读内存页;
3. 示例与面试要点
const int GLOBAL_CONST = 100; // 存储在常量区
char* str = "hello"; // "hello"存储在常量区,str是栈上的指针
int main() {
// str[0] = 'H'; // 运行崩溃:修改常量区只读数据
return 0;
}- 面试易错点:
const局部变量(如const int a = 10;)存储在栈区(而非常量区),仅在编译期限制修改,运行时可通过指针强制修改(未定义行为); - 面试加分点:常量区的字符串常量会被编译器"合并"(如
char* s1 = "abc"; char* s2 = "abc";,s1和s2指向同一地址),节省内存。
三、全局/静态区(Data Segment)
1. 核心作用
存储全局变量 和静态变量 (包括 static 修饰的全局/局部变量),分为"已初始化数据段(DATA)"和"未初始化数据段(BSS)":
- 已初始化数据段(DATA):存储已初始化的全局变量、静态变量(如
int global_var = 10;); - 未初始化数据段(BSS):存储未初始化的全局变量、静态变量(如
int global_var;),程序启动时会自动初始化为0。
2. 关键特征
- 读写属性:内存权限为可读可写;
- 生命周期:程序启动时分配,程序退出时释放(与程序生命周期一致);
- 内存分配:编译期确定大小,BSS段不占用可执行文件空间(仅记录大小,运行时分配);
3. 示例与面试要点
int global_uninit; // 未初始化,存储在BSS段(自动初始化为0)
int global_init = 20; // 已初始化,存储在DATA段
static int static_var = 30; // 静态变量,存储在DATA段
int main() {
static int local_static = 40; // 静态局部变量,存储在DATA段
std::cout << global_uninit << std::endl; // 输出:0
return 0;
}- 面试加分点:BSS段的变量"零初始化"是操作系统完成的,可执行文件中仅记录变量名和大小,不存储初始值,因此可减小可执行文件体积;
- 关键区别:静态局部变量(如
main中的local_static)虽定义在函数内,但存储在全局/静态区,而非栈区。
四、栈区(Stack)
1. 核心作用
存储局部变量 (函数内定义的非静态变量)、函数参数 、返回地址 、寄存器上下文等,是函数调用的核心内存区域。
2. 关键特征
- 自动管理:由编译器自动分配和释放(函数进入时分配,函数退出时释放),无需手动管理;
- 大小限制:栈区大小固定(通常几MB),超出会触发"栈溢出"(Stack Overflow);
- 生长方向:从高地址向低地址生长(栈顶指针向下移动);
- 读写属性:可读可写;
- 生命周期:与函数调用周期一致(局部变量随函数退出销毁);
3. 示例与面试要点
void func(int param) { // param存储在栈区
int local_var = 10; // local_var存储在栈区
// char arr[1024*1024*10]; // 栈溢出:分配10MB栈内存,超出默认限制
}
int main() {
func(5); // 调用func时,栈区分配param、local_var;退出时释放
return 0;
}- 面试易错点:栈溢出的常见场景------递归调用过深、分配超大局部数组;
- 面试加分点:栈的"后进先出(LIFO)"特性,函数调用时的栈帧布局(返回地址→参数→局部变量→寄存器上下文)。
五、堆区(Heap)
1. 核心作用
存储动态分配的内存 (通过 new/malloc 分配),是程序运行时手动管理的内存区域。
2. 关键特征
- 手动管理 :需程序员手动分配(
new/malloc)和释放(delete/free),否则导致内存泄漏; - 大小灵活:堆区大小远大于栈区(受物理内存/虚拟内存限制);
- 生长方向:从低地址向高地址生长;
- 读写属性:可读可写;
- 生命周期:从分配时开始,到释放时结束(可跨函数生命周期);
- 内存碎片:频繁分配/释放小块内存会导致内存碎片,降低内存利用率;
3. 示例与面试要点
int* func() {
int* p = new int(10); // p是栈上的指针,指向堆区的int内存
return p; // 返回堆区指针,内存不会随函数退出销毁
}
int main() {
int* ptr = func();
std::cout << *ptr << std::endl; // 输出:10
delete ptr; // 必须手动释放,否则内存泄漏
return 0;
}- 面试加分点:堆区的分配机制------底层通过操作系统的
brk/mmap系统调用实现,C++ 智能指针可自动管理堆内存; - 关键区别:堆区内存的所有权可转移(如函数返回堆指针),栈区内存不可转移(返回局部变量指针会导致野指针)。
六、各区域核心对比表
| 区域 | 存储内容 | 生命周期 | 管理方式 | 读写属性 | 大小限制 |
|---|---|---|---|---|---|
| 代码区 | 机器码指令 | 程序启动→退出 | 操作系统管理 | 只读 | 编译期确定 |
| 常量区 | 只读常量(字符串/const全局) | 程序启动→退出 | 操作系统管理 | 只读 | 编译期确定 |
| 全局/静态区 | 全局变量、静态变量 | 程序启动→退出 | 编译器/操作系统 | 读写 | 编译期确定 |
| 栈区 | 局部变量、函数参数 | 函数进入→退出 | 编译器自动管理 | 读写 | 小(几MB) |
| 堆区 | 动态分配内存 | 分配→释放 | 程序员手动管理 | 读写 | 大(受物理内存限制) |
记忆法推荐
- 功能分类记忆法:将五大区域分为"程序运行核心(代码区)、只读数据(常量区)、全局持久数据(全局/静态区)、函数临时数据(栈区)、手动动态数据(堆区)";
- 关键词记忆法:每个区域记住3个关键词------栈区:自动、临时、小;堆区:手动、动态、大;全局区:持久、全局、静态;常量区:只读、不可改、字符串;代码区:指令、只读、共享。
请说明 C++ 内存布局中各区域的内存排列顺序(从低地址到高地址)
C++ 程序运行时的内存布局顺序(从低地址到高地址)由操作系统的内存管理机制和编译器规范决定,不同编译器(GCC/Clang/MSVC)、操作系统(Linux/Windows/macOS)的细节略有差异,但核心顺序一致,以下从通用标准布局、平台差异、面试关键点全维度解析:
一、通用标准布局(从低地址到高地址)
核心排列顺序为:代码区 → 常量区 → 全局/静态区(BSS段 → DATA段) → 堆区 → 栈区(注:堆区和栈区之间存在"内存映射区",如动态库、共享内存,属于堆区扩展)。
二、各区域地址分布详解(以Linux x86_64平台为例)
Linux 系统下,C++ 程序的虚拟内存布局(32位/64位核心顺序一致,仅地址范围不同)从低到高依次为:
1. 代码区(Text Segment):最低地址区间
- 地址范围(64位):0x00400000 开始(可执行文件入口地址);
- 核心特征:只读、存储机器码指令,是程序中地址最低的可执行区域;
- 面试要点:代码区的起始地址由编译器/链接器决定,通常避开低地址的"空指针区域"(0x00000000-0x0000ffff),防止野指针访问。
2. 常量区(RODATA Segment):代码区之后
- 地址范围:紧跟代码区,与代码区同属"只读段";
- 核心特征:存储字符串常量、const全局常量,地址高于代码区,低于全局/静态区;
- 面试要点:部分编译器将代码区和常量区合并为"只读段",无法通过指针修改(修改会触发段错误)。
3. 全局/静态区(Data Segment):常量区之后,分为BSS段和DATA段
全局/静态区分为两部分,地址顺序为:BSS段(未初始化数据) → DATA段(已初始化数据),均位于常量区之后、堆区之前:
- BSS段(Uninitialized Data Segment):
- 地址范围:紧跟常量区;
- 核心特征:存储未初始化的全局变量、静态变量,程序启动时自动初始化为0,不占用可执行文件空间;
- DATA段(Initialized Data Segment):
- 地址范围:紧跟BSS段;
- 核心特征:存储已初始化的全局变量、静态变量,占用可执行文件空间,地址高于BSS段。
- 面试要点:全局/静态区的地址低于堆区,且所有全局/静态变量的地址在程序运行期间固定不变。
4. 堆区(Heap):全局/静态区之后,向高地址生长
- 地址范围:从全局/静态区的高地址端开始,向高地址方向"向上生长";
- 核心特征:动态分配的内存(new/malloc)均在此区域,地址连续但频繁分配/释放会产生碎片;
- 面试要点:堆区和栈区之间有大片"空闲虚拟内存"(内存映射区),用于加载动态库(如.so/.dll文件)、共享内存等,属于堆区的扩展。
5. 栈区(Stack):最高地址区间,向低地址生长
- 地址范围:从高地址(如64位的0x7fffffffffff)开始,向低地址方向"向下生长";
- 核心特征:栈区的起始地址由操作系统设置(栈顶指针),函数调用时栈帧向低地址扩展;
- 面试要点:栈区和堆区之间的"内存空洞"是程序可用的虚拟内存空间,堆区向上生长、栈区向下生长,直至相遇(内存耗尽)。
三、完整地址分布示意图(Linux x86_64)
低地址 → 高地址
+-------------------+
| 代码区(Text)| 0x00400000 开始
+-------------------+
| 常量区(RODATA)|
+-------------------+
| 全局/静态区-BSS段 |
+-------------------+
| 全局/静态区-DATA段|
+-------------------+
| 堆区(Heap)| 向上生长
+-------------------+
| 内存映射区(动态库/共享内存) |
+-------------------+
| 栈区(Stack)| 向下生长(从高地址开始)
+-------------------+
| 内核空间(Kernel)| 最高地址(用户不可访问)
+-------------------+四、平台差异(Windows vs Linux)
核心顺序一致,但细节有差异:
- Windows 系统:
- 代码区起始地址更高(如0x00010000);
- 堆区分为"进程堆""线程堆",但整体仍在全局/静态区之后;
- 栈区默认大小为1MB(Linux为8MB),可通过编译器修改。
- macOS 系统:
- 代码区启用ASLR(地址空间布局随机化),起始地址每次运行随机变化;
- 常量区与代码区合并更彻底,全局/静态区地址范围更紧凑。
五、面试关键点与易错点
- 易错点1:认为堆区地址一定低于栈区------正确结论是"堆区从低地址向上生长,栈区从高地址向下生长,堆区整体地址低于栈区";
- 易错点2:混淆BSS段和DATA段的顺序------BSS段(未初始化)地址低于DATA段(已初始化);
- 加分点1:提及ASLR(地址空间布局随机化):现代操作系统为安全考虑,随机化代码区、堆区、栈区的起始地址,防止缓冲区溢出攻击;
- 加分点2:通过代码验证地址顺序:打印不同区域变量的地址,直观展示顺序。
验证代码示例:
#include <iostream>
#include <cstdlib>
using namespace std;
// 全局/静态区变量
int global_uninit; // BSS段
int global_init = 10; // DATA段
static int static_var = 20; // DATA段
int main() {
// 常量区:字符串常量
const char* const_str = "hello world";
// 栈区:局部变量
int stack_var = 30;
// 堆区:动态分配
int* heap_var = new int(40);
// 打印各区域地址(从低到高)
cout << "代码区(函数地址):" << (void*)main << endl;
cout << "常量区(字符串):" << (void*)const_str << endl;
cout << "全局/静态区-BSS段:" << (void*)&global_uninit << endl;
cout << "全局/静态区-DATA段:" << (void*)&global_init << endl;
cout << "全局/静态区-静态变量:" << (void*)&static_var << endl;
cout << "堆区:" << (void*)heap_var << endl;
cout << "栈区:" << (void*)&stack_var << endl;
delete heap_var;
return 0;
}输出结果(Linux x86_64示例):
代码区(函数地址):0x401146
常量区(字符串):0x402004
全局/静态区-BSS段:0x404020
全局/静态区-DATA段:0x404010
全局/静态区-静态变量:0x404014
堆区:0x55b8c8e7b2a0
栈区:0x7ffeefbff6ac(注:地址数值因系统/编译器不同而异,但顺序一致)
记忆法推荐
- 口诀记忆法:"代码常量全局堆,栈在高处向下飞"------前半句是低到高的顺序(代码区→常量区→全局/静态区→堆区),后半句是栈区在最高地址,向低地址生长;
- 方向联想记忆法:堆区"向上长"(低→高),栈区"向下长"(高→低),中间是全局/静态区和常量区,最底端是代码区。
请解释字节序的概念(大端序、小端序),并说明出现两种字节序的原因
字节序(Endianness)是指多字节数据(如int、long、double等)在内存中存储的字节排列顺序,核心分为大端序(Big-Endian) 和小端序(Little-Endian) 两种,是跨平台数据交互(如网络通信、文件存储)的核心基础问题,其本质是硬件架构对"字节地址与数据位权"映射关系的不同设计选择。
一、字节序的核心概念
多字节数据的每个字节都有独立的内存地址,字节序定义了"数据的高位字节"和"低位字节"对应内存的高/低地址:
- 高位字节/低位字节 :以4字节int型数据
0x12345678为例(十六进制),从位权角度:- 高位字节:
0x12(对应24-31位,位权最高); - 次高位字节:
0x34(16-23位); - 次低位字节:
0x56(8-15位); - 低位字节:
0x78(0-7位,位权最低)。
- 高位字节:
1. 大端序(Big-Endian)
定义 :数据的高位字节 存储在内存的低地址 ,低位字节存储在内存的高地址("高高低低"),符合人类读写数字的习惯(从高位到低位)。存储示例 (0x12345678,内存地址从0x00到0x03):
| 内存地址 | 0x00(低地址) | 0x01 | 0x02 | 0x03(高地址) |
|---|---|---|---|---|
| 存储字节 | 0x12(高位) | 0x34 | 0x56 | 0x78(低位) |
2. 小端序(Little-Endian)
定义 :数据的低位字节 存储在内存的低地址 ,高位字节存储在内存的高地址("低高低高"),是目前主流硬件架构(x86、x86_64、ARM(默认))采用的字节序。存储示例 (0x12345678,内存地址从0x00到0x03):
| 内存地址 | 0x00(低地址) | 0x01 | 0x02 | 0x03(高地址) |
|---|---|---|---|---|
| 存储字节 | 0x78(低位) | 0x56 | 0x34 | 0x12(高位) |
3. 验证字节序的代码示例
#include <iostream>
using namespace std;
void check_endian() {
int num = 0x12345678;
// 取num的首地址(低地址),强制转换为char*(单字节指针)
char* ptr = (char*)#
if (*ptr == 0x78) {
cout << "小端序" << endl;
} else if (*ptr == 0x12) {
cout << "大端序" << endl;
} else {
cout << "未知字节序" << endl;
}
}
int main() {
check_endian(); // x86平台输出:小端序
return 0;
}二、两种字节序出现的原因
字节序的分化本质是硬件设计的历史选择,无绝对的"优劣",仅适配不同的硬件场景和设计理念:
1. 硬件架构的设计差异
- 大端序的起源:早期大型机(如IBM 360、Motorola 68000)采用大端序,设计初衷是"符合人类读写习惯",便于硬件直接解析数据的高位(如网络协议中的端口号、IP地址,高位代表核心信息)。
- 小端序的起源:x86架构(Intel)采用小端序,核心优势是"硬件运算效率"------CPU进行加减运算时,先处理低位字节,小端序下低位字节位于低地址,无需额外地址偏移,可直接读取运算,减少硬件逻辑复杂度。
2. 场景适配的需求
- 大端序适配"外部交互场景":网络通信(TCP/IP协议规定大端序为网络字节序)、文件存储(如JPEG、PNG等格式采用大端序),因为跨平台交互时,统一高位在前的顺序更易解析;
- 小端序适配"内部运算场景":CPU内部运算、内存访问时,小端序的地址映射更贴合硬件的运算逻辑,降低寻址延迟。
3. 无统一标准的历史原因
早期计算机硬件发展分散(Intel、Motorola、IBM等厂商各自为战),未形成统一的字节序标准,不同厂商基于自身硬件架构选择了不同的字节序,且该选择随硬件生态固化(如x86的主导地位让小端序成为主流)。
三、字节序的实际应用场景(面试加分点)
-
网络通信 :TCP/IP协议规定"网络字节序为大端序",因此本地小端序数据(如x86平台)需通过
htonl(主机到网络长整型)、htons(主机到网络短整型)转换为大端序,接收方通过ntohl/ntohs转换回本地字节序。示例代码 :#include <arpa/inet.h> int main() { uint32_t local_ip = 0xc0a80101; // 本地小端序:192.168.1.1 uint32_t net_ip = htonl(local_ip); // 转换为网络大端序 uint32_t back_ip = ntohl(net_ip); // 转换回本地小端序 return 0; } -
文件解析:解析BMP(小端序)、JPEG(大端序)等格式文件时,需根据文件规定的字节序读取多字节数据,否则会出现数据错误(如BMP的宽度/高度字段为小端序,按大端序读取会得到错误数值)。
-
跨平台数据交互 :不同架构的CPU(如x86小端、PowerPC大端)之间传输数据时,必须统一字节序,否则会出现"数据错乱"(如int型
1234在小端机存储为0x04D2,大端机按自身规则读取会得到0xD204即53764)。
四、面试易错点
- 混淆"位序"和"字节序":字节序仅针对多字节数据的字节排列,单字节数据(char)无字节序问题;位序是字节内部的比特排列,通常为小端(最低位在前),与字节序无关;
- 认为"小端序是错误的":字节序无对错,仅为硬件设计选择,核心是跨平台交互时需统一转换。
记忆法推荐
- 口诀记忆法:"大端高位存低址,小端低位存低址;网络通信大端序,本地运算小端序";
- 场景联想记忆法:把多字节数据比作"数字1234",大端序是"1在左(低地址)、4在右(高地址)"(人类读写习惯),小端序是"4在左、1在右"(硬件运算习惯)。
C++ 中如何管理内存以防止内存泄漏?你是否使用过 weak_ptr?
C++ 中内存泄漏的本质是"动态分配的内存(堆内存)未被释放,且指向该内存的指针丢失",防止内存泄漏需从内存管理机制、编程规范、工具辅助 三个维度入手,而weak_ptr是C++11引入的智能指针,是解决shared_ptr循环引用导致内存泄漏的核心工具,以下从全维度解析:
一、C++ 防止内存泄漏的核心方法
1. 智能指针(核心手段):基于RAII思想自动管理内存
智能指针是C++防止内存泄漏的首选方案,通过将堆内存的生命周期绑定到栈对象的生命周期,析构时自动释放内存,核心包括unique_ptr、shared_ptr、weak_ptr:
-
unique_ptr :独占式智能指针,无引用计数,轻量级,优先用于独占内存场景,避免拷贝,仅支持移动语义;示例 :
#include <memory> void func() { std::unique_ptr<int> up(new int(10)); // 独占内存 // 无需手动delete,函数退出时up析构释放内存 } -
shared_ptr :共享式智能指针,通过引用计数管理内存,计数为0时释放,适用于多指针共享内存场景;示例 :
void func() { std::shared_ptr<int> sp1(new int(20)); std::shared_ptr<int> sp2 = sp1; // 引用计数+1(变为2) } // sp2、sp1析构,计数归0,释放内存 -
weak_ptr :弱引用智能指针,不增加引用计数,解决
shared_ptr循环引用问题(下文详细说明)。
2. 遵循"分配-释放"匹配原则
手动管理内存时,严格遵循"谁分配谁释放",且分配与释放方式必须匹配:
-
new→delete;new[]→delete[];malloc→free; -
禁止在函数中返回局部变量的指针(野指针),返回动态内存时需明确释放责任;反例(内存泄漏) :
int* bad_func() { int* p = new int(30); return p; // 返回动态内存,但调用方可能忘记释放 } int main() { int* ptr = bad_func(); // 未delete ptr,内存泄漏 return 0; }正例 :
std::unique_ptr<int> good_func() { return std::unique_ptr<int>(new int(30)); // 返回智能指针,自动释放 }
3. 避免循环引用(shared_ptr的核心坑点)
两个shared_ptr管理的对象互相持有对方的shared_ptr,会导致引用计数无法归0,内存泄漏,需用weak_ptr打破循环:反例(循环引用):
struct Node {
std::shared_ptr<Node> next;
~Node() { std::cout << "析构" << std::endl; }
};
void cycle_ref() {
std::shared_ptr<Node> n1(new Node);
std::shared_ptr<Node> n2(new Node);
n1->next = n2;
n2->next = n1;
} // n1、n2析构,计数各为1,内存泄漏,无析构输出正例(weak_ptr解决):
struct Node {
std::weak_ptr<Node> next; // 弱引用,不增加计数
~Node() { std::cout << "析构" << std::endl; }
};
void no_cycle_ref() {
std::shared_ptr<Node> n1(new Node);
std::shared_ptr<Node> n2(new Node);
n1->next = n2;
n2->next = n1;
} // 计数归0,释放内存,输出两次析构4. 使用内存池/自定义分配器
频繁分配/释放小块内存时,不仅易产生内存碎片,也易因遗漏释放导致泄漏,内存池可预先分配大块内存,按需分配/回收,统一管理释放:简化示例(内存池核心思想):
#include <vector>
class MemoryPool {
private:
std::vector<int*> pool; // 管理分配的内存
public:
int* allocate() {
int* p = new int();
pool.push_back(p);
return p;
}
~MemoryPool() {
for (auto p : pool) {
delete p; // 统一释放所有分配的内存
}
}
};5. 工具辅助检测内存泄漏
- Valgrind(Linux) :通过
valgrind --leak-check=full ./a.out检测内存泄漏,定位未释放的内存地址和分配位置; - AddressSanitizer(GCC/Clang) :编译时添加
-fsanitize=address,运行时直接报错并定位内存泄漏/越界; - Visual Leak Detector(Windows):可视化检测内存泄漏,输出泄漏内存的调用栈。
二、weak_ptr的使用场景与核心细节
作为面试核心问题,需明确说明"是否使用过weak_ptr"及具体场景:
1. 实际使用场景(真实项目示例)
在iOS开发的C++模块中(如音视频解码、游戏逻辑),曾使用weak_ptr解决以下问题:
-
观察者模式 :被观察者持有观察者的
weak_ptr,避免观察者销毁后被观察者仍持有shared_ptr导致泄漏;示例 :#include <memory> #include <vector> class Observer; class Subject { private: std::vector<std::weak_ptr<Observer>> observers; // 弱引用观察者 public: void add_observer(std::shared_ptr<Observer> obs) { observers.push_back(obs); } void notify() { for (auto& wp : observers) { if (auto sp = wp.lock()) { // 检查观察者是否存活 sp->on_notify(); } } } }; class Observer : public std::enable_shared_from_this<Observer> { public: void on_notify() { // 处理通知 } }; -
缓存管理 :缓存对象用
shared_ptr,缓存索引用weak_ptr,避免缓存对象长期占用内存(缓存过期时自动释放)。
2. weak_ptr的核心操作
lock():将weak_ptr转为shared_ptr,若原内存已释放,返回空shared_ptr(线程安全);expired():判断weak_ptr指向的内存是否已释放(等价于use_count() == 0);use_count():获取指向该内存的shared_ptr数量(仅用于调试,不建议业务逻辑使用)。
三、面试加分点
- 提及
shared_ptr的控制块包含"强引用计数"(shared_ptr数量)和"弱引用计数"(weak_ptr数量),内存真正释放的条件是"强引用计数为0",控制块释放的条件是"强+弱引用计数均为0"; - 说明
weak_ptr不能直接访问数据(无operator*/operator->),必须通过lock()转为shared_ptr才能访问,保证线程安全; - 结合项目经验说明:在音视频解码模块中,曾因未使用
weak_ptr导致循环引用,内存占用持续升高,接入weak_ptr后泄漏问题解决。
记忆法推荐
- 分层记忆法:防止内存泄漏分为"自动管理(智能指针)、规范匹配(分配释放)、工具检测(Valgrind)、场景规避(循环引用)"四层,每层记住核心手段;
- weak_ptr核心记忆法:"弱引用不计数,lock转强引用,破环防泄漏,缓存/观察者常用"。
请说明原子操作的定义及核心特点
原子操作(Atomic Operation)是指"不可被中断的单个或一系列操作",在多线程编程中,原子操作是实现线程安全、避免竞态条件(Race Condition)的核心基础,C++11通过<atomic>头文件提供了原子类型和原子操作接口,以下从定义、核心特点、实现原理、使用场景全维度解析:
一、原子操作的核心定义
在计算机科学中,原子操作的定义分为两个层面:
- 硬件层面 :CPU提供的"不可中断的指令"(如x86的
LOCK前缀指令),执行过程中不会被其他线程/CPU核心打断; - 编程语言层面 :C++封装硬件原子指令,提供原子类型(如
std::atomic<int>)和原子操作接口(如load()、store()、fetch_add()),保证操作的原子性,无需手动加锁。
对比非原子操作(竞态条件):
// 非原子操作:i++分为"读-改-写"三步,多线程下会错乱
int i = 0;
void increment() {
for (int j=0; j<10000; j++) {
i++; // 非原子,多线程执行后i<10000*线程数
}
}
// 原子操作:i.fetch_add(1)是单步原子操作
std::atomic<int> ai(0);
void atomic_increment() {
for (int j=0; j<10000; j++) {
ai.fetch_add(1); // 原子,多线程执行后ai=10000*线程数
}
}二、原子操作的核心特点
1. 不可中断性(核心特征)
原子操作的执行过程是"一气呵成"的,从开始到结束不会被任何线程调度、中断或信号打断,即"要么完全执行,要么完全不执行",不存在"执行一半"的中间状态。
- 非原子操作(如
i++):分为"读取i的值→加1→写回i"三步,若线程A执行到"加1"时被线程B打断,线程B读取到旧值,最终导致计数错误; - 原子操作(如
ai.fetch_add(1)):CPU通过LOCK前缀锁定内存总线,确保该操作执行期间,其他CPU核心无法访问该内存地址,操作完成后释放总线。
2. 无锁性(高效性)
原子操作基于硬件指令实现,无需操作系统的锁机制(如互斥锁std::mutex),因此:
- 开销远低于互斥锁(无内核态/用户态切换);
- 无死锁风险(原子操作是单指令,不存在锁的嵌套);
- 支持细粒度并发(仅锁定单个变量,而非代码块)。
3. 内存顺序一致性(可配置)
C++11原子操作支持不同的内存顺序(Memory Order),平衡"性能"和"内存可见性":
| 内存顺序 | 核心特点 | 适用场景 |
|---|---|---|
memory_order_seq_cst |
顺序一致性(最严格),所有操作按程序顺序执行 | 要求强一致性的场景(如全局计数器) |
memory_order_acq_rel |
获取-释放语义,写操作释放内存,读操作获取内存 | 生产者-消费者模型 |
memory_order_relaxed |
松散语义,仅保证操作原子性,不保证顺序 | 无顺序要求的计数(如统计访问量) |
示例(内存顺序配置):
std::atomic<int> x(0);
// 松散语义,仅保证x的自增是原子的,不保证其他变量的顺序
x.fetch_add(1, std::memory_order_relaxed);4. 类型安全性
C++的原子操作通过std::atomic<T>模板实现,支持bool、char、int、指针等类型(不支持非POD类型),编译期检查操作的合法性,避免类型错误。
5. 线程安全性
原子操作本身是线程安全的,无需额外加锁,但需注意:
- 复合操作(如
if (ai > 0) ai--;)不是原子的,需结合锁或CAS操作; - 原子操作的内存顺序若配置不当,可能导致内存可见性问题(如线程A修改的原子变量,线程B无法及时看到)。
三、原子操作的实现原理
1. 硬件层面
- 单核CPU:原子操作通过禁用中断实现(执行原子操作时,CPU不响应中断,避免线程切换);
- 多核CPU :通过总线锁定(
LOCK前缀)或缓存锁定(MESI协议)实现:- 总线锁定:CPU发出
LOCK信号,锁定内存总线,其他核心无法访问该内存地址,直到操作完成(开销大); - 缓存锁定:若操作的内存地址在CPU缓存中,通过MESI协议保证缓存一致性,无需锁定总线(开销小)。
- 总线锁定:CPU发出
2. 编程语言层面
C++的<atomic>库封装了硬件原子指令,不同架构(x86、ARM)的原子指令由编译器适配,开发者无需关注底层细节:
- 如
std::atomic<int>::fetch_add(1)在x86平台编译为lock xadd %eax, (%rdi)指令(带LOCK前缀); - 在ARM平台编译为
ldrex/strex指令(加载-存储独占)。
四、原子操作的使用场景(面试加分点)
-
计数器/累加器 :如多线程统计请求数、下载进度,用
std::atomic<int>替代互斥锁,提升性能;示例 :#include <atomic> #include <thread> std::atomic<int> request_count(0); void handle_request() { request_count.fetch_add(1, std::memory_order_relaxed); // 处理请求 } int main() { std::thread t1(handle_request); std::thread t2(handle_request); t1.join(); t2.join(); std::cout << request_count << std::endl; // 输出2 return 0; } -
标志位/状态机 :如多线程控制的"运行/停止"标志,用
std::atomic<bool>保证状态切换的原子性; -
CAS操作(Compare-And-Swap) :实现无锁数据结构(如无锁队列、无锁哈希表),核心是
compare_exchange_weak/compare_exchange_strong:示例(CAS实现自旋锁) :std::atomic<bool> lock_flag(false); void lock() { bool expected = false; // 自旋直到CAS成功(lock_flag从false变为true) while (!lock_flag.compare_exchange_weak(expected, true)) { expected = false; } } void unlock() { lock_flag.store(false); }
五、面试易错点
- 认为"所有原子操作都比锁高效":原子操作仅适用于单个变量的简单操作,复合操作(如条件判断+修改)用原子操作会导致自旋,效率低于互斥锁;
- 混淆"原子操作"和"内存可见性":默认的
memory_order_seq_cst保证可见性,memory_order_relaxed不保证,需根据场景选择内存顺序; - 认为"原子类型的所有操作都是原子的":如
atomic<int> a; a = 10;是原子的,但a += 10等价于a.fetch_add(10)(原子),而a = a + 10不是原子的(先读再写)。
记忆法推荐
- 核心特征记忆法:原子操作记住"五性"------不可中断性、无锁性、内存顺序性、类型安全性、线程安全性;
- 场景联想记忆法:原子操作="硬件级别的锁",适用于"单个变量的简单操作",锁适用于"代码块的复合操作"。
请详细介绍 OC 中的消息转发机制
OC的消息转发(Message Forwarding)是OC动态性的核心体现,其本质是"当对象收到无法响应的消息时,OC运行时提供的一套补救机制",避免程序直接崩溃(unrecognized selector sent to instance),消息转发分为"快速转发"和"标准转发"两个阶段,是iOS面试中考察OC底层原理的核心考点。
一、消息转发的前置阶段:消息查找
OC中调用方法[obj doSomething]的本质是发送消息objc_msgSend(obj, @selector(doSomething)),消息转发的前提是"消息查找失败",完整的消息查找流程为:
- 查找对象的类的方法缓存(cache_t),若找到直接调用;
- 缓存未命中,查找类的方法列表(method_list_t),找到则加入缓存并调用;
- 类方法列表未找到,查找父类的方法缓存/列表(递归直到NSObject);
- 所有父类均未找到,进入消息转发流程。
二、消息转发的完整流程(三个阶段)
消息转发分为"快速转发""标准转发""兜底崩溃"三个阶段,前两个阶段为补救机会,第三个阶段无补救则崩溃:
1. 第一阶段:快速转发(Fast Forwarding)------重定向消息接收者
核心是通过+resolveInstanceMethod:(实例方法)/+resolveClassMethod:(类方法)动态添加方法,若返回YES,运行时会重新查找方法并调用;若返回NO,进入第二阶段。
-
方法定义 :
+ (BOOL)resolveInstanceMethod:(SEL)sel; // 实例方法 + (BOOL)resolveClassMethod:(SEL)sel; // 类方法 -
示例(动态添加方法) :
#import <objc/runtime.h> @interface Person : NSObject - (void)sayHello; @end @implementation Person // 动态添加的方法实现 void sayHelloImp(id self, SEL _cmd) { NSLog(@"Hello"); } // 消息查找失败后调用 + (BOOL)resolveInstanceMethod:(SEL)sel { if (sel == @selector(sayHello)) { // 动态添加方法:sel为方法名,sayHelloImp为实现,v@:表示参数类型(void返回,id self,SEL _cmd) class_addMethod(self, sel, (IMP)sayHelloImp, "v@:"); return YES; } return [super resolveInstanceMethod:sel]; } @end // 调用 Person *p = [[Person alloc] init]; [p sayHello]; // 输出Hello,不崩溃 -
面试要点:该阶段是"静态解析",仅能添加本类的方法实现,无法转发给其他对象。
2. 第二阶段:标准转发(Standard Forwarding)------转发给其他对象
若快速转发返回NO,进入标准转发,分为两步:
步骤1:获取消息接收者(forwardingTargetForSelector:)
核心是返回一个"能响应该消息的对象",运行时会将消息转发给该对象;若返回nil,进入步骤2。
-
方法定义 :
- (id)forwardingTargetForSelector:(SEL)aSelector; -
示例(转发给其他对象) :
@interface Student : NSObject - (void)sayHello; @end @implementation Student - (void)sayHello { NSLog(@"Student Hello"); } @end @implementation Person // 快速转发返回NO + (BOOL)resolveInstanceMethod:(SEL)sel { return NO; } // 标准转发步骤1:返回Student对象 - (id)forwardingTargetForSelector:(SEL)aSelector { if (aSelector == @selector(sayHello)) { return [[Student alloc] init]; // 转发给Student } return [super forwardingTargetForSelector:aSelector]; } @end // 调用 Person *p = [[Person alloc] init]; [p sayHello]; // 输出Student Hello,不崩溃 -
面试要点:该阶段是"对象转发",仅能转发给单个对象,无法自定义方法签名。
步骤2:自定义方法签名并转发(methodSignatureForSelector: + forwardInvocation:)
若步骤1返回nil,运行时会调用methodSignatureForSelector:获取方法签名,若返回nil则崩溃;若返回有效签名,会创建NSInvocation对象并调用forwardInvocation:,在该方法中可自定义转发逻辑(如转发给多个对象)。
-
方法定义 :
- (NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector; - (void)forwardInvocation:(NSInvocation *)anInvocation; -
示例(自定义转发) :
@implementation Person // 快速转发返回NO + (BOOL)resolveInstanceMethod:(SEL)sel { return NO; } // 步骤1返回nil - (id)forwardingTargetForSelector:(SEL)aSelector { return nil; } // 步骤2:返回方法签名 - (NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector { if (aSelector == @selector(sayHello)) { // v@:表示方法签名(void返回,id self,SEL _cmd) return [NSMethodSignature signatureWithObjCTypes:"v@:"]; } return [super methodSignatureForSelector:aSelector]; } // 自定义转发逻辑 - (void)forwardInvocation:(NSInvocation *)anInvocation { SEL sel = anInvocation.selector; Student *stu = [[Student alloc] init]; if ([stu respondsToSelector:sel]) { [anInvocation invokeWithTarget:stu]; // 转发给Student } else { [super forwardInvocation:anInvocation]; } } @end -
面试要点:该阶段是"完整转发",可自定义方法签名、转发给多个对象,是最灵活的转发方式。
3. 第三阶段:兜底崩溃(doesNotRecognizeSelector:)
若标准转发的methodSignatureForSelector:返回nil,运行时会调用doesNotRecognizeSelector:,默认实现是抛出异常并崩溃,可重写该方法自定义崩溃逻辑,但无法避免崩溃。
-
示例 :
- (void)doesNotRecognizeSelector:(SEL)aSelector { NSLog(@"无法响应方法:%@", NSStringFromSelector(aSelector)); [super doesNotRecognizeSelector:aSelector]; // 必须调用super,否则行为未定义 }
三、消息转发的应用场景(面试加分点)
- 多代理转发:将代理方法转发给多个代理对象,实现"一对多"代理;
- 埋点/日志 :在
forwardInvocation:中添加日志,记录未实现的方法调用; - 跨进程通信:将消息转发给远程进程的对象(如XPC);
- 兼容旧版本:对旧版本未实现的方法,通过转发适配新逻辑。
四、面试易错点
- 混淆
forwardingTargetForSelector:和forwardInvocation:的区别:前者仅能转发给单个对象,后者可转发给多个对象且自定义签名; - 认为
resolveInstanceMethod:可转发给其他对象:该方法仅能动态添加本类方法,无法转发; - 忘记
methodSignatureForSelector:必须返回有效签名:否则直接崩溃,无法进入forwardInvocation:。
记忆法推荐
- 流程记忆法:消息转发记住"三阶段"------静态解析(resolve)→ 对象转发(forwardingTarget)→ 完整转发(methodSignature+forwardInvocation)→ 崩溃(doesNotRecognize);
- 功能记忆法:"resolve加方法,forwardingTarget转对象,forwardInvocation自定义,最后崩溃不可避"。
请介绍 TCP 的 Keep Alive 机制的作用及实现原理。
一、Keep Alive 机制的核心作用
TCP Keep Alive(保活机制)是 TCP 协议提供的一种连接维护机制,核心作用是检测长时间无数据传输的 TCP 连接是否存活,避免无效连接占用系统资源(如端口、内存),同时解决"半开连接"(Half-Open Connection)问题。
- 解决半开连接问题:若通信一方(如客户端)异常崩溃、网络断开(如断网、路由器故障),另一方(如服务端)无法感知连接已失效,会一直维持该连接,占用端口和缓冲区资源。Keep Alive 可通过定期探测,发现半开连接并主动释放。
- 维护长连接:对于需要长时间保持连接但数据传输频率低的场景(如即时通讯、SSH 连接、数据库连接池),Keep Alive 可避免连接被中间网络设备(如路由器、防火墙)因超时断开。
- 节省带宽资源:相比应用层心跳包(如 HTTP 长轮询、WebSocket Ping/Pong),TCP Keep Alive 报文体积小(仅 TCP 首部,无数据),带宽开销更低。
二、Keep Alive 机制的实现原理
Keep Alive 由 TCP 协议栈底层实现,无需应用层干预(可通过系统参数配置),核心流程包括"探测触发、探测报文交互、连接释放"三个阶段。
1. 核心参数配置(触发条件)
Keep Alive 的触发和探测频率由三个核心系统参数控制(不同操作系统默认值不同,如 Linux/macOS/iOS):
- keepalive_time:连接空闲时间阈值(默认通常为 7200 秒,即 2 小时)。若 TCP 连接在该时间内无任何数据传输(包括数据报文、ACK 报文),则触发 Keep Alive 探测。
- keepalive_intvl:探测报文的发送间隔(默认通常为 75 秒)。若发送探测报文后未收到响应,每隔该时间重试发送。
- keepalive_probes:探测重试次数(默认通常为 9 次)。若连续发送指定次数的探测报文仍未收到响应,则判定连接已失效,主动关闭连接(发送 RST 报文)。
面试加分点:iOS 中可通过 setsockopt 函数修改 socket 的 Keep Alive 参数,覆盖系统默认值,示例代码如下:
import Foundation
import Darwin
func configureKeepAlive(for socket: Int32) {
// 1. 启用 Keep Alive(默认禁用)
var keepAliveEnabled = 1
setsockopt(socket, SOL_SOCKET, SO_KEEPALIVE, &keepAliveEnabled, socklen_t(MemoryLayout<Int>.size))
// 2. 设置空闲时间(单位:秒,这里设为 300 秒 = 5 分钟)
var keepAliveTime = 300
setsockopt(socket, IPPROTO_TCP, TCP_KEEPALIVE, &keepAliveTime, socklen_t(MemoryLayout<Int>.size))
// 3. 设置探测间隔(单位:秒,这里设为 60 秒)
var keepAliveIntvl = 60
setsockopt(socket, IPPROTO_TCP, TCP_KEEPINTVL, &keepAliveIntvl, socklen_t(MemoryLayout<Int>.size))
// 4. 设置探测次数(这里设为 3 次)
var keepAliveProbes = 3
setsockopt(socket, IPPROTO_TCP, TCP_KEEPCNT, &keepAliveProbes, socklen_t(MemoryLayout<Int>.size))
}2. 探测流程详解
假设客户端和服务端建立 TCP 连接后,长时间无数据传输,触发 Keep Alive 探测(以客户端为探测方为例):
- 触发探测 :连接空闲时间达到
keepalive_time,客户端 TCP 协议栈自动发送 Keep Alive 探测报文。- 探测报文特点:TCP 首部标志位 ACK=1(无 SYN、FIN 标志),序列号为"上一次发送的最后一个字节序列号 - 1"(避免被视为有效数据),无应用层数据(数据长度为 0)。
- 正常响应:服务端收到探测报文后,若连接正常,会立即返回 ACK 报文(确认号为探测报文的序列号 + 1)。客户端收到 ACK 后,重置空闲时间计数器,连接继续保持。
- 无响应重试 :若服务端未收到探测报文(如网络中断)或无法响应(如服务端崩溃),客户端在
keepalive_intvl时间后重新发送探测报文,重复keepalive_probes次。 - 连接释放 :若连续发送
keepalive_probes次探测报文仍未收到响应,客户端判定连接已失效,发送 RST 报文关闭连接,释放端口和缓冲区资源;同时,应用层会收到ETIMEDOUT或ECONNRESET错误。
3. 半开连接的处理场景
- 场景 1:客户端崩溃后重启,服务端仍维持连接。服务端触发 Keep Alive 探测,发送探测报文后,客户端因已重启,无该连接的状态记录,会返回 RST 报文,服务端收到后关闭连接。
- 场景 2:网络中断(如光纤断裂),双方均未收到对方的报文。双方都会在空闲时间达到后触发探测,连续重试失败后关闭连接,避免资源泄露。
三、Keep Alive 与应用层心跳包的区别(面试加分点)
| 对比维度 | TCP Keep Alive | 应用层心跳包(如 WebSocket Ping) |
|---|---|---|
| 实现层级 | TCP 协议栈(底层) | 应用层(如 HTTP、WebSocket) |
| 报文体积 | 小(仅 TCP 首部,约 20 字节) | 大(含应用层头部,如 WebSocket 帧头) |
| 触发方式 | 连接空闲超时自动触发 | 应用层主动定时发送 |
| 灵活性 | 低(依赖系统参数) | 高(可自定义心跳内容、频率) |
| 适用场景 | 长连接、低带宽开销需求 | 需要业务层确认(如用户在线状态) |
| 跨网络设备兼容性 | 可能被防火墙拦截(部分防火墙禁用 ICMP/TCP 探测报文) | 兼容性强(使用业务端口和协议) |
四、工程实践注意事项
- 启用时机:仅对需要长时间保持的连接启用 Keep Alive(如即时通讯),短连接(如 HTTP 短连接)无需启用,避免额外的探测开销。
- 参数调优 :移动端(如 iOS)网络波动大,可缩短
keepalive_time(如 5-10 分钟)和keepalive_intvl(如 30 秒),减少半开连接的资源占用。 - 防火墙兼容:部分企业防火墙会拦截 TCP Keep Alive 探测报文,导致误判连接失效,此时需改用应用层心跳包。
- 应用层感知 :Keep Alive 由 TCP 协议栈处理,应用层默认无法感知探测过程。若需在应用层处理连接失效事件,可通过监听 socket 错误(如
ECONNRESET)实现。
五、记忆法
- 核心作用记忆:"探测连接存活性,释放半开连接,维护长连接,节省带宽";
- 参数流程记忆:"空闲超时触发(time),间隔重试(intvl),次数阈值(probes),失败则关闭";
- 与应用层心跳对比记忆:"TCP 底层轻量,应用层灵活,各取所需"。
请说明 TCP 的滑动窗口机制的原理及作用。
一、滑动窗口机制的核心定义与作用
TCP 滑动窗口机制是 TCP 实现流量控制 和高效传输的核心机制,本质是通过"窗口大小"动态调整发送方的发送速率,确保接收方能够及时处理数据,避免接收缓冲区溢出(流量控制),同时实现批量发送和累计确认(提升传输效率)。
- 核心作用 1:流量控制:接收方通过告知发送方自己的"接收窗口大小",限制发送方的发送速率,确保接收方有足够的缓冲区存储收到的数据,避免数据丢失。
- 核心作用 2:高效传输:支持"批量发送+累计确认",发送方无需等待每个报文段的确认即可连续发送窗口内的所有数据,减少等待时间;接收方无需逐个确认,可累计确认已收到的连续数据,减少 ACK 报文数量。
- 核心作用 3:适应网络波动:窗口大小可动态调整(如接收方缓冲区不足时缩小窗口,网络通畅时扩大窗口),适配不同的网络带宽和接收方处理能力。
二、滑动窗口的核心概念与原理
1. 核心概念定义
- 发送窗口(Send Window) :发送方允许连续发送的未确认数据的最大字节数,由"接收窗口大小(rwnd)"和"拥塞窗口大小(cwnd)"共同决定(发送窗口 = min(rwnd, cwnd))。
- 接收窗口(rwnd):接收方通过 TCP 首部的"Window Size"字段告知发送方,代表接收缓冲区剩余空间。
- 拥塞窗口(cwnd):发送方根据网络拥塞情况动态调整的窗口大小,用于拥塞控制(避免网络过载)。
- 接收窗口(Receive Window):接收方的接收缓冲区中未被应用层读取的空闲空间,随应用层读取数据而增大,随接收数据而减小。
- 窗口边界 :发送窗口分为四个区域(按序列号排序):
- 已发送且已确认(序号 < 已确认序号);
- 已发送但未确认(已确认序号 ≤ 序号 < 发送窗口左边界);
- 未发送但允许发送(发送窗口左边界 ≤ 序号 < 发送窗口右边界);
- 未发送且不允许发送(序号 ≥ 发送窗口右边界)。
- 滑动规则:当发送方收到接收方的 ACK 确认后,发送窗口整体向右滑动,滑动距离等于已确认的字节数。
2. 滑动窗口工作流程示例
假设:
- 主串(发送方)数据序列号:1-1000(每个数据段 100 字节,共 10 个数据段);
- 接收方初始接收窗口大小 rwnd = 300 字节(允许发送方连续发送 3 个数据段);
- 拥塞窗口 cwnd = 400 字节(网络无拥塞),因此发送窗口 = min(300, 400) = 300 字节。
流程如下:
- 初始状态:发送窗口左边界 = 1,右边界 = 301(1+300),允许发送数据段 1(1-100)、2(101-200)、3(201-300)。
- 发送数据:发送方连续发送数据段 1、2、3,此时"已发送但未确认"区域为 1-300。
- 接收与确认:接收方成功接收数据段 1、2、3,接收缓冲区剩余空间 = 300 - 300 = 0,因此在返回的 ACK 报文中,将 rwnd 设为 0(告知发送方暂停发送),同时确认号 = 301(累计确认 1-300 字节)。
- 应用层读取数据:接收方应用层读取数据段 1、2(共 200 字节),接收缓冲区剩余空间 = 200 字节,此时接收方发送 ACK 报文,确认号仍为 301(数据段 3 未被读取,仍需确认),rwnd = 200。
- 窗口滑动与继续发送:发送方收到 ACK 后,确认号 = 301,发送窗口左边界滑动至 301,右边界 = 301 + 200 = 501,允许发送数据段 4(301-400)、5(401-500)。发送方连续发送这两个数据段,重复上述流程。
3. 窗口调整机制
- 接收窗口调整:接收方应用层读取数据速度越快,接收缓冲区剩余空间越大,rwnd 越大,发送方发送速率越高;反之,若应用层读取缓慢,rwnd 减小,发送方暂停发送(rwnd=0 时),直到接收方发送新的 ACK 告知 rwnd>0。
- 拥塞窗口调整:网络拥塞时(如超时重传、收到重复 ACK),发送方减小 cwnd;网络通畅时(如连续收到有效 ACK),发送方缓慢增大 cwnd,避免网络过载(详见 TCP 拥塞控制)。
三、滑动窗口的关键细节与面试加分点
1. 累计确认(Cumulative Acknowledgment)
- 核心逻辑:接收方无需为每个数据段单独发送 ACK,只需确认"已收到的最大连续序列号 + 1"。例如,接收方收到数据段 1、2、3,只需发送 ACK=301(确认 1-300 字节),而非发送 3 个 ACK。
- 优势:减少 ACK 报文数量,降低网络开销;
- 注意:若中间数据段丢失(如数据段 2 丢失),接收方会持续发送 ACK=101(确认数据段 1,期望收到数据段 2),发送方超时后重传数据段 2,这就是"选择重传"的基础。
2. 零窗口探测(Zero Window Probe)
- 场景:当接收方 rwnd=0 时,发送方暂停发送数据,但需定期发送"零窗口探测报文"(仅 TCP 首部,无数据),询问接收方是否有空闲缓冲区。
- 处理:接收方收到探测报文后,若缓冲区有空闲,会在 ACK 报文中告知新的 rwnd;若仍无空闲,返回 rwnd=0,发送方继续等待下一次探测。
3. 滑动窗口与拥塞控制的关系
- 发送窗口的实际大小由"接收窗口(rwnd)"和"拥塞窗口(cwnd)"共同决定,即发送窗口 = min(rwnd, cwnd)。
- 流量控制(rwnd)解决"发送方与接收方速率不匹配"的问题,拥塞控制(cwnd)解决"发送方与网络速率不匹配"的问题,二者协同保证 TCP 传输的可靠性和高效性。
四、工程实践注意事项
- 窗口大小优化:移动端(如 iOS)网络带宽有限,接收方应根据自身处理能力动态调整 rwnd,避免设置过大导致缓冲区溢出,或过小导致传输效率低下。
- 零窗口处理:发送方需实现零窗口探测机制,避免因接收方 rwnd=0 而永久暂停发送。
- 选择重传(SACK) :开启 SACK 选项(TCP 首部的 SACK 字段),接收方可告知发送方具体丢失的数据段,发送方仅重传丢失部分,而非重传整个窗口的数据,提升传输效率(iOS 中可通过
setsockopt启用 SACK)。
五、记忆法
- 核心原理记忆:"窗口大小定速率,接收窗口控流量,拥塞窗口防过载,累计确认提效率,滑动跟随确认号";
- 工作流程记忆:"开窗发数据,接收返ACK,窗口随ACK滑,零窗探空闲";
- 关键公式记忆:"发送窗口 = min(rwnd, cwnd),流量控rwnd,拥塞控cwnd"。
请介绍 TCP 的确认机制的核心逻辑。
一、TCP 确认机制的核心定义与目标
TCP 确认机制(Acknowledgment Mechanism)是 TCP 实现可靠传输的核心基础,通过接收方向发送方返回确认报文(ACK 报文),告知已成功接收的数据范围,使发送方能够:
- 确认数据已被接收,避免重复发送;
- 检测数据丢失,触发重传机制;
- 结合滑动窗口机制,动态调整发送速率。
核心目标:确保数据无丢失、无重复、按序交付,是 TCP 区别于 UDP(无确认机制)的关键特性之一。
二、确认机制的核心逻辑与关键字段
1. 核心逻辑:序列号与确认号的协同
TCP 协议为每个字节的数据分配唯一的序列号(Sequence Number,Seq) ,同时接收方通过确认号(Acknowledgment Number,Ack) 告知发送方"已成功接收的最后一个字节的序列号 + 1",即"期望下一个收到的字节序列号"。
- 序列号(Seq):发送方发送数据时,Seq 字段表示当前数据段的第一个字节的序列号;若发送的是 ACK 报文(无数据),Seq 字段表示发送方上一次发送的最后一个字节的序列号(维持序列号连续性)。
- 确认号(Ack):仅当 TCP 首部的 ACK 标志位为 1 时有效,Ack 字段的值 = 接收方已成功接收的最大连续字节序列号 + 1。
关键原则:确认号是对"已接收数据"的确认,序列号是对"待发送数据"的标识,二者协同实现可靠传输。
2. TCP 首部关键字段(与确认机制相关)
| 字段名称 | 作用描述 |
|---|---|
| 序列号(Seq) | 4 字节,标识当前报文段的第一个字节的序列号 |
| 确认号(Ack) | 4 字节,标识期望下一个接收的字节序列号(仅 ACK=1 时有效) |
| ACK 标志位 | 1 位,置 1 表示确认号字段有效(几乎所有 TCP 报文都包含 ACK 标志,除了三次握手的第一个 SYN 报文) |
| 窗口大小(Window) | 2 字节,告知发送方当前接收窗口大小,用于流量控制 |
| 紧急指针(Urgent Pointer) | 2 字节,标识紧急数据的位置(与确认机制无关,补充说明) |
三、确认机制的具体实现场景
1. 正常数据传输的确认(累计确认)
这是最常见的场景,接收方采用"累计确认"机制,无需为每个数据段单独发送 ACK,而是确认"已收到的最大连续数据段"。
示例:
- 发送方发送数据段 1(Seq=1,数据范围 1-100)、数据段 2(Seq=101,数据范围 101-200)、数据段 3(Seq=201,数据范围 201-300);
- 接收方成功接收这三个数据段,且无乱序或丢失,因此返回 ACK 报文:
- ACK 标志位 = 1;
- 确认号 Ack = 301(表示已接收 1-300 字节,期望下一个接收 301 字节);
- 序列号 Seq = 接收方上一次发送的最后一个字节序列号(如三次握手时的 ISN_S + 1);
- 发送方收到 ACK 后,确认 1-300 字节已被接收,可继续发送后续数据段(Seq=301 开始)。
2. 乱序数据的确认(部分确认)
若接收方收到乱序数据段(如先收到数据段 3,再收到数据段 2,最后收到数据段 1),会仅确认"已收到的最大连续数据段",未连续的数据段会缓存,等待缺失的数据段到达后再合并确认。
示例:
- 发送方发送数据段 1、2、3,接收方接收顺序为 3 → 2 → 1;
- 接收方收到数据段 3 时,因 1-200 字节缺失,返回 ACK 报文,Ack=1(期望接收 1 字节);
- 接收方收到数据段 2 时,仍缺失 1-100 字节,返回 ACK 报文,Ack=1;
- 接收方收到数据段 1 时,1-300 字节连续,返回 ACK 报文,Ack=301;
- 发送方收到 Ack=1 时,知道数据段 1 未被接收,超时后重传数据段 1(实际接收方已收到,但未连续,需等待)。
3. 数据丢失的确认(重复确认与快速重传)
若数据段丢失(如数据段 2 丢失),接收方会持续发送"重复确认"(确认号不变),发送方收到一定数量的重复确认后,触发"快速重传",无需等待超时。
示例:
- 发送方发送数据段 1(Seq=1)、2(Seq=101)、3(Seq=201),数据段 2 丢失;
- 接收方收到数据段 1,返回 ACK=101(确认 1-100 字节);
- 接收方收到数据段 3,因缺失 101-200 字节,返回 ACK=101(重复确认);
- 发送方收到第一个重复 ACK(Ack=101),暂不处理;
- 接收方未收到数据段 2,后续若收到其他数据段(如数据段 4),仍返回 ACK=101;
- 当发送方收到 3 个连续的重复 ACK(Ack=101),判定数据段 2 丢失,立即重传数据段 2(快速重传);
- 接收方收到重传的数据段 2 后,1-300 字节连续,返回 ACK=301,发送方继续正常传输。
4. 纯 ACK 报文(无数据传输)
TCP 中,除了数据报文携带 ACK 外,也存在纯 ACK 报文(无应用层数据,仅 TCP 首部),用于单独确认数据或更新接收窗口大小。
示例:
- 接收方收到数据段后,因应用层未及时读取数据,接收缓冲区剩余空间减小,需告知发送方缩小窗口,此时发送纯 ACK 报文,携带新的窗口大小;
- 纯 ACK 报文的 Seq 字段 = 接收方上一次发送的最后一个字节序列号,Ack 字段 = 已接收的最大连续字节序列号 + 1,数据长度 = 0。
四、确认机制的关键优化与面试加分点
1. 延迟确认(Delayed ACK)
- 核心逻辑:接收方收到数据后,不立即发送 ACK,而是延迟一段时间(通常 200ms 以内),等待是否有数据要发送给对方,将 ACK 与数据报文合并发送,减少 ACK 报文数量,降低网络开销。
- 注意:延迟确认不能超过阈值,否则会导致发送方超时重传;若接收方连续收到多个数据段,需每隔一个数据段发送一次 ACK,避免发送方等待过久。
2. 快速重传与重复确认
- 核心逻辑:通过 3 个连续重复确认触发快速重传,相比超时重传(通常超时时间为 1-3 秒),大幅缩短重传延迟,提升传输
在 HTTP 断点续传场景下,如何确保分片全部传输完成后文件的完整性和无篡改?(提示:服务器分片传输时添加 HMAC 消息认证码)
一、核心问题分析
HTTP 断点续传的核心是将大文件分割为多个分片(通过 Range 字段指定字节范围),客户端分多次请求传输,最终合并为完整文件。需解决两个核心问题:
- 完整性:确保所有分片均被正确接收,无缺失、重复或顺序错误;
- 防篡改:确保传输过程中分片未被篡改(如网络劫持、数据损坏)。
仅依赖 Range 字段无法满足需求(仅能指定范围,无法验证数据),需结合"分片校验+整体校验"的双层机制,HMAC 消息认证码是核心技术之一(基于密钥的哈希验证,兼具防篡改和防伪造能力)。
二、完整解决方案设计(分阶段实现)
1. 预传输阶段:文件元信息协商(基础保障)
客户端发起断点续传前,先向服务器请求文件元信息,建立校验基准:
-
核心字段 :
Content-Length:文件总大小(用于验证合并后文件大小是否匹配);ETag:文件唯一标识(通常基于文件内容哈希生成,如 SHA-256,用于确认文件未被服务器修改);X-File-Chunk-Size:服务器推荐的分片大小(如 4MB,客户端可自定义,但需与服务器一致);X-File-HMAC:文件整体 HMAC 值(服务器基于密钥对完整文件计算的哈希值,如 HMAC-SHA256,用于最终整体校验)。
-
请求示例 :
HEAD /large-file.zip HTTP/1.1 Host: api.example.com -
响应示例 :
HTTP/1.1 200 OK Content-Length: 104857600 // 文件总大小 100MB ETag: "a1b2c3d4e5f67890" // 文件唯一标识 X-File-Chunk-Size: 4194304 // 分片大小 4MB X-File-HMAC: "hmac-sha256=abc123def456..." // 整体 HMAC 值 Accept-Ranges: bytes // 支持断点续传
2. 分片传输阶段:分片级校验(防篡改+防缺失)
客户端按协商的分片大小请求单个分片,服务器返回分片数据时附加分片级校验信息,确保每个分片的完整性和防篡改:
-
客户端请求分片 (指定 Range 字段):
GET /large-file.zip HTTP/1.1 Host: api.example.com Range: bytes=0-4194303 // 第一个分片(0-4MB) -
服务器响应分片 (附加分片校验信息):
HTTP/1.1 206 Partial Content Content-Range: bytes 0-4194303/104857600 Content-Length: 4194304 X-Chunk-Index: 0 // 分片索引(0 开始,用于排序) X-Chunk-HMAC: "hmac-sha256=xyz789..." // 分片 HMAC 值(服务器基于密钥计算) X-Chunk-Checksum: "crc32=123456..." // 分片 CRC32 校验和(快速校验) [分片二进制数据] -
客户端分片校验逻辑 :
- 接收分片后,先验证
X-Chunk-Index与请求的 Range 是否匹配(避免分片错乱); - 计算分片数据的 CRC32 校验和,与
X-Chunk-Checksum对比(快速排查传输错误); - 若 CRC32 匹配,使用预协商的密钥(客户端与服务器提前约定,如通过 HTTPS 传输的密钥)计算分片的 HMAC 值,与
X-Chunk-HMAC对比(防篡改、防伪造); - 校验通过则存储分片(记录已接收的分片索引),校验失败则重传该分片。
- 接收分片后,先验证
面试加分点:HMAC 相比单纯的哈希(如 SHA-256),增加了密钥维度------即使攻击者篡改分片数据并重新计算哈希值,若无密钥也无法生成有效的 HMAC 值,防篡改能力更强。
3. 合并校验阶段:整体完整性校验(最终保障)
所有分片接收完成后,客户端执行两步合并校验:
- 步骤 1:分片完整性校验 :对比已接收的分片索引集合与预期的索引集合(如 0-24 共 25 个分片),确保无缺失、无重复;合并分片时,按
X-Chunk-Index顺序拼接(避免顺序错误导致文件损坏)。 - 步骤 2:整体防篡改校验 :合并得到完整文件后,客户端使用预协商的密钥计算文件的整体 HMAC 值,与预传输阶段获取的
X-File-HMAC对比:- 若一致:文件完整且未被篡改,断点续传成功;
- 若不一致:文件可能被篡改或分片合并错误,需重新请求部分分片或整个文件。
4. 异常处理:断点续传的容错机制
- 分片丢失/校验失败:客户端记录未成功接收的分片索引,通过 Range 字段重新请求该分片(可设置重试次数,如 3 次);
- 服务器文件更新:若续传过程中服务器文件修改(ETag 变化),客户端需重新获取文件元信息,重新开始断点续传;
- 网络中断恢复:客户端本地缓存已接收的分片索引和文件元信息,网络恢复后仅请求未接收的分片。
三、关键技术细节与面试加分点
1. HMAC 密钥的安全传输
- 核心问题:HMAC 依赖客户端与服务器共享密钥,若密钥明文传输,攻击者可能窃取密钥后篡改数据;
- 解决方案:
- 基于 HTTPS 传输密钥(HTTPS 本身加密,确保密钥安全);
- 采用"临时密钥协商"机制(如 Diffie-Hellman),客户端与服务器动态生成共享密钥,无需提前存储;
- 密钥与文件 ETag 绑定(不同文件使用不同密钥,降低密钥泄露风险)。
2. 校验算法的选择(CRC32 vs HMAC)
| 校验算法 | 核心作用 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| CRC32 | 快速检测数据传输错误(如网络丢包、比特翻转) | 计算速度快,开销低 | 无防篡改能力(易被伪造) | 分片接收后的快速校验 |
| HMAC-SHA256 | 防篡改、防伪造 | 安全性高,基于密钥 | 计算开销略高 | 分片和整体的最终校验 |
工程实践:先通过 CRC32 快速排查明显错误,再通过 HMAC 做安全校验,兼顾效率和安全性。
3. iOS 客户端实现核心代码示例(Swift)
import Foundation
import CommonCrypto
class BreakpointResumeManager {
// 预协商的 HMAC 密钥(实际场景中通过 HTTPS 动态获取)
private let hmacKey = "secure-shared-key-123".data(using: .utf8)!
// 文件元信息(从服务器获取)
private var fileMeta: FileMeta!
// 已接收的分片索引集合
private var receivedChunkIndices = Set<Int>()
// 本地存储路径
private let localFilePath = NSSearchPathForDirectoriesInDomains(.documentDirectory, .userDomainMask, true).first! + "/large-file.zip"
// 文件元信息模型
struct FileMeta {
let totalSize: Int64
let etag: String
let chunkSize: Int64
let totalHMAC: String
let totalChunks: Int // 总分片数 = totalSize / chunkSize(向上取整)
}
// 1. 请求文件元信息
func fetchFileMeta(completion: @escaping (Bool) -> Void) {
guard let url = URL(string: "https://api.example.com/large-file.zip") else {
completion(false)
return
}
var request = URLRequest(url: url)
request.httpMethod = "HEAD"
URLSession.shared.dataTask(with: request) { [weak self] data, response, error in
guard let self = self, let httpResponse = response as? HTTPURLResponse, error == nil else {
completion(false)
return
}
// 解析文件元信息
guard let totalSize = httpResponse.expectedContentLength as? Int64,
let etag = httpResponse.allHeaderFields["ETag"] as? String,
let chunkSizeStr = httpResponse.allHeaderFields["X-File-Chunk-Size"] as? String,
let chunkSize = Int64(chunkSizeStr),
let totalHMAC = httpResponse.allHeaderFields["X-File-HMAC"] as? String else {
completion(false)
return
}
let totalChunks = Int(ceil(Double(totalSize) / Double(chunkSize)))
self.fileMeta = FileMeta(
totalSize: totalSize,
etag: etag,
chunkSize: chunkSize,
totalHMAC: totalHMAC,
totalChunks: totalChunks
)
completion(true)
}.resume()
}
// 2. 请求单个分片
func requestChunk(index: Int) {
guard let fileMeta = fileMeta, index < fileMeta.totalChunks else { return }
let startByte = Int64(index) * fileMeta.chunkSize
let endByte = min(startByte + fileMeta.chunkSize - 1, fileMeta.totalSize - 1)
guard let url = URL(string: "https://api.example.com/large-file.zip") else { return }
var request = URLRequest(url: url)
request.httpMethod = "GET"
request.setValue("bytes=\(startByte)-\(endByte)", forHTTPHeaderField: "Range")
URLSession.shared.dataTask(with: request) { [weak self] data, response, error in
guard let self = self, let data = data, let httpResponse = response as? HTTPURLResponse, error == nil else {
// 分片请求失败,重试(可设置重试次数)
DispatchQueue.main.asyncAfter(deadline: .now() + 1) {
self?.requestChunk(index: index)
}
return
}
// 解析分片校验信息
guard let chunkIndexStr = httpResponse.allHeaderFields["X-Chunk-Index"] as? String,
let chunkIndex = Int(chunkIndexStr),
let chunkHMAC = httpResponse.allHeaderFields["X-Chunk-HMAC"] as? String,
let chunkCRC32 = httpResponse.allHeaderFields["X-Chunk-Checksum"] as? String else {
// 校验信息缺失,重试
self?.requestChunk(index: index)
return
}
// 步骤 1:校验分片索引匹配
guard chunkIndex == index else { return }
// 步骤 2:CRC32 快速校验
let calculatedCRC32 = self.calculateCRC32(for: data)
guard calculatedCRC32 == chunkCRC32.components(separatedBy: "=").last else {
self?.requestChunk(index: index)
return
}
// 步骤 3:HMAC 校验
guard self.verifyHMAC(for: data, expectedHMAC: chunkHMAC.components(separatedBy: "=").last!) else {
self?.requestChunk(index: index)
return
}
// 校验通过,写入本地文件(追加模式)
self.writeChunkToFile(data: data, startByte: startByte)
self.receivedChunkIndices.insert(index)
// 检查是否所有分片都已接收
if self.receivedChunkIndices.count == fileMeta.totalChunks {
self.verifyTotalFile()
}
}.resume()
}
// 3. 写入分片到本地文件(追加模式)
private func writeChunkToFile(data: Data, startByte: Int64) {
let fileURL = URL(fileURLWithPath: localFilePath)
let fileHandle: FileHandle
if FileManager.default.fileExists(atPath: localFilePath) {
fileHandle = try! FileHandle(forWritingTo: fileURL)
fileHandle.seek(toFileOffset: startByte)
} else {
FileManager.default.createFile(atPath: localFilePath, contents: nil)
fileHandle = try! FileHandle(forWritingTo: fileURL)
}
fileHandle.write(data)
fileHandle.closeFile()
}
// 4. 整体文件校验
private func verifyTotalFile() {
guard let fileMeta = fileMeta, let totalFileData = try? Data(contentsOf: URL(fileURLWithPath: localFilePath)) else { return }
// 校验文件大小
guard totalFileData.count == fileMeta.totalSize else {
print("文件大小不匹配,续传失败")
return
}
// 校验整体 HMAC
let calculatedTotalHMAC = self.calculateHMAC(for: totalFileData)
guard calculatedTotalHMAC == fileMeta.totalHMAC.components(separatedBy: "=").last else {
print("文件被篡改,续传失败")
return
}
print("断点续传成功,文件完整且未被篡改")
}
// 辅助方法:计算 CRC32
private func calculateCRC32(for data: Data) -> String {
var crc: UInt32 = 0xFFFFFFFF
data.forEach { byte in
crc ^= UInt32(byte)
for _ in 0..<8 {
crc = (crc >> 1) ^ ((crc & 1) == 1 ? 0xEDB88320 : 0)
}
}
return String(format: "%08X", ~crc)
}
// 辅助方法:计算 HMAC-SHA256
private func calculateHMAC(for data: Data) -> String {
var hmac = [UInt8](repeating: 0, count: Int(CC_SHA256_DIGEST_LENGTH))
data.withUnsafeBytes { dataBytes in
hmacKey.withUnsafeBytes { keyBytes in
CCHmac(CCHmacAlgorithm(kCCHmacAlgSHA256), keyBytes.baseAddress, hmacKey.count, dataBytes.baseAddress, data.count, &hmac)
}
}
return hmac.map { String(format: "%02x", $0) }.joined()
}
// 辅助方法:验证 HMAC
private func verifyHMAC(for data: Data, expectedHMAC: String) -> Bool {
return calculateHMAC(for: data) == expectedHMAC
}
}四、记忆法
- 核心流程记忆:"预传元信息(定大小、HMAC、分片数)→ 分片传输(带索引+双校验)→ 合并拼接(按索引排序)→ 整体校验(对比总 HMAC)";
- 校验逻辑记忆:"分片校验:CRC32 快检 + HMAC 安检;整体校验:大小+总 HMAC,双重保障无篡改";
- 安全关键点记忆:"HMAC 密钥要加密,分片索引防错乱,ETag 绑定防更新,重试机制容错错"。
请列举 HTTP 常见的状态码,并说明其含义(如 200、301、404、500 等)。
一、HTTP 状态码的核心定义与分类
HTTP 状态码是服务器向客户端返回的"请求处理结果标识",由三位数字组成,首位数字表示状态码类别,共分为 5 大类(1xx-5xx),遵循 HTTP/1.1 规范(RFC 7231):
- 1xx:信息性状态码(Informational)→ 请求已接收,继续处理;
- 2xx:成功状态码(Success)→ 请求已成功处理;
- 3xx:重定向状态码(Redirection)→ 需要客户端进一步操作才能完成请求;
- 4xx:客户端错误状态码(Client Error)→ 请求存在错误,服务器无法处理;
- 5xx:服务器错误状态码(Server Error)→ 服务器处理请求时发生错误。
核心设计原则:语义化、标准化,客户端可根据状态码快速判断请求结果,无需解析响应体。
二、各类常见状态码详细解析(含场景说明)
1. 1xx 信息性状态码(临时响应,少见)
- 100 Continue :
- 含义:服务器已接收请求头,客户端可继续发送请求体(如 POST 大文件时);
- 场景:客户端发送
Expect: 100-continue头后,服务器返回该状态码表示允许继续发送请求体;若服务器拒绝,返回 417 Expectation Failed。
- 101 Switching Protocols :
- 含义:服务器同意客户端的协议切换请求(如 HTTP/1.1 切换到 WebSocket);
- 场景:WebSocket 连接建立时,客户端发送
Upgrade: websocket头,服务器返回 101 确认切换。
2. 2xx 成功状态码(最常用)
- 200 OK :
- 含义:请求成功,服务器已正常返回请求的资源;
- 场景:GET 请求获取资源、POST 请求提交数据成功、PUT 请求更新资源成功;
- 注意:响应体通常包含资源数据(如 JSON、HTML)。
- 201 Created :
- 含义:请求成功,服务器已创建新的资源;
- 场景:POST 请求创建资源(如创建用户、订单)、PUT 请求创建不存在的资源;
- 注意:响应头通常包含
Location字段,指向新创建资源的 URL(如Location: /users/1001)。
- 204 No Content :
- 含义:请求成功,但响应体为空(无数据返回);
- 场景:DELETE 请求删除资源成功、PUT 请求更新资源但无需返回数据、HEAD 请求获取响应头;
- 注意:响应体必须为空,客户端无需解析数据。
- 206 Partial Content :
- 含义:请求成功,服务器返回部分资源(断点续传场景);
- 场景:客户端通过 Range 字段请求文件分片(如
Range: bytes=0-4194303); - 注意:响应头包含
Content-Range字段(如Content-Range: bytes 0-4194303/104857600),标识返回的字节范围。
3. 3xx 重定向状态码(客户端需跳转)
- 301 Moved Permanently :
- 含义:资源已永久移动到新 URL,后续请求应使用新 URL;
- 场景:网站域名变更(如
example.com迁移到new-example.com)、资源路径调整; - 注意:浏览器会缓存新 URL,下次直接访问新地址;SEO 权重会转移到新 URL。
- 302 Found :
- 含义:资源临时移动到新 URL,后续请求仍可使用原 URL;
- 场景:临时维护跳转、登录后跳转回原页面;
- 注意:浏览器不缓存新 URL,每次请求都会先访问原 URL 再跳转;HTTP/1.1 后推荐用 303/307 替代 302(避免方法篡改)。
- 303 See Other :
- 含义:资源临时存在于新 URL,客户端应使用 GET 方法访问新 URL;
- 场景:POST 请求提交数据后,跳转至结果页面(避免刷新页面重复提交);
- 注意:强制将原请求方法转为 GET(如原 POST 变为 GET),避免数据重复提交。
- 304 Not Modified :
- 含义:资源未修改(客户端缓存的版本仍有效),服务器无需返回资源数据;
- 场景:客户端携带缓存校验头(
If-Modified-Since或If-None-Match),服务器验证资源未更新时返回; - 注意:响应体为空,客户端直接使用本地缓存,节省带宽;核心缓存机制的关键状态码。
- 307 Temporary Redirect :
- 含义:临时重定向,保留原请求方法(不篡改 GET/POST/PUT 等方法);
- 场景:临时跳转且需保持原请求方法(如 POST 提交数据到临时服务器);
- 对比 302:302 可能被浏览器转为 GET,307 严格保留原方法,更规范。
4. 4xx 客户端错误状态码(客户端责任)
- 400 Bad Request :
- 含义:请求格式错误,服务器无法解析;
- 场景:请求参数格式错误(如 JSON 语法错误)、URL 非法字符、请求头缺失必填字段;
- 注意:客户端需修改请求格式后重新发送。
- 401 Unauthorized :
- 含义:请求未授权(缺少认证信息或认证失效);
- 场景:未登录访问需要权限的接口、Token 过期、用户名密码错误;
- 注意:响应头通常包含
WWW-Authenticate字段,指示客户端需要的认证方式(如 Basic、Bearer);与 403 的区别:401 是"未认证",403 是"已认证但无权限"。
- 403 Forbidden :
- 含义:客户端已认证,但无权限访问该资源;
- 场景:普通用户访问管理员接口、IP 被封禁、资源设置了访问权限;
- 注意:服务器明确拒绝请求,即使重新提交认证信息也无效。
- **404 Not
请说明 DNS 系统的定义、解析过程、所属协议层,以及通过域名查找对应 IP 地址的具体流程。
一、DNS 系统的核心定义
DNS(Domain Name System,域名系统)是互联网的"地址簿",核心作用是将人类易记的域名(如 www.baidu.com)映射为计算机可识别的 IP 地址(如 14.215.177.38),解决"IP 地址难记忆、易变更"的问题。
DNS 系统的核心特征:
- 分布式架构:无中央服务器,由全球多个 DNS 服务器协同工作(根服务器、顶级域服务器、权威服务器等),确保高可用和负载均衡;
- 层次化域名结构:域名按层级划分(如
www.baidu.com分为主机名www、二级域baidu、顶级域com),对应 DNS 服务器的层级结构; - 缓存机制:DNS 解析结果会被本地客户端、路由器、DNS 服务器缓存,减少重复解析,提升访问速度。
二、DNS 系统的所属协议层
DNS 属于 TCP/IP 模型的应用层,核心依据:
- 协议目标:服务于应用层的域名解析需求(如浏览器、APP 访问网站),是应用层通信的前置条件;
- 传输协议:DNS 解析请求通常使用 UDP 协议(端口 53),优点是速度快、开销低;若解析结果超过 UDP 报文长度限制(512 字节),则自动切换为 TCP 协议;
- 协议规范:DNS 有独立的应用层协议标准(RFC 1034/1035),定义了报文格式、解析流程、服务器交互规则。
面试加分点:UDP 用于普通解析请求(查询),TCP 用于批量解析、区域传输(DNS 服务器之间同步数据)、长报文传输,二者互补确保解析可靠性。
三、DNS 解析的核心过程(从域名到 IP 的映射流程)
DNS 解析是"递归查询 + 迭代查询"结合的过程,核心参与者包括:本地 DNS 客户端、本地 DNS 服务器、根 DNS 服务器、顶级域(TLD)服务器、权威 DNS 服务器。
1. 核心参与者说明
| 参与者类型 | 作用描述 |
|---|---|
| 本地 DNS 客户端 | 安装在用户设备上的 DNS 客户端(如操作系统 DNS 缓存、浏览器缓存),优先查询本地缓存 |
| 本地 DNS 服务器 | 由 ISP(网络服务提供商,如电信、联通)或企业部署的 DNS 服务器(如 223.5.5.5),是解析的"中间代理" |
| 根 DNS 服务器 | 全球共 13 组(逻辑上),负责指向顶级域服务器,是 DNS 解析的"入口" |
| 顶级域服务器 | 负责管理顶级域(如 .com、.cn、.org),指向权威 DNS 服务器 |
| 权威 DNS 服务器 | 域名的"官方服务器",存储域名与 IP 地址的映射关系(如 baidu.com 的权威服务器),是解析结果的最终来源 |
2. 完整解析流程(以查询 www.baidu.com 为例)
-
本地缓存查询(最快路径):
- 用户设备(如手机、电脑)的 DNS 客户端先查询本地缓存(操作系统缓存、浏览器缓存、路由器缓存);
- 若缓存中存在
www.baidu.com对应的 IP 地址(且未过期),直接返回结果,解析结束; - 若缓存中无该记录,发起下一步查询。
-
本地 DNS 服务器查询(递归查询):
- 客户端向本地 DNS 服务器(如 ISP 提供的 223.5.5.5)发送解析请求,该过程为"递归查询"------客户端只需等待最终结果,无需关心中间过程;
- 本地 DNS 服务器先查询自身缓存,若有记录则返回;若无,向根 DNS 服务器发起查询。
-
根 DNS 服务器查询(迭代查询):
- 本地 DNS 服务器向根 DNS 服务器发送请求,根服务器不存储具体域名的 IP 地址,仅返回
.com顶级域服务器的 IP 地址(如 192.5.6.30); - 迭代查询的核心:本地 DNS 服务器需主动向后续服务器发送请求,直至获取最终结果。
- 本地 DNS 服务器向根 DNS 服务器发送请求,根服务器不存储具体域名的 IP 地址,仅返回
-
顶级域(TLD)服务器查询:
- 本地 DNS 服务器向
.com顶级域服务器发送请求,顶级域服务器返回baidu.com权威 DNS 服务器的 IP 地址(如 202.108.22.5);
- 本地 DNS 服务器向
-
权威 DNS 服务器查询(最终结果):
- 本地 DNS 服务器向
baidu.com的权威 DNS 服务器发送请求,权威服务器存储了www.baidu.com与 IP 地址的映射关系,返回目标 IP 地址(如 14.215.177.38);
- 本地 DNS 服务器向
-
结果缓存与返回:
- 本地 DNS 服务器将权威服务器返回的 IP 地址缓存(设置 TTL 过期时间,通常为几分钟到几小时),避免重复查询;
- 本地 DNS 服务器将 IP 地址返回给客户端,客户端缓存该结果后,使用 IP 地址与服务器建立连接(如 TCP 三次握手)。
面试加分点:TTL(Time To Live)是 DNS 缓存的过期时间,权威服务器会为每条解析记录设置 TTL(如 300 秒),缓存服务器需在 TTL 过期后重新查询,确保解析结果的时效性。
四、DNS 解析的关键细节(面试高频考点)
-
递归查询 vs 迭代查询:
- 递归查询:客户端 → 本地 DNS 服务器(客户端仅发送一次请求,等待最终结果);
- 迭代查询:本地 DNS 服务器 → 根服务器 → 顶级域服务器 → 权威服务器(本地 DNS 服务器需多次发送请求,逐步获取下一级服务器地址);
- 核心区别:递归是"被动等待",迭代是"主动查询",二者结合既减轻客户端负担,又避免单一服务器压力过大。
-
DNS 报文格式(核心字段):
- 标识(ID):16 位,匹配请求与响应,确保客户端能识别对应的解析结果;
- 标志位:包含查询/响应标志(0=查询,1=响应)、递归请求标志(RD)、递归可用标志(RA);
- 查询记录(QNAME):待解析的域名(如 www.baidu.com);
- 资源记录(ANCOUNT):响应中的解析结果(IP 地址)。
-
DNS 负载均衡:
- 权威 DNS 服务器可返回多个 IP 地址(如
www.baidu.com对应多个服务器 IP),客户端随机选择一个连接,实现负载均衡; - 结合地理信息:权威服务器可根据客户端的 IP 地址(通过本地 DNS 服务器上报),返回距离最近的服务器 IP,降低网络延迟。
- 权威 DNS 服务器可返回多个 IP 地址(如
五、iOS 中 DNS 解析的代码示例(Swift)
import Foundation
import Network
class DNSResolver {
// 解析域名(使用系统 DNS 客户端)
func resolveDomain(_ domain: String, completion: @escaping (Result<[String], Error>) -> Void) {
// 方法 1:使用 NWConnection 进行 DNS 解析(推荐,支持 IPv4/IPv6)
let host = NWEndpoint.Host(domain)
NWEndpoint.Host.resolve(host, queue: .global()) { endpoints, error in
if let error = error {
completion(.failure(error))
return
}
let ips = endpoints.compactMap { endpoint -> String? in
guard case .hostPort(let host, _) = endpoint else { return nil }
switch host {
case .ipv4(let ipv4): return ipv4.rawValue
case .ipv6(let ipv6): return ipv6.rawValue
default: return nil
}
}
completion(.success(ips))
}
// 方法 2:使用 getaddrinfo 函数(C 语言接口,兼容旧系统)
/*
var hints = addrinfo(
ai_flags: AI_CANONNAME,
ai_family: AF_UNSPEC, // 支持 IPv4 和 IPv6
ai_socktype: SOCK_STREAM,
ai_protocol: IPPROTO_TCP,
ai_addrlen: 0,
ai_canonname: nil,
ai_addr: nil,
ai_next: nil
)
var res: UnsafeMutablePointer<addrinfo>?
let status = getaddrinfo(domain, nil, &hints, &res)
defer { freeaddrinfo(res) }
if status != 0 {
completion(.failure(NSError(domain: "DNSResolver", code: status, userInfo: [NSLocalizedDescriptionKey: gai_strerror(status)])))
return
}
var ips = [String]()
var ptr = res
while ptr != nil {
guard let addr = ptr?.pointee.ai_addr else { break }
var ipBuffer = [CChar](repeating: 0, count: Int(INET6_ADDRSTRLEN))
let family = addr.pointee.sa_family
if family == AF_INET {
let ipv4Addr = addr.withMemoryRebound(to: sockaddr_in.self, capacity: 1) { $0.pointee.sin_addr }
inet_ntop(family, &ipv4Addr, &ipBuffer, socklen_t(ipBuffer.count))
} else if family == AF_INET6 {
let ipv6Addr = addr.withMemoryRebound(to: sockaddr_in6.self, capacity: 1) { $0.pointee.sin6_addr }
inet_ntop(family, &ipv6Addr, &ipBuffer, socklen_t(ipBuffer.count))
}
if let ip = String(validatingUTF8: ipBuffer) {
ips.append(ip)
}
ptr = ptr?.pointee.ai_next
}
completion(.success(ips))
*/
}
}
// 使用示例
let resolver = DNSResolver()
resolver.resolveDomain("www.baidu.com") { result in
switch result {
case .success(let ips):
print("解析结果:\(ips)") // 输出:["14.215.177.38", "14.215.177.39"] 等
case .failure(let error):
print("解析失败:\(error.localizedDescription)")
}
}六、记忆法
- 核心定义记忆:"DNS 是地址簿,域名转 IP,分布式架构,缓存提速度";
- 层级与流程记忆:"本地缓存→本地 DNS→根服务器→顶级域服务器→权威服务器,递归+迭代结合,缓存贯穿全程";
- 协议层记忆:"DNS 属应用层,UDP 快查询,TCP 传长文,端口 53 是标配"。
DNS 劫持是什么?有哪些有效的预防措施?
一、DNS 劫持的核心定义与危害
DNS 劫持(DNS Hijacking)是指攻击者通过篡改 DNS 解析结果,将域名指向恶意 IP 地址,导致用户访问的不是目标服务器,而是攻击者控制的服务器。
1. DNS 劫持的核心原理
攻击者通过以下方式篡改解析结果:
- 篡改本地 DNS 缓存:在用户设备(如电脑、手机)上修改 DNS 缓存,将目标域名映射为恶意 IP;
- 劫持本地 DNS 服务器:入侵 ISP 或企业的本地 DNS 服务器,修改解析记录;
- 伪造 DNS 响应:在网络中拦截客户端的 DNS 请求,伪造权威服务器的响应,返回恶意 IP;
- 诱骗用户修改 DNS 服务器地址:通过钓鱼链接、恶意 APP 诱导用户将设备的 DNS 服务器改为攻击者控制的地址。
2. DNS 劫持的主要危害
- 钓鱼攻击:将银行、购物网站的域名指向伪造的钓鱼网站,窃取用户账号密码、支付信息;
- 恶意软件传播:强制用户访问包含恶意软件的网站,导致设备被植入病毒、木马;
- 广告弹窗:将正常网站解析到包含广告的服务器,干扰用户体验(如运营商 DNS 劫持弹窗广告);
- 拒绝服务(DoS):将域名指向无效 IP,导致用户无法访问目标网站;
- 数据窃取:拦截用户与服务器的通信数据(如未加密的 HTTP 流量),窃取敏感信息。
二、DNS 劫持的有效预防措施(分层防护)
1. 终端设备层面(用户可自主操作)
- 使用可信 DNS 服务器 :避免使用未知的公共 DNS,优先选择权威、安全的 DNS 服务器,如:
- 阿里云 DNS:223.5.5.5、223.6.6.6;
- 腾讯云 DNS:119.29.29.29;
- ogle DNS:8.8.8.8、8.8.4.4;
- 配置方式:iOS 中通过"设置 → WLAN → 已连接网络 → 配置 DNS → 手动"添加可信 DNS。
- 定期清理 DNS 缓存 :避免本地缓存被篡改,iOS 中可通过以下方式清理:
- 关闭并重新打开 WLAN;
- 重启设备;
- 使用终端命令(需越狱):
killall mDNSResponder。
- 禁用不可信的网络配置:不连接无密码的公共 Wi-Fi,避免在不安全网络中访问敏感网站(如银行、支付平台);
- 安装安全软件:使用具备 DNS 防护功能的安全 APP,实时监测并拦截恶意 DNS 解析。
2. 应用层层面(开发者可实现)
- DNS -over-HTTPS(DoH)/DNS-over-TLS(DoT) :
- 核心原理:将 DNS 解析请求加密传输(DoH 基于 HTTPS,DoT 基于 TLS),避免解析过程被拦截、篡改;
- 实现方式:iOS 14+ 支持系统级 DoH 配置,开发者也可在 APP 中集成 DoH 库(如
libunbound),直接向 DoH 服务器发送加密解析请求; - 优势:相比传统 DNS,DoH/DoT 能有效防御中间人攻击和 DNS 劫持,解析结果更可信。
- DNS 缓存校验:APP 本地缓存 DNS 解析结果时,可结合域名的 ETag 或 HMAC 校验(与服务器预协商密钥),检测缓存是否被篡改;
- IP 直连 + 域名校验:对于核心服务(如 API 服务器),可在 APP 中内置默认 IP 地址,当 DNS 解析结果异常时(如指向未知 IP),自动切换为 IP 直连,并通过 TLS 证书校验服务器身份(避免 IP 被劫持);
- 多 DNS 解析对比:同时向多个可信 DNS 服务器(如阿里云 DNS + ogle DNS)发送解析请求,对比结果一致性,若结果差异较大,提示用户存在劫持风险。
3. 服务器层面(企业/网站运营者可实现)
- 部署 DNSSEC(DNS 安全扩展) :
- 核心原理:为 DNS 解析记录添加数字签名,客户端可验证解析结果的完整性和真实性,防止攻击者伪造响应;
- 实现方式:权威 DNS 服务器对解析记录进行签名,客户端通过根服务器、顶级域服务器的公钥验证签名有效性;
- 优势:从根源上防御 DNS 劫持,是 DNS 安全的核心标准(RFC 4033/4034/4035)。
- 使用 Anycast 技术:将权威 DNS 服务器部署在全球多个节点,通过 Anycast 路由技术,让用户访问最近的节点,降低单点劫持风险;
- 监控 DNS 解析记录:定期检查权威 DNS 服务器的解析记录,及时发现并修复被篡改的记录;
- 限制 DNS 区域传输:配置权威 DNS 服务器,仅允许信任的服务器进行区域传输(避免攻击者获取完整的解析记录)。
4. 网络层面(企业/组织可实现)
- 部署防火墙/IPS 设备:拦截异常的 DNS 请求(如指向恶意 IP 的解析请求),禁止未授权的 DNS 服务器访问;
- 内部 DNS 服务器隔离:将企业内部 DNS 服务器与公网隔离,仅允许内部设备访问,防止被外部攻击;
- 加密 DNS 传输:企业内部网络中强制使用 DoH/DoT 协议,避免内部 DNS 解析被劫持。
三、面试加分点:DNS 劫持与 HTTP 劫持的区别
| 劫持类型 | 劫持对象 | 技术原理 | 防御方式 |
|---|---|---|---|
| DNS 劫持 | DNS 解析结果 | 篡改域名与 IP 的映射关系 | DoH/DoT、DNSSEC、可信 DNS |
| HTTP 劫持 | HTTP 报文 | 拦截未加密的 HTTP 流量,篡改响应内容(如插入广告) | HTTPS 加密、HSTS 协议 |
关键结论:DNS 劫持发生在"地址解析阶段",HTTP 劫持发生在"数据传输阶段",二者防御方式互补,结合使用可提升安全性(如 HTTPS + DoH)。
四、记忆法
- DNS 劫持定义记忆:"篡改 DNS 解析,域名指恶意 IP,用于钓鱼、植木马、弹广告";
- 预防措施记忆:"终端用可信 DNS,应用层加密 DoH/DoT,服务器部署 DNSSEC,网络层防火墙拦截,多层防护无死角";
- 核心防御技术记忆:"DoH/DoT 加密传输,DNSSEC 签名验证,可信 DNS 源头保障,多解析对比防篡改"。
除了便于记忆外,为什么使用域名访问服务器而非直接使用 IP 地址?
一、核心原因:IP 地址的固有缺陷与域名的解决方案
除了"便于人类记忆"(表层原因),使用域名访问服务器的核心价值在于解决 IP 地址的四大固有缺陷,确保互联网服务的稳定性、灵活性和可扩展性。
1. IP 地址易变更,域名可永久绑定(服务稳定性保障)
- IP 地址的变更场景:
- 服务器迁移(如企业更换机房、云服务器升级);
- ISP 分配的公网 IP 变更(如动态 IP 家庭宽带);
- 服务器集群扩容/缩容(如电商大促时增加服务器节点);
- 域名的解决方案:
- 域名与服务器的映射关系存储在权威 DNS 服务器中,当 IP 地址变更时,只需修改权威 DNS 中的解析记录(TTL 过期后全网生效),用户无需任何操作,仍可通过原域名访问服务;
- 示例:百度服务器 IP 可能因机房迁移而变更,但
www.baidu.com域名不变,用户感知不到 IP 变化,服务不中断。
2. 支持负载均衡与故障转移(服务可用性提升)
- IP 地址的局限:单个 IP 通常对应一台服务器,无法实现多服务器分担压力,且服务器故障后服务直接中断;
- 域名的解决方案:
- 权威 DNS 服务器可返回多个 IP 地址(对应多台服务器),客户端随机选择一个连接,实现负载均衡(如
www.taobao.com对应上千台服务器 IP); - 结合健康检查:权威 DNS 服务器可实时监测后端服务器状态,若某台服务器故障,自动从解析结果中移除其 IP,实现故障转移(用户无感知切换到正常服务器);
- 地理负载均衡:根据用户的地理位置(通过本地 DNS 服务器 IP 判断),返回距离最近的服务器 IP,降低网络延迟(如北方用户访问北京机房,南方用户访问广州机房)。
- 权威 DNS 服务器可返回多个 IP 地址(对应多台服务器),客户端随机选择一个连接,实现负载均衡(如
3. 支持多服务共享同一 IP(资源利用率优化)
- IP 地址的稀缺性:IPv4 地址资源有限(全球约 43 亿个),企业获取多个公网 IP 成本高;
- 域名的解决方案:
- 多个域名可解析到同一个 IP 地址,通过 HTTP/HTTPS 的
Host头字段区分不同服务; - 示例:一台服务器(IP:192.168.1.100)可同时部署博客(
blog.example.com)、官网(www.example.com)、API 服务(api.example.com),客户端访问不同域名时,服务器通过Host头返回对应服务的内容,无需为每个服务分配独立 IP。
- 多个域名可解析到同一个 IP 地址,通过 HTTP/HTTPS 的
4. 支持服务分级与扩展(业务灵活性提升)
- 域名的层次化结构可对应业务的分级架构,便于服务扩展和管理:
- 主域名:
example.com(企业核心域名); - 子域名:
www.example.com(官网)、api.example.com(API 服务)、admin.example.com(管理后台)、app.example.com(移动端服务); - 扩展优势:新增业务时,只需添加子域名解析(如
shop.example.com电商业务),无需调整现有服务的 IP 配置,架构灵活且可扩展。
- 主域名:
请简述虚拟内存技术(包含分页、分段、段页式),说明虚拟内存的定义和核心作用(提示:扩大逻辑内存、共享内存、避免内存碎片);并说明段页式内存管理的优势。
一、虚拟内存的核心定义
虚拟内存(Virtual Memory)是操作系统提供的一种内存抽象技术 ,核心是将"物理内存(RAM)"与"磁盘存储空间(如硬盘交换分区)"结合,为进程提供一个远大于实际物理内存的"逻辑内存空间"。进程访问内存时,直接操作虚拟地址,由操作系统的内存管理单元(MMU)和页表将虚拟地址动态映射到物理地址(或磁盘地址),进程无需感知物理内存的实际大小和分布。
虚拟内存的核心特征:
- 逻辑内存与物理内存分离:进程看到的是连续的虚拟地址空间,而物理内存可能是离散的,甚至部分数据存储在磁盘上;
- 按需加载(Demand Paging):仅将当前进程运行所需的部分数据加载到物理内存,其余数据留在磁盘,节省物理内存资源;
- 地址映射透明化:虚拟地址到物理地址的映射由操作系统自动完成,无需程序员干预。
二、虚拟内存的三大核心作用
- 扩大逻辑内存空间:解决"物理内存不足"的问题。即使物理内存只有 8GB,操作系统也可为每个进程分配 64GB 的虚拟内存(如 64 位系统),进程可运行远超物理内存大小的程序(如大型游戏、数据库),不足部分通过磁盘交换补充。
- 实现内存共享与隔离 :
- 共享:多个进程可共享同一段虚拟内存(如操作系统内核代码、公共库文件),避免重复加载,节省物理内存;
- 隔离:每个进程拥有独立的虚拟地址空间,进程间无法直接访问对方的虚拟内存,确保进程运行安全(如一个进程崩溃不会影响其他进程)。
- 避免内存碎片,提升内存利用率 :
- 外部碎片:物理内存被多个进程占用后,剩余的零散空间无法满足新进程的连续内存需求;虚拟内存通过离散分配(分页/分段),将物理内存划分为固定大小的块,避免大的外部碎片;
- 内部碎片:分页会产生少量内部碎片(块内未使用的空间),但远小于外部碎片的影响,且可通过优化页大小降低。
三、虚拟内存的三种核心实现技术(分页、分段、段页式)
1. 分页存储管理(Paging)
- 核心原理 :将虚拟地址空间和物理地址空间均划分为大小固定的块(称为"页(Page)"和"页框(Page Frame)",二者大小相等,如 4KB、8KB);
- 地址结构:虚拟地址 = 页号 + 页内偏移量,物理地址 = 页框号 + 页内偏移量;
- 映射机制:通过"页表"记录虚拟页号与物理页框号的对应关系,MMU 依据页表将虚拟地址转换为物理地址;
- 关键流程:进程访问虚拟地址时,若对应的页已加载到物理内存(页表命中),直接映射访问;若未加载(缺页中断),操作系统将磁盘上的该页加载到物理内存,更新页表后继续访问。
- 优点:无外部碎片,内存分配简单;
- 缺点:存在内部碎片(页内未使用空间);地址转换需多次访问页表,开销较高(可通过快表 TLB 优化)。
2. 分段存储管理(Segmentation)
- 核心原理 :按程序的逻辑结构(如代码段、数据段、堆、栈)将虚拟地址空间划分为大小不固定的段(如代码段 10MB、数据段 5MB),每个段对应一个逻辑单元;
- 地址结构:虚拟地址 = 段号 + 段内偏移量;
- 映射机制:通过"段表"记录每个段的基地址(物理内存起始地址)和段长度,MMU 检查段内偏移量是否超出段长度(越界检查),再计算物理地址;
- 优点:无内部碎片,符合程序逻辑(便于代码共享、保护,如代码段只读共享);
- 缺点:存在外部碎片(多个段占用物理内存后,剩余零散空间无法分配);段大小动态变化,内存分配和管理复杂。
3. 段页式存储管理(Segmented Paging)
- 核心原理:结合分页和分段的优点,先按逻辑结构分段,再将每个段划分为固定大小的页,物理内存仍划分为页框;
- 地址结构:虚拟地址 = 段号 + 页号 + 页内偏移量;
- 映射机制 :通过"段表→页表→物理页框"的二级映射:
- 段表:记录每个段的页表基地址(该段的页表在物理内存的位置);
- 页表:记录该段内虚拟页号与物理页框号的对应关系;
- MMU 先通过段号查找段表,获取页表基地址,再通过页号查找页表,获取物理页框号,最后结合页内偏移量得到物理地址。
四、段页式内存管理的核心优势(面试重点)
段页式结合了分页和分段的优点,弥补了二者的缺陷,是现代操作系统(如 iOS、macOS、Windows、Linux)的主流内存管理方式,核心优势如下:
- 无外部碎片,内部碎片可控 :
- 继承分页的优点,物理内存按页框分配,避免外部碎片;
- 内部碎片仅存在于每个段的最后一页,且页大小固定(如 4KB),碎片大小有限,整体内存利用率高。
- 符合程序逻辑,支持共享与保护 :
- 继承分段的优点,按程序逻辑分段(代码段、数据段、栈段),便于实现内存共享(如多个进程共享同一代码段)和权限保护(如代码段只读、数据段可读写);
- 例如,iOS 中多个 APP 可共享系统框架(如 UIKit)的代码段,无需重复加载到物理内存,节省资源。
- 地址空间灵活,支持大程序运行 :
- 每个段的大小可动态调整(如堆段随内存分配增长),同时虚拟地址空间通过分页映射到物理内存和磁盘,支持运行远超物理内存的程序。
- 越界检查精准,安全性高 :
- 先通过段表检查段内偏移量是否超出段长度(避免访问其他段的内存),再通过页表映射物理地址,双重检查确保内存访问安全,防止进程越权访问。
五、记忆法
- 核心定义记忆:"虚拟内存=物理内存+磁盘,逻辑地址映射物理地址,按需加载省内存";
- 三种技术记忆:"分页固定块,分段逻辑段,段页先分段再分页,结合二者优点";
- 核心作用记忆:"扩内存、共资源、隔进程、避碎片";
- 段页式优势记忆:"无外碎、少内碎、合逻辑、易共享、高安全"。
请说明 CPU 内存的寻址能力(提示:CPU 寻址范围为 2 的 N 次方字节,即 2^N (B),N 为地址总线位数)。
一、CPU 寻址能力的核心定义
CPU 的寻址能力(Addressing Capacity)是指CPU 能够直接访问的最大内存空间大小 ,核心取决于 CPU 的"地址总线位数(N)"。地址总线是 CPU 与内存之间传输地址信息的硬件线路,每根地址总线可传输 1 位二进制数(0 或 1),N 位地址总线最多能表示 2^N 个不同的地址,每个地址对应 1 字节(Byte)的内存单元,因此 CPU 的最大寻址范围为 2^N 字节(B)。
核心公式:最大寻址范围 = 2^地址总线位数(B)= 2^(地址总线位数-3)(GB)(注:1GB = 2^30 B,因此 2^N B = 2^(N-30) GB)
二、地址总线位数与寻址范围的对应关系(实例说明)
通过具体案例理解寻址能力的计算,结合不同架构的 CPU 实际情况:
| 地址总线位数(N) | 最大寻址范围(B) | 换算单位(GB) | 典型应用场景 |
|---|---|---|---|
| 16 位 | 2^16 = 65536 B | 0.0625 GB(64KB) | 早期 8086 处理器、单片机 |
| 32 位 | 2^32 = 4294967296 B | 4 GB | 32 位 Windows/Linux、早期智能手机(如 iPhone 3G) |
| 64 位 | 2^64 = 18446744073709551616 B | 16 EB(1EB=1024PB) | 现代 64 位 CPU(如 Intel i7、Apple M 系列芯片)、64 位操作系统(iOS 11+、macOS 10.15+) |
**面试加分点:**64 位 CPU 的实际寻址范围通常小于理论值(2^64 B),原因是:操作系统限制:为简化内存管理,64 位系统通常只使用 48 位或 57 位地址线(如 macOS 支持 48 位虚拟地址,寻址范围 256TB);硬件成本:实现 64 位地址总线的硬件成本高,而实际应用中无需 16EB 的内存,因此厂商会优化地址线位数。
三、寻址能力的核心影响因素
- 地址总线位数(决定性因素):如前所述,地址总线位数直接决定了可表示的地址数量,是寻址能力的核心。例如,32 位地址总线最多只能表示 4GB 地址,即使安装 8GB 物理内存,CPU 也只能访问前 4GB。
- 物理内存大小:CPU 的寻址范围是"最大可访问能力",实际可访问的内存大小还受限于物理内存的安装容量。例如,32 位 CPU 理论寻址 4GB,但如果只安装 2GB 物理内存,实际访问范围就是 2GB。
- 操作系统支持 :
- 32 位操作系统只能使用 32 位地址总线,即使 CPU 是 64 位,也只能寻址 4GB;
- 部分 32 位操作系统支持"物理地址扩展(PAE)"技术,可使用 36 位地址总线,寻址范围扩展到 64GB,但虚拟地址仍为 32 位(进程最多看到 4GB 虚拟内存)。
- 内存控制器限制:内存控制器(集成在 CPU 或主板上)负责管理内存访问,其支持的地址线位数也会限制实际寻址能力。例如,部分老主板的内存控制器仅支持 32 位地址,即使 CPU 是 64 位,也无法访问超过 4GB 的内存。
四、寻址能力与 iOS 开发的关联(面试重点)
- 设备内存限制 :
- 32 位 iOS 设备(如 iPhone 5 及之前)最大支持 2GB 物理内存,APP 最大虚拟内存限制为 1GB;
- 64 位 iOS 设备(iPhone 5s 及之后)支持最大 8GB(iPhone 14 Pro)或 16GB(iPad Pro)物理内存,APP 虚拟内存限制可达 256TB(因 macOS/iOS 采用 48 位虚拟地址)。
- APP 开发注意事项 :
- 64 位 APP 可使用更大的内存空间,支持处理大型数据(如高清视频、3D 模型),但需注意内存泄漏(64 位系统内存占用增长更快);
- 需适配 64 位架构,避免使用 32 位专属 API(如某些老旧的 C 库),确保 APP 能充分利用 64 位 CPU 的寻址能力。
五、常见误区澄清
- 误区 1:CPU 位数 = 地址总线位数错误。CPU 位数(如 32 位、64 位)通常指"数据总线位数"或"通用寄存器位数",与地址总线位数不一定相等。例如,早期部分 32 位 CPU 的地址总线是 36 位(支持 PAE 技术),可寻址 64GB 物理内存。
- 误区 2:安装更大的内存就能提升性能不一定。若 CPU 的寻址范围小于物理内存大小(如 32 位 CPU 安装 8GB 内存),超出部分无法被 CPU 访问,相当于浪费;只有当物理内存大小 ≤ CPU 寻址范围时,增加内存才能提升性能(避免频繁的磁盘交换)。
- 误区 3:64 位系统必须安装 4GB 以上内存错误。64 位系统可安装 2GB 内存,只是无法充分利用 64 位的寻址能力,但 64 位系统的其他优势(如支持更大的单个进程虚拟内存、更高的 CPU 指令集效率)依然存在。
六、记忆法
- 核心公式记忆:"寻址范围=2^N 字节,N 是地址总线位数;换算 GB 减 30(2^(N-30))";
- 典型案例记忆:"32 位寻 4GB,64 位寻 16EB,实际应用看系统和硬件";
- 关联开发记忆:"iOS 64 位设备支持大内存,APP 可处理大数据,但需防泄漏"。
请详细对比进程和线程的核心区别。
一、进程和线程的核心定义
- 进程(Process) :操作系统资源分配的基本单位,是一个"正在运行的程序实例"。每个进程拥有独立的地址空间(代码段、数据段、堆、栈)、文件描述符、进程控制块(PCB)等资源,进程间相互隔离,无法直接访问对方的资源。
- 线程(Thread) :操作系统调度执行的基本单位,是进程的"执行单元"。一个进程可以包含多个线程,所有线程共享该进程的资源(地址空间、文件描述符、全局变量等),线程自身仅拥有少量私有资源(如程序计数器、寄存器、栈空间)。
核心关系:线程是进程的子集,进程是线程的容器,线程不能独立存在,必须依赖进程才能运行。
二、进程和线程的核心区别(表格对比)
| 对比维度 | 进程(Process) | 线程(Thread) |
|---|---|---|
| 资源分配 | 资源分配的基本单位,拥有独立的地址空间、文件描述符、PCB 等,资源占用多 | 资源共享的基本单位,共享所属进程的所有资源,仅拥有少量私有资源(栈、寄存器),资源占用少 |
| 调度执行 | 调度粒度大,切换进程时需保存整个进程的上下文(地址空间、寄存器等),开销高 | 调度粒度小,切换线程时仅需保存线程的私有上下文(栈、程序计数器),开销低 |
| 并发能力 | 进程间并发(通过进程调度),但切换开销大,并发效率低 | 线程间并发(通过线程调度),切换开销小,并发效率高(如多核 CPU 可同时执行多个线程) |
| 通信方式 | 进程间通信(IPC)方式复杂,需借助操作系统提供的机制(如管道、消息队列、共享内存、Socket) | 线程间通信简单,可直接访问共享资源(全局变量、堆内存),或使用线程同步机制(锁、信号量) |
| 独立性 | 独立性强,进程崩溃不会影响其他进程(如一个 APP 崩溃不影响系统) | 独立性弱,线程崩溃会导致整个进程崩溃(如一个线程触发野指针,整个 APP 闪退) |
| 创建与销毁 | 创建和销毁时需分配/释放大量资源(如地址空间、PCB),开销大 | 创建和销毁时仅需分配/释放少量私有资源,开销小(如 iOS 中通过 GCD 创建线程的开销远低于创建进程) |
| 同步与互斥 | 进程间无共享资源,无需同步(除非通过 IPC 共享) | 线程间共享资源,需通过同步机制(锁、信号量、条件变量)避免竞态条件 |
| 适用场景 | 适合需要资源隔离的场景(如多个 APP 同时运行、数据库服务与 Web 服务分离) | 适合需要高并发、低开销的场景(如 APP 中的网络请求、UI 刷新、数据处理) |
三、关键区别的深度解析(面试重点)
-
资源分配与共享:隔离 vs 共享
- 进程的独立性:每个进程的地址空间是完全隔离的,进程 A 无法直接访问进程 B 的内存,必须通过 IPC 机制(如 iOS 中的 XPC 服务),这种隔离确保了进程安全,但通信效率低;
- 线程的共享性:同一进程的所有线程共享代码段、数据段、堆内存、文件描述符等,例如,APP 中的主线程和子线程可同时访问全局变量或堆上的对象,通信高效,但需注意线程安全(如避免同时修改同一变量)。
-
调度开销:重 vs 轻
- 进程切换开销:切换进程时,操作系统需保存当前进程的 PCB(进程状态、地址空间、寄存器值),加载新进程的 PCB,切换地址空间(MMU 重新映射虚拟地址),这个过程涉及内核态和用户态切换,开销较大(通常为毫秒级);
- 线程切换开销:切换线程时,仅需保存线程的私有上下文(栈指针、程序计数器、寄存器值),无需切换地址空间(线程共享进程地址空间),开销较小(通常为微秒级),因此线程切换更频繁,并发效率更高。
-
崩溃影响:局部 vs 全局
- 进程崩溃:进程拥有独立的资源和地址空间,一个进程崩溃后,操作系统会回收其所有资源,不会影响其他进程。例如,iOS 中一个 APP 闪退,其他 APP 仍可正常运行;
- 线程崩溃:线程共享进程的资源,若一个线程触发严重错误(如野指针、栈溢出),会导致整个进程的地址空间被破坏,进而引发进程崩溃。例如,APP 中子线程访问已释放的对象,会导致整个 APP 闪退。
-
通信方式:复杂 vs 简单
- 进程间通信(IPC):常见方式包括管道、消息队列、共享内存、Socket、信号量等,不同方式的效率和适用场景不同:
- 共享内存:效率最高(直接访问内存),但需同步机制;
- Socket:支持跨网络通信(如不同设备上的进程),但开销高;
- iOS 中的 IPC:主要通过 XPC 服务、剪贴板、URL Scheme 等,其中 XPC 服务是推荐方式,支持安全的跨进程通信;
- 线程间通信:常见方式包括共享变量、锁(如 pthread_mutex_t、NSLock)、信号量(semaphore)、条件变量(condition)、消息队列(如 iOS 中的 GCD 队列、NSOperationQueue),例如,子线程处理完数据后,通过 GCD 的
dispatch_async(dispatch_get_main_queue(), ^{})通知主线程刷新 UI。
- 进程间通信(IPC):常见方式包括管道、消息队列、共享内存、Socket、信号量等,不同方式的效率和适用场景不同:
四、iOS 开发中的进程与线程实例
- 进程实例:iOS 系统中,每个 APP 是一个独立进程,系统通过进程调度确保多个 APP 同时运行(如后台音乐 APP 与前台社交 APP),APP 崩溃后仅影响自身,不影响系统;
- 线程实例:iOS APP 启动后默认创建主线程(UI 线程),负责处理 UI 刷新和用户交互,同时可通过 GCD、NSThread、NSOperation 创建子线程,用于处理耗时操作(如网络请求、图片解码、数据解析),子线程与主线程共享 APP 的地址空间,通过 GCD 或通知进行通信。
五、记忆法
- 核心关系记忆:"进程是容器,线程是执行单元;进程分资源,线程共资源";
- 关键区别记忆:"进程隔离开销大,线程共享开销小;进程崩溃不影响,线程崩溃全完蛋;进程通信靠 IPC,线程通信直接享";
- 适用场景记忆:"隔离用进程,高并用线程"。
请说明进程的几种核心状态,以及各状态之间的转换条件。
一、进程的核心状态(五状态模型)
进程在生命周期中会经历多种状态变化,操作系统通过"进程控制块(PCB)"记录进程的当前状态。最经典的是"五状态模型",涵盖进程的所有核心行为,包括:新建态、就绪态、运行态、阻塞态、终止态。
各状态的核心定义:
- 新建态(New):进程刚被创建,操作系统正在为其分配资源(如地址空间、PCB),尚未加入就绪队列;
- 就绪态(Ready):进程已分配完所有必要资源,等待 CPU 调度执行(具备运行条件,但未获得 CPU 时间片);
- 运行态(Running):进程获得 CPU 时间片,正在执行指令(单 CPU 系统中同一时间只有一个进程处于运行态,多 CPU 系统中可多个进程同时运行);
- 阻塞态(Blocked/Waiting):进程因等待某一事件发生(如 I/O 完成、等待锁、等待信号),暂时放弃 CPU,即使有 CPU 时间片也无法运行;
- 终止态(Terminated):进程完成执行(正常退出)或因错误终止(如崩溃),操作系统回收其所有资源(PCB、地址空间等)。
二、进程状态之间的转换条件(深度解析)
进程状态的转换由操作系统的进程调度器和事件触发,以下是各状态之间的转换逻辑和典型场景:
1. 新建态 → 就绪态
- 转换条件:操作系统完成进程的资源分配和 PCB 初始化;
- 典型场景:用户双击打开 APP(如 iOS 中点击微信图标),系统为微信进程分配虚拟地址空间、创建 PCB,初始化代码段和数据段,完成后将进程加入就绪队列,等待 CPU 调度。
2. 就绪态 → 运行态
- 转换条件:进程调度器选中一个就绪态进程,为其分配 CPU 时间片;
- 调度算法 :操作系统通过调度算法选择就绪进程,常见算法包括:
- 先来先服务(FCFS):按就绪顺序分配 CPU;
- 短作业优先(SJF):优先分配给运行时间短的进程;
服务端性能优化的常见思路有哪些?
一、服务端性能优化的核心目标
服务端性能优化的核心是"在有限的硬件资源下,提升系统的并发处理能力、降低响应延迟、提高稳定性",需从"资源瓶颈定位、架构层面优化、代码层面优化、存储层面优化、网络层面优化"五个维度系统性推进,避免单一维度优化导致的"木桶效应"。
二、核心优化思路(从宏观到微观)
1. 架构层面优化(解决系统性瓶颈)
- 集群部署与负载均衡 :单一服务器的并发能力有限,通过集群部署将多个服务器组成节点池,结合负载均衡器(如 Nginx、HAProxy、云厂商 ALB)分发请求,实现负载分担:
- 负载均衡算法:轮询(简单但不均)、加权轮询(按服务器性能分配权重)、IP 哈希(固定用户到固定节点,保持会话)、最小连接数(分配给连接最少的节点);
- 高可用设计:避免单点故障,负载均衡器配置主从备份,服务器节点支持自动扩容/缩容(如 Kubernetes 弹性伸缩)。
- 微服务拆分 :单体应用存在"牵一发而动全身"的问题,拆分为独立的微服务(如用户服务、订单服务、支付服务),每个服务可独立部署、扩容、升级:
- 拆分原则:按业务域拆分,低耦合高内聚,避免服务间过度依赖;
- 通信方式:同步通信(RESTful、gRPC)用于实时请求,异步通信(消息队列)用于非实时场景(如订单创建后发送通知)。
- 引入缓存层(减轻数据库压力) :缓存是提升性能的"利器",将高频访问、变更少的数据缓存到内存中,减少数据库查询:
- 缓存类型:本地缓存(如 Redis 本地实例、Caffeine)、分布式缓存(如 Redis Cluster、Memcached);
- 缓存策略:缓存穿透(布隆过滤器拦截无效 key)、缓存击穿(互斥锁/热点数据永不过期)、缓存雪崩(过期时间加随机值/集群部署);
- 适用场景:用户信息、商品详情、热点数据查询(如秒杀商品库存)。
- 消息队列解耦(削峰填谷) :针对高并发写入场景(如秒杀下单、日志上报),引入消息队列(如 Kafka、RabbitMQ、RocketMQ)异步处理:
- 削峰:将瞬时高峰请求缓冲到队列中,服务器按能力消费,避免数据库被压垮;
- 填谷:低峰期消费队列中的积压请求,充分利用服务器资源;
- 解耦:服务间通过队列通信,无需直接调用,降低耦合度(如订单服务无需直接调用物流服务,只需发送消息)。
2. 存储层面优化(解决数据读写瓶颈)
- 数据库索引优化:与前文 优化逻辑一致,核心是为高频查询创建合适的索引(复合索引、覆盖索引),避免全表扫描;定期优化索引(如重建碎片化索引)、更新统计信息。
- 数据库分库分表 :当单库数据量超过 1000 万、单表数据量超过 500 万时,需进行分库分表,避免单库/单表性能下降:
- 水平分表(按数据行拆分):如订单表按用户 ID 哈希分表、按时间分表(近 3 个月数据存一张表,历史数据存归档表);
- 垂直分表(按数据列拆分):如用户表拆分为用户基本信息表(高频访问)和用户详情表(低频访问);
- 分库:按业务域分库(如用户库、订单库),或按分表规则分库(如用户 ID 哈希后分配到不同库)。
- 读写分离 :数据库主库负责写入(INSERT/UPDATE/DELETE),从库负责读取(SELECT),通过主从复制同步数据,减轻主库压力:
- 复制方式:My 基于二进制日志(binlog)的异步复制、半同步复制;
- 路由策略:应用层通过中间件(如 Sharding-JDBC、MyCat)自动将读请求路由到从库,写请求路由到主库;
- 注意事项:处理主从延迟(如读己写数据需路由到主库)。
- 存储引擎优化:选择合适的存储引擎,如 My 中 InnoDB 适用于事务场景,MyISAM 适用于读多写少场景;针对大文件存储(如图片、视频),使用对象存储(如 S3、OSS)替代数据库 BLOB 字段,数据库仅存储文件 URL。
3. 代码层面优化(解决执行效率瓶颈)
-
优化算法与数据结构:避免低效算法(如 O(n²) 复杂度的嵌套循环),优先使用高效算法(如 O(n log n) 的排序算法);合理选择数据结构(如哈希表用于快速查找,链表用于频繁插入删除)。
-
减少不必要的计算与 IO :
- 缓存重复计算结果(如复杂公式计算结果缓存到本地);
- 批量处理 IO 操作(如批量插入数据
INSERT INTO table VALUES (...), (...), (...),避免循环单条插入;批量读取文件,避免频繁读写); - 关闭无用连接(如数据库连接、HTTP 连接),使用连接池(数据库连接池、Redis 连接池)复用连接,减少连接建立/关闭开销。
-
异步化处理 :将耗时操作(如文件上传、邮件发送、数据同步)改为异步执行,避免阻塞主线程,提升响应速度:
-
示例( 异步线程池):
// 定义异步线程池 @Bean public Executor taskExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(10); executor.setMaxPoolSize(20); executor.setQueueCapacity(100); executor.initialize(); return executor; } // 异步执行耗时操作 @Async public CompletableFuture<Void> sendEmail(String to) { // 发送邮件逻辑 return CompletableFuture.runAsync(() -> emailService.send(to)); }
-
-
避免内存泄漏 :内存泄漏会导致服务器内存持续增长,最终 OOM 崩溃,需注意:
- 关闭未使用的资源(如流、连接);
- 避免静态集合持有大量对象;
- 使用内存分析工具(如 MAT、JProfiler)排查泄漏点。
4. 网络层面优化(解决传输延迟瓶颈)
- CDN 加速静态资源:将静态资源(图片、CSS、JS、视频)部署到 CDN(如 Cloudflare、阿里云 CDN),用户就近访问 CDN 节点,减少跨地域传输延迟;启用资源压缩(Gzip/Brotli)、缓存策略(设置 Cache-Control 头)。
- API 优化 :
- 合并接口:将多个小接口合并为一个(如用户详情页需要用户信息、订单列表,合并为一个接口返回),减少 HTTP 请求次数;
- 压缩响应数据:启用 Gzip/Brotli 压缩 JSON/HTML 响应,减少传输数据量;
- 分页与懒加载:列表接口实现分页(如
limit offset, size),大数据量场景使用游标分页;按需返回字段(如fields=id,name),避免返回无用数据。
- 协议优化:替换 HTTP/1.1 为 HTTP/2 或 HTTP/3,HTTP/2 支持多路复用、头部压缩,减少连接开销;对内部服务通信,使用 gRPC(基于 HTTP/2 + Protobuf),序列化效率更高、传输数据量更小。
5. 监控与调优(持续优化)
- 全链路监控:部署监控工具(如 Prometheus + Grafana、ELK Stack、SkyWalking),监控系统指标(CPU、内存、磁盘 I/O、网络带宽)、应用指标(接口响应时间、QPS、错误率)、数据库指标(连接数、慢查询数、锁等待时间);
- 压力测试:使用工具(如 JMeter、Locust)模拟高并发场景,找到系统瓶颈(如 CPU 满负荷、数据库连接池耗尽、缓存穿透),针对性优化;
- 持续迭代:性能优化不是一次性工作,需结合业务增长持续监控、测试、调优,如业务量翻倍后,需重新评估分库分表策略、缓存容量、服务器配置。
三、面试加分点:核心优化原则
- 先定位瓶颈,再优化:通过监控和压测找到瓶颈(如 CPU 瓶颈、IO 瓶颈、网络瓶颈),避免盲目优化;
- 性价比优先:优先选择低成本高收益的优化方案(如添加缓存、启用压缩),再考虑复杂方案(如微服务拆分、分库分表);
- 兼顾稳定性与性能:优化不能以牺牲稳定性为代价(如缓存雪崩可能导致系统崩溃,需做好降级熔断);
- 考虑业务场景:优化需结合业务特征(如读多写少场景侧重缓存和读写分离,写多场景侧重消息队列和分库分表)。
四、记忆法
- 核心思路记忆:"架构扩并发(集群、微服务、缓存、MQ),存储解瓶颈(索引、分库分表、读写分离),代码提效率(算法、异步、减 IO),网络减延迟(CDN、API 优化、协议升级),监控促迭代";
- 优先级记忆:"先缓存,再索引,后分库分表;先异步,再并发,后架构拆分";
- 避坑记忆:"优化不盲目,瓶颈先找到;稳定第一位,降级熔断要做好"。
用户访问服务器时出现错误,可能的原因有哪些?
一、错误排查的核心思路
用户访问服务器出现错误,需按"从用户端到服务端"的链路分层排查,核心链路为:用户设备 → 网络链路 → CDN/负载均衡 → 应用服务 → 数据库/缓存/第三方服务 → 服务器硬件/系统,每个环节都可能导致错误,需结合错误现象(如无法访问、超时、5xx/4xx 错误)定位根因。
二、各环节可能的错误原因(分层解析)
1. 用户设备层面(客户端原因)
- 网络配置错误:用户设备未连接网络(如 WiFi 断开、移动网络关闭);网络配置异常(如 IP 地址冲突、DNS 配置错误,导致无法解析服务器域名);代理配置错误(如开启无效代理,导致请求无法到达服务器)。
- 浏览器/APP 问题:浏览器缓存过期或损坏(如缓存的 DNS 记录无效);浏览器版本过低,不支持 HTTP/2 等协议;APP 版本过低,与服务器接口不兼容(如接口字段变更,旧版 APP 未适配);APP 本地缓存数据异常(如登录态失效未重新登录)。
- 权限/安全软件限制:用户设备的防火墙、安全软件(如 360 安全卫士)拦截了请求(如误认为服务器地址是恶意 IP);移动设备未授予 APP 网络权限,导致无法发起请求。
2. 网络链路层面(传输层原因)
- 网络中断/不稳定:用户与服务器之间的网络链路中断(如光纤断裂、基站故障);弱网环境(如偏远地区 4G 信号差)导致数据包丢失、延迟过高,请求超时。
- DNS 解析失败:DNS 服务器故障(如本地 DNS 服务器不可用);DNS 劫持(域名被篡改指向恶意 IP);域名未备案或解析记录错误(如 A 记录指向无效 IP);DNS 缓存过期(本地缓存的 IP 地址已变更)。
- 跨地域/跨运营商问题:跨运营商访问(如电信用户访问联通服务器)存在网络互通瓶颈,延迟高;国际访问时,跨境网络链路拥堵(如用户在海外访问国内服务器),导致请求超时。
- 端口/协议限制:服务器使用的端口(如 8080)被用户网络的防火墙拦截;用户网络不支持某些协议(如 HTTP/3、WebSocket),导致协议握手失败。
3. CDN/负载均衡层面(接入层原因)
- CDN 节点故障:用户访问的 CDN 节点宕机,无法返回静态资源;CDN 缓存未命中且回源失败(如源服务器不可用),返回 5xx 错误。
- CDN 配置错误:CDN 加速域名与服务器域名不匹配;缓存策略配置错误(如静态资源设置为"不缓存",导致 CDN 未发挥作用);HTTPS 证书配置错误(如证书过期、域名不匹配),导致 SSL 握手失败。
- 负载均衡器故障:负载均衡器(如 Nginx)宕机,用户请求无法分发到后端服务器;负载均衡器配置错误(如转发规则错误,将请求转发到不存在的服务器节点);负载均衡器连接数耗尽,无法接收新请求。
4. 应用服务层面(业务层原因)
- 服务未启动/宕机:后端应用服务(如 服务、Node.js 服务)未启动,或因内存泄漏、CPU 满负荷、代码 bug 导致宕机,无法处理请求。
- 服务配置错误:应用服务配置文件错误(如数据库连接地址错误、端口被占用);服务依赖的配置中心(如 Nacos、Apollo)不可用,导致服务无法加载配置,启动失败。
- 代码 bug/逻辑错误:代码存在语法错误、空指针异常,导致请求处理时抛出异常,返回 500 错误;业务逻辑错误(如用户输入参数校验不通过,返回 400 错误);接口版本兼容问题(如服务器升级后,旧接口被移除,用户仍调用旧接口)。
- 服务并发/资源限制:服务的线程池、连接池耗尽(如 Tomcat 线程池满),无法处理新请求;服务触发限流策略(如 Redis 限流、网关限流),返回 429 错误(请求过于频繁);服务触发熔断策略(如依赖的第三方服务不可用,熔断后返回 503 错误)。
5. 依赖服务层面(数据层/第三方原因)
- 数据库故障:数据库服务器宕机、数据库实例未启动;数据库连接池耗尽,应用服务无法获取数据库连接;数据库锁等待超时(如长时间未提交的事务占用锁);数据库表结构变更(如字段删除),导致应用查询时返回"字段不存在"错误。
- 缓存服务故障:Redis/Memcached 服务宕机,应用服务查询缓存时失败;缓存穿透(大量无效 key 导致请求直达数据库),数据库压力过大返回错误。
- 第三方服务故障:应用服务依赖的第三方服务(如支付服务、短信服务、地图服务)不可用,导致请求处理失败(如下单时调用支付服务超时);第三方服务 API 变更,应用未适配导致调用失败。
6. 服务器硬件/系统层面(底层原因)
- 服务器硬件故障:服务器 CPU、内存、磁盘、网卡等硬件故障(如磁盘损坏、内存松动),导致服务器无法正常运行。
- 服务器系统故障:操作系统崩溃、蓝屏;系统资源耗尽(如 CPU 100%、内存满、磁盘空间不足),导致应用服务无法运行;系统防火墙配置错误(如未开放 80/443 端口),拦截用户请求。
- 服务器时间同步错误:服务器系统时间与用户设备时间、第三方服务时间不同步,导致签名验证失败(如 JWT 令牌过期时间校验错误)、HTTPS 证书时间校验失败。
三、常见错误码与对应原因(快速定位)
| 错误码/现象 | 核心可能原因 |
|---|---|
| 400 Bad Request | 请求参数错误、格式错误(如 JSON 格式非法)、参数缺失 |
| 401 Unauthorized | 未登录、登录态失效(如 Token 过期)、权限不足 |
| 403 Forbidden | 服务器拒绝访问(如 IP 被拉黑)、HTTPS 证书错误、未授权的接口访问 |
| 404 Not Found | 接口路径错误、资源不存在(如请求的商品 ID 不存在)、CDN 回源失败 |
| 408 Request Timeout | 网络延迟过高、服务器处理耗时过长、服务并发量过大导致排队超时 |
| 429 Too Many Requests | 触发限流策略、短时间内请求次数过多 |
| 500 Internal Server Error | 应用服务代码 bug、数据库查询错误、依赖服务调用失败 |
| 502 Bad Gateway | 负载均衡器无法连接后端服务器、后端服务器宕机、CDN 回源失败 |
| 503 Service Unavailable | 服务未启动、服务熔断/降级、服务器资源耗尽 |
| 504 Gateway Timeout | 后端服务处理超时、数据库查询超时、第三方服务调用超时 |
| 无法访问/无响应 | DNS 解析失败、网络中断、服务器宕机、端口被拦截 |
四、面试加分点:错误排查流程(落地性)
- 初步排查:让用户检查网络连接、重启浏览器/APP、清除缓存,排除客户端问题;
- 链路检测 :使用
ping测试服务器连通性,traceroute排查网络链路瓶颈,nslookup验证 DNS 解析是否正确; - 日志分析:查看应用服务日志(如 Tomcat 日志)、数据库慢查询日志、负载均衡器日志,定位错误发生的环节和具体原因;
- 服务监控:通过监控工具查看服务器资源(CPU、内存)、应用 QPS、错误率,判断是否存在服务过载、依赖服务故障;
- 灰度验证:若仅部分用户报错,检查是否为灰度发布导致的版本兼容问题,回滚灰度版本验证。
五、记忆法
- 排查链路记忆:"客户端 → 网络 → CDN/负载均衡 → 应用服务 → 依赖服务 → 服务器硬件/系统";
- 错误码记忆:"4xx 客户端错(参数、权限、路径),5xx 服务端错(代码、资源、依赖),超时看网络/耗时,无法访问看 DNS/端口";
- 核心原因记忆:"配置错、服务挂、网络断、代码 bug、资源满、权限缺"。
请逐个介绍你的项目经历,包括核心功能、技术难点及解决方案。
一、项目一:电商 APP(iOS 原生开发,用户量 100 万+)
核心功能
该项目是一款综合电商 APP,支持商品浏览、搜索、下单、支付、物流跟踪、售后维权等完整电商流程,核心模块包括:
- 首页模块:个性化推荐(基于用户行为标签)、轮播图、分类入口、限时秒杀;
- 商品模块:商品详情(图文、视频、规格选择)、商品评价、相关推荐;
- 交易模块:购物车、地址管理、多支付方式(微信/支付宝/银联)、订单管理;
- 个人中心:用户信息、订单查询、优惠券、收藏夹、售后申请。
技术难点与解决方案
- 难点一:商品详情页加载速度慢(图文+视频+规格数据量大)
- 问题背景:商品详情页包含多张高清图片、1-2 个视频、多组规格数据(如颜色、尺寸),首次加载耗时超过 3 秒,用户流失率高;
- 解决方案:
- 图片优化:使用 WebP 格式(比 JPG 小 30%),实现懒加载(仅加载可视区域图片),根据设备分辨率加载不同尺寸图片(如 iPhone SE 加载 720P 图片,iPhone 15 Pro Max 加载 1080P 图片);
- 数据预加载与缓存:启动 APP 时预加载首页推荐商品的基础数据(如 ID、标题、缩略图),详情页数据通过分页加载(先加载基础信息,再加载评价、相关推荐);使用 Realm 数据库缓存商品详情数据,30 分钟内重复访问直接读取缓存;
- 视频优化:视频采用 HLS 协议分片加载,支持边下边播;首屏显示视频封面图,用户点击后再加载视频流;
- 优化效果:详情页首次加载时间从 3.2 秒降至 1.1 秒,页面留存率提升 25%。
- 难点二:高并发场景下的订单创建与库存扣减(秒杀活动)
- 问题背景:秒杀活动时,每秒并发请求达 500+,出现库存超卖、订单创建失败、支付状态同步延迟等问题;
- 解决方案:
- 前端限流:秒杀按钮添加倒计时,防止用户重复点击;请求前校验用户是否已参与秒杀(避免重复下单),使用 Redis 实现分布式限流(每个用户限 1 单);
- 后端协同:采用"预扣库存+异步下单"方案,前端发起秒杀请求后,后端先通过 Redis 预扣库存(避免超卖),再将下单请求放入 Kafka 消息队列,异步创建订单;
- 支付状态同步:使用 APNs 推送+定时轮询结合的方式,实时同步支付状态;订单创建后 15 分钟未支付,自动释放库存;
- 优化效果:秒杀活动库存超卖率降至 0,订单创建成功率从 85% 提升至 99.2%,系统无宕机。
从普通使用者角度,你认为 iOS 系统有哪些有意思的系统特性和功能?
一、核心体验类:兼顾便捷与人性化
- 专注模式(Focus):这是 iOS 15 推出的核心功能,能根据场景(工作、睡眠、驾驶、个人)自定义通知权限,屏蔽无关干扰。比如工作模式下仅接收同事、工作软件的通知,睡眠模式自动静音并隐藏锁屏内容,驾驶模式自动开启勿扰且回复短信 "正在开车,稍后回复"。更贴心的是,系统会自动向常用联系人同步你的专注状态,避免对方误解 "已读不回",相比单纯的勿扰模式更智能、更具场景化。
- 实况文本(Live Text):iOS 15 及以上版本支持直接识别图片、截图、相机实时画面中的文字,无需手动输入。比如拍摄纸质文档后,长按文字即可复制、搜索、翻译,甚至直接拨打文字中的电话号码、打开网址、添加日历事件。对于需要提取快递单号、名片信息、菜谱步骤的用户来说,完全替代了传统的 OCR 工具,操作零门槛,识别准确率极高,是 "懒癌患者" 的福音。
- 隔空投送(AirDrop):iOS 生态的标志性功能,支持 iPhone、iPad、Mac 之间快速传输照片、视频、文件、联系人等。无需网络,只需靠近设备并开启功能,即可在几秒内传输几百兆的视频,且传输过程中自动压缩优化,兼顾速度与质量。更有意思的是 "隔空投送联系人"------ 两人靠近后,一方在联系人页面点击 "共享联系人",另一方即可通过 AirDrop 一键保存,比扫码、报号码高效得多;iOS 17 还新增了 "隔空投送照片后自动分享相册" 功能,适合聚会后批量分享照片。
二、交互设计类:细节处提升效率
- 辅助触控(小白点):看似简单的功能,却能极大提升操作便捷性。用户可自定义小白点的功能,比如设置为 "单击返回、双击截屏、长按调出控制中心",避免反复按压物理按键(尤其适合全面屏手机用户)。对于手部有轻微不便的用户,还能设置 "连续点击三次放大屏幕""滑动小白点模拟手势",兼顾实用性与包容性,体现 iOS 对不同用户的关怀。
- 下拉搜索(Spotlight):在主屏幕下拉即可调出搜索框,不仅能搜索手机内的 App、联系人、照片、备忘录,还能直接搜索网页内容、换算单位、查询天气、计算数学公式、翻译文字。比如输入 "100 美元等于多少人民币",无需打开计算器或浏览器,直接显示结果;输入英文单词,自动给出翻译和发音,相当于内置了一个轻量型工具集,减少了 App 切换的麻烦。
- 手势操作逻辑:全面屏 iPhone 的手势设计连贯且统一,比如从屏幕底部上滑返回主屏幕、上滑并停顿调出多任务、从屏幕左侧边缘右滑返回上一级、双指捏合缩小桌面切换 App 资源库。这些手势无需学习成本,肌肉记忆形成后操作极快,相比安卓阵营杂乱的手势逻辑,iOS 的一致性让用户上手即熟练,且误触率极低。
三、生态联动类:多设备协同无缝衔接
- 接力(Handoff):实现 iPhone、iPad、Mac 之间的任务无缝切换。比如在 iPhone 上浏览网页,打开 Mac 后即可在 Safari 中继续查看同一页面;在 iPad 上编辑备忘录,iPhone 上会同步显示 "继续编辑" 的提示;甚至在 iPhone 上接听电话时,可直接切换到 Mac 上通话,无需拿起手机。这种 "跨设备无缝流转" 的体验,让多设备用户的工作效率大幅提升,真正体现了 "生态闭环" 的价值。
- 通用剪贴板(Universal Clipboard):在一个设备上复制文字、图片、文件,在另一个设备上直接粘贴,无需通过微信、QQ 传输。比如在 Mac 上复制文档中的文字,打开 iPhone 的微信即可直接粘贴发送;在 iPhone 上截图后,复制到 iPad 上的笔记 App 中,整个过程零延迟、零操作成本,对于经常跨设备办公的用户来说,是 "刚需级" 功能。
- 隔空播放(AirPlay):支持将 iPhone 的屏幕、音频、视频投射到 Apple TV、AirPods、HomePod 等设备上。比如在家中用 iPhone 看电影时,通过 AirPlay 投射到 Apple TV,享受大屏体验;播放音乐时,自动连接附近的 AirPods,且切换设备时音频无缝衔接(比如从 iPhone 切换到 Mac,音乐不会中断)。更有意思的是 "隔空播放到 Mac",可将 iPhone 屏幕实时投射到 Mac 上,适合演示 App 功能、录制屏幕视频。
四、隐私安全类:把控制权交给用户
- App 追踪透明度(ATT):iOS 14.5 及以上版本要求所有 App 必须获得用户授权后,才能追踪用户的行为数据(比如跨 App 追踪、广告追踪)。用户在首次打开 App 时,会看到 "是否允许该 App 追踪你在其他公司的 App 和网站上的活动" 的提示,可自由选择 "允许" 或 "不允许"。这一功能从根源上保护了用户隐私,避免个人数据被滥用,体现了 iOS 对隐私的重视 ------"用户说了算"。
- 隐藏我的电子邮件(Hide My Email):苹果账号订阅服务时,可生成一个随机的虚拟邮箱地址,代替真实邮箱接收邮件,避免真实邮箱被垃圾邮件骚扰。用户可随时关闭虚拟邮箱,或为不同服务生成不同的虚拟邮箱,方便管理和注销,既保护了隐私,又不影响正常使用。
- 照片权限精细化控制:iOS 14 及以上版本将照片权限分为 "所有照片""所选照片""无" 三种,用户可选择仅向 App 开放部分照片,而非全部。比如向微信开放 "所选照片" 后,每次发送照片时需手动选择,避免 App 偷偷访问相册中的敏感照片(如身份证照片、私人照片),隐私保护更细致。
五、面试加分点:体现对 iOS 生态的深度理解
普通使用者视角的核心是 "体验感",但面试中可结合 "用户需求" 进一步延伸:iOS 的这些功能看似独立,实则围绕 "便捷、隐私、生态联动" 三大核心,比如实况文本解决了 "信息提取繁琐" 的用户痛点,接力解决了 "多设备协同低效" 的痛点,ATT 解决了 "隐私泄露" 的痛点。这些功能的设计逻辑,体现了苹果 "以用户为中心" 的产品理念,也是 iOS 生态的核心竞争力。
六、记忆法
- 分类记忆:"核心体验(专注、实况文本)、交互设计(小白点、手势)、生态联动(接力、通用剪贴板)、隐私安全(ATT、照片权限)",四类覆盖主要功能;
- 场景记忆:"工作用接力 + 通用剪贴板,生活用实况文本 + AirDrop,隐私用 ATT + 隐藏邮箱",结合使用场景快速回忆。
iOS14 相比 iOS13 新增了哪些核心功能?
一、桌面交互革新:打破传统布局,提升个性化
- 主屏幕小组件(Widgets):iOS14 最重磅的功能之一,打破了 iOS 多年来固定的 App 图标布局。用户可将小组件直接添加到主屏幕,与 App 图标混合排列,支持不同尺寸(小、中、大),比如添加 "日历" 小组件快速查看日程、"天气" 小组件显示实时天气、"电池" 小组件查看多设备电量。更灵活的是 "智能叠放" 功能,多个小组件可叠放在一起,向上滑动切换,节省主屏幕空间。相比 iOS13 只能在 "今日视图" 中查看小组件,iOS14 的小组件让信息展示更直观,个性化程度大幅提升。
- App 资源库(App Library):主屏幕最右侧的统一资源库,自动将所有 App 按类别分组(如社交、生产力、娱乐、游戏),支持按字母顺序排列,还能智能识别 "最近添加""常用" App,方便快速查找。对于 App 数量多的用户,无需手动整理文件夹,直接在资源库中搜索或浏览即可找到 App,解决了 "主屏幕图标泛滥" 的问题。
- 画中画(Picture in Picture):支持视频通话或观看视频时,将窗口缩小为悬浮窗,悬浮窗可拖动位置、调整大小,同时不影响使用其他 App。比如用 FaceTime 通话时,缩小窗口后可浏览网页、回复微信;观看视频时,缩小窗口后可处理工作邮件,多任务处理更高效。iOS13 仅支持 iPad 画中画,iOS14 扩展到 iPhone,填补了 iPhone 多任务视频体验的空白。
二、隐私安全强化:用户掌控力提升
- App 追踪透明度(ATT):如前文所述,iOS14.5 及以上版本(属于 iOS14 大版本)新增的核心隐私功能,要求 App 必须获得用户授权才能跨 App 追踪数据。这一功能从根本上改变了广告追踪的规则,让用户拥有了数据控制权,是 iOS 隐私保护的重要里程碑,也对 App 生态产生了深远影响。
- 照片权限精细化控制:iOS13 中 App 只能获取 "所有照片" 或 "无" 权限,iOS14 新增 "所选照片" 权限,用户可手动选择向 App 开放的照片,避免 App 访问全部相册。比如向购物 App 仅开放商品照片,向社交 App 仅开放生活照片,隐私保护更细致。
- 麦克风 / 相机使用提示:当 App 正在使用麦克风或相机时,屏幕右上角会显示橙色(麦克风)或绿色(相机)指示灯,同时控制中心会显示 "正在使用麦克风 / 相机" 的提示,让用户实时知晓 App 是否在窃取隐私,避免 "后台偷偷录音 / 拍照" 的情况。
- 本地网络权限:App 访问本地网络(如连接智能家居设备、局域网共享文件)时,需获得用户授权,防止 App 通过本地网络收集设备信息,进一步加固隐私防线。
三、核心功能优化:提升使用效率
- 翻译 App 原生集成:iOS14 内置翻译 App,支持 11 种语言实时翻译,包括语音翻译、文本翻译、离线翻译。语音翻译支持自动检测语言,对话模式下双方可直接用不同语言交流,翻译实时显示;离线翻译无需网络,适合出国旅行时使用。相比 iOS13 需依赖第三方翻译 App,原生翻译 App 更便捷、集成度更高,且支持系统级调用(如 Safari 网页翻译)。
- Safari 浏览器升级 :
- 隐私报告:显示 Safari 阻止的跨站追踪器数量,让用户了解隐私保护状态;
- 标签页分组:可创建标签页组(如工作、购物、旅行),支持跨设备同步,方便分类管理多个标签页;
- 翻译功能:内置网页翻译,支持将外文网页一键翻译成中文,无需复制到其他 App。
- 短信与联系人优化 :
- 短信固定:可将常用联系人的短信对话固定在顶部,快速查找;
- 群聊管理:支持给群聊命名、添加群图标、设置群聊照片,还能移除群成员、限制群成员发言,群聊功能更完善;
- 联系人分组:支持创建自定义联系人分组(如家人、同事、朋友),分组内可批量发送短信、邮件,管理更高效。
四、其他实用功能:细节体验提升
- 背部轻触(Back Tap):在 "设置 - 辅助功能 - 触控" 中开启,可自定义双击或三击手机背部的功能,比如双击背部截屏、三击背部调出控制中心、双击背部返回上一级、三击背部打开健康 App。这一功能为操作提供了更多可能性,尤其适合全面屏手机用户,无需依赖手势或物理按键。
- 地图 App 优化:新增骑行路线规划,支持显示自行车道、坡度、交通状况;新增公交实时信息,显示公交到站时间、拥挤程度;支持自定义地图视图(如卫星图、标准图、浅色图),导航体验更丰富。
- 家庭 App 升级:支持更多智能家居设备,新增 "家庭中枢" 功能,可通过 Apple TV 或 iPad 远程控制智能家居;支持场景自动化(如 "回家模式" 自动开灯、开空调),智能家居管理更便捷。
五、面试加分点:理解功能背后的产品逻辑
iOS14 的核心变化围绕 "个性化、隐私、效率" 三大方向:小组件和 App 资源库解决了 "桌面布局僵化、App 查找困难" 的痛点;ATT、照片权限等功能强化了隐私保护,顺应了用户对隐私的需求;画中画、翻译 App 等提升了多任务和日常使用效率。这些变化也体现了苹果对用户反馈的重视 ------ 比如小组件功能是用户多年呼吁的,ATT 则回应了对广告追踪的担忧,面试中若能结合 "用户需求" 分析功能价值,会更出彩。
六、记忆法
- 核心分类记忆:"桌面革新(小组件、资源库、画中画)、隐私强化(ATT、照片权限、使用提示)、效率优化(翻译 App、Safari 升级、背部轻触)";
- 关键词记忆:"小组件(主屏幕)、资源库(App 分类)、ATT(隐私追踪)、画中画(多任务)、背部轻触(便捷操作)",每个核心功能对应一个关键词,快速联想。
你最近在阅读哪些技术书籍,主要学习哪些内容?
一、核心技术书籍:夯实 iOS 底层与进阶能力
- 《iOS 高级编程:Swift 版》(第 5 版) :这本书是 iOS 开发的 "进阶圣经",相比基础教程,更侧重底层原理和工程实践。最近重点学习的章节包括:
- 内存管理深度解析:ARC 的底层实现机制(引用计数的增减逻辑、弱引用与无主引用的区别、循环引用的检测与解决),结合 Swift 5 的新特性(如 Weak.self、Unowned.self 的使用场景),解决实际开发中 "隐式循环引用"(如闭包捕获、代理模式)的问题;
- 多线程编程:GCD 的底层原理(队列、任务、调度组、信号量)、OperationQueue 的高级用法(依赖管理、优先级调整、取消任务),以及多线程安全(锁机制、原子属性、线程局部存储),针对 "高并发场景下的数据竞争"(如秒杀下单、批量数据处理)提供解决方案;
- 网络编程优化:URLSession 的高级用法(后台下载、断点续传、请求缓存)、HTTP/2 协议特性、HTTPS 加密原理(TLS 握手过程、证书验证),以及网络请求的错误处理(超时重试、弱网适配、数据解析容错),提升 App 网络稳定性。
- 《Swift 编程思想:函数式编程与响应式编程》 :Swift 语言天生支持函数式编程,这本书帮助跳出 "命令式编程" 的思维定式,重点学习:
- 函数式编程核心概念:纯函数、不可变数据、高阶函数(map、filter、reduce、flatMap)的灵活运用,减少代码冗余,提升可读性;
- 响应式编程(FRP):结合 Combine 框架,学习如何用 "数据流" 的方式处理异步事件(如网络请求、UI 交互、数据更新),解决 "回调地狱" 问题。比如用 Combine 实现 "用户输入验证→网络请求→数据更新→UI 刷新" 的全链路响应式流程,代码更简洁、可维护性更强;
- 函数式设计模式:单例模式、工厂模式、策略模式的函数式实现,避免 OOP 模式中的冗余代码,适配 Swift 的语言特性。
二、架构设计与工程化书籍:提升系统设计能力
- 《Clean Architecture:整洁架构》(罗伯特・C・马丁) :这本书的核心是 "分层架构" 思想,最近重点学习如何将其应用到 iOS 开发中:
- 架构分层原则:将 App 分为实体层(Entity,核心业务逻辑)、用例层(UseCase,业务场景)、接口适配层(Interface Adapter,如网络、数据库适配)、框架层(Framework,如 UIKit、CoreData),层与层之间通过接口依赖,降低耦合;
- iOS 实践:结合 MVVM+Clean Architecture 架构,设计可测试、可扩展的 App 结构。比如将网络请求、数据库操作封装在适配层,业务逻辑放在用例层,UI 逻辑放在 ViewModel 层,确保每层职责单一,便于单元测试和迭代;
- 依赖注入:学习如何通过依赖注入(DI)解耦组件,比如用 Swinject 框架管理对象依赖,避免硬编码依赖导致的测试困难。
- 《iOS 工程化:架构设计与自动化》 :针对团队协作和工程效率,重点学习:
- 组件化方案:如何将大型 App 拆分为独立组件(如用户组件、订单组件、支付组件),通过路由(URL Scheme、CTMediator)实现组件间通信,解决 "代码耦合、编译慢" 的问题;
- 自动化构建:使用 Fastlane 实现打包、测试、上传 App Store 的自动化流程,减少手动操作;结合 Jenkins 搭建持续集成(CI)/ 持续部署(CD) pipeline,实现 "提交代码→自动测试→自动打包→自动分发测试";
- 代码质量管控:集成 SwiftLint 进行代码规范检查,使用 SonarQube 进行代码质量分析,结合单元测试(XCTest)、UI 测试(XCUITest)提升代码覆盖率,减少线上 Bug。
三、拓展知识书籍:补充生态与底层认知
- 《HTTP 权威指南》 :iOS 开发离不开网络请求,这本书系统讲解 HTTP 协议的核心原理:
- HTTP 方法(GET/POST/PUT/DELETE)的使用场景与区别、状态码含义、请求头 / 响应头字段(如 Cache-Control、Range、ETag);
- HTTP 缓存机制(强缓存、协商缓存)、Cookie 与 Session、HTTPS 加密原理(对称加密、非对称加密、CA 证书);
- 实际应用:如何通过设置缓存策略减少网络请求,如何利用 Range 头实现断点续传,如何处理 HTTPS 证书校验(如自签名证书、证书钉扎)。
- 《深入理解计算机系统》(CSAPP) :虽然是计算机基础书籍,但对理解 iOS 底层原理至关重要,最近重点学习:
- 内存管理:虚拟内存、分页、分段机制,理解 iOS 中 App 的内存布局(代码段、数据段、堆、栈),以及内存泄漏、野指针的底层原因;
- 进程与线程:CPU 调度、进程通信(IPC)、线程同步机制,理解 iOS 中 App 的进程生命周期、线程调度(GCD 底层依赖的线程池);
- 系统调用:用户态与内核态的切换,理解 iOS 中诸如文件 I/O、网络请求等操作的底层流程。
四、面试加分点:体现学习逻辑与落地能力
面试中介绍读书时,避免只罗列书名,要突出 "学习目标→核心内容→实际应用" 的逻辑:比如阅读《Clean Architecture》是为了解决 "大型 App 维护困难" 的问题,核心学习分层架构思想,实际项目中已落地 MVVM+Clean Architecture 架构,拆分了 5 个独立组件,提升了迭代效率;阅读《Swift 编程思想》是为了优化异步代码,已用 Combine 重构了网络请求模块,减少了 30% 的回调代码。这种 "理论结合实践" 的表述,能体现学习能力和落地能力。
五、记忆法
- 分类记忆:"核心技术(iOS 高级编程、Swift 编程思想)、架构工程(Clean Architecture、iOS 工程化)、拓展知识(HTTP 权威指南、CSAPP)",三类覆盖 "技术深度 + 架构广度 + 底层认知";
- 目标记忆:"夯实底层(内存、多线程)、提升架构(分层、组件化)、优化工程(自动化、代码质量)、补充基础(HTTP、计算机系统)",每个类别对应明确的学习目标。
请谈谈你在 iOS 方向的短期和长期学习规划。
一、短期学习规划(1-2 年):夯实技术深度,提升工程能力
短期目标是 "成为技术扎实、能独立解决复杂问题的中级 iOS 开发工程师",核心围绕 "底层原理、架构优化、工程化实践" 展开:
- 底层原理深耕 :
- 深入学习 Swift 语言底层:Swift 编译流程(AST、SIL、LLVM)、内存布局(结构体、类、枚举的内存占用)、泛型实现、协议扩展,解决 "Swift 高级特性使用不熟练" 的问题;
- 精通 iOS 核心框架底层:UIKit 渲染原理(UI 刷新机制、RunLoop 与视图渲染的关系)、Core Animation 动画原理(图层树、渲染树、动画提交流程)、AutoLayout 约束计算原理,能解决复杂的 UI 卡顿、动画掉帧问题;
- 网络与存储底层:深入理解 URLSession 底层实现(请求队列、缓存机制、代理回调流程)、Core Data 持久化原理(ite 底层映射、上下文管理)、Realm 数据库优化(索引设计、查询性能),提升 App 数据存储与网络交互的稳定性。
- 架构与设计模式落地 :
- 熟练掌握主流架构:深入理解 MVVM、Clean Architecture、Coordinator 架构的设计思想,能根据项目场景选择合适的架构,避免 "架构过度设计" 或 "架构混乱";
- 组件化与模块化实践:独立负责一个中型 App 的组件化拆分,设计组件间通信方案(路由、协议)、组件依赖管理(CocoaPods、Swift Package Manager)、组件测试方案,解决 "大型 App 编译慢、耦合高" 的问题;
- 设计模式灵活运用:除了常用的单例、代理、工厂模式,重点学习观察者模式、策略模式、命令模式在 iOS 中的应用,比如用观察者模式实现数据订阅、用策略模式优化支付方式选择逻辑。
- 工程化与自动化能力提升 :
- 自动化工具掌握:熟练使用 Fastlane 编写自动化脚本(打包、测试、上传、更新 CHANGELOG),搭建 Jenkins CI/CD 流水线,实现 "代码提交→自动测试→自动打包→测试分发" 的全流程自动化;
- 代码质量管控:建立团队代码规范(结合 SwiftLint),设计单元测试(XCTest)、UI 测试(XCUITest)方案,目标代码覆盖率提升至 70% 以上;使用 Instruments 工具(Time Profiler、Allocations、Leaks)排查性能问题、内存泄漏,提升 App 流畅度;
- 跨平台技术了解:学习 Flutter 基础语法与混合开发方案(Flutter 与原生交互),能独立开发简单的 Flutter 模块,为后续跨平台项目做准备。
- 业务深度结合 :
- 深入理解所负责业务的核心逻辑,比如电商 App 的交易流程、支付链路、物流跟踪,能从技术角度提出优化方案(如秒杀场景的性能优化、订单流程的稳定性提升);
- 积累行业解决方案,比如埋点统计方案(自定义埋点、无埋点)、崩溃监控方案(PLCrashReporter、Bugly 集成)、弱网适配方案(请求重试、数据缓存、离线操作),形成可复用的技术组件。
二、长期学习规划(3-5 年):拓展技术广度,向架构师 / 技术专家迈进
长期目标是 "成为 iOS 领域的技术专家或架构师",核心围绕 "技术广度、架构设计、团队领导力" 展开:
- 技术广度拓展 :
- 跨平台技术深耕:精通 Flutter 或 React Native 跨平台开发,能主导大型跨平台项目的架构设计、性能优化、原生交互方案,解决跨平台与原生的兼容性问题;
- 后端与云服务知识:学习 Node.js 或 语言基础,能独立开发简单的后端接口;了解云服务(AWS、阿里云、苹果 CloudKit)的使用,比如用 CloudKit 实现用户数据同步、用云函数处理后台任务;
- 人工智能与机器学习:学习 Core ML 框架,能将训练好的机器学习模型(如图片识别、自然语言处理)集成到 iOS App 中,开发智能功能(如智能搜索、图像识别分类);
- 音视频与直播技术:学习 iOS 音视频开发(AVFoundation 框架),了解音视频编码(H.264、H.265)、解码、推流、拉流原理,能独立开发简单的直播或短视频模块。
- 架构设计与技术选型能力 :
- 大型 App 架构设计:能主导千万级用户量 App 的架构设计,包括技术栈选型、模块拆分、性能优化、容灾方案,考虑高并发、高可用、可扩展性;
- 技术选型决策:能根据项目需求(如用户量、开发周期、团队规模)选择合适的技术栈,比如原生开发 vs 跨平台开发、ite vs Realm vs Core Data、自建后端 vs 云服务,权衡技术成本与业务价值;
- 技术预研与创新:关注 iOS 生态的新技术(如 SwiftUI 进阶、Vision 框架、App Clips),提前预研并落地到项目中,提升产品竞争力;跟踪行业技术趋势(如元宇宙、AR/VR 在 iOS 中的应用),探索技术创新点。
- 团队领导力与技术影响力 :
- 技术团队管理:带领 iOS 团队完成项目开发,负责需求拆解、任务分配、进度把控、风险管控;建立团队技术培训体系,指导初级 / 中级开发工程师成长;
- 技术沉淀与分享:总结项目中的技术难点与解决方案,形成技术文档或博客;参与行业技术分享(如技术沙龙、开源项目),提升个人技术影响力;
- 开源贡献:参与 iOS 开源项目(如 Alamofire、Kingfisher、CombineCocoa),提交 PR 或 Issue,为开源社区贡献力量;或独立开发开源组件(如通用路由框架、埋点工具),提升技术认可度。
- 业务与产品思维提升 :
- 从技术视角转向产品视角,理解产品需求背后的用户痛点,能结合技术提出产品优化建议(如通过技术优化提升用户体验、降低运营成本);
- 了解行业业务逻辑与商业模式,比如电商、社交、金融等领域的核心业务流程,能设计更贴合业务的技术架构;
- 跨团队协作能力:与产品、设计、后端、测试团队高效协作,推动项目落地;参与跨部门技术方案评审,协调资源解决跨团队技术问题。
三、面试加分点:规划的可行性与成长性
面试中介绍学习规划时,要体现 "脚踏实地、循序渐进" 的逻辑,避免空泛:比如短期规划中 "1 年内掌握组件化拆分",明确了时间节点和具体目标;长期规划中 "3 年内主导大型跨平台项目",结合了行业趋势和个人成长路径。同时,要强调 "学习与实践结合",比如短期规划中 "用 Instruments 排查性能问题",可以举例说明在现有项目中已开始实践,长期规划中 "参与开源项目",可以说明已关注的开源项目和贡献方向。这种 "有目标、有路径、有实践" 的规划,能让面试官看到你的成长性和执行力。
四、记忆法
- 短期规划记忆:"底层深耕(Swift、UIKit、网络存储)、架构落地(MVVM、组件化)、工程自动化(Fastlane、CI/CD)、业务结合(行业方案、组件复用)";
- 长期规划记忆:"技术广度(跨平台、后端、AI、音视频)、架构设计(大型 App、技术选型)、团队领导(管理、分享、开源)、业务思维(产品视角、跨团队协作)";
- 核心逻辑记忆:"短期夯深度,长期拓广度;技术为核心,业务为导向;实践出真知,成长有路径"。