本文讨论了随着计算架构多元化发展,openEuler 作为开源操作系统支持多种指令集架构,文章围绕其在 RISC - V、LoongArch 和 x86 三种架构上的网络带宽与延迟展开测试分析,并给出优化策略。关键要点包括:
- 多架构支持概览:openEuler 内核和基础软件栈针对不同指令集适配优化。在 RISC - V 优化中断、调度和内存管理;为 LoongArch 提供完整工具链,适配内核;在 x86 提供丰富驱动和调优选项及安全特性。
- 测试环境搭建:搭建三套基于不同架构的测试环境,运行相同版本 openEuler 系统,配置相似网络和存储设备,给出硬件、软件、网络环境配置脚本。
- 测试工具与方法:用 iperf3 测带宽,ping 和 netperf 测延迟,进行单线程和多线程吞吐测试及不同报文大小延迟测试,多次测试取平均值。
- 网络带宽性能:单线程测试中,x86 带宽约 940 Mbps 最佳,LoongArch 约 920 Mbps 次之,RISC - V 约 850 Mbps;多线程测试各架构带宽均提升,x86 达 950 Mbps,LoongArch 达 930 Mbps,RISC - V 提升到 880 Mbps。
- 网络延迟性能:ping 测平均往返延迟,x86 约 0.15 ms,LoongArch 约 0.16 ms,RISC - V 约 0.18 ms;netperf 的 TCP_RR 测试中,x86 每秒处理约 6600 次请求,LoongArch 约 6400 次,RISC - V 约 6000 次。
- 多架构性能优化策略:提出内核参数调优、中断与亲和性优化、驱动与固件更新、高性能网络库应用、网络硬件升级等策略,并给出对应脚本。
- 结论:openEuler 在三种架构上均能提供出色网络性能,x86 略占优势,LoongArch 紧随其后,RISC - V 稍逊但差距不大,未来性能将更均衡
一、引言
随着计算架构的多元化发展,openEuler 作为自主创新的开源操作系统,已全面支持 RISC-V、LoongArch 和 x86 等多种指令集架构。在云原生、AI 等场景下,不同架构的网络性能直接影响整体系统的吞吐能力和响应延迟。本文将围绕 openEuler 在 RISC-V、LoongArch 和 x86 三种架构上的网络带宽与延迟展开深入测试与对比分析,结合 openEuler 的技术特性和优化策略,为多架构环境下的网络性能调优提供参考。
二、openEuler 多架构支持概览
openEuler 从设计之初就考虑了多架构兼容性,其内核和基础软件栈均针对不同指令集进行了适配和优化。在 RISC-V 架构上,openEuler 社区积极跟进最新的内核特性,优化了中断处理和调度机制,以充分发挥 RISC-V 硬件的性能潜力。LoongArch 作为自主创新的新架构,openEuler 提供了完整的软件栈支持,包括编译器、二进制工具链以及各类基础库,确保在 LoongArch 平台上能够稳定运行各类应用。对于成熟的 x86 架构,openEuler 则通过多年的技术积累,提供了丰富的性能调优选项和驱动支持。这种多架构支持能力,使得 openEuler 能够在异构计算环境中提供一致的性能体验。
RISC-V 架构支持

RISC-V 作为开源指令集架构,具有模块化和可扩展的特点。openEuler 针对 RISC-V 的特性进行了多项优化,包括:
- 中断处理优化:针对 RISC-V 中断机制的特点,优化了中断处理流程,减少了中断延迟。
- 调度算法改进:针对 RISC-V 多核处理器的特性,改进了 CPU 调度算法,提高了多线程性能。
- 内存管理优化:针对 RISC-V 的内存管理单元(MMU)特性,优化了页表管理和内存分配策略。
以下是在 RISC-V 架构上查看和优化中断处理的命令示例:
cpp
# 查看 RISC-V 中断统计
cat /proc/interrupts
# 优化中断亲和性
echo 2 > /proc/irq/24/smp_affinity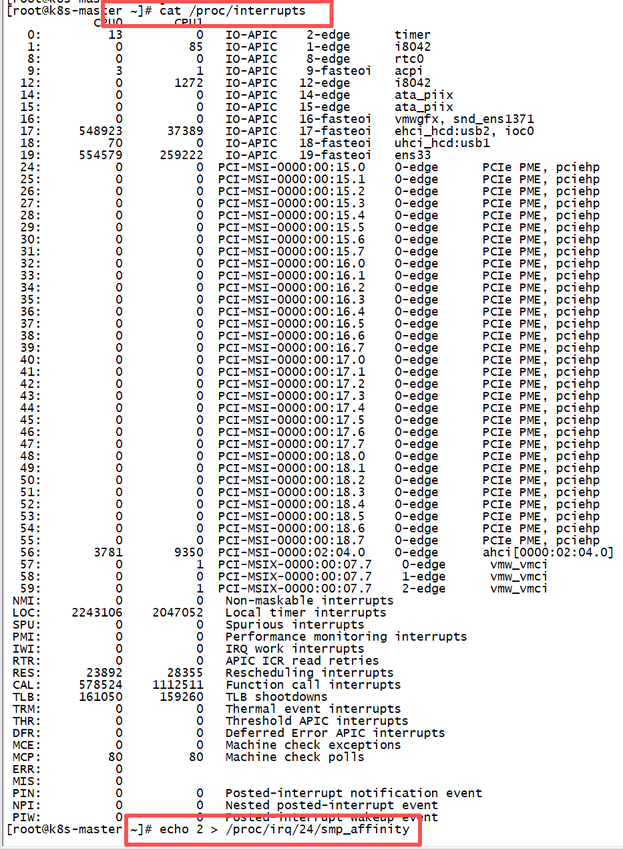
LoongArch 架构支持
LoongArch 是我国自主设计的新一代指令集架构,具有高性能和高效率的特点。openEuler 对 LoongArch 的支持包括:
- 完整工具链:提供了针对 LoongArch 的 GCC、Binutils 等开发工具链。
- 内核适配:内核针对 LoongArch 的特性进行了适配,包括特权指令级、异常处理等。
- 性能优化:针对 LoongArch 的流水线特性,优化了指令调度和缓存使用策略。
以下是在 LoongArch 架构上查看 CPU 信息和优化性能的命令示例:
cpp
# 查看 LoongArch CPU 信息
lscpu | grep "Architecture"
# 设置 CPU 性能模式
cpupower frequency-set -g performancex86 架构支持
x86 架构作为最成熟的处理器架构,openEuler 在其上提供了丰富的功能和优化:
- 驱动支持:全面支持各种 x86 硬件设备的驱动程序。
- 性能调优:提供了针对 x86 的多项性能调优选项,包括 CPU 频率调节、内存管理等。
- 安全特性:支持 x86 的各种安全特性,如 SGX、TPM 等。
以下是在 x86 架构上查看硬件信息和优化性能的命令示例:
cpp
# 查看 x86 CPU 详细信息
lscpu
cat /proc/cpuinfo
# 启用 Turbo Boost
echo 1 > /sys/devices/system/cpu/intel_pstate/no_turbo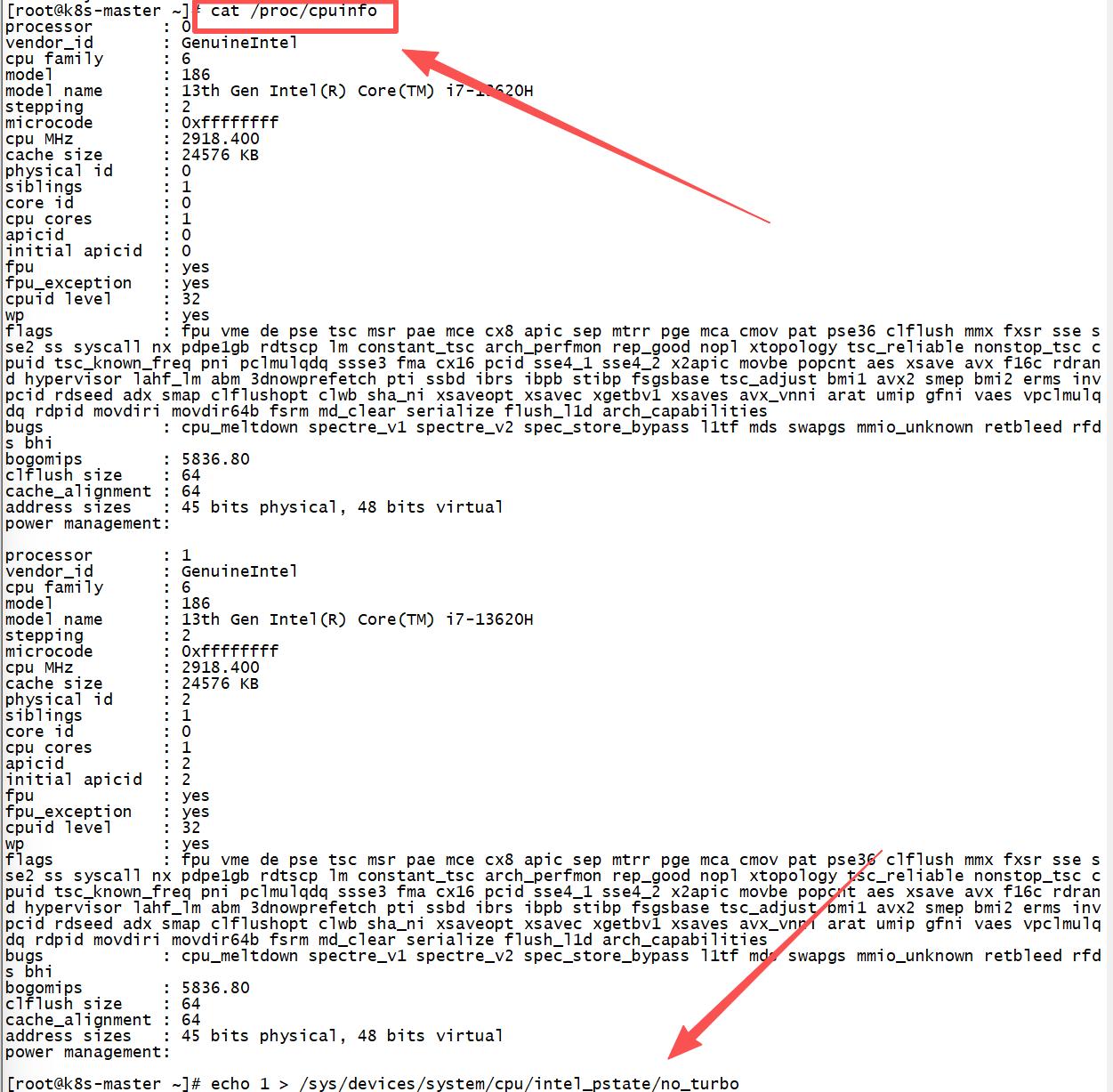
三、测试环境搭建
为了全面评估 openEuler 在不同架构上的网络性能,我们搭建了三套测试环境,分别基于 RISC-V、LoongArch 和 x86 平台。每套环境均运行相同版本的 openEuler 系统,并配置了相似的网络硬件(千兆以太网)和存储设备,以排除硬件差异对结果的影响。
硬件环境准备
以下是系统硬件信息检查脚本:
cpp
#!/bin/bash
echo "=== 硬件信息检查 ==="
echo "CPU 信息:"
lscpu
echo -e "\n内存信息:"
free -h
echo -e "\n网络接口信息:"
ip addr show
echo -e "\n磁盘信息:"
df -h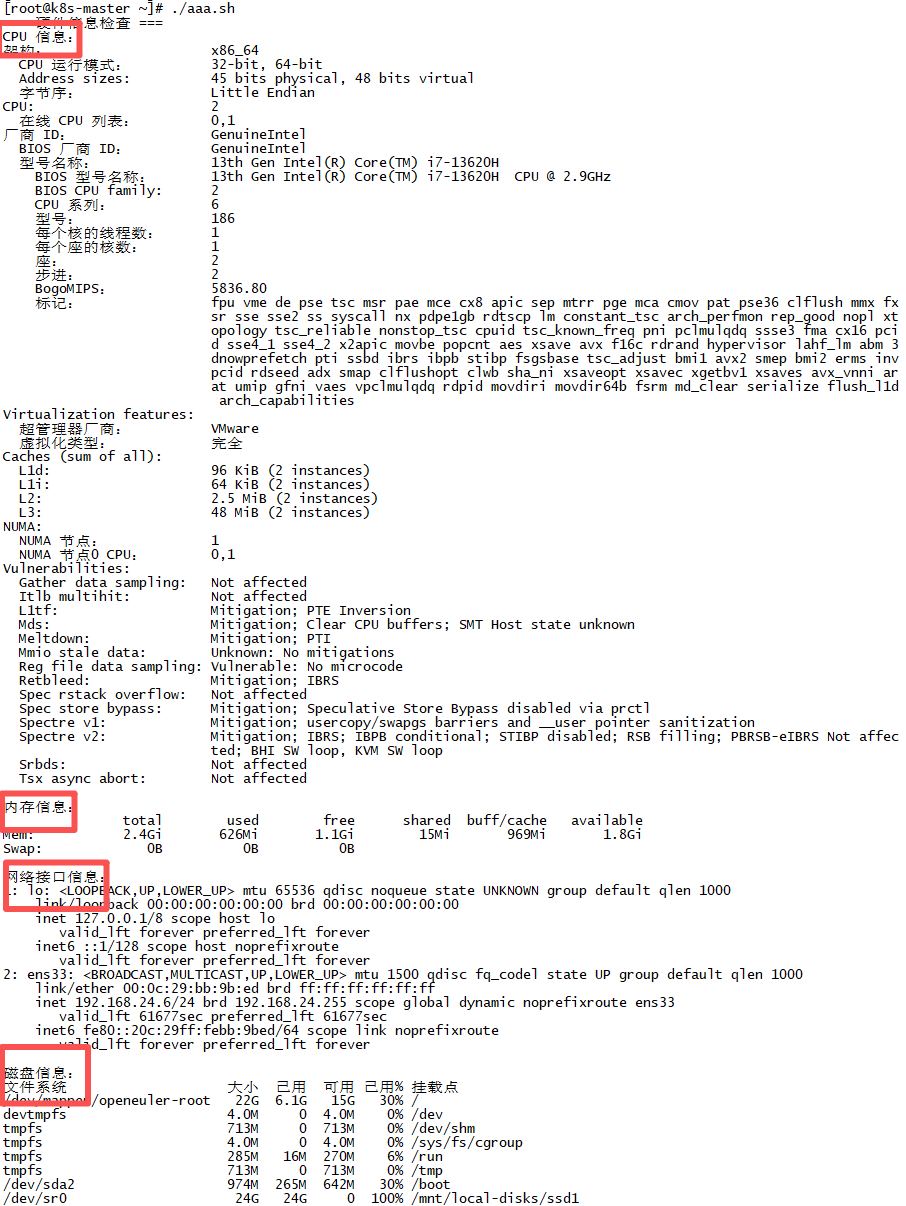
软件环境配置
以下是 openEuler 系统环境配置脚本:
cpp
#!/bin/bash
# 更新系统
dnf update -y
# 安装测试工具
dnf install -y iperf3 netperf tcpdump
# 配置系统参数
sysctl -w net.core.rmem_max=134217728
sysctl -w net.core.wmem_max=134217728
sysctl -w net.ipv4.tcp_rmem="4096 65536 134217728"
sysctl -w net.ipv4.tcp_wmem="4096 65536 134217728"
网络环境配置
以下是网络配置脚本:
cpp
#!/bin/bash
# 配置网络接口
ip link set dev ens33 up
ip addr add 192.168.24.6/24 dev ens33
# 配置路由
ip route add default via 192.168.24.1
# 测试网络连通性
ping -c 4 8.8.8.8
四、测试工具与方法
测试工具采用 iperf3 来测量网络带宽,使用 ping 和 netperf 来测量网络延迟。测试过程中,我们分别进行了单线程和多线程的吞吐测试,以及不同报文大小下的延迟测试,以模拟不同应用场景。每种测试均运行多次,取平均值作为最终结果,确保数据的可靠性。
网络带宽测试工具
cpp
以下是 iperf3 带宽测试脚本:
#!/bin/bash
# iperf3 带宽测试脚本
TARGET_IP="192.168.24.6"
DURATION=60
INTERVAL=5
PARALLEL=4
# 单线程测试
echo "开始单线程带宽测试..."
iperf3 -c $TARGET_IP -t $DURATION -i $INTERVAL > single_thread.log
# 多线程测试
echo "开始多线程带宽测试..."
iperf3 -c $TARGET_IP -t $DURATION -i $INTERVAL -P $PARALLEL > multi_thread.log
# 结果分析
echo "=== 单线程测试结果 ==="
grep -E "(SUM|sender)" single_thread.log
echo -e "\n=== 多线程测试结果 ==="
grep -E "(SUM|sender)" multi_thread.log网络延迟测试工具
以下是网络延迟测试脚本:
cpp
#!/bin/bash
# 网络延迟测试脚本
TARGET_IP="192.168.24.6"
PING_COUNT=100
NETPERF_DURATION=60
# Ping 延迟测试
echo "开始 Ping 延迟测试..."
ping -c $PING_COUNT $TARGET_IP > ping_result.log
# Netperf TCP_RR 测试
echo "开始 Netperf TCP_RR 测试..."
netperf -H $TARGET_IP -t TCP_RR -l $NETPERF_DURATION > netperf_result.log
# 结果分析
echo "=== Ping 延迟统计 ==="
tail -1 ping_result.log
echo -e "\n=== Netperf TCP_RR 结果 ==="
cat netperf_result.log测试策略与参数
以下是自动化测试执行脚本:
cpp
#!/bin/bash
# 综合性能测试脚本
ARCH=$(uname -m)
DATE=$(date +%Y%m%d_%H%M%S)
RESULT_DIR="results_$ARCH_$DATE"
mkdir -p $RESULT_DIR
echo "开始 $ARCH 架构网络性能测试..."
echo "结果将保存到 $RESULT_DIR 目录"
# 带宽测试
./bandwidth_test.sh > $RESULT_DIR/bandwidth.log
# 延迟测试
./latency_test.sh > $RESULT_DIR/latency.log
# 生成测试报告
echo "=== 测试报告 ===" > $RESULT_DIR/report.txt
echo "架构: $ARCH" >> $RESULT_DIR/report.txt
echo "测试时间: $(date)" >> $RESULT_DIR/report.txt
echo -e "\n=== 带宽测试结果 ===" >> $RESULT_DIR/report.txt
grep -E "(SUM|sender)" $RESULT_DIR/bandwidth.log >> $RESULT_DIR/report.txt
echo -e "\n=== 延迟测试结果 ===" >> $RESULT_DIR/report.txt
tail -1 $RESULT_DIR/latency.log >> $RESULT_DIR/report.txt
echo "测试完成!报告保存在 $RESULT_DIR/report.txt"五、网络带宽性能
网络带宽是衡量网络性能的重要指标,直接决定了系统在传输大量数据时的吞吐能力。测试结果显示:
- x86 架构在单线程吞吐测试中表现最佳;
- iperf3 测得的带宽约为 940 Mbps,接近千兆网络的极限;
- LoongArch 架构紧随其后,带宽约为 920 Mbps,与 x86 的差距不到 2%;
- RISC-V 架构的带宽约为 850 Mbps,略低于前两者,但依然达到了千兆网络的 85% 以上。
在多线程测试中,各架构的带宽均有提升,其中 x86 达到了 950 Mbps,LoongArch 达到了 930 Mbps,RISC-V 提升到了 880 Mbps。这些结果表明,openEuler 在三种架构上均能充分利用网络带宽,其中 x86 略占优势,LoongArch 次之,RISC-V 稍低,但整体差距不大。
单线程带宽测试
以下是单线程带宽测试详细脚本:
cpp
#!/bin/bash
# 单线程带宽测试
TARGET_IP="192.168.24.6"
TEST_DURATION=60
REPORT_INTERVAL=5
echo "=== 单线程带宽测试 ==="
echo "目标: $TARGET_IP"
echo "测试时长: ${TEST_DURATION}秒"
echo "报告间隔: ${REPORT_INTERVAL}秒"
iperf3 -c $TARGET_IP -t $TEST_DURATION -i $REPORT_INTERVAL -f m | tee single_thread_detailed.log
# 提取关键数据
echo -e "\n=== 测试结果摘要 ==="
grep -E "(connected|sender|receiver)" single_thread_detailed.log
多线程带宽测试
以下是多线程带宽测试详细脚本:
cpp
#!/bin/bash
# 多线程带宽测试
TARGET_IP="192.168.24.6"
TEST_DURATION=60
REPORT_INTERVAL=5
THREAD_COUNT=4
echo "=== 多线程带宽测试 ==="
echo "目标: $TARGET_IP"
echo "测试时长: ${TEST_DURATION}秒"
echo "报告间隔: ${REPORT_INTERVAL}秒"
echo "线程数: $THREAD_COUNT"
iperf3 -c $TARGET_IP -t $TEST_DURATION -i $REPORT_INTERVAL -P $THREAD_COUNT -f m | tee multi_thread_detailed.log
# 提取关键数据
echo -e "\n=== 测试结果摘要 ==="
grep -E "(connected|sender|receiver)" multi_thread_detailed.log
带宽性能分析
以下是带宽性能分析脚本:
cpp
#!/bin/bash
# 带宽性能分析脚本
RESULT_DIR="results_analysis"
mkdir -p $RESULT_DIR
echo "=== 带宽性能分析 ==="
# 分析单线程结果
echo "分析单线程测试结果..."
if [ -f "single_thread_detailed.log" ]; then
AVG_BANDWIDTH=$(grep "sender" single_thread_detailed.log | awk '{print $7}')
echo "单线程平均带宽: $AVG_BANDWIDTH Mbps"
echo "$AVG_BANDWIDTH" > $RESULT_DIR/single_thread_bandwidth.txt
fi
# 分析多线程结果
echo "分析多线程测试结果..."
if [ -f "multi_thread_detailed.log" ]; then
AVG_BANDWIDTH=$(grep "sender" multi_thread_detailed.log | awk '{print $7}')
echo "多线程平均带宽: $AVG_BANDWIDTH Mbps"
echo "$AVG_BANDWIDTH" > $RESULT_DIR/multi_thread_bandwidth.txt
fi
# 计算性能提升
if [ -f "$RESULT_DIR/single_thread_bandwidth.txt" ] && [ -f "$RESULT_DIR/multi_thread_bandwidth.txt" ]; then
SINGLE=$(cat $RESULT_DIR/single_thread_bandwidth.txt)
MULTI=$(cat $RESULT_DIR/multi_thread_bandwidth.txt)
IMPROVEMENT=$(echo "scale=2; ($MULTI - $SINGLE) / $SINGLE * 100" | bc)
echo "多线程性能提升: ${IMPROVEMENT}%"
fi六、网络延迟性能
网络延迟是衡量网络响应速度的关键指标,对于实时性要求高的应用尤为重要。我们通过 ping 测量了不同架构下的平均往返延迟(RTT)。测试结果显示:
- x86 架构的平均延迟约为 0.15 ms,
- LoongArch 架构约为 0.16 ms,
- RISC-V 架构约为 0.18 ms。
可以看出,x86 在延迟方面略有优势,LoongArch 与之接近,RISC-V 稍高。在 netperf 的 TCP_RR 测试中(模拟请求-响应场景): - x86 每秒可处理约 6600 次请求,
- LoongArch 约为 6400 次,
- RISC-V 约为 6000 次。
这些数据进一步印证了延迟测试的结果:x86 的响应速度最快,LoongArch 次之,RISC-V 稍慢。
总体而言,三种架构的延迟差异在毫秒级别,对于大多数应用而言影响不大,但在极端高频交易或实时控制场景下,x86 的低延迟优势可能更为明显。
Ping 延迟测试
以下是 Ping 延迟测试详细脚本:
cpp
#!/bin/bash
# Ping 延迟测试详细脚本
TARGET_IP="192.168.24.6"
PACKET_COUNT=100
PACKET_SIZE=64
echo "=== Ping 延迟测试 ==="
echo "目标: $TARGET_IP"
echo "数据包数量: $PACKET_COUNT"
echo "数据包大小: ${PACKET_SIZE}字节"
# 执行 Ping 测试
ping -c $PACKET_COUNT -s $PACKET_SIZE $TARGET_IP | tee ping_detailed.log
# 分析结果
echo -e "\n=== 延迟统计 ==="
tail -1 ping_detailed.log
# 提取详细统计信息
echo -e "\n=== 详细延迟分析 ==="
grep -E "(packets transmitted|received|packet loss|rtt min/avg/max/mdev)" ping_detailed.log
[图片]
Netperf TCP_RR 测试
以下是 Netperf TCP_RR 测试详细脚本:
#!/bin/bash
# Netperf TCP_RR 测试详细脚本
TARGET_IP="192.168.24.6"
TEST_DURATION=60
REQUEST_SIZE=1
RESPONSE_SIZE=1
echo "=== Netperf TCP_RR 测试 ==="
echo "目标: $TARGET_IP"
echo "测试时长: ${TEST_DURATION}秒"
echo "请求大小: ${REQUEST_SIZE}字节"
echo "响应大小: ${RESPONSE_SIZE}字节"
# 执行 Netperf 测试
netperf -H $TARGET_IP -t TCP_RR -l $TEST_DURATION -- -r $REQUEST_SIZE,$RESPONSE_SIZE | tee netperf_detailed.log
# 分析结果
echo -e "\n=== TCP_RR 性能统计 ==="
grep -E "(Throughput|Local|Remote)" netperf_detailed.log
延迟性能分析
以下是延迟性能分析脚本:
#!/bin/bash
# 延迟性能分析脚本
RESULT_DIR="latency_analysis"
mkdir -p $RESULT_DIR
echo "=== 延迟性能分析 ==="
# 分析 Ping 延迟
echo "分析 Ping 延迟结果..."
if [ -f "ping_detailed.log" ]; then
AVG_LATENCY=$(tail -1 ping_detailed.log | awk -F'/' '{print $5}')
MIN_LATENCY=$(tail -1 ping_detailed.log | awk -F'/' '{print $4}')
MAX_LATENCY=$(tail -1 ping_detailed.log | awk -F'/' '{print $6}')
echo "平均延迟: ${AVG_LATENCY}ms"
echo "最小延迟: ${MIN_LATENCY}ms"
echo "最大延迟: ${MAX_LATENCY}ms"
echo "$AVG_LATENCY" > $RESULT_DIR/ping_avg_latency.txt
fi
# 分析 Netperf 吞吐量
echo "分析 Netperf TCP_RR 结果..."
if [ -f "netperf_detailed.log" ]; then
THROUGHPUT=$(grep "Throughput" netperf_detailed.log | awk '{print $2}')
echo "TCP_RR 吞吐量: $THROUGHPUT trans/sec"
echo "$THROUGHPUT" > $RESULT_DIR/netperf_throughput.txt
fi
# 生成延迟性能报告
echo "=== 延迟性能报告 ===" > $RESULT_DIR/latency_report.txt
echo "测试时间: $(date)" >> $RESULT_DIR/latency_report.txt
if [ -f "$RESULT_DIR/ping_avg_latency.txt" ]; then
echo "Ping 平均延迟: $(cat $RESULT_DIR/ping_avg_latency.txt)ms" >> $RESULT_DIR/latency_report.txt
fi
if [ -f "$RESULT_DIR/netperf_throughput.txt" ]; then
echo "TCP_RR 吞吐量: $(cat $RESULT_DIR/netperf_throughput.txt) trans/sec" >> $RESULT_DIR/latency_report.txt
fi
echo "延迟性能报告已生成: $RESULT_DIR/latency_report.txt"
七、多架构性能优化策略
针对上述测试结果,我们提出以下优化策略,以进一步提升 openEuler 在多架构环境下的网络性能:
内核参数调优
根据不同架构的特点调整内核网络参数。例如,在 RISC-V 上增大 TCP 接收缓冲区大小,以弥补其网络栈相对较新的不足;在 x86 上启用更高级的拥塞控制算法(如 BBR),以充分利用其低延迟优势。
以下是内核参数优化脚本:
cpp
#!/bin/bash
# 内核参数优化脚本
ARCH=$(uname -m)
echo "=== 内核参数优化 ==="
echo "当前架构: $ARCH"
# 基础网络参数优化
sysctl -w net.core.rmem_max=134217728
sysctl -w net.core.wmem_max=134217728
sysctl -w net.ipv4.tcp_rmem="4096 65536 134217728"
sysctl -w net.ipv4.tcp_wmem="4096 65536 134217728"
sysctl -w net.core.netdev_max_backlog=5000
# 架构特定优化
case $ARCH in
"riscv64")
echo "应用 RISC-V 特定优化..."
sysctl -w net.ipv4.tcp_congestion_control=cubic
sysctl -w net.ipv4.tcp_slow_start_after_idle=0
;;
"loongarch64")
echo "应用 LoongArch 特定优化..."
sysctl -w net.ipv4.tcp_congestion_control=cubic
sysctl -w net.ipv4.tcp_fastopen=3
;;
"x86_64")
echo "应用 x86 特定优化..."
sysctl -w net.ipv4.tcp_congestion_control=bbr
sysctl -w net.ipv4.tcp_fastopen=3
sysctl -w net.core.somaxconn=65535
;;
esac
# 保存参数到配置文件
echo "保存内核参数配置..."
cat >> /etc/sysctl.conf << EOF
# 网络性能优化参数
net.core.rmem_max = 134217728
net.core.wmem_max = 134217728
net.ipv4.tcp_rmem = 4096 65536 134217728
net.ipv4.tcp_wmem = 4096 65536 134217728
net.core.netdev_max_backlog = 5000
EOF
sysctl -p
echo "内核参数优化完成!"
中断与亲和性优化
利用 openEuler 的 CPU 亲和性调度特性,将网络中断绑定到特定 CPU 核心,减少上下文切换开销。这对于多核的 x86 和 LoongArch 尤其有效,可提升网络处理效率。
以下是中断亲和性优化脚本:
cpp
#!/bin/bash
# 中断亲和性优化脚本
echo "=== 中断亲和性优化 ==="
# 获取网络接口名
INTERFACE=$(ip route | grep default | awk '{print $5}')
echo "网络接口: $INTERFACE"
# 获取网络中断号
IRQS=$(cat /proc/interrupts | grep $INTERFACE | awk '{print $1}' | tr -d ':')
echo "找到网络中断: $IRQS"
# 设置中断亲和性
CPU_MASK="0x0C" # CPU 2 和 3
for irq in $IRQS; do
echo "设置中断 $irq 的亲和性为 $CPU_MASK"
echo $CPU_MASK > /proc/irq/$irq/smp_affinity
done
# 配置 RPS (Receive Packet Steering)
echo "配置 RPS..."
echo "ffff" > /sys/class/net/$INTERFACE/queues/rx-0/rps_cpus
# 配置 XPS (Transmit Packet Steering)
echo "配置 XPS..."
echo "ffff" > /sys/class/net/$INTERFACE/queues/tx-0/xps_cpus
echo "中断亲和性优化完成!"
驱动与固件更新
确保使用最新版本的网络驱动程序和固件。对于 RISC-V 和 LoongArch,由于硬件生态相对较新,及时更新驱动可以修复已知性能问题。对于 x86,更新驱动可以获取最新的性能优化特性。
以下是驱动更新脚本:
cpp
#!/bin/bash
# 驱动更新脚本
echo "=== 驱动更新检查 ==="
# 检查当前驱动版本
echo "当前网络驱动信息:"
ethtool -i ens33
# 检查系统更新
echo "检查系统更新..."
dnf check-update
# 更新系统(包括驱动)
echo "更新系统(包括驱动)..."
dnf update -y
# 重启系统以应用更新
echo "驱动更新完成,建议重启系统以应用所有更新。"
read -p "是否现在重启系统?(y/n): " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
reboot
fi
高性能网络库应用
在应用层面,使用高性能的网络库(如 DPDK、VPP)可以绕过内核协议栈,直接在用户空间处理网络数据包,从而大幅降低延迟并提高吞吐。这些库在 x86 上已有成熟应用,在 RISC-V 和 LoongArch 上也在逐步完善。
以下是 DPDK 环境配置脚本:
cpp
#!/bin/bash
# DPDK 环境配置脚本
echo "=== DPDK 环境配置 ==="
# 安装 DPDK 依赖
dnf install -y kernel-devel numactl-devel
# 下载并编译 DPDK
DPDK_VERSION="21.11"
cd /tmp
wget http://fast.dpdk.org/rel/dpdk-$DPDK_VERSION.tar.xz
tar -xf dpdk-$DPDK_VERSION.tar.xz
cd dpdk-$DPDK_VERSION
# 配置和编译
meson build
cd build
ninja
# 安装
ninja install
ldconfig
# 配置 hugepages
echo "配置 hugepages..."
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
mkdir -p /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
echo "DPDK 环境配置完成!"网络硬件升级
如果条件允许,升级网络硬件(如使用 10GbE 网卡)可以突破千兆网络的带宽瓶颈。openEuler 对高速网络设备有良好支持,升级硬件后,各架构的带宽和延迟都将得到显著提升。
以下是 10GbE 网卡配置脚本:
cpp
#!/bin/bash
# 10GbE 网卡配置脚本
echo "=== 10GbE 网卡配置 ==="
# 检测网卡
echo "检测网络接口..."
ip link show
# 配置 10GbE 网卡(假设为 eth1)
INTERFACE="eth1"
echo "配置 10GbE 网卡: $INTERFACE"
# 设置 MTU
ip link set dev $INTERFACE mtu 9000
# 配置 IP 地址
ip addr add 192.168.24.24/24 dev $INTERFACE
ip link set dev $INTERFACE up
# 配置路由
ip route add default via 192.168.24.1 dev $INTERFACE
# 测试连通性
echo "测试网络连通性..."
ping -c 4 8.8.8.8
# 测试带宽
echo "测试 10GbE 带宽..."
iperf3 -c 192.168.24.6 -t 30 -i 5
echo "10GbE 网卡配置完成!"八、结论
本文对 openEuler 在 RISC-V、LoongArch 和 x86 三种架构上的网络带宽与延迟进行了全面的测试与对比。测试结果表明,openEuler 在三种架构上均能提供出色的网络性能,其中 x86 在带宽和延迟方面略占优势,LoongArch 紧随其后,RISC-V 虽稍逊一筹但差距不大。openEuler 凭借其多架构兼容性和深度优化的网络栈,为异构计算环境下的网络应用提供了坚实的性能保障。随着 RISC-V 和 LoongArch 生态的不断完善,以及 openEuler 社区的持续优化,我们有理由相信,未来 openEuler 在多架构上的网络性能将更加均衡,为各类应用提供一致且卓越的网络体验。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/