TL;DR
- 场景:在日志分析、报表统计、运营看板中,需要用 Elasticsearch 聚合替代数据库 GROUP BY/COUNT。
- 结论:合理组合指标聚合和桶聚合,能在一次查询中完成统计、分组、过滤和「类 HAVING」逻辑。
- 产出:给出从 max/sum/stats 到 range/bucket_selector 的完整示例,可直接改字段名复制到生产环境使用。
版本矩阵
| 已验证版本 | 说明 |
|---|---|
| Elasticsearch 7.17.x | 基本聚合语法(metrics、bucket、percentiles)均可正常使用 |
| Elasticsearch 8.9.x | 在日志与业务报表场景验证 range + 嵌套 metrics 聚合可用 |
| Elasticsearch 8.12.x | bucket_selector、percentile_ranks 等高阶聚合在生产环境跑通 |
| Kibana 8.x Dev Tools | 所有示例均可在 Dev Tools 控制台中直接执行与调试 |
聚合介绍
Elasticsearch 的聚合分析是一种强大的功能,允许用户在查询数据的同时对其进行统计分析、分组计算和排序,类似于 SQL 中的 GROUP BY 和 COUNT() 等操作。聚合分析包括两个主要类别:指标聚合和桶聚合。在聚合的基础上,你还可以进行嵌套聚合,将多个聚合组合在一起,从而构建复杂的分析查询。
聚合分析是数据库中的重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出某个字段(或计算表达式的结果)的最大值、最小值、计算和、平均值等。Elasticsearch作为搜索引擎兼数据库,同样提供了强大的聚合分析能力。 对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合metric,而关系型数据库中除了有桶聚合函数外,还可以对查询出的数据进行分组GROUP BY,再在组上进行指标聚合,在ES中GROUP BY称为分桶,桶聚合Bucketing Elasticsearch聚合分析语法,在查询请求体中aggregations节点,按如下语法定义聚合分析:
json
"aggregations" : {
"<aggregation_name>" : { <!--聚合的名字 -->
"<aggregation_type>" : { <!--聚合的类型 -->
<aggregation_body> <!--聚合体:对哪些字段进行聚合 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!--元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!--在聚合里面在定义子聚合 -->
}
}说明:aggregatations 也可以简写做:aggs
指标聚合
max min sum avg
指标聚合 (Metrics Aggregations) 指标聚合的主要功能是计算某个字段的数值统计结果。常见的指标聚合包括求和、平均值、最大值、最小值、计数等。它们通常用于返回单个数值结果。
常用的指标聚合包括:
- avg:计算数值字段的平均值。
- sum:计算数值字段的总和。
- min:返回数值字段的最小值。
- max:返回数值字段的最大值。
- value_count:计算某个字段的值的数量。
- stats:返回字段的统计信息,包括最小值、最大值、平均值、总和和数量。
- extended_stats:比 stats 聚合提供更详细的统计信息,如标准差和方差。
查询最贵的
json
# price的最大值
POST /book/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}执行结果如下图所示: 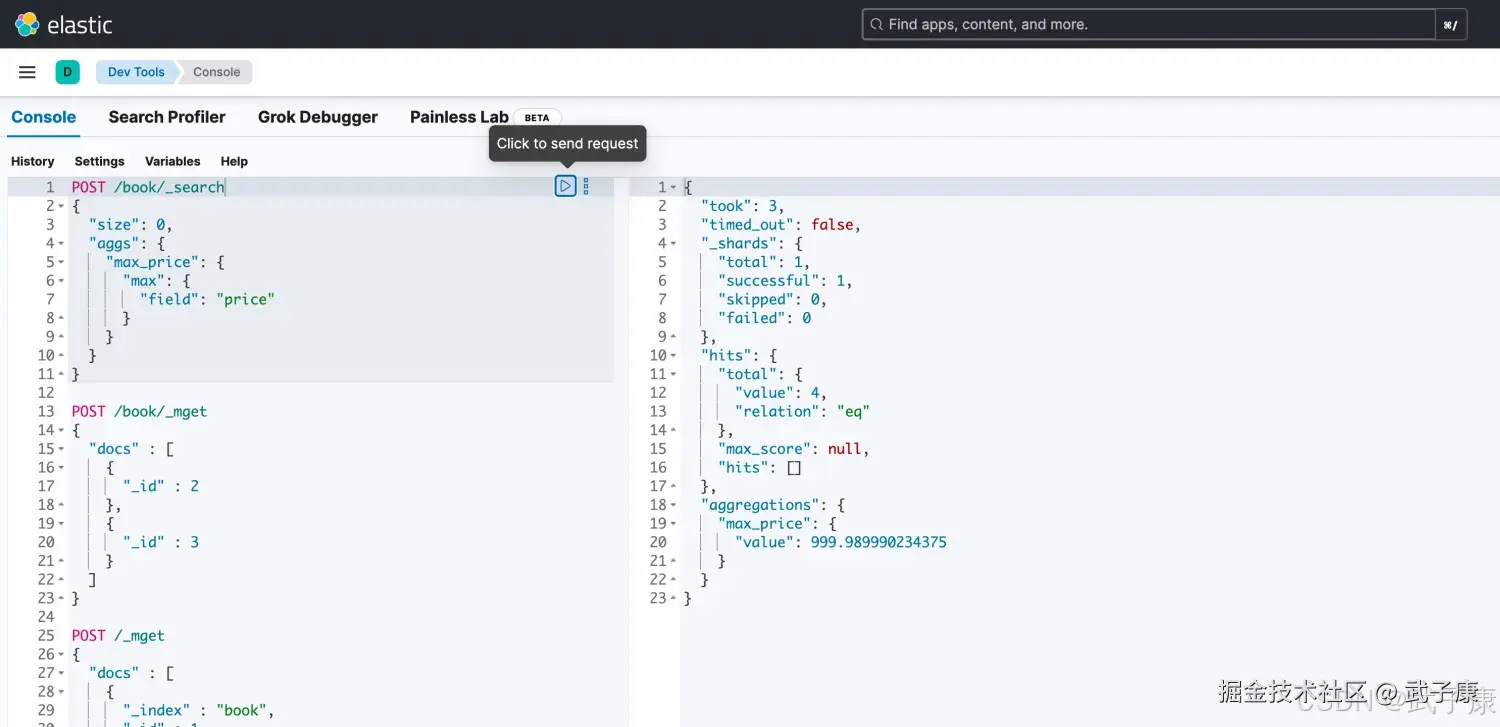
price大于100的
json
# 使用 _count 计算数量
POST /book/_count
{
"query": {
"range": {
"price" : {
"gt":100
}
}
}
}执行结果如下: 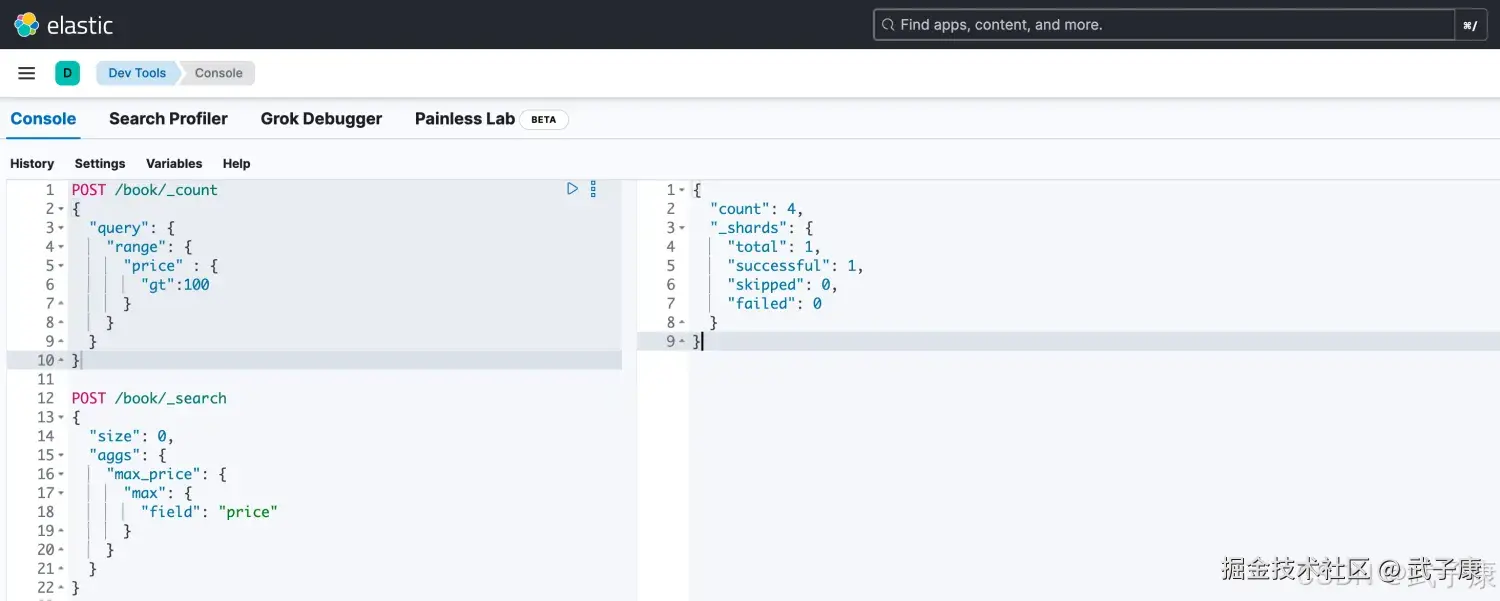
统计字段有值
json
# 通过聚合的方式 统计 price 有值的
POST /book/_search
{
"size": 0,
"aggs": {
"book_nums": {
"value_count": {
"field": "price"
}
}
}
}执行结果如下图所示: 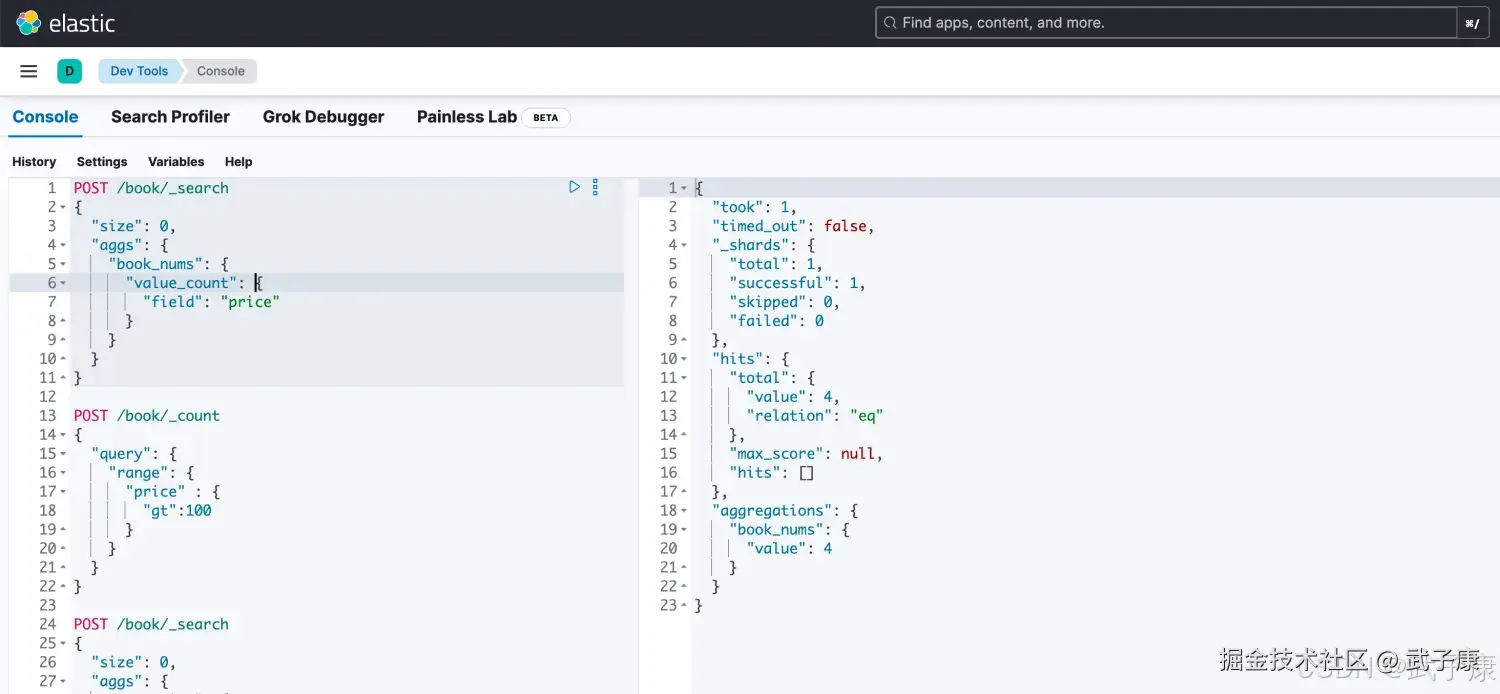
去重计数
json
# agg 聚合 去重数量
POST /book/_search?size=0
{
"aggs": {
"price_count": {
"cardinality": {
"field": "price"
}
}
}
}执行的结果如下图所示: 
统计计数
stats 可以统计好几个值:
- max
- min
- count
- avg
- sum
json
# stats
POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}运行结果如下图所示: 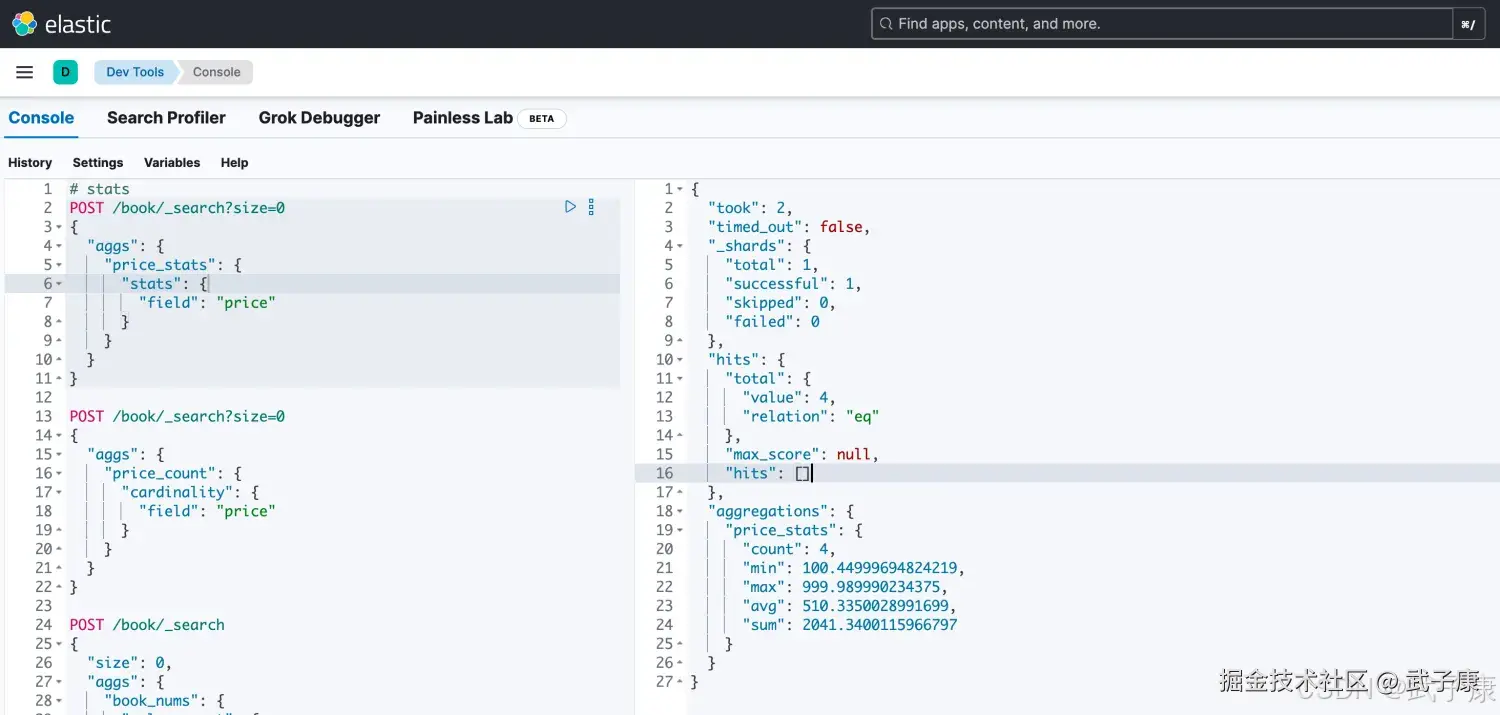
扩展统计
Extended Stats,高级统计,比stats多4个统计结果:
- 平方和
- 方差
- 标准差
- 平均值加/减两个标准差的区间
json
# extended stats
POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"extended_stats": {
"field": "price"
}
}
}
}占比百分位
Percentiles 占比百分位对应的值统计
json
# 占比百分位
POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price"
}
}
}
}执行结果如下图所示: 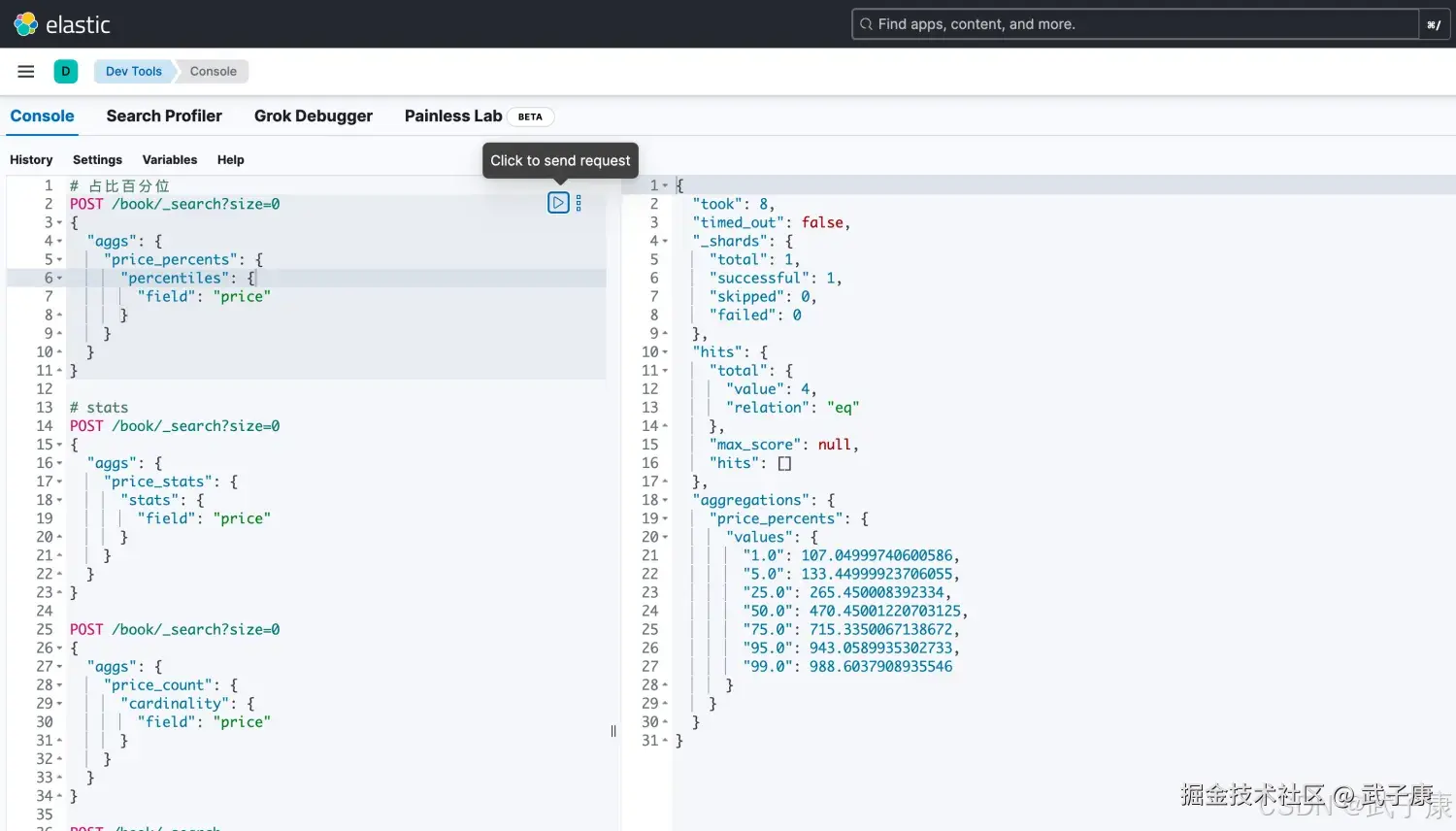
当然,我们也可以指定分位值:
json
# 指定分位值
POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price",
"percents" : [75, 99, 99.9]
}
}
}
}运行结果如下图: 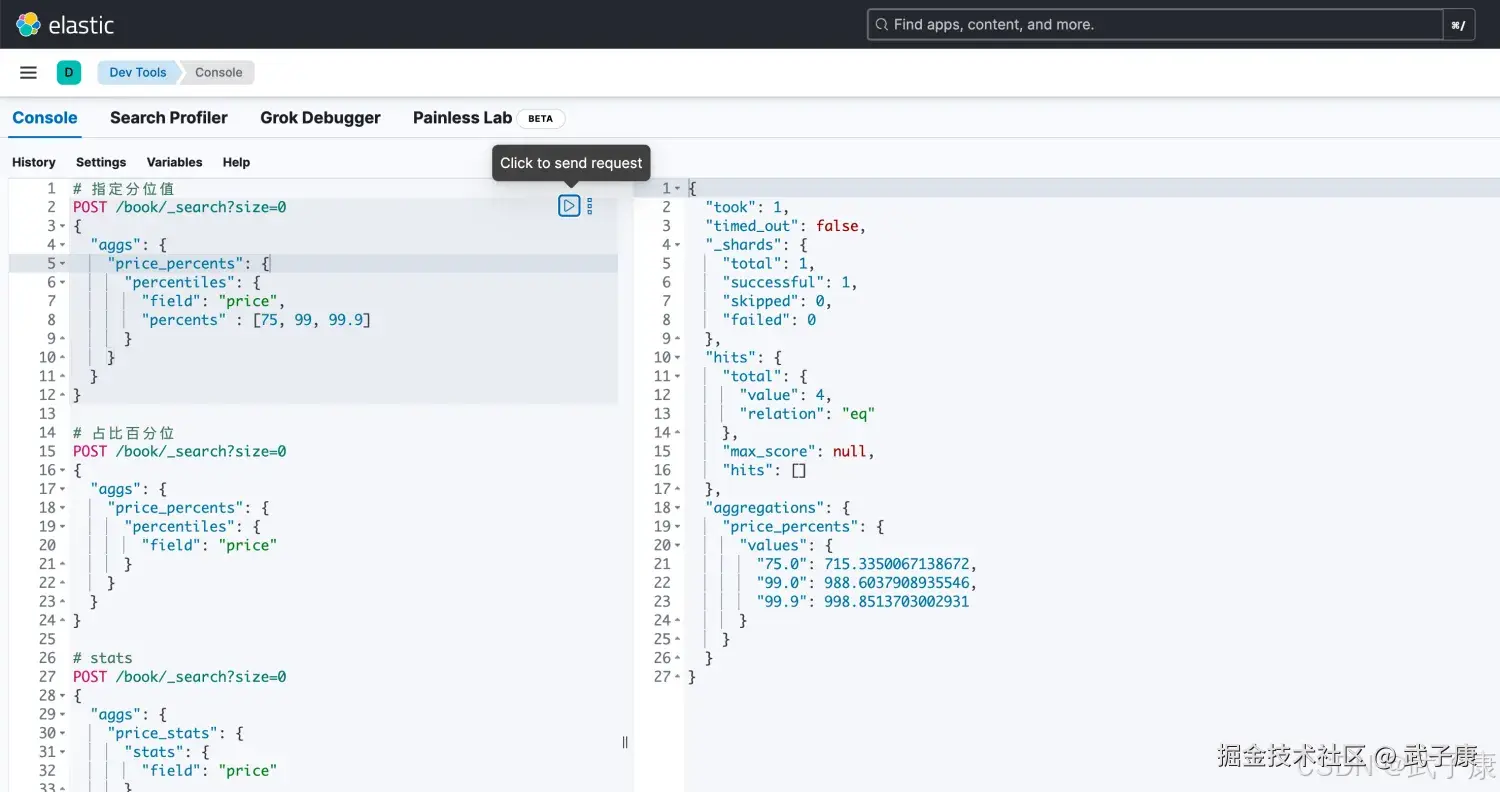
统计值小于等于指定值的文档占比
统计price小于100和200的文档的占比
json
POST /book/_search?size=0
{
"aggs": {
"gge_perc_rank": {
"percentile_ranks": {
"field": "price",
"values": [
100,200
]
}
}
}
}运行结果如下图所示: 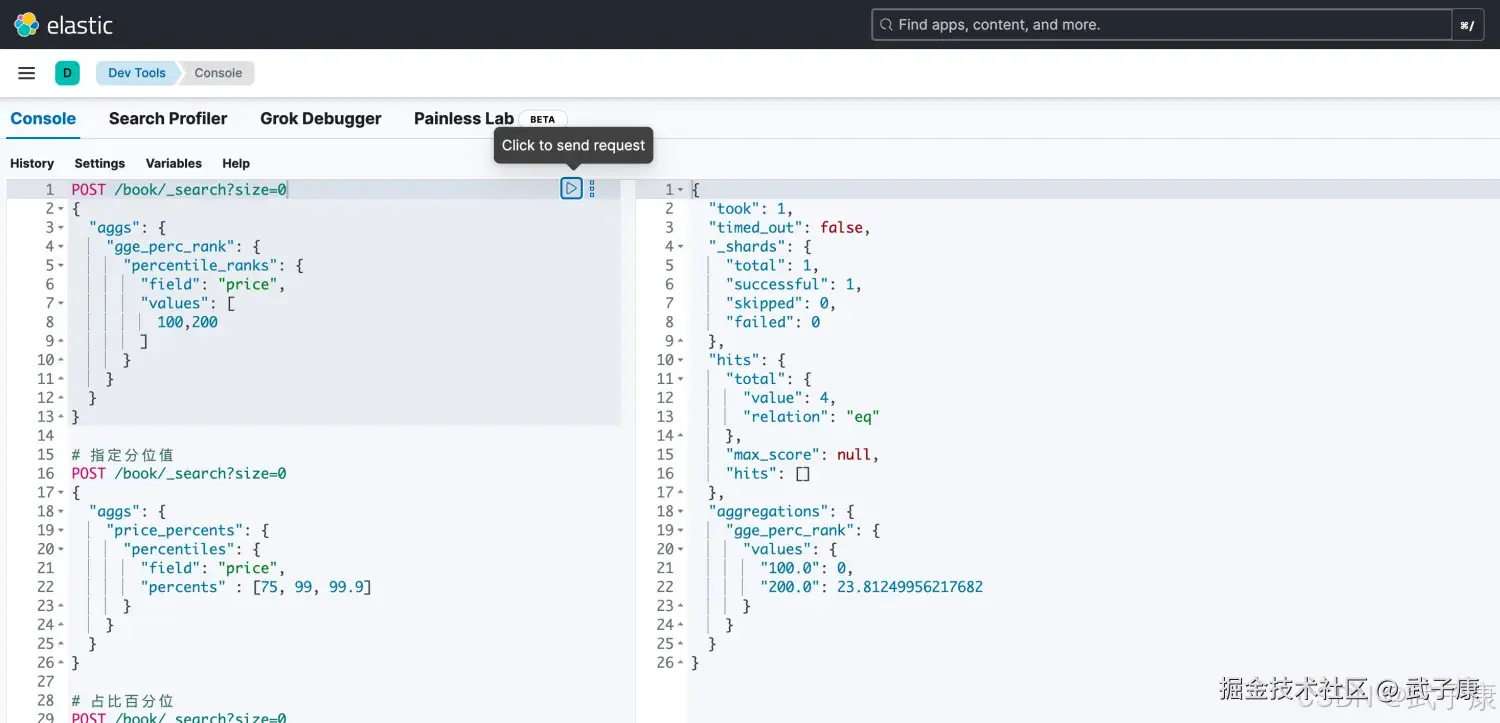
桶聚合
Bucket Aggregations,桶聚合。 它执行的是对文档分组的操作(与SQL中的GROUP BY类似),把满足相关特性的文档分到一个桶里,即桶分,输出结果往往是一个包含多个文档的桶(一个桶就是一个GROUP)
- bucket 一个数据分组
- metric 对一个数据分组执行的统计
桶聚合的目的是根据某些条件对文档进行分组,每个组称为一个"桶"。每个桶包含符合特定条件的文档集合,可以对每个桶进一步执行其他聚合分析(如指标聚合或嵌套的桶聚合)。
常见的桶聚合包括:
- terms:按某个字段的不同值进行分组(类似 SQL 的 GROUP BY)。
- range:根据数值范围对字段进行分组。
- date_histogram:基于时间字段按固定时间间隔分组。
- histogram:基于数值字段按固定间隔分组。
- filter:根据查询条件过滤文档。
- filters:根据多个查询条件将文档分为多个不同的桶。
- geo_distance:基于地理位置和距离的范围来分组。
json
POST /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 200
},
{
"from": 200,
"to": 400
},
{
"from": 400,
"to": 1000
}
]
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}执行的结果如下图所示: 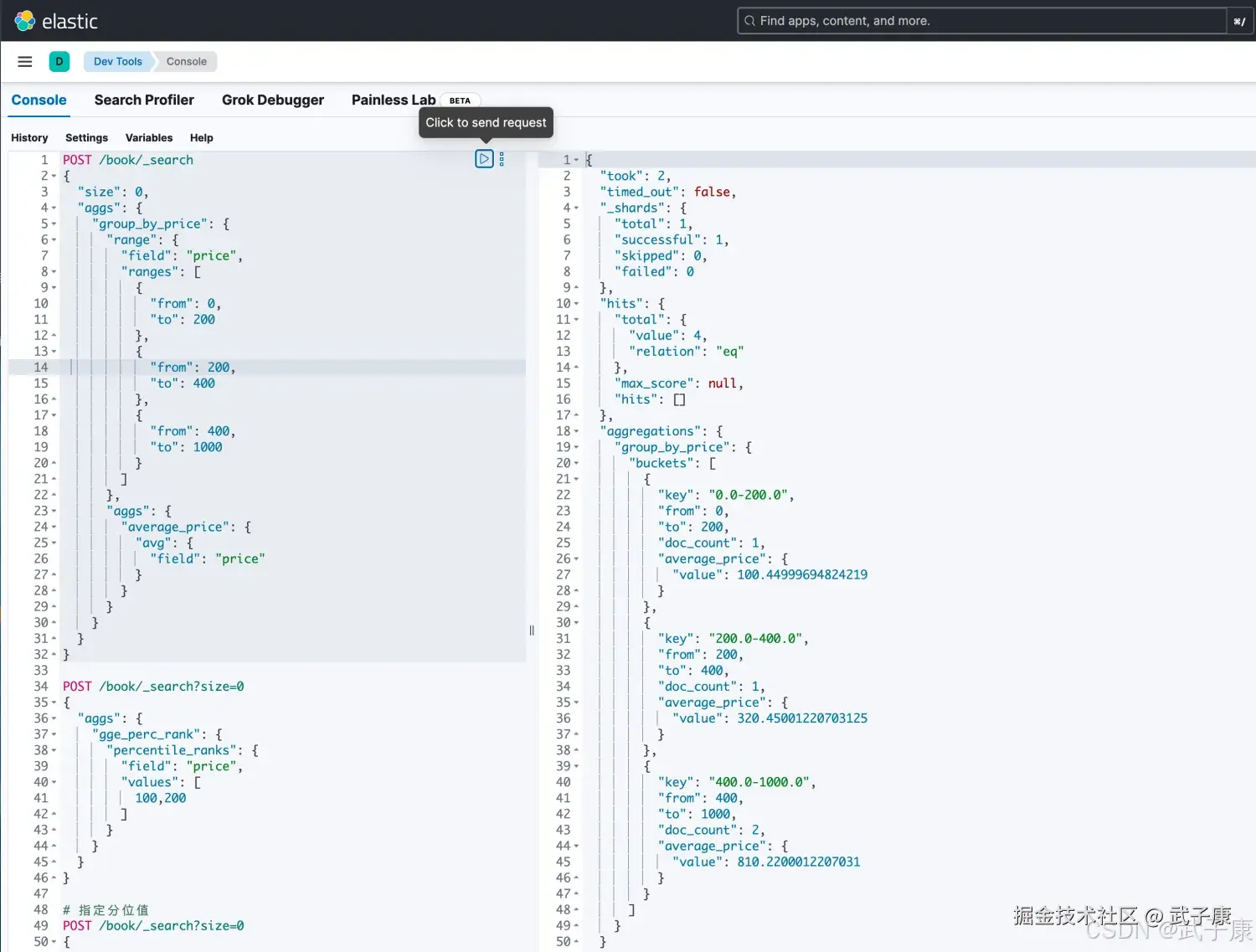
我们也可以实现having的效果:
json
POST /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 200
},
{
"from": 200,
"to": 400
},
{
"from": 400,
"to": 1000
}
]
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
},
"having": {
"bucket_selector": {
"buckets_path": {
"avg_price": "average_price"
},
"script": {
"source": "params.avg_price >= 200 "
}
}
}
}
}
}
}执行结果如下图所示: 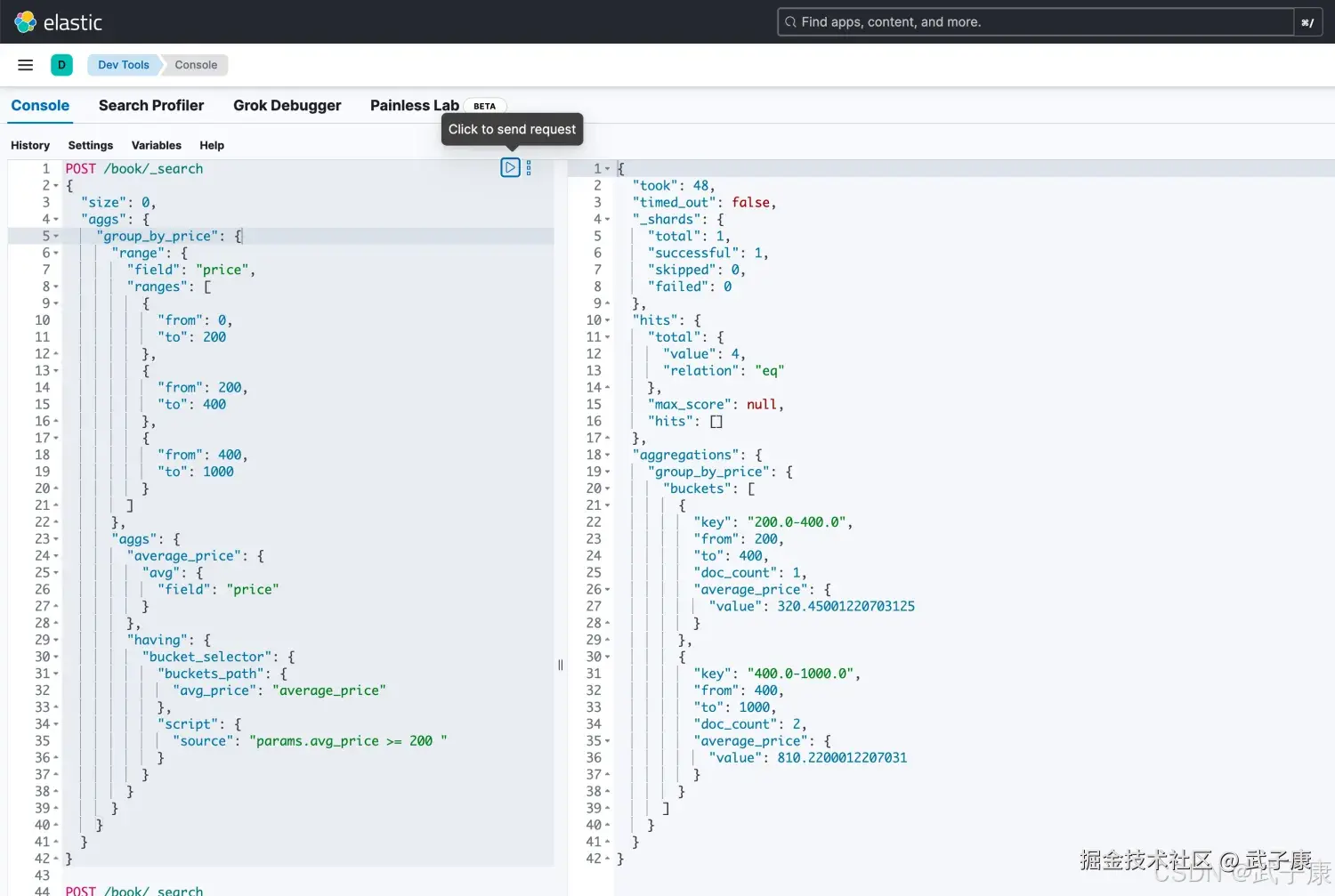
错误速查
| 症状 | 根因 | 定位修复 |
|---|---|---|
| 查询报错:Fielddata is disabled on text fields | 对 text 类型字段做 terms/聚合,未启用 fielddata | 查看 mapping,字段类型为 text改用 xxx.keyword 字段,或在 mapping 新增 keyword 子字段 |
| 聚合结果为空,hits 又有数据 | 聚合字段在部分文档中不存在或为 null | 用 exists 查询该字段,确认文档实际数据补齐数据、使用 missing 参数或改用 filter 先筛选 |
| cardinality 去重结果明显偏小或不稳定 | 默认 precision_threshold 较低,逼近估算误差边界 | 对比数据库真实去重计数提升 precision_threshold,或在关键统计链路避免用估算 |
| percentiles / percentile_ranks 报错或结果异常 | 对非数值字段或字符串字段做百分位聚合 | 查看 mapping,确认字段为 keyword/text 而非 numeric将字段改为数值类型,或新增数值型冗余字段用于聚合 |
| bucket_selector 无结果,桶全部被过滤 | 脚本条件过严或 buckets_path 字段名写错 | 临时去掉 bucket_selector 查看原始 bucket 统计校验 buckets_path 与 metrics 名称,放宽脚本阈值再调优 |
| 返回异常:too_many_buckets_exception | 桶数量过多(高基数 terms / 过细 histogram) | 查看响应中的 caused_by,确认异常类型限制 size、增加 shard_size 控制、改为预聚合或下采样 |
| 聚合请求非常慢,甚至拖垮集群 | 对高基数字段做全量聚合,未加 query 过滤或时间范围限制 | 在 Profiling / slowlog 中可看到该查询耗时异常先用 query 限定时间/业务范围,再做聚合;必要时走独立索引 |
| extended_stats 报 NaN 或统计无意义 | 数据量过少或字段中存在大量 null/异常值 | 使用 stats 对比,排查 count/sum 是否异常清洗异常值,必要时在 ingest 阶段过滤或做数值兜底 |
| range 桶统计结果与预期区间边界不一致 | 边界包含规则(from/to)理解错误,或浮点边界不精确 | 打印每个桶的 from/to,与文档样例逐条对比明确使用 from/to(左闭右开),必要时改为 filter 聚合 |
| date_histogram 桶数量与时间跨度不匹配 | fixed_interval 或 calendar_interval 配置不合理 | 查看响应中 buckets 数量与 interval 配置调整 interval(如 1d→1h 或反之),并限制查询时间范围 |
| 在 Dev Tools 能跑,代码中 DSL 报错解析失败 | 代码中 JSON/字符串转义错误或注释未去掉 | 打印最终发送到 ES 的 request body保持与 Dev Tools 一致的纯 JSON,避免内联注释、尾逗号等问题 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解