大家好,我是 方圆 。在前文 Cursor 无法跨项目读取源码怎么办?MCP Easy Code Reader 帮你解决 中,介绍了 MCP Easy Code Reader 原理、实践和接入方法,而本文主要是想分享"Easy Code Reader 这个 MCP 是因何诞生的",让大家来了解 "我为什么想写一个这样的 MCP" 以及 "开发一个 MCP 需要注意哪些问题",希望对大家能有一些启发,大家如果想阅读源码的话可以访问 Github: easy-code-reader。
因为我在 JD 工作,在内部使用 JoyCode,它也是一款 AI IDE(插件),大家在阅读时可以将其类比为 Cursor 或 Copilot,当然也欢迎大家下载体验 JoyCode。
JoyCode 不能跨项目读取源码的"困境"
在日常某个开发需求中,我需要在 "两个项目" 中完成 不同场景 消息推送的开发,这两段逻辑虽然场景不同,但是开发逻辑很相似,所以我就想使用 JoyCode 帮我在 B 项目中,参考 A 项目中已经开发完的代码,来完成 B 项目中的逻辑,提示词如下:
你是一位 Java 技术专家,请你参考 baozhang-trade 项目中,本机目录下的
/Users/fangyuan/IDEA PROJECT/baozhang-trade/baozhang-trade-web/src/main/java/com/jd/baozhang/trade/web/resource/LargeDeliverySyncResourceImpl.java中的 syncCompleteMessage 和 syncRefundMessage 方法的逻辑,帮我完成 bugou-trade 项目中@/athena-bugou-trade-web/src/main/java/com/jd/jr/baozhang/athena/bugou/trade/web/jsf/OutOrderSendMessageResourceImpl.java中 doSendCompleteMessage 和 doSendRefundMessage 方法的开发
之前 JoyCode 是没办法跨项目读取 Java 代码的:它不会脱离当前项目的"工作空间"读取其他文件。即使提示词中表达了要读取其他项目的本机文件,但是它依然会在当前项目中不断的寻找,所以它没办法帮我来完成这部分开发工作。
这个时候开发一个 MCP 的灵感就来了:写一个能够通过项目名和类名来读取 Java 源码的 Tool。定义 Tool 的内容如下,这个工具我把它命名为 read_project_code:
json
Tool(
name="read_project_code",
description=(
"从本地项目目录中读取指定文件的源代码或配置文件内容。"
),
inputSchema={
"type": "object",
"properties": {
"project_name": {
"type": "string",
"description": "项目名称(例如: my-project)"
},
"file_path": {
"type": "string",
"description": "文件标识符:可以是完全限定的 Java 类名或文件相对路径。Java 类名示例: com.example.MyClass(自动查找 .java 文件);文件路径示例: src/main/resources/application.yml、pom.xml、README.md、core/src/main/java/MyClass.java"
}
},
"required": ["project_name", "file_path"]
}
)入参只是项目名称project_name和文件标识符file_path,可以是类名和项目的相对路径,那么有了这个工具之后,我后续便能在提示词中表达:
请使用 MCP 参考 baozhang-trade 本地项目中
LargeDeliverySyncResourceImpl.java的源码内容,帮我实现 ... 功能
这个 Tool 对应 Python 实现的一个函数,并不复杂就不贴源码了,函数签名如下:
python
class EasyCodeReader:
async def _read_project_code(self, project_name: str, file_path: str) -> List[TextContent]:
"""..."""这样便完成了源码读取的基本功能,但是还需要考虑一个问题,JoyCode 现在还不清楚我的项目目录是什么,只知道我要读取的项目名称是baozhang-trade,就像我在最初的提示词中表达的:
请你参考 baozhang-trade 项目中,本机目录下的
/Users/fangyuan/IDEA PROJECT/baozhang-trade/baozhang-trade-web/src/main/java/com/jd/baozhang/trade/web/resource/LargeDeliverySyncResourceImpl.java
我明确告知了文件的绝对路径,但是这个 Tool 的入参只是项目名称和项目内的.java文件名,那该如何检索到这个 .java 文件的具体位置呢?
我是这样解决的:在 MCP Server 本地启动时添加一个 --project-dir的参数配置,这样 Easy Code Reader 就能在固定在这个目录下读取某个项目的某个文件了。本地打好 Python 包后,MCP Server 启动配置如下:
json
{
"mcpServers":{
"Easy Code Reader":{
"command":"uvx",
"args":[
"easy-code-reader",
"--project-dir",
"/Users/fangyuan/IDEA PROJECT"
]
}
}
}这样,我将最初的提示词改动一下,再给 JoyCode 时,便能完成跨项目的文件读取了:
你是一位 Java 技术专家,请你使用 MCP 帮我读取本机项目
baozhang-trade中的com.jd.baozhang.trade.web.resource.LargeDeliverySyncResourceImpl中的 syncCompleteMessage 和 syncRefundMessage 方法的逻辑,帮我完成 @/athena-bugou-trade-web/src/main/java/com/jd/jr/baozhang/athena/bugou/trade/web/jsf/OutOrderSendMessageResourceImpl.java 中 doSendCompleteMessage 和 doSendRefundMessage 方法的开发
因为我安装的 MCP 只有 Easy Code Reader,所以我只在提示词中表达了 MCP 而没具体到 Easy Code Reader 或者它具体的某个 Tool,它便帮我完成了以下工作:
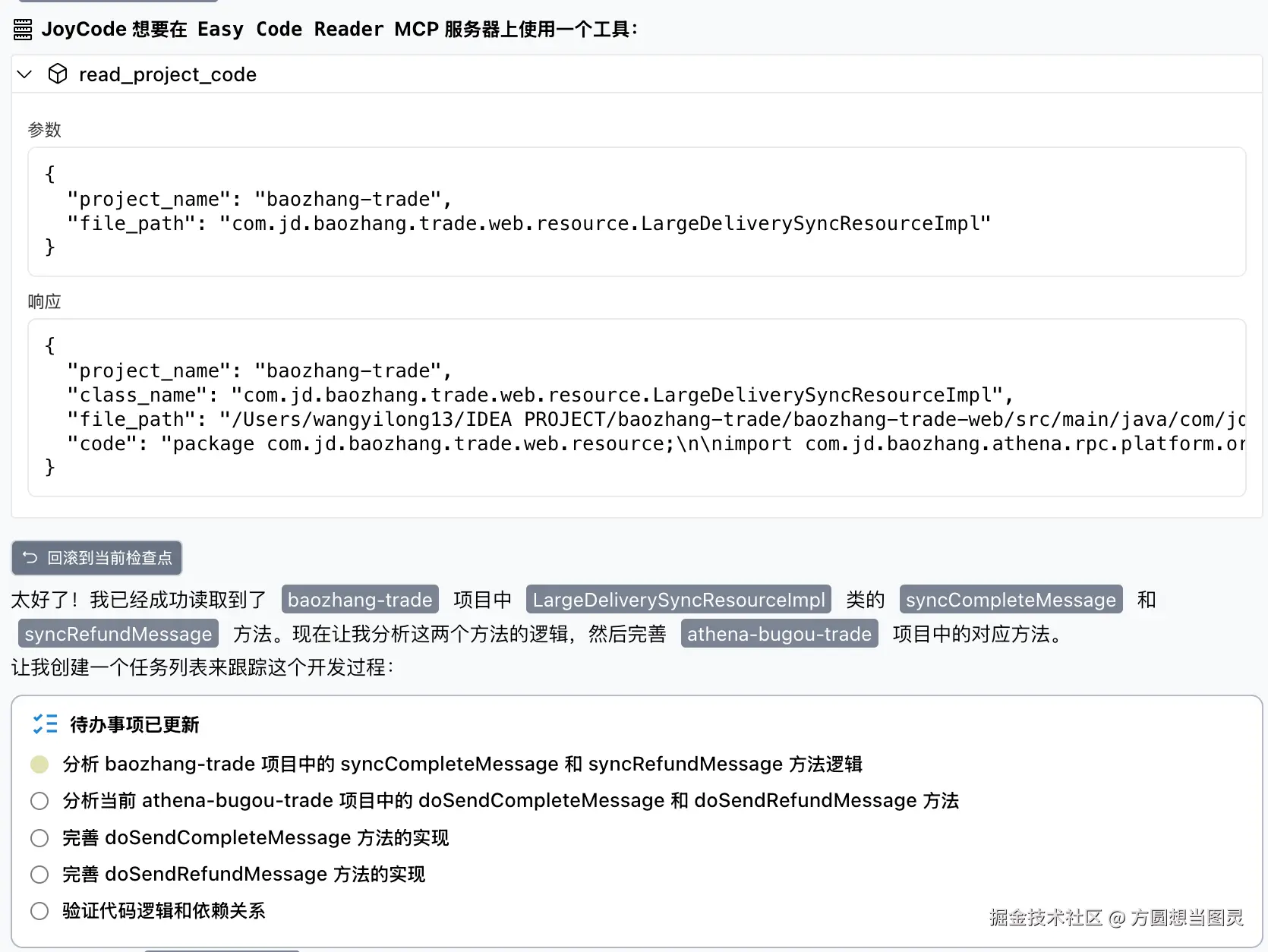
这个就是 Easy Code Reader 的最初版本。
我还想读 Jar 包中的源码怎么办?
下文中,JSF 接口请类比 Dubbo RPC 接口。
如题,JoyCode 无法读取 jar 包中的代码至少会有两个痛点:
- 我们的业务线根据业务场景划分了很多微服务,微服务与微服务之间通过 JSF 调用交互时,我们都会打一个
exportjar 包,通常情况下我们会依赖 Jar 包中的代码编写 JSF 接口的实现 - 在使用一些开源组件或京东内部组件的 SDK 时,这些代码往往也是被封装在 jar 包内的,无法读取这部分代码只能自己动手编写或者将 jar 包中的代码复制给 JoyCode,费时费力,有时可能因为复制内容不全导致 JoyCode 输出错误的结果
那么该如何让 JoyCode 读取到 jar 包中的源码呢?其实思路很简单:将 jar 包进行反编译。
现在只需解决反编译问题就好了,大家平时最常用的就是 IDEA 中的反编译功能了,因为它将这部分内容封装起来了,所以大家感知比较轻,但是大家平常打开 Maven 依赖中的类查看代码时便调用 IDEA 反编译的功能:

源码中这段注释内容表达的便是使用了 IDEA 内置的 FernFlower Decompiler 反编译器读取了 Java 代码,那么我们能不能使用 IDEA 反编译的能力呢?
其实是可以的,IDEA 把这项反编译功能开源了出来:Github - fernflower。它也是用 Java 编写的,我把它 clone 下来,执行 mvn package 命令把它打包成了一个 Java 包 fernflower.jar,它可以通过执行以下命令来完成 jar 包的反编译:
bash
# 反编译目标 jar 文件到目标目录
java -jar fernflower.jar [target_jar_path] [output_dir]那么我们写一个 Python 函数来执行这个命令不就好了?但是还需要提到一个点:因为这个开源项目是使用 JDK21 编写的,所以在执行 java -jar 命令时要求本机的 Java 版本也要大于等于 21,这就意味着大家需要重新装一下本地的 JDK 到 21 版本以上,这对大家来说太麻烦了,IDEA 能丝滑的使用这个反编译器是因为它内置了高版本的 JDK,所以为了方便大家使用还需要兼容低版本 JDK 的情况(JDK8 ~ 20)。
那么该怎么做呢?其实除了 IDEA 的反编译器,还有 CFR 反编译器能够执行反编译读取 Java 源码,所以读取 jar 包源码的 Tool 需要兼容两种反编译模式,在 Python 包中把这两个反编译器的 jar 包也一同打进去,在执行反编译操作时自动选择:
| Java 版本 | 反编译器 | 说明 |
|---|---|---|
| 8 - 20 | CFR | 自动使用CFR 反编译器(兼容 Java 8+),已包含在包中:src/easy_code_reader/decompilers/cfr.jar |
| 21+ | Fernflower | 自动使用Fernflower 反编译器(IntelliJ IDEA 使用的反编译器),已包含在包中:src/easy_code_reader/decompilers/fernflower.jar |
如下所示,我直接将这两个包放到了 Python 源码的打包目录下,这也是这个 Python 包在本地安装时有 20MB+ 的原因:
这下思路基本上清晰了,通过判断本机的 Java 版本选择合适的反编译器编译 jar 包,将反编译的结果返回,接下来我们继续编写 MCP Server,添加新的 Tool: read_jar_source:
json
Tool(
name="read_jar_source",
description=(
"从 Maven 依赖中读取 Java 类的源代码。\n"
"工作流程:1) 首先尝试从 -sources.jar 中提取原始源代码;2) 如果 sources jar 不存在,自动使用反编译器(CFR 或 Fernflower)反编译 class 文件。\n"
"支持 SNAPSHOT 版本的智能处理,会自动查找带时间戳的最新版本。\n"
"适用场景:阅读第三方库源码(如 Spring、MyBatis)、理解依赖实现细节、排查依赖相关问题。\n"
"注意:需要提供完整的 Maven 坐标(group_id、artifact_id、version)和完全限定的类名(如 org.springframework.core.SpringVersion)。\n"
),
inputSchema={
"type": "object",
"properties": {
"group_id": {
"type": "string",
"description": "Maven group ID (例如: org.springframework)"
},
"artifact_id": {
"type": "string",
"description": "Maven artifact ID (例如: spring-core)"
},
"version": {
"type": "string",
"description": "Maven version (例如: 5.3.21)"
},
"class_name": {
"type": "string",
"description": "完全限定的类名 (例如: org.springframework.core.SpringVersion)"
}
},
"required": ["group_id", "artifact_id", "version", "class_name"]
}
)在这个 Schema 中需要传入 Maven jar 包的坐标,包括 group_id, artifact_id, version,以及要读取的类名 class_name,这个 Tool 也对应一个 Python 函数,因为逻辑比较简单但是代码比较长就不再展示了。
与读取项目目录配置类似,也需要用户在启动 MCP Server 时配置本地 Maven 仓库目录参数--maven-repo,如下:
json
{
"mcpServers":{
"Easy Code Reader":{
"command":"uvx",
"args":[
"easy-code-reader",
"--maven-repo",
"/customer/maven-repository",
"--project-dir",
"/Users/fangyuan/IDEA PROJECT"
]
}
}
}这时这个 MCP 基本可用了,但是我在试用时又遇到了以下两个问题:
重复反编译问题
比如,我要多次读取某个 jar 包中的内容,每次都重复反编译怎么办?对于小 jar 包还好,对于比较大的 jar 包,尤其是一些大型 SDK,等待反编译的过程会非常耗时,有这个时间恨不得自己已经写完了,所以便 需要"缓存" 。
那缓存应该放在哪呢?
- 放在用户电脑的运行内存里合适吗?随着 Easy Code Reader MCP Server 的关闭而释放。这肯定是不行的,因为读取的 jar 包越多,占用内存越多,这就会导致"随着写代码时间变长,电脑怎么变卡了"
这样不行的话,那就放在硬盘里吧,这一点我参考的是 Nacos 开源项目的实现,它在做缓存时为了容灾把缓存内容直接写在了硬盘里,这样的话就不会占用运行内存也能避免重复反编译,还能高效的响应结果了。
我是这样做的,反编译后的文件会被缓存在 JAR 包所在目录的easy-code-reader/子目录中,例如:
如果 JAR 包位置为:
~/.m2/repository/org/springframework/spring-core/5.3.21/spring-core-5.3.21.jar
反编译后的源文件将存储在:
~/.m2/repository/org/springframework/spring-core/5.3.21/easy-code-reader/spring-core-5.3.21.jar
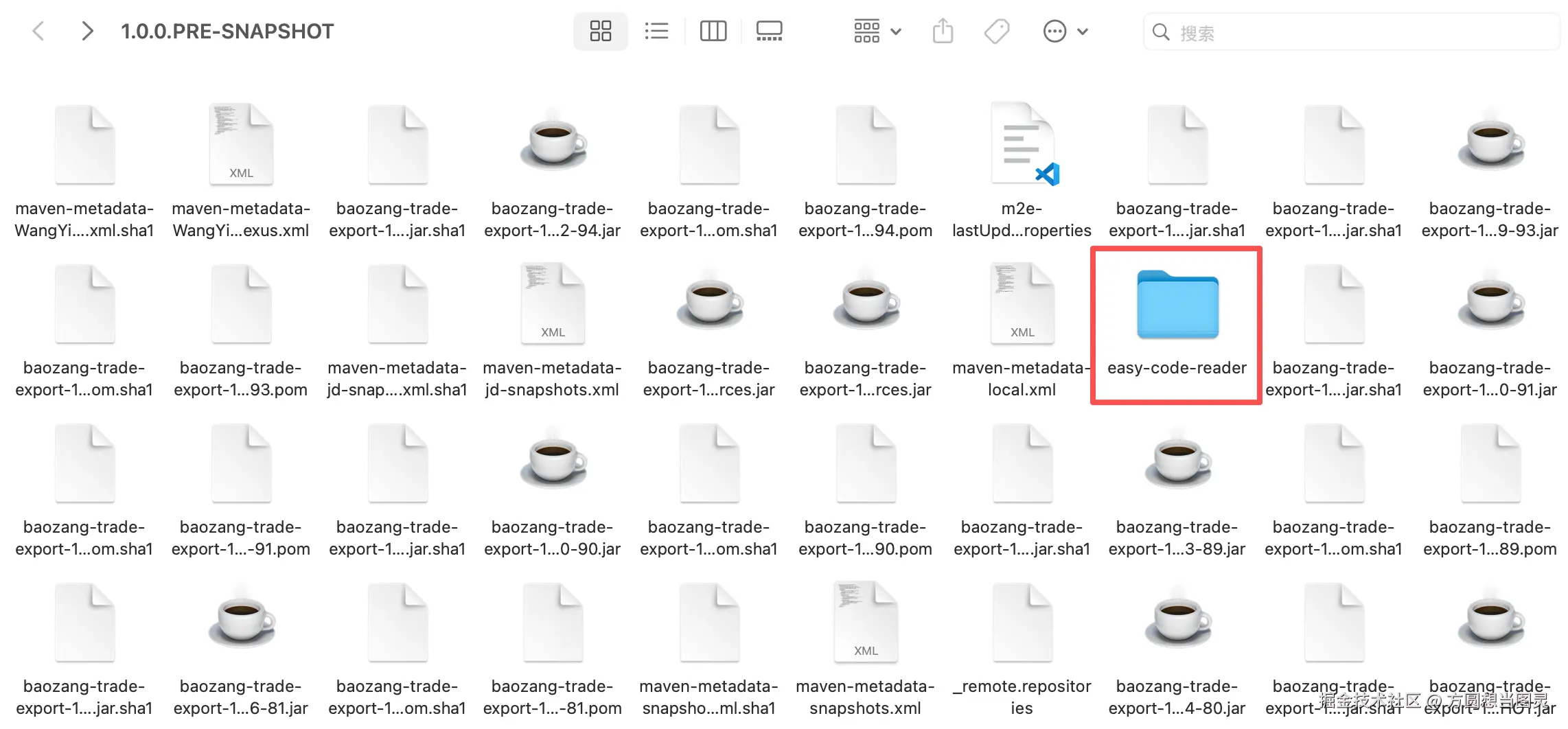
缓存文件本身也是一个 .jar 格式的压缩包,包含所有反编译后的.java文件,这样可以避免重复反编译相同的 jar 包,提高性能了。
还有一个问题需要注意:针对 SNAPSHOT 版本需要特殊处理, 比如说某个快照版本更新了多个,那么就会在对应的版本下生成多个时间版本,如下
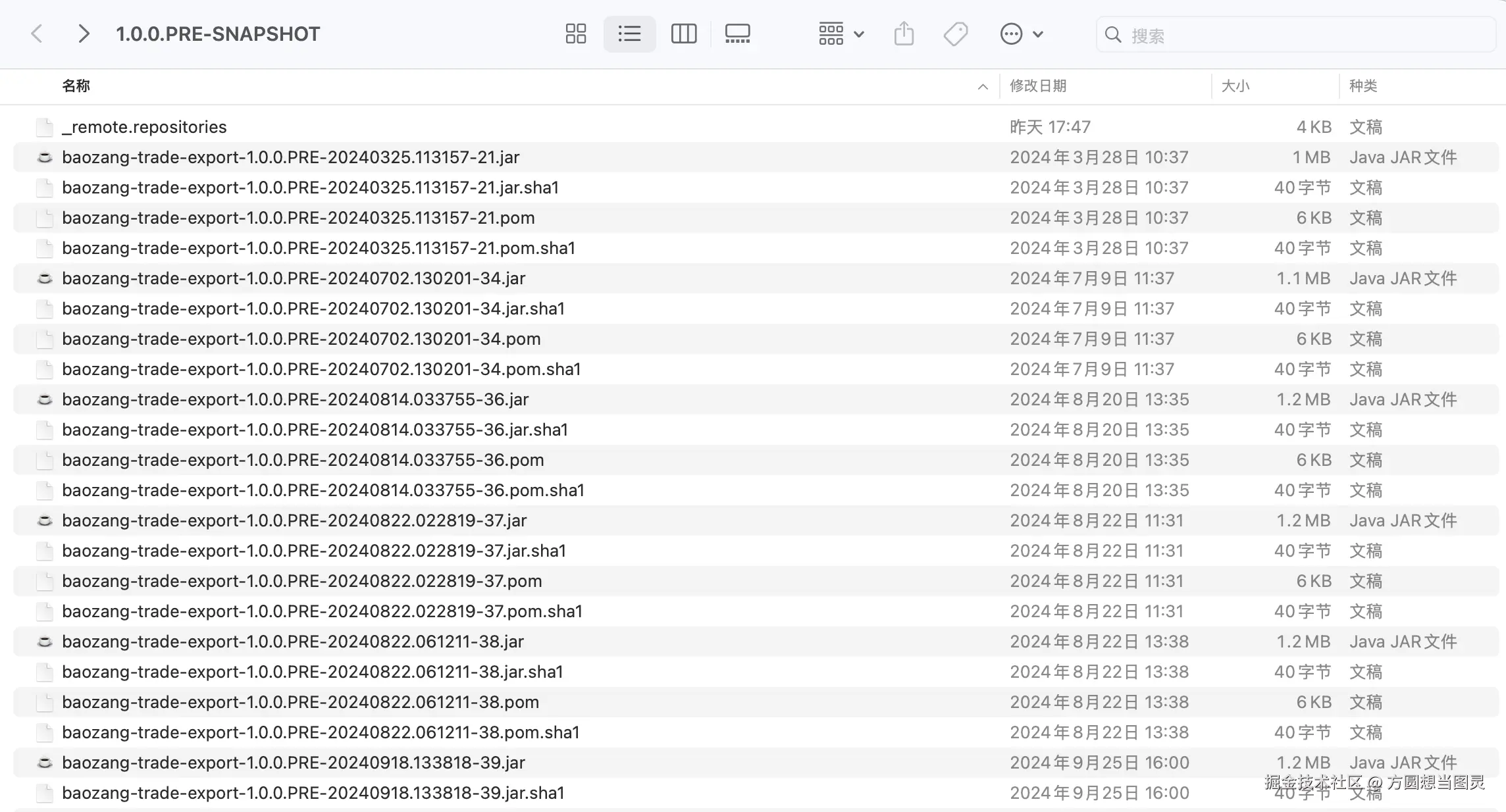
在对这这种快照版本进行反编译时:需要去查找最新的带时间戳版本进行反编译,并且缓存以artifact-1.0.0-20251030.085053-1.jar名称存储,提供版本判断的依据 ,每次读取快照版本的反编译缓存结果时,需要检测是否为最新版本,如果不是的话需要将旧的 SNAPSHOT 缓存进行清理,生成新的缓存文件,避免缓存失效。
Maven 坐标信息大模型判断不精准
在我们想要读取 jar 包中某个类时,通常我不会专门的在提示词中告诉大模型这个类对应的 Maven 坐标信息(group_id, artifact_id, version),而是直接在提示词中表达:
请使用 MCP 帮我读取
com.jd.jr.baozhang.athena.bugou.trade.export.resource.OutOrderSendMessageResource中的源码信息
有时大模型可能就会出现读取 Maven 坐标不准的情况,比如它可能会按照以下坐标去读取:
xml
<dependency>
<groupId>com.jd.jr</groupId>
<artifactId>athena-bugou-trade-export</artifactId>
<version>${export.version}</version>
</dependency>
或
<dependency>
<groupId>com.jd.jr.baozhang</groupId>
<artifactId>athena-bugou-trade-export</artifactId>
<version>${export.version}</version>
</dependency>
实际的:
<dependency>
<groupId>com.jd.jr.baozhang.athena</groupId>
<artifactId>athena-bugou-trade-export</artifactId>
<version>${export.version}</version>
</dependency>因为我没在提示词中告诉它具体的坐标,所以它会"自己猜测一个坐标"去读取,偶尔就会出现 group_id 猜测不全导致"扑空"的情况,那这个问题该如何解决呢?
首先我们需要了解一下大模型是如何猜测的,以 jar 包中 com.jd.jr.baozhang.athena.bugou.trade.export.resource.OutOrderSendMessageResource 的上下文信息为例:

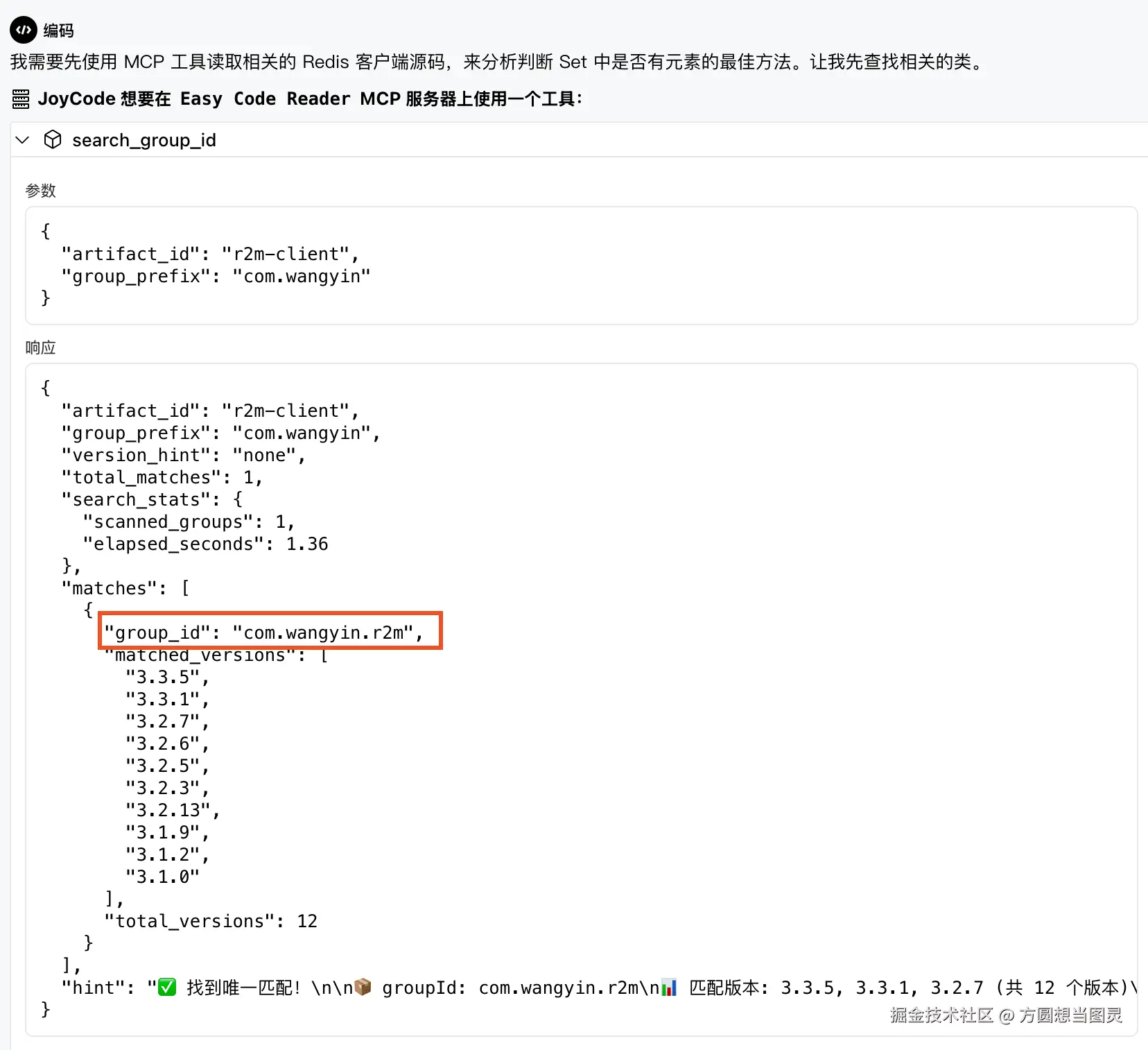
其实我们能够获取到准确的 Maven 坐标,但是大模型不行,所以我又提供了一个 Tool: search_group_id,这个 Tool 能够通过artifact_id查询出来本地仓库中对应的 group_id:
json
Tool(
name="search_group_id",
inputSchema={
"type": "object",
"properties": {
"artifact_id": {
"type": "string",
"description": "Maven artifact ID,不含版本号(例如:spring-context)"
}
},
"required": ["artifact_id"]
}
)实现起来并不难,所以就不再赘述源码了,接下来演示一个我最近使用的最佳实践,这个在开发中提效还是蛮明显的。这是在最近的需求中,我使用 Redis 的 SDK 做了一个令牌桶,我想让 JoyCode 读取 SDK 中的内容来帮我分析使用哪些方法比较合适,提示词如下:
你是一位 Java 技术专家,精通 Redis 的使用,请你使用 MCP 读取
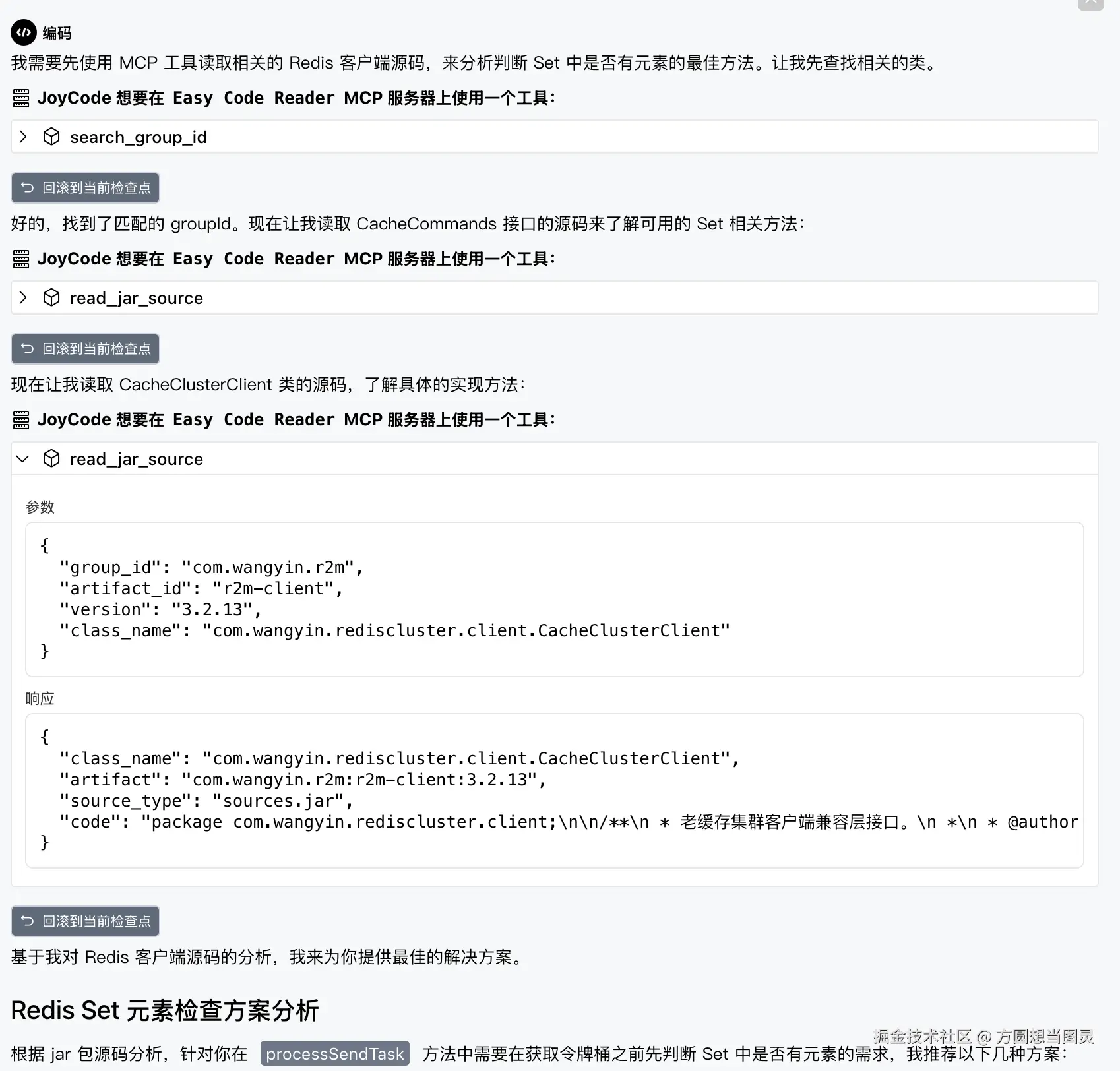
com.wangyin.rediscluster.client.CacheCommands或com.wangyin.rediscluster.client.CacheClusterClient等类中的 jar 包源码信息,帮我分析,目前我在 @/baozang-trade-service/src/main/java/com/jdd/baozang/trade/service/impl/QualityInspectionAgentServiceImpl.java 中的 sendToAgent 方法使用了 sadd 方法添加缓存元素,但是在 processSendTask 方法中,执行了获取令牌桶的方法,实际上在获取令牌桶之前应该先判断添加元素的 Set 中有没有元素,请你根据jar 包中源码帮我分析,调用哪个方法来判断比较合适?
它会先执行search_group_idTool 来获取 group_id:
随后使用 read_jar_source 来读取 jar 包源码完成分析:
功能的"质变":链路分析
其实开发完以上内容后,基本上已经解决了我在日常开发中的痛点了,所以我也在团队内部分享了一下,想让大家也用一用。这个时候组内架构师提了一个问题一下就启发了我:"这个 MCP 能沿着调用链路读取代码进行分析吗?"
现在的功能已经满足读取 jar 包和其他项目代码了,如果再提供两个 Tool 分别让大模型 了解到本地有哪些其他项目 和 在某个项目中有哪些文件,它就能通过 JSF 接口的入口一直沿着调用链路进行分析了,所以我又开发了两个 Tool:
list_all_project: 列出本地项目 ,这个工具能将配置的项目目录--project-dir下所有的文件夹都读取出来,每个文件夹代表一个项目,这样 JoyCode 便能根据项目名称来选择需要读取的项目list_project_files: 列出指定项目中的所有文件名,这个工具能将指定项目下的所有源码文件名都读取出来,Code Agent 便能根据调用链路选择需要读取的文件
开发过程与上面的内容类似,我就只拿其中的list_project_filesTool,再讲一点开发时需要注意的内容:
Tool: list_project_files
刚才我们讲过这个工具的作用是 列出指定项目中的所有文件名 ,但是需要考虑一个问题:如果我有一个非常大的项目,其中几百上千个文件,那么就有一种可能:大模型调用完这个 Tool 后便产生了大量的无效上下文,影响模型输出结果。所以这个 Tool 在实现的使用提供了一个入参 project_name_pattern进行模糊匹配:
python
async def _list_all_project(project_dir: Optional[str] = None,
project_name_pattern: Optional[str] = None) -> List[TextContent]:
"""
列举项目目录下所有的项目文件夹
参数:
project_dir: 项目目录路径(可选)
project_name_pattern: 可选,项目名称模糊匹配模式(不区分大小写)
"""比如我只想获取 a 项目下所有的 Service 文件,那么入参 project_dir: a, project_name_pattern: service,便能获取需要的类名称而不是所有的类。有了这个实现大模型便能够推理系统间调用链路接口的关键字只获取必要的提示词信息,缩小上下文。
但是模糊匹配就会丢失一些信息,大模型可能会出现幻觉,出现幻觉再模糊匹配就会导致必要的类信息被忽略,导致结果出现变差,那这个该如何解决呢?我的方法是在返回的结果中添加提示信息:
python
# 如果使用了项目名称模式但没有匹配到项目,添加提示
if project_name_pattern and len(projects) == 0:
result["hint"] = (
f"⚠️ 使用项目名称模式 '{project_name_pattern}' 未匹配到任何项目。\n\n"
"可能原因:\n"
"- 模式关键词不在项目名称中\n"
"- 项目名称拼写与模式不符\n\n"
"建议操作:\n"
"1. 不传入 project_name_pattern 参数,重新调用 list_all_project 查看完整文件列表\n"
"2. 从完整列表中找到正确的项目名称后再进行后续操作"
)
result["total_all_projects"] = len(all_projects)
elif project_name_pattern:
result["hint"] = (
f"✓ 已使用项目名称模式 '{project_name_pattern}' 进行过滤,共匹配到 {len(projects)} 个项目。\n\n"
"如果未找到预期的项目:\n"
"- 可能是模式匹配过于严格\n"
"- 建议不传入 project_name_pattern 参数重新调用 list_all_project 查看完整项目列表"
)
result["total_all_projects"] = len(all_projects)如果使用了模糊匹配都会有提示信息,让大模型重新调用 Tool 来获取全量的数据重新进行分析,这是目前我想到的兜底办法。
接下来我们来看一个链路分析的最佳实践:
最佳实践
以实际业务中 3cs 下单流程为例,在 3cs 下单流程中使用了 协同式 Saga 保证数据的一致性,这个流程中跨越多个应用且流程复杂,如果不了解相关的业务和逻辑的话,上手开发或者排查问题还是较为困难的事情,那么提供了以上 Tool 之后,能让 JoyCode 帮我们根据消息入口读取相关链路源码并进行分析吗?我试了一下是可以的:
开始任务时采用的是以下 Prompt,并且使用的是 "智能体团队" 智能体,这个智能体能开启多个任务,避免单一任务上下文太长:
text
你是一位 Java 技术专家,熟悉分布式事务的原理,我现在想了解 3cs 订单下单的流程(不关注换货或退单),但是它的链路非常长,涉及的应用比较多,包括 yb-trade, yb-orders, yb-platform 和 lvsheng-trade 等本地应用,入口在 yb-trade 以 JMQ 消息的形式,它的主题是 pvp_test_order 定义了 @/yb-trade-service/src/main/java/com/jdd/baoxian/yb/trade/service/mq/Order3csServiceHandler.java 消费者,请你根据源码分析,从这个消息消费,到调用 yb-orders 再到 lvsheng-trade 落数据库订单的流程,你需要检查相关链路上的源码和配置文件(包括但不限于 jmq 或 jsf 配置),读取多个本地项目或依赖的 jar 包内容,在这个过程中你需要依赖 easy-code-reader 的 MCP 的能力,输出结果并请帮我画出接口调用的时序图,并告诉我在处理的过程中涉及那些具体的 JMQ 主题,JSF 接口和落数据库的表名
注意以下几点:
0. 每次创建子任务时需要使用编码智能体,这样才能使用 MCP 工具
1. 在读取项目文件时,请严格遵守使用 easy-code-reader MCP 的原则,不能自主扫描和读取应用代码,避免出现读错应用代码的情况
2. 如果遇到 jar 包需要读取,也需要使用 easy-code-reader MCP 的工具
3. 3cs下单链路是自上向下的过程,由 yb-trade 到 yb-orders 到 yb-platform 到 lvsheng-trade,所以你在每分析完一个应用的逻辑后,会获取到衔接下一个应用的逻辑,请你记住这些衔接的逻辑,这些需要作为检查加一个项目的起点它会执行一个时间非常长的任务,根据消息和JSF接口的调用链路不断处理 ,生成的结果与业务流程基本一致,这会 极大的降低复杂系统的上手难度,加快开发者对现有微服务项目的理解。说实话我也对 AI 本次任务输出的结果感到吃惊,随着 AI 能力进一步的发展,处理任务的结果只会更好。
总结
我觉得 "从问题中来,到问题中去" 是本次开发 MCP Server 中最大的灵感来源,当我想要去解决问题的时候才会源源不断地迸发出很多想法。大家如果想使用这个 MCP 的话可以参照前文 Cursor 无法跨项目读取源码怎么办?MCP Easy Code Reader 帮你解决 或 Github: easy-code-reader。