前言
Go 语言的"高并发"核心支撑是 GMP 调度模型,通过 Goroutine(协程)、Machine(操作系统线程)、Processor(逻辑处理器)的协同管理,实现"百万级协程低成本调度"与"多核 CPU 高效利用"的平衡。本文基于 Go 1.23+ 源码,从基础概念、核心原理、实践场景到误区澄清
(一)基础概念:GMP 三组件核心定义
1. 核心组件对比
| 组件 | 中文含义 | 核心作用 | 关键特性 |
|---|---|---|---|
| G | 用户级协程 | 承载业务逻辑的最小并发单元 | 轻量(初始栈 2KB)、创建/切换成本低、支持动态扩容 |
| M | 操作系统线程抽象 | 执行 G 的物理载体 | 对应 OS 线程、需绑定 P 才能执行 G、阻塞时释放 P |
| P | 逻辑处理器 | 调度中枢,连接 G 与 M | 数量=CPU 核数、管理本地 G 队列(256 容量)、支持工作窃取 |
2. 关联辅助组件
- 全局 G 队列(GRQ):存储 P 本地队列溢出或阻塞恢复的 G,需加锁访问。
- 网络轮询器(Netpoller):基于 epoll/kqueue 管理网络 I/O 事件,唤醒阻塞 G。
- sysmon 线程:后台监控,负责抢占长任务、触发 GC、检测 I/O 就绪事件。
3. GMP 组件关系架构图(精简)
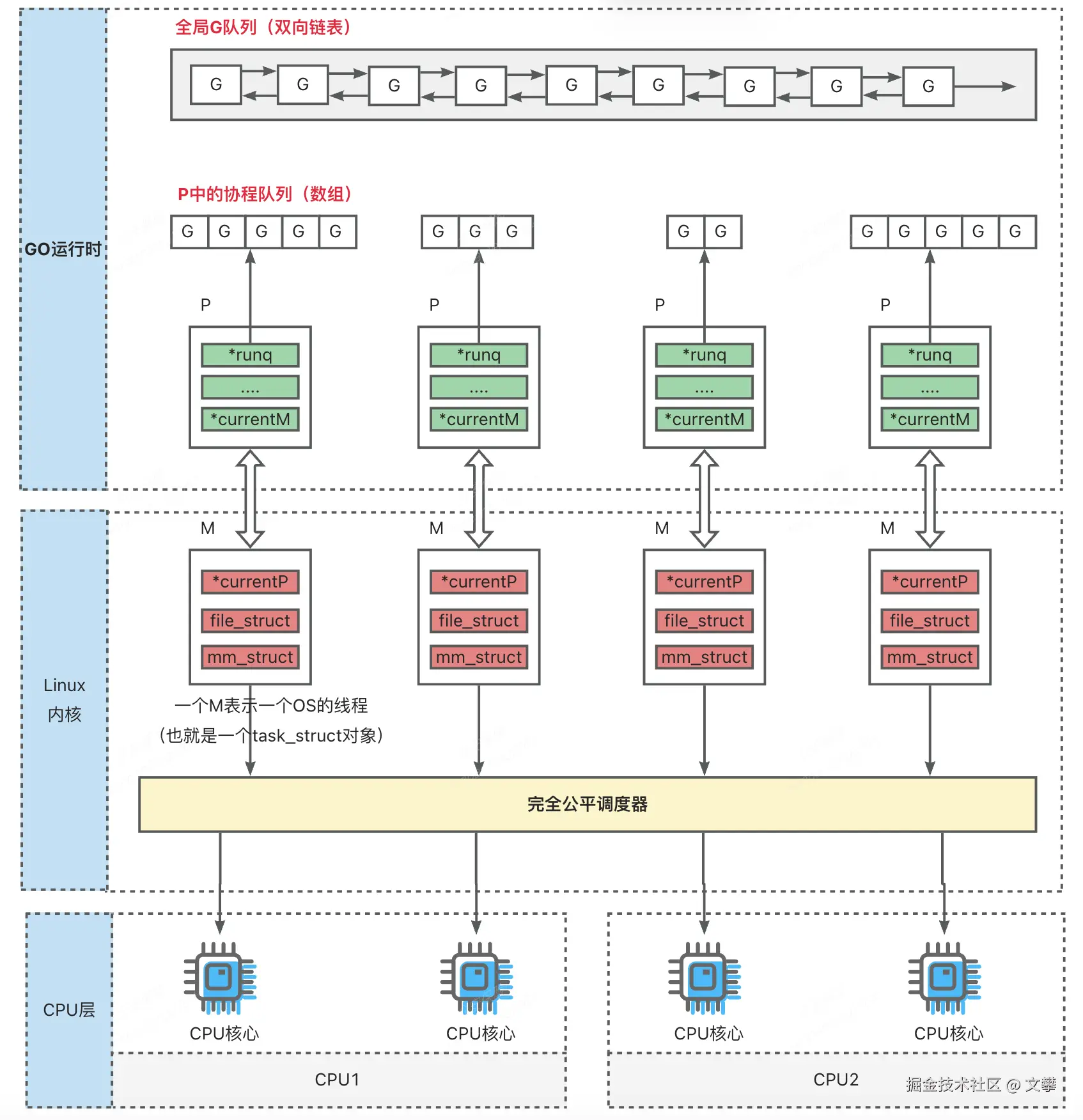
3.1 GMP 调度核心流程
结合精简流程图,GMP 调度的完整生命周期可拆解为 G 创建入队、M-P 绑定调度、G 阻塞与恢复、G 抢占与复用 四个核心阶段,各阶段 G、M、P 协作逻辑如下:
3.1.1 阶段1:Goroutine 创建与入队(G 就绪)
核心目标: 完成G的初始化与入队,为调度执行做准备。
- 用户触发: 执行go func(),向运行时发起G创建请求。
- G初始化: 复用或新建G结构体,初始化栈(默认2KB)、状态设为_Grunnable,绑定当前P。
- 入队操作: P的本地队列(LRQ)未满则直接入队;已满则迁移部分G至全局队列(GRQ)后入队。
- M唤醒: 若P无可用M,复用或新建M并绑定P,启动调度循环。
3.1.2 阶段2:M-P 绑定调度(G 执行)
核心目标: M绑定P后按优先级取G执行,核心原则:本地优先、全局兜底、空闲窃取。
- 启动调度: M绑定P后,通过runtime.schedule()进入调度循环。
- 优先取G: 每调度61次检查GRQ避免G饿死,否则从P的LRQ取G。
- 上下文切换:通过g0协程完成用户态切换,G状态设为_Grunning并执行。
- 工作窃取:无G可执行时,先取网络就绪G,再从其他P偷取一半G,仍无则M与P解绑空闲。
3.1.3 阶段3:G 阻塞与恢复(资源不闲置)
核心目标:处理G阻塞场景,通过M-P动态调整避免资源浪费,分为内核态与用户态两类阻塞。
系统调用阻塞(如文件 I/O、syscall)
- G执行系统调用,M进入内核阻塞态。
- 运行时解绑M与P,P绑定新M继续调度。
- 原M恢复后,优先绑定空闲P执行G,否则G入GRQ、M空闲。
用户态阻塞(如 channel、Mutex、time.Sleep)
- G因channel/锁等阻塞,状态设为_Gwaiting并入等待队列。
- M无需解绑P,直接调度LRQ队列中下一个G。
- 阻塞条件满足后,G设为_Grunnable入队,唤醒M执行。
3.1.4 阶段4:G 抢占与复用(避免饥饿)
核心目标: Go 1.14+通过抢占机制,解决长任务独占CPU问题,保障调度公平性。
- 抢占场景: G执行超10ms、函数调用时、触发GC时。
- 核心步骤: sysmon发送抢占信号→保存G上下文→G设为_Gpreempted入队→M调度新G,被抢占G等待复用。
3.1.5 阶段5:G 执行完成与复用
- G执行完毕,状态设为_Gdead。
- G的栈与结构体回收至空闲池,供新G复用以降低开销。
3.1.6 核心协作总结
GMP协作本质:P管资源、M做执行、G承任务,通过动态调度实现高效并发。
- P:调度中枢,靠LRQ和工作窃取实现负载均衡;
- M:执行载体,动态绑定P避免资源闲置;
- G:轻量任务单元,池化复用支撑百万级并发。
(二)核心数据结构:从源码看关键字段
1. 核心结构体简化(基于 Go 1.23.3)
1.1 Goroutine(g)
go
type g struct {
stack stack // 栈边界(支持动态扩容)
atomicstatus atomic.Uint32 // 状态(就绪/运行/阻塞等)
m *m // 绑定的 M
p *p // 关联的 P
sched gobuf // 上下文切换状态(sp/pc 指针)
}1.2 Machine(m)
go
type m struct {
g0 *g // 调度协程(负责上下文切换)
curg *g // 当前执行的 G
p puintptr // 绑定的 P
}1.3 Processor(p)
go
type p struct {
runqhead uint32 // 本地队列头部索引
runqtail uint32 // 本地队列尾部索引
runq [256]guintptr // 本地 G 队列(环形数组)
m *m // 绑定的 M
}(三)GMP 调度核心流程:精简关键步骤
1. 阶段1:Goroutine 创建与入队流程
2. 阶段2:M 调度 G 执行流程
3. 阶段3:G 阻塞与恢复流程
4. 阶段4:抢占式调度流程(Go 1.14+)
(四)、GMP 核心优化机制:支撑百万级并发
1. 机制1:工作窃取(负载均衡)
2. 机制2:内存隔离(MCache)
3. 机制3:轻量 G 与资源池化
- 轻量 G:初始栈 2KB(动态扩容)、用户态切换(开销仅 100ns)。
- 资源池化:M 池(复用 OS 线程)、G 池(回收 G 结构体,减少 GC 压力)。
(五)实践场景:协程池的使用决策
在GO语言中关于是否要像Java线程池那样搞个协程池,这个问题一直争论不休,其实这也是需要分情况而论的!
1. 无需使用协程池的场景
适用场景:Web 服务、I/O 密集型任务(HTTP 请求、数据库查询)。
- 核心原因:G 大部分时间阻塞,不占用 CPU,runtime 自动管理 M 数量。
2. 需要使用协程池的场景
2.1 场景1:资源受限(第三方 API/QPS 限制、数据库连接池)
2.2 场景2:CPU 密集型任务(图像处理、加密计算)
- 优化建议:协程池大小=
runtime.NumCPU()或runtime.NumCPU()*2。
(六)常见误区澄清
1. 误区1:4核服务器+4个P,M阻塞时所有G都会阻塞
一个4核的服务器,在GO中对应4个P,每个P绑定一个M,那么当每个M都在执行等待磁盘IO时,这个GO应用里的所有协程G都会被阻塞掉
正确结论:不会阻塞,P 与 M 动态绑定,runtime 自动创建新 M。
2. 误区2:Java 10个线程比 Go 4个M效率高
一个4核的服务器,在一个GO应用中有4个P,每个P绑定一个M,在同样的一个Java应用中我开启了10个线程,那么这种情况下这10个线程是不是就比GO应用的4个M的效率高了呢?
正确结论:Go 效率更高,线程数量≠执行效率。
核心原因:
- 4核 CPU 同一时间仅能执行 4 个任务,Java 多线程会导致内核频繁切换(开销高)。
- Go 协程切换是用户态(100ns),Java 线程切换是内核态(1μs),开销相差 10 倍。
(七)总结
GMP 模型的核心优势的是 M:N 映射 、用户态调度 、工作窃取 与 内存隔离,实现了"低成本高并发"与"多核高效利用"的平衡。关键要点如下
- G 是轻量任务载体,M 是执行载体,P 是调度中枢。
- 调度流程:创建入队→调度执行→阻塞恢复→抢占调度,全链路覆盖异常。
- 实践决策:I/O 密集型直接用
go func(),CPU 密集型或资源受限场景用协程池。 - Go 的并发模型之所以强大,是因为它具备如下特征,理解 GMP了,你就掌握了 Go 高并发的"灵魂"。
- 轻:协程 2KB,百万级无压力;
- 快:本地队列无锁,调度微秒级;
- 稳:线程阻塞自动替补,CPU 不闲;
- 智:网络透明异步,同步写法;
- 公:后台监控 + 抢占,防止饿死。