1. 系统架构与设计原理
Megatron-LM 概述: Megatron-LM 是 NVIDIA 开源的大规模语言模型训练框架,旨在将 Transformer 等模型扩展到数十亿到万亿参数规模。它基于 PyTorch 实现,利用 GPU 通信库 NCCL 实现高效分布式训练,并支持混合精度训练以提高性能。Megatron-LM 保持了常规 Transformer 模型架构,但在每一层内部引入显式的并行化设计,这是其核心特色之一。
核心设计理念: Megatron-LM 的关键在于 "层内模型并行" (intra-layer model parallelism)。具体做法是将 Transformer 每层内部的计算拆分到多个 GPU 上并行执行,从而突破单 GPU 内存限制。例如,对于 Transformer 中的多层感知机(MLP)部分,Megatron-LM将第一层全连接权重矩阵按列拆分到不同 GPU,上一个非线性(如 GeLU)可以在各 GPU 上独立计算,第二层全连接则按行拆分并在汇聚输出前进行一次全规约(all-reduce)通信。类似地,自注意力层的 Query/Key/Value 投影按注意力头拆分到各 GPU,每个 GPU 只计算部分头的注意力,随后再对注意力输出的投影结果按行划分并行,最后通过全规约合并结果。这种设计使得各 GPU 无需在非线性激活前就频繁同步,只需在层输出时进行少量全规约,大幅减少了跨设备通信开销。
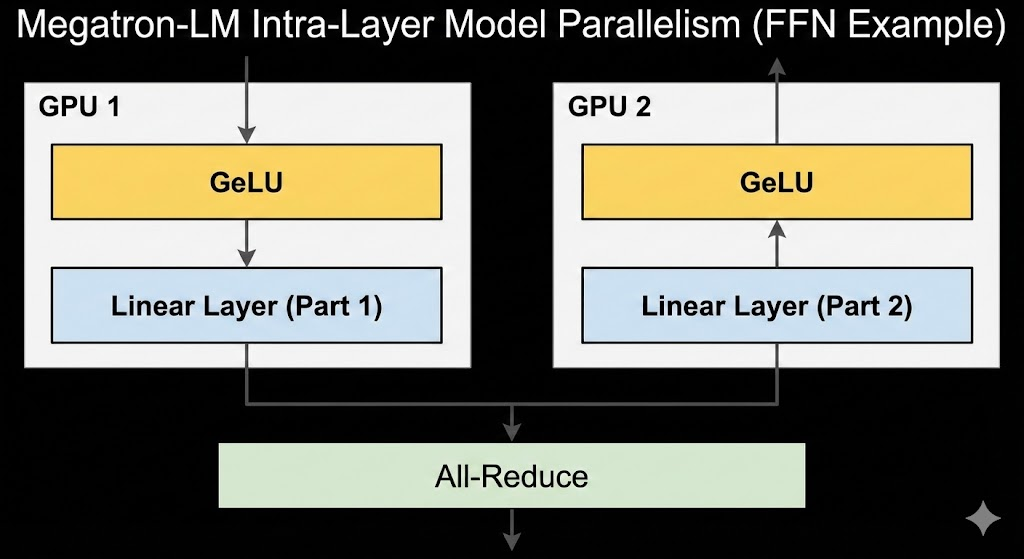
简单高效的实现: Megatron-LM 的实现尽量简单,不依赖特殊编译器或定制框架,仅通过在现有 PyTorch 的自动求导图中插入少量 NCCL 通信操作即可完成并行机制 。例如,它自定义了一个简易的 autograd 函数,在正向传播中只是身份映射,在反向传播中插入 all_reduce 来同步梯度。每个 Transformer 块的前向和反向只需各两次 all-reduce,同步梯度和激活值。正是靠这样的少量原语改动 ,Megatron-LM 实现了模型权重和中间激活的分片存储,大幅降低单卡内存占用,同时保持较高的计算效率 。这种方法无需重写模型,只需对标准实现做局部修改即可兼容,使开发者可以较低成本将模型扩展到多GPU训练。总体而言,Megatron-LM 以最大化 GPU 算力利用率、最小化通信瓶颈为设计原则,在系统层面进行了诸多优化以支持数百到上千GPU的分布式训练。
支持的模型和框架集成: Megatron-LM 最初用于训练 GPT-2/3 风格的自回归 Transformer 和 BERT 等模型,并取得了当时最大的模型规模和领先性。目前项目提供了 GPT、BERT、T5、LLaMA 等主流Transformer架构的预配置实现,方便用户按需修改配置进行训练。Megatron-LM 也与 NVIDIA 自家的 NeMo 框架集成,用于企业级的端到端大模型训练和部署;其底层优化(如并行策略、混合精度Kernel等)也演化为Megatron-Core 库,提供模块化接口供其他训练框架使用。通过这些演进,Megatron-LM 已成为 NVIDIA 生态中训练大模型的基石之一,同时保持开源社区的活跃,使研究者和开发者能够利用其最佳实践来探索更大规模模型。
2. 并行化策略
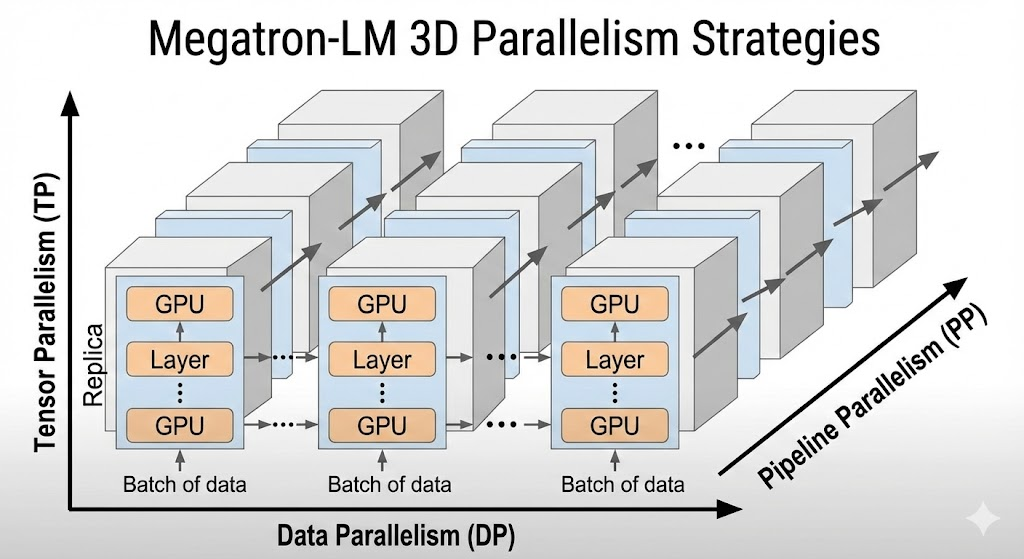
为支持大规模模型训练,Megatron-LM 综合采用了多种并行化策略,主要包括数据并行、张量并行和流水线并行,近期还引入了"序列并行"等新技术。在超大规模训练中,这些并行维度常被组合成所谓"3D 并行"方案。下面详细说明各策略的原理、实现方式及优劣:
-
数据并行(Data Parallelism, DP): 数据并行是深度学习中最经典的并行方法,即将批数据拆分 到多个设备,每个设备维护一份完整模型拷贝进行前向和反向计算,最后对梯度做全同步更新。Megatron-LM 也支持常规的数据并行,用于进一步扩大计算规模。然而,仅靠数据并行要求模型本身能放入单卡显存,无法训练超大模型。因此 Megatron-LM 将数据并行与模型并行相结合:例如在每台节点内先做模型分片,在多节点之间再做数据并行,同步不同数据分区的梯度。数据并行的优势在于实现简单、对现有训练代码改动小;但劣势是不解决模型太大无法放入单卡的问题,通信开销也随着节点数线性增长。
-
张量并行(Tensor Model Parallelism, TP): 这是 Megatron-LM 的核心并行策略,着眼于层内张量计算的并行 。具体方法如前文所述,将每层网络的权重矩阵按一定维度拆分到多卡:例如 Transformer 中,将全连接层的权重在输入维度(列方向)上拆为多块,每个 GPU 负责一块权重乘相应的输入子向量,独立计算非线性激活;然后再将输出层的权重在输出维度(行方向)拆分,各 GPU 基于各自激活计算部分输出,最后通过一次 all-reduce 得到完整输出 。自注意力的 Q/K/V 投影矩阵也可以按注意力头划分,每个 GPU 处理一部分注意力头,以减少计算依赖。张量并行的优点 是:可以将巨大的层计算负载拆给多个GPU承担,大幅降低单卡显存占用,并能接近线性提升计算吞吐;且每层只需在层末少量全规约,通信开销相对较低。在 NVIDIA DGX 集群测试中,8卡张量并行的弱扩展效率可达约79.6%(以1.2B参数模型单卡为基准),说明张量并行在高带宽互联上能高效扩展。局限性是:张量并行需要GPU之间高速互联(如NVLink/NVSwitch或InfiniBand),否则全规约同步可能成为瓶颈;另外由于模型拆分固定维度,适配不同模型结构需要一定代码改造。不过Megatron-LM已将这些并行算子封装好,用户只需按照框架提供的模型定义编写即可。
-
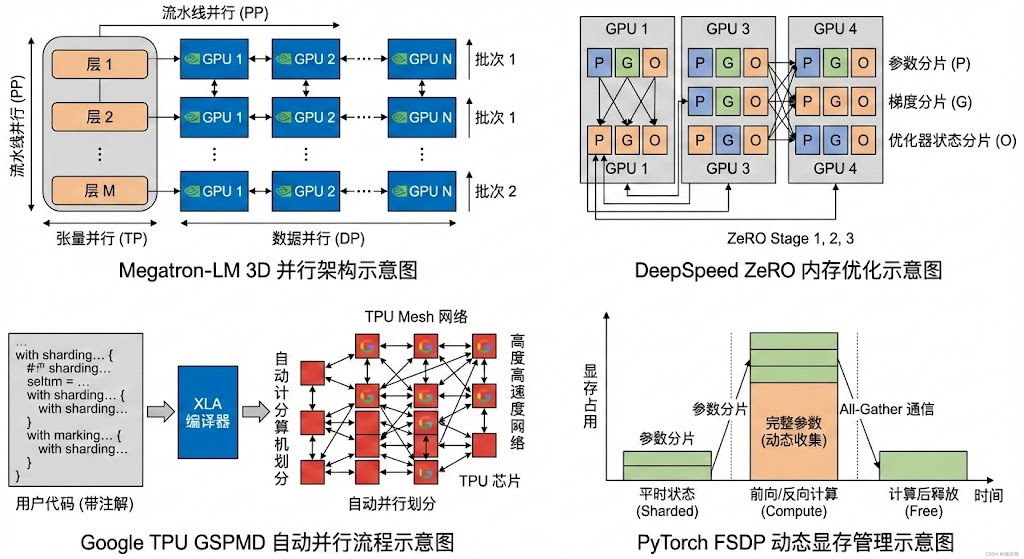
流水线并行(Pipeline Parallelism, PP): 为进一步扩展模型规模,Megatron-LM 还支持将不同层拆分到不同设备顺序执行 ,即流水线并行。在Pipeline并行中,各GPU不再持有模型的完整层次,而是划分为若干连续层的分段(stage) 。训练时通过分批次的微模型计算,实现类似工业流水线的并发:当第1段GPU处理批次1的第1层时,第2段GPU可以同时处理上一批次的第2层,以此类推,从而多批数据在管道中不同阶段并行流动。Megatron-LM 实现了基于常规**"批次微切分"的Pipeline并行,同时在SC21论文中提出了 "交织流水线并行 (Interleaved Pipeline)"的新调度方案。交织方案让同一GPU上交错存放多个分段的层,以减少纯Pipeline并行下各显卡上可能出现的"bubble(流水空泡)"等待时间。据报道,这种改进能够在不增加显存开销的情况下,将流水线并行的吞吐提升 超过10%。Pipeline并行的 优势是:当单个模型分片仍超出单卡显存时,可进一步跨设备拆分层数,实现 线性扩展模型深度**;其通信开销主要发生在相邻pipeline段之间传递激活值,相比全模型全同步要少。劣势在于:会引入额外的训练延迟(pipeline填充和冲刷阶段使有效批量增大),实现和调试复杂度较高;另外需要较大总批量才能填满流水线,否则会有硬件空闲。Megatron-LM 通过改进调度和混合并行,尽量缓解了这些问题,使Pipeline并行在千卡规模训练中表现出良好性能和可扩展性。
-
序列并行(Sequence Parallelism, SP): 序列并行是 Megatron-LM 在近年加入的新技术,主要解决在张量并行中仍未并行化的部分。例如 Transformer 中的 LayerNorm、Dropout 等操作以往是在每张卡对完整序列长度数据进行处理,没有并行拆分。序列并行的思想是在序列长度维度 对这些操作进行拆分:将一个长序列的token序列划分为多段,分别由不同GPU处理对应部分的 LayerNorm、Dropout 等,从而并行分摊这部分计算和内存 。其最大的收益在于 降低激活记忆开销 :以往张量并行下,每卡仍需存储完整序列的中间激活用于反向,而序列并行后每卡只保存自己负责的子序列激活,显存占用显著减少。这使得更多激活可以直接保存而不必重算,从而减少反向重计算开销 。NVIDIA 测试表明,结合序列并行和选择性激活重计算等手段,可使GPT-3 175B模型训练速度提升约30%。局限 是序列并行需要更复杂的分布式同步逻辑(比如跨卡拼接序列输出等),目前主要支持标准Transformer结构下的LayerNorm/Dropout部分,并集成在NeMo/Megatron最新版本中。总体而言,序列并行进一步完善了Megatron-LM的并行版图,消除了先前未并行的维度瓶颈,在极大模型训练中提供了额外的提速与省内存效果。
-
优化器状态分片(ZeRO 技术): 除了模型前向/反向计算的并行,超大模型训练还面临优化器状态(如梯度、动量、梯度平方等)占用巨量内存的问题。微软的 DeepSpeed 提出了 ZeRO(Zero Redundancy Optimizer)技术,按数据并行进程分摊这些状态以消除冗余。Megatron-LM 也吸收了类似思路,在其代码中实现了
DistributedOptimizer,可以按数据并行组将梯度和优化器状态进行分片存储。这相当于 ZeRO Stage-1/2 级别的优化器并行,能够大幅降低每块 GPU 的内存开销 。不过,Megatron-LM 原生的实现未对通信与计算充分重叠,导致超大规模下通信易成瓶颈。为此,阿里巴巴等开源了 Megatron-LLaMA 等改进版本,实现了类似 ZeRO-2 的重叠通信,使通信与反向计算几乎并行,从而在相同硬件上取得比原版更高的训练吞吐。总体来看,ZeRO 技术与 Megatron-LM 的张量并行/流水线并行是正交且互补的:前者解决大模型的优化存储问题,后者解决计算和激活内存问题。在实际超大模型训练中,两者常被结合使用(例如 5300 亿参数模型训练采用 Megatron-LM + DeepSpeed 混合方案)。
小结: Megatron-LM 通过3D 并行 架构将上述并行维度有机结合,实现了在数千 GPU 集群上的高效率扩展。例如,在 Microsoft 与 NVIDIA 合作训练的 MT-NLG 530B 模型中,采用了 8路张量并行 × 8路流水线并行 × 若干路数据并行 的3D方案,将Transformer块按层划分给不同流水段,每段内再用张量切分降低单卡负载,同时用数据并行扩展到成千上万GPU。这种多层次并行使模型的内存和计算需求同时降低 ,在保证每GPU高效利用的前提下实现空前规模的模型训练。当然,并行度的配置需要根据模型规模和集群拓扑精心选择,以平衡通信与计算。Megatron-LM 的论文和文档提供了这方面的实践指南,例如当模型参数总量一定时,增加流水段数会减小每段层数但增加通信链路,而增加张量并行度则减小每卡参数量但增加all-reduce开销,需要综合权衡来获得最佳吞吐。总体而言,Megatron-LM 为超大模型训练提供了经过验证的可扩展并行策略组合,其成功也带动了业界对于混合并行(模型并行 + 数据并行 + 流水并行)的广泛采用。
3. 与其他大型语言模型框架的对比
当前大模型训练领域,除了 Megatron-LM(NVIDIA)外,主要还有 Microsoft 的 DeepSpeed、Google TPU 上的 GSPMD 并行方案,以及 Meta 的 FairScale 等框架。它们在性能、可扩展性、灵活性和社区支持等方面各有特点。下面将 Megatron-LM 与这些框架进行比较:
-
DeepSpeed(微软):DeepSpeed 是微软开源的深度学习优化库,以 ZeRO 优化器技术 闻名,能够将模型的各部分状态在数据并行进程间分布存放,从而训练超大模型 而不会因显存不足而崩溃。在并行策略上,DeepSpeed 提供数据并行、流水线并行(Pipeline Engine)等,并通过 ZeRO Stage 1-3 实现梯度、参数、优化器状态全分片。它本身不直接实现张量并行,但可以与 Megatron-LM 等集成以形成3D并行方案。例如训练 MT-NLG 530B 模型时,使用了 DeepSpeed 的数据+流水线并行结合 Megatron 的张量切分,实现了高效的3D并行训练。性能与可扩展性 :DeepSpeed 已被用于 GPT-3 (1750亿参数) 等量级模型的训练,尤其在内存优化上效果显著,使得单机单卡也能加载超大模型进行调优。其官方报告显示,通过 ZeRO-Offload 等技术,DeepSpeed 可在单台40GB GPU上训练超过100亿参数模型,这在纯数据并行下是无法做到的。此外,在多机环境下,DeepSpeed 展现出良好的扩展效率。例如官方公布使用 512张 V100 GPU 成功训练了含1万亿参数的稠密Transformer模型(与 Megatron 合作实现)pytorch.org。灵活性与易用性 :DeepSpeed 作为 PyTorch 的一个插件,使用上非常简便。用户往往只需在训练脚本中加入几行 DeepSpeed 初始化配置代码或一个
deepspeed.initialize调用,再用 JSON 配置 ZeRO级别、并行度等即可。它对现有模型几乎零改动 即可加速,并兼容大多数 PyTorch Layer。另外 DeepSpeed 还提供自动调优、混合并行配置推荐等工具,降低了大模型并行的门槛。社区支持 :DeepSpeed 由微软持续维护,社区十分活跃(GitHub 上有上万星)。它与 HuggingFace Transformers 集成紧密,不少开源大模型项目(如 BLOOM、OPT等)都采用了DeepSpeed做并行优化。因此,DeepSpeed 在业界有广泛的采用度和支持,是大模型训练的主流选择之一。 -
TPU GSPMD(谷歌):GSPMD 全称 "General and Scalable Parallelization for ML via SPMD",是 Google 针对 TPU 平台提出的通用并行方案。它属于编译器级别的自动并行 :开发者使用 JAX/TF 2 等框架写模型,并通过在张量上添加 Sharding 注解,XLA 编译器会自动将计算图按照 SPMD (Single Program, Multiple Data) 模式划分到 TPU Pod 的不同加速器上执行。相比手工模型并行,GSPMD 的优势 在于:并行细粒度由编译器决定,能够针对不同模型结构自动找到高效的并行策略,省去了手动拆分层和通信同步的繁琐工作。它支持任意维度 的划分,包括数据批次维度、模型参数维度甚至专家模型的专家维度,具有很高的灵活性。Google 在 PaLM 540B 等超大模型训练中使用了基于 GSPMD 的并行(结合了数据+张量并行和一定深度的流水线)来让模型横跨多个 TPU设备。性能与扩展性 :TPU 的 GSPMD 并行可以扩展到整个 TPU Pod(如数千个 TPU核)。由于 XLA 编译器能够进行全局优化,GSPMD 通常能够充分利用 TPU 高速的环形互联,实现接近理想 的加速比。例如 Google 提到,通过 GSPMD+Pipeline 并行,某些"深而窄"的 Transformer 模型在 TPU Pod 上比单纯张量分片更高效。缺点是 XLA 编译时间会随模型和设备数急剧增加,且内存优化需要编译器自动平衡,不像手工划分那样完全可控。灵活性与易用性 :GSPMD 对使用者较为透明------只需在模型代码中用 JAX 的
with sharding等 API 指定如何在 mesh 上划分张量,剩下由系统完成。但这也意味着用户需要熟悉 XLA 的并行抽象,对于纯PyTorch用户来说有学习曲线。另外 GSPMD 主要用于 TPU/Google 云环境,在GPU上原生不支持(虽然有 PyTorch XLA SPMD 实验性支持)。社区支持 :GSPMD 论文和 JAX 社区在推进相关理念,但总体来说,它更多是 Google 内部基础设施的一部分,开源生态相对封闭。使用GSPMD通常意味着依赖JAX/Flax或TensorFlow生态。在需要极致性能且拥有TPU资源的情况下,GSPMD 是非常强大的并行方案,但对普通研究者来说其获取和使用门槛较高。 -
FairScale/FSDP(Meta): FairScale 是 Meta 开源的分布式训练库,定位类似 DeepSpeed,提供一系列并行和内存优化工具。它最著名的功能是 Fully Sharded Data Parallel (FSDP),即全分片数据并行。FSDP 与 ZeRO 类似,将每层的参数、梯度和优化器状态在多个GPU之间按块拆分,并在需要计算时动态收集,计算完立即释放。这种方法大幅降低了激活峰值内存,占用,从而使模型能够扩展到更大(PyTorch官方测试FSDP成功训练了1万亿参数模型,并且GPT-3 175B在AWS集群上每卡性能达到159 TFLOPS)。FairScale 还实现了 Pipeline 并行(称为 "FairScale Pipe"),可以将模型层按顺序切分,并通过schedule来流水执行训练,与 Megatron-LM 的流水并行类似。性能与扩展性:FSDP 在GPU集群上表现出接近线性扩展能力,并解决了GPU存储瓶颈。在不开启重计算的情况下,全分片可以比传统数据并行节省多达数倍显存,从而使用同样资源训练更大的模型或更大batch。Meta 在其 CV 、NLP 大模型训练中均采用了 FSDP 技术,并把它贡献回 PyTorch 主代码库。灵活性与易用性:FairScale/FSDP 作为 PyTorch 的扩展库,相对容易上手。特别地,PyTorch 1.11+ 已经将 FSDP 纳入
torch.distributed模块,应用时只需用 FSDP 类包装模型即可(甚至支持自动wrap超过阈值大小的层)。与 DeepSpeed 不同的是,FairScale/FSDP 没有统一的json配置,而是通过代码API来配置,这对研究人员在模型定义处做分片有一定自由度。缺点是,FSDP Stage 2/3 的实现相对复杂,对于梯度同步、参数重用场景需要仔细处理(如手工处理optimizer等)。社区支持:FairScale 由 Meta AI 推出,早期社区使用者主要是对标 DeepSpeed 的一些研究项目。但随着 PyTorch 官方接手 FSDP,原生支持让更多人使用这种技术,社区讨论和文档也逐步完善。目前FairScale库本身热度稍逊(因为核心功能已被Upstream),但其思路在社区得到广泛认可。总的来说,FairScale/FSDP 提供了无需模型并行也可扩展模型规模的方案,更偏重内存优化,与 Megatron-LM的张量并行属于不同侧重。
为了更加直观地比较,这里列出 Megatron-LM、DeepSpeed、TPU GSPMD、FairScale 在关键维度上的对比:
| 框架 | 并行特性与优化 | 性能与可扩展性 | 灵活性与易用性 | 社区支持 |
|---|---|---|---|---|
| Megatron-LM (NVIDIA) | 张量并行 + 流水线并行 + 数据并行(3D);有分布式优化器(类似ZeRO-2);支持序列并行等新技术 | 在 NVIDIA GPU 上验证至 万亿级模型训练; 8卡张量并行弱扩展效率~79.6%;1兆参数模型3072 GPU上达 52% 理论峰值效率 | 针对Transformer架构高度优化,需要按框架提供方式编写模型;提供现成脚本和配置,对底层硬件要求高(需要高速GPU互联) | NVIDIA 主导开源(GitHub★14k+),研究社区采用用于最前沿模型;与 NeMo、TensorRT 等深度集成 |
| DeepSpeed (微软) | 数据并行 + ZeRO全分片 + 流水线并行;支持混合并行配置(与Megatron结合实现张量并行);提供内存优化、自动调参等 | 成功支持 千亿到万亿参数模型训练(MT-NLG 530B 用其3D并行实现);显著降低内存使单机可训练百亿模型;扩展效率高,官方报告1T模型每卡达84TFLOPs | 易用性高:与 PyTorch 紧密结合,几行代码或配置即用;对现有模型改造极小;支持众多训练选项(混合精度、梯度压缩等) | 微软维护(GitHub★19k+),HuggingFace 等广泛整合,社区活跃度高,用户群覆盖学术和工业 |
| TPU GSPMD (谷歌) | XLA SPMD 编译器自动并行;按 mesh 维度自动张量切片;结合 Pipeline(如 Pathways)实现模型并行 | Google 使用其在 TPU Pod 上训练540B+模型;可充分利用 TPU 环路通信实现近线性加速;曾用于百万亿参数MoE模型并取得佳绩 | 需使用 JAX/TF2,在代码中注解张量分片,由编译器自动并行;对用户透明度较高但仅适用TPU,迁移成本高 | 谷歌内部为主,JAX 社区部分采用;开源生态有限(XLA SPMD 在PyTorch中实验支持);一般用户可及性低 |
| FairScale/FSDP (Meta) | 全分片数据并行(FSDP)+ Pipeline 并行;参数/梯度/优化器全部分片;支持ZeRO式 CPU/offload 等选项 | 大规模 GPU 上验证可训练1T参数模型,每卡性能达**~160TFLOPs**(175B模型,AWS A100);对通信带宽要求高但可弹性扩展(支持逐层异步通信) | 通过 PyTorch API 调用,支持自动或手动分片;需要对模型结构有一定包装,但已集成进PyTorch官方,使用方式统一;对硬件要求相对低(常规GPU集群即可) | Meta 提供(GitHub★3k+),核心功能并入 PyTorch 官方后使用更普及;社区讨论和文档逐渐丰富,企业和学界均有采用 |
(注:上述性能数据来自公开论文或官方博客,实际效率可能因硬件和模型而异。Megatron-LM 与 DeepSpeed 常协同使用,各擅所长。)
小结: 总的来说,Megatron-LM 相比其他框架更专注于利用GPU算力极限 来训练最大规模的模型,在NVIDIA硬件上表现卓越;DeepSpeed 则以通用性和内存优化 见长,使得大模型训练门槛降低,并在分布式优化和易用性上领先;TPU GSPMD 代表了编译器自动并行 的方向,在谷歌内部大模型上效果突出,但封闭性较强;FairScale(FSDP)提供了与ZeRO类似的开源替代方案 ,已经融入PyTorch生态,在需要纯数据并行扩展模型时非常有效。随着框架间互相融合(如Megatron与DeepSpeed结合、PyTorch集成FSDP等),未来大模型训练将更趋向于融合多种并行技术的综合方案,开发者可根据硬件平台和需求选择合适的工具组合。
4. 使用方法:训练、微调与部署
Megatron-LM 提供了一套完整的训练、微调和推理部署流程。典型使用涵盖以下几个步骤和注意事项:
环境与依赖: Megatron-LM 对硬件和软件环境有一定要求。建议使用具有大显存的 NVIDIA GPU (如 32GB V100、40GB A100 或以上)以及高速 GPU 互联(NVLink/NVSwitch 或 InfiniBand)的多GPU服务器或集群,尤其在训练百亿级以上模型时。这是因为模型并行和流水线并行需要 GPUs 之间频繁通信,高带宽互联能避免成为瓶颈。在软件方面,需要安装相应版本的 PyTorch、CUDA、NCCL 等(Megatron-LM 通常追随最新稳定版 PyTorch 和 NVIDIA 算法库进行优化)。NVIDIA 官方也提供了预构建的 Docker 镜像,包含 Megatron 所需环境,可直接使用以避免依赖问题。
代码获取与安装: 用户可以从 GitHub 获取 Megatron-LM 源代码。安装方式包括基于提供的 Dockerfile 构建容器、使用 pip install 安装(需要CUDA对齐的编译)或源码安装github.com。由于 Megatron-LM 内含自定义 CUDA 内核(如 fused kernel 等)和 Apex AMP 支持,使用官方容器或按照官方步骤编译能保证性能最优。安装完毕后,仓库目录下包含 megatron/ 核心库和 examples/ 示例等。在使用前需确保多机环境下 NCCL 可正常通信(比如设置NCCL_P2P_LEVEL等变量)以及主机之间免密SSH已配置好(用于PyTorch分布式启动)。
配置文件与参数: Megatron-LM 没有采用单一的配置文件,而是通过命令行参数 或 JSON 字符串来配置模型和训练选项。常见配置包括:模型结构参数(如隐藏层维度、层数、注意力头数、词表大小等)、并行规模参数(如 --tensor-model-parallel-size 张量并行度,--pipeline-model-parallel-size 流水线并行度,数据并行进程由启动脚本 -nproc_per_node 等决定)、训练超参数(batch大小、学习率、优化器、训练步数等)以及 I/O 参数(数据集路径、日志路径、检查点路径等)。Megatron-LM 提供了一些现成的配置脚本和JSON模版,例如 examples/gpt3_13B.sh 之类,其中包含针对13B GPT-3模型的参数设置。用户可在此基础上修改相应尺寸和路径。配置的一致性很重要:特别是并行度配置需与实际启动的GPU拓扑匹配 ,否则程序将报错或性能不佳。例如使用8张GPU且希望每张GPU承担模型的不同部分,则可设置 --tensor-model-parallel-size 8 --pipeline-model-parallel-size 1(表示纯张量并行8路);如果是8 GPU两两分担一个层的张量并行,并串行4段流水,则配置 --tensor-model-parallel-size 2 --pipeline-model-parallel-size 4,总GPU数 2×4=8。Megatron-LM 的文档提供了详细的参数说明和不同模型规模下的推荐配置。
数据准备: 在运行训练脚本前,需要准备好训练数据集 并进行Megatron-LM格式的预处理。Megatron-LM 通常要求将文本语料转换为带字节对编码(BPE)的Id序列,并打包成二进制文件 以提高读取效率。项目提供了 tools/preprocess_data.py 脚本,可将一个或多个原始文本文件分块处理成 .bin 和对应的 .idx 索引文件。这一步可以指定词表(如 GPT-2 BPE 字典)和分片大小等。对于上下游任务微调的数据,需转换成对应格式(如GPT类模型的自回归格式或BERT的句子分类格式),Megatron-LM 也提供了一些示例转化脚本。数据准备好后,在运行训练时通过 --data-path 指定数据文件前缀以及 --vocab-file --merge-file 指定词表。如果数据集很大,建议将数据文件存放在高速并行文件系统上,或使用分布式数据加载,以免I/O成为瓶颈。
启动训练: Megatron-LM 使用 PyTorch 分布式启动训练作业。在单机多卡情况下,可使用 PyTorch 自带的 torch.distributed.launch(PyTorch<1.9)或 torchrun(1.9+)工具。例如在一台8卡机器上启动GPT预训练:
torchrun --nproc_per_node=8 pretrain_gpt.py \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 64 --hidden-size 3072
--num-attention-heads 32 \ ... <其他参数>在多机环境下,需要使用主节点IP和端口等初始化环境,或者通过 MPI/Srun 等方式启动。Megatron-LM 也提供了 scripts/ 目录下的示例集群提交脚本,以及如何结合 Slurm 等调度系统运行的说明。训练过程中,日志会输出每步的loss、学习率,以及 throughput 等信息。Megatron-LM 针对长时间训练提供了断点续训 功能:可指定 --save 路径定期保存模型和优化器状态快照,用 --load 恢复继续训练。此外还支持模型 Exponential Moving Average (EMA)、LR调度等高级功能,可按需启用。
微调与下游任务: 利用 Megatron-LM 预训练完的大模型,用户可以执行微调(finetune)或直接进行零/少样本推理。微调时的流程与预训练类似,但通常需要加载预训练好的checkpoint,然后在较小的数据集上继续训练若干步。Megatron-LM 的 examples 中有下游任务微调脚本(例如分类任务、问答任务等)。这些脚本会加载主干模型权重,再添加适配头(如分类层),然后用较小的 batch 和更低的学习率训练。由于 Megatron 主要面向超大模型,在微调阶段也要注意显存占用,如必要可以降低并行度或者使用梯度累积来减少每步batch大小。
值得注意的是,Megatron-LM 生成的模型权重与 HuggingFace 等框架格式不同。为方便生态融合,Megatron-LM 提供了 权重转换工具,可以将 Megatron-LM 的checkpoint转换为 HuggingFace的模型格式,或相反。Megatron-LLaMA 等衍生项目已实现了与 HuggingFace 的双向转换接口,降低了使用 Megatron 训练模型后在其他框架下部署的难度。
推理和部署: 训练完成后,大模型的推理同样需要高性能支持。Megatron-LM 提供了专门的 Inference 模块和脚本,用于高效地进行大模型推理。其 megatron/inference/ 目录下实现了一个高吞吐的推理服务器 ,支持批量文本生成等操作。在多GPU环境下,Megatron-LM 推理也可使用张量并行将模型拆分到多卡,以加载超过单卡显存的权重。为进一步加速推理,Megatron-LM 整合了 NVIDIA TensorRT 和 TensorRT-LLM 优化:可以将模型导出为 ONNX 再交由 TensorRT 进行图优化和半精度/八比特量化,加速GPU上的推断。最新的 Megatron-Core 还支持一键将模型导出到 TensorRT-LLM 引擎并结合 Triton Inference Server 部署,从而实现大模型的高效推理服务。例如,NVIDIA 宣布基于 Megatron 和 TensorRT-LLM,可以在多GPU上对数百亿参数的Transformer实现接近实时的文本生成服务。这对于需要在线服务大模型的场景(如对话系统)非常重要。用户在部署时,可以选择直接用 Megatron-LM 提供的 inference server(需要一定配置流程),也可以将模型权重转换后使用 HuggingFace + DeepSpeed Runtime 或 TensorRT 引擎配合 Triton 部署。NVIDIA NeMo 框架也封装了训练到部署的流程,Megatron-LM 训练的模型可以无缝接入 NeMo 的云原生部署方案,如通过 Helm 部署 Triton 服务等。
典型使用示例: 综上,一个典型的 Megatron-LM 使用流程如下:
-
准备数据和环境: 确认集群GPU资源和互联拓扑,安装 Megatron-LM 及依赖。用提供的脚本将训练语料预处理为二进制格式,并准备好词表文件。
-
配置并发参数: 根据模型大小和硬件情况确定并行策略(TP、PP、DP 的拆分),设置相应命令行参数。调整批大小、优化器等超参数,填写到脚本或配置JSON中。
-
启动训练作业: 使用 torchrun/mpirun 等在多GPU/多节点上启动
pretrain_xxx.py脚本,监控日志中吞吐和loss,适当调整学习率策略保证收敛稳定。 -
保存与评估: 定期保存 checkpoints。训练完毕后,可加载模型对验证集进行评估,或抽取若干下游任务做零样本推断评测模型能力。
-
微调(可选): 如需在特定任务上微调,在加载预训练权重的基础上,运行
finetune_xxx.py脚本,使用小学习率和早停策略在任务数据上训练,并监控验证集性能。 -
部署: 将最终模型权重转换为需要的格式,选择合适的推理方案部署。如果追求极致性能,使用 TensorRT 优化并在 Triton 中多实例并行推理;如注重易开发,可用 HuggingFace + DeepSpeed-Inference pipeline。在部署前可能还需进一步蒸馏或压缩模型以满足延迟要求。
总之,Megatron-LM 提供了从训练到部署的完整工具链,但由于大模型训练本身的复杂性,在使用时需要谨慎设置参数、充分测试小规模配置,再扩展到大规模运行。良好的硬件支持(高速网络存储、可靠的多节点作业管理)也对顺利训练至关重要。
5. 性能指标与论文解读
Megatron-LM 自2019年发布以来,在多篇重要论文中展示了其卓越的性能和规模突破。以下梳理关键论文及报告的指标:
-
2019 年 -- Megatron-LM 初始论文(Shoeybi 等人) :这一工作首次提出了 Megatron-LM 的层内模型并行技术,当时训练了8.3 亿 参数的 GPT-2 类语言模型和3.9 亿 参数的 BERT 类模型,规模远超同期公开模型。在512张 NVIDIA V100 GPU(每卡32GB)上,使用8路模型并行和64路数据并行成功让8.3B模型收敛。性能方面,该模型在 512 GPU 上实现了 15.1 PetaFLOPs 的持续计算吞吐,相当于单卡39 TeraFLOPs基准的 76% 并行效率 。这是当时少有的在大规模GPU集群上能保持如此高效率的训练案例,证明了Megatron并行策略的有效性。准确率上,8.3B GPT-2 模型取得了 WikiText-103 困惑度 10.8 (此前SOTA为15.8)以及 LAMBADA完形填空 66.5% 准确率(高于此前SOTA的63.2%)。3.9B的BERT模型在RACE阅读理解挑战上达到 90.9% 准确率,亦刷新当时纪录。有趣的是,论文指出为了成功训练更大的BERT,需对架构做细微修改(如将 LayerNorm 从残差后移至Attention/FFN之前),否则模型增大后反而精度下降。这一经验后来被广泛采纳到RoBERTa等模型中。2019年的Megatron-LM工作奠定了大模型"参数规模提升=性能提升"的基础,也证明了通过模型并行可以在有限算力时间内训练比原先大一两个数量级的模型,为之后的GPT-3出现铺平了道路。
-
2021 年 -- SC21 高性能计算大会论文(Narayanan 等人) :这篇论文题为"在GPU集群上高效训练超大语言模型",详细探讨了Megatron-LM在千卡规模 集群上的扩展性和改进。作者将并行维度拓展为3个(数据+张量+流水线),并提出了前述交织流水线并行 调度,使大量流水段下的硬件利用率进一步提升。论文中最引人瞩目的是其训练了一个1 万亿参数 的 Transformer 模型(被称为 "MT-NLG 1T")的性能展示:在包含 3072 张 GPU (当时可能是NVIDIA A100)的集群上,实现了总计算吞吐 502 PFLOP/s ,折合每卡约 0.163 TFLOP/s,而每卡达到其理论峰值的 52% 。要知道,如此规模下通信开销和负载不平衡极易拉低效率,而他们仍保持过半峰值,体现了Megatron并行架构的卓越设计。论文还系统分析了不同并行配置的权衡,例如给定GPU数量下,采用更多流水线段还是更多张量并行度对吞吐的影响,给出了经验之谈。这一工作证明 Megatron-LM 能扩展到千级GPU、万亿参数级别,同时也优化了内存占用(通过梯度异步交换等技术,使1T模型能在有限显存中运行)。值得注意的是,这时Megatron-LM依然使用纯FP16训练(配合动态loss scaling),尚未使用更稳健的BF16;即便如此,1T模型仍成功收敛,显示软件和硬件的协同进步。SC21论文为学术界了解工业界训练超大模型的实践提供了宝贵数据,其提出的交织流水线策略后来也被PyTorch等框架借鉴,实现更高并行效率。
-
2022 年 -- Megatron-Turing NLG 530B (Smith 等人, Microsoft & NVIDIA) :"Megatron-Turing NLG (MT-NLG) 5300亿参数模型"是微软与英伟达合作完成的当时全球最大的单体Transformer语言模型。相关论文发表于2022年初。该项目结合了微软DeepSpeed和NVIDIA Megatron-LM的优势,搭建了一个高效的3D并行训练系统 。具体而言,使用 DeepSpeed 实现 数据并行 + 流水线并行 ,以及 ZeRO 技术优化内存;利用 Megatron-LM 实现 张量切分并行 ,三者结合训练530B模型。MT-NLG 530B 模型的规模是 GPT-3 (175B) 的3倍之多,训练难度极大。最终训练在 NVIDIA 自家的 Selene 超级计算机上完成,使用了 560 台 DGX A100节点(4480 张 A100 80GB GPU) ,混合精度 BFloat16 计算峰值高达 1.4 EFLOP/s 。尽管没有公开具体训练时长,据推测约在数十天级别完成了千亿步级别的训练。MT-NLG 在性能上取得了多项新纪录:在零样本、少样本学习任务上全面超越以往模型。例如在 PiQA 常识问答、多项选择、翻译等基准上刷新SOTA。论文中特别分析了训练数据 对超大模型的影响,精心构建了一个高质量、大规模的语料库(270GB以上文本)。同时报告了训练中遇到的挑战,如不稳定的loss尖峰 (通过调整优化器和梯度norm解决)等。这次合作标志着业界顶尖团队在大模型训练上的合力,也说明仅靠单一框架很难包揽所有方面,于是出现了框架融合的新模式。MT-NLG 530B 作为当时参数最多的Transformer模型,展示了Megatron-LM框架在工业规模训练中的实用性和稳定性,也证明了3D并行栈的可行性。其成功经验后来被应用到更多模型中,也推动了像 BLOOM 176B 等开源大模型的诞生。
-
2022--2023 年 -- 新技术与衍生工作: 此阶段没有更大的单模型出现,但Megatron团队在优化方面持续发力。NVIDIA 在2022年中发布技术博客,宣布通过 Sequence Parallelism (SP) 和 Selective Activation Recomputation (SAR) 等技术,将 175B 级模型训练速度提升了30%。这些优化已整合进 Megatron-LM / NeMo 中,使得训练 1TB模型在1024卡上只需24天(3000亿 token)。同年,Megatron-LM 也开始支持稀疏MoE专家并行 (即多个专家模型,结合DeepSpeed Mixture of Experts),在参数规模上突破了万亿参数(虽然稠密计算量未同比例增长)。2023年,NVIDIA 将 Megatron-LM 的核心功能升级为模块化的 Megatron-Core 库,并在GPT-4等多模态模型探索中使用了一些Megatron提供的并行能力(如Context Parallel等)。同时,社区也出现了如 Megatron-DeepSpeed 项目,将两者结合为开箱即用方案,以及 Colossal-AI 等国内团队开发的框架,借鉴Megatron思想提供一体化的大模型训练方案。可以说,Megatron-LM 相关论文和技术报告在这几年的飞速发展直接推动并引领了"大模型时代"的到来,其提出的许多技术指标如今已成为行业标准参考,如PFLOPS/GPU利用率 、并行扩展效率 、zero-shot基准成绩等。
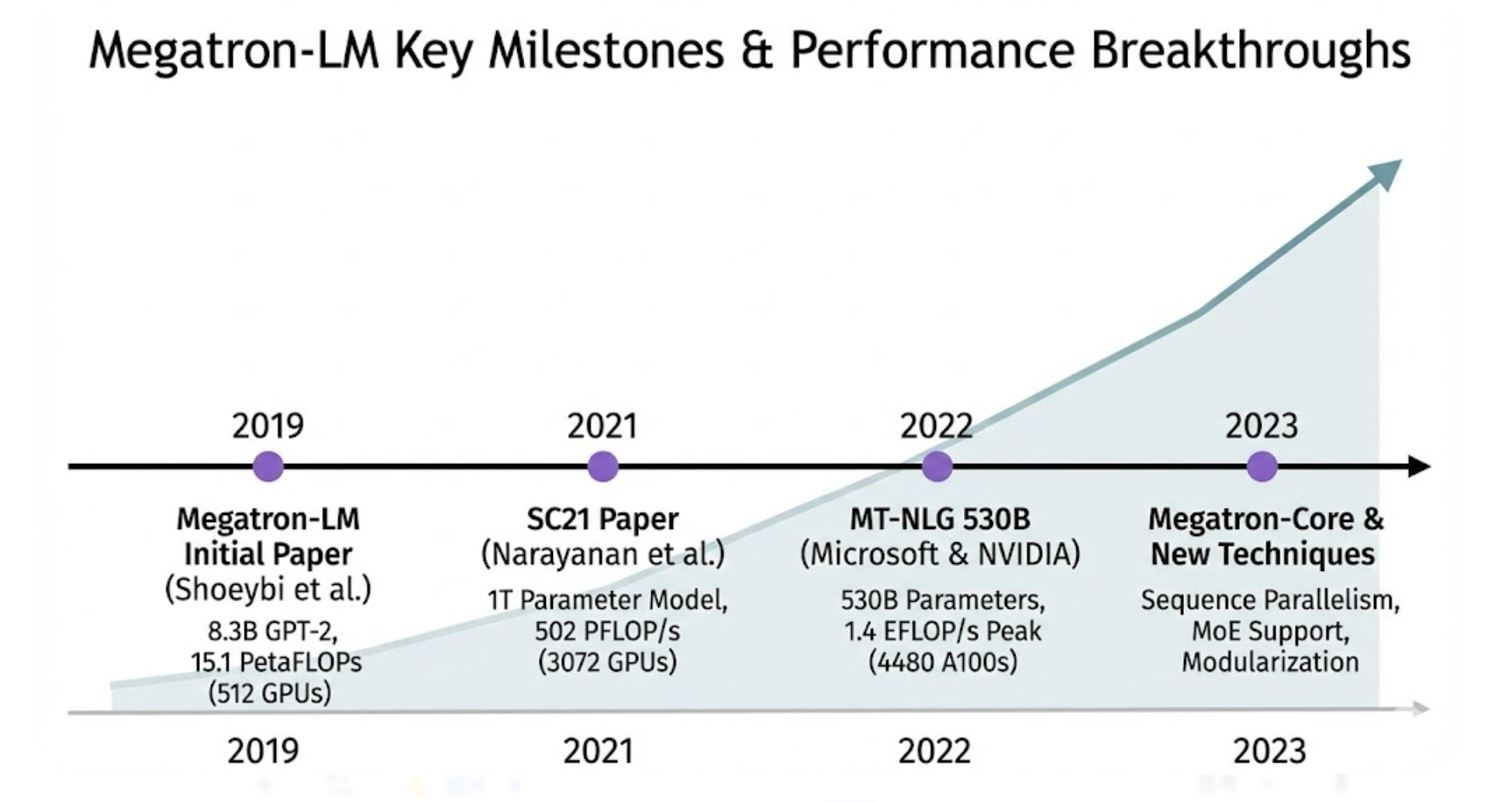
综上,Megatron-LM 的关键论文记录了从数亿参数到数千亿乃至万亿参数的跨越式发展过程。从最初验证模型并行有效性并达成SOTA成绩、到后来突破训练硬件极限实现1T模型、再到业界协作训练出迄今参数最多的单模型。这些成果奠定了现代大语言模型的基础,也为后续更大模型(如Google PaLM 540B、OpenAI GPT-4等)提供了宝贵经验教训。例如,如何构建高质量海量数据、如何在超大并行下保持稳定收敛、如何评估大模型的新能力等,都可以在 Megatron-LM 的论文中找到答案。Megatron-LM 本身也在演进,新发布的技术往往先在报告中给出理论和实验依据,再集成到开源代码中,使社区受益。
6. 项目发展历程与开源情况
Megatron-LM 项目自推出以来经历了不断的版本演进和生态融合,以下是其发展历程和开源现状:
-
版本演进: Megatron-LM 由 NVIDIA Applied Deep Learning Research 团队开发,最初于 2019 年 8 月 在其ADLR博客上公布原型和8.3B模型实验。随后在 2019年底至2020年间,作者将代码开源到 GitHub(NVIDIA/Megatron-LM),并不断更新以支持更大的模型和新功能。2020-2021年 ,项目加入了 Pipeline 并行、改进了可扩展性,并配合SC21论文做了重大升级。这段时间Megatron版本号从1提升到2,支持了1T模型训练。2022年 ,NVIDIA 和 Microsoft 合作将 Megatron-LM 与 DeepSpeed 深度整合,推出用于530B训练的混合代码(未单独开源,但社区有Megatron-DeepSpeed作为参考)。与此同时,NVIDIA 在其 AI 算法套件 NeMo 中封装了 "Megatron-LM Service",方便企业用户使用。同年下半年,Megatron-LM 引入了序列并行、Selective activation recompute 等实验特性,版本进入3.x阶段,有时也称 Megatron-LM 3D并行 。2023年 ,NVIDIA宣布将 Megatron-LM 核心功能模块化,推出 Megatron-Core 库(作为 Megatron-LM 仓库的一部分)。Megatron-Core 提供了Composable的Transformer模块、并行策略API等,旨在让开发者更灵活地将其集成进自定义训练流程。Megatron-LM 仓库则同时保留了 Reference 实现(包含完整训练脚本、现成模型配置)和 Core库。截至 2025年,Megatron-LM/Megatron-Core 仍在活跃开发,最新 Roadmap 显示正在研究如多数据中心并行、FP8 混合精度、下一代 MoE 等前沿特性。这一系列演进体现了 Megatron 项目从研究原型 逐步走向生产级工具的转变。
-
社区维护与影响: Megatron-LM 采用开源方式发布,最初代码以 MIT/Apache 协议开放,鼓励社区交流和贡献。目前其 GitHub 仓库有超过 14k 星标 ,有众多使用者提出 issue 和 pull request。不过,由于 Megatron-LM 针对的领域(超大模型训练)门槛较高,大多数贡献仍由 NVIDIA 官方团队完成,社区提交多集中在适配新版本PyTorch、修复bug等方面。Megatron-LM 的出现对开源大模型运动有积极影响:EleutherAI 在 2020-2021 年复现 GPT-3 时,参考了 Megatron-LM 的并行实现思想,初版GPT-Neo就是模型并行的。此后如 BigScience(BLOOM模型组织)等也借鉴了Megatron的经验。Megatron-LM 也成为学术基准:不少关于分布式训练的研究会在实验中对比Megatron,以证明自己方法在效率或内存上的改进。总体而言,Megatron-LM 通过开源拉近了研究与工业之间的距离,使得学术界可以基于类似框架探索更大模型。NVIDIA 官方还在 GTC 等大会上多次介绍 Megatron-LM 的技术,进一步扩大了其在社区的影响力。
-
与 NVIDIA 生态集成: 作为 NVIDIA 出品的工具,Megatron-LM 与自家硬软件生态深度结合。例如:NVIDIA NeMo 框架中包含 Megatron-LM 的训练管线,用户可通过NeMo更高层的接口调用 Megatron 的并行能力。在推理方面,Megatron-LM 与 TensorRT 引擎结合,提供 Transformer 特化的Kernel(如FlashAttention、INT8/FP8支持),帮助大幅加速推理吞吐。NVIDIA 于2023年推出的 TensorRT-LLM 方案,就是在 Megatron-Core 基础上扩展,允许将大模型切分到多个 GPU 上并行推理,支持流式输出等特性,满足实际部署需求。据报道,使用 TensorRT-LLM,可将 175B 模型在 8×A100 上推理延迟降低到数百毫秒量级,这对于实时应用是很重要的改进。此外,Megatron-LM 训练得到的模型可方便地接入 Triton Inference Server 进行服务部署。通过 Triton,用户可以将经过 TensorRT 优化的 Megatron 模型作为一种后端加载,并充分利用批处理、动态路由等 Triton 功能,实现大模型的高并发推理服务。NVIDIA 也提供了 Triton + FasterTransformer 的例子,用于Serving 530B这样的超大模型。可以说,Megatron-LM 在训练端和推理端都成为 NVIDIA AI 平台的一部分:训练端与 GPU 调度和监控工具(如 NVML、Nemo Navigator)集成,推理端与 TensorRT/Triton 集成。这种端到端打通使得使用 Megatron-LM 训练的大模型可以较容易地投入生产环境,而不必担心转换兼容性问题。
-
开源衍生项目: Megatron-LM 的成功也催生了一些衍生项目和社区版优化。例如阿里巴巴开源的 Megatron-LLaMA 框架,整合 Megatron-LM 并针对 LLaMA 模型做了优化和成本降低。其引入更高效的通信-计算重叠技术,使相同硬件上训练13B模型比基于DeepSpeed的实现快约22% ,成本节省上千美元。又如 Microsoft DeepSpeed 与 Harmony 结合的 Megatron-DeepSpeed ,封装了配置流程,方便一键启动3D并行训练。这些衍生项目表明业界对 Megatron-LM 框架的认可,并希望进一步改进其不足之处(比如原生通信重叠、IO 加载等)。值得一提的是,Facebook 的 FairSeq 和后来 huggingface 的 Trainer 也分别实现了与 Megatron 类似的模型并行选项,不过没有Megatron那么完整的3D方案。Colossal-AI 等国内团队则提供了一个统一接口调用张量并行和ZeRO并行的方法,功能上与Megatron+DeepSpeed组合类似。这些开源繁荣的背后,是 Megatron-LM 树立的一个高效并行范式在发挥作用:人们不再质疑"大模型能否训练",而是思考"如何训练得更快、更省"。Megatron-LM 在这场技术变革中无疑扮演了先驱角色。
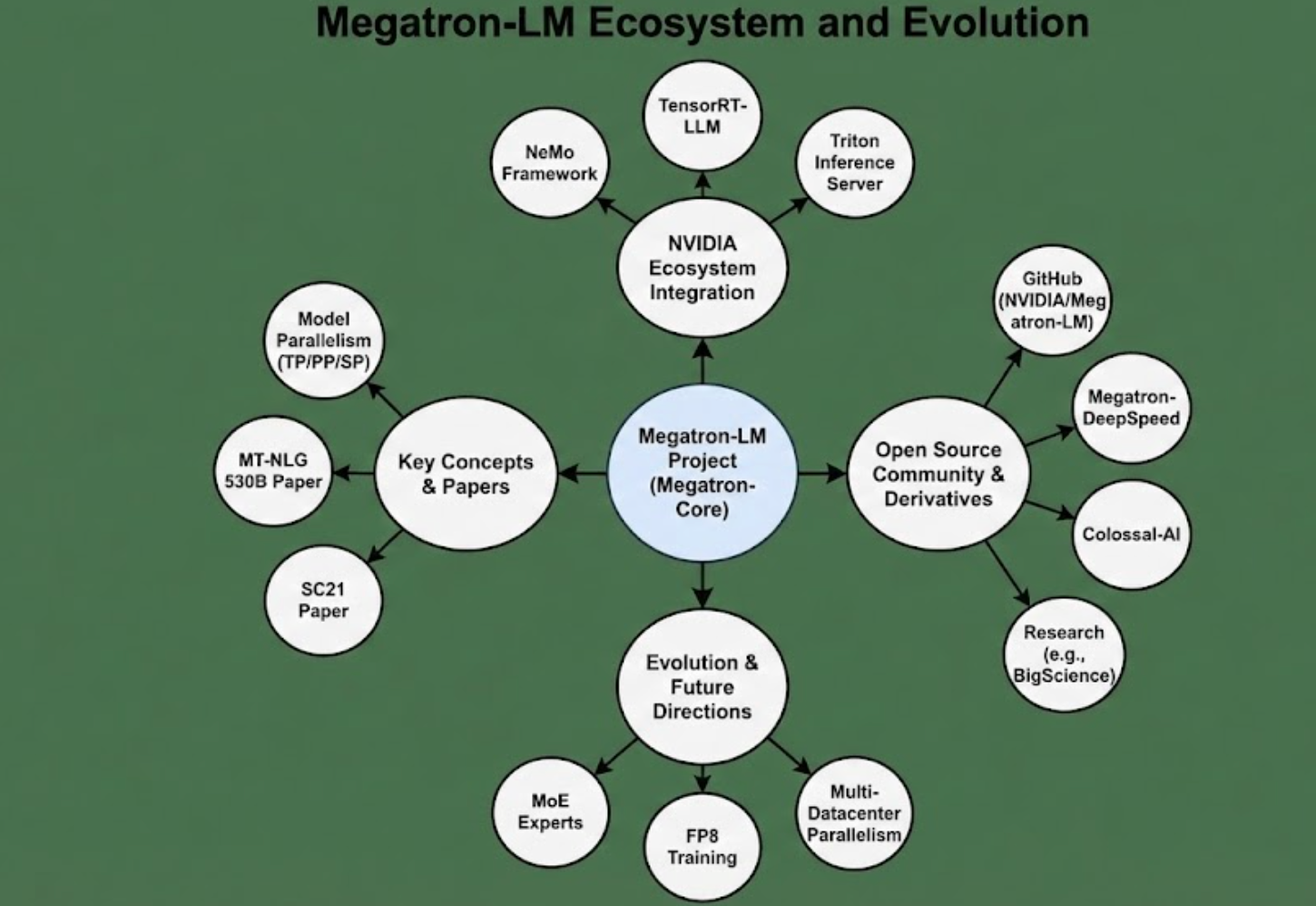
总结: Megatron-LM 从诞生到现在,已经成长为一个涵盖训练算法、工程实现到部署支持 的完备大模型框架。在 NVIDIA 的持续投入和开源社区的参与下,Megatron-LM 不断吸纳最新的研究成果(如优化器、混合精度、新并行算法),保持行业领先。同时,它与其他框架的竞争合作也推动了整个生态的进步------当下训练超大语言模型,往往是 Megatron-LM、DeepSpeed、FSDP、XLA 等"你中有我"的综合方案,共同克服计算和内存壁垒。站在2025年的视角,Megatron-LM 已不仅仅是一个代码库,而代表着大规模AI模型训练的经验结晶和标准基线。它的架构理念将继续影响未来的框架和硬件设计;而其开源精神也将帮助更多团队打造属于自己的"巨型模型"。
参考资料
Introducing PyTorch Fully Sharded Data Parallel (FSDP) API
https://github.com/RapidAI/Megatron-LLaMA
https://github.com/NVIDIA/Megatron-LM
NVIDIA AI Platform Delivers Big Gains for Large Language Models
State-of-the-Art Language Modeling Using Megatron on the NVIDIA A100 GPU
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism