在前文中,我们讲述了pretrain函数的执行流程,其首要步骤是megatron分组的初始化与环境的配置。本文将深入initialize_megatron函数源码,剖析其初始化分布式训练环境的内部机制。
注:在此假设读者具备3D并行相关知识
一. initialize_megatron函数的上下文调用关系(initialize.py)
在Megatron-LM中,initialize.py文件中的initialize_megatron函数是分布式训练环境的初始化核心。该函数由trainning.py的pretrain函数调用,是整个pretrain流程中的第一个核心步骤,负责配置3D并行的环境和分组信息。

1. initialize_megatron函数源码
initialize_megatron函数的核心代码段如下:

需要注意的是,尽管initialize_megatron函数还涵盖了设置全局参数、分词器构建、自动恢复配置、TensorBoard日志记录、计时器设置以及依赖编译等辅助功能,但这些功能在初始化流程中虽具重要性,却非其核心职责所在。其核心功能聚焦于上述代码段所描述的分布式与模型并行初始化流程,而该流程主要是通过finish_mpu_init中调用的_initialize_distributed函数实现的,如下图。
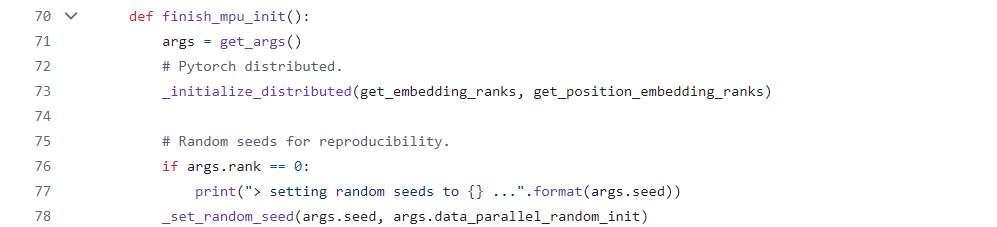
2. _initialize_distributed
_initialize_distributed函数主要有两个作用:
a. 通过调用torch.distributed.init_process_group()初始化分布式环境,该函数设置了分布式训练所需的基本通信环境,包括进程间的通信后端、worldsize(参与训练的进程总数)、每个进程的rank号等。默认情况下,它会创建一个全局的进程组,这个进程组定义了哪些进程可以相互通信,也可以根据需要创建更多的进程组以支持更复杂的通信模式。
在使用 init_process_group() 初始化分布式环境之后,我们可以使用PyTorch提供的分布式通信和同步 API 来实现跨进程的通信和数据同步。这包括使用dist.all_reduce() 来聚合梯度、dist.barrier() 同步所有进程的执行点等。
请注意,在调用init_process_group()之前,需要确保已经正确设置了所有相关的环境变量(如MASTER_ADDR、MASTER_PORT),并且这些环境变量对于每张卡都是唯一的。
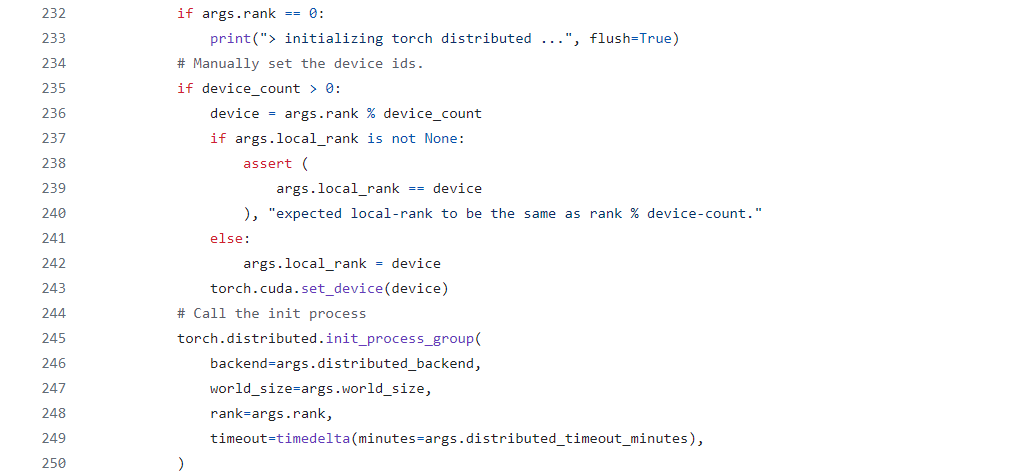
b. 通过调用mpu.initialize_model_parallel()来初始化分布式训练环境中的数据并行(DP)、张量并行(TP)、和流水线并行(PP)的分组,如下图。

mpu.initialize_model_parallel()的入参解释如下:
-
tensor_model_parallel_size:张量并行的大小。
-
pipeline_model_parallel_size:流水线并行的大小。
-
virtual_pipeline_model_parallel_size:虚拟流水线并行的大小,这是一个更高级的特性,允许在流水线阶段内部进一步分割模型。
-
pipeline_model_parallel_split_rank:该参数指定了流水线分割的起始rank,即决定了哪个rank的设备将开始处理流水线的第一个阶段,然后接下来的阶段按顺序分配给rank号递增的设备。
-
context_parallel_size、expert_model_parallel_size等参数用于特定的模型架构,如带有上下文并行或专家并行的Transformer模型。
-
distributed_timeout_minutes:分布式操作的超时时间(以分钟为单位)。
-
nccl_communicator_config_path:NCCL通信器的配置文件路径,NCCL是用于NVIDIA GPU的高效通信库。
-
order:指定并行策略的顺序,例如'tp-cp-ep-dp-pp'表示张量并行(Tensor Parallelism)、上下文并行(Context Parallelism)、专家并行(Expert Parallelism)、数据并行(Data Parallelism)和流水线并行(Pipeline Parallelism)的顺序。
-
encoder_pipeline_model_parallel_size:专门用于编码器的流水线并行大小。
-
get_embedding_ranks和get_position_embedding_ranks:用于获取特定用于embedding或position embedding的GPU rank号,以便为这些组件配置特定的并行策略。
二. mpu.initialize_model_parallel函数的调用关系(init.py)
mpu.initialize_model_parallel()函数的调用关系在import中表明,如下图:

其中mpu定义在megatron/core/init.py中:

如上图,mpu指向parallel_state,因此,对于mpu.initialize_model_parallel()的调用既是对parallel_state.initialize_model_parallel()的调用,该函数实现在parallel_state.py中。
三. 分组逻辑的具体实现(parallel_state.py)
1. parallel_state.initialize_model_parallel的调用关系
parallel_state.initialize_model_parallel函数在分布式训练架构中扮演着关键但非终结性的角色,其核心功能是启动模型并行所需的基础设置。该函数专注于预配置模型并行相关的进程群组(process groups)与全局状态变量,确保并行执行环境的基础通信框架得以确立。
下面以dp为例,展示该函数的代码执行逻辑。
首先,该函数创建RankGenerator对象实体,该对象的作用是根据用户输入的tp/dp/pp大小,以及总卡数(world_size),确定最终每张卡的分组,如下图。

其次,它首先调用RankGenerator组件动态生成高效的rank分配方案,这一步骤是优化资源利用与通信效率的关键。随后,通过调用后端(backend)接口,根据RankGenerator产出的分组策略,构建起实际用于数据交换的通信群组(communication groups)。这些通信群组覆盖了数据并行(dp)、张量并行(tp)、以及流水线并行(pp)等维度(这里只以dp为例),确保模型训练过程中的数据流通与参数同步能够高效且有序地进行,如下图。
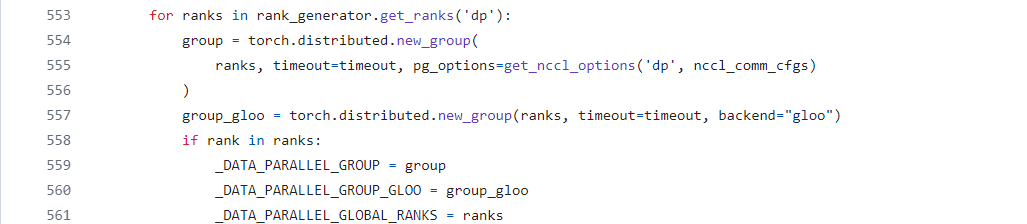
随着所有必需通信群组的成功建立,以及全局分组变量的初始化,模型并行的核心通信网络得以全面搭建完成。这一网络的构建不仅标志着模型并行化训练环境的初步就绪,更为后续的高性能计算任务奠定了坚实的基础,确保了分布式训练过程中数据一致性与效率的最优化实现。
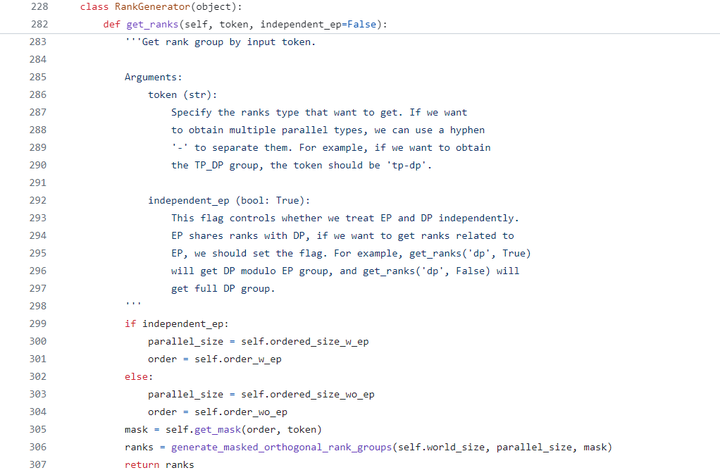
2. RankGenerator.get_ranks
RankGenerator,顾名思义,其主要职责为生成rank分组,它管理着用户的tp/pp/dp/ep/cp数值,以及全局卡数(world_size)等分组相关的配置项,并在get_ranks函数中调用generate_masked_orthogonal_rank_groups函数获取用户需要的最终分组信息,如下图:
3. generate_masked_orthogonal_rank_groups
generate_masked_orthogonal_rank_groups函数是rank分组的最终实现,其代码逻辑如下:
a. 筛选并行性尺寸:
masked_shape:从parallel_size和mask中筛选出被掩码(即True)的并行尺寸,这些尺寸将用于生成组内的rank。
unmasked_shape:同样从parallel_size和mask中筛选出未被掩码的并行尺寸,这些尺寸将用于在更广泛的并行环境中(跨组)定位每个组。
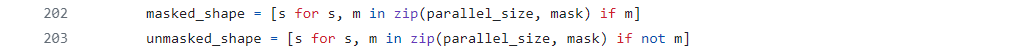
b. 计算步长:
global_stride:通过prefix_product(parallel_size)计算得到全局步长。
masked_stride和unmasked_stride:分别根据mask从global_stride中筛选出被掩码和未被掩码的步长。这些步长用于计算全局rank。

c. 确定组大小和组数:
group_size:通过prefix_product(masked_shape)-1计算得到每个组的大小。
num_of_group:通过world_size // group_size计算得到组的数量,即全局大小除以每个组的大小。
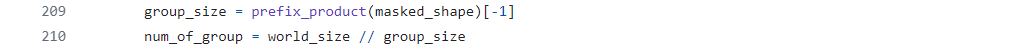
d. 生成rank:
遍历每个组(group_index从0到num_of_group-1)。
使用decompose(group_index, unmasked_shape)根据未被掩码的并行尺寸分解组索引,得到该组在全局并行环境中的位置(decomposed_group_idx)。

在每个组内,遍历每个rank(rank_in_group从0到group_size-1)。
使用decompose(rank_in_group, masked_shape)根据被掩码的并行尺寸分解组内rank,得到该rank在组内的位置(decomposed_rank_idx)。
计算每个rank的全局索引,通过将被掩码和未被掩码的索引分别与其对应的步长进行内积(inner_product),然后将两个内积相加得到。
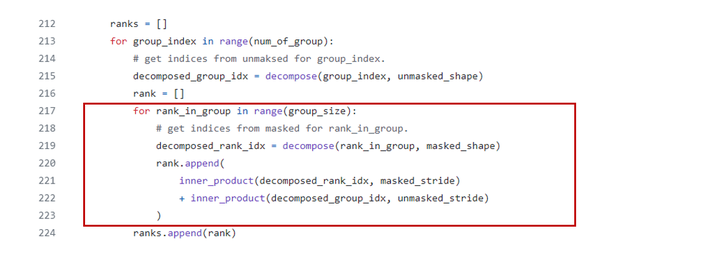
最后,将计算得到的每个组内的rank添加到ranks列表中。
e. 返回rank列表:
函数最终返回ranks列表,其中包含了每个组内的所有rank,这些rank在全局并行环境中是唯一的。
** 至此分布式训练分组的全部逻辑均介绍完毕,后续文章将继续解析分组完成后的训练逻辑。**