核心思路:将复杂查询分解为一系列递进的提示,引导模型逐步细化和完善问题
举例:
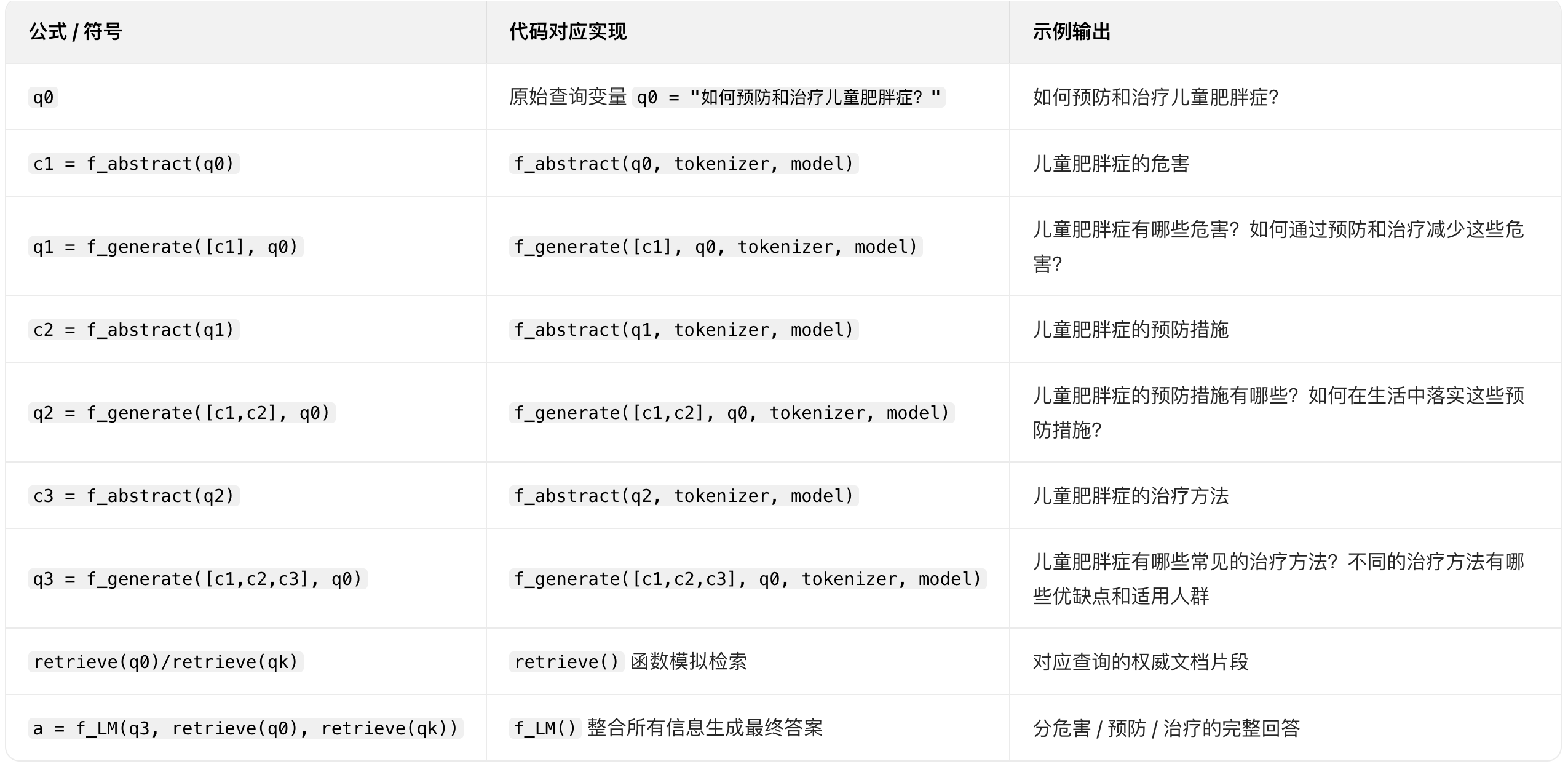
原始查询:如何预防和治疗儿童肥胖症?
c1 = 儿童肥胖症的危害
q1 = 儿童肥胖症有哪些危害?如何通过预防和治疗减少这些危害?
c2 = 儿童肥胖症的预防措施
q2 = 儿童肥胖症的预防措施有哪些?如何在生活中落实这些预防措施?
c3 = 儿童肥胖症的治疗方法
q3 = 儿童肥胖症有哪些常见的治疗方法?不同的治疗方法有哪些优缺点和适用人群
最后原始查询、细化查询、提取的关键概念的检索结果被输入答案生成器,生成一个全面有针对性的答案
q0 = original query
ci = f_abstract(qi-1), i = 1,2,3,...,K
qi = f_generate(c1,c2, ..., ci; q0), i = 1,2,3,...,K
a = f_LM(qK, retrieve(q0), retrieve(qk))
q0 原始查询
ci 第i步提取出来的高层概念
f_abstract 概念提取模型
f_generate 查询生成模型
f_LM 综合概念、原始查询、细化查询的答案生成器
q0→c1/c2/c3→q1/q2/q3→检索+答案生成
概念提取、细化查询生成、检索模拟、答案整合
代码
py
import torch
from typing import List, Dict, Tuple
from transformers import AutoTokenizer, AutoModelForCausalLM
# ====================== 1. 配置项 ======================
# 建议替换为中文优化模型(如 ChatGLM3-6B、Llama2-Chinese)
MODEL_NAME = "THUDM/chatglm3-6b"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
K = 3 # 分步细化的轮数(对应c1/c2/c3)
# ====================== 2. 初始化模型/分词器 ======================
def init_models() -> Tuple[AutoTokenizer, AutoModelForCausalLM]:
"""初始化概念提取/查询生成/答案生成共用的模型(也可拆分不同模型)"""
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
trust_remote_code=True,
torch_dtype=torch.float16 if DEVICE == "cuda" else torch.float32
).to(DEVICE)
model.eval()
return tokenizer, model
# ====================== 3. 核心函数:f_abstract 概念提取(ci = f_abstract(qi-1)) ======================
def f_abstract(prev_query: str, tokenizer, model) -> str:
"""
从第i-1步的查询中提取高层概念ci
prev_query: 上一轮的查询(q0/q1/q2)
return: 提取的核心概念(如"儿童肥胖症的危害")
"""
abstract_prompt = f"""
请从查询语句「{prev_query}」中提取一个核心高层概念,要求:
1. 概念需聚焦查询的一个核心维度(如危害、预防、治疗);
2. 仅返回概念短语,无需解释,字数控制在5-8字;
3. 避免重复已提取的概念(若有)。
"""
# 模型推理
inputs = tokenizer(abstract_prompt, return_tensors="pt", truncation=True, max_length=512).to(DEVICE)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=32,
num_beams=3,
temperature=0.1, # 低随机性保证概念精准
repetition_penalty=1.2,
pad_token_id=tokenizer.pad_token_id if tokenizer.pad_token_id else 0
)
# 解析结果
ci = tokenizer.decode(outputs[0], skip_special_tokens=True).strip()
# 过滤冗余内容(仅保留核心概念)
ci = ci.replace(abstract_prompt, "").strip().replace(":", "").replace(":", "")
return ci
# ====================== 4. 核心函数:f_generate 查询生成(qi = f_generate(c1..ci; q0)) ======================
def f_generate(
core_concepts: List[str], # [c1, c2, ..., ci]
q0: str,
tokenizer,
model
) -> str:
"""
基于已提取的核心概念和原始查询,生成第i步的细化查询qi
core_concepts: 累计提取的核心概念列表
q0: 原始查询
return: 细化后的查询语句qi
"""
generate_prompt = f"""
原始查询:{q0}
已提取的核心概念:{', '.join(core_concepts)}
请基于这些概念生成一个细化的查询语句,要求:
1. 聚焦最新提取的概念({core_concepts[-1]});
2. 关联原始查询的核心意图(预防和治疗);
3. 查询需具体、有针对性,包含"如何/有哪些/优缺点"等引导词;
4. 仅返回查询语句,无需额外解释。
"""
# 模型推理
inputs = tokenizer(generate_prompt, return_tensors="pt", truncation=True, max_length=512).to(DEVICE)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=64,
num_beams=3,
temperature=0.7,
repetition_penalty=1.2,
pad_token_id=tokenizer.pad_token_id if tokenizer.pad_token_id else 0
)
# 解析结果
qi = tokenizer.decode(outputs[0], skip_special_tokens=True).strip()
qi = qi.replace(generate_prompt, "").strip()
return qi
# ====================== 5. 模拟检索函数:retrieve(q) ======================
def retrieve(query: str) -> str:
"""
模拟检索函数(实际场景替换为BM25/向量数据库检索)
return: 该查询对应的检索结果(权威文档片段)
"""
# 模拟检索知识库(实际需替换为真实检索逻辑)
retrieval_knowledge = {
"如何预防和治疗儿童肥胖症?": "儿童肥胖症是多因素导致的营养障碍性疾病,预防需饮食+运动结合,治疗需避免节食。",
"儿童肥胖症的危害": "儿童肥胖易引发高血压、糖尿病、心理自卑等问题,远期增加心脑血管疾病风险。",
"儿童肥胖症有哪些危害?如何通过预防和治疗减少这些危害?": "危害:1.生理:高血压、脂肪肝;2.心理:社交障碍。预防可减少高糖饮食,治疗可通过运动干预降低风险。",
"儿童肥胖症的预防措施": "预防核心:控制高糖高脂零食、每天60分钟中等强度运动、家长以身作则养成健康习惯。",
"儿童肥胖症的预防措施有哪些?如何在生活中落实这些预防措施?": "预防措施:1.饮食:规律进餐、多吃蔬菜;2.运动:减少视屏时间,增加户外活动。落实:家庭制定饮食计划,每天亲子运动30分钟。",
"儿童肥胖症的治疗方法": "治疗原则:不节食、循序渐进,包括饮食调整、运动干预、专业医疗指导,极端病例可药物/手术。",
"儿童肥胖症有哪些常见的治疗方法?不同的治疗方法有哪些优缺点和适用人群": "1.饮食调整:优点安全,缺点见效慢,适用于所有肥胖儿童;2.药物治疗:优点见效快,缺点有副作用,适用于重度肥胖;3.手术治疗:优点减重显著,缺点风险高,适用于极重度肥胖且合并并发症的儿童。"
}
return retrieval_knowledge.get(query, f"未检索到「{query}」相关信息")
# ====================== 6. 核心函数:f_LM 答案生成(a = f_LM(qK, retrieve(q0), retrieve(qk))) ======================
def f_LM(
qK: str, # 最后一步的细化查询
q0: str, # 原始查询
all_queries: List[str], # [q0, q1, q2, q3]
tokenizer,
model
) -> str:
"""
整合原始查询、所有细化查询的检索结果,生成最终答案
"""
# 收集所有检索结果
all_retrieval_results = []
for q in all_queries:
res = retrieve(q)
all_retrieval_results.append(f"查询「{q}」的检索结果:{res}")
# 答案生成提示
lm_prompt = f"""
请基于以下信息,全面、有针对性地回答原始查询「{q0}」:
1. 最后一步细化查询:{qK}
2. 所有查询的检索结果:
{chr(10).join(all_retrieval_results)}
回答要求:
1. 结构清晰,分"危害、预防、治疗"三部分;
2. 内容基于检索结果,不编造信息;
3. 语言通俗易懂,适合家长阅读;
4. 突出预防和治疗的实操性建议。
"""
# 模型生成最终答案
inputs = tokenizer(lm_prompt, return_tensors="pt", truncation=True, max_length=1024).to(DEVICE)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
num_beams=5,
temperature=0.7,
repetition_penalty=1.2,
pad_token_id=tokenizer.pad_token_id if tokenizer.pad_token_id else 0
)
final_answer = tokenizer.decode(outputs[0], skip_special_tokens=True).strip()
final_answer = final_answer.replace(lm_prompt, "").strip()
return final_answer
# ====================== 7. 主流程:分步提示完整链路 ======================
def step_by_step_prompting(q0: str) -> str:
"""
完整流程:q0 → c1/c2/c3 → q1/q2/q3 → 检索 → 答案生成
"""
# 初始化模型
tokenizer, model = init_models()
# 存储中间结果
core_concepts = [] # [c1, c2, c3]
all_queries = [q0] # [q0, q1, q2, q3]
# 分步生成c1→q1, c2→q2, c3→q3
# 左闭右开区间
for i in range(1, K+1):
# 步骤1:提取第i个核心概念ci(基于上一轮的查询qi-1)
prev_query = all_queries[-1]
ci = f_abstract(prev_query, tokenizer, model)
core_concepts.append(ci)
print(f"【第{i}步】提取的核心概念c{i}:{ci}")
# 步骤2:生成第i个细化查询qi
qi = f_generate(core_concepts, q0, tokenizer, model)
all_queries.append(qi)
print(f"【第{i}步】生成的细化查询q{i}:{qi}\n")
# 步骤3:生成最终答案
qK = all_queries[-1] # 最后一步的细化查询q3
final_answer = f_LM(qK, q0, all_queries, tokenizer, model)
# 输出最终结果
print("="*80)
print("【原始查询】:", q0)
print("="*80)
print("【最终答案】:\n", final_answer)
return final_answer
# ====================== 8. 执行主流程 ======================
if __name__ == "__main__":
# 原始查询q0
q0 = "如何预防和治疗儿童肥胖症?"
# 执行分步提示流程
step_by_step_prompting(q0)结果
【第1步】提取的核心概念c1:儿童肥胖症的危害
【第1步】生成的细化查询q1:儿童肥胖症有哪些危害?如何通过预防和治疗减少这些危害?
【第2步】提取的核心概念c2:儿童肥胖症的预防措施
【第2步】生成的细化查询q2:儿童肥胖症的预防措施有哪些?如何在生活中落实这些预防措施?
【第3步】提取的核心概念c3:儿童肥胖症的治疗方法
【第3步】生成的细化查询q3:儿童肥胖症有哪些常见的治疗方法?不同的治疗方法有哪些优缺点和适用人群
================================================================================
【原始查询】:如何预防和治疗儿童肥胖症?
================================================================================
【最终答案】:
### 一、儿童肥胖症的危害
儿童肥胖症不仅会引发短期健康问题,还会增加远期患病风险:
1. 生理危害:易导致高血压、脂肪肝、2型糖尿病等疾病,影响骨骼发育;
2. 心理危害:因体型问题易遭受欺凌,引发自卑、社交障碍等心理问题。
### 二、儿童肥胖症的预防措施
预防需从饮食、运动、家庭习惯三方面落实:
1. 饮食管控:减少高糖高脂零食和含糖饮料摄入,规律进餐、多吃蔬菜和全谷物;
2. 运动培养:每天保证60分钟中等强度运动(如游泳、球类),减少视屏时间,久坐45分钟后需起身活动;
3. 家庭配合:家长以身作则养成健康习惯,制定家庭饮食计划,每天陪孩子进行30分钟亲子运动。
### 三、儿童肥胖症的治疗方法
治疗需遵循"不节食、循序渐进"的原则,不同方法适配不同人群:
1. 饮食调整:优点是安全无副作用,缺点是见效较慢,适用于所有肥胖儿童,核心是优化饮食结构(增加优质蛋白、膳食纤维)而非减少主食量;
2. 药物治疗:优点是减重见效快,缺点是存在一定副作用,仅适用于重度肥胖儿童,且需在医生全程监督下使用;
3. 手术治疗:优点是减重效果显著,缺点是手术风险高,仅适用于极重度肥胖且合并心脑血管并发症的儿童。附录
chr(10)
将列表 all_retrieval_results 中的所有字符串元素,用 "换行符" 连接成一个完整的字符串
chr(10):Python 中 chr(n) 是返回对应 ASCII 码的字符
chr(10) 对应 换行符(\n)(ASCII 码 10 是换行符的标准编码)
等价于直接写 "\n"
py
"\n".join(all_retrieval_results)
chr(10).join(all_retrieval_results)str.join(iterable):Python 字符串的核心方法,作用是 "用当前字符串作为分隔符,拼接可迭代对象(如列表)中的所有元素",要求可迭代对象内的元素必须是字符串。
strip()
strip() 是 Python 字符串的内置函数,核心作用是:
移除字符串首尾的指定字符(默认移除空白字符),返回处理后的新字符串(原字符串不变)