大模型训练的"最后一公里":为什么强化学习(RL)不可或缺?
1. 引言:从"学会说话"到"善于沟通"的飞跃
训练一个出色的大语言模型(LLM),如同培养一个孩子从呱呱坠地到成长为社会精英,需要经历循序渐进的几个核心阶段。我们可以将其类比为一个人的成长历程:
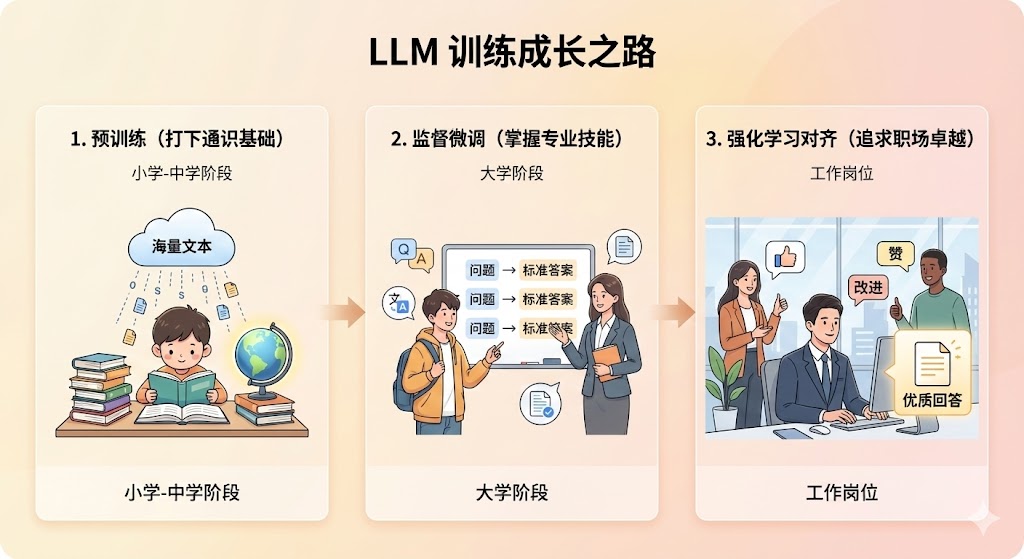
- 预训练(打下通识基础):如同"小学到中学"阶段,模型通过阅读海量的互联网文本,学习语言的规律、语法和世界常识,为未来的发展奠定坚实的知识基础。
- 监督微调(掌握专业技能):进入"大学"阶段,模型开始学习特定技能。我们为它提供大量"问题-标准答案"的范例,教会它如何按照特定格式完成问答、翻译、摘要等任务。
- 强化学习对齐(追求职场卓越):走上"工作岗位"后,模型需要学会的不再是标准答案,而是如何提供更有帮助、更负责任的优质回答。这一步,模型通过与人类的反馈互动,不断试错和改进,追求卓越。
本文将深入探讨,为什么仅仅完成前两个阶段------特别是监督微调(Supervised Fine-Tuning, SFT)------是远远不够的。我们将揭示强化学习(Reinforcement Learning, RL)在将一个模型从"能用"提升到"好用"的过程中,所扮演的不可替代的关键角色。
然而,就像一个只会背诵标准答案的学生,SFT模型很快就遇到了它的天花板。让我们来看看它面临的三个"致命局限"。
加入 赋范空间 免费领取 强化学习RL相关资料,还有更多Agent、RAG、MCP等开发教程等你来拿
2. "学霸"的瓶颈:监督微调(SFT)的三大局限
监督微调(SFT)确实能有效地教会模型回答问题的基本格式和套路,使其成为一个合格的"学霸"。但这种学习方式存在三个难以克服的根本性问题,限制了它成为真正专家的可能。
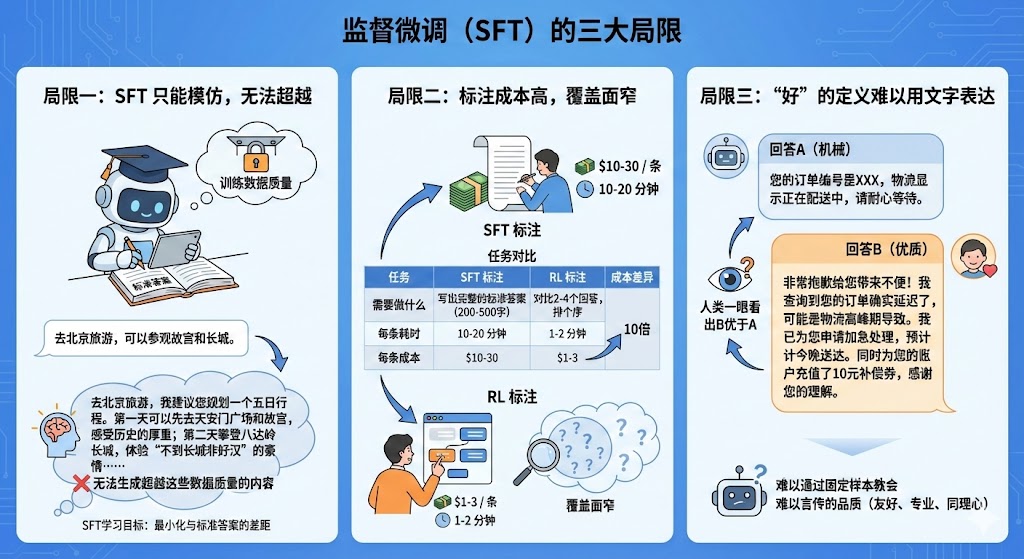
局限一:SFT 只能模仿,无法超越
- 原因解释:SFT的学习目标是"最小化与标准答案的差距",这意味着它的天花板就是训练数据的质量。它只能努力模仿、复制训练数据中的风格和知识,却无法生成超越这些数据质量的内容。
- 举例说明:假设我们用SFT训练模型提供旅游建议,训练样本是"去北京旅游,可以参观故宫和长城。" 模型学会后,最多也只能生成类似的简短建议。它永远无法"自己想出"一个更详尽、更优质的回答,例如:"去北京旅游,我建议您规划一个五日行程。第一天可以先去天安门广场和故宫,感受历史的厚重;第二天攀登八达岭长城,体验'不到长城非好汉'的豪情......"
局限二:标注成本高,覆盖面窄
- 原因解释:SFT要求为每一个问题都提供一个高质量、完整的标准答案。这种标注方式不仅耗时耗力,成本极高,也导致了训练数据无法覆盖现实世界中无穷无尽、千变万化的用户问题。
- 举例说明:SFT和RL的标注任务有着本质不同,导致成本存在巨大差异。RL标注的核心优势在于将任务从"创作"变成了"评判",效率因此提升了10倍。
| 任务 | SFT 标注 | RL 标注 | 成本差异 |
|---|---|---|---|
| 需要做什么 | 写出完整的标准答案(200-500字) | 对比2-4个回答,排个序 | - |
| 每条耗时 | 10-20 分钟 | 1-2 分钟 | 10倍 |
| 每条成本 | $10-30 | $1-3 | 10倍 |
局限三:"好"的定义难以用文字表达
- 原因解释:很多时候,一个"好"的回答并不仅仅是内容正确,还包含了友好、专业、有同理心等"软标准"。这些难以言传的品质,很难通过编写几个固定的SFT样本来教会模型。
- 举例说明:当用户抱怨"我的订单还没到,已经过了预计送达时间"时,两个回答高下立判:
- 回答A(机械):"您的订单编号是XXX,物流显示正在配送中,请耐心等待。"
- 回答B(优质):"非常抱歉给您带来不便!我查询到您的订单确实延迟了,可能是物流高峰期导致。我已为您申请加急处理,预计今晚送达。同时为您的账户充值了10元补偿券,感谢您的理解。"
- 人类一眼就能看出回答B远胜于A,但我们很难通过SFT样本来定义"为什么B更好"。模型无法从中学会这种微妙的人类偏好。
正是因为SFT存在这些难以逾越的障碍,一种更智能、更灵活的学习范式------强化学习,便应运而生。
3. 另辟蹊径:强化学习(RL)如何破局?

强化学习的核心思想与传统教学截然不同。我们可以用一个生动的比喻来理解它:训练宠物。
- 传统教学方式(类似SFT):手把手地抬起小狗的爪子,放在你的手上,重复这个动作。小狗只是在模仿,并不真正理解。
- 强化学习方式:你发出"握手"的指令,让小狗自己尝试。如果它碰巧抬起了爪子,你就立刻给它零食作为奖励;如果它跑开了,就不给奖励。通过反复的试错和反馈,小狗最终学会了什么是"好"的行为。
RL正是这样,它不直接提供标准答案,而是通过"奖励"和"惩罚"的反馈,引导模型在探索中逐步学习,找到更优的解决方案。
下表清晰地展示了监督学习(SFT)与强化学习(RL)在本质上的区别:
| 对比维度 | 监督学习 (SFT) | 强化学习 (RL) |
|---|---|---|
| 学习目标 | 最小化与标准答案的差距 | 最大化累积奖励 |
| 学习方式 | 模仿标准答案 | 自己探索+获取反馈 |
| 评价标准 | "是否和标准答案一模一样" | "回答质量有多高" |
| 能否超越数据 | ❌ 只能复制训练集 | ✅ 可能发现更优解 |
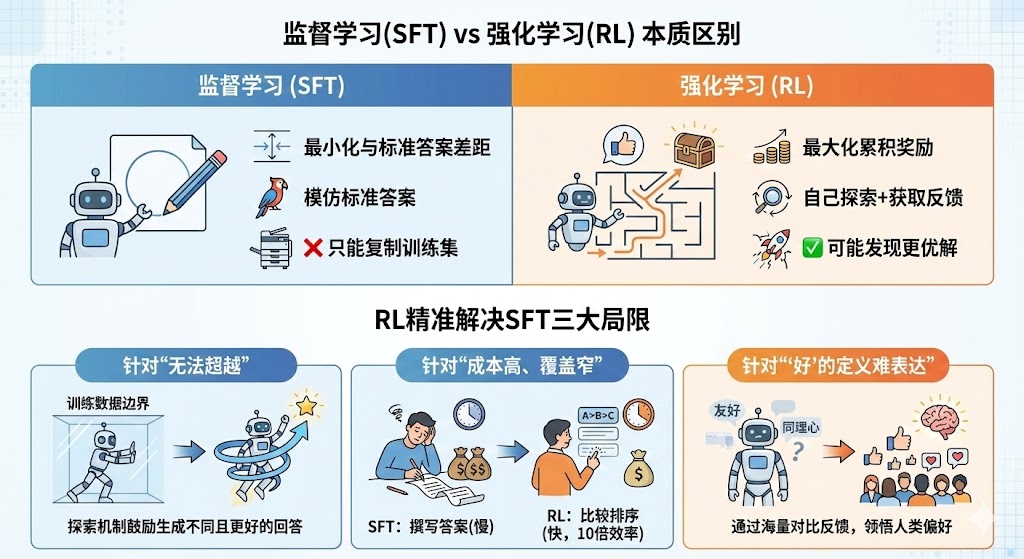
基于这些本质区别,强化学习能够精准地解决SFT的三大局限:
- 针对"无法超越":RL通过探索和奖励机制,鼓励模型生成不同于训练数据的、可能更好的回答。只要一个新答案获得了更高的奖励,模型就会朝这个方向优化,从而有能力超越标注数据的水平。
- 针对"成本高、覆盖窄":RL的标注方式从根本上改变了任务。它不再要求标注员撰写一篇完美的500字答案,而是让他们比较几个机器生成的答案并排序。这把一项耗时的创作工作,变成了一个快速的判断任务,从而将时间和成本降低了10倍,使得用同样的预算覆盖10倍以上的多样化问题成为可能。
- 针对"'好'的定义难表达":对于友好、有同理心等"软标准",人类标注者可以轻易地判断出哪个回答更好。通过成千上万次的对比反馈,RL能够让模型逐渐领悟这些"只可意会,不可言传"的人类偏好。
尽管强化学习为我们指明了方向,但将它应用于动辄拥有数十亿参数的大模型时,挑战也随之而来。
4. 新的征程:大模型强化学习面临的特殊挑战
将理论上简洁的强化学习范式,应用到工业级的、参数量巨大的语言模型上,会遇到一系列独特的工程和技术挑战。正是这些挑战,催生了像verl这样的专业强化学习框架,它们的设计初衷就是为了解决这些棘手的难题。
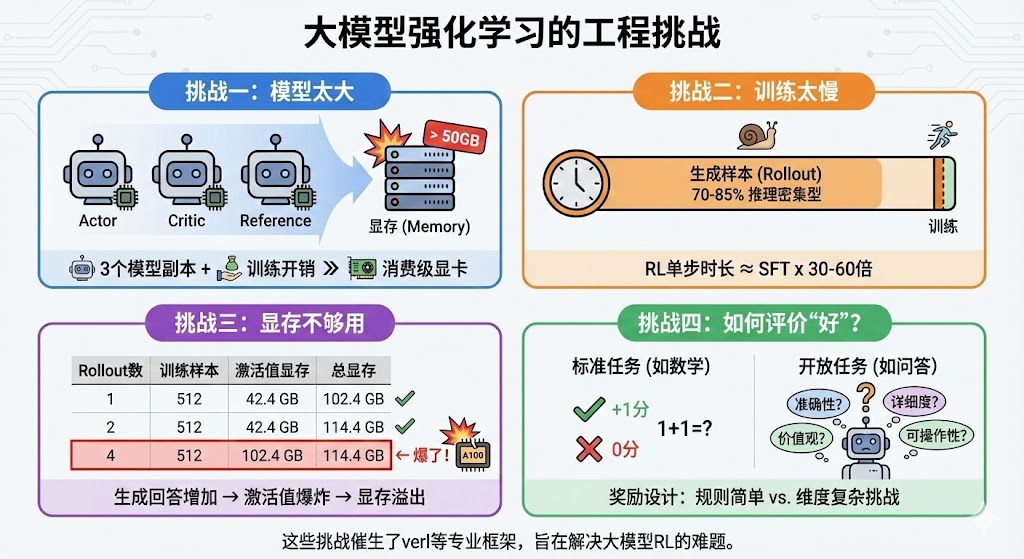
挑战一:模型太大
强化学习通常需要同时加载多个模型副本:一个负责学习的Actor,一个负责评价的Critic,以及一个作为基准的Reference。对于一个1.5B模型(本身约3GB),仅这三个模型就需要约9GB的基础显存,再算上梯度和优化器状态等训练开销(通常是4-6倍),总显存需求轻易突破50GB,远超消费级显卡(如24GB)。
挑战二:训练太慢
RL训练是典型的"推理密集型"任务。在每一步训练开始前,模型都需要先生成(Rollout)多个回答样本。这个生成过程非常耗时,占据了整个训练时间的 70-85%。这导致RL的单步训练时长是SFT的 30-60倍,极大地拖慢了整个训练周期。
挑战三:显存不够用
为了进行有效的对比学习,RL需要模型为每个问题生成多个不同的回答。这会导致中间计算结果(激活值)的显存需求成倍增加。以一个批处理大小(Batch Size)为128的训练任务为例,显存占用会随着生成回答数量的增加而爆炸,轻易超出单张顶级专业显卡(如A100 80GB)的限制。
| Rollout数 | 训练样本数 | 激活值显存 | 总显存 |
|---|---|---|---|
| 1 | 128 | 25.6 GB | 37.6 GB |
| 2 | 256 | 51.2 GB | 63.2 GB |
| 4 | 512 | 102.4 GB | 114.4 GB ← 爆了! |
挑战四:如何评价"好"的回答?
奖励(Reward)的设计是RL的核心,也是其最大的难点。
- 对于有标准答案的任务(如数学题),奖励设计相对简单。我们可以制定规则:答案正确得+1分,错误得0分。
- 对于开放性问题(如"如何成为一名优秀的产品经理?"),评价维度变得极其复杂,包括内容的准确性、详细程度、可操作性、价值观等。设计一个能够准确衡量这些维度的奖励函数或奖励模型,是一项极具挑战性的工作。
了解这些挑战,能帮助我们更全面地认识大模型强化学习这一前沿领域的复杂性与巨大潜力。
加入 赋范空间 免费领取 强化学习相关资料,还有更多Agent、RAG、MCP等开发教程等你来拿
5. 结论:通往卓越的必经之路
综上所述,从只能模仿标准答案的监督微调(SFT),到能够通过试错和反馈进行自我优化的强化学习(RL),是大型语言模型从"合格"迈向"卓越"的必经之路。
本文的核心观点可以提炼为以下三点:
- SFT的局限:SFT只能模仿,无法超越训练数据。其高昂的标注成本和狭窄的覆盖范围,使其难以真正理解"好"的回答所蕴含的复杂人类偏好。
- RL的价值:RL通过试错和反馈机制,让模型有能力生成比训练数据更优质的答案,并学会那些难以用规则描述的人类偏好,最终实现从"能用"到"好用"的质变。
- RL的挑战:将RL应用于大模型并非易事,它在实际工程中面临着由模型规模、训练效率和奖励设计带来的巨大挑战,需要专业的框架和技术来解决。
ChatGPT的巨大成功在很大程度上归功于RLHF(基于人类反馈的强化学习)。 数据显示,在应用了RLHF后,即便是同一个基础模型,其用户满意度也实现了 70%以上 的惊人提升。这雄辩地证明了强化学习在当今大模型竞争中的决定性地位。