RoboBrain 2.0是一个机器人的具身大脑模型,具备统一感知 、推理 和规划能力;
同时适应对物理环境中****复杂的具身任务;
它提供不同版本:轻量级的3B、7B模型和全尺寸的 32B 模型,包含视觉编码器和语言模型。
代码地址:https://github.com/FlagOpen/RoboBrain2.0
论文地址:RoboBrain 2.0 Technical Report
目录
示例1:图文问答,使用RoboBrain2.0-7B模型,不开思考模式
示例2:图文问答,使用RoboBrain2.0-7B模型,开启思考模式
快速了解模型
RoboBrain 2.0 支持交互式推理, 包括长远规划和闭环反馈、从复杂指令中精确预测点和边界框的空间感知、用于估计未来轨迹的 时间感知,
以及通过实时结构化记忆构建和更新进行场景推理。
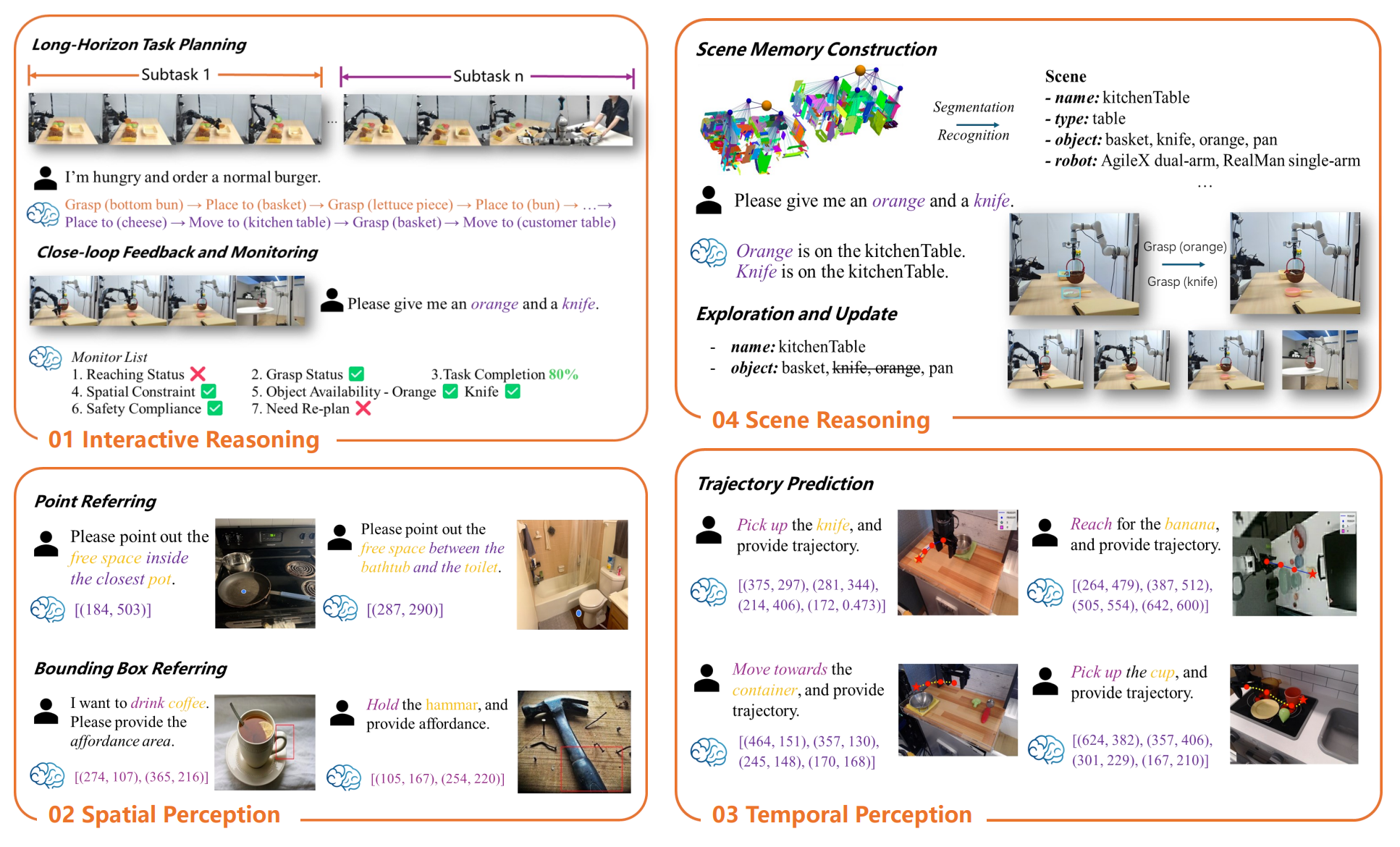
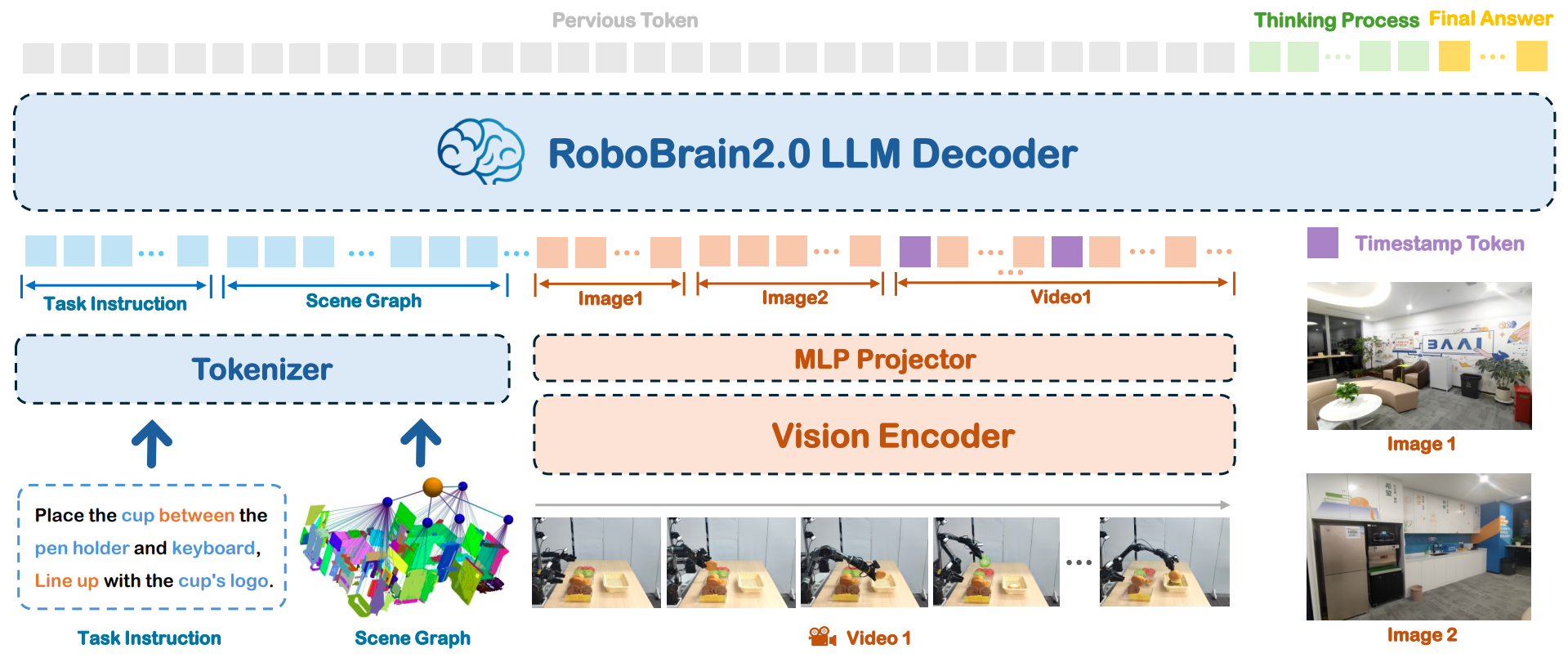
模型架构:
1、创建Conda环境
首先创建一个Conda环境,名字为robobrain2,python版本为3.10;
然后进入robobrain2环境,执行下面命令:
conda create -n robobrain2 python=3.10
conda activate robobrain2下载robobrain2代码到本地:
git clone https://github.com/FlagOpen/RoboBrain2.0.git
cd RoboBrain2.02、安装依赖库
编辑requirements.txt文件,内容如下所示:
# pip install -r requirements.txt
# 深度学习框架 & 训练/推理加速
pytorch-lightning==1.9.5
transformers==4.50.0
tokenizers==0.21.0
huggingface-hub==0.27.1
safetensors==0.5.2
accelerate==1.3.0
deepspeed==0.15.0
peft==0.14.0
trl==0.9.6
flash-attn==2.5.9.post1
xformers==0.0.28.post3
triton==3.1.0
vllm==0.7.3
tensor-parallel==1.2.4
fairscale==0.4.13
diffusers==0.29.2
bitsandbytes==0.43.3
gguf==0.10.0
# 科学计算 & 数值 / 图像 / 信号
numpy==1.26.4
scipy==1.15.1
scikit-learn==1.6.1
scikit-image==0.20.0
pandas==2.2.3
matplotlib==3.7.5
seaborn==0.13.2
Pillow==11.1.0
opencv-python==4.7.0.72
opencv-python-headless==4.11.0.86
av==14.4.0
imageio-ffmpeg==0.5.1
PyWavelets==1.4.1
numba==0.60.0
einops==0.8.0
einx==0.3.0
ml_dtypes==0.5.3
cupy-cuda12x==13.4.1
# 数据 & 特征 / 向量 / 文本
datasets==3.6.0
evaluate==0.4.2
sentence-transformers==3.4.1
FlagEmbedding==1.3.4
openai==1.60.0
tiktoken==0.7.0
sentencepiece==0.2.0
regex==2024.11.6
ftfy==6.2.0
chattts==0.2.1
qwen-vl-utils==0.0.8
# 分布式 / 并行 / 集群
ray==2.40.0
dask==2023.4.1
torch-ort==1.17.0
msccl==2.3.0
# Web 服务 & API 框架
fastapi==0.115.6
uvicorn==0.34.0
starlette==0.41.3
gradio==5.12.0
gradio_client==1.5.4
httpx==0.27.2
requests==2.32.3
pydantic==2.10.5
pydantic-settings==2.7.1
typer==0.15.1
# 异步 / 并发 / 网络
aiohttp==3.11.11
anyio==4.8.0
websockets==14.1
tornado==6.4.1
async-timeout==4.0.3
# 配置 / 日志 / 进度 / 序列化
omegaconf==2.3.0
tqdm
PyYAML
orjson==3.10.14
msgpack==1.1.0
lz4==4.4.4
xxhash==3.5.0
# 其他常用工具
typing_extensions==4.12.2
packaging==24.2
filelock==3.16.1
psutil==7.0.0执行下面命令,进行依赖库安装:
pip install -r requirements.txt等待安装完成~
3、安装torch
这里指定CUDA12.1和torch==2.5.0的版本
执行下面命令,进行torch的安装:
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121等待安装完成~
4、模型推理
主要包括:图文问答(支持思考模式)、 目标检测(视觉基础能力)、可供性预测(具身认知)
操作轨迹预测与规划(具身决策) 、 具身导航任务
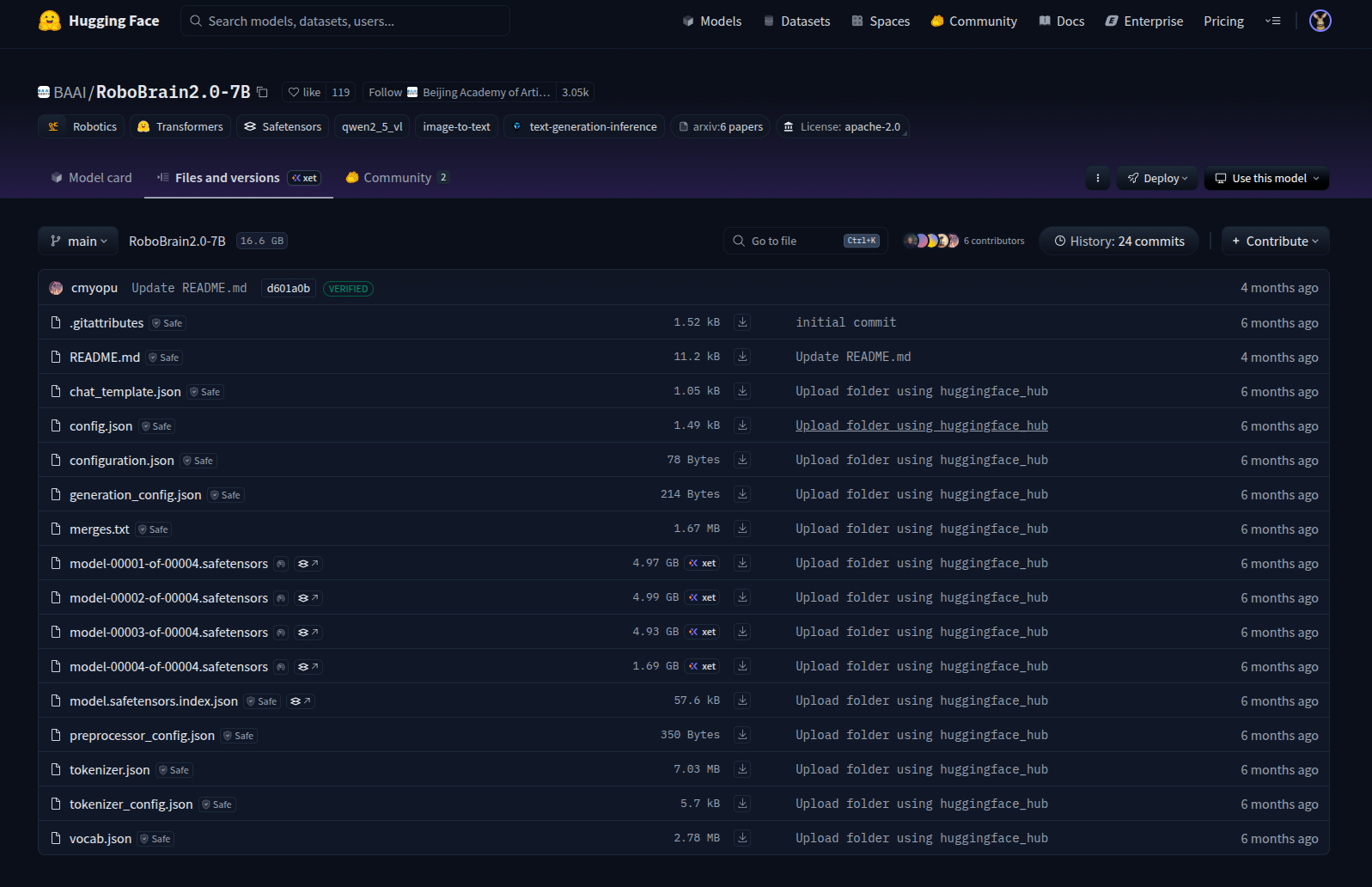
在首次运行时,需要下载模型权重的,比如RoboBrain2.0-7B:
备注:需要在终端输入"huggingface-cli login "命令,然后输入"Access Tokens"进行登陆
而且下载RoboBrain2.0的模型,需要先签名认证,才能下载的(对应下面图片的**"verified"**)
比如:https://huggingface.co/BAAI/RoboBrain2.0-7B/tree/main
Trying to resume download...
model-00001-of-00004.safetensors: 100%|████████████████████████████████████████████████████| 4.97G/4.97G 01:30\<00:00, 19.4MB/s
model-00002-of-00004.safetensors: 100%|████████████████████████████████████████████████████| 4.99G/4.99G 00:40\<00:00, 24.6MB/s
model-00002-of-00004.safetensors: 80%|█████████████████████████████████████████▌ | 4.00G/4.99G 01:34\<01:36, 10.3MB/s
model-00003-of-00004.safetensors: 100%|████████████████████████████████████████████████████| 4.93G/4.93G 01:57\<00:00, 19.8MB/s
Fetching 4 files: 100%|███████████████████████████████████████████████████████████████████████████| 4/4 01:58\<00:00, 29.70s/it
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████| 4/4 00:01\<00:00, 3.59it/s
generation_config.json: 100%|██████████████████████████████████████████████████████████████████| 214/214 00:00\<00:00, 1.05MB/s
Some parameters are on the meta device because they were offloaded to the cpu.████████████▉| 4.93G/4.93G 01:57\<00:00, 24.4MB/s
preprocessor_config.json: 100%|████████████████████████████████████████████████████████████████| 350/350 00:00\<00:00, 1.70MB/sUsing a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.50, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
tokenizer_config.json: 5.70kB 00:00, 16.0MB/s
vocab.json: 2.78MB 00:37, 75.0kB/s
merges.txt: 1.67MB 00:00, 3.62MB/s
tokenizer.json: 7.03MB 00:00, 8.12MB/s
chat_template.json: 1.05kB 00:00, 3.80MB/s
示例1:图文问答,使用RoboBrain2.0-7B模型,不开思考模式
示例代码:
from inference import UnifiedInference
model = UnifiedInference("BAAI/RoboBrain2.0-7B")
prompt = "What is shown in this image?"
image = "http://images.cocodataset.org/val2017/000000039769.jpg"
pred = model.inference(prompt, image, task="general", enable_thinking=False, do_sample=True)
print(f"Prediction:\n{pred}")输入图片:

模型推理结果:
Loading Checkpoint ...
Loading checkpoint shards: 100%|██████████████████████████████| 4/4 00:01\<00:00, 3.67it/s
Some parameters are on the meta device because they were offloaded to the cpu.
......
Model thinking support: True
==================== INPUT ====================
What is shown in this image?===============================================
Thinking disabled (but supported).
Running inference ...
Prediction:
{'answer': 'Two cats are shown sleeping in the image, lying on a couch.'}
示例2:图文问答,使用RoboBrain2.0-7B模型,开启思考模式
示例代码:
from inference import UnifiedInference
model = UnifiedInference("BAAI/RoboBrain2.0-7B")
prompt = "What is shown in this image?"
image = "http://images.cocodataset.org/val2017/000000039769.jpg"
pred = model.inference(prompt, image, task="general", enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")输入图片(和示例1一样的)
模型推理结果,描述得很详细,而且准确
Loading Checkpoint ...
Loading checkpoint shards: 100%|██████████████████████████████| 4/4 00:01\<00:00, 3.67it/s
Some parameters are on the meta device because they were offloaded to the cpu.
......
Model thinking support: True
==================== INPUT ====================
What is shown in this image?===============================================
Thinking disabled (but supported).
Running inference ...
Prediction:{'answer': 'The image shows two cats sleeping on a couch covered with a pink blanket or sheet, and a couple of remote controls nearby.', 'thinking': 'Within the visual input, there are two cats, both of which appear to be sleeping, lying on a couch. The couch has a pink blanket or sheet that covers its surface. Additionally, a couple of remote controls can be seen lying nearby, suggesting that someone might have been watching television or using the devices before the cats decided to snooze.'}
中文意思:
{'answer': '图片中,两只猫正睡在一张铺着粉色毯子或床单的沙发上,旁边还放着几个遥控器。', 'thinking': '在视觉输入中,可以看到两只猫,它们似乎都在睡觉,躺在沙发上。沙发上铺着一条粉色的毯子或床单。此外,还能看见几个遥控器放在旁边,暗示可能有人在猫决定打盹之前正在看电视或使用这些设备。'}
示例3:图文问答,使用RoboBrain2.0-3B模型
示例代码:(3B模型没有思考模式的)
python
from inference import UnifiedInference
model = UnifiedInference("BAAI/RoboBrain2.0-3B")
prompt = "What is shown in this image?"
image = "http://images.cocodataset.org/val2017/000000039769.jpg"
pred = model.inference(prompt, image, task="general", do_sample=True)
print(f"Prediction:\n{pred}")模型推理结果;
......Model thinking support: False
==================== INPUT ====================
What is shown in this image?===============================================
Thinking disabled (but supported).
Running inference ...
Prediction:{'answer': 'The image shows two cats laying next to each other on a pink blanket and a couch, with their tails touching. They appear to be sleeping or relaxing in close proximity.'}
示例4:视觉基础能力,目标检测
示例代码:
python
from inference import UnifiedInference
import cv2, os, datetime
model = UnifiedInference("BAAI/RoboBrain2.0-7B")
prompt = "the person wearing a red hat"
image_path = "./assets/demo/grounding.jpg"
# 1. 运行推理,plot=True 会自动在 result/ 目录生成带框图
pred = model.inference(
prompt, image_path,
task="grounding",
plot=True,
enable_thinking=True,
do_sample=True
)
print(f"Prediction:\n{pred}")
# 2. 只保存可视化结果(自己定目录+文件名)
save_dir = "vis_results"
os.makedirs(save_dir, exist_ok=True)
vis_img = cv2.imread("result/grounding_with_grounding_annotated.jpg")
out_path = os.path.join(save_dir, f"redhat_det_{datetime.datetime.now().strftime('%H%M%S')}.jpg")
cv2.imwrite(out_path, vis_img)
print("可视化结果已保存至:", os.path.abspath(out_path))可视化结果:

模型推理:
==================== INPUT ====================
Please provide the bounding box coordinate of the region this sentence describes: the person wearing a red hat.===============================================
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted bounding boxes: \[0, 192, 186, 614]
Annotated image saved to: result/grounding_with_grounding_annotated.jpg
Prediction:{'answer ': '0, 192, 186, 614', 'thinking ': "After examining the visual input, I notice two main subjects involved in this scene --- an adult male and a child. The adult is wearing a blue garment, indicating a larger individual, while the child is clad in a red cap and a striped garment, suggesting a smaller presence. The child's hand is positioned near a banana peel held by both individuals.\n\nIn terms of spatial analysis, the child, identifiable by his distinct red cap, is visually closer to the right side of the image, while the adult male is towards the left side. The banana peel, grasped by both, is centrally located, bridging their interaction visually.\n\nAnalyzing the elements around them, they appear seated on a stone surface against a wall, which serves as the backdrop. The environment suggests an outdoor setting, reinforcing the casual nature of their interaction.\n\nThus, based on my visual-spatial reasoning capabilities, the child, wearing the red cap and striped outfit, is the one interacting with the banana peel, evidenced by his proximity to it and the distinct red accessory he wears."}
可视化结果已保存至: /home/lgp/2025_project/RoboBrain2.0/vis_results/redhat_det_161556.jpg
输出的提示词,也可以是中文的,比如:prompt = "找到一个香蕉"
可视化结果:

模型推理:
==================== INPUT ====================
Please provide the bounding box coordinate of the region this sentence describes: 找到一个香蕉.===============================================
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted bounding boxes: \[205, 368, 290, 497]
Annotated image saved to: result/grounding_with_grounding_annotated.jpg
Prediction:{'answer ': '205, 368, 290, 497', 'thinking ': 'From the visual input, I perceive a scene involving an adult and a child. The child is holding a banana, which is a key object in the scene. The adult appears to be sitting next to or behind the child, engaged with them. The child\'s position is slightly turned away from the observer, creating an interactive moment.\n\nAnalyzing the spatial arrangement, the banana is held in such a way that its curved shape and peel are prominent features in the visual field. This positioning allows for a clear identification of the fruit\'s location within the frame.\n\nThe task requires identifying the banana\'s location relative to certain elements in the visual input. Given the child\'s direct interaction with the banana, it can be determined as being held by the child. From the visual context, the banana is indeed found within the child\'s grasp. Therefore, based on the observed details, the answer to the question, "What is the banana?" is that it is positioned where the child is holding it.'}
可视化结果已保存至: /home/lgp/2025_project/RoboBrain2.0/vis_results/redhat_det_162204.jpg
示例5:具身认知,用于可供性预测
示例代码:
python
from inference import UnifiedInference
import cv2, os, datetime
model = UnifiedInference("BAAI/RoboBrain2.0-7B")
prompt = "如何抓住杯子"
image = "./assets/demo/affordance.jpg"
# 运行推理,plot=True 会自动保存可视化图到 result/affordance_with_affordance_annotated.jpg
pred = model.inference(
prompt, image,
task="affordance",
plot=True,
enable_thinking=True,
do_sample=True
)
print(f"Prediction:\n{pred}")
# ----------- 仅保存可视化结果 -----------
save_dir = "vis_results"
os.makedirs(save_dir, exist_ok=True)
vis_img = cv2.imread("result/affordance_with_affordance_annotated.jpg")
out_path = os.path.join(save_dir, f"affordance_{datetime.datetime.now().strftime('%H%M%S')}.jpg")
cv2.imwrite(out_path, vis_img)
print("可视化结果已保存至:", os.path.abspath(out_path))可视化效果:

模型推理结果:
==================== INPUT ====================
You are a robot using the joint control.The task is "如何抓住杯子". Please predict a possible affordance area of the end effector.
===============================================
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted bounding boxes: \[561, 224, 623, 303]Annotated image saved to: result/affordance_with_affordance_annotated.jpg
Prediction:{'answer ': '561, 224, 623, 303', 'thinking ': 'From the visual input, the object is recognized as a white mug, with a cylindrical body and a round handle on its right side. The approximate size suggests that it\'s about 10cm tall and has an opening wide enough to hold a standard coffee cup\'s capacity, making it around 7-8 cm in diameter. The mug appears to be made from ceramic or similar material, inferred by its smooth surface and uniform color. It rests stably on what seems like a wooden table surface, with no immediate obstructions nearby.\n\nMy end-effector, capable of joint control manipulation, is designed to grasp objects securely. Its design allows for precision in grasping curved surfaces and handles up to a certain height and thickness. The handle on the mug presents a suitable engagement point due to its shape and size, which my gripper can wrap around effectively without slipping.\n\nThe current task is to "如何抓住杯子," which involves identifying the most secure area to grip the mug. Given its position on the table, the handle stands out as the best affordance area because it provides a stable, protruding edge that is easy to approach and firmly grasp. \n\nTherefore, the mug\'s handle affords an optimal interaction point. This choice is supported by both the visually confirmed handle dimensions compatible with my gripper\'s capabilities and the requirement to accomplish the task efficiently.'}
可视化结果已保存至: /home/lgp/2025_project/RoboBrain2.0/vis_results/affordance_162938.jpg
示例6:用于具身的轨迹预测
示例代码:
python
from inference import UnifiedInference
import cv2, os, datetime
model = UnifiedInference("BAAI/RoboBrain2.0-7B")
prompt = "伸手去拿红色的瓶子"
image = "./assets/demo/trajectory.jpg"
# 运行推理,plot=True 会自动保存可视化图到 result/trajectory_with_trajectory_annotated.jpg
pred = model.inference(
prompt, image,
task="trajectory",
plot=True,
enable_thinking=True,
do_sample=True
)
print(f"Prediction:\n{pred}")可视化效果:

推理结果:
==================== INPUT ====================
You are a robot using the joint control. The task is "伸手去拿红色的瓶子". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. \[x1, y1, x2, y2, ...], where each tuple contains the x and y coordinates of a point.
===============================================
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted trajectory points: \[(145, 123), (259, 168), (327, 136)]Annotated image saved to: result/trajectory_with_trajectory_annotated.jpg
Prediction:{'answer ': '(145, 123), (259, 168), (327, 136)', 'thinking': "From the visual input, the target object, a red bottle, is clearly identified resting upright on a black tray positioned towards the right side of the scene. My current end-effector position is to the left of the scene, near several other objects like cups and plates that do not obstruct the path directly. Notably, there's ample space between my initial position and the red bottle, allowing for an unobstructed path.\n\nMy joint control system enables me to generate smooth trajectories. I will plan a sequence of movements starting from my current location, moving towards the red bottle. Given the open field, I can calculate intermediate points ensuring a direct approach without collision with nearby objects. Up to 10 key points are suggested but fewer may suffice given the straightforward nature of this task.\n\nThe task involves reaching and grasping the red bottle. The trajectory must be efficient and direct, originating from the initial position on the left and terminating precisely at the bottle. Each segment of the motion should ensure clearance from surrounding objects, minimizing potential interaction. This requires careful placement of key waypoints to guide the motion smoothly.\n\nVerification confirms the path's logical progression. The sequence of points is checked to ensure they maintain a safe distance from obstacles while advancing toward the red bottle. The final point must accurately target the bottle's handle or body for a successful grasp.\n\nTherefore, based on this comprehensive visual analysis and planning, the key trajectory points to reach the red bottle are determined as (145, 123), (259, 168), (327, 136). These points form a viable path from the initial position to the target while respecting the environment."}
示例7:用于指向预测(具身认知)
示例代码:
python
from inference import UnifiedInference
model = UnifiedInference("BAAI/RoboBrain2.0-7B")
prompt = "在两个杯子之间的空隙中,找出几个可以放置杯子的位置"
image = "./assets/demo/pointing.jpg"
pred = model.inference(
prompt, image,
task="pointing",
plot=True,
enable_thinking=True,
do_sample=True
)
print(f"Prediction:\n{pred}")可视化效果:

推理结果:
==================== INPUT ====================
在两个杯子之间的空隙中,找出几个可以放置杯子的位置. Your answer should be formatted as a list of tuples, i.e. (x1, y1), (x2, y2), ..., where each tuple contains the x and y coordinates of a point satisfying the conditions above. The coordinates should indicate the normalized pixel locations of the points in the image.===============================================
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted points: (334, 320), (305, 316), (369, 315), (389, 317), (314, 313), (350, 314), (378, 313), (325, 317)Annotated image saved to: result/pointing_with_pointing_annotated.jpg
Prediction:{'answer ': '(334, 320), (305, 316), (369, 315), (389, 317), (314, 313), (350, 314), (378, 313), (325, 317)', 'thinking': "From the visual input, two cups are clearly placed on a horizontal surface, with one blue cup on the left and another green cup on the right. The empty space between them is crucial for identifying potential placement points. This area lies flat on the surface and offers an unobstructed path, making it an ideal candidate for placing additional cups.\n\nMy advanced visual processing capability allows me to segment this gap visually, ensuring that any identified points will lie entirely within this region, avoiding edges or other objects nearby. It is essential to confirm that there are no physical obstructions like shadows or reflections, which might affect perceived space availability.\n\nThe task requires determining several spots within this vacant area. I start by verifying its dimensions, confirming the gap's width and height. Next, I select multiple points, spread evenly across the free space, to ensure diversity and coverage across the entire visible region, simulating different spots to place an additional cup effectively.\n\nEach identified point undergoes verification to ensure it falls strictly within the boundaries of the open space between the cups. Distinctness among points is also confirmed, avoiding overlap and maintaining separation.\n\nTherefore, through direct visual analysis, combined with my cognitive capabilities, the identified points within the vacant space are (334, 320), (305, 316), (369, 315), (389, 317), (314, 313), (350, 314), (378, 313), (325, 317). These points fulfill all requirements as they are located centrally within the available space, ensuring effective placement."}
示例8:用于具身导航任务
示例代码:
python
from inference import UnifiedInference
model = UnifiedInference("BAAI/RoboBrain2.0-7B")
prompt = "来到沙发这里,我需要休息了"
image = "./assets/demo/navigation.jpg"
pred = model.inference(
prompt, image,
task="pointing",
plot=True,
enable_thinking=True,
do_sample=True
)
print(f"Prediction:\n{pred}")可视化效果:

分享完成~