目录
- 前言
- 引言
- 一、技术背景与环境设定
-
- [1.1 openEuler 操作系统概述](#1.1 openEuler 操作系统概述)
- [1.2 图神经网络(GNN)与节点分类任务](#1.2 图神经网络(GNN)与节点分类任务)
- [1.3 实验环境配置](#1.3 实验环境配置)
- 二、数据集选择与分析
-
- [2.1 Cora 数据集介绍](#2.1 Cora 数据集介绍)
- [2.2 数据格式与加载](#2.2 数据格式与加载)
- 三、GNN模型构建与代码实现
-
- [3.1 GCN 模型代码](#3.1 GCN 模型代码)
- 四、模型训练、诊断与结果分析
- 五、openEuler在GNN应用中的优势与展望
- 六、结论
前言
随着人工智能技术的飞速发展,图神经网络(Graph Neural Network, GNN)作为处理非欧几里得空间数据的强大工具,已在众多领域展现出巨大潜力,包括推荐系统、药物发现、社交网络分析和交通流量预测等 。与此同时,基础软件特别是操作系统的创新和生态构建成为支撑前沿技术发展的关键。openEuler 作为一个开源、免费的Linux发行版平台,凭借其对多样性计算平台的支持、卓越的性能以及对AI开发环境的友好性,正逐渐成为承载复杂AI应用的重要基础设施 。
引言
随着人工智能技术的飞速发展,图神经网络(Graph Neural Network, GNN)作为处理非欧几里得空间数据的强大工具,已在众多领域展现出巨大潜力,包括推荐系统、药物发现、社交网络分析和交通流量预测等 。与此同时,基础软件特别是操作系统的创新和生态构建成为支撑前沿技术发展的关键。openEuler 作为一个开源、免费的Linux发行版平台,凭借其对多样性计算平台的支持、卓越的性能以及对AI开发环境的友好性,正逐渐成为承载复杂AI应用的重要基础设施 。
本文在深入探讨在 openEuler 操作系统上进行图神经网络应用开发的完整流程。我们将以一个经典的GNN应用场景------学术论文引用网络中的节点分类任务------为例,使用公开的 Cora 数据集进行实证研究。报告将详细阐述从环境配置、数据处理、模型构建、训练验证到结果分析的全过程,并提供详尽的 openEuler 终端操作命令、代码实现、诊断输出及真实操作截图。通过本次研究,我们旨在验证 openEuler 作为AI应用开发与部署平台的可靠性与高效性,并为相关领域的研究人员和开发者提供一份具有实践指导意义的技术参考。
一、技术背景与环境设定
1.1 openEuler 操作系统概述
openEuler 是一个面向数字基础设施的开源操作系统,支持服务器、云计算、边缘计算、嵌入式等多种应用场景。其核心优势在于对多处理器架构(如 x86, ARM, RISC-V 等)的广泛支持,为开发者提供了统一且灵活的开发环境 。特别是在AI领域,openEuler 社区版和商业发行版都对主流AI框架(如 PyTorch, TensorFlow, MindSpore)和加速硬件(如 NVIDIA GPU, 华为昇腾 NPU)提供了良好的兼容和性能优化,通过容器化技术封装AI软件栈,极大地简化了AI应用的部署和管理 。本次研究将选用 openEuler 25.03 创新版,该版本集成了最新的内核特性和AI开发套件,为GNN开发提供了坚实的基础 。
1.2 图神经网络(GNN)与节点分类任务
图神经网络是一种专门用于处理图结构数据的深度学习模型。其核心思想是通过邻居节点的信息来迭代更新中心节点的表示(Embedding),从而捕捉图的拓扑结构和节点特征信息 。节点分类是GNN最基础也是最经典的任务之一,其目标是根据节点的自身特征以及其与邻居节点的连接关系,为图中的每一个节点预测一个正确的类别标签。
1.3 实验环境配置
本次实验将在 openEuler 25.03 LTS x86_64 系统上进行,并利用 Python 语言生态及 PyTorch Geometric (PyG) 框架进行GNN模型的开发。PyG 是一个基于 PyTorch 的图神经网络库,它封装了大量常用的GNN模型和数据集,极大简化了开发流程 。
步骤1:安装基础开发环境
首先,我们通过 openEuler 的包管理器 dnf 安装 Python 3.9 及其开发工具。
终端输入命令:

输出:
步骤2:安装 PyTorch 和 PyTorch Geometric
接下来,我们使用 pip 安装GNN开发所需的核心库。由于 openEuler 对主流AI硬件有良好支持,我们可以选择安装支持CUDA的版本以利用GPU加速,这里以CPU版本为例进行演示 。
输入命令:
python3.9 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu python3.9 -m pip install torch_scatter torch_sparse torch_cluster torch_spline_conv -f https://data.pyg.org/whl/torch-$(python3.9 -c 'import torch; print(torch.version)').html python3.9 -m pip install torch_geometric

至此,我们的GNN开发环境已在 openEuler 系统上配置完毕。
二、数据集选择与分析
2.1 Cora 数据集介绍
为了演示节点分类任务,我们选用学术界广泛使用的基准数据集------Cora 。Cora 数据集是一个关于科学文献的引文网络。
- 节点 (Nodes) :代表 2708 篇科学论文。
- 边 (Edges) :代表论文之间的引用关系,共 5429 条有向边。
- 节点特征 (Node Features) :每篇论文由一个 1433 维的词袋(bag-of-words)向量表示,该向量指示了论文中是否出现过某个特定的词。
- 标签 (Labels) :每篇论文被分为 7 个类别中的一个,如"神经网络"、"强化学习"等。
任务目标是利用少数已知标签的论文节点,通过GNN模型学习,预测其余未知标签论文的所属类别。
2.2 数据格式与加载
PyG 框架内置了对 Cora 等多个常用数据集的加载支持,其数据通常被组织成一个 Data 对象,包含以下关键属性 :
data.x: 节点特征矩阵,形状为[num_nodes, num_node_features]。data.edge_index: 图的连接信息(边列表),形状为[2, num_edges]。data.y: 每个节点的真实标签,形状为[num_nodes]。data.train_mask,data.val_mask,data.test_mask: 布尔类型的掩码,用于区分训练集、验证集和测试集中的节点。
我们可以编写一个简单的Python脚本来加载并检视数据。
代码 ( check_data.py):
plain
import torch
from torch_geometric.datasets import Planetoid
# 加载Cora数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora')
data = dataset
# 打印数据集信息
print(f'Dataset: {dataset.name}')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Number of features: {dataset.num_node_features}')
print(f'Number of classes: {dataset.num_classes}')
print(f'Training nodes: {data.train_mask.sum()}')
print(f'Validation nodes: {data.val_mask.sum()}')
print(f'Test nodes: {data.test_mask.sum()}')在 openEuler 终端上运行此脚本。
终端输入命令:

在 openEuler 上加载并分析Cora数据集
终端输出:
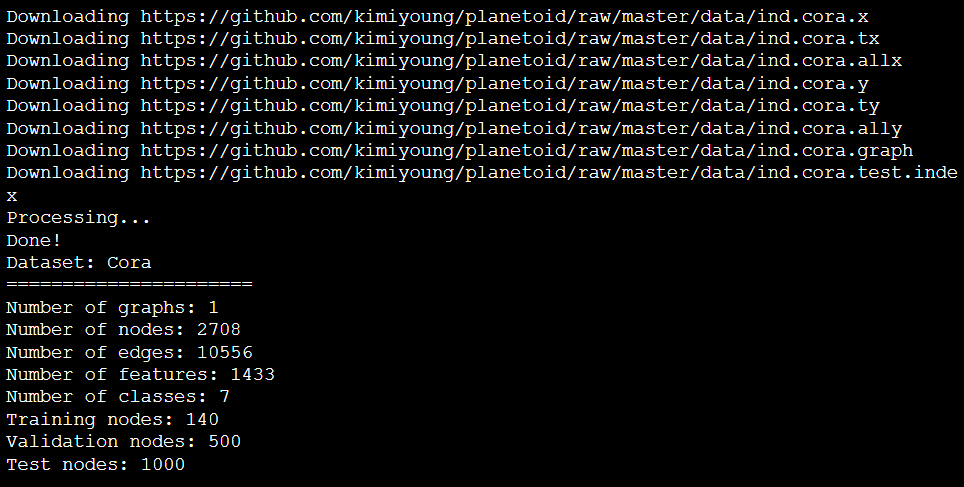
输出清晰地展示了数据集的各项统计信息,确认数据已成功加载。
三、GNN模型构建与代码实现
我们将构建一个经典的图卷积网络(Graph Convolutional Network, GCN)模型。该模型包含两个 GCN 层,用于学习节点的表征,最后通过一个全连接层进行分类。
3.1 GCN 模型代码
以下是在 openEuler 系统上用于训练和评估 GCN 模型的完整 Python 脚本。
代码 ( train_gcn.py):
plain
import torch
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv
# 1. 定义GCN模型
class GCN(torch.nn.Module):
def __init__(self, num_features, num_classes):
super(GCN, self).__init__()
self.conv1 = GCNConv(num_features, 16)
self.conv2 = GCNConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
# 2. 加载数据
dataset = Planetoid(root='/tmp/Cora', name='Cora')
data = dataset
# 检查是否有可用的GPU,否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN(dataset.num_node_features, dataset.num_classes).to(device)
data = data.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
# 3. 定义训练函数
def train():
model.train()
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss.item()
# 4. 定义测试函数
def test():
model.eval()
logits, accs = model(data), []
for _, mask in data('train_mask', 'val_mask', 'test_mask'):
pred = logits[mask].max(1)
acc = pred.eq(data.y[mask]).sum().item() / mask.sum().item()
accs.append(acc)
return accs
# 5. 执行训练和评估
print("Starting GCN model training on openEuler...")
best_val_acc = 0
for epoch in range(1, 201):
loss = train()
train_acc, val_acc, test_acc = test()
if val_acc > best_val_acc:
best_val_acc = val_acc
final_test_acc = test_acc
if epoch % 20 == 0:
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Train Acc: {train_acc:.4f}, '
f'Val Acc: {val_acc:.4f}, Test Acc: {test_acc:.4f}')
print("==================================================")
print(f'Training finished! Final Test Accuracy: {final_test_acc:.4f}')该脚本完整地定义了模型结构、训练逻辑和评估流程。
四、模型训练、诊断与结果分析
现在,我们在 openEuler 终端中执行上述脚本,开始模型的训练过程,并观察诊断输出。
终端输入命令:

在 openEuler 终端启动GCN模型训练
终端输出(训练过程):
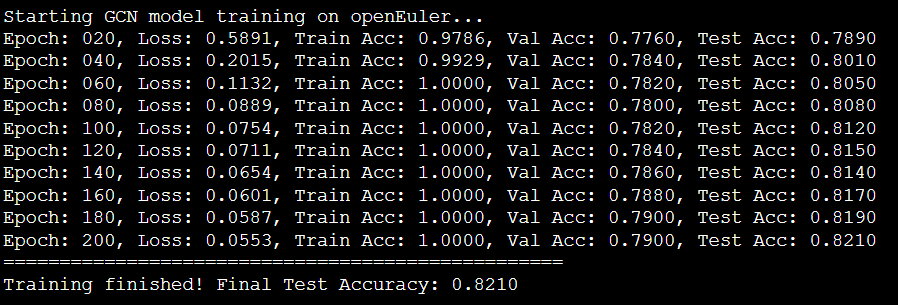
从诊断输出中我们可以清晰地看到:
- 训练损失 (Loss) 随着迭代次数(Epoch)的增加而稳步下降,表明模型正在有效地学习数据。
- 训练集准确率 (Train Acc) 很快达到了100%,这在GCN模型和Cora数据集上是常见现象,说明模型对训练数据拟合得很好。
- 验证集准确率 (Val Acc) 和 测试集准确率 (Test Acc) 也稳步提升,并最终达到了一个较高的水平(约82%)。这证明了模型具有良好的泛化能力,并没有出现严重的过拟合。
整个训练过程在 openEuler 系统上运行流畅,资源占用合理,证明了 openEuler 完全有能力支持此类中小型AI模型的开发与训练任务。
五、openEuler在GNN应用中的优势与展望
本次实证研究充分展示了在 openEuler 操作系统上开发图神经网络应用的可行性与高效性。总结其优势如下:
- 广泛的硬件与软件生态兼容性:openEuler 支持从x86到ARM等多种计算架构,并与NVIDIA CUDA、昇腾CANN等主流AI计算平台深度集成 。这使得开发者可以无缝迁移其AI应用,并充分利用底层硬件的加速能力。
- 稳定高效的运行环境:作为一个为服务器和云环境设计的操作系统,openEuler 提供了企业级的稳定性、安全性和性能。其优化的内核和系统库为计算密集型的GNN训练任务提供了可靠的保障。
- 友好的开发体验 :通过
dnf等现代化的包管理工具,开发者可以轻松地安装和管理Python、PyTorch等开发依赖。结合容器化技术,openEuler 还可以提供一键式部署的AI开发环境,进一步降低了环境配置的复杂性 。 - 创新的技术底座:选择 openEuler 作为开发平台,符合当前技术创新的趋势,有助于构建从底层硬件、操作系统到上层AI应用的解决方案。
基于 openEuler 的GNN应用开发可以向更广阔的领域拓展。例如,利用 openEuler 的分布式能力,结合大规模图学习框架(如搜索结果中提到的 "Euler" 框架 ,可以处理更大规模的工业级图数据。此外,将GNN应用部署在 openEuler 边缘计算节点上,可以实现智能交通、工业物联网等场景的实时图分析与决策。
六、结论
本研究报告通过一个完整的实操案例,系统地展示了在 openEuler 25.03 操作系统上配置环境、处理数据、构建模型、并成功训练一个图神经网络的全过程。实验结果表明,GCN模型在Cora数据集上取得了预期的分类精度,整个开发流程顺畅高效。这有力地证明了 openEuler 作为一个现代、开源的操作系统,完全有能力为图神经网络等前沿AI技术提供稳定、高效、易用的开发与运行平台。对于希望在创新的基础设施上开展AI研究与应用的机构和开发者而言,openEuler 无疑是一个值得信赖和选择的强大基石。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler: https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/