在当今的大模型(LLM)应用中,"流式输出"(Streaming)已经成为标配。用户不再愿意盯着空白屏幕等待几秒甚至几十秒后的"一次性全量回复",而是希望像看着对方打字一样,实时看到思维的流淌。
本文将结合 Vue 3、Fetch API 以及底层的二进制编码知识,带你从零构建一个类似 ChatGPT 的流式对话 Demo,并深入解析其背后的技术细节。
一、 溯源:一切皆为二进制 (Buffer)
在进入 Vue 和 AI 之前,我们需要补一课:浏览器是如何处理数据的?
我们在屏幕上看到的"你好",在计算机底层和网络传输中,本质上都是二进制(0和1)。当后端大模型一点点"吐"出数据时,浏览器接收到的不是完整的字符串,而是字节流。
1.1 编码与解码 (Encoder & Decoder)
HTML5 提供了原生的 API 来处理这种转换,这比传统的字符操作更高效。让我们看一段底层的实验代码(源自 buffer.html):
JavaScript
// 1. 编码:字符串 -> Uint8Array (二进制)
const encoder = new TextEncoder();
const myBuffer = encoder.encode("你好 HTML5");
console.log(myBuffer);
// 输出: Uint8Array(10) [228, 189, 160, 229, 165, 189, 32, 72, 84, 77, 76, 53]
// 注意:中文通常占3个字节,英文占1个字节
// 2. 解码:ArrayBuffer -> 字符串
const decoder = new TextDecoder();
const originalText = decoder.decode(myBuffer);
console.log(originalText); // 输出: "你好 HTML5"1.2 缓冲区 (ArrayBuffer) 与视图 (View)
在处理流式数据时,我们经常听到 Buffer 这个词。ArrayBuffer 代表内存中一段固定长度的原始二进制数据缓冲区。
JavaScript
// 创建一个 12 字节的缓冲区
const buffer = new ArrayBuffer(12);
// 我们不能直接操作 ArrayBuffer,必须通过"视图(View)"
const view = new Uint8Array(buffer);
// 将之前编码的数据逐个字节写入缓冲区
for(let i = 0; i < myBuffer.length; i++){
view[i] = myBuffer[i];
}为什么要懂这个?
因为在使用 fetch 获取流式响应时,reader.read() 读出来的 value 正是 Uint8Array。如果我们不懂解码,看到的就是一堆乱码数字。
二、 架构:Vue 3 响应式驱动
接下来,我们进入应用层。利用 Vue 3 的 Composition API,我们可以轻松实现数据驱动的 UI 更新。
2.1 核心响应式数据
在 App.vue 中,我们定义了应用的状态:
JavaScript
import { ref } from 'vue';
// 双向绑定:用户的问题
let question = ref('讲一个喜羊羊和灰太狼的故事,20字');
// 单向流:是否开启流式模式
const stream = ref(true);
// 核心展示:AI 的回复内容
const content = ref(''); 2.2 数据流向
- 输入: 通过
v-model="question"将 Input 框与变量绑定。 - 触发: 点击按钮调用
askLLM函数。 - 输出: AI 的回复被追加到
content.value中,Vue 的响应式系统会自动检测变化并更新 DOM。
三、 核心深潜:处理 SSE (Server-Sent Events) 风格的流
这是本文最核心的部分。如何将大模型返回的 continuous stream 转换成屏幕上的文字?
通常 LLM 的流式接口(如 DeepSeek, OpenAI)采用类似 Server-Sent Events (SSE) 的格式,数据长这样:
Plaintext
data: {"choices":[{"delta":{"content":"喜"}}]}
data: {"choices":[{"delta":{"content":"羊"}}]}
data: {"choices":[{"delta":{"content":"羊"}}]}
data: [DONE]我们需要处理三个挑战:
- 网络分片(Chunking): 网络不是按行发送的,一个数据包可能包含半行 JSON,或者两行半 JSON。
- 解码: 将二进制流转为文本。
- 解析: 提取 JSON 中的
content字段。
3.1 开启流式读取
首先,发起请求并获取读取器:
JavaScript
const response = await fetch(endpoint, {
method: 'POST',
headers,
body: JSON.stringify({
model: 'deepseek-chat',
stream: true, // 关键:告诉服务器我要流式
messages: [{ role: 'user', content: question.value }]
})
});
// 获取 ReadableStream 的读取器
const reader = response.body?.getReader();3.2 复杂的读取与拼接逻辑 (Buffer 机制)
这里有一个极其重要的缓冲区处理逻辑 (注意代码中的 buffer 变量)。由于 TCP 分包的存在,我们可能会收到截断的 JSON 字符串。
错误场景模拟:
假设服务器发送 {"content": "hello"},但网络原因,我们分两次收到:
- 第一次收到:
{"con - 第二次收到:
tent": "hello"}
如果直接 JSON.parse("{"con") 肯定会报错。所以我们需要一个临时字符串 buffer 来拼接。
深度代码解析:
JavaScript
const decoder = new TextDecoder();
let buffer = ''; // 这里的 buffer 是字符串缓存,用于处理分片
let done = false;
while (!done) {
// 1. 读取原始二进制数据
const { value, done: doneReading } = await reader?.read();
done = doneReading;
// 2. 解码并追加到临时 buffer
// chunkValue 可能包含上一次循环遗留的半截数据 + 本次新收到的数据
const chunkValue = buffer + decoder.decode(value, { stream: true });
// 3. 按行分割 (SSE 协议通常以 \n 分隔事件)
// 这里的逻辑有点巧妙:它先把 buffer 清空,准备存处理失败的碎片
buffer = '';
const lines = chunkValue.split('\n').filter(line => line.startsWith('data: '));
for (const line of lines) {
const incoming = line.slice(6); // 去掉 "data: " 前缀
if (incoming === '[DONE]') {
done = true;
break;
}
try {
// 4. 尝试解析 JSON
const data = JSON.parse(incoming);
const delta = data.choices[0].delta.content;
if (delta) {
// 5. 成功解析,上屏!
content.value += delta;
}
} catch (err) {
// 6. 关键容错:解析失败说明数据不完整(被截断了)
// 将这行残缺的数据放回 buffer,等待下一次循环拼接
buffer += `data: ${incoming}`;
}
}
}3.3 流程图解
为了更直观地理解这个过程:
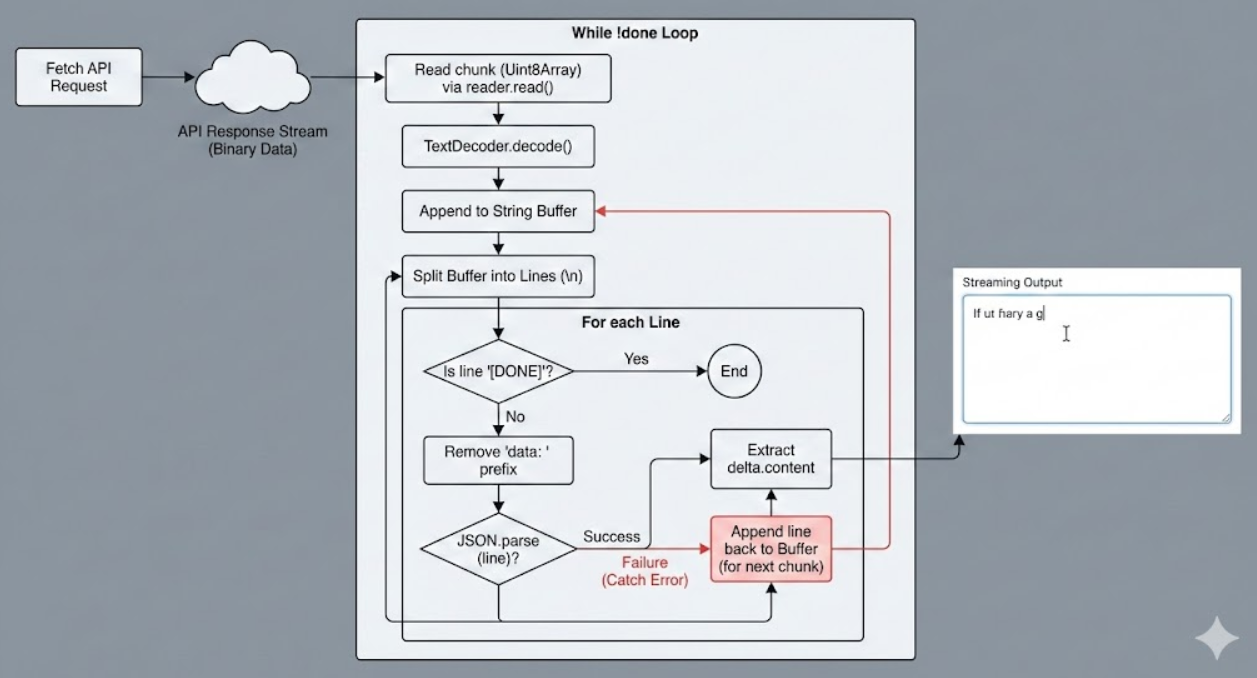
四、 总结:从 Demo 到生产环境
通过 buffer.html 我们理解了数据的本质是二进制,通过 App.vue 我们实现了复杂的流式解析逻辑。
核心知识点回顾:
- 用户体验 (UX): 流式输出极大地降低了用户的感知延迟(Perceived Latency)。
- Fetch API: 使用
response.body.getReader()能够访问底层网络流,而不是等待整个 Body 下载完成。 - 二进制处理:
TextDecoder是连接网络二进制流和 JS 字符串的桥梁。 - 鲁棒性解析: 网络传输的不确定性要求我们在前端必须实现"拼接-尝试解析-回退缓存"的机制,以防止 JSON 解析错误导致程序崩溃。
五、流式输出全代码示例
js
<script setup>
import { ref } from 'vue';
// v-model 指令,响应式绑定表单的数据
// v-model 双向数据绑定指令
// v-model 绑定 question stream 变量
let question = ref('讲一个喜羊羊和灰太狼的故事,20字');
const stream = ref(true);
const content = ref('') // 单向绑定,常用的
// 调用大模型
const askLLM = async () => {
if (!question.value) {
console.log('question 不能为空');
return;
}
// 用户体验
content.value = '思考中...';
// 请求行
// 请求头
// 请求体
const endpoint = 'https://api.deepseek.com/chat/completions';
const headers = {
'Authorization': `Bearer ${import.meta.env.VITE_DEEPSEEK_API_KEY}`,
'Content-Type': 'application/json'
}
const response = await fetch(endpoint, {
method: 'POST',
headers,
body: JSON.stringify({
model: 'deepseek-chat',
stream: stream.value,
messages: [
{
role: 'user',
content: question.value
}
]
})
})
if(stream.value){
// 流式输出
content.value = ""; // 把上次的生成清空
// HTML5 流式响应体
// 响应体的读对象
const reader = response.body?.getReader();
// 流出来的是二进制流 buffer
const decoder = new TextDecoder();
let done = false; // 流是否结束,没有
let buffer = '';
while(!done) {
// 只要没有完成,就一直拼接buffer
// 解构重命名,外面有同名done,这里重命名为doneReading
const { value, done: doneReading } = await reader?.read();
console.log(value, doneReading);
done = doneReading;
// chunk 内容块 包含多行data: 有多少行不确定
// data: {} 能不能传完也不确定
const chunkValue = buffer + decoder.decode(value); // 字符串
console.log(chunkValue);
buffer = '';
const lines = chunkValue.split('\n').filter((line => line.startsWith('data: ')));
for(const line of lines){
const incoming = line.slice(6); // 干掉数据标志 data:
if(incoming === '[DONE]'){
done = true;
break;
}
try{
// 大模型流式生成,tokens 长度不定的
const data = JSON.parse(incoming);
const delta = data.choices[0].delta.content;
if(delta){
content.value += delta;
}
}catch(err){
// JSON.parse 解析失败
buffer += `data: ${incoming}`
}
}
}
}
else{
const data = await response.json();
console.log(data);
content.value = data.choices[0].message.content;
}
}
</script>
<template>
<div class="container">
<div>
<label>输入: </label>
<input class="input" v-model="question" />
<button @click="askLLM">提交</button>
</div>
<div class="output">
<div>
<label>Streaming</label>
<input type="checkbox" v-model="stream" />
<div>{{ content }}</div>
</div>
</div>
</div>
</template>
<style scoped>
* {
margin: 0;
padding: 0;
}
.container {
display: flex;
/* 主轴、次轴 */
flex-direction: column; /* 设置主轴 */
align-items: start; /* 次轴对齐方式 */
justify-content: start; /* 主轴对齐方式 */
height: 100vh;
font-size: 0.85rem;
}
.input {
width: 200px;
}
button {
padding: 0 10px;
margin-left: 6px;
}
.output{
margin-top: 10px;
min-height: 300px;
width: 100%;
text-align: left;
}
</style>