概述
本文发表于2023年。聚焦3D-Visual Language Grounding(视觉-语言接地),提出了一种用于3D视觉与文本对齐的已经预训练过的Transformer(1),并构建了首个用于3D-VL预训练的大规模3D场景-文本数据集scanscribe数据集(2)。scanscribe包括来自原有大型数据集scannet和3rscan数据集,并由gpt生成场景的描述。
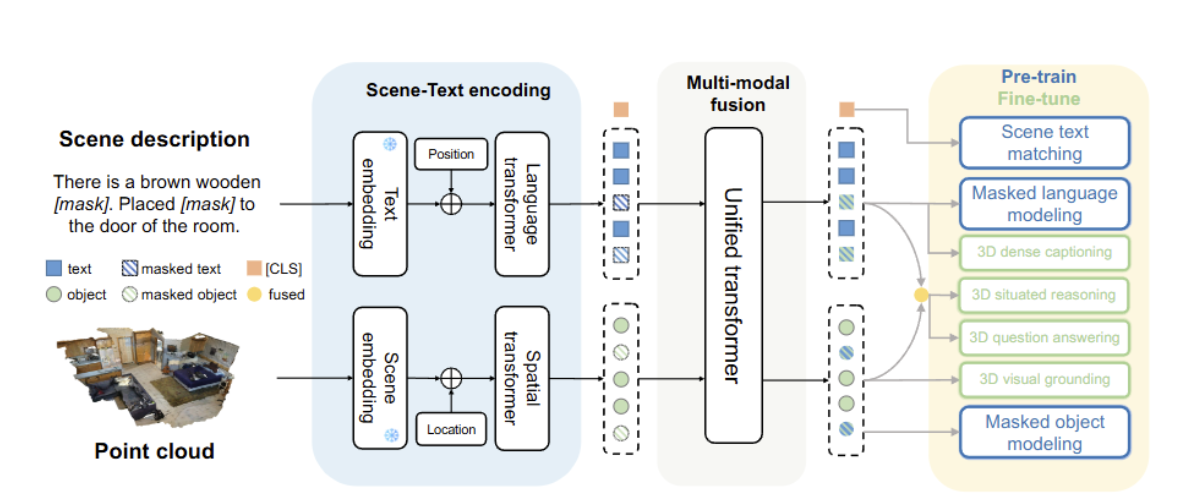
3D-VisTA通过掩码语言/对象建模和场景-文本匹配,在ScanScribe上进行与训练。
引言
难点:大多数为3D视觉语言接地开发的模型仅仅专注于任务中的一两个(如仅关注视觉语言特征/视觉定位/密集captioning/问答/情景推理/语法学习),缺乏统一。
Dense Captioning:在一张图片(或视频帧)中,*同时定位多个区域(Region Proposals)并为每个区域生成独立的文字描述(caption)的任务。
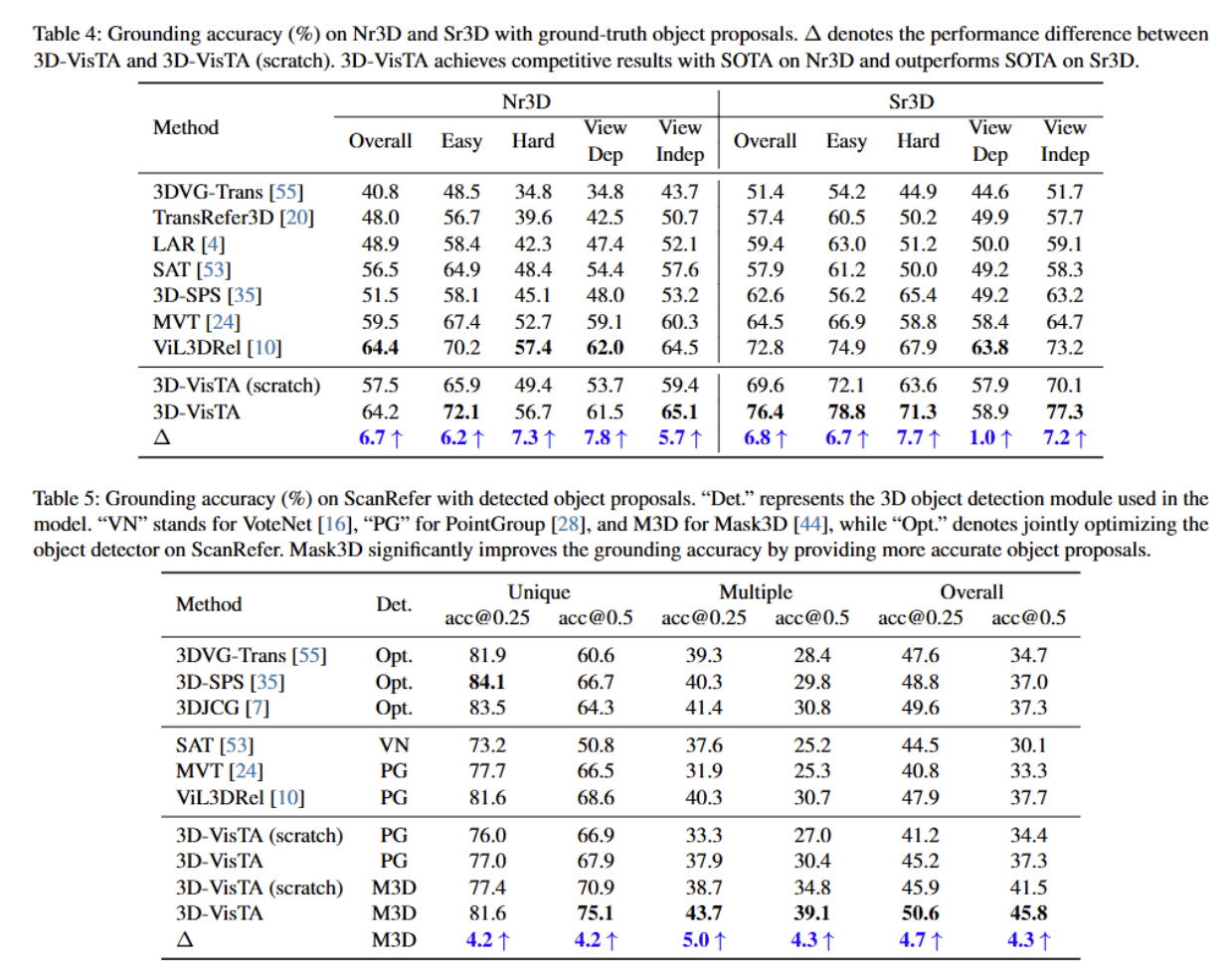
涉及的3D-VL任务及其对应的数据集上的结果:
视觉接地(ScanRefer提升8.1%、Nr3D/Sr3D提升3.6%)
问答(ScanQA提升10.1%)
情境推理(SQA3D提升1.9%)
3D-VisTA
输入:场景点云+句子---(通过场景编码模块处理点云)--->文本/3D对象标记----->通过一个多模态融合模块进行融合,捕捉3D物体和文本之间的对应关系。
1. 场景编码
给定三维场景的点云 ,使用分割掩码将场景分解为对象。
分割掩码获取方式:
(1)真实标签
(2)实例分割模型
对每个对象,采样1024个点,将其坐标归一化到单位球内。
然后将点云 输入得到PointNet++中,获取其点特征 、语义类别。
组合点特征、语义类别、嵌入、三维位置,作为对象标记的表示,通过将物体令牌注入一个4层Transformer捕捉物体之间的交互。将物体的成对的空间关系明确编码到空间Transformer中。

2. 实验设置
epoch:30
batchsize:128
learning rate:1e-4
预热步数:3000,采用余弦衰减,AdamW优化器,β1=0.9 β2=0.98