这一节课开始,我们进入第二模块的学习:Node.js 的运行时。
第一模块我带你了解了什么是 Node.js,以及 Node.js 支持的两种模块管理规范和它内置的包管理工具(NPM)。我们说过,Node.js 提供了能够让 JavaScript 操作 PC 系统的运行时环境。
那第二模块我们就来学习如何使用 Node.js 开发 PC 小应用:随机文章生成器。通过这个应用,你将了解 node 环境下如何使用 fs、process、readline 模块,如何创建自己的模块,以及如何安装并引入第三库。
首先,我们来了解一下这个应用的需求:随机文章生成器的功能是能根据语料库的配置和用户输入的规则,随机生成一篇可长可短的文本,里面的内容语句通顺,但是废话连篇。
生成这样的文本,在 Web 开发中可以被用来测试布局和网页内容在特定数量时页面呈现的效果,也可以用来测试数据库或文件的读写,或者纯粹作为娱乐项目以图一乐。如果你关注 GitHub,你可能知道最近有个类似的应用很火,叫做《狗屁不通文章生成器》,我们就模仿它来写一个类似的生成器,对它的不足之处也会有一些改进。

狗屁不通文章生成器网页版效果
文章生成器的产品原型非常简单,就是用户设定主题和字数,应用根据内置的语料库,按照规则自动生成一篇随机的文章。
我们可以画一下它的大致流程:
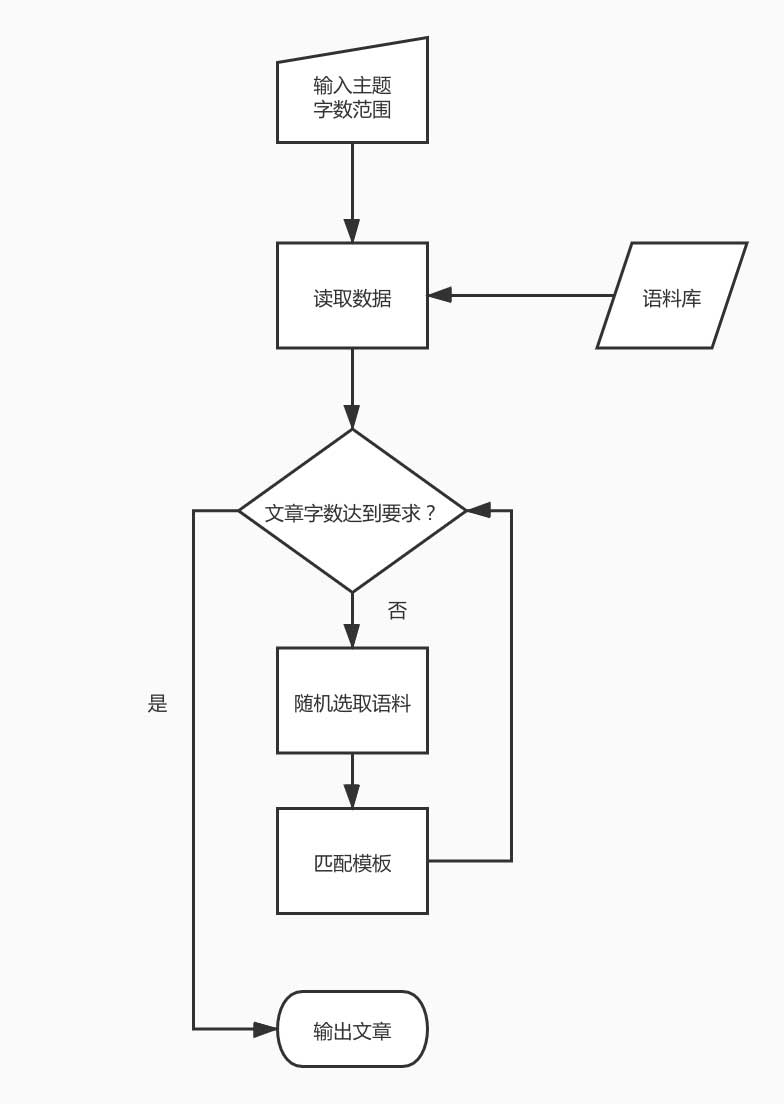
所以我们需要实现以下功能:
- 读取语料库并解析;
- 随机选取语料的随机算法;
- 字符串模板的参数替换;
- 文章内容的拼装;
- 生成文章输出。
如果再考虑到用户交互,我们还要完成:
- 接收命令行输入的参数;
- 提供给用户命令行使用指引;
- 输出文本内容的格式和存储。
总的来说,对应的技术点如下:
- 利用 fs 模块读取语料库文件内容;
- 实现一个随机模块,提供符合要求的随机算法;
- 使用正则表达式和字符串模板替换以及字符串拼接,完成文章生成;
- 使用 process.argv 接收用户参数,根据参数输出不同内容;
- 利用 fs 模块、二进制模块,将生成的文本内容保存成文本和图片格式。
我们新建项目,叫bullshit_generator,项目目录结构如下:
.
├── corpus
│ └── data.json
├── index.js
├── lib
│ ├── generator.js
│ └── random.js
├── package.json
└── outputcorpus 存放语料库文件,这是一份 json 文件,文件名 data.json。index.js 是项目主文件,是一个可以运行的 Node.js 脚本。lib目录下是项目依赖的库文件,这里我们不依赖外部的库,自己实现两个模块,一个是 generator.js 模块,用来生成文章内容,另一个是随机模块,用来提供随机算法。
package.json是项目的配置文件。output存放项目输入结果。在后面的几节课中,我们就来使用上面的技术点实现我们的文章生成器应用。
这一节课,我们先带你了解 Node.js 文件模块的使用,利用 fs 模块读取我们的语料库。先来看看语料库的内容,它是一份 JSON 文件,大致内容如下:
{
"title": [
"一天掉多少根头发",
"中午吃什么",
...
],
"famous":[ // 名人名言
"爱迪生{{said}},天才是百分之一的勤奋加百分之九十九的汗水。{{conclude}}",
"查尔斯·史{{said}},一个人几乎可以在任何他怀有无限热忱的事情上成功。{{conclude}}",
"培根说过,深窥自己的心,而后发觉一切的奇迹在你自己。{{conclude}}",
...
],
"bosh_before": [
"既然如此,",
"那么,",
"我认为,",
...
],
"bosh":[
"{{title}}的发生,到底需要如何做到,不{{title}}的发生,又会如何产生。 ",
"而这些并不是完全重要,更加重要的问题是,",
"{{title}},到底应该如何实现。 ",
...
],
"conclude":[
"这不禁令我深思。 ",
"带着这句话,我们还要更加慎重的审视这个问题: ",
"这启发了我。",
...
],
"said":[
"曾经说过",
"在不经意间这样说过",
"说过一句著名的话",
...
]
}这份文件里面一共有六个字段,title 表示文章的主题,famous 表示名人名言,bosh_before 表示废话的前置分句,bosh 表示废话的主体,conclude 表示结论,said 是名人名言中可选的文字片段。
根据上一节课的目录结构,我们将这份文件保存在项目的corpus目录下。
我们这个项目采用 ES Modules 模块规范,所以我们先在 package.json 中配置一下type: module。接着创建index.js文件,准备从项目中读取这份语料库配置。
fs 内置模块
读取文件内容可以采用fs内置模块。我们先试一下,在项目目录下创建 index.js 文件,写入以下内容:
import fs from 'fs';
console.log(fs);上面的代码可以打印出 fs 模块的所有 API:
{
appendFile: [Function: appendFile],
appendFileSync: [Function: appendFileSync],
access: [Function: access],
...
read: [Function: read],
readSync: [Function: readSync],
readFile: [Function: readFile],
readFileSync: [Function: readFileSync],
...
promises: [Getter]
}我们会看到这个模块有非常多的 API,读取文件的内容用到两个 API:
- readFile 异步地读取文件内容
- readFileSync 同步地读取文件内容
我们分别来试一下它们的用法,修改 index.js 代码,引入 readFile API:
import {readFile} from 'fs';
readFile('./corpus/data.json', (err, data) => {
if(!err) {
console.log(data);
} else {
console.error(err);
}
});readFile是异步方法,第一个参数是要读取的文件的路径,第二个参数可以是一个回调函数,当文件读取成功或读取失败时,readFile都会回调这个函数,根据不同的情况返回不同的内容。如果成功,返回的err为 null,data为实际文件内容;否则,err为一个包含了错误信息的对象。
我们在项目目录下运行index.js,看到控制台输出结果:
<Buffer 7b 0a 20 20 22 74 69 74 6c 65 22 3a 20 5b 0a 20 20 20 20 22 e4 b8 80 e5 a4 a9 e6 8e 89 e5 a4 9a e5 b0 91 e6 a0 b9 e5 a4 b4 e5 8f 91 22 2c 0a 20 20 20 ... 14204 more bytes>可以看到,输出的内容不是文本内容,而是 Buffer 对象,表示文件的二进制数据内容。想要将二进制内容转变成文本信息,有两个做法。
第一个我们可以直接调用 data 的 toString 方法,传入utf-8,我们修改代码:
import {readFile} from 'fs';
readFile('./corpus/data.json', (err, data) => {
if(!err) {
console.log(data.toString('utf-8'));
} else {
console.error(err);
}
});这样就可以获得 JSON 文件的文本内容了。此外,另一个办法是我们可以在readFile方法中多传一个参数:
import {readFile} from 'fs';
readFile('./corpus/data.json', {encoding: 'utf-8'}, (err, data) => {
if(!err) {
console.log(data);
} else {
console.error(err);
}
});如上面代码所示,我们在回调函数前多传一个参数{encoding: 'utf-8'}这样就能在读取文件的时候默认使用utf-8编码得到文件内容了。
readFile是异步读取文件内容,如果我们读取的文件很大,又不希望阻塞后续的操作,可以使用这个方法。但是如果文件不大,更简单的方式是使用readFileSync方法。这个方法与readFile用法相似,却是同步读取文件,不需要异步,使用上会更简单。
我们修改一下上面的代码,使用readFileSync来读取文件:
import {readFileSync} from 'fs';
const data = readFileSync('./corpus/data.json', {encoding: 'utf-8'});
console.log(data);我们看到,使用readFileSync和readFile差不多,不过我们不再需要 callback 函数,可以直接通过readFileSync的返回值获取内容。
到这里,读取文件内容的功能我们就实现了,但是它还有一点问题。
文件路径问题
在上面的代码里,我们通过路径./corpus/data.json来读取文件,如果我们在项目根目录运行index.js,这没有问题。但是,如果我们从其他目录执行它会如何呢?
我们到bullshit_generator的上一级目录去运行:
cd ..
node ./bullshit_generator/index.js这时我们的命令报错了:
fs.js:461
handleErrorFromBinding(ctx);
^
Error: ENOENT: no such file or directory, open './corpus/data.json'
at Object.openSync (fs.js:461:3)
at readFileSync (fs.js:363:35)
at file:///Users/akirawu/Workspace/junyux/bullshit_generator/index.js:3:14
at ModuleJob.run (internal/modules/esm/module_job.js:110:37)
at async Loader.import (internal/modules/esm/loader.js:167:24) {
errno: -2,
syscall: 'open',
code: 'ENOENT',
path: './corpus/data.json'
}上面的错误信息是./corpus/data.json文件不存在。
这是因为,我们使用的相对路径./corpus/data.json是相对于脚本的运行目录(即,node执行脚本的目录),而不是脚本文件的目录。所以当我们在bullshit_generator当前目录运行时,读取的文件路径是bullshit_generator目录下的/corpus/data.json,这没有问题。如果我们在上一级目录运行它时,读取的文件路径实际变成了../bullshit_generator目录下的/corpus/data.json,因为这个路径下文件不存在,这样就找不到文件了。这也就意味着,如果使用相对路径./,我们在不同的目录下运行脚本命令,./corpus/data.json实际上表示的是不同的文件路径。
要让这个命令在任何目录下运行都能正确找到文件,我们必须要修改路径的方式,从相对于脚本运行的目录改为相对于脚本文件的目录。
我们修改代码:
import {readFileSync} from 'fs';
import {fileURLToPath} from 'url';
import {dirname, resolve} from 'path';
const url = import.meta.url; // 获取当前脚本文件的url
const path = resolve(dirname(fileURLToPath(url)), 'corpus/data.json');
const data = readFileSync(path, {encoding: 'utf-8'});
console.log(data);我们先来看看这段代码中具体做了什么。
首先,import.meta.url表示获得当前脚本文件的 URL 地址,因为ES Modules是通过 URL 规范来引用文件的(这就统一了浏览器和 Node.js 环境),所以对于我们这个项目来说,这个地址是形如下面这样的:
file:///.../bullshit_generator/index.js其次,url是 Node.js 的内置模块,用来解析 url 地址。fileURLToPath是这个模块的方法,可以将 url 转为文件路径。然后再通过内置模块path的dirname方法就可以取到当前 JS 文件目录。
最后,path是 Node.js 处理文件路径的内置模块。dirname和resolve是它的两个方法,dirname方法可以获得当前 JS 文件的目录,而resolve方法可以将 JS 文件目录和相对路径corpus/data.json拼在一起,最终获得正确的文件路径。
const path = resolve(dirname(fileURLToPath(url)), 'corpus/data.json');这条语句表示将当前脚本文件的 url 地址转化成文件路径,然后再通过 resolve 将相对路径转变成 data.json 文件的绝对路径。这样不论在哪个路径下运行index.js,都能成功读取到data.json文件了。
💡注意,因为本项目采用ES Modules模块规范,所以需要通过fileURLToPath来转换路径。如果采用CommonJS规范,就可以直接通过模块中的内置变量__dirname获得当前 JS 文件的工作目录。因此在使用CommonJS规范时,上面的代码可以简写为const path = resolve(__dirname, 'corpus/data.json')。
到目前为止,我们成功读取了文件的字符串内容,要将它转成 JSON 对象使用,我们只需要调用 JSON.parse 即可:
const corpus = JSON.parse(data);之后的课程中,我们还会使用这个 JSON 文件来生成文章,所以你一定要确保自己已经完成这一步了。
总结
这一节,我们学习了如何用 fs 模块读取文件内容。fs 模块中有两个方法可以方便地读取出文件内容,一个是readFile,一个是readFileSync,前者是异步方法,后者是同步方法,使用起来都不复杂。不过需要注意的是,为了准确读取到文件,我们需要处理好文件的路径,这个可以通过使用url和path模块来完成。
fs、url和path都是 Node.js 比较常用的内置模块包。fs模块包除了readFile和readFileSync外,比较常用的子模块和 API 还有如下这些。
- fs.dir:操作目录的子模块,提供
dir.read、dir.readSync等 API 来读取目录信息。
- fs.createReadStream():创建一个读文件流对象。
- fs.createWriteSteam():创建一个写文件流对象。
- fs.stat()、fs.statSync():读取文件信息,包括文件状态、权限、创建时间、修改时间等等信息。
- fs.appendFile()、fs.appendFileSync():追加内容到文件
- fs.chmod()、fs.chown():改变文件权限、权限组。
- fs.copyFile()、fs.copyFileSync():拷贝文件。
- fs.mkdir()、fs.mkdirSync():创建目录。
- fs.rename()、fs.renameSync():修改文件名。
- fs.rmdir()、fs.rmdirSync():删除目录。
- fs.unlink()、fs.unlinkSync():删除文件。
- fs.watchFile():这是用来监听文件内容变化的 API。
- fs.writeFile()、fs.writeFileSync():写入文件。
url模块主要用来处理 URL 地址,除了我们用到的fileURLToPath外,它可以通过new URL创建一个 URL 对象,然后访问这个对象的 protocal、hostname、port、origin、pathname、query、hash 等等属性,拿到 URL 上的各部分信息。
path模块主要用来处理文件路径,除了我们用到的dirname、resolve外,还有basename()、extname()、join()、format()等等方法,可以解析 path 路径的各个部分,以及拼接文件路径或者将对象内容格式化为文件路径。
这三个模块都是常用模块,我们后续课程中还会用到,到时候会针对用到的部分做进一步的详细说明。关于这三个内置模块的其他 API 具体内容,如果你有兴趣可以阅读 Node.js 官方文档。