新专栏包含:基础 + 后续的优化技巧
一、环境配置
1.前置环境安装---miniconda
打开网址https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/:
然后选择py38 或者py10的windows版本(根据自己的电脑类型选择)
双击打开下载好的 exe文件,注意下面两点
• 如果C盘有空间,最好安装在C盘,且安装目录中不要有中文
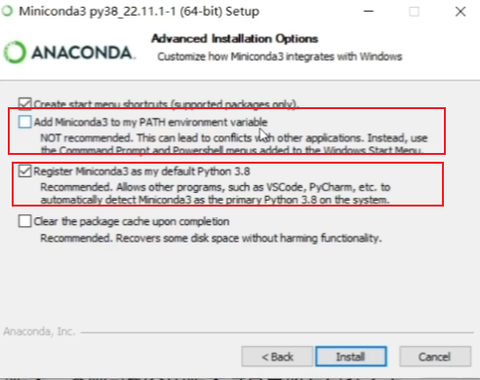
• 勾选将其添加到PATH
把下面的两个选项勾选上
2、conda环境创建
• 命令:conda create -n yolov8 python=3.8 -y
• 明确指定版本,否则可能会因版本过高导致有包装不上
3、pypi配置国内源
• 清华源:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
配置全局默认源:参考官网的指引,把下面的命令输入到命令行即可
python
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple二、前置环境安装---pytorch
• pytorch安装
• 官方地址:https://pytorch.org/
• 在一个单独的环境中,能使用 pip 就尽量使用pip,实在有问题的情况,例如没有合适的编译好的系统版本的安装包,再使用conda进行安装,不要来回混淆

注意:
• CUDA是否要安装
• 如果只需要训练、简单推理,则无需单独安装CUDA,直接安装pytorch;如果有部署需求,例如导出TensorRT模型,则需要进行CUDA安装
• Pytorch安装注意事项
• 16XX的显卡,安装cu102的版本,否则可能训练出现问题
• 30XX、40XX显卡,要安装cu111以上的版本,否则无法运行
三、ultralytics(YOLOv8)安装
• 直接使用源码(不是很推荐,无法使用命令行工具)
• https://github.com/ultralytics/ultralytics
• pip直接安装(官方推荐,个人不是很推荐)
python
pip install ultralytics pip源码安装(个人推荐)
• https://github.com/ultralytics/ultralytics && unzip ultralytics-main.zip && cd ultralytics-main 直接克隆包
python
pip install -e . (-e参数必须要有,否则后续修改代码无效)
输入 pip list,这样的好处就是直接把源码放在了桌面上。如果自己修改源码,看源码就可以直接生效

可以直接修改源码
四、模型预测的基本使用
1. 预测的方式:命令行方式(CLI)
vbscript
yolo task=detect mode=predict model=./yolov8n.pt source="./ultralytics/assets/bus.jpg"2.Python API 方式(推荐)
python
from ultralytics import YOLO
yolo = YOLO("./yolov8n.pt", task="detect") #detect表示检测任务,非必写
result = yolo(source="./ultralytics/assets/bus.jpg",save = True)source里面的source可以改成视频或者自己的显示器
python
result = yolo(source="./XXX.mp4") # 视频
result = yolo(source="screen") # 屏幕
result = yolo(source=0) # 打开摄像头YOLO类的配置的参数在这个 yolo/cfg/default.yaml文件里面
|----------------|------------|-------|--------------------------------------|----------------|
| 参数 | 类型 | 默认值 | 含义 | 使用场景 |
| source | str / list | 必填 | 输入源路径,可以是单张图片、文件夹、视频文件或摄像头 | 所有预测任务必须指定 |
| show | bool | FALSE | 是否实时显示结果(需 GUI 支持) | 调试时查看结果 |
| save_txt | bool | FALSE | 是否保存检测结果为 .txt 文件(类似 COCO 格式) | 需要后处理分析时 |
| save_conf | bool | FALSE | 是否在输出中包含置信度分数 | 需要精确评估模型性能 |
| save_crop | bool | FALSE | 是否保存每个检测框裁剪后的图像 | 目标提取、数据增强 |
| hide_labels | bool | FALSE | 是否隐藏类别标签 | 美观化展示,如比赛提交 |
| hide_conf | bool | FALSE | 是否隐藏置信度数值 | 简洁显示 |
| vid_stride | int | 1 | 视频帧跳过步长,用于降低视频处理频率(提升速度) | 处理高帧率视频时优化性能 |
| line_thickness | int | 3 | 边界框线条粗细(像素) | 自定义可视化样式 |
| visualize | bool | FALSE | 是否可视化模型内部特征图(如 Backbone 输出) | 模型调试、研究用途 |
| augment | bool | FALSE | 是否对输入图像进行数据增强(如翻转、缩放)后再推理 | 提升鲁棒性,但会减慢速度 |
| agnostic_nms | bool | FALSE | 是否启用"类无关非极大抑制"(Agnostic NMS) | 多类目标重叠严重时使用 |
| classes | int / list | None | 过滤特定类别结果,如 class=0 或 class=0,2,3 | 只关心某些类别(如只检测人) |
| retina_masks | bool | FALSE | 是否使用高分辨率分割掩码(提高分割精度) | 分割任务中追求更精细边界 |
| boxes | bool | TRUE | 在分割任务中是否显示边界框 | 控制分割结果的显示方式 |
五、检测结果拓展
其实检测结果是包含这么多信息的 ,它的外层是一个list,如果我们想要取它的结果的话,最好是result0这么取
检测可视化
在 Jupyter Notebook 环境中使用 matplotlib 可视化 YOLOv8 的检测结果。将模型预测输出的图像(带有边界框、标签等)显示在 Notebook 中。
python
# 检测结果可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(result.plot()[:, :, ::-1]) # plot默认的是BGR通道,需要修改一下box信息
python
result[0].boxes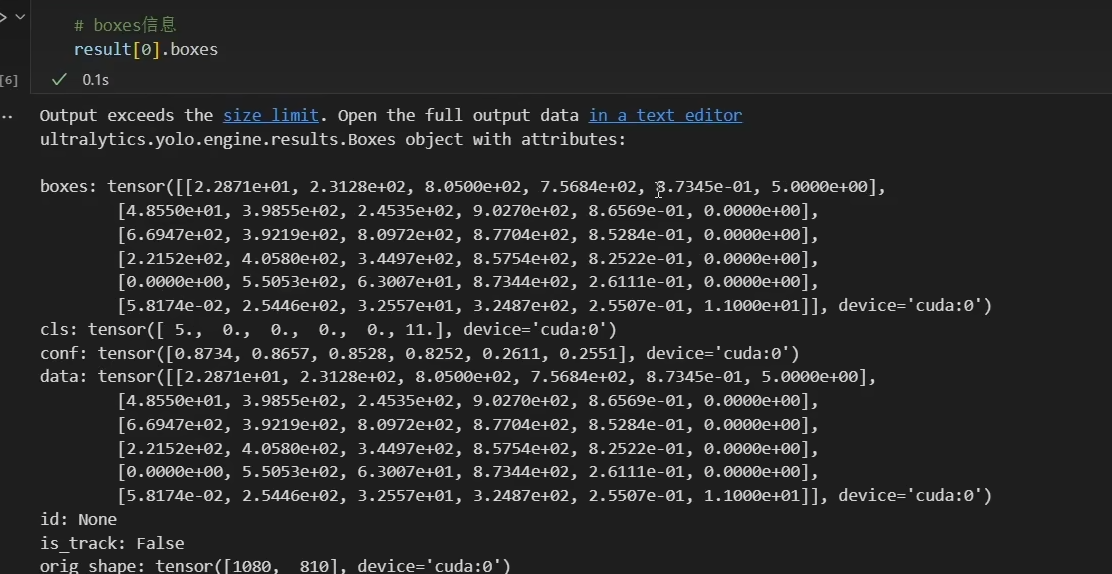
python
result[0].boxes.xywh.cpu().numpy() # tensor转换成numpy形式,展示框的信息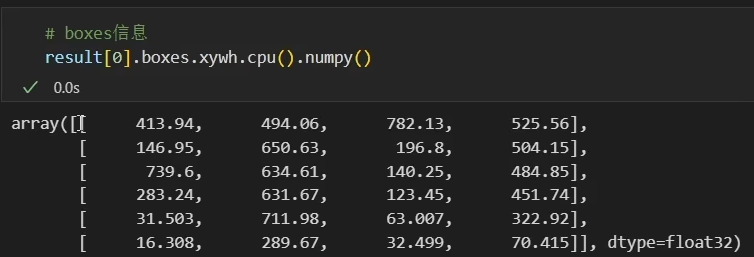
注意事项
• Jupyter中使用,要可视化模型,一定要设置%matplotlib inline,否则无法使用,因为在plot部分,YOLO强制将后端设置为了Agg • Jupyter中使用,要重新加载模型,否则预测过程中的参数,将不会更新,除非手动再次给出

六、数据准备
• 图片类型数据
• 无需额外处理,直接可以进行标注
• 视频类型数据
• 进行抽帧处理,导出为图片
视频读取帧的代码 ,可以自己试试
python
import cv2
import matplotlib.pyplot as plt
video = cv2.VideoCapture("./BVN.mp4")
ret,frame = video.read()
plt.imshow(frame)
# BGR格式需要转化成RGB格式
plt.imshow(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB))视频抽帧代码
python
video = cv2.VideoCapture("./BVN.mp4")
num = 0 # 计数器
save_step = 30 # 间隔帧
while True:
ret, frame = video.read()
if not ret:
break
num += 1
if num % save_step == 0:
cv2.imwrite("./demo_images/" + str(num) + ".jpg", frame)七、数据标注
labelimg数据集标注 or make sence标注工具(这个有辅助标注)
• 环境安装
• pip install labelimg
• 启动命令
• labelimg
• 关键设置
• autosave
• YOLO format
注:这里要切成yolo
八、计算机视觉数据集
roboflow 公开数据集
• 地址
• https://public.roboflow.com/object-detection
• https://universe.roboflow.com/
九、训练步骤
9.1训练前准备
• 数据集准备
• images:存放图片
• train:训练集图片
• val:验证集图片
• labels:存放标签
• train:训练集标签文件,要与训练集图片名称一一对应
• val:验证集标签文件,要与验证集图片名称一一对应
config/XXX.yaml文件里面配置
python
# parent
# ├── ultralytics
# └── datasets
# └── coco8 ← downloads here (1 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ...]
path: bvn # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: daitu
1: mingren9.2训练
训练
使用命令行训练
python
yolo detect train \
data=path/to/dataset.yaml \
model=yolov8n.pt \
epochs=100 \
imgsz=640 \
batch=16 \
name=exp1或者使用train.py文件来训练
python
from ultralytics import YOLO
# 加载预训练模型(或从头训练)
model = YOLO("yolov8n.pt")
# 开始训练
results = model.train(
data="./datasets/yolo-bvn.yaml", # 数据集配置
epochs=100,
imgsz=640,
batch=8,
name="bvn_train_v1",
device=0, # 0 表示 GPU,"cpu" 表示 CPU
workers=4,
cache=False
)
metrics = model.val() 推理
使用 Ultralytics YOLOv8 模型对视频文件进行目标检测
python
yolo detect predict model=runs/detect/train/weights/best.pt source=./BVN.mp4 show=True注意事项
• 以代码方式运行时
• workers要设置成0,windows
• 页面文件太小,无法完成操作
• 调整训练参数中的workers,设置为1/0
• 修改虚拟内存,将环境安装位置所在的盘,设置一个较大的参数
• 数据集描述文件
• 数据地址从datasets目录里开始写起,且就放在根目录下,会避免很多坑
• 调整数据集目录后再次训练
• 删除 ~/AppData/Roaming/Ultralytics文件夹下的settings.yaml