FPGA教程系列-8B10B编码
目的
看了几篇文章,其实目的很简单,为了防止连续的0或者1,造成不必要的损耗,所以采用这种编码的形式,来达到一个直流平衡。以下是一些原文:
8b/10b编码可以实现直流平衡,有助于减少信号传输过程中的电磁干扰(EMI)和信号失真,提高数据传输的稳定性和准确性。
由于串行链路中存在交流耦合电容,理想电容的阻抗公式为Zc=1/2πf*C。因此,随着信号频率的增加,阻抗逐渐降低;反之,频率降低时阻抗增加。在这种情况下,当信号频率较高时,传输基本上可以实现零损耗。然而,当码型为连续"0"或"1"时,电容的损耗显著增加,导致信号幅度不断下降。这带来的严重后果是无法准确识别是"1"还是"0"。因此,为了尽量减小低频码型的损耗,8b10b编码技术应运而生。
不均等性------Disparity
8b10b编码产生的输出为10位,经过8b10b编码后只存在三种情况,分别是"+2" "0" "-2",它们代表了三种不均等性(Disparity)。在这里,不均等性通过计算 "1" 的数量减去 "0" 的数量得到,即 Disparity = "1"的数量 - "0"的数量。通过利用这种不均等性与 Disparity 的关系,可以确保发送的 "0" 和 "1" 的数量保持一致,从而有效地限制了连续的 "1" 或 "0" 不超过5位。这种机制有助于维持编码的直流平衡,保障了数据的可靠传输。
Disparity=(1 的数量)−(0 的数量)
编码原理
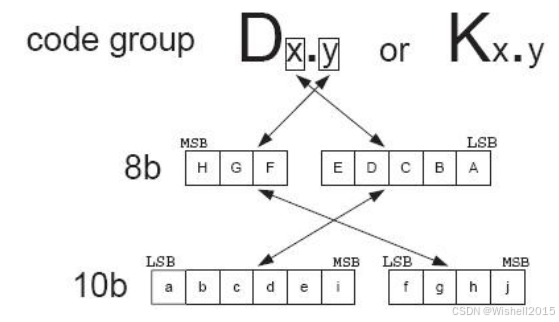
8B/10B编码方法是把8bit代码组合编码成10bit代码,代码组合包含256个数据字符编码和12个控制字符编码,分别记为Dx. y和Kx.y。
8B/10B编码方案是把8bit数据分成2个子分组: 3个最高有效位(y)和5个最低有效位( x)。代码字按顺序排列,从最高有效位到最低有效位分别记为H、G、F和E、D、C、B、A。3
bit的子分组编码成4 bit,记为j、h、g、f; 5 bit的子分组编码成6bit,记为i、e、d、c、b、a,其映射关系如图1所示, 4bit和6bit的子分组再组合成10bit的编码值。
-
3B 和 5B:8B/10B 编码将一个 8位字节 分成两部分:低 5 位(5B)和高 3 位(3B)。
-
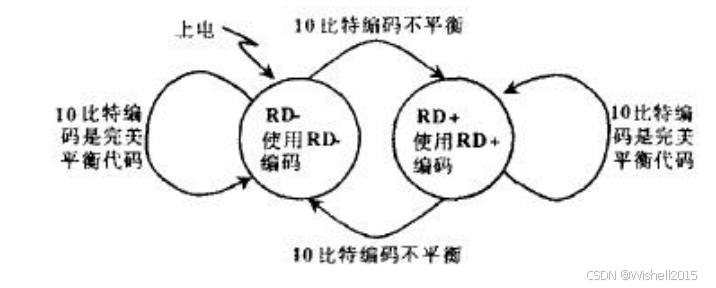
RD- 和 RD+ :即 Running Disparity(运行极性) 。
- RD- :表示之前的传输中"0"比较多(或者平衡),当前处于负极性,需要发更多的"1"来平衡,或者保持平衡。
- RD+ :表示之前的传输中"1"比较多,当前处于正极性,需要发更多的"0"来平衡。
-
单值编码 (Single Value) :该码字中"0"和"1"的数量相等(例如 6位码中有3个0、3个1),它在 RD- 和 RD+ 状态下输出是一样的,因为它不改变极性。
-
双值编码 (Double Value) :该码字中"0"和"1"数量不等,因此必须有两套编码(一套 1 多,一套 0 多),用来根据当前的 RD 状态进行反转补偿。
个人小tip:感觉有点像字节下CRC,都是通过查找表去找相应的编码。纯属个人想法。
具体解读:
规则 1:3B 部分本身是平衡的(无需借位)
高 3 位转换成的 4 位码已经是 2个0和2个1 (平衡了),它不需要去平衡别人,也不需要别人平衡它。
此时,整个 10 位码的极性压力全看低 5 位(5B)那部分。如果 5B 是不平衡的,它就自己按照标准规则去翻转。
举例:数据 D04.5 (二进制 101 00100)
3B 部分 (101) :对应的 4B 编码是 1010。
- 这里有 2 个 1,2 个 0。它是平衡的。
5B 部分 (00100) :这是不平衡的,有 2 种 6B 编码:
- 110101(4个1,2个0) -> 用来提升极性。
- 001010(2个1,4个0) -> 用来降低极性。
编码过程:
- 若当前是 RD- (缺1) :5B 选 1多的 110101,3B 选 1010。组合结果:110101 1010(整体 1 多,极性翻转)。
- 若当前是 RD+ (缺0) :5B 选 0多的 001010,3B 选 1010。组合结果:001010 1010(整体 0 多,极性翻转)。
规则 2:3B 和 5B 都不平衡(相互抵消/互补)
高 3 位是不平衡的(比如变出 3个1),低 5 位也是不平衡的(比如变出 4个1)。
如果不加控制,两个都发"1多"的码,整个系统极性就会瞬间失控。
所以,8B/10B 规定:在一个 10bit 符号内部,如果 6B 部分偏向一边,4B 部分必须偏向另一边,从而让整个 10bit 符号保持完美平衡(5个0,5个1)。
举例:数据 D01.0 (二进制 000 00001)
3B 部分 (000) :这是严重不平衡的。
- 编码 A:1011(3个1,1个0)。
- 编码 B:0100(1个1,3个0)。
5B 部分 (00001) :也是不平衡的。
- 编码 A:011101(4个1,2个0)。
- 编码 B:100010(2个1,4个0)。
编码过程(内部互补):
-
若当前是 RD- (缺1) :
- 此时系统期望保持平衡或增加1。但在该特殊规则下,我们追求"符号内平衡"。
- 6B 部分:取 1 多的 011101(RD值为4,即4个1)。
- 4B 部分 :强制取 1 少的 0100(RD值为1,即1个1)。
- 结果 :011101 0100。总共 10 位,有 4+1=5 个 1。完美平衡! 极性状态保持 RD- 不变。
-
若当前是 RD+ (缺0) :
- 6B 部分:取 0 多的 100010(RD值为2,即2个1)。
- 4B 部分 :强制取 0 少的 1011(RD值为3,即3个1)。
- 结果 :100010 1011。总共 10 位,有 2+3=5 个 1。也是完美平衡!
规则 3:特殊情况 3B=111 (避免假逗号)
当高 3 位是 111 (D7) 时,标准的 4B 编码应该是 0111 或 1000。
但是!如果低 5 位对应的 6B 编码结尾是 ...11,这时候如果你后面接一个 111...,连起来就会出现 11111。这在硬件电路里会被误判为逗号(K码,同步符号) ,或者导致连 1 过多时钟失锁。
因此,当 3B 是 111 时,需要根据 5B 长什么样,来决定 4B 是用常规编码,还是用备用编码。
举例:数据 D17.7 (二进制 111 10001)
假设当前状态是 RD+ (之前 1 太多,需要发 0),我们要发送 D17.7。
-
发送 5B (D17) :
- RD+ 下发送 100011。
- 状态保持 RD+。
-
发送 3B (x.7) :
- 按照标准规则,RD+ 下应该取 1110。
-
拼接:
- 100011 + 1110 = 1000 11 111 0
- 看中间:出现了 5 个连续的 1! (11111)
这个时候,标准规定:当 5B 是 D17, D18, D20 时,3B (111) 必须换一套编码表。
这套替代编码表是这样的:
- RD- 时:取 1000 (1个1) ------ 原本标准是 0001
- RD+ 时:取 0111 (3个1) ------ 原本标准是 1110
所以更换完以后就避免了这种情况的发生。
其他的什么带宽利用率之类的,比较一目了然了,就不再赘述。