前言
前面基本学习了 RAG 的基础使用,也简单有两个小的实战。那么 RAG 技术在现实中究竟有哪些常用的应用场景呢?
这一篇我们就以一个实战项目来将之前学的 RAG 知识串联起来。
项目背景
背景
RAG 主要用于知识检索。那么对于一个企业,会有各种各样的文档(如公司管理制度、采购流程、晋升流程等)。那我们就可以将这些塞到 RAG 知识库,然后结合 LLM 做一个企业智能知识库系统。
目标
项目应实现以下核心目标:
1. 智能文档管理
- 文档上传:支持 Word (.docx) 、PDF文档上传
- 自动分块处理:采用智能文本分割技术,将长文档切分为适合检索的语义片段
- 向量化存储:使用先进的Embedding技术将文档内容转化为向量,存储于ChromaDB向量数据库
2. 智能问答系统
- 语义检索:基于向量相似度检索,精准定位相关问题答案
- 上下文增强:自动整合检索到的相关文档片段,构建丰富的上下文提示
- 大模型生成:调用通义千问等大语言模型,生成准确、自然的回答
- 检索溯源(基础版):展示检索到的原始文档片段(相似度分数、来源文档标识等详细追溯信息开发中)
3. Web交互界面
- 简洁美观的UI:现代化的界面设计,提供流畅的用户体验
- 单轮问答:支持基于知识库的智能问答(多轮对话开发中)
- 文档管理:便捷的上传和管理企业文档
核心技术
| 层级 | 组件 | 说明 |
|---|---|---|
| Web框架 | Flask 3.1.2 | Python轻量级Web框架 |
| 向量数据库 | ChromaDB 1.3.5 | 开源向量数据库,支持持久化存储 |
| 大语言模型 | 通义千问 (qwen3.5-flash) | 阿里云大语言模型API |
| Embedding模型 | text-embedding-v4 | 阿里云文本向量化模型 |
| 文档处理 | python-docx | Word文档解析 |
| 文本分割 | LangChain | 递归字符文本分割器 |
技术框架
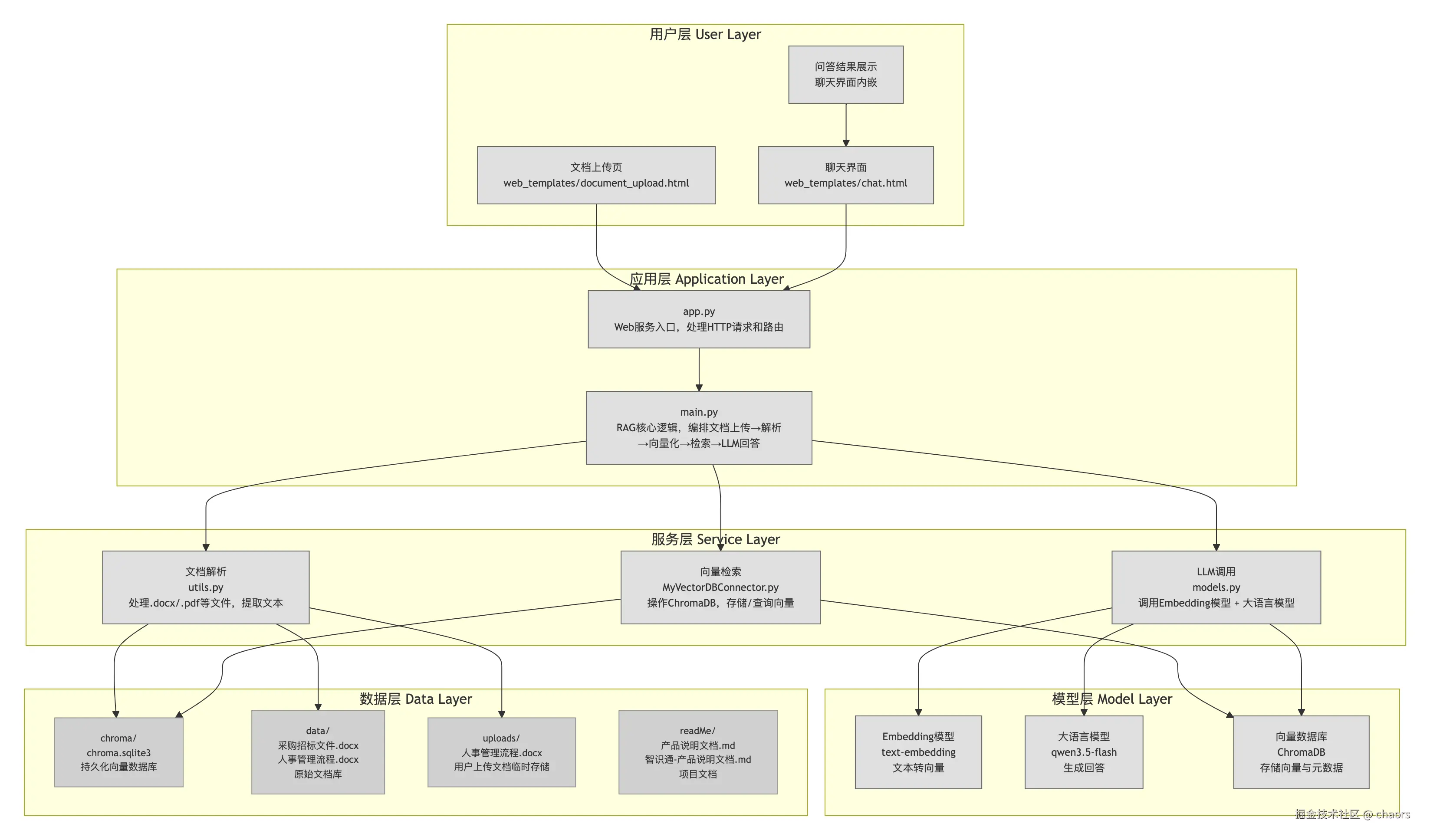
Flask
在 Langchain服务部署 接触过 Flask,他是一个用Python编写的轻量级Web应用框架 。其核心哲学是"微核",只提供路由、请求/响应处理、模板渲染等最基础的功能。这里,Flask作为胶水层,将前端请求、检索模块、大模型接口、业务逻辑等串联成一个可工作的服务。
RAG & LLM
RAG和LLM 这里的技术和代码,之前基本都用过。这里重在整合。
MyVectorDBConnector
前面我们知道,知识的检索都是基于向量数据库。所以这里需要定义一个向量数据库类。基本和前面 Vector数据库 里的写法一样。
ini
class MyVectorDBConnector:
def __init__(self):
# 创建ChromaDB客户端
# PersistentClient表示"持久化客户端",数据会保存到本地文件
# path="../chroma" 表示数据保存在一级目录的chroma文件夹中
self.chroma_client = chromadb.PersistentClient(path="../chroma")
# 创建AI模型客户端(用于生成向量)
# get_normal_client() 在models.py中定义,返回OpenAI格式的客户端
self.client = get_normal_client()
def get_embeddings(self, texts, model=ALI_TONGYI_EMBEDDING_V4):
return [x.embedding for x in data]
def get_embeddings_batch(self, texts, model=ALI_TONGYI_EMBEDDING_V4, batch_size=10):
all_embeddings = [] # 存储所有向量
# range(0, len(texts), batch_size) 生成批次起始索引
# 比如 len=25, batch_size=10,生成:0, 10, 20
for i in range(0, len(texts), batch_size):
# 切出当前批次的文本
# texts[0:10], texts[10:20], texts[20:25]
batch_text = texts[i:i + batch_size]
# 调用API转换这一批文本
data = self.client.embeddings.create(input=batch_text, model=model).data
# 将结果添加到总列表中
all_embeddings.extend([x.embedding for x in data])
print(f"【Embedding】已处理 {min(i + batch_size, len(texts))}/{len(texts)} 条")
return all_embeddings
def add_documents(self, documents, collection_name='demo'):
# get_or_create_collection: 获取集合,如果不存在就创建
collection = self.chroma_client.get_or_create_collection(name=collection_name)
# collection.add() 添加数据到集合
# 需要三个参数:
# 1. embeddings: 每个文档的向量表示
# 2. documents: 文档的原文
# 3. ids: 每个文档的唯一标识符
collection.add(
embeddings=self.get_embeddings_batch(documents), # 向量列表
documents=documents, # 原文列表
ids=[str(uuid.uuid4()) for _ in documents] # 唯一ID列表
)
print(f'【向量数据库】成功添加 {len(documents)} 个文档片段')
def search(self, query, collection_name='demo', n_results=5):
# 获取集合
collection = self.chroma_client.get_or_create_collection(name=collection_name)
# collection.query() 执行向量相似度搜索
# query_embeddings: 查询文本的向量(把问题转成向量)
# n_results: 返回最相似的n条结果
results = collection.query(
query_embeddings=self.get_embeddings_batch([query]),
n_results=n_results
)
return resultsutils
这个目录主要提供额外的工具类,比如models获取、文档解析等。
LLM Model
ini
def get_completion(prompt, model=ALI_TONGYI_TURBO_MODEL):
messages = [{"role": "user", "content": prompt}]
# 获取AI客户端
client = get_normal_client()
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 0表示最确定,不随机
)
# 从响应中提取AI的回答文本
# response.choices[0] 是第一个回答选项
# .message.content 是回答的内容
return response.choices[0].message.contentdoc处理
- 功能:从Word文档中提取文字内容
- 参数:filename: Word文档的文件路径
- 返回值:文档内容列表,每个元素是一段文字(已经被切分)
- 处理流程:
- 打开Word文档
- 读取所有段落的文字
- 将长文本切分成小块(方便检索)
- 为什么要切分?
- 一篇文档可能很长(几千字),如果整体存储:
- 检索时只能整篇匹配,不够精确
- 可能超出模型处理长度限制
- 一篇文档可能很长(几千字),如果整体存储:
ini
def extract_text_from_docx(filename):
full_text = '' # 存储完整文本
# Document() 打开Word文档
doc = Document(filename)
# 遍历文档中的所有段落
# doc.paragraphs 是段落列表
for para in doc.paragraphs:
# para.text 获取段落文字
# .strip() 去除首尾空白
# 只保留非空段落
if para.text.strip():
full_text += para.text + '\n' # 加换行符分隔段落
print(f'【文档读取】原文共 {len(full_text)} 个字符')
# 使用RecursiveCharacterTextSplitter切分文本
# chunk_size=300: 每个块大约300个字符
# chunk_overlap=30: 相邻块重叠30个字符(避免信息断裂)
splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # 块大小
chunk_overlap=30 # 重叠大小
)
# split_text() 执行切分
documents = splitter.split_text(full_text)
print(f'【文档读取】切分成 {len(documents)} 个片段')
return documentspdf-MyPDF2Text
由于 pdf 的解析较 doc 文件更为复杂,这里单摘出一个类用于pdf的解析。
python
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def extract_text_from_pdf(self, filename: str) -> List[Document]:
# 1. 基础验证
if not os.path.exists(filename):
raise FileNotFoundError(f"文件不存在: {filename}")
if not filename.lower().endswith('.pdf'):
raise ValueError("文件必须是PDF格式")
logger.info(f"【PDF解析】开始处理: {filename}")
# 2. 检测PDF类型并选择合适的解析器
pdf_type = self._detect_pdf_type(filename)
logger.info(f"【PDF检测】文件类型: {pdf_type}")
# 3. 根据类型选择解析策略
if pdf_type == "digital" and not self.use_ocr:
# 数字PDF,使用高效解析
pages_text = self._parse_digital_pdf(filename)
else:
# 扫描件或强制OCR
pages_text = self._parse_scanned_pdf(filename)
# 4. 后处理:清理文本
cleaned_text = self._post_process_text(pages_text)
# 5. 智能分块
documents = self.splitter.create_documents([cleaned_text])
# documents = self.splitter.split_text(cleaned_text)
# 6. 添加元数据
for i, doc in enumerate(documents):
doc.metadata.update({
"source": filename,
"page_count": len(pages_text),
"chunk_index": i,
"total_chunks": len(documents),
"pdf_type": pdf_type
})
logger.info(f"【PDF解析】完成!提取{len(pages_text)}页,分割为{len(documents)}个文档块")
return documentsto_pinyin()
- 装饰器:将中文集合名转换为拼音
- 作用:有些数据库不支持中文作为标识符,所以把中文转成拼音更安全。
- 🌰:"人事管理流程.docx" -> "renshiguanliliuchengdocx"
ini
def to_pinyin(fn):
@wraps(fn) # 保留原函数的元信息
def chinese_to_pinyin(*args, **kwargs):
# 获取collection_name参数
chinese_name = kwargs['collection_name']
# 去掉文件名中的点号(.)
chinese_name = chinese_name.replace('.', '')
# 使用pypinyin库将中文转为拼音
# style=Style.NORMAL: 普通风格,不带声调
# heteronym=False: 不使用多音字
pinyin_list = pinyin(chinese_name, style=Style.NORMAL, heteronym=False)
# 将拼音列表拼接成字符串
# word[0] 取每个字的第一个拼音
# .lower() 转成小写
pinyin_str = ''.join([word[0].lower() for word in pinyin_list])
# 替换参数中的中文名为拼音
kwargs['collection_name'] = pinyin_str
# 调用原函数
return fn(*args, **kwargs)
return chinese_to_pinyinmain(RAG)逻辑
这里是文档加载,检索的核心逻辑所在。这里定义的几个函数会在 app 文件被调用,用于和前端页面交互并产出结果。
简单地说,main里的函数都是可以写在 app 里的,这里只是为了解耦前端与客户端做的封装。这样 main 专注的是 RAG 逻辑,app 更专注前端逻辑。符合"注意力分离"的设计逻辑。
数据库存储
ini
def save_to_db(filepath, collection_name='demo'):
# documents变量用来存储文档内容
documents = ''
# 根据文件扩展名判断文件类型,调用对应的读取函数
# 目前只支持Word文档(.docx 或 .doc)
if filepath.endswith('.docx') or filepath.endswith('.doc'):
# 调用extract_text_from_docx函数读取Word文档
# 这个函数在function_tools.py中定义
documents = extract_text_from_docx(filepath)
# 检查是否成功读取到内容
if not documents:
print('【错误】读取文件内容为空')
return '读取文件内容为空'
vector_db.add_documents(documents, collection_name=collection_name)智能问答
都是前面 的基本用法,没什么可说的。这里注意📢函数返回两个值:
- AI生成的答案
- 检索到的原始文档片段
后者用于展示给用户,增加可信度。当然这里也可以根据我们的实际需要,返回其他字段。🌰:
- distances:相似度
ini
def rag_chat(user_query, collection_name='demo', n_results=5):
search_results = vector_db.search(
user_query,
collection_name=collection_name,
n_results=n_results
)
# 获取检索到的文档内容(取第一个列表,因为query只有一个)
retrieved_docs = search_results['documents'][0]
# 将检索到的文档片段用换行符连接成一个字符串
# 这就是提供给AI的"已知信息"
info = '\n'.join(retrieved_docs)
# 构建完整的Prompt
# f"""...""" 是Python的f-string,可以在字符串中嵌入变量
prompt = f"""
你是一个专业的企业知识库问答助手。
你的任务是根据下述给定的已知信息回答用户问题。
请确保你的回复完全依据下述已知信息,不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"根据现有资料,我无法回答您的问题"。
【已知信息】:
{info}
================================================================================
【用户问题】:
{user_query}
================================================================================
请用中文回答用户问题,回答要简洁明了。
"""
response = get_completion(prompt)
print('AI回答生成完成')
print('=' * 100)
return response, retrieved_docs测试
Code
python
if __name__ == '__main__':
print("=" * 100)
print("开始测试 RAG 系统")
print("=" * 100)
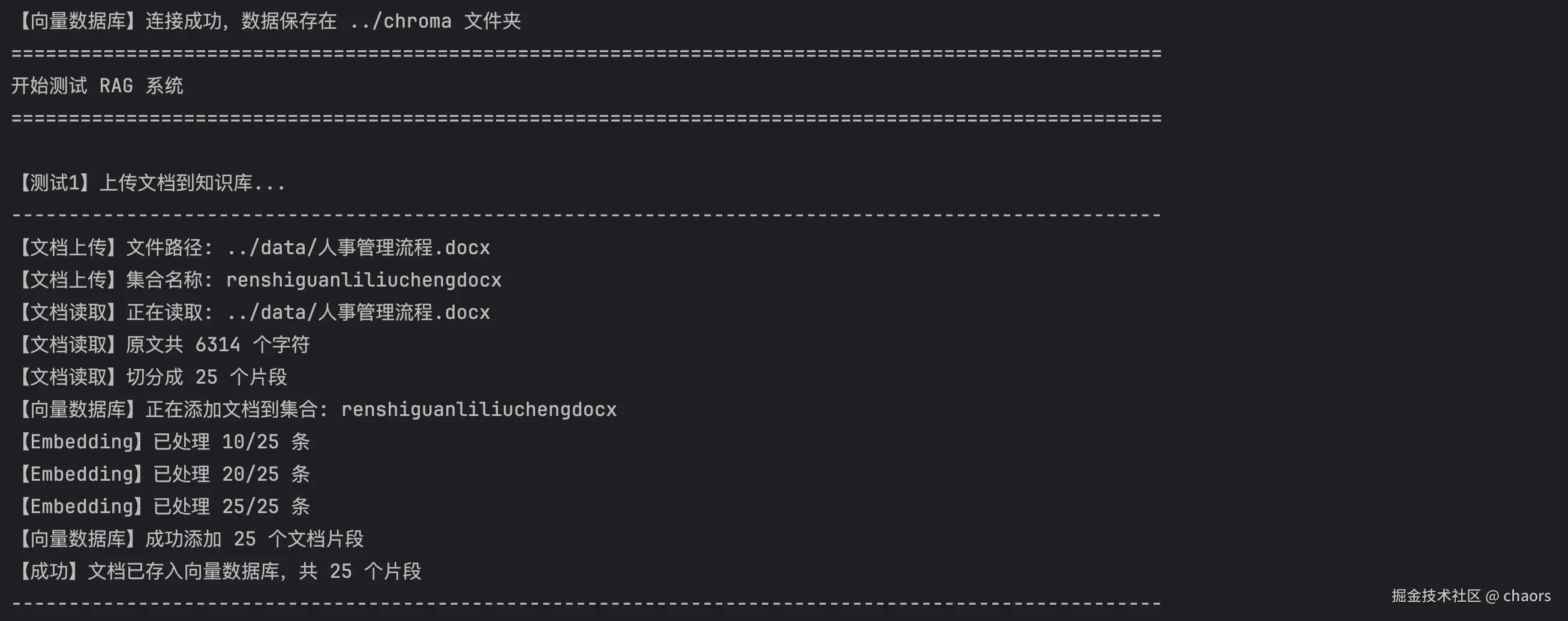
# ------ 测试1:上传文档 ------
print("\n【测试1】上传文档到知识库...")
# 调用save_to_db函数,将测试文档存入向量数据库
# filepath: 文档路径(..表示上级目录)
# collection_name: 用文件名作为集合名
save_to_db(
filepath='../data/人事管理流程.docx',
collection_name='人事管理流程.docx'
)
print('-' * 100)
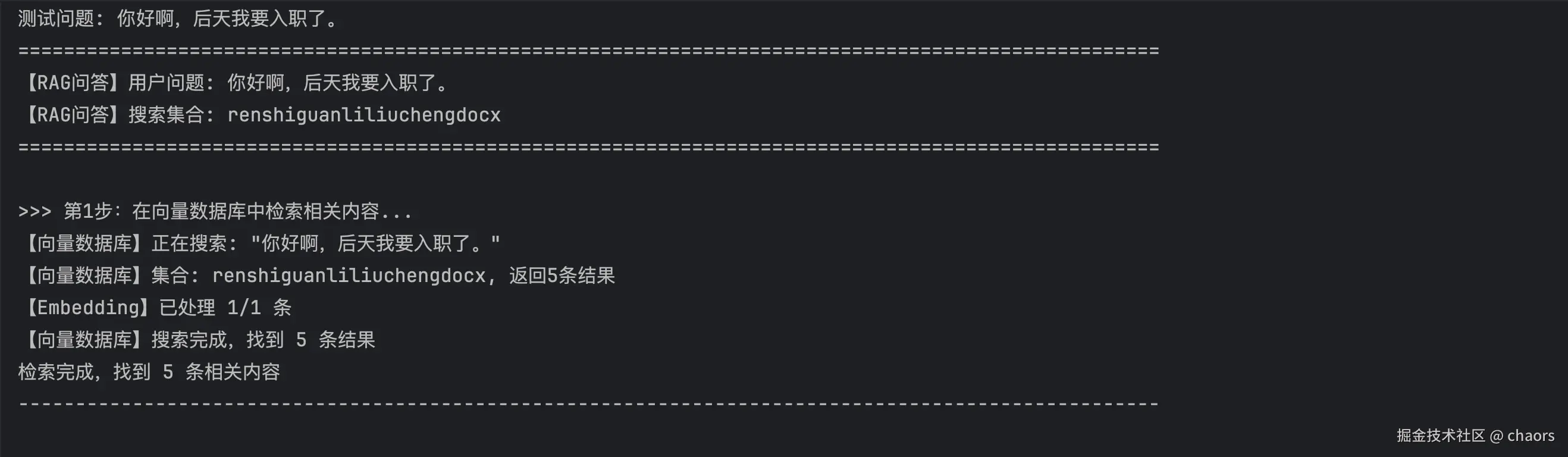
# ------ 测试2:智能问答 ------
print("\n【测试2】测试智能问答功能...")
# 定义测试问题
user_query = "视为不符合录用条件的情形有哪些?"
print(f"测试问题: {user_query}")
# 调用rag_chat函数获取答案
response, search_results = rag_chat(
user_query,
collection_name='人事管理流程.docx',
n_results=5
)
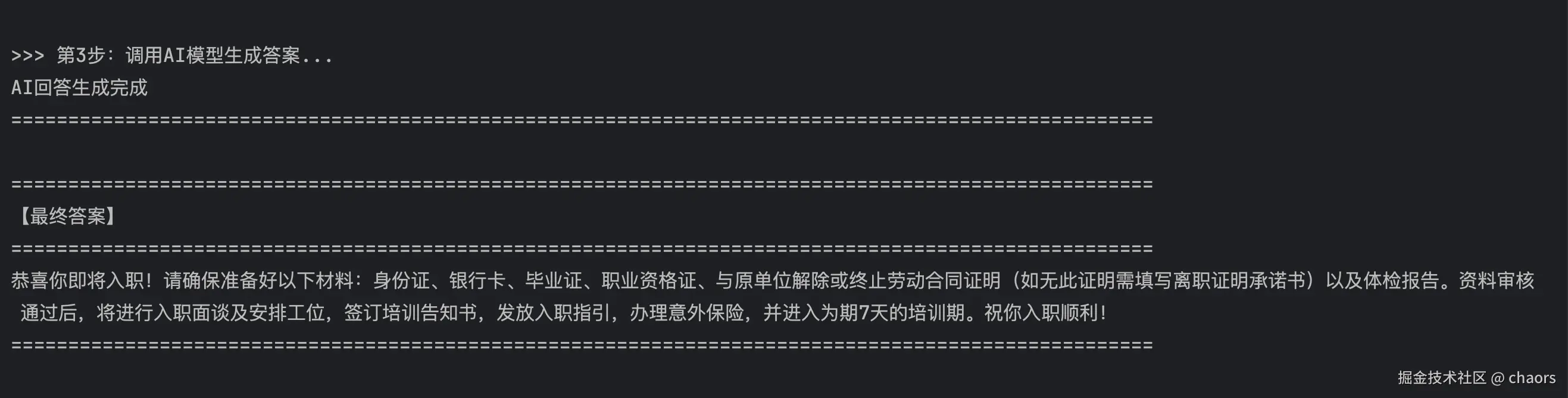
# 打印最终结果
print("\n" + "=" * 100)
print("【最终答案】")
print("=" * 100)
print(response)
print("=" * 100)Run
文档上传
向量数据库检索
LLM-Prompt构造

LLM-Answer
app(前端逻辑)
至此,RAG 检索的核心逻辑就完成了。但是我们程序员使用没问题,也不能批量上传文件。我们把他做成一个前端应用,如此才能让广大员工像使用App/网页一样使用这个智能知识库。
app文件就是实现这个的,这里使用的是 Flask 框架来联通 RAG 服务和前端页面。
Flask初始化
ini
# Flask(__name__) 创建一个Flask应用实例
# __name__ 是Python的特殊变量,表示当前模块的名字
# template_folder默认app同级目录下名为templates的目录
app = Flask(__name__, template_folder='web_templates')upload功能
UPLOAD_FOLDER配置
ini
# UPLOAD_FOLDER: 上传的文件保存在哪个文件夹
# 这里设置为 'uploads',表示文件会保存在项目目录下的uploads文件夹中
UPLOAD_FOLDER = '../uploads'
# 检查uploads文件夹是否存在,如果不存在就创建它
# os.path.exists() 检查路径是否存在
# os.makedirs() 创建文件夹
if not os.path.exists(UPLOAD_FOLDER):
os.makedirs(UPLOAD_FOLDER)
# 将上传文件夹的配置告诉Flask
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER文件类型
文件类型检查,只有符合条件的文件才允许上传。目前只允许上传 .docx (Word文档) 和 .pdf 文件。
ini
# ALLOWED_EXTENSIONS 是一个集合(set),存储允许的文件扩展名
ALLOWED_EXTENSIONS = {'docx', 'pdf'}
def allowed_file(filename):
extension = filename.rsplit('.', 1)[1].lower()
# 检查扩展名是否在允许的集合中
is_allowed = extension in ALLOWED_EXTENSIONS
return has_dot and is_allowed设置知识库
ini
# collection_name: 当前使用的知识库名称
# 在向量数据库中,每个上传的文档会创建一个"集合"(collection)
# 查询时会在当前集合中搜索相关内容
collection_name = 'demo' # 默认集合名称为'demo'
# 检查uploads文件夹中是否已有上传的文档
# os.listdir() 列出文件夹中的所有文件
name_list = os.listdir(UPLOAD_FOLDER)
# 如果有文件,就把第一个文件名作为当前集合名称
# 这样系统启动后会自动使用最新上传的文档
if name_list:
collection_name = name_list[0]route路由配置
@app.route() 是装饰器,用来定义URL路由,当用户访问某个网址时,Flask会调用对应的函数。
document_upload
- 功能:处理文档上传
- URL:/document_upload/
- 请求方式:
- GET: 用户打开上传页面(浏览器输入网址)
- POST: 用户提交表单(点击上传按钮)
- 流程:
- GET请求 -> 显示上传页面
- POST请求 -> 接收文件 -> 保存文件 -> 存入向量数据库
- render_template:Flask会根据 templetes内提供的模版来渲染网页
python
@app.route('/document_upload/', methods=['GET', 'POST'])
def document_upload():
# ====== 情况1: 用户打开页面 (GET请求) ======
if request.method == 'GET':
return render_template('document_upload.html')
# ====== 情况2: 用户提交文件 (POST请求) ======
elif request.method == 'POST':
# --- 步骤1: 检查是否有文件被上传 ---
# request.files 是一个字典,包含所有上传的文件
# 'file' 是表单中文件输入框的name属性
if 'file' not in request.files:
flash('没有选择文件') # 显示错误提示
return redirect(request.url) # 刷新页面
# 获取上传的文件对象
file = request.files['file']
# --- 步骤2: 检查文件名是否为空 ---
if file.filename == '':
return redirect(request.url)
# --- 步骤3: 检查文件类型并保存 ---
if file and allowed_file(file.filename):
# 获取文件名
filename = file.filename
file_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
# 保存文件到uploads文件夹
file.save(file_path)
# --- 步骤4: 将文档存入向量数据库 ---
global collection_name
# 使用正则表达式处理文件名,去除路径分隔符
# re.split(r'[/\]', filename) 按 / 或 \ 分割
# [-1] 取最后一部分(真正的文件名)
collection_name = re.split(r'[/\]', filename)[-1]
save_to_db(file_path, collection_name=collection_name)
# 上传完成后,刷新页面
return redirect(request.url)
# ====== 其他情况 ======
else:
return render_template('document_upload.html')/
主页面。
less
@app.route('/') # 根路径,访问 http://127.0.0.1:5000/ 会到这里chat
聊天页面。注意这里的return值是一个json格式:
jsonify({ 'response': response, # AI的回答 'search_results': search_results # 检索到的相关文档片段 })
ini
@app.route('/chat/', methods=['GET', 'POST'])
def chat():
# ====== 情况1: 用户打开页面 (GET请求) ======
if request.method == 'GET':
return render_template('chat.html')
# ====== 情况2: 用户发送问题 (POST请求) ======
elif request.method == 'POST':
message = request.json.get('message')
# 检查问题是否为空
if message:
response, search_results = rag_chat(
message,
collection_name=collection_name,
n_results=5
)
# 将检索结果合并成一个字符串(用于调试)
final_search_results = '\n'.join(search_results)
# 返回JSON格式的响应给前端
# jsonify() 将Python字典转换为JSON字符串
return jsonify({
'response': response, # AI的回答
'search_results': search_results # 检索到的相关文档片段
})
else:
# 400 是HTTP状态码,表示"错误的请求"
return jsonify({'error': '请输入问题'}), 400collection
管理和切换知识库(文档集合)。当上传了多个文档时,用户可以切换使用哪个文档进行问答
python
@app.route('/collection/', methods=['GET', 'POST'])
def collection():
# 声明使用全局变量,这样修改会影响到其他函数
global collection_name
# ====== 情况1: 获取文档列表 (GET请求) ======
if request.method == 'GET':
# 获取uploads文件夹中的所有文件名
name_list = os.listdir(UPLOAD_FOLDER)
# 如果有文件,返回文件列表和当前使用的文档名
if name_list:
return {
'name_list': name_list, # 所有文档名称列表
'collection_name': collection_name # 当前使用的文档名
}
# 如果没有文件,返回空列表
return {
'name_list': [],
'collection_name': collection_name
}
# ====== 情况2: 切换文档 (POST请求) ======
elif request.method == 'POST':
# 获取前端传来的新文档名称
new_collection = request.json.get('collection_name')
# 更新全局变量
collection_name = new_collection
print('已切换到文档:', collection_name)
# 重定向到聊天页面
return redirect('/chat/')
# 其他情况,重定向到聊天页面
return redirect(request.url)web_templetes
app 渲染网页需要的 html 模版。属于前端知识,这里不做过多赘述。
Run
ini
if __name__ == '__main__':
# app.run() 启动Flask开发服务器
# debug=True 开启调试模式:
# - 代码修改后自动重启
# - 出错时显示详细的错误信息
# - 不要在生产环境使用!
# 默认port=5000
app.run(debug=True, port=5555)
# 启动后,在浏览器访问 http://127.0.0.1:5555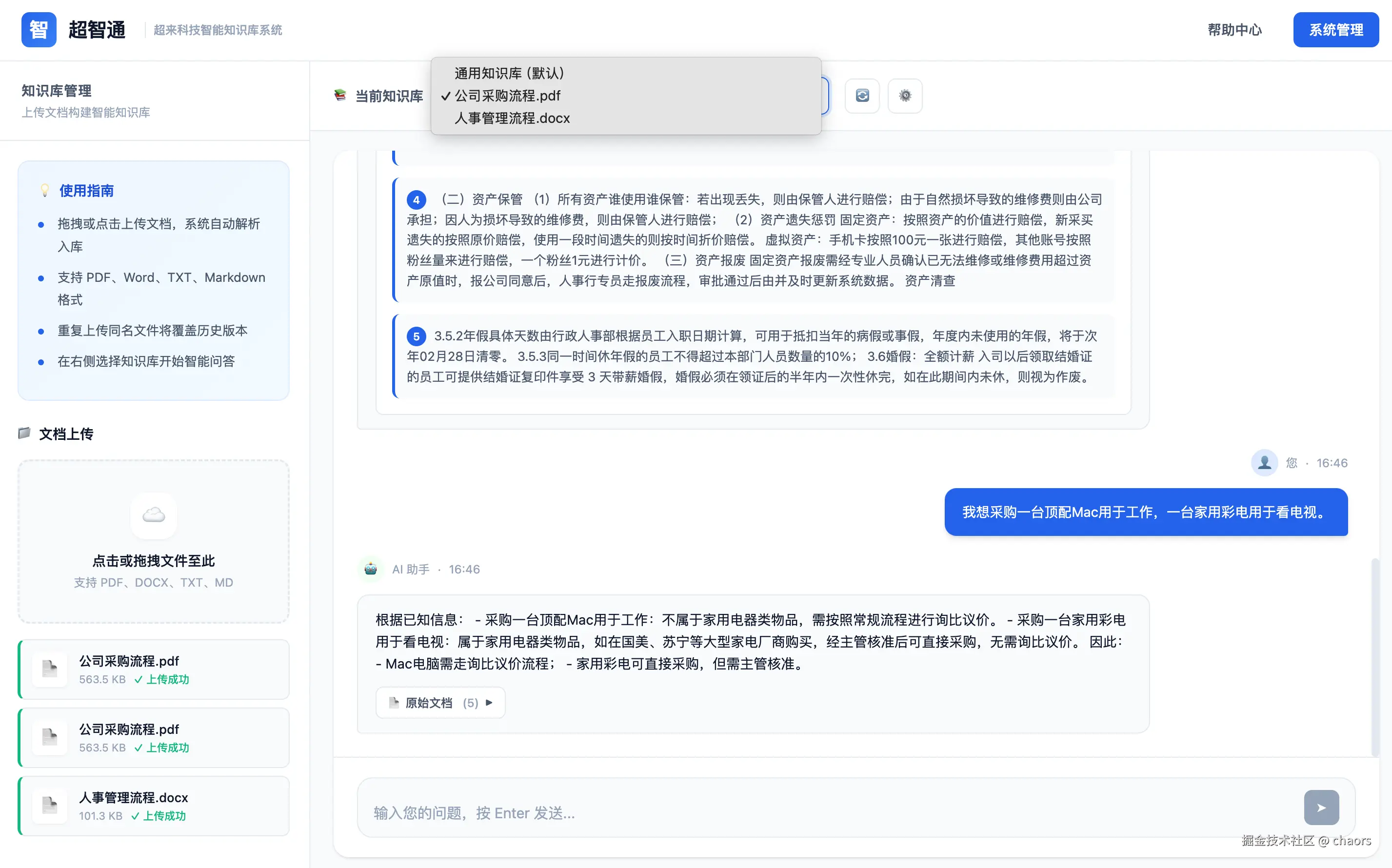
扩展
待完善
至此,一个简单可用的企业智能知识库就开发完成了,也算是麻雀虽小五脏俱全。整体核心原理已基本实现,后续就是其他锦上添花的功能。比如性能优化、前端界面美化、前端实现更多功能、文档失效性检查等等。
思考🤔🤔🤔
那么,问题来了:我们做这个真的有用吗?又是 RAG 又是 LLM 的,听上去很唬人也很酷,可是他跟传统的内部文库搜索有什么本质区别呢?在整体效率上又能提高多少呢?我觉得这确实是一个我们应该努力思考的问题。
-
传统文库搜索:本质是 "匹配-排序" 。它基于倒排索引等技术,将文档拆解为关键词(词元),核心工作是计算用户查询词与文档集的匹配度(如TF-IDF、BM25),然后返回一个相关文档的列表。它理解的是"词",而不是"意"。
- 🌰:搜"苹果",他只知道它知道"苹果"这个词经常出现在哪几个文档,但并不知道"苹果"之真实是含义:是水果还是科技公司。
-
RAG 的核心是 "理解-检索-生成" 的闭环。它分为三步:
-
理解 :利用大模型的嵌入能力,将用户问题和所有知识文档都转化为高维空间的向量(机器语言的"语义指纹")。
-
检索:不是匹配关键词,而是在向量空间中,快速找到与问题"语义指纹"最相似的几段知识片段。
-
生成:指令大模型扮演"分析师"角色,基于检索到的最相关片段,组织语言,直接生成一个精准、连贯的答案,并可以注明参考来源。
简言之,传统搜索处理的是词语的符号 ,而RAG处理的是词语的语义向量表征,是知"词",也知"意"的、。
| 效率维度 | 文库搜索 | RAG智能问答 |
|---|---|---|
| 耗时 | 分钟级(搜索+人工浏览筛选) | 秒级(直接获得答案) |
| 准确性与可用性 | 高度依赖用户关键词提炼能力和运气,返回的是"可能相关的文档"。 | 基于最相关上下文生成,答案精准、完整、口语化,并支持多轮追问 |
| 门槛与体验 | 需要用户熟悉内部文档命名、分类逻辑和关键词。 | 自然语言交互,新人也能快速上手,体验接近ChatGPT。 |